作者:来自 Elastic Jeffrey Rengifo
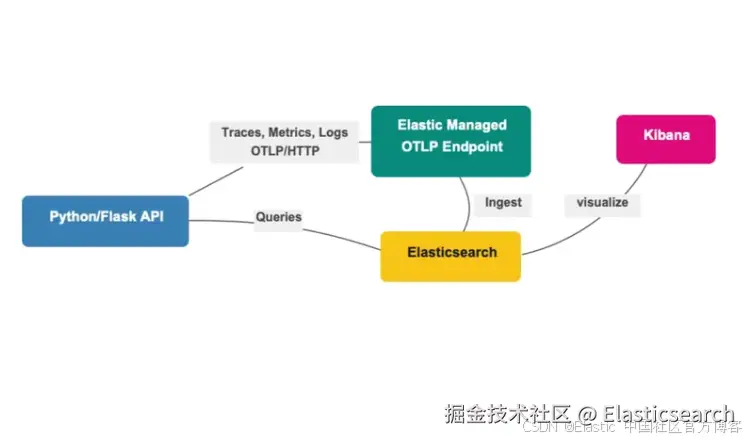
使用 OpenTelemetry 为 Flask API 添加监测,并仅通过 2 个环境变量将追踪、指标和日志发送到 Elastic Cloud,无需采集器。
Elastic 的 托管 OTLP 端点 允许你的 Python 应用仅使用标准的 OpenTelemetry SDK 和 2 个环境变量,直接将追踪、指标和日志发送到 Elastic Cloud。无需部署、配置或维护 Collector。
本文将通过一个完整添加监测的 Flask API 示例,演示从创建第一个 span 到在 Kibana 服务地图中查看服务的全过程,并实现日志与追踪关联。
前提条件
-
一个 Elastic Cloud 账户(Serverless 或 Cloud Hosted v9.0+)
-
Python 3.9+
-
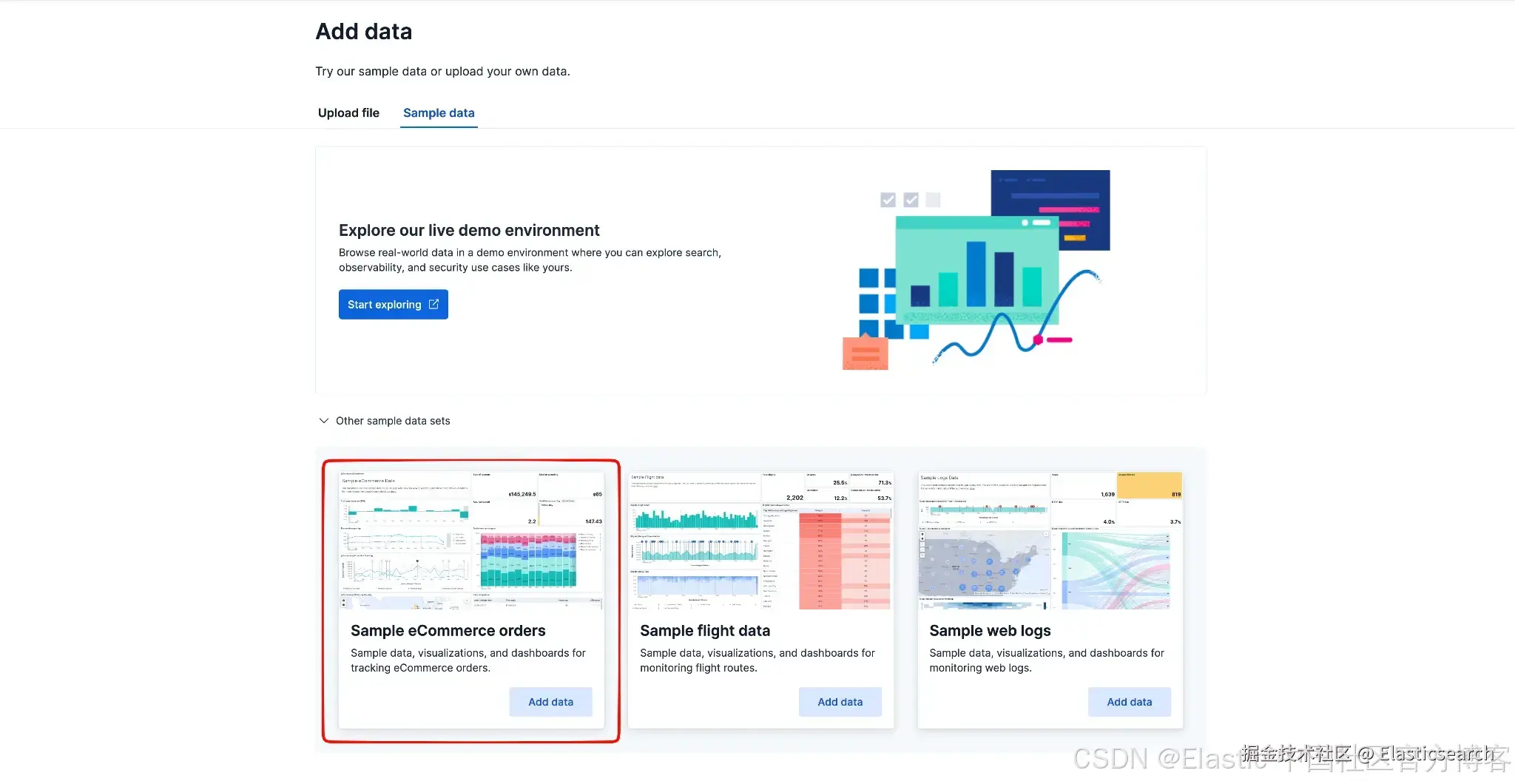
Kibana 内置的示例 eCommerce orders 数据集(Add data > Sample data > Sample eCommerce orders)
安装所需的包:
markdown
`
1. pip install flask elasticsearch python-dotenv \
2. opentelemetry-api opentelemetry-sdk \
3. opentelemetry-exporter-otlp
`AI写代码什么是 Elastic 托管 OTLP 端点?
