前段时间,我写过一篇关于 ProgramBench 的文章《Meta 做了个实验:让 AI 从零重建软件,结果全军覆没》。它讨论的是:只给一个程序和文档,AI 能不能从零重建一个真实软件?
最近,RepoZero 又从另一个角度切进了同一个问题:如果给 Agent API 规格、隐藏测试和可验证的 oracle,它能不能从零复刻一个仓库的行为?
这两篇论文看起来像是在给出不同答案,但我更愿意把它们放在一起看:它们不是简单的互相反驳,而是在共同说明一件事------AI Coding 的瓶颈,正在从"会不会写代码",转向"任务能不能被表示,行为能不能被验证,系统能不能在反馈中收敛"。
RepoZero 这篇论文,是一位参与相关工作的同学推荐给我的。他提到,这个工作和 ProgramBench 有明显的对照关系。这个提醒很有价值,因为它让"AI 能不能从零写软件"这个问题,变得更值得拆开看。
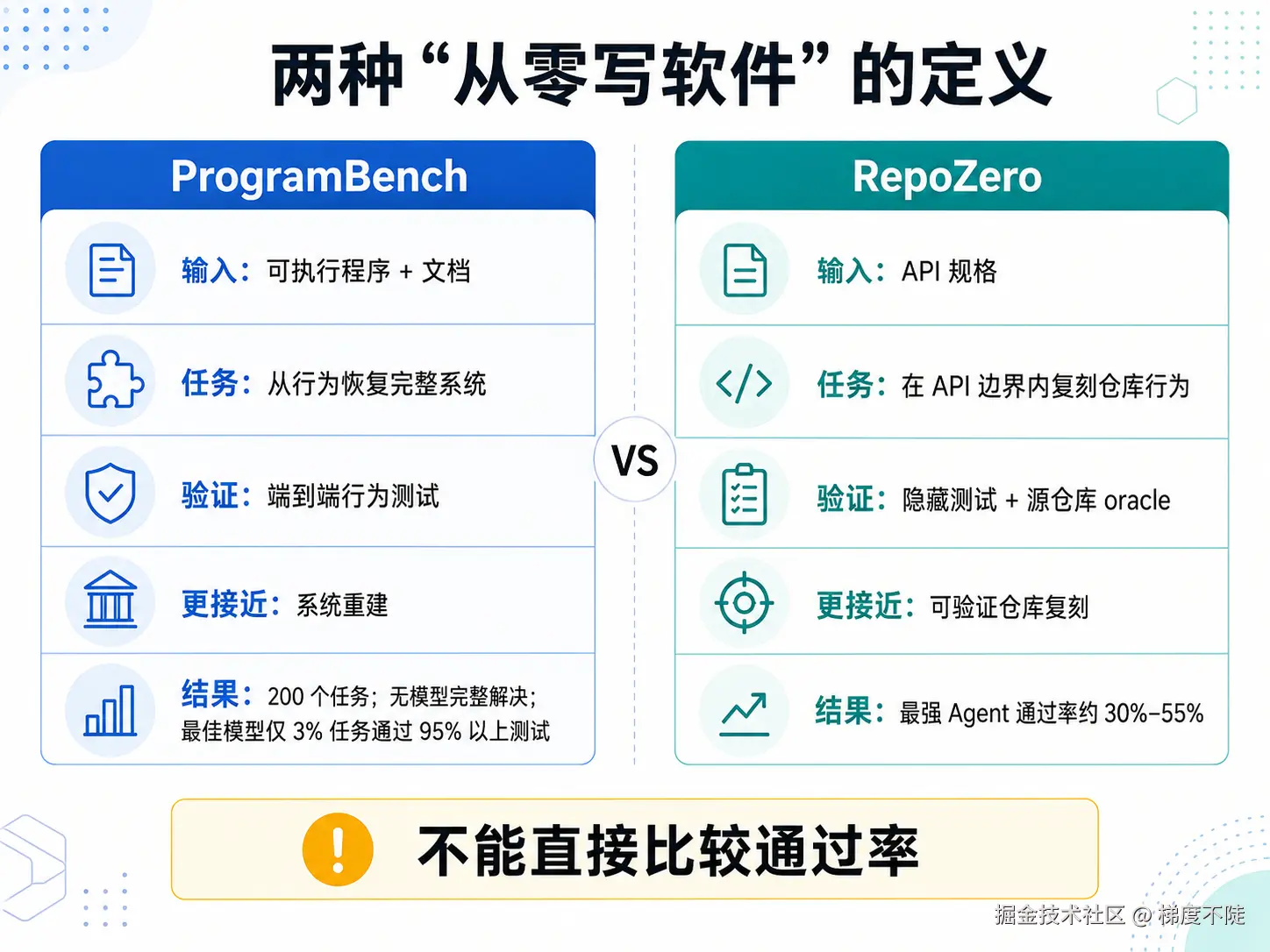
表面上看,这两篇论文都在问一件事:AI 能不能从零生成一个软件项目?
