Kronos 调研:金融 K 线基础模型,是真突破,还是量化圈的新玩具?
说明:本文只做技术研究和工程拆解,不构成任何投资建议,也不讨论任何具体标的的买卖决策。
TL;DR
- 场景:金融 K 线时间序列的基础模型范式探索(tokenize + pretrain + generate)
- 结论:Kronos 把 LLM 的离散 token 自回归范式搬到了金融 K 线,提供统一 backbone 与多任务建模能力
- 产出:技术路线拆解 + 工程使用指南 + 边界与适用场景判断
版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
| K-line Tokenizer(BSQ + coarse/fine subtoken) | ✅ 已验证 | 项目核心组件,GitHub 源码可读 |
| Decoder-only Transformer 自回归预训练 | ✅ 已验证 | 类似 GPT 范式,causal mask |
| Kronos-mini(约 4.1M 参数,context 2048) | ✅ 已验证 | Hugging Face NeoQuasar/Kronos-mini |
| Kronos-small(约 24.7M 参数,context 512) | ✅ 已验证 | Hugging Face NeoQuasar/Kronos-small |
| Kronos-base(约 102.3M 参数,context 512) | ✅ 已验证 | Hugging Face NeoQuasar/Kronos-base |
| Kronos-large(约 499.2M 参数) | ⚠️ 待验证 | 用户原文标注"当前未公开" |
| 多路径采样与概率预测 | ✅ 已验证 | 官方示例支持 sample_count、T、top_p |
| 基于 Qlib 的微调流程 | ✅ 已验证 | finetune/ 目录提供样例 |
| 真实交易系统接入能力 | ❌ 未提供 | 需自行补数据治理、风控、监控 |
| 真实交易盈利能力 | ❌ 未验证 | 项目明确不构成投资建议 |
文章正文