Elastic 托管 OTLP 端点是一个托管的摄取层,支持应用直接通过 HTTP 或 gRPC 接收标准 OTLP 数据,无需使用采集器。
OpenTelemetry 使用 OTLP(OpenTelemetry 协议) 来传输遥测数据。
在传统架构中,应用会将数据发送到 OpenTelemetry Collector,再由 Collector 转发到 Elasticsearch 等后端系统。
Collector 负责批处理、重试和路由,但也意味着你需要额外部署、配置并维护一个组件。
Elastic 的 托管 OTLP 端点(近期正式发布)移除了这一步骤。
你的应用可以直接将 OTLP 数据发送到 Elastic 托管的端点。
该端点支持标准 OTLP over HTTP 或 gRPC,并由托管摄取层提供支撑,负责扩展、缓冲和可靠性保障。
你使用的仍然是同一套 opentelemetry-exporter-otlp 包,这些包与任何后端兼容。
使用 OpenTelemetry 构建 Python Flask API
我们将用 Python 和 Flask 构建一个小型 REST API,用于列出和查询存储在 Elasticsearch 中的 eCommerce 订单。
作为数据源,我们将使用 Kibana 内置的示例数据集。
你可以在 配套代码仓库 中找到完整的应用代码。
下面的教程会逐步构建代码,但如果你愿意,也可以直接克隆仓库并跟着一起操作。
在添加遥测之前,我们先看基础应用:一个用于查询 Kibana 示例 eCommerce 索引的 Flask API。
它包含两个端点:列出最近订单,以及通过 ID 查询单个订单。
创建一个名为 app.py 的文件:
ini
`
1. import os
3. from dotenv import load_dotenv
4. from elasticsearch import Elasticsearch
5. from flask import Flask, jsonify
7. load_dotenv()
9. # Elasticsearch client
10. es = Elasticsearch(
11. hosts=[os.environ["ES_URL"]],
12. api_key=os.environ["ES_API_KEY"],
13. )
14. INDEX = "kibana_sample_data_ecommerce"
16. app = Flask(__name__)
18. @app.route("/orders")
19. def list_orders():
20. response = es.search(
21. index=INDEX,
22. size=10,
23. sort=[{"order_date": "desc"}],
24. aggs={"total_revenue": {"sum": {"field": "taxful_total_price"}}},
25. )
27. hits = response["hits"]["hits"]
28. total_revenue = response["aggregations"]["total_revenue"]["value"]
29. orders = [
30. {
31. "order_id": h["_source"]["order_id"],
32. "customer": h["_source"]["customer_full_name"],
33. "total": h["_source"]["taxful_total_price"],
34. "date": h["_source"]["order_date"],
35. }
36. for h in hits
37. ]
39. return jsonify({"orders": orders, "total_revenue": total_revenue})
