一条推文引来700万人围观,Claude Code作者直言"我也不写prompt,我写Loop"。
今天,我们就来拆解这个让AI自己"卷"自己的编程范式------AI Loop。
什么是AI Loop?循环才是AI的底层基因
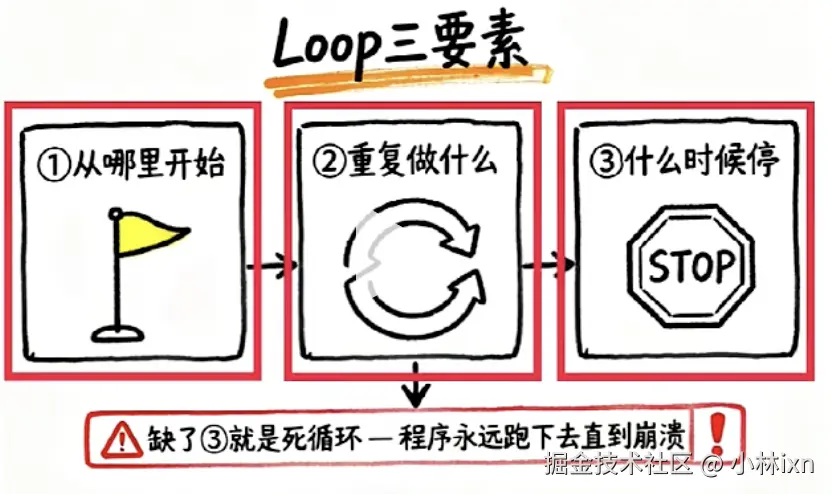
如果你写过代码,一定对 for、while 不陌生。循环(Loop) 是计算机最基础的控制结构,它只做三件事:
- 从哪开始
- 重复做什么
- 什么时候停
比如,你有一万行Excel数据要逐行检查格式,人工可能要搞一整天,但写个循环程序,几秒钟跑完。循环的价值,就是把重复劳动交给机器。
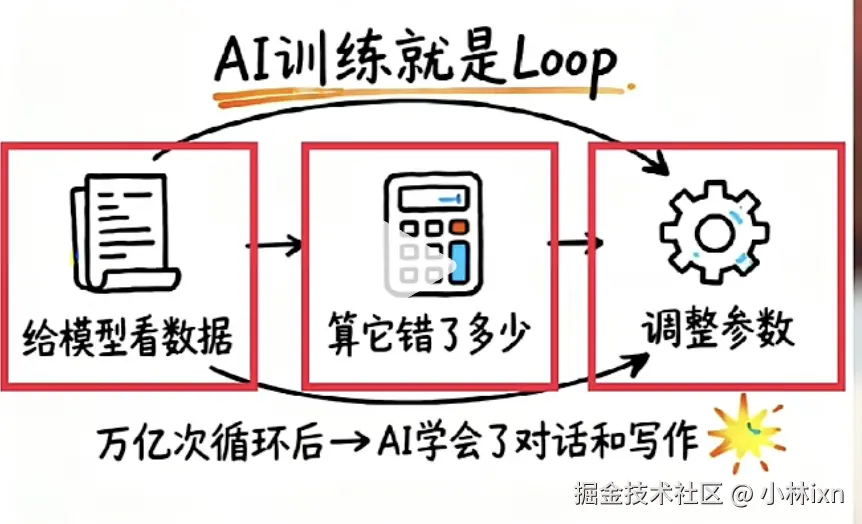
而我们现在使用的所有大语言模型(LLM)------DeepSeek、Claude、Qwen......它们的训练过程本质上也是一个巨大的循环:
拿一批数据给模型看 → 计算它错了多少 → 调整参数 → 再来一轮。
万亿次循环后,AI 学会了对话、写作、推理。
 然而,在日常使用中,我们却常常陷入手动循环:
然而,在日常使用中,我们却常常陷入手动循环:
- 写Prompt → 看结果 → 不满意 → 改Prompt → 再看结果......