最近 GitHub 上一个叫 shiyu-coder/Kronos 的项目热度很高。它的完整标题是 Kronos: A Foundation Model for the Language of Financial Markets,直译过来就是"金融市场语言的基础模型"。
这个名字很容易让技术人产生联想:既然大语言模型可以学习自然语言,图像模型可以学习视觉 token,那么金融市场里的 K 线、成交量、波动结构和周期节奏,是否也可以被看成一种"语言"?如果可以,是否也能先在大规模金融时间序列上预训练一个基础模型,再迁移到预测、回测、风控、合成数据等任务?
Kronos 的核心尝试,就是沿着这个方向走了一步。
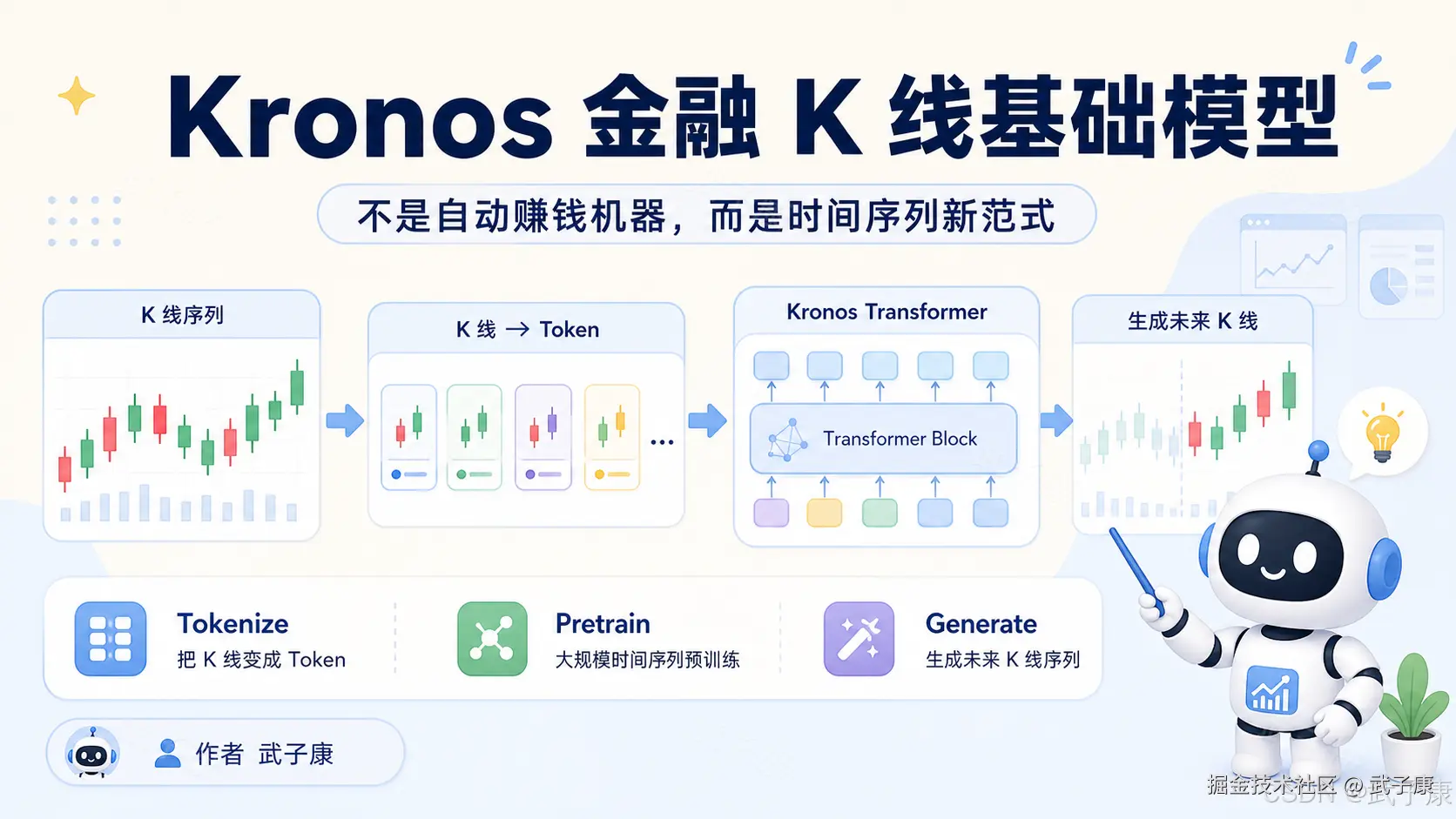
它不是传统意义上的"股票预测脚本",也不是简单技术指标模型,而是把金融 K 线序列转成离散 token,再用自回归 Transformer 建模未来 token 的生成过程。简单说,它把 K 线当成一种特殊语言,把金融预测改写成"下一段市场 token 生成问题"。
TL;DR:Kronos 到底值得看什么?
如果只用一句话概括:Kronos 值得关注的不是"它能不能直接赚钱",而是它把 LLM 时代的 tokenize + pretrain + generate 范式,搬到了金融 K 线这种高噪声、强非平稳、多变量约束的时间序列上。
它的技术主线大概是:
- 输入是金融 K 线数据,例如 open、high、low、close、volume、amount。
- 先训练 K-line tokenizer,把连续 OHLCVA 数值离散化成 token。
- token 不是单层,而是 coarse subtoken + fine subtoken。
- 再用 decoder-only Transformer 做自回归预训练。
- 推理时像文本生成一样生成未来 token,再解码回连续 K 线。
- 通过多次采样,可以得到多条未来路径,用于概率预测和情景分析。
这条路线的新意在于:它不是直接回归未来价格,而是先构造"金融市场的词表",再学习这些词在时间维度上的排列规律。
但边界也很明确:Kronos 不是交易圣杯,不是自动赚钱机器,也不是一个完整量化系统。它更适合作为研究工具、信号模块、合成数据生成器或金融时间序列基础模型案例。
Kronos 是什么?