ProgramBench 的答案很悲观。论文给 Agent 一个程序和对应文档,要求它从零实现一个行为一致的程序。结果是,在 200 个任务上,没有任何模型完整解决任务,最好的模型也只在 3% 的任务上通过了 95% 以上测试。任务范围从小型 CLI 工具,到 FFmpeg、SQLite、PHP interpreter 这类真实软件。论文还观察到,模型往往倾向于生成单文件、长函数、结构上明显偏离人类代码的实现。
RepoZero 的答案看起来更积极一些。它把问题重新定义为 repository reproduction:给 Agent API specifications,让它重新实现一个仓库,使其行为与原始实现一致。它还通过 cross-language constraints、sandboxed evaluation、black-box validation,以及源仓库作为 oracle 的方式,让评测可以自动化、可复现、可扩展。论文报告显示,即使当前较强的 Agent,也只能达到约 30% 到 55% 的有限通过率,但这已经比 ProgramBench 那种"完整重建真实软件"的设定看起来更可推进。
所以问题来了:这两篇论文到底谁更能代表 AI Coding 的真实能力?
我的判断是:它们不是谁推翻谁,而是在测两个不同层次的问题。

一、ProgramBench 测的是"从行为恢复系统"
ProgramBench 的任务设定非常硬。
Agent 拿到的不是源码,不是架构图,不是需求文档,也不是清晰的 API specification,而是一个可执行程序和它的文档。它必须自己决定使用什么语言、如何组织代码、如何拆模块、如何实现构建脚本,并最终让新程序表现得像原程序一样。
这件事比"写代码"难得多。
因为它要求 Agent 不只是写出一些函数,而是从有限观察中恢复一个软件系统的行为边界。换句话说,它要回答:这个程序到底接受什么输入?有哪些边界情况?错误分支应该怎么处理?文档没写清楚的行为是什么?不同参数组合之间有什么隐含约束?哪些行为是核心逻辑,哪些只是实现细节?
