模型本身是无状态的。
这一次调用和下一次调用之间,模型不会自动记住你之前说过什么。它看起来"有记忆",通常是因为 Agent 在每次调用模型前,把历史消息重新组织成上下文发给了模型。
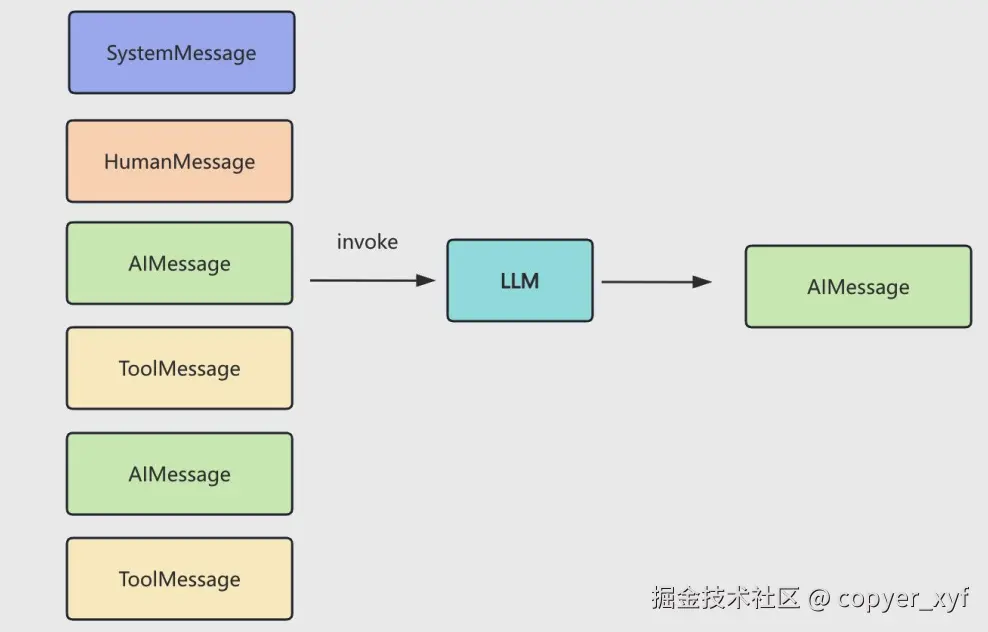
图里的关键点是:Agent 一直在收集用户消息、模型回复、工具结果,然后把这些消息组成队列。模型每次回答时,看到的是这次传进去的完整上下文,而不是它自己真的保存了记忆。
先记住一句话:Agent 的 Memory 本质上是消息管理,不是模型真的拥有记忆。
为什么需要 Memory
如果你连续问两句话:
txt
用户:我叫张三。
用户:我叫什么?第二次调用模型时,如果你只发送"我叫什么?",模型并不知道"张三"这个信息。
要让模型回答出来,就必须把前面的消息一起发过去:
txt
HumanMessage("我叫张三")
AIMessage("你好张三")
HumanMessage("我叫什么?")所以 Memory 要解决两个问题:
- 历史消息存在哪里。
- 每次调用模型时,应该带上哪些历史消息。
最简单的消息历史
最基础的 Memory 就是一个列表。
python
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
messages = [
SystemMessage(content="你是一个记得用户偏好的学习助手。"),
]
def chat(input_text: str) -> str:
# 1. 把本轮用户输入追加到消息列表
messages.append(HumanMessage(content=input_text))
# 2. 把完整 messages 发给模型
response = model.invoke(messages)
# 3. 把模型回复也存下来,供下一轮使用
messages.append(response)
return str(response.content)
chat("我叫张三,喜欢 Python。")
chat("我喜欢什么语言?")这就是最小可用的短期记忆。
优点是简单,缺点也明显:
- 进程结束后就丢失。
- 消息越来越多,迟早超过模型上下文窗口。
- 所有历史都塞给模型,成本会越来越高。
持久化消息历史
如果希望重启程序后还能继续对话,就需要把消息保存到外部存储。
最简单的方式是保存到 JSON 文件。
python
import json
from pathlib import Path
from typing import Literal, TypedDict
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
history_file = Path("chat_history.json")
class StoredMessage(TypedDict):
role: Literal["human", "ai"]
content: str
def load_history() -> list[StoredMessage]:
try:
# 1. 从文件读取历史消息
return json.loads(history_file.read_text(encoding="utf-8"))
except FileNotFoundError:
# 2. 文件不存在时,从空历史开始
return []
def save_history(history: list[StoredMessage]) -> None:
# 3. 每轮对话后写回文件
history_file.write_text(
json.dumps(history, ensure_ascii=False, indent=2),
encoding="utf-8",
)
# 消息分类
def to_langchain_messages(history: list[StoredMessage]):
result = []
for message in history:
if message["role"] == "human":
result.append(HumanMessage(content=message["content"]))
else:
result.append(AIMessage(content=message["content"]))
return result
def chat(input_text: str) -> str:
# 加载历史消息
history = load_history()
# 添加本轮消息
history.append({"role": "human", "content": input_text})
# 组装消息
messages = [
SystemMessage(content="你是一个能基于历史对话回答问题的助手。"),
*to_langchain_messages(history),
]
response = model.invoke(messages)
history.append({"role": "ai", "content": str(response.content)})
save_history(history)
return str(response.content)文件只是一个例子。
真实项目里,Memory 可以存在:
- 文件系统:适合本地工具和单机应用。