41. @app.route("/orders/<order_id>")
42. def get_order(order_id):
43. response = es.search(
44. index=INDEX,
45. size=1,
46. query={"term": {"order_id": order_id}},
47. )
49. hits = response["hits"]["hits"]
50. if not hits:
51. return jsonify({"error": "Order not found"}), 404
53. return jsonify(hits[0]["_source"])
55. if __name__ == "__main__":
56. app.run(host="0.0.0.0", port=5001)
`AI写代码收起代码块创建一个 .env 文件,填写你的 Elasticsearch 凭证。
要获取 OTLP 端点和 API Key,请参考 快速开始:将 OTLP 数据发送到 Elastic 指南。
ini
`
1. OTEL_EXPORTER_OTLP_ENDPOINT=
2. OTEL_EXPORTER_OTLP_HEADERS=Authorization=ApiKey <api_key>
3. ES_URL=
4. ES_API_KEY=
`AI写代码这是一个未进行任何监测(instrumentation)的可运行 API。接下来的部分将逐步为其添加追踪、指标和日志,每次只引入一种信号。
从 Python 发送 traces
我们先从 traces 开始,使用 Python OpenTelemetry SDK。
我们会用 spans 包裹 Elasticsearch 调用,从而观察每个查询的耗时。
设置 tracer
在 app.py 的顶部添加以下内容:
python
`
1. from opentelemetry import trace
2. from opentelemetry.sdk.trace import TracerProvider
3. from opentelemetry.sdk.trace.export import BatchSpanProcessor
4. from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
5. from opentelemetry.sdk.resources import Resource, SERVICE_NAME
7. # Create a resource identifying your service
8. resource = Resource.create({
9. SERVICE_NAME: "my-python-app"
10. })
12. # Set up the tracer provider with OTLP export
13. tracer_provider = TracerProvider(resource=resource)
14. tracer_provider.add_span_processor(BatchSpanProcessor(OTLPSpanExporter()))
15. trace.set_tracer_provider(tracer_provider)
17. tracer = trace.get_tracer(__name__)
`AI写代码为你的 endpoints 添加 spans
现在将每个 route handler 用一个 parent span 包裹,并在 Elasticsearch 调用外再嵌套一个 child span。这样你就得到一个两层 trace:一个 span 表示 HTTP 请求,另一个 span 表示内部数据库查询。
