在 MapReduce 的宏大叙事中,如果说 Map 是"分"的智慧,Reduce 是"合"的艺术,那么连接这两者的 Shuffle 过程,就是那根穿针引线的"金线"。
很多初学者认为 Shuffle 仅仅是数据的传输,但实际上,它是 MapReduce 中最复杂、最消耗资源,也是最核心的阶段。据统计,Shuffle 过程可能占据整个作业30%-50%的执行时间。今天,我们就来一场"心脏手术",深度解剖 Shuffle 的四大核心组件:Partition、Sort、Combiner 和 GroupingComparator。
Hadoop 相关知识与文章参考:
1. Partition 分区
在 Map 端输出了大量的<key, value>对之后,这些数据需要被发送给 Reducer。但是,发给哪一个Reducer 呢?这就是 Partition(分区)要解决的问题。
1.1. 为什么要分区
假设我们有3个 Reducer,如果不进行分区,数据就会随机乱飞。为了保证同一个 Key(比如单词"apple")的所有数据都汇聚到同一个 Reducer 手中进行汇总,我们必须制定规则。
1.2. 默认分区器
Hadoop 默认使用HashPartitioner。它的逻辑非常简单粗暴:利用 Key 的哈希值对 Reducer 的数量取模。
源码逻辑如下:
Java
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}参数说明:
- key.hashCode():获取键的哈希值。
- Integer.MAX_VALUE:Integer 的最大值,
key.hashCode() & Integer.MAX_VALUE确保哈希值为非负数。 - numReduceTasks:Reduce任务的个数,取余操作,将数据均匀分散到 Reducer 中。
1.3. 自定义分区器
默认分区虽然简单,但有时无法满足业务需求。例如,在处理手机号数据时,我们希望将北京(139开头)的数据分发给 Reducer 1,上海(138开头)的数据分发给 Reducer 2。这时就需要自定义分区。
1.3.1. 自定义分区器步骤
- 继承 Partitioner,然后,重写 getPartition() 方法,返回分区。
- 在 Job 驱动类中,设置自定义的分区器。
- 自定义分区器后,需要根据自定义分区器的逻辑,设置相应数量的 ReduceTask。
1.3.2. 自定义分区示例
需求:将文件中的手机号按前三位数,分区输出到不同文件中。
注意:当前示例直接在之前"手机上下行流量"示例基础上实现,重复的代码省略,具体可参考:4Hadoop序列化实战。主要修改如下:
- 添加分区类
DefPartitioner。 - 修改 Driver 类,添加分区器的定义。
核心代码修改如下:
- 创建分区类 DefPartitioner。
Java
package com.example.hadoop.mapreduce.partition;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* @Description TODO 自定义分区器,该方法返回指定分区
*/
public class DefPartitioner extends Partitioner<Text, FlowBean> {
/**
* 计算,并返回分区
*
* @param text
* @param flowBean
* @param i
* @return
*/
@Override
public int getPartition(Text text, FlowBean flowBean, int i) {
int res = 0;
switch (text.toString().substring(0, 3)) {
case "136":
res = 0;
break;
case "137":
res = 1;
break;
case "138":
res = 2;
break;
case "139":
res = 3;
break;
default:
res = 4;
break;
}
return res;
}
}- Driver 驱动类中,添加分区类与 ReduceTask 的个数配置。
Java
//分区类
job.setPartitionerClass(DefPartitioner.class);
//设置ReduceTask个数
job.setNumReduceTasks(5);- 执行后,在
output/目录下,会创建出5个文件分别对应5个分区,查看文件内的内容是否正确。
2. WritableComparable排序
Shuffle 的核心承诺之一是:发给 Reducer 的数据,Key 必须是有序的。为了实现这一点,Hadoop 需要一种机制来比较任意两个 Key 的大小。
2.1. 概述
在 Java 中,对象比较通常依赖Comparable接口。但在 Hadoop 的分布式环境中,数据需要在网络上传输(序列化),并在不同节点间比较(反序列化后比较)。因此,Hadoop 定义了自己的接口WritableComparable。
它结合了两种能力:
- Writable:支持序列化(写出)和反序列化(读取),以便网络传输和磁盘存储。
- Comparable:支持比较大小(
compareTo方法),以便排序。
2.2. WritableComparable排序示例
需求:根据手机流量示例,对总流量进行降序排序。
注意:当前示例直接在之前"手机上下行流量"示例基础上实现,具体可参考:4Hadoop序列化实战。这次整体的逻辑大致一致,但是我们不复用代码了,这里我们重新实现。
- 自定义 Bean 对象 ComFlowBean 实现
WritableComparable接口。
Java
package com.example.hadoop.mapreduce.writablecomparable1;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @Description TODO 实体类,封装上下行流量和总流量
*/
public class ComFlowBean implements WritableComparable<ComFlowBean> {
private long upFlow;
private long downFlow;
private long sumFlow;
public ComFlowBean() {
}
// getter and setter... ...