这已经不是单纯的 code generation,而更接近一种黑盒行为复原。
ProgramBench 论文也明确指出,现有很多 benchmark 主要测的是 bug fix、局部 feature 或已有代码库内的增量修改,而 ProgramBench 想测的是更整体的软件开发能力:给定一个程序和文档,Agent 要从头 architect and implement 一个行为一致的 codebase。
所以,ProgramBench 的失败并不只是说明"模型不会写代码"。
它更像是在说明:当软件行为是隐式的、系统边界是开放的、规格需要从行为中恢复时,当前 Agent 很难稳定完成系统级重建。
这和我们在真实研发中遇到的问题很像。很多时候,需求文档本身并不能完整表达系统行为,代码仓库里也有大量隐含约束。人类工程师能做这件事,是因为他会结合历史代码、业务规则、测试反馈、团队规范、线上问题和上下文经验,逐步形成对系统的理解。
而 Agent 一旦缺少这些结构化支撑,就很容易进入一种状态:看起来写了很多代码,但并没有真正恢复系统行为。
二、RepoZero 测的是"在 API 边界内复刻仓库行为"
RepoZero 的设定则不同。
它不是让 Agent 从一个完整程序的外部行为中恢复整个软件系统,而是把问题收敛到 API 层:给定 API specifications,Agent 需要重新实现一个仓库,使其 API 行为与源仓库一致。评测时,生成的目标仓库会在隐藏测试上执行,并与源仓库输出进行对比。
这一步非常关键。
因为一旦问题被压缩到 API 层,Agent 面对的任务就更"可表示"了。它知道要实现哪些接口,知道输入输出大致是什么,知道行为要和源仓库保持一致。源仓库本身还可以作为 oracle,用来生成和验证测试结果。
这和 ProgramBench 的任务不是同一个难度层级。
ProgramBench 更像是:这里有一个黑盒程序,你自己观察、理解、设计、重建。
RepoZero 更像是:这里有一组 API 边界,你在这个边界内复刻行为,并接受隐藏测试验证。
这并不意味着 RepoZero 简单到没有价值。恰恰相反,它的价值在于把一个原本很难评测的问题,改写成了一个可自动验证的问题。
论文自己也指出,现有 from-scratch repository generation benchmark 的一个根本瓶颈,是缺少可验证、可扩展的评测方式。很多工作依赖 human evaluation 或 LLM-as-a-judge,这会引入主观偏差,也限制可复现性。RepoZero 的做法,是把 repository generation 改写为 repository reproduction,并利用源仓库作为 oracle,从而得到确定性的自动化验证标准。
这件事对 AI Coding 很重要。
因为一旦任务可以被自动验证,Agent 就不再只是"一次性生成代码",而可以进入 code-test-refine 的闭环。
三、RepoZero 真正重要的不是通过率,而是验证闭环
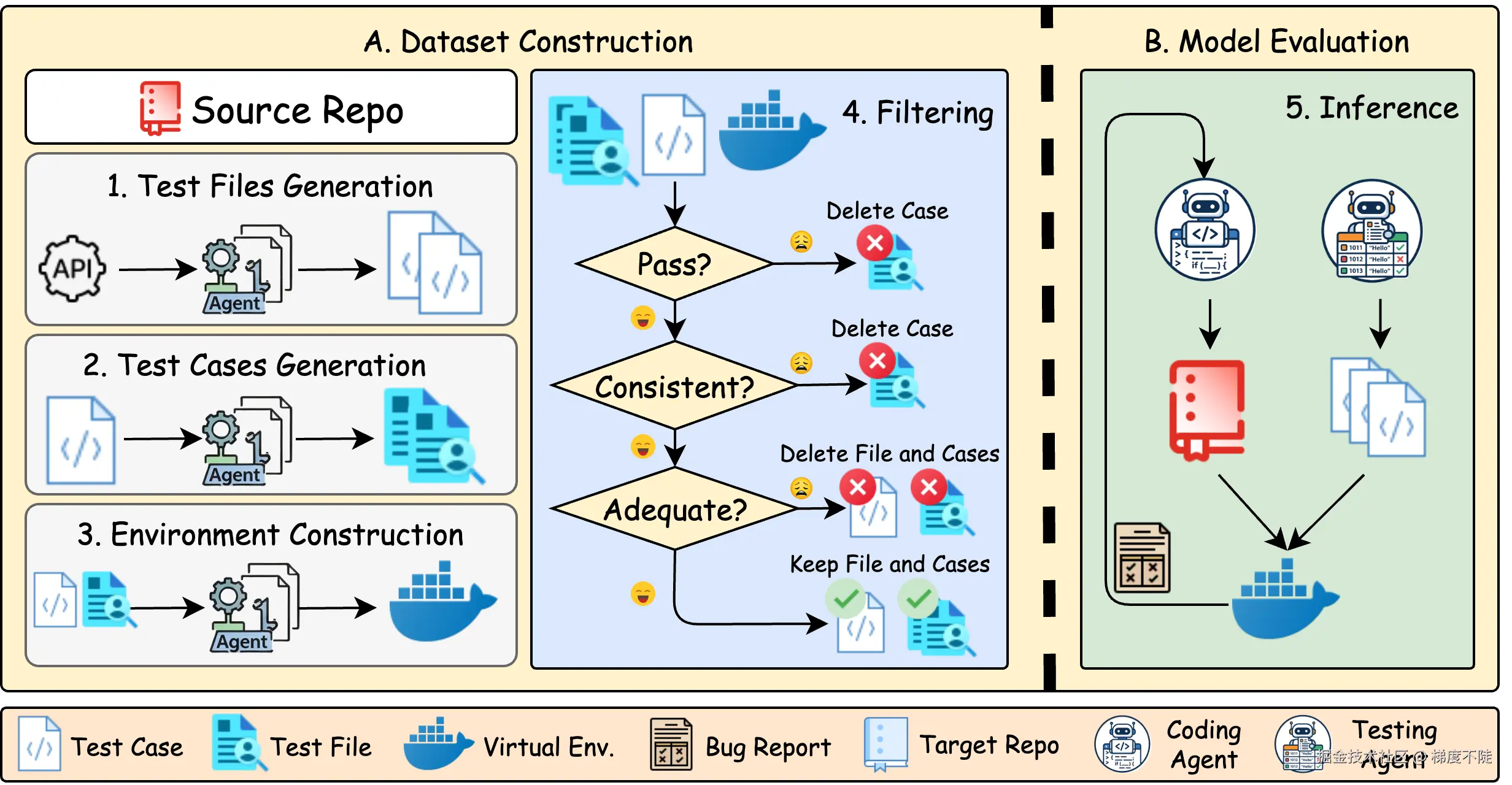
RepoZero 最值得注意的地方,不只是它测了 repository reproduction,而是它把整个任务组织成了一个可验证、可反馈、可收敛的运行闭环。论文中的 Figure 2 很直观地展示了这一点。
 RepoZero 论文里还有一个值得注意的设计:ACE,Agentic Code-Test Evolution。