Kronos 是一个面向金融 K 线数据的时间序列基础模型项目。
传统 K 线通常包含 open、high、low、close、volume,有些场景还会包含 amount,也就是开盘价、最高价、最低价、收盘价、成交量、成交额。这类数据不是普通的一维时间序列,而是多维、强噪声、非平稳、受市场结构影响极强的序列。
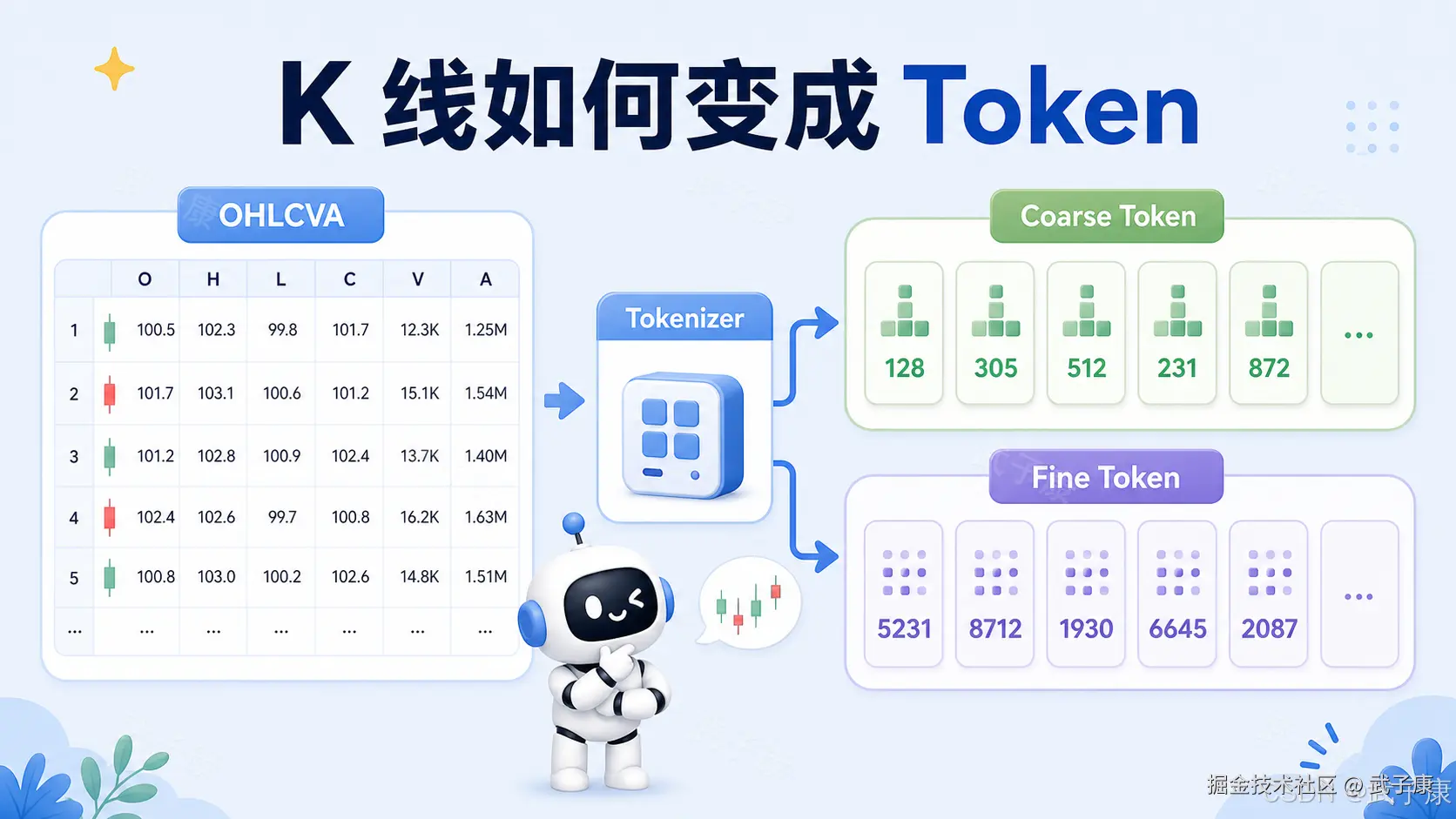
Kronos 没有直接拿连续数值做回归,而是先训练一个专门的 K-line tokenizer,把连续 OHLCVA 数据离散化成 token。之后,再用 decoder-only Transformer 做自回归预训练,让模型根据历史 token 生成未来 token。
这和大语言模型的逻辑很像。
大语言模型输入文本 token,目标是预测下一个 token。Kronos 输入 K-line token,目标是预测未来 K-line token。不同点在于,自然语言 token 本来就是离散符号,而 K 线原本是连续数值,所以 Kronos 需要先完成"金融连续信号到离散 token"的转换。
从官方定位看,Kronos 不是只针对单一预测任务,而是试图服务多个金融时间序列任务:价格序列预测、收益预测、波动率预测、合成 K 线生成、投资模拟等。
为什么金融 K 线需要专门的基础模型?
过去两年,时间序列基础模型越来越多,例如 Chronos、TimesFM、Moirai、Moment、TimeMOE 等。它们都在尝试把时间序列问题做成预训练模型问题。
但金融 K 线和通用时间序列不完全一样。
温度、流量、电力、销售额、传感器数据通常有相对稳定的物理或业务规律。金融市场更复杂,至少有四个典型难点。
第一,信噪比很低。
K 线里确实包含趋势、波动、流动性和交易行为信息,但这些信号经常被大量噪声掩盖。短期价格波动尤其如此。模型看起来拟合了走势,实际学到的可能只是噪声相关性。
第二,非平稳性很强。