// toString...
/**
* 序列化方法
*
* @param dataOutput
* @throws IOException
*/
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
}
/**
* 反序列化方法
* 注意:读取顺序与序列化顺序一致
*
* @param dataInput
* @throws IOException
*/
@Override
public void readFields(DataInput dataInput) throws IOException {
this.upFlow = dataInput.readLong();
this.downFlow = dataInput.readLong();
this.sumFlow = dataInput.readLong();
}
/**
* WritableComparable 接口需要实现的比较方法
* 方法需要给出比较的逻辑
*
* @param o 与当前实例比较的对象
* @return
*/
@Override
public int compareTo(ComFlowBean o) {
return Long.compare(o.sumFlow, this.sumFlow);
}
}- 编写 Mapper 类 ComFlowMapper。
Java
package com.example.hadoop.mapreduce.writablecomparable1;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @Description TODO
*/
public class ComFlowMapper extends Mapper<LongWritable, Text, ComFlowBean, Text> {
private ComFlowBean flowBean = new ComFlowBean();
private Text phone = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.将输入数据,按\t切分
String[] infos = value.toString().split("\t");
//2.获取数据,并封装
flowBean.setUpFlow(Long.parseLong(infos[infos.length - 3]));
flowBean.setDownFlow(Long.parseLong(infos[infos.length - 2]));
flowBean.setSumFlow(flowBean.getUpFlow() + flowBean.getDownFlow());
phone.set(infos[1]);
//3.输出
context.write(this.flowBean, this.phone);
}
}- 编写 Reducer 类 ComReducer。
Java
package com.example.hadoop.mapreduce.writablecomparable1;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @Description TODO
*/
public class ComFlowReducer extends Reducer<ComFlowBean, Text, Text, ComFlowBean> {
@Override
protected void reduce(ComFlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 这里直接输出即可
for (Text phone : values) {
context.write(phone, key);
}
}
}- 编写 Driver 类 ComDriver。
Java
package com.example.hadoop.mapreduce.writablecomparable1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @Description TODO
*/
public class ComFlowDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1.生成一个job实例
Job job = Job.getInstance(new Configuration(), "flow bean");
//设置类路径
job.setJarByClass(ComFlowDriver.class);
//2.设置job的mapper和reducer
job.setMapperClass(ComFlowMapper.class);
job.setReducerClass(ComFlowReducer.class);
//3.设置输入输出数据类型
job.setMapOutputKeyClass(ComFlowBean.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(ComFlowBean.class);