css
`
1. @app.route("/orders")
2. def list_orders():
3. with tracer.start_as_current_span("list-orders") as span:
5. with tracer.start_as_current_span("es.search") as es_span:
6. es_span.set_attribute("db.system", "elasticsearch")
7. es_span.set_attribute("db.elasticsearch.index", INDEX)
9. response = es.search(
10. index=INDEX,
11. size=10,
12. sort=[{"order_date": "desc"}],
13. aggs={"total_revenue": {"sum": {"field": "taxful_total_price"}}},
14. )
16. hits = response["hits"]["hits"]
17. total_revenue = response["aggregations"]["total_revenue"]["value"]
18. orders = [19. {20. "order_id": h["_source"]["order_id"],
21. "customer": h["_source"]["customer_full_name"],
22. "total": h["_source"]["taxful_total_price"],
23. "date": h["_source"]["order_date"],
24. }
25. for h in hits
26. ]
28. span.set_attribute("orders.returned", len(orders))
29. return jsonify({"orders": orders, "total_revenue": total_revenue})
`AI写代码每个请求都会创建一个 parent span(list-orders),并包含一个 child span(es.search)用于包裹 Elasticsearch 调用。
db.system 和 db.elasticsearch.index 属性是 Kibana 用来在 trace waterfall 中识别该调用为 Elasticsearch 查询的关键字段。
从 Python 发送 metrics
metrics 用于揭示跨所有请求的模式:有多少调用命中了每个 endpoint、响应时间如何随时间变化。我们现在添加一个 counter 和 histogram 来捕获这些信息。
设置 meter
在 app.py 中添加以下内容:
ini
`
1. from opentelemetry import metrics
2. from opentelemetry.sdk.metrics import MeterProvider
3. from opentelemetry.sdk.metrics.export import PeriodicExportingMetricReader
4. from opentelemetry.exporter.otlp.proto.http.metric_exporter import OTLPMetricExporter
6. # 设置 metric reader 和 provider
7. metric_reader = PeriodicExportingMetricReader(
8. OTLPMetricExporter(),
9. export_interval_millis=10000 # 每 10 秒导出一次
