"我的磁盘怎么又满了?"------数据库存储空间全景探测与精细化瘦身实战

前面几篇我们聊了跨平台联调网络的事,也像探长一样,从好几千个并发里面,把搞卡系统的僵尸进程还有行锁冲突给找出来了。那么,平时搞数据库运维的时候,比系统变慢更让人头疼的生产级灾难,其实就是这四个英文单词:No space left on device(磁盘空间不足)。
磁盘使用率跑到 100% 会怎样呢?数据库内核就没法往磁盘写事务日志(WAL)了。这是一个大问题。整个实例马上就只读了,有时候甚至直接就内核级宕机(Crash)了。那么业务那边想写数据的话,肯定就全瘫了。
很多开发同学收到磁盘告警,第一反应就是去数据库里敲一条 DELETE。想删个几千万条半年前的日志数据来救个急。但是诡异的事情就来了:SQL 提示成功了呀,数据也没了,去服务器一看,磁盘空间竟然连 1MB 都没放出来!
那这到底是为什么呢?
搞数据库的人,其实不能只看着表面头痛医头。今天我们就跳出单一的 SQL 视角,搞一个从"OS物理层 -> DB逻辑层 -> MVCC内核层 -> 企业架构层"的排查框架出来。也就是说,我们一步步来,怎么找准空间黑洞,搞明白"删了数据却不释放空间"的底层原因。接着的话,再通过企业层级里的架构调优,把这个磁盘空间的问题给彻底解决掉。
@toc
第一阶段:宏观俯瞰 ------ 跨越 OS 与 DB 的双重视角审计
收到磁盘告警的时候,其实千万别急着登录数据库去乱查。正确的排障标准作业程序(SOP),通常来说是要先看操作系统(OS)的物理层。接着再到数据库(DB)的逻辑层里面去核对一下。
1. OS 物理层扫盲:是谁吃掉了磁盘?
那么首先,SSH 登录到你的 CentOS 数据库服务器上。我们要先搞明白,到底是不是数据库自己占的空间。因为很多时候的话,磁盘满了是因为应用打出来的日志文件太大了。或者也有可能是系统内核的 Core Dump 文件搞出来的情况。
执行以下系统级探测命令:
bash
# 1. 查看全系统挂载点的使用率,锁定爆满的磁盘分区
df -Th
# 2. 假设数据库安装在 /opt/Kingbase/ES/V9 目录下,我们进入该目录
cd /opt/Kingbase/ES/V9/data
# 3. 统计数据目录下各个核心子目录的物理大小(极其关键)
du -sh * | sort -hr | head -n 10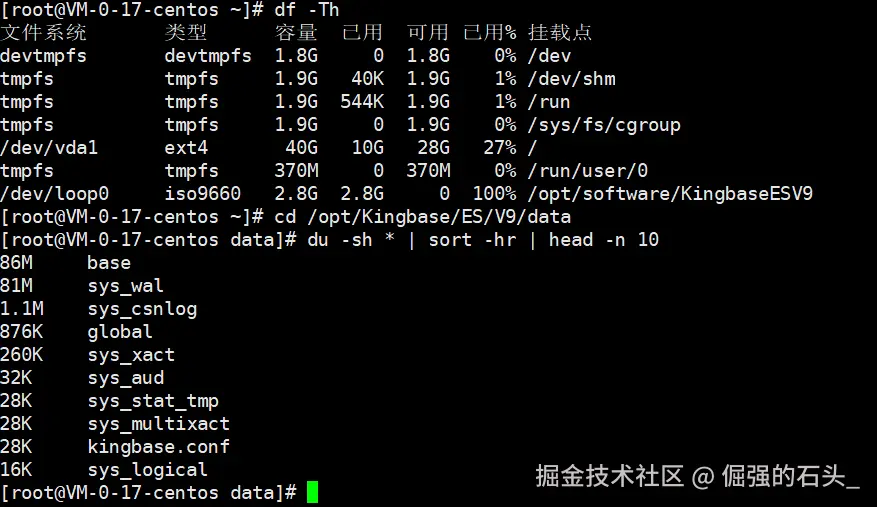
