在大数据处理的宏大叙事中,MapReduce 无疑是那个开启了时代篇章的经典模型。它将复杂的并行计算抽象为"Map(映射)"和"Reduce(归约)"两个核心阶段,让开发者能够专注于业务逻辑本身,而无需深陷于分布式系统的复杂性泥潭。然而,一个 MapReduce 作业的成功启动,并非始于 Mapper 的第一行代码,而是源于对输入数据的精准规划与读取。这正是 InputFormat 大显身威的舞台。
如果把 MapReduce 作业比作一场精密的流水线生产,那么 InputFormat 就是原料的"质检与分装车间"。它的核心职责有两项:
- 数据切片:决定如何将海量的输入文件在逻辑上划分为一个个独立的、可并行处理的数据块,即 InputSplit。切片的数量直接决定了MapTask 的数量,从而影响整个作业的并行度与执行效率。
- 数据解析:为每个切片提供一个 RecordReader,负责将切片中的原始字节流解析成 Mapper 能够理解的键值对(Key/Value Pair)。
理解 InputFormat,是深入 MapReduce 原理的第一步,也是优化作业性能的关键一环。
Hadoop 相关知识与文章参考:
1. FileInputFormat切片机制
FileInputFormat 是所有基于文件的 InputFormat 的基类,它定义了最基础也最核心的切片逻辑。理解它,就掌握了 MapReduce 数据输入的命脉。
1.1. 切片的核心思想
首先需要明确一个至关重要的概念:数据切片(Split)是逻辑上的划分,而非物理上的。HDFS 中的 Block 是物理存储单元,而 InputSplit 只是一个包含了文件路径、起始位置、长度等元数据的对象。它并不会在磁盘上真正切割文件,只是在逻辑上告诉 MapTask:"你的任务就是处理文件的这一段数据"。
1.2. 默认切片机制
FileInputFormat 的切片逻辑非常直观:针对每个文件单独进行切片,且不考虑数据集整体。
- 按照文件内容长度进行切片;
- 切片大小,默认等于 Block 大小,Block 大小默认128MB;
- 切片不考虑数据集整体,而是针对每个文件单独切片;
假设我们有两个文件:file1.txt(320MB)和file2.txt(10MB),HDFS Bolck 大小为128MB,FileInputFormat 的处理逻辑如下:
diff
文件 file1.txt,会切分成3个切片,如下:
- 0 ~ 128MB
- 128 ~ 256MB
- 256 ~ 320MB,注意:第3个切片实际大小只有56MB,虽然小于128M,但是也是单独一个切片,不会与 fil2.txt 进行合并。
文件 file2.txt,只会切分成1个切片,如下:
- 0 ~ 10MB潜在问题:如果目录下存在海量小文件,FileInputForamt 会为每个小文件生成一个切片,进而启动一个 MapTask。这会导致集群中充斥着大量处理极少量数据的任务,极大地降低处理效率。
1.3. 切片大小计算公式
FileInputFormat 如何决定一个切片的大小呢?其核心逻辑在computeSplitSize方法中,公式如下:
Shell
splitSize = Math.max(minSize, Math.min(maxSize, blockSize));参数说明:
- blockSize:HDFS 的数据块大小,默认为128MB。这是切片的基准。
- minSize:切片的最小尺寸,由参数
mapreduce.input.fileinputformat.split.minsize控制,默认为1字节。 - maxSize:切片的最大尺寸,由参数
mapreduce.input.fileinputformat.split.maxsize控制,默认为 Long 的最大值。
在默认配置下,minSize 极小,maxSize 极大,因此,splitSize 就等于 blockSize。这意味着,一个128MB的文件会被切分成一个128MB的切片,一个300MB的文件则会被切分成128MB、128MB和44MB三个切片。
1.4. 切片源码浅析
切片的生成过程主要在FileInputFormat.getSplits()方法中完成。核心源码如下:
Java
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
bytesRemaining -= splitSize;
}参数说明:
- bytesRemaining:文件剩余大小。
- splitSize:切片大小,默认等于 Block 大小为128M。
- SPLIT_SLOP:这里是固定值1.1。
这里有个细节,为避免小文件产生,当文件剩余大小(bytesRemaining)小于切片的1.1倍(splitSize * SPLIT_SLOP)时,框架会倾向将剩余部分合并到一个切片中,而不是单独创建一个新的切片。