10. )
11. meter_provider = MeterProvider(
12. resource=resource,
13. metric_readers=[metric_reader]
14. )
15. metrics.set_meter_provider(meter_provider)
17. meter = metrics.get_meter(__name__)
`AI写代码创建 instruments
ini
`
1. # 请求总数 counter
2. request_counter = meter.create_counter(
3. ,
4. description="Total number of requests",
5. unit="1"
6. )
8. # 请求耗时 histogram
9. request_duration = meter.create_histogram(
10. ,
11. description="Request duration in seconds",
12. unit="s"
13. )
`AI写代码在 endpoints 中记录 metrics
更新 route handler 来记录 metrics:
css
`
1. import time
3. @app.route("/orders")
4. def list_orders():
5. start_time = time.time()
7. with tracer.start_as_current_span("list-orders") as span:
9. with tracer.start_as_current_span("es.search") as es_span:
10. es_span.set_attribute("db.system", "elasticsearch")
11. es_span.set_attribute("db.elasticsearch.index", INDEX)
13. response = es.search(
14. index=INDEX,
15. size=10,
16. sort=[{"order_date": "desc"}],
17. aggs={"total_revenue": {"sum": {"field": "taxful_total_price"}}},
18. )
20. hits = response["hits"]["hits"]
21. total_revenue = response["aggregations"]["total_revenue"]["value"]
22. orders = [23. {24. "order_id": h["_source"]["order_id"],
25. "customer": h["_source"]["customer_full_name"],
26. "total": h["_source"]["taxful_total_price"],
27. "date": h["_source"]["order_date"],
28. }
29. for h in hits
30. ]
32. duration = time.time() - start_time
33. span.set_attribute("orders.returned", len(orders))
34. request_counter.add(1, {"endpoint": "/orders", "status": "200"})
35. request_duration.record(duration, {"endpoint": "/orders"})
37. return jsonify({"orders": orders, "total_revenue": total_revenue})