- 你把工作交给了AI,但自己还得像监工一样盯着,手动迭代。
这就是手动Loop------低效、费时、容易遗漏。
而我们要讲的AI Loop ,就是把这些手动过程自动化,让AI自己生成、自己检查、自己修正,直到满足你的要求为止。
一个真实的AI Loop代码实战
下面这段代码(main.mjs)是我用DeepSeek API实现的一个完整AI Loop。它让AI自主完成"小红书美妆文案"的生成,并自动校验规则,不达标就重来,直到通过或触发刹车条件。
我们先贴出完整代码,再逐行拆解。
javascript
import { OpenAI } from 'openai';
import dotenv from 'dotenv';
dotenv.config();
const client = new OpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
baseURL: process.env.DEEPSEEK_BASE_URL
});
// -------------------- Loop 可控边界 --------------------
const limit = {
maxRound: 5, // 最大尝试轮数(防死循环)
maxToken: 2000, // 总token消耗上限(防超预算)
sameStop: 2 // 连续相同结果几次就停(防原地踏步)
};
const task = {
desc: "小红书美妆文案", // 目标
rules: ["标题带数字", "正文<300字", "大爆款", "结尾有行动号召"] // 校验规则
};
let round = 0, totalToken = 0, lastText = "", sameCount = 0;
// -------------------- 刹车判断 --------------------
function needStop() {
return round >= limit.maxRound ||
totalToken >= limit.maxToken ||
sameCount >= limit.sameStop;
}
// -------------------- 生成文案(生产者) --------------------
async function gen() {
const res = await client.chat.completions.create({
model: 'deepseek-v4-flash',
messages: [{
role: 'user',
content: `假如你是一位资深小红书美妆博主,
写一篇${task.desc}, 严格遵守:
${task.rules.join("、")}, 只输出文案`
}]
});
console.log(res.usage.total_tokens, res.choices[0].message.content);
return {
text: res.choices[0].message.content.trim(),
token: res.usage.total_tokens
};
}
// -------------------- 校验文案(检查者) --------------------
async function check(text) {
const res = await client.chat.completions.create({
model: "deepseek-v4-flash",
messages: [{
role: "user",
content: `校验文案: ${text}
规则: ${task.rules.join("、")},
仅输出JSON {pass: 布尔, fail: 数组}`
}]
});
return JSON.parse(res.choices[0].message.content.trim());
}
// -------------------- 主循环 --------------------
async function runLoop() {
console.log('AI Loop 开始');
while (!needStop()) {
round++;
console.log(`\n 第${round}轮`);
// 1. 生成
const { text, token } = await gen();
totalToken += token;
// 2. 记录重复情况(用于 sameStop)
sameCount = (text === lastText) ? sameCount + 1 : 0;
lastText = text;
// 3. 校验
const { pass, fail } = await check(text);
if (pass) {
console.log(`✅ 全部规则通过,循环结束`);
console.log(`最终文案:\n${text}`);
return;
}
console.log(`❌ 不满足规则: ${fail.join(', ')},继续下一轮...`);
}
console.log(`\n⛔ 触发刹车强制停止,最后一次内容:\n${lastText}`);
}
runLoop();逐行拆解:每个变量、每个函数都在做什么
1. 客户端初始化(OpenAI兼容接口)
arduino
const client = new OpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
baseURL: process.env.DEEPSEEK_BASE_URL
});这里使用了 openai 库,但 baseURL 指向了 DeepSeek 的接口。因为 DeepSeek 兼容 OpenAI 的 API 格式,所以我们能用同一套代码调用 DeepSeek 模型。环境变量中存储了密钥和地址。
2. 控制边界 ------ limit 对象
yaml
const limit = {
maxRound: 5,
maxToken: 2000,
sameStop: 2
};这三个字段是循环的"刹车系统" ,防止程序失控:
maxRound:最大尝试轮数。避免因为规则永远无法满足而陷入死循环。maxToken:总 token 消耗上限。调用 API 是按 token 计费的,设定预算可以控制成本。sameStop:连续多少次生成结果完全相同时强制停止。有时候AI会卡在同一个错误输出上,这个条件能及时止损。
3. 任务定义 ------ task
arduino
const task = {
desc: "小红书美妆文案",
rules: ["标题带数字", "正文<300字", "大爆款", "结尾有行动号召"]
};desc是目标描述,会注入到生成 prompt 中。rules是校验规则列表,既会注入生成 prompt(让AI按规则写),也会单独用于检查。
4. 全局状态变量
ini
let round = 0, totalToken = 0, lastText = "", sameCount = 0;round:当前轮次。totalToken:累计消耗的 token 数。lastText:上一轮生成的文案文本,用于比较是否重复。sameCount:连续重复的次数。
5. 刹车函数 needStop()
matlab
function needStop() {
return round >= limit.maxRound ||
totalToken >= limit.maxToken ||
sameCount >= limit.sameStop;
}它返回一个布尔值,只要满足任意一个刹车条件,循环就终止。这是 Loop 的"退出检查点"。
注意:原代码中
totalToken >= limit.matToken应为maxToken,是个小笔误,大家写代码时要留意。
6. 生成函数 gen() ------ 生产者
javascript
async function gen() {
const res = await client.chat.completions.create({
model: 'deepseek-v4-flash',
messages: [{
role: 'user',
content: `假如你是一位资深小红书美妆博主,
写一篇${task.desc}, 严格遵守:
${task.rules.join("、")}, 只输出文案`
}]
});
console.log(res.usage.total_tokens, res.choices[0].message.content);
return {
text: res.choices[0].message.content.trim(),
token: res.usage.total_tokens
};
}- 它向 DeepSeek 发送一个 生成 prompt ,要求 AI 按照
task.rules写文案。 - 返回一个对象,包含
text(文案内容)和token(本次消耗的 token 数)。 console.log会打印出每次的 token 数和原始输出,方便调试。
7. 校验函数 check(text) ------ 检查者
javascript
async function check(text) {
const res = await client.chat.completions.create({
model: "deepseek-v4-flash",
messages: [{
role: "user",
content: `校验文案: ${text}
规则: ${task.rules.join("、")},
仅输出JSON {pass: 布尔, fail: 数组}`
}]
});
return JSON.parse(res.choices[0].message.content.trim());
}这是整个 Loop 的自我检验环节。
- 它把生成的文案和规则一起发给 AI,要求 AI 扮演"质检员"。
- 强制要求 AI 只输出 JSON ,格式为
{pass: true/false, fail: ["规则1", "规则2"]}。 - 我们解析 JSON 得到
pass和fail,从而知道文案是否达标,以及哪些规则没通过。
为什么让 AI 自己检查自己?