RepoZero 论文里还有一个值得注意的设计:ACE,Agentic Code-Test Evolution。
它不是只让模型生成一次代码,然后结束。ACE 会让测试 Agent 生成测试,执行源仓库得到 ground truth 输出,再把失败信息反馈给 coding Agent,让它继续修正。这本质上是一种 test-time scaling:不是只在模型参数里寻找能力,而是在运行时通过测试和反馈来释放能力。
这和我们在工程实践中观察到的方向非常一致。
AI Coding 的能力提升,并不只来自模型变强,还来自执行环境变强、验证链路变强、反馈机制变强。当 Agent 可以运行代码、生成测试、观察错误、比较输出、重新修正,它才从"代码生成器"逐渐变成一个能在环境中收敛的执行系统。
RepoZero 的实验也说明了这一点。论文强调,高表现 Agent 往往会主动在环境中设计并执行自动化单元测试。这种利用可执行环境进行自我修正的能力,是复杂软件工程任务中的重要成功因素。
这也是我觉得 RepoZero 值得单独讨论的原因。
它不是简单地说"AI 已经能从零生成仓库了"。相反,它的结论仍然谨慎:即便是当前较强的模型和 Agent 框架,通过率也只是有限水平,和真实软件开发要求之间仍有明显差距。
但它给出了一个更积极的方向:
当任务边界被明确表达,验证 oracle 被构造出来,执行环境能够稳定运行,Agent 能够在测试反馈中迭代,代码生成能力就会被释放出来一部分。
这不是"模型突然会了",而是"系统开始能让模型工作了"。
四、为什么不能简单比较两篇论文的通过率
把 ProgramBench 和 RepoZero 放在一起看,最容易犯的错误,就是直接比较通过率。
ProgramBench 是 0% 完整解决。
RepoZero 是 30% 到 55% 的有限通过率。
于是有人可能会说:RepoZero 证明 ProgramBench 太悲观了,AI 其实能从零写仓库。
这个判断不准确。
因为两者的任务输入、目标边界和验证方式都不同。
ProgramBench 给的是可执行程序和文档,Agent 要自己恢复规格,自己决定实现结构。它评估的是从黑盒行为中恢复完整程序的能力。ProgramBench 论文也明确提到,它和一些假设已知规格的优化类 benchmark 不同,ProgramBench 要求模型从 observed behavior 中恢复 specification,而且是在完整软件项目尺度上,而不是单个函数。
RepoZero 给的是 API specifications,目标是复刻源仓库的 API 行为。它更强调 repository-level generation 的自动化验证、跨语言约束和数据泄漏防御。RepoZero 中,源仓库可以作为 oracle,隐藏测试可以用于严格的 output equivalence 验证。
所以,这两篇论文不是在同一条跑道上比谁分数高。
更准确的说法是:
ProgramBench 测的是"规格不明确时,Agent 能不能从行为中恢复系统"。
RepoZero 测的是"规格相对明确时,Agent 能不能在 API 边界内复刻仓库行为"。
前者更接近系统重建。
后者更接近可验证仓库生成。
这两件事都重要,但不能混在一起。
五、它们共同说明了一个更大的变化
过去讨论 AI Coding,大家很容易把问题压缩成一句话:模型会不会写代码?