`AI写代码从 Python 发送 logs
traces 和 metrics 告诉你发生了什么以及发生频率。logs 捕获细节:错误信息、参数值和调试上下文。OpenTelemetry 通过桥接 Python 的标准 `` 模块,让你现有的日志语句与 traces 和 metrics 一起通过 OTLP 导出。
当你在 span 上下文中输出 log 时,SDK 会自动附加 trace ID 和 span ID,因此你可以从一条 log 直接跳转到生成它的 trace。
设置 log provider
scss
`
1. import logging
2. from opentelemetry._logs import set_logger_provider
3. from opentelemetry.sdk._logs import LoggerProvider, LoggingHandler
4. from opentelemetry.sdk._logs.export import BatchLogRecordProcessor
5. from opentelemetry.exporter.otlp.proto.http._log_exporter import OTLPLogExporter
7. # 设置 logger provider
8. logger_provider = LoggerProvider(resource=resource)
9. logger_provider.add_log_record_processor(
10. BatchLogRecordProcessor(OTLPLogExporter())
11. )
12. set_logger_provider(logger_provider)
14. # 将 Python logging 接入 OpenTelemetry
15. handler = LoggingHandler(
16. level=logging.INFO,
17. logger_provider=logger_provider
18. )
19. logging.getLogger().addHandler(handler)
20. logging.getLogger().addHandler(logging.StreamHandler()) # 同时输出到终端
21. logging.getLogger().setLevel(logging.INFO)
23. logger = logging.getLogger(__name__)
`AI写代码LoggingHandler() 确保 logs 在开发时也会显示在你的终端中。
如果没有它,logs 只会发送到 Elastic,而终端不会输出内容,这在测试时可能会让人困惑。
从 endpoints 发送 logs
css
`
1. @app.route("/orders")
2. def list_orders():
3. start_time = time.time()
5. with tracer.start_as_current_span("list-orders") as span:
6. logger.info("列出最近订单")
8. with tracer.start_as_current_span("es.search") as es_span:
9. es_span.set_attribute("db.system", "elasticsearch")
10. es_span.set_attribute("db.elasticsearch.index", INDEX)
12. response = es.search(
13. index=INDEX,
14. size=10,
15. sort=[{"order_date": "desc"}],