市场结构会变化。不同年份、不同市场环境、不同资产类别、不同交易制度下,数据分布都可能漂移。一个模型在历史数据中有效,不代表未来继续有效。
第三,多变量之间有强约束。
OHLCVA 不是随便六个数字。最高价不能低于开盘价和收盘价,最低价不能高于开盘价和收盘价,成交量和成交额也与价格区间有关。模型如果直接做连续值回归,很容易生成不合理 K 线。
第四,下游任务不只有预测价格。
量化研究不只是"预测下一根 K 线涨跌"。更实际的任务包括排序信号、波动率估计、风险暴露控制、组合构建、合成数据、策略回测和稳定性评估。一个只会预测点位的模型,距离真实量化工作流很远。
Kronos 的出发点就是:通用时间序列模型有基础模型能力,但金融 K 线的统计特性太特殊,需要更贴近金融数据结构的 tokenizer、训练目标和评估任务。
核心路线:先离散化,再自回归生成
Kronos 最核心的设计可以概括成两步:
text
K-line Tokenization
-> Autoregressive Pre-training也就是:先把连续 K 线变成离散 token,再用自回归 Transformer 学习 token 序列。
K-line tokenizer:把连续市场信息变成 token
Kronos 的 tokenizer 不是简单把价格按区间分桶。它使用 Transformer autoencoder 加 Binary Spherical Quantization,也就是 BSQ,把每个时间点的多维 K-line item 编码成离散 token。
更关键的是,它不是生成单一 token,而是把 token 拆成两部分:coarse subtoken 和 fine subtoken。
可以把它理解为"粗粒度 token + 细粒度 token"。
粗粒度 token 负责捕捉主要结构,比如这一根 K 线大致处于什么形态、什么区间、什么状态;细粒度 token 负责补充残差信息,让重建更精细。
