技术债是高息贷款------每天小额偿还,别让它滚雪球。
一个令人不安的发现
OpenAI 的驭缰工程团队在实验初期遇到了一个意想不到的问题:
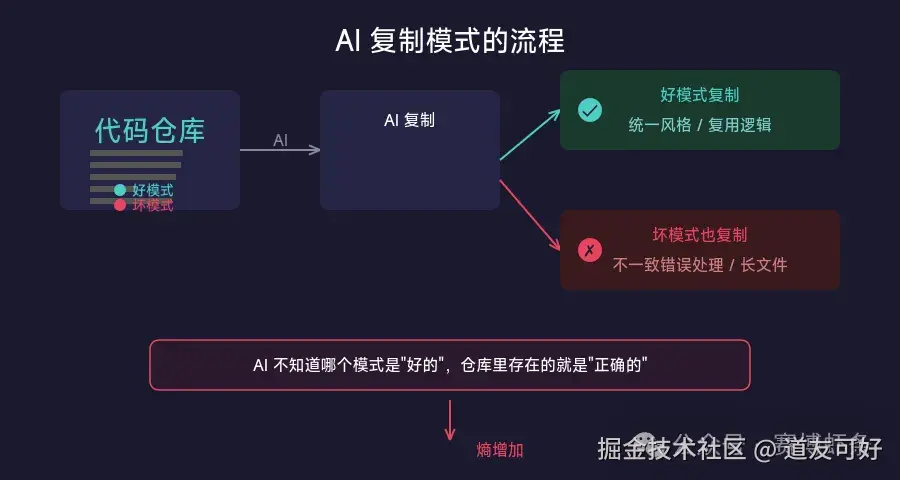
智能体会复现代码库里已有的模式------包括坏模式。
如果仓库里有一个手写的辅助函数,AI 会模仿着再写一个。如果错误处理方式不统一,AI 会继续用不一致的方式处理。如果某个文件有 1000 行,AI 就觉得文件可以 1000 行。
AI 不知道哪个模式是"好的",哪个是"历史遗留的坏习惯"。对它来说,仓库里存在的就是"正确的"。
这就是熵------代码库的混乱度会随时间自然增长,而 AI 是最好的混乱放大器。
OpenAI 的失败尝试
最初,团队每周花 20% 的时间手动清理"AI 残渣"------重复代码、不一致的错误处理、过时的文档。
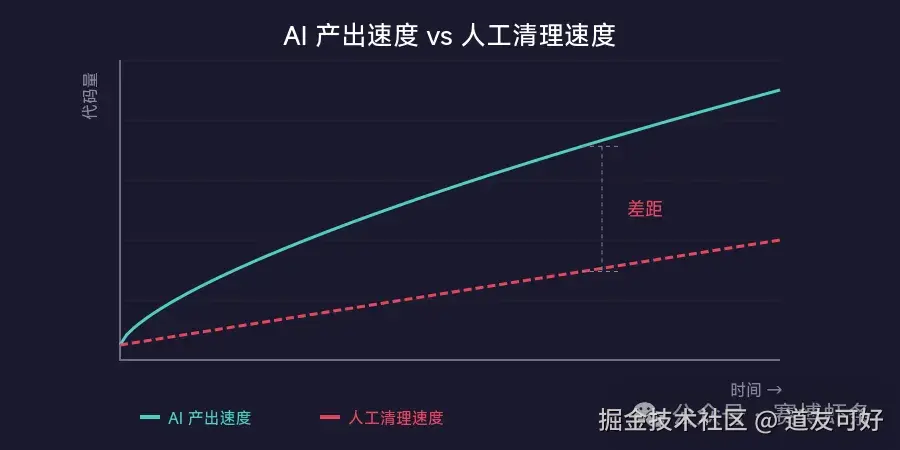
结果:不具备可扩展性。
- 20% 的时间用来清理 → 生产力直接打了八折
- 手动清理永远追不上 AI 生成速度
- 人会累、会漏、会烦
这和传统工程里的技术债本质相同,只不过速度被 AI 拉快了 10 倍。
垃圾回收:正确的类比
OpenAI 最终找到的解决方案,用了一个非常精准的类比:垃圾回收(Garbage Collection)。
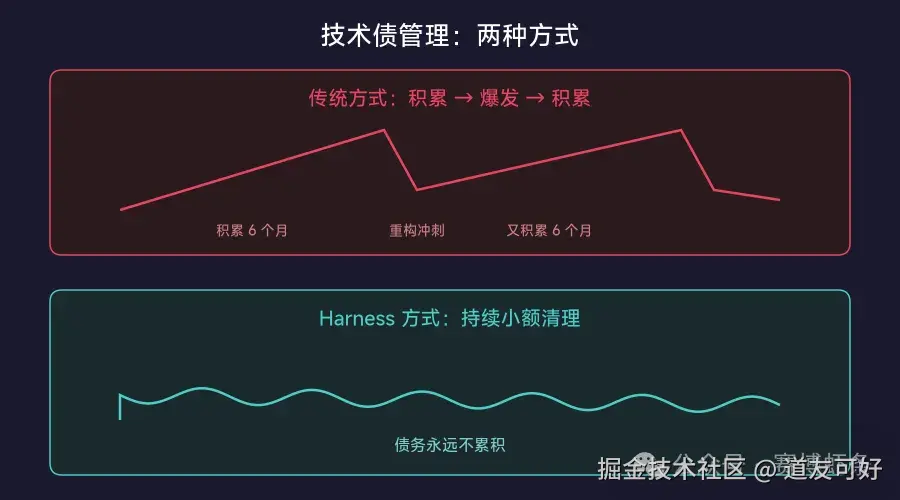
在编程语言中,GC 不是等内存全用光了再一次性清理。而是持续地、小颗粒地、自动地回收不再使用的内存。
技术债管理也应该是这样:
❌ 传统方式:积累 6 个月 → 一个月的重构冲刺 → 积累 6 个月 → ...
✅ Harness 方式:每天小额偿还 → 持续清理 → 债务永远不累积
具体怎么做:编码 + 自动化