16. aggs={"total_revenue": {"sum": {"field": "taxful_total_price"}}},
17. )
19. hits = response["hits"]["hits"]
20. total_revenue = response["aggregations"]["total_revenue"]["value"]
21. orders = [22. {23. "order_id": h["_source"]["order_id"],
24. "customer": h["_source"]["customer_full_name"],
25. "total": h["_source"]["taxful_total_price"],
26. "date": h["_source"]["order_date"],
27. }
28. for h in hits
29. ]
31. duration = time.time() - start_time
32. span.set_attribute("orders.returned", len(orders))
33. logger.info(
34. "订单已列出",
35. extra={"orders.returned": len(orders), "duration_s": round(duration, 4)}
36. )
38. request_counter.add(1, {"endpoint": "/orders", "status": "200"})
39. request_duration.record(duration, {"endpoint": "/orders"})
41. return jsonify({"orders": orders, "total_revenue": total_revenue})
`AI写代码因为这些 logger.info() 调用发生在 span 上下文中,OpenTelemetry 会自动为每条日志记录附加 trace ID 和 span ID。
在 Kibana 中,这意味着你可以从一条 log 直接跳转到对应的 trace。
运行已添加监测的 Flask 应用并生成流量
Traces、metrics 和 logs 已经全部接入后,应用就完成了完整的可观测性配置。现在我们运行它、发送请求,并验证数据是否进入 Kibana。
go
`python app.py` AI写代码注意: Flask 自带的开发服务器适用于本教程。在生产环境中,应使用类似 gunicorn (花生壳) 的 WSGI 服务器。
生成一些流量:
bash
`
1. curl http://localhost:5001/orders
2. curl http://localhost:5001/orders/584677
3. curl http://localhost:5001/orders/does-not-exist
`AI写代码几秒后,打开 Kibana,进入 Observability > APM > Services。
你应该能看到 my-python-app 被列出。
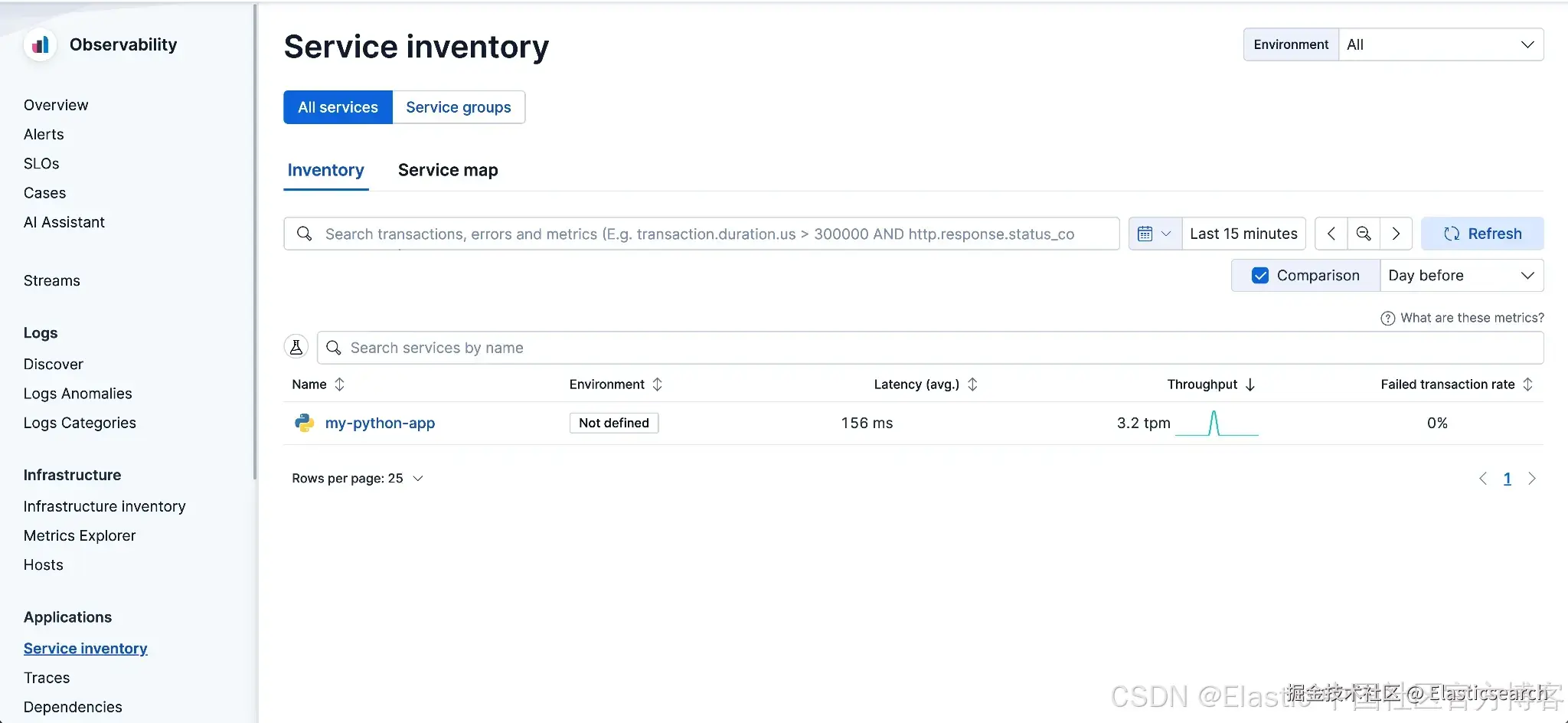
在 Kibana 中查看 traces、metrics 和 logs
现在遥测数据已经开始流动,我们来看看每种信号在 Kibana 中的落点,以及它们是如何相互关联的。
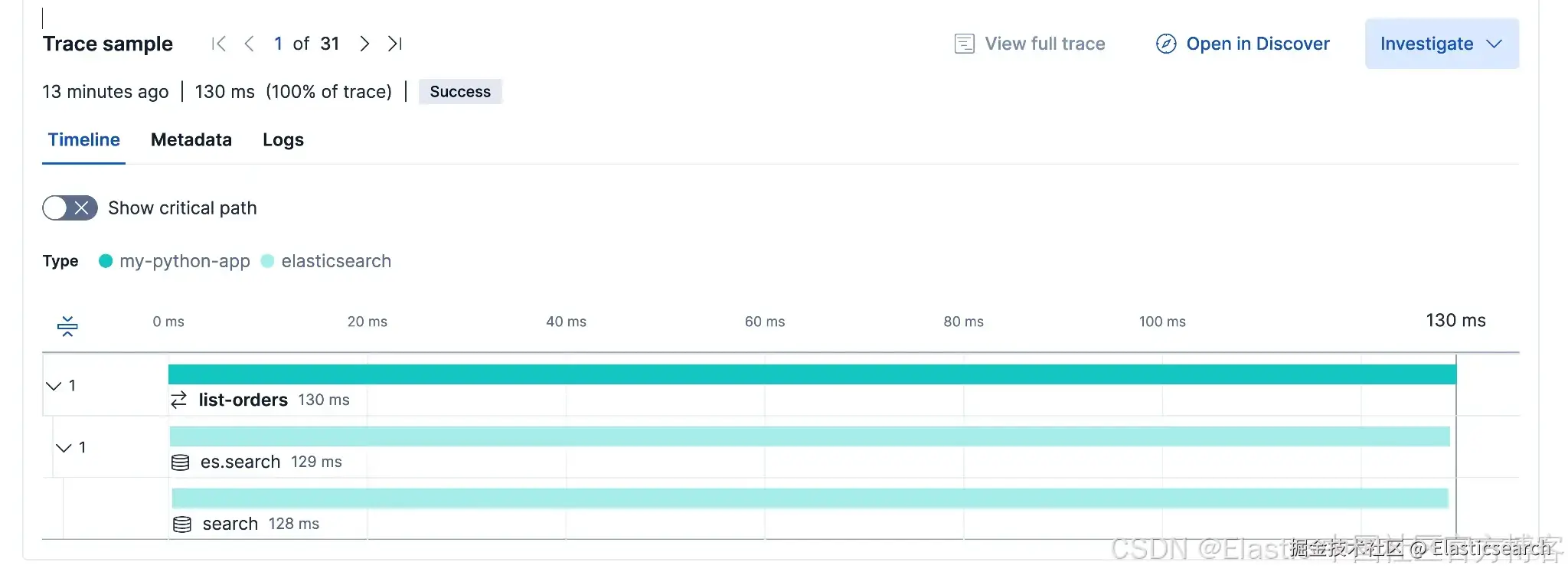
Traces
进入 APM > Services > my-python-app > Transactions。点击一个 list-orders transaction 来打开 trace waterfall。
你应该会看到 parent span list-orders,以及一个 child span es.search。