//4.设置程序的输入输出
FileInputFormat.setInputPaths(job, new Path("D:/input/*"));
FileOutputFormat.setOutputPath(job, new Path("D:/output"));
//5.提交任务
boolean b = job.waitForCompletion(true);
System.exit(b ? 0: 1);
}
}- 执行后,在
output/目录下,会输出一个文件,查看该文件内容是否正确排序。
2.3. WritableComparable分区内排序示例
需求:要求按照手机号前三位分区输出,每个分区内按照总流量排序。
注意:当前示例直接在"手机上下行流量排序"示例基础上实现,具体可参考:2.2WritableComparable排序示例。主要修改如下:
- 添加分区类
ComPartitioner。 - 修改 Driver 类,添加分区器的定义。
核心代码修改如下:
- 添加自定义 Partitioner 分区类
ComPartitioner。
Java
package com.example.hadoop.mapreduce;
import com.example.hadoop.mapreduce.writablecomparable1.ComFlowBean;
import org.apache.hadoop.mapreduce.Partitioner;
import javax.xml.soap.Text;
/**
* @Description TODO
*/
public class ComPartitioner extends Partitioner<ComFlowBean, Text> {
@Override
public int getPartition(ComFlowBean comFlowBean, Text text, int i) {
String prePhoneNum = text.toString().substring(0, 3);
int partition = 4;
switch (prePhoneNum) {
case "136":
partition = 0;
break;
case "137":
partition = 1;
break;
case "138":
partition = 2;
break;
case "139":
partition = 3;
break;
}
return partition;
}
}- 在 Driver 驱动类中,添加自定义分区类和 ReducerTask 个数。
Java
//设置分区器
job.setPartitionerClass(ComPartitioner.class);
//设置reduceTask数量
job.setNumReduceTasks(5);- 执行后,在
output/目录下,会输出5个文件,对应5个分区,查看各个文件内容,是否正确,以及是否排序。
3. Combiner合并
在 Shuffle 过程中,网络带宽是最宝贵的资源。如果 Map 端输出了1亿条数据,全部通过网络传给 Reducer,网络很容易拥堵。Combiner 就是为了解决这个问题而生的。
3.1. 概述
Combiner 本质上是一个运行在 Map 端的、局部的 Reducer。它在数据溢写(Spill)到磁盘之前,或者在合并(Merge)溢写文件时运行。
3.2. 作用
对同一个 Map 任务输出的相同Key的数据进行"预聚合"。
3.3. 场景举例
以 WordCount 为例:
- 没有 Combiner:Map 输出
<hello, 1>, <hello, 1>, <hello, 1>,网络传输3条记录。 - 使用Combiner:Map 输出后,Combiner 先计算一次
<hello, 3>。网络传输仅1条记录。
3.4. 自定义Combiner
Combiner 本质就是一个 Reducer,所以逻辑直接复用 Reducer 代码即可,如下:
Java
public class WordcountCombiner extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 逻辑代码
context.write(key, v);
}
}Driver 驱动类中设置 Combiner。
Java
job.setCombinerClass(MyCombiner.class);避坑指南:如果业务逻辑是求"平均值",直接复用 Reducer 逻辑作为 Combiner 的逻辑的话,会出错。
4. GroupingComparator分组比较器
数据到了 Reducer 端,数据已经按键排好序了,但是,Reducer 的reduce()方法签名是:
Java
reduce(KEY key, Iterable<VALUE> values, Context context)这意味着,所有相同 Key 的数据,会被封装成一个 Iterable 传过来。那么,框架是如何判断哪些 Key 是相同的呢?