DBA 避坑指南(健康基线法则): 看看上面那个真实环境的截图。也就是说,哪怕你这个数据库实例啥业务都没跑,非常健康的情况下,容量吃得最多的永远是 base 目录,这个是放实际业务数据的。然后就是 sys_wal 目录,它是放预写式日志的。
这个健康的基线模型要记住。在真实的生产环境里头,你看到 base 目录很大,那是业务数据在涨,这很正常。但是,如果你看到 sys_wal 目录大得离谱,比如说占了几十上百GB。那为什么会这样呢?通常来说,这说明你的归档机制(Archive)失效了。也有可能是有一个极长的事务挂在那边了,历史日志堆着没法循环覆盖。这时候你去清理业务数据是没用的,必须去查系统的归档配置。
2. DB 逻辑层全景:实例与库级容量核查
确认了是业务数据,也就是 base 目录膨胀了以后,我们回到 Win11 本地。接着打开 KStudio 或者 ksql 命令行,进入数据库的管理视角里面。
一个数据库实例下面,通常来说会有好几个 Database。那么到底是谁在吃资源呢?金仓数据库这边给了几个很直观的容量测算函数。执行以下 SQL:
sql
SELECT
d.datname AS 数据库名称,
sys_size_pretty(sys_database_size(d.datname)) AS 物理总大小,
sys_database_size(d.datname) AS 原始字节数
FROM sys_database d
ORDER BY 原始字节数 DESC;(注:sys_size_pretty 这个函数的话,其实挺好用的。它会自动把那一大串字节数,给你换成 KB、MB、GB 这种好读的单位。)
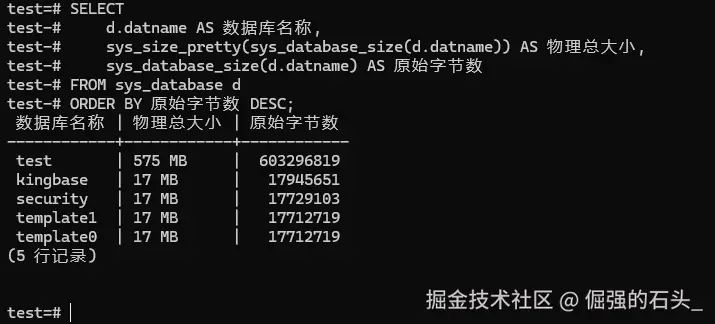
结合上面的监控反馈,我们一眼就能看出来。经过海量业务写入,那个 test 库的体积已经飙到了 575 MB,占了资源消耗的榜首,而其他系统级的默认库才 17 MB。
找到这个大库之后,还得继续往下看。因为一个库里面可能有成百上千张表。我们必须像拿显微镜一样,把那个真正吃空间的表给找出来。
第二阶段:微观狙击 ------ X 光级表级容量透视与 TOAST 探秘
很多新手只会用简单的语句去查表的数据量,也就是跑个 count(*)。但是数据行数多,其实不代表占的物理磁盘空间就大。一张表可能只有 10 万行,但是里面存了长文本,它的体积往往比一张 1000 万行但只存纯数字的表还要大。
1. 打造"DBA 超级空间扫描仪"
所以的话,我给你准备了下面这段企业层级里的"空间扫描仪 SQL"。跑一下,基本上所有表的底层物理信息就全出来了:
sql
SELECT
schemaname AS 模式名,
relname AS 表名,
sys_size_pretty(sys_relation_size(relid)) AS 纯数据大小,
sys_size_pretty(sys_indexes_size(relid)) AS 索引总大小,
sys_size_pretty(sys_total_relation_size(relid)) AS 表及附属总物理大小,
CAST(sys_indexes_size(relid) AS float) / sys_relation_size(relid) AS 索引数据比
FROM sys_stat_user_tables
WHERE sys_relation_size(relid) > 0
ORDER BY sys_total_relation_size(relid) DESC
LIMIT 10;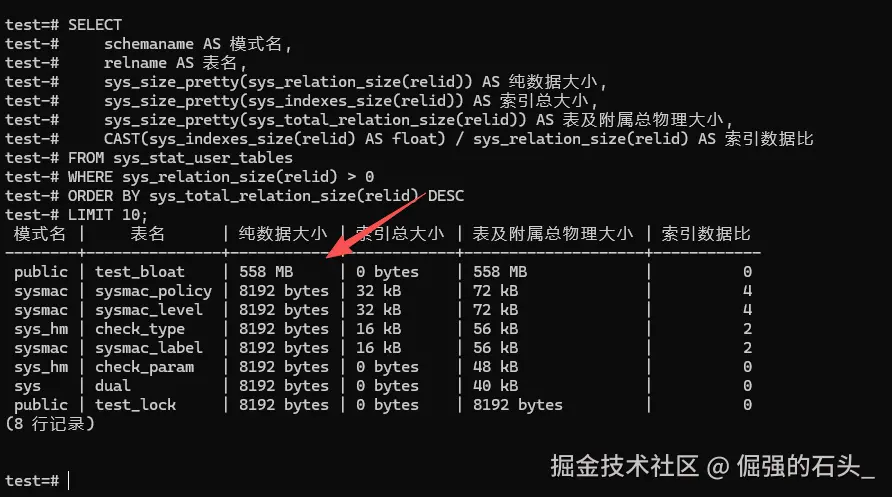
2. 深度剖析:纯数据、索引与 TOAST 机制
看着上面扫描仪出来的这个表格,你要去读懂里面藏着的那些技术门道。重点看下面这三个东西:
- 纯数据大小(
sys_relation_size): 这个的话,就是业务数据在磁盘上实实在在的占位,也就是 Heap Tuple。就像截图里红箭头指的那个,那个叫test_bloat的模拟业务日志表,纯数据就有 558 MB。这就是整个库体积暴增的元凶了。 - 索引数据比过高危机: 截图里这个表的索引是 0,因为它是一张纯日志流水表。但是如果在真实生产环境里,你看到一张表的纯数据才 1GB,索引大小居然有 5GB。也就是说索引数据比大于 5 了。那为什么会这样呢?这说明研发同学在这表上建了一堆没用的索引。每次写数据进去,数据库还得去维护那几棵庞大的索引树。这不仅浪费磁盘空间,往往更是把写入性能拉垮的致命伤。
- 神秘的差值与 TOAST 机制: 你仔细看的话,有时候会发现纯数据大小加上索引大小,还是比总物理大小要小。中间差的那些容量跑哪去了呢?这就得说说金仓底层的 TOAST(超大属性存储技术) 了。表里面要是有了巨大的 JSON 或者是长文本字段,内核就会自动把这些单行超限的大字段给切碎压缩。接着的话,转移到一张隐蔽的系统附属表里面去存着了。
第三阶段:内核揭秘 ------ 为什么删了数据,空间还没变?
那么现在,我们就要来看看开头说的那个让人崩溃的现象了:明明执行了 DELETE,为什么空间就是不释放呢?