因为规则是自然语言描述的(如"标题带数字"),传统代码很难直接判断。而 LLM 本身具备语义理解能力,让它当检查员是最自然的选择。这其实是 LLM 的自我反思(Self-Reflection) 技术的简化版。
8. 主循环 runLoop()
javascript
javascript
async function runLoop() {
console.log('AI Loop 开始');
while (!needStop()) {
round++;
console.log(`\n 第${round}轮`);
// ① 生成
const { text, token } = await gen();
totalToken += token;
// ② 记录重复
sameCount = (text === lastText) ? sameCount + 1 : 0;
lastText = text;
// ③ 校验
const { pass, fail } = await check(text);
if (pass) {
console.log(`✅ 全部规则通过,循环结束`);
console.log(`最终文案:\n${text}`);
return;
}
console.log(`❌ 不满足规则: ${fail.join(', ')},继续下一轮...`);
}
console.log(`\n⛔ 触发刹车强制停止,最后一次内容:\n${lastText}`);
}流程图如下:
text
markdown
开始 → 检查刹车 → (未刹车) → 轮次+1 → 生成文案 → 累加token → 判断是否与上一轮相同 → 更新sameCount → 校验文案 → 通过? → 结束并输出
↓ 不通过
打印失败规则,回到循环开头关键点:
- 每轮都会生成全新的文案(不是基于上一轮修改,而是重新生成),这样能保证多样性,但也会增加 token 消耗。
- 校验结果
fail数组会打印出来,让我们知道具体哪里不达标,方便人工干预(也可以进一步把失败规则反馈给生成 prompt,实现"带反馈的生成",但本例未做)。 - 如果校验通过,立即
return退出,输出最终文案。 - 如果触发刹车,则输出最后一次内容并退出。
循环的自我检验(Self-Check)过程详解
这是 AI Loop 最精髓的部分。我们来看一个具体例子:
第一轮生成:
"美妆新手必看!这些口红颜色超显白......"(标题有数字吗?没有 → 不满足规则"标题带数字")
校验函数收到文案后,AI 检查员返回:
json
{"pass": false, "fail": ["标题带数字"]}于是循环继续。
第二轮生成(可能因为随机性,这次带数字了):
"3支必入口红,黄皮也能轻松驾驭......"(正文可能超过300字?检查员说"正文<300字"未通过)
校验返回:
json
{"pass": false, "fail": ["正文<300字"]}继续循环。
第三轮生成,AI 终于写出了满足所有规则的文案,校验返回 {"pass": true, "fail": []},循环结束。
这个过程中,AI 既是作者 ,又是审稿人,不需要我们手动检查每一轮,完全自动化。
为什么说 AI Loop 解放了人,但也带来"Token大爆炸"?
优势:
- 将重复的"生成→检查→修改"工作完全自动化,我们只需要设定目标和规则。
- 可以并行运行多个 Loop,快速产出高质量内容。
- 适用于各种有明确规则的文本生成任务(广告文案、产品描述、代码生成、邮件撰写等)。
缺点:
- Token 消耗会成倍增加。假设平均每轮消耗 500 token,跑 5 轮就是 2500 token,比一次生成贵 5 倍。
- 如果规则设置不合理,可能永远无法通过,全靠刹车机制兜底。
- AI 校验本身也可能出错(比如误判),导致 Loop 提前结束或无限循环。
所以,设计 Loop 时要精心设置边界:最大轮数、预算上限、重复停止条件,三者缺一不可。
如何改进?让 Loop 更聪明
- 反馈式生成 :把上一轮
fail的规则传回给生成 prompt,比如"上次缺少标题数字,这次请加上"。这样能加速收敛。 - 动态调整规则:如果连续几轮都卡在同一个规则,可以适当放宽要求(比如字数从"<300"改为"<350")。
- 多模型协作:生成用创意模型,校验用严谨模型(如 GPT-4 校验,Claude 生成),各取所长。
- 记录历史:保存每一轮的文案和校验结果,方便分析 Loop 行为。
结语:你写的不是代码,是AI的工作流
Loop 是计算机科学最基础的概念,但在 AI 时代被赋予了新的生命。AI Loop 不仅仅是循环,而是一种自主迭代的工作流------让 AI 自己生成、自己检查、自己完善,直到满足人类设定的目标。
下次当你还在手动改 Prompt 时,不妨想一想:能不能把这件事交给一个 Loop?
700 万人看过的那条推文说:"别再给 AI 写提示词,你应该去设计 Loop。"
今天,你设计 Loop 了吗?