这个设计的好处是避免词表过大。如果直接用一个很大的二进制码表示 K 线,表达能力很强,但词表规模会指数级增长,后面的自回归模型会变重。Kronos 把 token 拆成两个子 token,本质上是在表达能力和计算复杂度之间做折中。
自回归 Transformer:学习市场 token 的时间结构
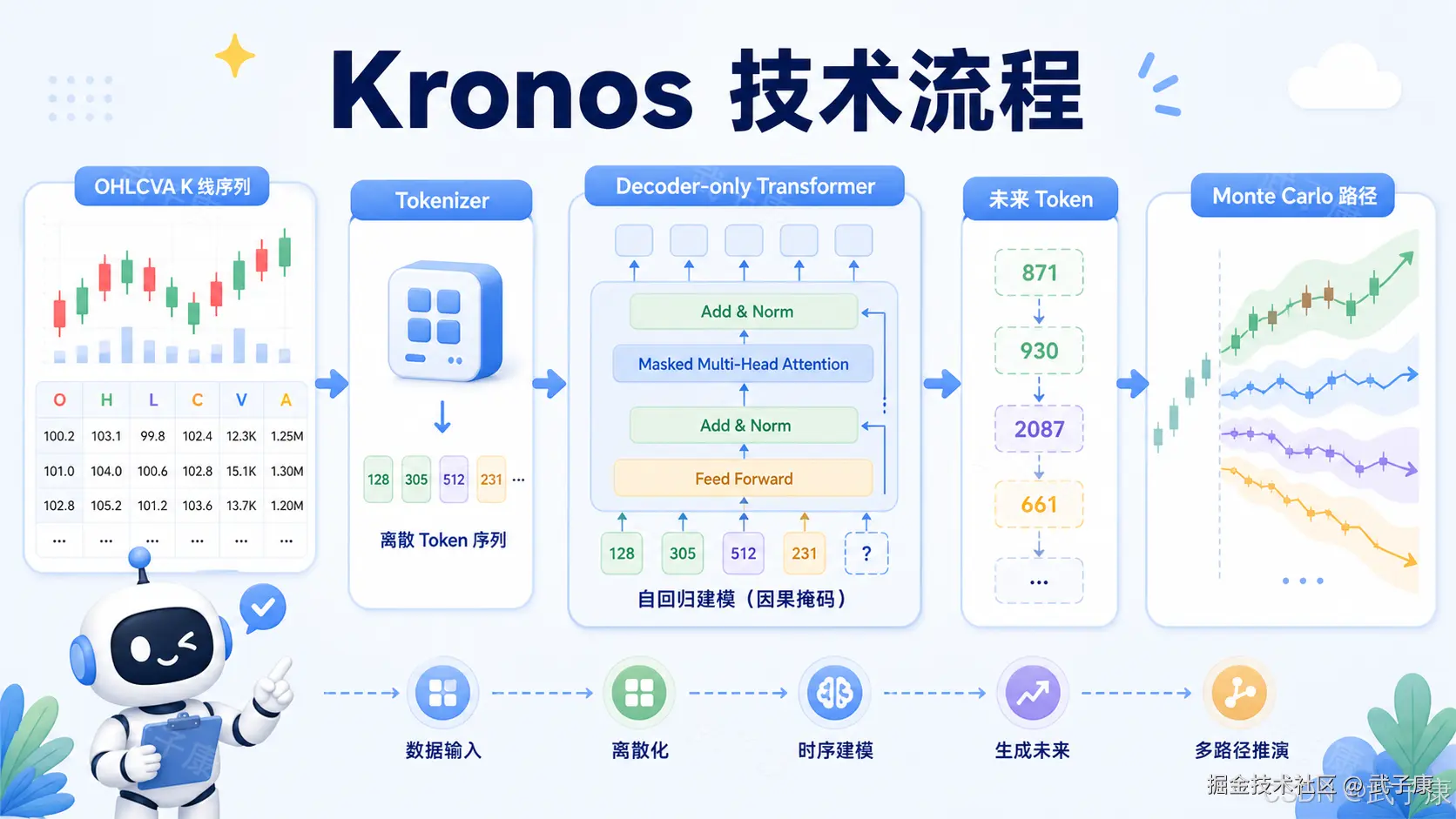
得到 token 后,Kronos 使用 decoder-only Transformer 做自回归建模。
这和 GPT 类模型结构逻辑相似:模型根据历史 token 预测未来 token。不同的是,Kronos 的 token 不是文字,而是 K 线状态。
它的预测顺序也利用了粗细两级结构:先预测 coarse subtoken,再基于 coarse subtoken 预测 fine subtoken。这样做的含义是,模型先确定大致市场状态,再补充更细的市场细节。
在推理阶段,Kronos 可以像文本生成一样,一步步生成未来 K 线 token,再通过 tokenizer decoder 把 token 转回连续 OHLCVA 数值。
因此,它输出的不是简单回归出来的一条线,而是可以通过采样生成多条未来路径。这也是它支持概率预测和 Monte Carlo rollout 的基础。
模型规模:不是超大模型,但路线清晰
从模型规模看,Kronos 不是动辄几十亿、几百亿参数的大模型。
官方模型 zoo 里包含几个版本:
| 模型 | 参数量 | 上下文长度 |
|---|---|---|
| Kronos-mini | 约 4.1M | 2048 |
| Kronos-small | 约 24.7M | 512 |
| Kronos-base | 约 102.3M | 512 |
| Kronos-large | 约 499.2M | 512,当前未公开 |
从参数量看,small 和 base 对普通 AI 工程师更友好。base 只有一亿级参数,理论上推理门槛不算离谱,mini 甚至更轻。