但 ProgramBench 和 RepoZero 放在一起,恰好说明这个问题已经不够用了。
因为"写代码"只是最后一个动作。真正决定 Agent 能不能完成任务的,往往是写代码之前和写代码之后的东西。
写代码之前,任务有没有被清楚表达?系统边界有没有被明确收敛?API、数据结构、交互行为、错误分支有没有形成可执行表示?Agent 知不知道自己到底要实现什么?
写代码之后,行为能不能被验证?隐藏 case 能不能覆盖?源系统有没有 oracle?测试失败后能不能自动反馈?Agent 能不能在环境中迭代收敛?
从这个角度看,ProgramBench 和 RepoZero 其实指向同一个变化:
AI Coding 的瓶颈,正在从代码生成本身,迁移到任务表示、验证 oracle、执行环境和反馈闭环。
 ProgramBench 告诉我们:缺少足够清晰的表示和验证时,Agent 很难重建真实软件系统。
ProgramBench 告诉我们:缺少足够清晰的表示和验证时,Agent 很难重建真实软件系统。
RepoZero 告诉我们:一旦问题被压缩成 API 边界,验证 oracle 被构造出来,Agent 的能力就能被更稳定地测量、迭代和放大。
这正是我一直在思考的方向:AI 研发自动化不是把一个大模型接进 IDE 就结束了。它需要一套新的系统能力。换句话说,Representation 定义任务,Harness 承载执行,Verification 形成判断,System 组织闭环。
- Representation:把需求、API、设计、仓库上下文和验收标准表达成 Agent 能消费的结构,让任务从"自然语言描述"变成"可执行表示"。
- Harness:提供 Agent 执行任务所需的运行环境、工具接口、状态保持、错误恢复和上下文承载能力,让任务不只是被生成,而是能被持续执行。
- Verification:把测试、oracle、覆盖率、行为比对、视觉检查、回归验证等能力组织起来,让系统知道代码是否真的满足预期,而不是只判断代码是否生成完成。
- System:把输入理解、任务建模、代码执行、自动验证和结果反馈组织成一条可运行、可观测、可迭代的研发链路。
这里需要区分一点:Harness 更像执行与反馈的承载层,Verification 更像基于证据形成判断的验证层。前者让系统能跑起来、拿到反馈;后者决定这些反馈意味着什么,以及当前产物是否真的满足预期。
也正因为如此,AI Coding 的能力边界不能只看模型本身。更关键的是,系统能否把一个开放的软件开发问题,转化成可表达、可执行、可验证、可迭代的问题。
六、这对真实研发有什么启发
这两篇论文对真实研发的启发,不是"AI 现在到底能不能替代工程师"。
这个问题太粗了。
更值得问的是:我们能不能把真实研发任务拆成更适合 Agent 工作的形态?