4.1. 分组排序步骤
- 继承 WritableComparator。
- 重写 compare() 方法。
- 创建一个构造方法,将比较对象的类传递给父类。
4.2. GroupingComparator分组比较器示例
需求:输出每个订单成交额最大的订单,输出格式:<订单ID 成交额>。
输入数据:
订单ID 商品ID 成交额
0000001 Pdt_01 222.8
0000002 Pdt_05 722.4
0000001 Pdt_02 33.8
0000003 Pdt_06 232.8
0000003 Pdt_02 33.8
0000002 Pdt_03 522.8
0000002 Pdt_04 122.4输出数据:
订单ID 成交额
0000001 222.8
0000002 722.4
0000003 232.8- 自定义订单实现类 OrderBean,需要实现 WritableComparable。
Java
package com.example.hadoop.mapreduce.groupingcomparator;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* @Description TODO
*/
public class OrderBean implements WritableComparable<OrderBean> {
private String orderId;
private String productId;
private double price;
public OrderBean() {
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getProductId() {
return productId;
}
public void setProductId(String productId) {
this.productId = productId;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return orderId + '\t' + productId + '\t' + price;
}
@Override
public int compareTo(OrderBean o) {
int i = this.orderId.compareTo(o.orderId);
if (i == 0) {
return Double.compare(o.price, this.price);
}
return i;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(orderId);
dataOutput.writeUTF(productId);
dataOutput.writeDouble(price);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.orderId = dataInput.readUTF();
this.productId = dataInput.readUTF();
this.price = dataInput.readDouble();
}
}- 编写 Mapper 类 OrderMapper。
Java
package com.example.hadoop.mapreduce.groupingcomparator;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @Description TODO
*/
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> {
private OrderBean orderBean = new OrderBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1.切分数据
String[] infos = value.toString().split("\t");
//2.封装数据
orderBean.setOrderId(infos[0]);
orderBean.setProductId(infos[1]);
orderBean.setPrice(Double.parseDouble(infos[2]));
//3.输出
context.write(orderBean, NullWritable.get());
}
}- 编写自定义分组比较器 OrderComparator。
Java