不过金融时间序列推理的成本不只看参数量,还要看预测长度、采样次数、资产数量、频率粒度和批处理方式。
你只预测一个资产未来 24 个时间步,和同时预测 3000 个资产未来 120 个时间步,完全不是一个计算量级。如果还要 Monte Carlo 采样 20 次、50 次,成本会继续上升。
所以工程上更合理的理解是:Kronos 可以作为批处理预测服务接入研究、回测、信号生成系统,但不应该被直接想象成低延迟在线交易模型。
Kronos 真正解决了什么?
Kronos 解决的不是"明天涨还是跌"这种问题。
它真正有价值的地方在于:给金融 K 线建模提供了一种基础模型范式。
第一,从任务专用模型转向通用金融序列表征。
过去做金融预测,往往是每个任务单独建模。预测收益率一个模型,预测波动率一个模型,合成数据又是另一个模型。Kronos 的思路是先用大量 K 线数据预训练统一 backbone,再迁移到多个任务。
第二,更自然地支持概率预测。
很多传统模型输出一个点预测,例如未来 close 是多少。但金融市场里,单点预测往往不够。更有价值的是分布:未来可能有多条路径,风险不是只看均值,还要看波动范围、尾部风险和不确定性。Kronos 通过自回归采样生成多条未来路径,再对路径做均值、分位数或情景分析。
第三,可以生成合成 K 线。
量化研究经常遇到数据不足、极端行情样本少、隐私或授权限制等问题。合成数据如果足够逼真,可以用于压力测试、模型预训练和鲁棒性评估。当然,合成金融数据非常容易出问题,它可能看起来像真实数据,却遗漏关键结构,所以不能直接替代真实历史数据。
第四,可以作为信号生成模块。
Kronos 可以预测未来 K 线、收益、波动率,也可以通过预测结果构造排序信号。但真实策略还要处理交易成本、冲击成本、滑点、容量、换手、风控暴露、停牌、涨跌停、数据延迟、幸存者偏差等问题。
模型输出的是信号,不是收益。
Kronos 和 Chronos 有什么区别?
