前言
上一篇文章我们讲了 Agent 的三要素:LLM 是大脑,Tools 是手脚,Messages 是记忆。
Tool 是 Agent 能从"聊天机器人"升级为"能干活的助理"的关键。没有 Tool,AI 只能空谈;有了 Tool,AI 能读文件、写代码、查数据库、发邮件------真正把手伸进现实世界。
但这套手脚怎么装?LLM 怎么知道什么时候用哪个 Tool?参数怎么传?这篇文章把 Tool 的一切讲清楚。
一、Tool 的本质:函数 + 说明书
Tool 就是一个普通的函数,但多了一层 JSON 格式的"说明书"。LLM 读不懂你的代码,它读的是这份说明书。
bash
说明书(function definition)→ 给 LLM 看的,让它知道什么时候用、怎么传参
实现(function body) → 给运行时执行的,真正干活的代码一个完整的 Tool 定义长这样:
javascript
{
type: "function", // 固定值,类型声明
function: {
name: "get_closing_price", // 函数名:snake_case,动词开头
description: "获取指定股票的最近收盘价。需要股票全称,如'青岛啤酒'、'贵州茅台'。",
parameters: { // 参数 JSON Schema
type: "object",
properties: {
name: {
type: "string",
description: "股票全称,如'青岛啤酒'"
}
},
required: ["name"]
}
}
}五个字段各司其职:
| 字段 | 作用 | 谁来用 |
|---|---|---|
type |
类型声明,固定写 "function" |
API 协议 |
name |
LLM 靠这个名字决定"我要调这个" | LLM |
description |
LLM 靠这个判断"这个 Tool 能干什么、该不该用" | LLM(最重要!) |
parameters |
LLM 靠这个知道"该传什么参数、参数长什么样" | LLM |
| 函数体(代码) | 真正执行操作,返回结果 | 你的程序 |
二、description:Tool 的灵魂
LLM 不理解你的代码。它只看 description。
description 的好坏,直接决定了 LLM 能不能在正确的时机选中正确的 Tool、传正确的参数。它是 LLM 和你的 Tool 之间唯一的语义接口。
javascript
// ❌ 差 --- LLM 不知道该不该调
description: "获取股票信息"
// ❌ 也差 --- 何时用、用什么参数都不清楚
description: "获取收盘价"
// ✅ 好 --- 功能、场景、边界、输入格式全说清楚了
description: "根据完整股票名称查询最近交易日收盘价。" +
"支持 A 股主板,不支持港股和美股。" +
"一周内未开盘则返回最近交易日数据。" +
"输入须为股票全称,如'青岛啤酒',不要用代码。"description 写作黄金法则:
| 要包含的要素 | 作用 | 示例 |
|---|---|---|
| 功能 | 这个 Tool 做什么 | "查询最近交易日收盘价" |
| 适用场景 | 什么时候用 | "当用户需要股价信息时" |
| 限制条件 | 什么时候不能用 | "不支持港股美股" |
| 输入提示 | LLM 怎么正确传参 | "股票全称,如'青岛啤酒'" |
三、parameters 与 properties:大门和格子
这是最容易被搞混的两个概念。
css
parameters ─────────────── 大门:声明"这个 Tool 接收什么"
├── type: "object" ← 固定套路,参数总是一个 JSON 对象
├── properties ← 格子们:每个参数逐个定义
│ ├── 字段A: { type: "string", description: "..." }
│ ├── 字段B: { type: "integer", description: "..." }
│ └── 字段C: { type: "boolean", description: "..." }