package com.example.hadoop.mapreduce.groupingcomparator;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* @Description TODO
*
* Map 输出通过 WritableComparator 进行分组,key 相同为一组,然后输出到 Reduce 中
*
* WritableComparator 默认比较器,key相同认为是同一组
* 但是当前示例中,OrderBean 作为 key,里面重写了比较方法,所有只有 orderId 和 price 相同才会认为是同一组
*
* 上述分组流程,并不可以满足当前需求,所以需要重写分组方式
*
* 重新为:订单相同就认为是同一组
*/
public class OrderComparator extends WritableComparator {
public OrderComparator() {
super(OrderBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean oa = (OrderBean) a;
OrderBean ob = (OrderBean) b;
return oa.getOrderId().compareTo(ob.getOrderId());
}
}- 编写 Reducer 类 OrderReducer。
Java
package com.example.hadoop.mapreduce.groupingcomparator;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
/**
* @Description TODO
*/
public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable> {
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//1.获取迭代器
Iterator<NullWritable> iterator = values.iterator();
//2.获取数据
//注:这里相同订单号的数据作为输入,并且同一订单号数据进行了逆序排序
//按照需求,取第一条数据即可,这里手动 next()
if (iterator.hasNext()) {
iterator.next();
context.write(key, NullWritable.get());
}
}
}- 编写 Driver 类 OrderDriver。
Java
package com.example.hadoop.mapreduce.groupingcomparator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @Description TODO
*/
public class OrderDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(OrderDriver.class);
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
// 设置分组比较器
job.setGroupingComparatorClass(OrderComparator.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("D:/input/*"));
FileOutputFormat.setOutputPath(job, new Path("D:/output"));
boolean b = job.waitForCompletion(true);
System.out.println(b ? 0 : 1);
}
}- 执行后,查看
output/目录下,生成文件内容是否正确。
5. Shuffle机制
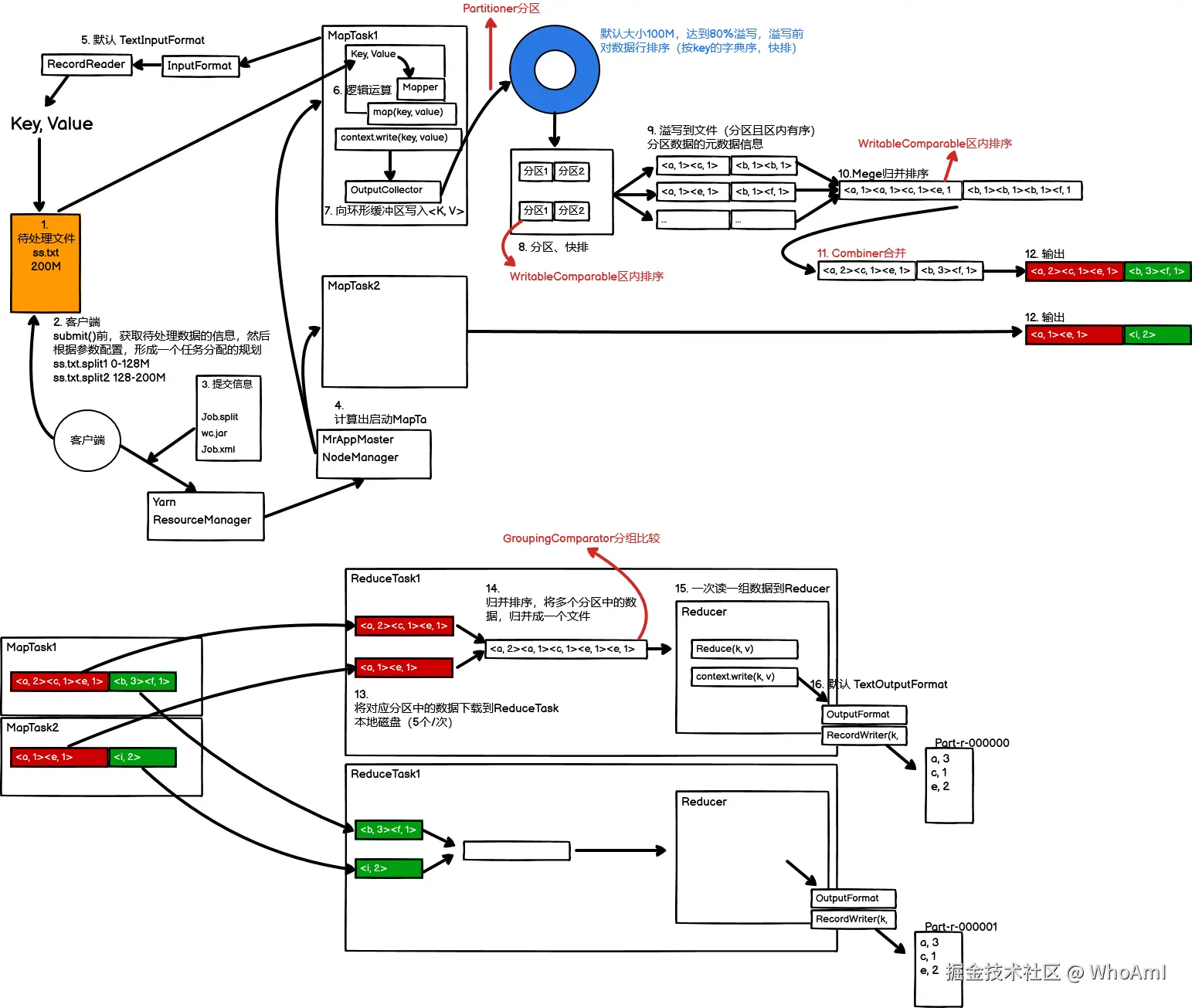
6. 总结
Shuffle 并非黑盒,而是一个精密的流水线:
- Partition 决定了数据去往哪个"车间"(Reducer)。
- WritableComparable 确保了数据在车间内部是按顺序排列的。
- Combiner 在出发前剔除了冗余数据,减轻了运输压力。
- GroupingComparator 在终点站决定了哪些数据被打包成一个包裹交给工人(reduce函数)处理。
理解了这四个组件,你就掌握了 MapReduce 性能调优的钥匙。在下一篇中,我们将继续探讨 MapReduce 的 OutputFormat 相关内容。敬请期待!