我们之前设置的 db.system 和 db.elasticsearch.index 属性会显示在 span 详情中,同时 Kibana 会将这个 child 识别为一个 Elasticsearch 查询。
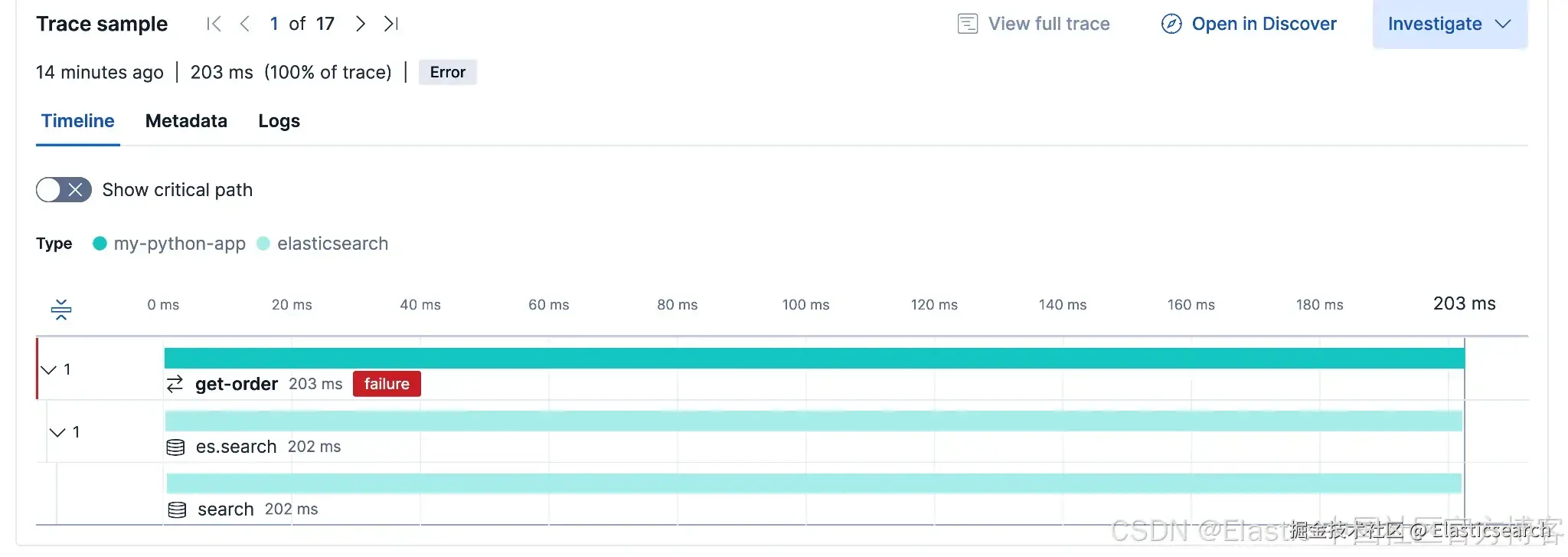
失败的 transactions
为了查看错误可见性,打开一个针对/orders/does-not-exist 请求的 get-order transaction。
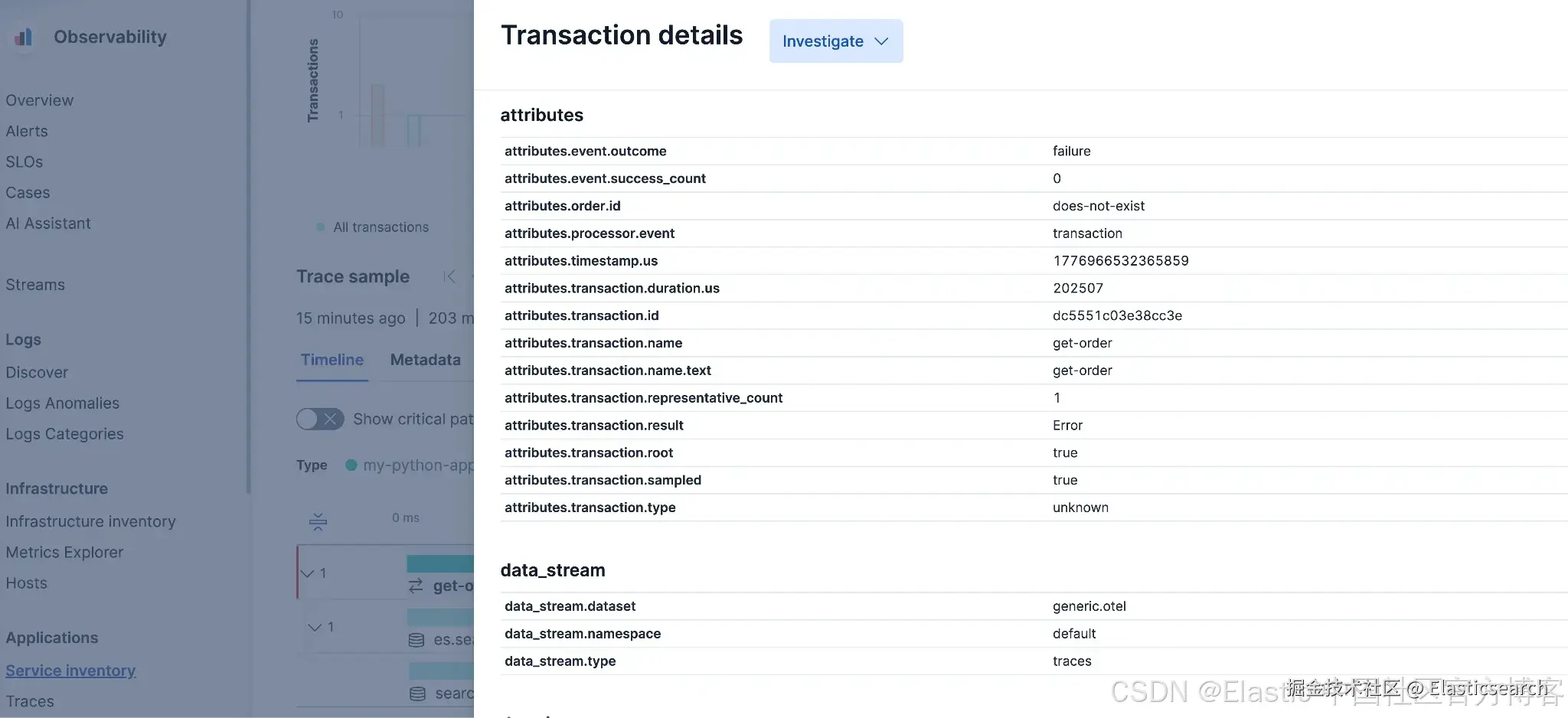
transaction 详情中会显示 event.outcome: failure,以及我们附加的 order.id: does-not-exist 属性。
这表明错误状态和自定义属性可以正确地通过托管端点进行传播。
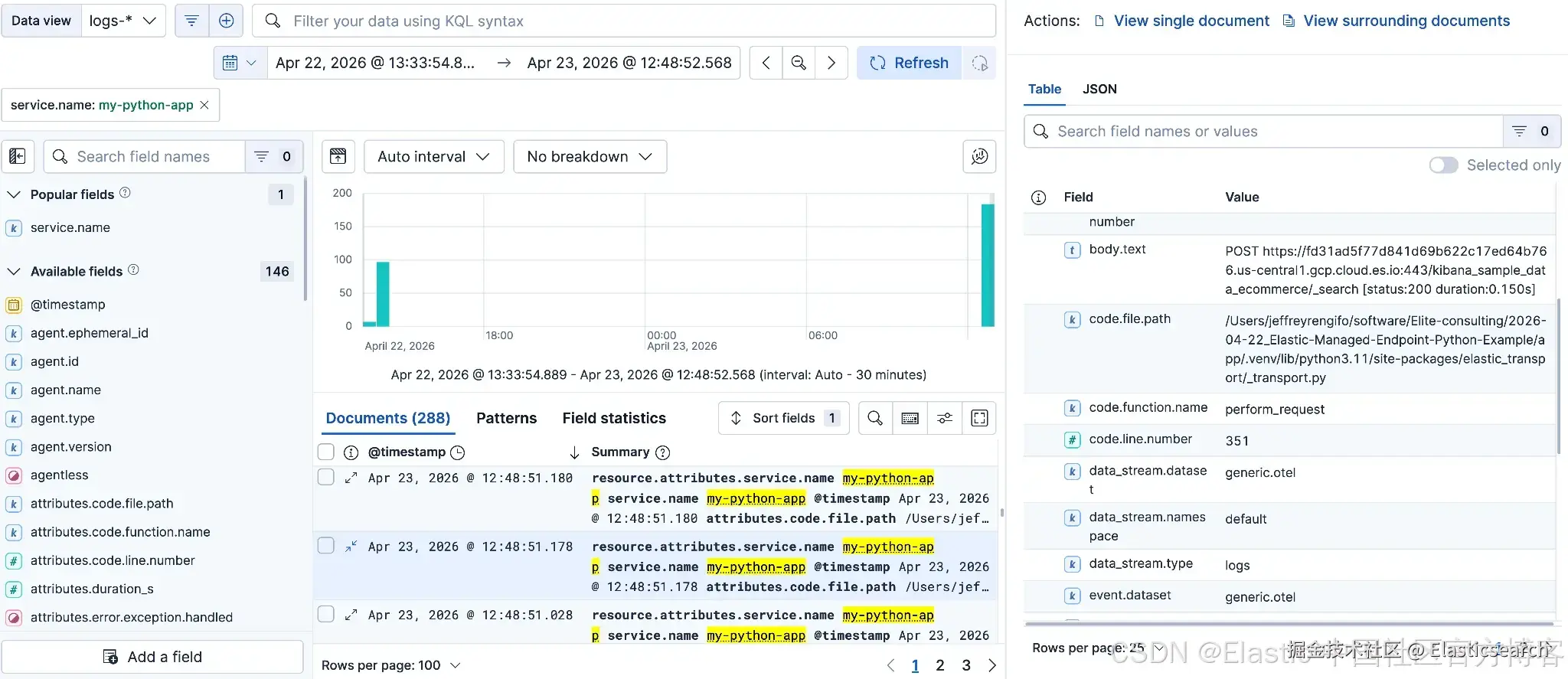
关联日志(Correlated logs)
进入 Discover ,按 service.name: my-python-app. 进行过滤。
展开一条日志文档,可以看到 body.text, trace_id 和 span_id 字段。
由于我们是在 span 上下文中发送 logs,每条日志记录都会携带 trace ID。
你可以复制 trace_id 的值,然后进入 APM,直接跳转到生成该日志的 trace。
Metrics
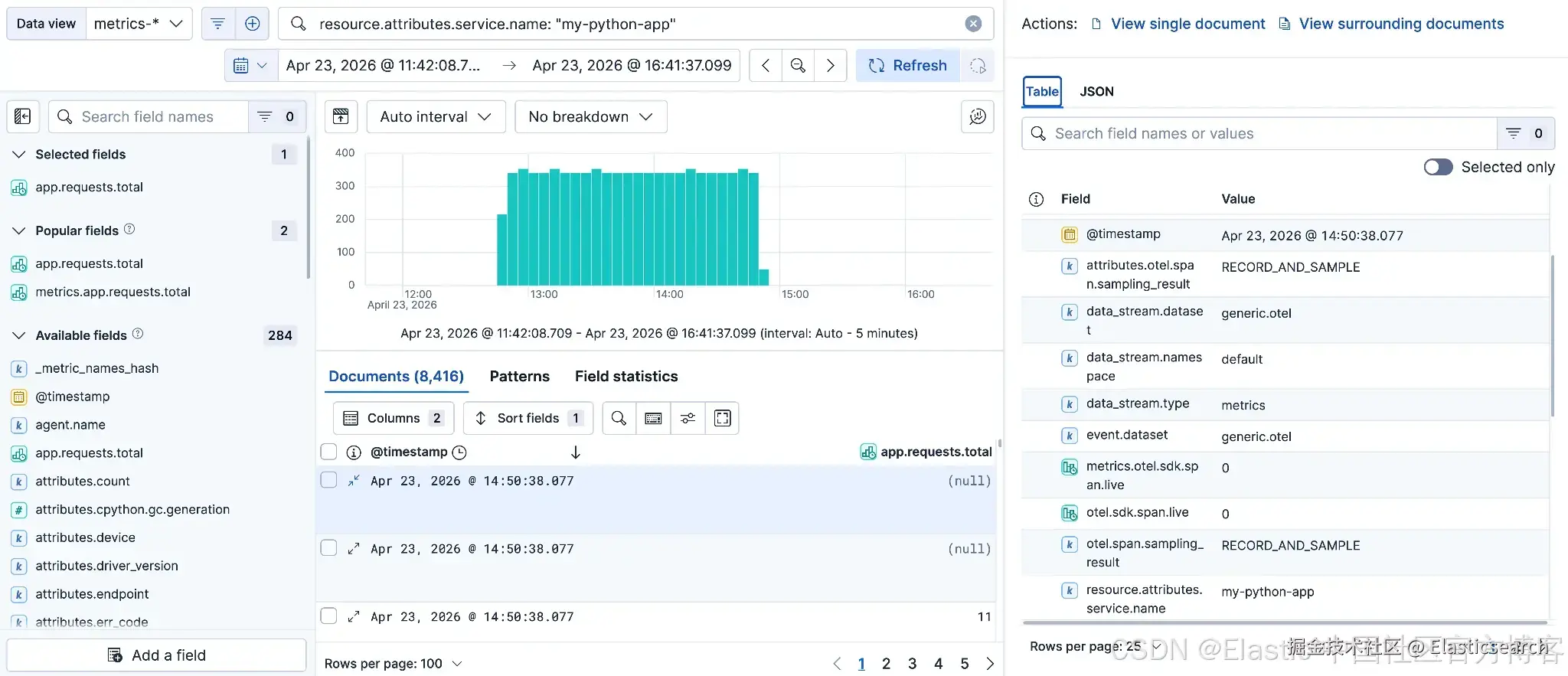
在 Discover 中切换到 metrics-* data view。
你应该会看到 app.requests.total counter 和 app.request.duration histogram 以固定间隔持续到达。
你也可以在 Lens 中创建一个可视化:app.requests.total 在 Y 轴使用 ,@timestamp 在 X 轴使用 ,来观察请求量随时间的变化。
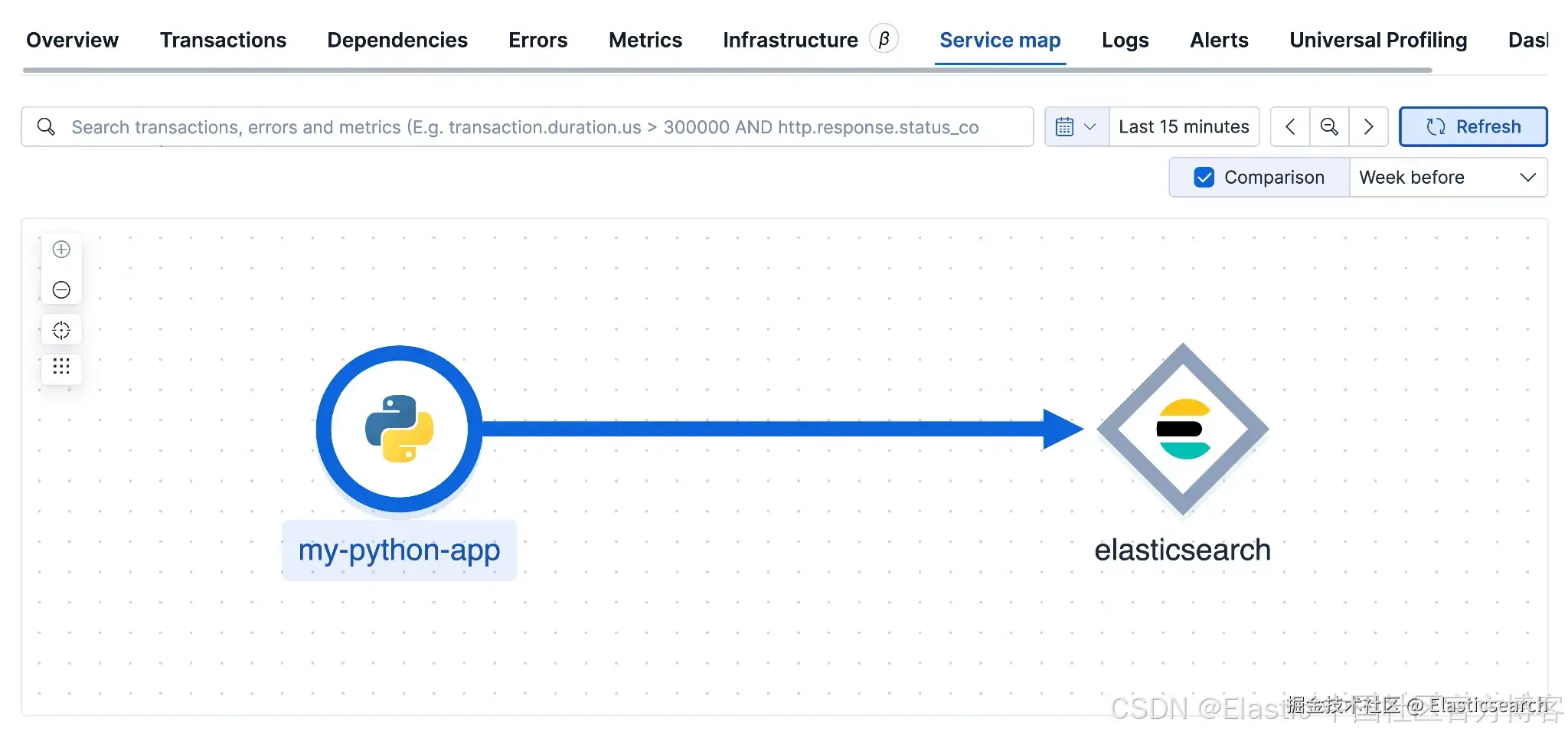
服务地图
Kibana 会基于我们之前设置的 span 属性自动构建 服务地图。
因为我们在 Elasticsearch spans db.system: elasticsear 中标记了 ,Kibana 会绘制 my-python-app 和 elasticsearch 之间的依赖关系,从而为你提供服务及其后端的可视化概览。
总结:在 Python 中无需 Collector 即可实现完整 OpenTelemetry 可观测性
在本教程中,我们使用标准 OpenTelemetry SDK 和两个环境变量为 Flask API 添加了 traces、metrics 和 logs,然后在 Kibana 中验证了所有三种信号,并实现了内置的 log-to-trace 关联。
托管 OTLP 端点负责处理扩展、缓冲和持久化,因此你可以专注于应用本身,而无需运维摄取基础设施。
接下来,你可以考虑使用 EDOT Python 进行自动埋点,以移除手动 spans,或者添加更贴合业务领域的自定义 metrics。
下一步
-
查看 Elastic 托管 OTLP 端点文档 了解高级配置。
-
尝试 `` 或 EDOT Python,在无需手动 spans 的情况下自动为 Flask 和 Elasticsearch 客户端进行埋点。
-
查阅 OpenTelemetry Python SDK 文档 获取更多埋点选项。
-
如需对 histogram 的时序特性进行细粒度控制,请参考 托管 OTLP 端点文档。
原文:OpenTelemetry Python to Elastic in 2 environment variables --- Elastic Observability Labs