└── required: ["字段A"] ← 哪些必须填parameters 是容器,properties 是容器里的具体字段。 写 Tool 时,你把精力放在 properties 里每个字段的定义上------尤其是每个字段的 description。
参数 description 同样重要
LLM 从用户消息里提取参数值时,靠的不是参数名匹配,而是参数 description 和用户原话的语义匹配。
javascript
// 参数叫 stock_code,但用户说"茅台"------
// 如果 description 写得清楚,LLM 会主动把"茅台"翻译成"600519"
properties: {
stock_code: {
type: "string",
description: "上市公司股票代码,6 位数字。例如贵州茅台是 600519"
}
}四、parameters 里的约束全家桶
除了 type 和 description,每个参数还可以加这些约束,让 LLM 更准确:
| 约束字段 | 适用类型 | 作用 | 示例 |
|---|---|---|---|
enum |
string | 限定只能从几个值里选 | ["北京", "上海", "深圳"] |
default |
任意 | LLM 不传时用默认值 | 3 |
minimum |
number/integer | 数值下限 | 1 |
maximum |
number/integer | 数值上限 | 100 |
items |
array | 数组元素的类型定义 | { type: "string" } |
minItems |
array | 数组最少元素数 | 1 |
maxItems |
array | 数组最多元素数 | 10 |
additionalProperties |
object | false 禁止未定义的字段 |
--- |
嵌套 properties |
object | 定义嵌套对象的子字段 | --- |
一个完整示例
javascript
const tools = [{
type: "function",
function: {
name: "search_flights",
description: "搜索航班信息。用于用户查询特定日期、城市间的航班。价格单位为人民币。",
parameters: {
type: "object",
properties: {
from: {
type: "string",
description: "出发城市中文全称,如'北京'",
enum: ["北京", "上海", "广州", "深圳", "成都"]
},
to: {
type: "string",
description: "目的城市中文全称,如'上海'",
enum: ["北京", "上海", "广州", "深圳", "成都"]
},
date: {
type: "string",
description: "出发日期,格式 YYYY-MM-DD"
},
passengers: {
type: "object",
description: "乘客信息",
properties: {
adults: {
type: "integer",
description: "成人数量",
minimum: 1,
maximum: 9,
default: 1
},
children: {
type: "integer",
description: "儿童数量(2-12 岁)",
minimum: 0,
maximum: 9,
default: 0
}
},
required: ["adults", "children"]
}
},
required: ["from", "to", "date"]
}
}
}];五、调用层控制:让 LLM 听话
Tool 定义好之后,还能通过调用参数控制 LLM 的行为:
javascript
const response = await client.chat.completions.create({
model: 'deepseek-v4-flash',
messages: [...],
tools: [...],
tool_choice: "auto", // ← 控制调不调、怎么调