例如,一个需求是否能被拆成清晰的任务边界?前端、后端、测试、设计稿、接口、历史代码之间的关系,是否能被组织成 Agent 可读的上下文?验收标准是否能前置,而不是等代码写完后再人工判断?自动化测试、浏览器验证、覆盖率采集、视觉比对、接口 mock、异常分支验证,是否能形成一套持续反馈机制?当 Agent 写错时,我们能不能知道它错在输入理解、任务表示、实现选择,还是验证不足?
这些问题,比"模型能不能写代码"更接近真实的工程瓶颈。
ProgramBench 让我们看到,没有这些结构时,AI 很难从黑盒行为中恢复完整系统。
RepoZero 让我们看到,当 API 边界、oracle 和测试反馈被组织起来时,Agent 可以在更明确的空间里前进。
这也解释了为什么很多团队在 AI Coding 落地时,早期会有一种错觉:单个 demo 很惊艳,但一进入真实需求,就开始不稳定。
原因不一定是模型突然变差了,而是任务从"局部生成"变成了"系统交付"。
系统交付需要的不只是代码能力,还需要需求理解、上下文组织、任务建模、执行编排和验证闭环。
这里也需要保留一个边界意识:Benchmark 不是现实研发本身,而是为了让问题可比较、可复现、可讨论,对真实软件开发做过压缩后的观测窗口。它们无法覆盖需求澄清、架构演进、团队规范、非功能质量和长期维护等复杂因素。因此,这两篇论文的价值不在于给出最终裁判,而在于帮助我们看到:任务表示、验证条件和执行环境的变化,会显著改变 Agent 的能力边界。
七、RepoZero 更像一个信号
所以,RepoZero 对我来说最重要的地方,不是它和 ProgramBench 谁更强,也不是它证明 AI 已经能从零写仓库。
它更像是一个信号:
AI Coding 评测正在从"给定代码修 bug",走向"从零生成仓库";从"主观评判",走向"执行验证";从"单次生成",走向"测试反馈驱动的迭代收敛";从"比模型会不会写",走向"比系统能不能让 Agent 稳定工作"。
ProgramBench 是一个上限压力测试。它把问题推到非常开放、非常困难的位置,告诉我们当前 Agent 离真正的软件系统重建还很远。
RepoZero 是一个更工程化的切面。它把问题收敛到 API reproduction 和 output equivalence,让 from-scratch repository generation 变得更可验证、更可扩展,也更适合持续比较。
这两篇论文放在一起,最有价值的结论不是"AI 行"或"AI 不行"。
而是:AI Coding 正在进入一个新的阶段。
在这个阶段,真正重要的不只是模型本身,而是我们如何定义任务,如何表达边界,如何构造验证,如何让 Agent 在反馈中持续收敛。
换句话说,AI 能不能从零写软件,不能只问模型。
还要问:我们给它的"零",到底是什么?是一个模糊想法?是一段文档?是一个可执行程序?是一组 API specification?是一套隐藏测试?还是一个完整的、可运行的研发环境?
不同的"零",会得到完全不同的答案。
结语
ProgramBench 和 RepoZero 给出的不是两个互相冲突的答案,而是同一个问题的两个层次。
这两种答案之所以不同,不是因为一篇论文更乐观、一篇论文更悲观,而是因为它们定义的"从零"并不一样。
如果"从零"意味着只给一个程序和文档,让 Agent 自己恢复完整系统行为,那当前能力还远远不够。
如果"从零"意味着在清晰 API 边界、可执行测试、确定性 oracle 和反馈闭环中重新实现仓库行为,那 Agent 已经可以做出一部分事情,但距离真实软件开发的稳定交付仍有明显差距。
这也是为什么,AI Coding 的主战场不会停留在"模型生成代码"这一层。
它会继续向上移动到 Representation ,向下扎进 Harness ,在中间形成稳定的 Verification ,最后汇入新的研发 System。模型仍然重要,但真正决定 Agent 能否完成复杂软件任务的,正在变成一整套围绕任务表示、执行环境、行为验证和反馈闭环展开的系统能力。
感谢 RepoZero 作者之一对本文涉及论文设定和实验细节的技术事实进行校对。文中的趋势判断与延伸分析由我本人负责。