1. 撕开 MVCC 的底层面纱
金仓数据库为了实现企业层级里的高并发读写,也就是读不阻塞写,写不阻塞读。它在内核里面用了 MVCC(多版本并发控制) 这个机制。
这个机制是怎么运作的呢?当你敲 UPDATE 去改一条数据的时候,底层并不是在原来的地方把旧数据抹掉。它是插入了一条全新的数据版本,然后给旧数据打上一个"已过期(Dead Tuple)"的标记 。同样的道理,你敲 DELETE 删数据的时候,底层也就是给这些数据打了个"被删除"的隐形标记。物理磁盘上并没有马上把它们擦掉。
那些被打上标记的,物理上还占着磁盘空间的数据,在数据库工程界叫作"表膨胀(Table Bloat)"。这也就解释了,为什么你删了百万级的数据以后,去 CentOS 上用 du -sh 看底层的物理文件,大小还是一点都不变的情况。
动手实验:一键复现表膨胀 想亲自验证一下的话,你可以在测试库跑一下这个脚本:先插 50 万条长文本数据进去,接着
DELETE删掉里面的 30 万条。这个时候你再去查这个表的物理大小,你会发现空间一点都没变,这就是经典的表膨胀现场。
2. 检测表膨胀率:揪出"虚胖"的表
那么我们需要通过系统统计视图,来看看一张表到底虚胖到什么程度了。执行以下 SQL:
sql
SELECT
relname AS 表名,
n_live_tup AS 存活数据行数,
n_dead_tup AS 死亡标记行数,
ROUND(n_dead_tup::numeric / (n_dead_tup + n_live_tup) * 100, 2) AS 虚胖膨胀率百分比
FROM sys_stat_user_tables
WHERE n_dead_tup + n_live_tup > 0
ORDER BY 虚胖膨胀率百分比 DESC;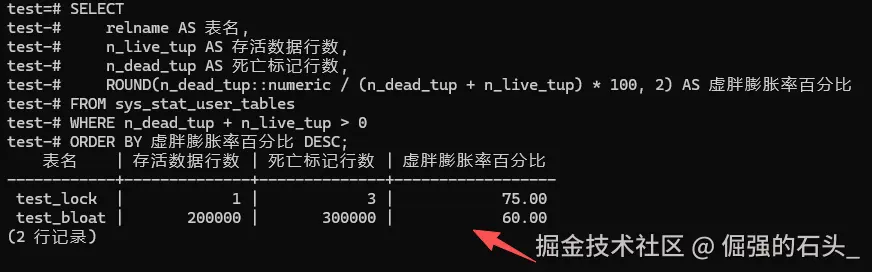
(注:要是你看到某张表的 n_dead_tup 比 n_live_tup 还要大得多,膨胀率都过了 50% 的情况了。这就说明这张表里的死数据实在太多了。也就是说,它在那白白占着空间,而且的话,你跑全表扫描的时候,性能往往也会掉得很厉害。)
3. 清理多占的空间:常规 VACUUM 与彻底的 VACUUM FULL
那么既然 DELETE 没法把空间放出来,我们怎么才能把这些死掉的数据占的物理空间,真正还给操作系统呢?其实,我们需要用到数据库里的一个清理功能,也就是清理命令(VACUUM)。
-
常规清理:
VACUUM 表名;这个操作的话,通常来说是比较轻量的。它会去扫一遍全表,然后把你那些死亡数据,也就是 Dead Tuple 占的空间,标记成可以用的状态。注意啊:它其实还是不会把空间还给操作系统的,物理文件的大小也不会变小! 那它有啥用呢?它的作用就是,以后要是再有新的INSERT数据进来的话,数据库会优先去用这些空出来的位置。也就是说,它能挡住物理文件继续变大。这个操作是不锁表的,平时经常跑一跑没问题。 -
彻底清理:
VACUUM FULL 表名;这个才是真正能把空间抠出来,还给 CentOS 操作系统的办法。那它是怎么做的呢?底层逻辑其实很简单的。也就是说,它会去建一个新的物理文件,接着把活着的那些数据都拷过去,排得紧实一点,最后把原来那个撑大的旧文件给删掉。 【高危警告】: 敲VACUUM FULL的时候,它会给这张表加上最高级别的排他锁(AccessExclusiveLock) 。啥意思呢?就是拷贝完之前,业务那边想做增删改查的话,全都会被堵住,根本执行不了!所以说,除非是半夜那种停机维护的时间段,千万别在业务跑得最猛的时候去敲这个命令!