parallel_tool_calls: true, // ← 是否允许一次调多个
max_tool_calls: 128, // ← 单次调用上限
});tool_choice 的四种模式
| 值 | 含义 | 适合场景 |
|---|---|---|
"auto" |
LLM 自己判断:文字回答 还是 调 Tool | 最常用,适合大部分场景 |
"none" |
强制纯文字,禁止调 Tool | 你确定不需要 Tool 时 |
"required" |
强制必须调 Tool,不许直接答 | 需要强制行动时 |
{ type: "function", function: { name: "xxx" } } |
强制只调某个特定 Tool | 多 Tool 但你知道该用哪个 |
parallel_tool_calls
javascript
parallel_tool_calls: true // LLM 可一次同时调多个互不依赖的 Tool
parallel_tool_calls: false // 一次只能调一个,按顺序来当用户问"北京和上海的天气各是多少",且你有 get_weather 工具时,parallel_tool_calls: true 允许 LLM 同时发出两次天气查询,而不是先查北京、等结果、再查上海。
六、一次 Tool 调用的完整生命周期
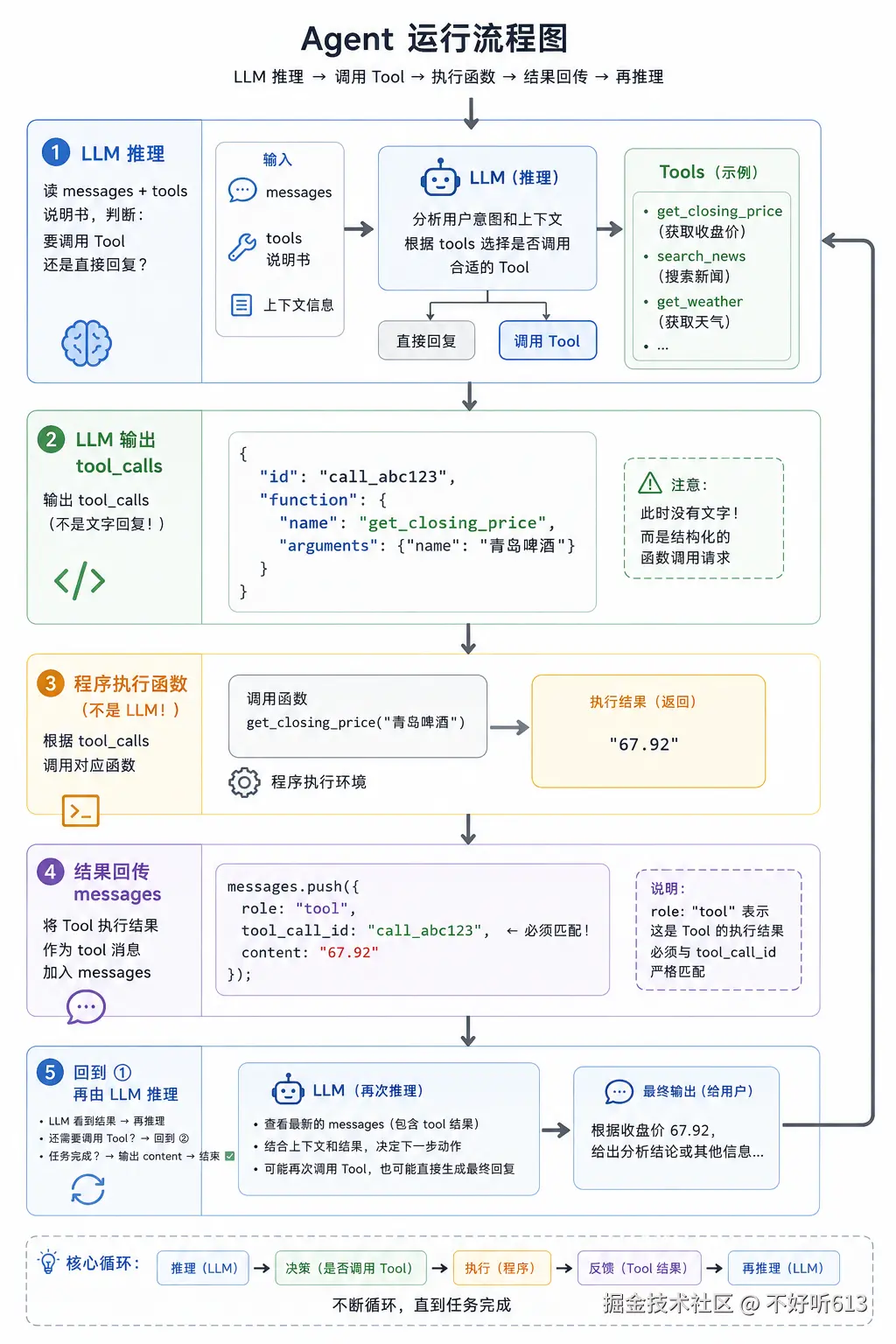
两个最容易出错的地方:
tool_call_id忘记带上 → LLM 不知道这个结果对应哪个调用,任务失败- 没有循环 → 只调了一次 LLM,拿到 tool_calls 就结束了,没有执行函数也没有把结果喂回去
七、多 Tool 场景:LLM 怎么选
当你注册了多个 Tool 时,LLM 根据每个 Tool 的 name 和 description 做语义匹配,选择最合适的那个:
javascript
tools = [
{ function: { name: "get_stock_price", description: "获取股票当前价格" } },
{ function: { name: "get_weather", description: "获取城市天气信息" } },
{ function: { name: "search_web", description: "搜索互联网获取实时信息" } },
];
// "青岛啤酒收盘价多少?" → LLM 选 get_stock_price
// "北京今天天气如何?" → LLM 选 get_weather
// "C 罗是谁?" → LLM 选 search_web 或直接文字回答(看哪个更合适)LLM 的这个选择过程本身是它推理的一部分------如果你开启了 reasoning,能从 reasoning_content 里看到它为什么选了 A 而不是 B。
八、如何让 LLM 准确用你的 Tool(工程实践)
经过上面的讲解,核心原则已经呼之欲出:
- description 是 LLM 唯一的信息来源 --- 细节写进 description,别指望 LLM 猜
- 参数的 description 同样关键 --- LLM 靠它从用户消息中提取参数值
- 善用约束 ---
enum、minimum/maximum、default能显著提高准确率 - 开启 strict --- 防止 LLM 幻觉出多余的参数
- 写出使用边界 --- description 里说清什么场景不该用这个 Tool,和说清该用一样重要
总结
arduino
Tool = name(让 LLM 选中它)
+ description(让 LLM 判断该不该用)
+ parameters(让 LLM 知道怎么传参)
参数 = properties(逐个定义每个字段)
+ required(标注必填)
+ enum/default/min/max/items(精细约束)
调用 = tool_choice(调不调)
+ parallel_tool_calls(并行吗)
+ max_tool_calls(调多少)Tool 不是"写了就行",它的每一个 description、每一个参数约束,都在直接影响 LLM 的调用准确率。