其实转换一下 while 表达式,可以得到bytesRemaining > splitSize * SPLIT_SLOP,也就是bytesRemaining > 128M * 1.1 = 140.8,所以,这说明文件剩余大小只要不大于140.8M时,就不会单独切出一个新的切片来。
根据上述源码可以计算出来,默认情况下,切片最大为140.8M,最小(要大于)12.8M。
2. CombineTextInputFormat切片机制
默认的TextInputFormat(FileInputFormat的实现类)在处理大量小文件时会遇到性能瓶颈。因为每个文件,无论多小,都会生成至少一个切片,从而启动一个 MapTask。当面对成千上万个几KB的小文件时,会产生海量的 MapTask,导致集群资源被大量消耗在任务的调度和初始化上,而非真正的数据处理。
2.1. 应用场景
CombineTextInputFormat 正是为了解决"小文件过多"的问题而设计的。它的核心思想是:将多个小文件在逻辑上合并到一个切片中,让一个 MapTask 处理多个文件,从而大幅减少 MapTask 的数量,提升作业效率。
2.2. 示例与配置
假设我们有一个包含4个1MB小文件的目录。使用默认的 TextInputFormat,会产生4个 MapTask。而使用 CombineTextInputFormat,我们可以通过配置,让一个 MapTask 处理所有4个文件。
Java
// 在Driver中设置InputFormat类
job.setInputFormatClass(CombineTextInputFormat.class);
// 设置虚拟存储切片最大值,例如4MB
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
// 可选:设置最小切片大小,例如2MB
CombineTextInputFormat.setMinInputSplitSize(job, 2097152);其工作原理分为两步:
- 虚拟存储过程:将所有小文件的大小相加,然后根据设定的
maxSize和minSize,将这些文件逻辑上打包成几个"虚拟存储块"。 - 切片过程:每个"虚拟存储块"最终形成一个 InputSplit。这样,多个小文件就被"打包"进了同一个切片,由一个 MapTask 统一处理。
在代码中,可以通过控制台输出查看 CombineTextInputFormat 是否生效。
在未添加上述代码时,控制台输出的切片数为4,如下:

在添加上述代码后,控制台输出的切片数为1,如下:

3. 自定义InputFormat
3.1. 如何实现
Hadoop 提供的默认 InputFormat 虽然强大,但面对特殊的文件格式(如自定义的二进制日志、非文本格式的序列文件等)时,往往力不从心。这时,我们就需要自定义 InputFormat。
自定义 InputFormat 的核心是继承FileInputFormat(或其子类),并实现两个关键方法:
isSplitable():决定文件是否可以被切分。对于某些不可分割的文件格式(如某些压缩文件),需要返回false。createRecordReader():这是自定义的核心。你需要返回一个自定义的RecordReader实例,它负责将切片中的原始数据解析成你想要的键值对。
3.2. 实现示例
需求:将多个小文件合并成一个 SequenceFile 文件,SequenceFile 里面存储着多个文件,存储的形式为文件路径+名称为 key,文件内容为value。SequenceFile 文件是 Hadoop 用来存储二进制形式的 key-value 对的文件格式。
注意:该示例中,没有定义 Mapper 和 Reducer,原因是在自定义的 InputFormat 中已经得到我们想要的输出,不需要 Mapper 和 Reducer。
- 文件就自己写几个文件即可。
- 自定义 InputFormat。
Java
package com.example.hadoop.mapreduce.definputformat;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
/**
* @Description TODO 自定义 InputFormat
* 实现功能:将读入的文件,以 <文件路径 + 文件名, 文件内容> 的形式输出
*/
public class DefInputFormat extends FileInputFormat<Text, BytesWritable> {
/**
* 将读入文件打散成对应的kv
*
* @param inputSplit
* @param taskAttemptContext
* @return
* @throws IOException
* @throws InterruptedException
*/
@Override