第四阶段:架构调整 ------ 用物理隔离和分区机制解决长远问题
一直靠 VACUUM FULL 去处理问题,这其实也就是运维层面没办法的办法。那么,如果你是有架构思维的 DBA 的话,我们往往就需要去规划一下底层的东西了。也就是说,要从根本上把一个地方容量不够,还有清理的时候锁表这些痛点给解决掉。
1. 物理层空间转移:用表空间(Tablespace)来搞定
比如说你的 /opt 所在的系统盘,容量已经到 99% 了。甚至于你想跑个 VACUUM FULL,连要用的临时交换空间都挤不出来了。那遇到这种情况怎么办呢?
这个时候的话,我们可以在 CentOS 上挂一块新的 2TB 数据盘上去,比如挂到 /data_new。接着,我们用金仓数据库里面的表空间(Tablespace)功能,在业务不用停的情况下,把那些很大的历史表,挪到新的磁盘里面去:
sql
-- 1. 在新磁盘路径下创建一个名为 ts_archive 的物理表空间
CREATE TABLESPACE ts_archive LOCATION '/data_new/kingbase_ts';
-- 2. 将庞大的历史表,从默认的满载磁盘,动态腾挪到新的表空间(新磁盘)中
ALTER TABLE trade_history_log SET TABLESPACE ts_archive;敲了这条指令以后,内核就会直接把这张表的物理文件,全都搬到 /data_new 下面去了。那么这样的话,原来那个快满的系统盘,也就不用那么吃紧了。
2. 逻辑架构调整:从 DELETE 到表分区(Partitioning)
对于系统日志表、订单流水表这种带着明显时间属性,每天疯狂写入的数据。真的不要再写定时任务去 DELETE 一个月前的数据了!因为 MVCC 机制的存在,高频的大批量 DELETE 简直就是自己给自己找麻烦。
企业层级里的终极解决方案是:时间范围分区表(Range Partition)。
也就是说,在建表初期,我们就按照月份,把一张庞大的逻辑表,在物理底层切成 12 张独立的子表,就像 log_2025_01, log_2025_02 那样。
当 1 月份的数据过期了需要清理的时候,我们不再去执行 DELETE 了。而是直接敲一条很轻量的 DDL 命令:
sql
DROP TABLE log_2025_01;这种做法的好处在于: DROP TABLE 根本不走 MVCC 机制,也就不会产生什么死亡标记。它在 Linux 底层直接就把那个物理文件给抹掉了,也就是 unlink。100GB 的空间,0.1 秒内瞬间就释放还给操作系统了。一点表膨胀都不产生,而且也不会影响当前 2 月份子表的写入!
结语
这篇文章,其实走完了一个挺完整的过程。我们先是在 CentOS 上跑 du -sh 去看物理磁盘的情况。接着用 sys_total_relation_size 去摸清逻辑层面的占用。然后还扒开了 MVCC 底下那个让人头疼的"表膨胀"机制。最后呢,又用上了表空间腾挪、分区表这些手段,把整体架构往上提了一下。磁盘空间这事儿,算是实打实地处理了一回。
搞技术的,我们不光要知道怎么把空间清出来,这只是第一步。更关键的是,得搞明白"空间它到底为什么没了",把这个根儿给挖出来。然后,再往前走一步的话,就是通过事先的架构设计,把这些要命的容量问题,在它刚冒出点苗头的时候就直接按下去。
你想想看,到了这会儿,像连接数爆炸、锁冲突卡顿、磁盘空间告警这些情况,你都能应付得来了。其实这已经算是过了那个只能被动去救火的阶段了。但是,在系统更底层的地方,有时候还会藏着一些那种情况。就是平时跑得好好的,偶然给你慢一下,慢得让人摸不着头脑的诡异 SQL。
所以,在下一篇里,咱们这个系列专栏就要进入到最后的部分了,也就是------"猎捕慢查询:执行计划的微观解析与索引调优实战"。我会跟你一块儿,去琢磨那些看起来很复杂的"执行树"到底是怎么回事。然后把数据库的性能瓶颈给它控制住。行,那咱们下一篇见吧!