Kronos 很容易和 Chronos 混淆。
Chronos 是一个通用时间序列基础模型框架,主要思路是把时间序列数值缩放和量化成固定词表 token,再用 T5 系列模型做概率预测。
Kronos 则是面向金融 K 线的专用基础模型。
二者共同点是:都把时间序列离散化,再用类似语言模型的范式建模。
区别在于:Chronos 面向更广泛的时间序列场景;Kronos 聚焦金融市场 K 线。Kronos 的 tokenizer 处理的是多维 OHLCVA 结构,并设计了 coarse/fine 两级 token;它的评估任务也更金融化,包括收益预测、波动率预测、合成 K 线、投资模拟等。
如果你做电力负荷、销售预测、传感器预测,Chronos、TimesFM、Moirai 这类通用模型可能更自然。
如果你做 K 线、成交量、价格行为、量化信号研究,Kronos 的建模假设更贴近领域。
工程使用:跑起来不难,用好不简单
从官方仓库看,Kronos 是标准 Python/PyTorch 工程。基础依赖包括 numpy、pandas、torch、einops、huggingface_hub、matplotlib、tqdm、safetensors 等。
最小使用流程大致是:
- 安装依赖。
- 加载 tokenizer 和模型。
- 准备历史 K 线 DataFrame。
- 准备历史时间戳和未来时间戳。
- 调用
KronosPredictor.predict()输出未来 OHLCVA 预测结果。
输入 DataFrame 必须包含 open、high、low、close。volume 和 amount 是可选项,缺失时会做填充或推导。
这说明它不是一个拿任意 CSV 就能直接跑的"万能预测器"。你需要保证字段结构、时间戳、频率一致性、缺失值处理、复权处理、异常值处理都合理。
金融数据前处理本身就是量化工程的核心部分。如果数据源质量差、复权逻辑不一致、时间戳错乱、缺失值处理粗糙,模型再先进也只会放大错误。