public RecordReader<Text, BytesWritable> createRecordReader(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
return new DefRecordReader();
}
/**
* 该方法判断读入文件是否可切分
* 由于当前需求,是将文件的内容整体作为 value,应该默认全都不允许切分
* 所以,该方法直接让其返回 false,表示文件不可切分
*
* @param context
* @param filename
* @return
*/
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
}- 自定义 RecordReader。
Java
package com.example.hadoop.mapreduce.definputformat;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
/**
* @Description TODO 自定义RecordReader
* 实现功能:读入文件,将文件的全路径作为key,文件内容作为value输出
*/
public class DefRecordReader extends RecordReader<Text, BytesWritable> {
//文件切片对象
FileSplit fs;
//文件系统
FileSystem fileSystem;
//输入流
FSDataInputStream inputStream;
//标记是否读取完成
private boolean isRead = false;
//输出数据的 key-value
private Text key = new Text();
private BytesWritable value = new BytesWritable();
/**
* 初始化方法,用于创建流对象
*
* @param inputSplit
* @param taskAttemptContext
* @throws IOException
* @throws InterruptedException
*/
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
//获取文件路径
fs = (FileSplit) inputSplit;
Path path = fs.getPath();
//创建文件系统
fileSystem = FileSystem.get(taskAttemptContext.getConfiguration());
//创建输入流
inputStream = fileSystem.open(path);
}
/**
* 尝试获取下一个kv值
*
* @return
* @throws IOException
* @throws InterruptedException
*/
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (isRead) {
//isRead=true,读取完成,当前方法返回false,表示不再获取下一kv
return false;
} else {
//isRead=false,未读取完成,继续获取下一kv
//key
key.set(fs.getPath().toString());
//value
byte[] bytes = new byte[(int) fs.getLength()];
int read = inputStream.read(bytes);
value.set(bytes, 0, read);
isRead = true;
return true;
}
}
/**
* 当前key
*
* @return
* @throws IOException
* @throws InterruptedException
*/
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return key;
}
/**
* 当前value
*
* @return
* @throws IOException
* @throws InterruptedException
*/
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return value;
}
/**
* 进度/是否完成
*
* @return
* @throws IOException
* @throws InterruptedException
*/
@Override
public float getProgress() throws IOException, InterruptedException {
return isRead ? 1 : 0;
}
/**
* 关闭流
*