第一步:把"黄金规则"编码到仓库
OpenAI 定义的黄金规则(有主观意见的机械规则):
- 共享工具包 > 手写辅助函数 --- 把不变式集中管理
- 不做 YOLO 探测 --- 不凭猜测访问数据,必须有类型或验证
- 偏好自有实现的关键子集 --- 与其包装复杂的第三方库,不如实现一个简单可控的子集
这些不是写在文档里的"建议",这是编码成 lint 规则和结构测试的可执行约束。
第二步:建立自动清理流程
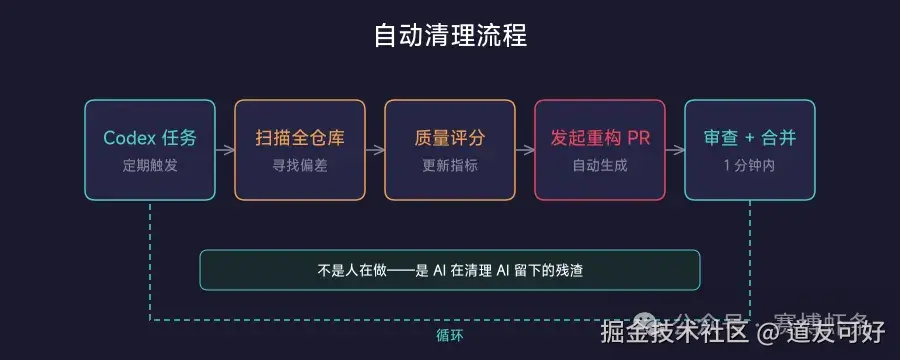
定期后台 Codex 任务 → 扫描全仓库 → 寻找偏差 → 更新质量评分 → 发起重构 PR → 大多数 1 分钟内审查 + 自动合并
这是 AI 在清理 AI 留下的残渣。
第三步:形成自纠循环
人类审查发现坏模式 → 更新黄金规则文档 → 转化为 lint 规则 → 自动应用于所有代码 → doc-gardening 智能体扫描文档一致性
人类发现的坏模式一旦编码为规则,后续代码都会自动遵守------不用每次都靠人盯着。
Claude Code 源码里的熵管理启示

张汉东的《驾驭工程》(马书)从 Claude Code 源码中提炼了几条直接相关的原则:
"三行重复代码优于过早抽象"
这看起来反直觉------我们不是一直在追求 DRY(Don't Repeat Yourself)吗?
但在 AI 编码的世界里,过早抽象比适度重复更危险。因为:
- AI 理解"三行重复代码"比理解"一个通用抽象层"容易得多
- 抽象一旦有缺陷,影响的是所有调用方
- 重复代码可以通过 lint 检测和批量重构;抽象错误则需要深入理解才能发现
"不要给你没修改的代码添加 docstring"(基于 Claude Code 行为的归纳)
AI 有一个倾向:顺手"优化"它路过的代码。加注释、加类型、重构命名。
这看起来是好事。但它增加了 diff 的噪音,让 review 变困难,还可能引入意外变更。
这一条其实就是范围匹配:只改该改的,不多管闲事。
不同场景下的熵管理策略

| 场景 | 熵增长速度 | 清理策略 |
|---|---|---|
| AI 独立生成的绿地项目 | 极高 | 需要完整的自动清理流程 |
| AI 辅助的现有项目 | 中等 | 重点关注 AI 修改的文件 |
| 纯人工项目 | 较低 | 传统技术债管理即可 |
| AI 重构的遗留代码 | 极高 | AI 可能把坏模式带到新代码里 |
个人开发者的最小熵管理

你不需要 OpenAI 级别的基础设施。一个简单的方案:
每周一次"园艺时间"(15 分钟)
- 看 AI 本周改动的 diff
- 有没有重复代码?→ 提炼为共享函数
- 有不一致的模式?→ 加 lint 规则
- 有过时的文档?→ 更新
- 新发现的坏模式?→ 加到黄金规则
自动化的底线
- 类型检查 --- 防止数据形状漂移
- 基础 lint --- 保持代码风格一致
- 测试覆盖率检查 --- 确保不遗漏
这三样东西配置一次,终身受益。它们是最便宜也最有效的"熵传感器"。
写在最后
很多团队根本没想过这件事。
AI 写代码的项目交付效率约 10 倍于人类。制造技术债的速度也差不多------毕竟 AI 一天能改几百个文件,人一天只能审几个。不做熵管理,代码库迟早崩溃。
好消息是:熵管理本身也可以自动化。让 AI 来清理 AI 留下的残渣------这是驭缰工程中最实用的自循环之一。
觉得这篇文章有帮助?关注我,驭缰工程系列每周更新,下一篇讲怎么从零开始实践。
这是驭缰工程系列的第七篇。上一篇:《Anthropic 的三智能体实验:用 AI 监督 AI》 下一篇:《从今天开始:你的第一个 Harness Engineering 实践》