- Redis:适合临时会话和分布式服务。
- 数据库:适合长期保存和复杂查询。
- 向量数据库:适合按语义找相关历史。
为什么不能一直追加
模型有上下文窗口限制。
如果每一轮都把全部历史消息发给模型,会遇到三个问题:
- 超过上下文长度,模型调用失败。
- token 成本越来越高。
- 很早之前的无关信息会干扰当前回答。
所以 Memory 管理的重点不是"无限保存",而是"选择哪些历史应该进入本次上下文"。
常见策略有三种:
txt
截断:只保留最近消息(数量、长度)
总结:把旧消息压缩成摘要
检索:根据当前问题找相关历史按数量截断
最简单的策略是只保留最近 N 条消息。
python
from langchain_core.messages import BaseMessage, HumanMessage, SystemMessage
history: list[BaseMessage] = []
def get_recent_messages(max_messages: int) -> list[BaseMessage]:
# 保留最后 max_messages 条消息
return history[-max_messages:]
def chat_with_count_limit(input_text: str) -> str:
history.append(HumanMessage(content=input_text))
messages = [
SystemMessage(content="你是一个简洁的助手。"),
# 只把最近 6 条消息发送给模型
*get_recent_messages(6),
]
response = model.invoke(messages)
history.append(response)
return str(response.content)这种方式很好理解,但它只按消息条数处理,不关心每条消息有多长。
如果某条消息特别长,仍然可能撑爆上下文。
按长度截断
更稳一点的方式是按内容长度控制。
这里先用字符数演示思想;生产环境里可以换成模型对应的 token 计算方式。
python
from langchain_core.messages import BaseMessage, HumanMessage, SystemMessage
def get_message_text(message: BaseMessage) -> str:
# message.content 可能不是纯字符串,统一转成可计数文本
return message.content if isinstance(message.content, str) else str(message.content)
# 从后往前保留最近消息(不超过 max_chars)
def trim_by_char_length(messages: list[BaseMessage], max_chars: int) -> list[BaseMessage]:
result: list[BaseMessage] = []
total_chars = 0
# 从后往前保留最近消息
for message in reversed(messages):
length = len(get_message_text(message))
if total_chars + length > max_chars:
break
result.insert(0, message)
total_chars += length
return result
def chat_with_length_limit(input_text: str) -> str:
history.append(HumanMessage(content=input_text))
messages = [
SystemMessage(content="你是一个简洁的助手。"),
*trim_by_char_length(history, 2000),
]
response = model.invoke(messages)
history.append(response)
return str(response.content)按长度截断比按条数更接近真实 token 控制。
但它仍然会丢掉旧信息,比如用户一开始说过的名字、偏好、项目背景。
总结旧消息
总结策略的思路是:旧消息不直接丢掉,而是先压缩成摘要。
python
from langchain_core.messages import AIMessage, BaseMessage, SystemMessage, get_buffer_string
def summarize_messages(messages: list[BaseMessage]) -> str:
if not messages:
return ""
# 1. 把消息列表转成适合总结的对话文本
conversation_text = get_buffer_string(
messages,
human_prefix="用户",
ai_prefix="助手",
)
# 2. 让模型总结旧对话里的稳定信息
summary_response = model.invoke(
[
SystemMessage(
content=f"""请总结以下对话,保留用户身份、偏好、任务背景和重要结论:
{conversation_text}
总结:"""
)
]
)