* @throws IOException
*/
@Override
public void close() throws IOException {
IOUtils.closeStream(inputStream);
}
}- Driver 类。
Java
package com.example.hadoop.mapreduce.definputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import java.io.IOException;
/**
* @Description TODO 自定义inputformat的driver驱动类
*/
public class DefInputFormatDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(DefInputFormatDriver.class);
// 设置输入的 InputFormat 为自定义的 InputFormat
job.setInputFormatClass(DefInputFormat.class);
// 设置输出的 OutputFormat 为 SequenceFileOutputFormat
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(BytesWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
FileInputFormat.setInputPaths(job, new Path("d:/input/*"));
FileOutputFormat.setOutputPath(job, new Path("d:/output"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}4. MapReduce的Job提交流程
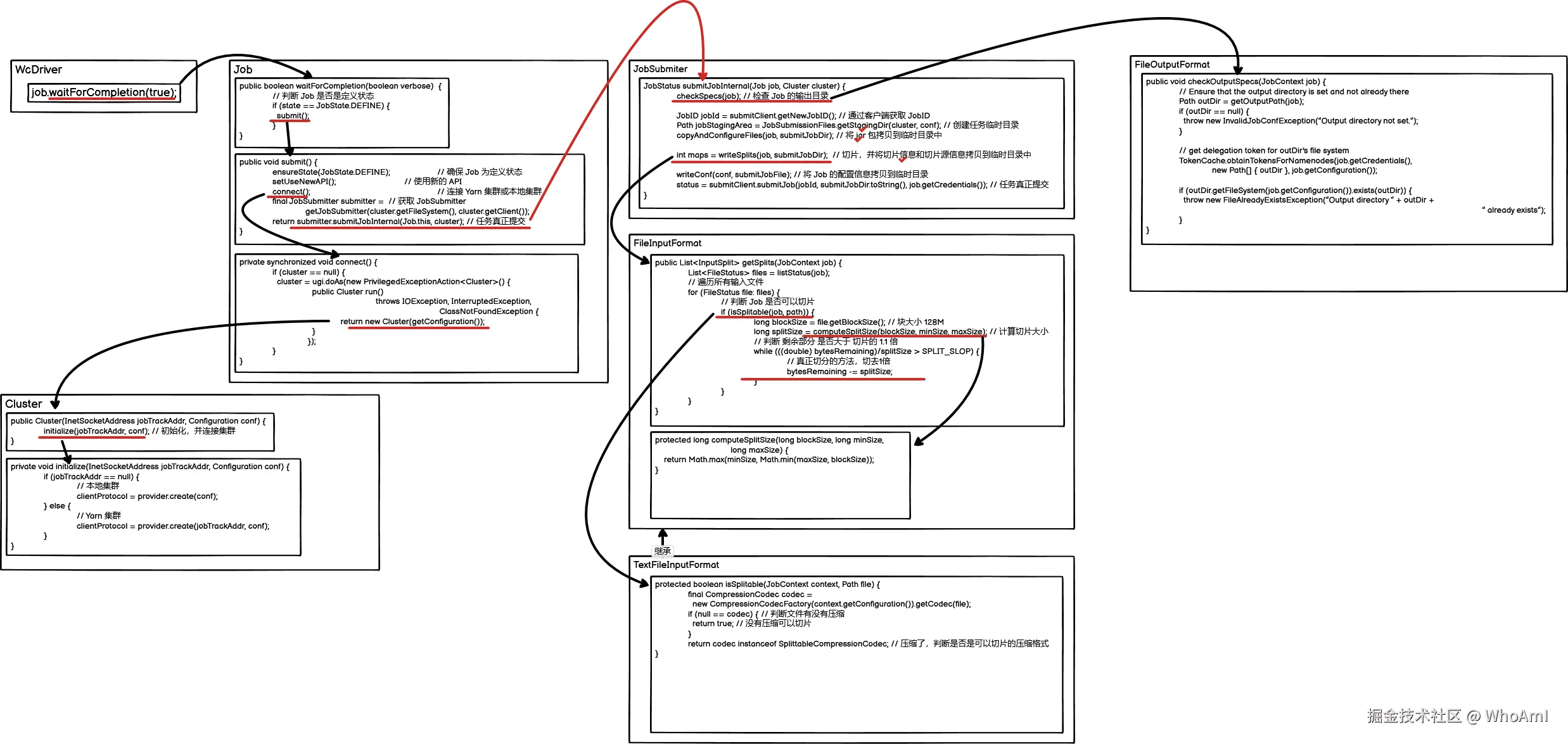
- 检查 Job 状态是否为定义状态。
- 提交配置文件,连接集群,确定是本地还是 Yarn 集群。
- 提交 Job,并检查输出文件(output)是否存在。
- 确定客户端的文件系统 jobClientFileSystem 是本地客户端还是 HDFS。
- 根据集群客户端获取相应身份 jobId。
- 如果是集群模式,需要拷贝 jar 包到集群。
- 计算切片,生成切片规划文件。
- 向文件系统中提交临时文件(jar 包、切片信息 和 配置信息)。
- 提交 Job,返回提交状态。
5. InputFormat实现类对比
| Inputformat实现类 | 切片方式 | 打散KV方式 |
|---|---|---|
| FileInputFormat | 1.1倍判断,1倍切片 | 没实现 |
| CombineTextInputFormat | 重写:setMaxInputSplitSize = 4M切片 | CombineFileRecordReader |
| TextInputFormat | 同FileInputFormat | LineRecordReader |
| KeyValueInputFormat | 同FileInputFormat | KeyVlaueLineRecordReader |
| NLineInputFormat | 重写:按行切 | LineRecordReader |
| 自定义 Inputformat | 同FileInputFormat | 自定义RecordReader |
说明:
- CombineFileRecordReader:因为需要跨文件读数据,此 CombineFileRecordReader 包装了 TextInputFormat,所以打散成 KV 与 LineRecordReader 一致;
- LineRecordReader:key 为行偏移量,value 为当前行内容;
- KeyVlaueLineRecordReader:key 为第一个分隔符之前的内容,value 为剩余行内容;
6. 总结
InputFormat 是 MapReduce 数据处理的入口,它通过精巧的切片机制,将庞大的数据集转化为可并行处理的单元,奠定了整个作业高效执行的基础。从FileInputFormat的默认切片逻辑,到CombineTextInputFormat对小文件场景的优化,再到自定义 InputFormat 的无限可能,这一机制展现了 Hadoop 框架在设计上的灵活性与扩展性。
掌握 InputFormat 的原理,不仅有助于我们理解 MapReduce 的底层运作,更能帮助我们在面对实际生产中的性能瓶颈时,找到精准的优化方向。在下一篇中,我们将深入 MapReduce 的核心------Shuffle 机制,一探数据如何在 Map 和 Reduce之 间"洗牌"与流转。