return str(summary_response.content)
def compress_history(max_messages: int = 8, keep_recent: int = 3) -> None:
if len(history) <= max_messages:
return
# 3. 最近几条消息保留原文
recent_messages = history[-keep_recent:]
# 4. 更早的消息压缩成摘要
old_messages = history[:-keep_recent]
summary = summarize_messages(old_messages)
history.clear()
# 5. 摘要也作为一条消息放回历史
history.append(AIMessage(content=f"历史摘要:{summary}"))
history.extend(recent_messages)总结适合保存长期背景:
- 用户叫什么。
- 用户正在做什么项目。
- 用户偏好的回答风格。
- 前面已经达成的结论。
它的缺点是摘要可能丢细节,也可能总结错。
所以常见做法是:摘要保留长期信息,最近几轮保留原文。
检索向量数据库
有些历史消息不适合一直放在上下文里,但也不应该彻底丢掉。
这时可以把历史消息保存到可检索的存储里,当前问题来了之后,只取最相关的几条。
python
from dataclasses import dataclass
from datetime import datetime
from uuid import uuid4
from langchain_core.messages import HumanMessage, SystemMessage
@dataclass
class MemoryRecord:
id: str
text: str
created_at: str
memory_store: list[MemoryRecord] = []
def save_memory(user_input: str, ai_output: str) -> None:
# 真实项目里可以在这里生成 embedding,并写入向量数据库
memory_store.append(
MemoryRecord(
id=str(uuid4()),
text=f"用户:{user_input}\n助手:{ai_output}",
created_at=datetime.now().isoformat(),
)
)
def retrieve_memory(query: str, limit: int = 3) -> list[MemoryRecord]:
# 这里用字符串包含演示检索思想;真实项目里应替换成向量检索(向量数据库 milvus 等)
return [item for item in memory_store if query in item.text][:limit]
def chat_with_retrieval(input_text: str) -> str:
# 1. 根据当前问题找相关历史
related_memories = retrieve_memory(input_text)
memory_text = "\n\n".join(
f"历史 {index + 1}:\n{item.text}"
for index, item in enumerate(related_memories)
)
# 2. 只把相关历史放进本次上下文
messages = [
SystemMessage(
content=(
"你是一个能利用相关历史回答问题的助手。"
+ (f"\n相关历史:\n{memory_text}" if memory_text else "")
)
),
HumanMessage(content=input_text),
]
response = model.invoke(messages)
# 3. 保存本轮对话,供未来检索
save_memory(input_text, str(response.content))
return str(response.content)检索式记忆适合:
- 历史很多,不可能全部放进上下文。
- 当前问题只和一小部分历史相关。
- 需要跨会话记住用户偏好、项目事实、长期背景。
真实实现通常会用 embedding + 向量数据库。
这部分和 RAG 思路接近,只是检索对象从"知识文档"换成了"历史对话"。
怎么选策略
可以按复杂度逐步升级:
txt
小 demo:消息列表
临时会话:内存历史 + 最近 N 条
本地工具:文件持久化 + 截断
长期助理:总结 + 最近消息
大量历史:总结 + 向量检索一般不要只用一种方式。
更常见的组合是:
- 最近几轮保留原文。
- 更早的对话压缩成摘要。
- 长期事实写入可检索存储。
这样既能控制上下文长度,又不至于丢掉重要信息。
小结
这一篇要记住几个核心点:
- 模型本身无状态,Memory 是 Agent 管理 messages 的结果。
- 最简单的 Memory 是消息列表。
- 需要跨会话时,要把历史消息持久化到文件、Redis 或数据库。
- 上下文有限,所以不能无限追加历史。
- 截断适合控制长度,但会丢旧信息。
- 总结适合压缩旧对话,但可能丢细节。
- 检索式记忆适合大量历史和长期偏好。
- 实际 Agent 往往会组合使用最近消息、摘要和检索。