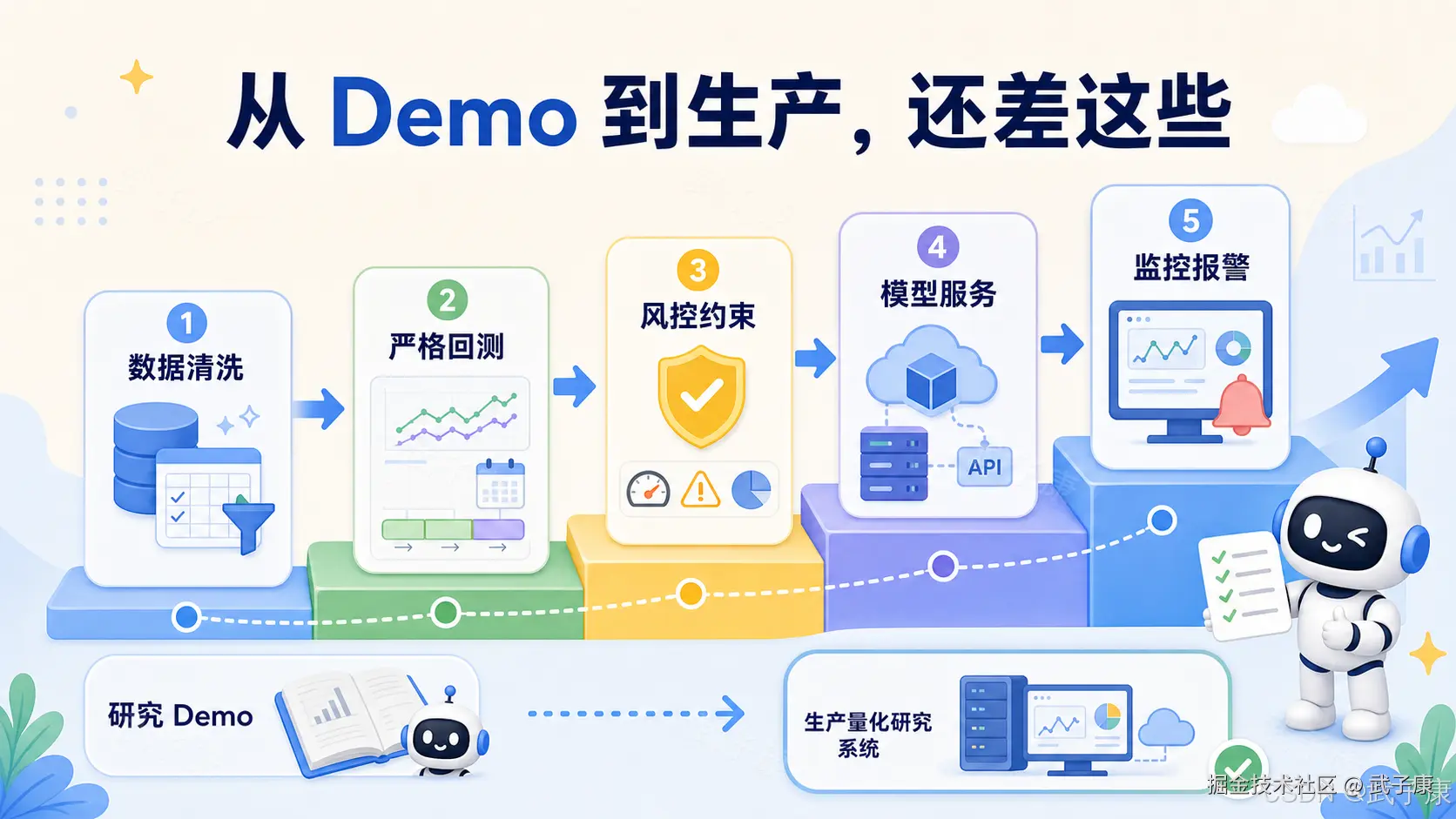
Kronos 还提供了微调流程,使用 Qlib 准备数据、训练 tokenizer、训练 predictor、做简单回测。这个流程对研究者有用,因为它给了一个从数据准备到模型微调再到评估的样例。
但这仍然不是生产系统。真正上线还需要自己补数据治理、任务调度、模型版本管理、回测框架、风险约束、监控报警、结果归因等系统能力。
亮点与边界
Kronos 的亮点主要有四个。
第一,领域专用 tokenizer。它没有简单分桶,而是用 Transformer autoencoder 加 BSQ 构造离散 token,并显式引入粗细层级。
第二,统一建模多个金融任务。它不只做单点预测,而是把价格、收益、波动率、合成数据、投资模拟都纳入评估。
第三,开源模型足够轻。mini、small、base 都是相对轻量的模型,对个人开发者、研究生、量化爱好者、AI 工程师来说,门槛比超大模型低很多。
第四,生成式路径适合表达不确定性。金融市场不是确定性系统,多路径生成比单点回归更适合做风险分析、情景模拟和稳定性评估。
但它的局限也必须说清楚。
第一,它不是交易圣杯。即便模型有统计预测优势,也可能被交易成本、滑点、容量、风控约束、过拟合、数据偏差和市场状态变化抵消。
第二,分布迁移仍然是核心风险。金融市场制度、参与者结构、流动性环境、波动状态都会变化,历史规律可能失效。
第三,回测结果需要谨慎解读。真实回测必须严肃处理未来函数、复权、停牌、涨跌停、交易成本、冲击成本、组合约束、行业中性、市值中性、风格中性等问题。
第四,只看 K 线不够。市场还有基本面、新闻、盘口、资金流、宏观变量、行业结构、事件冲击等信息。Kronos 更合理的定位,是价格行为和成交结构建模模块,而不是完整投资决策系统。
适合谁研究 Kronos?
Kronos 对四类人比较有价值。
AI 工程师可以通过它理解:基础模型范式不只存在于文本和图像,也可以迁移到结构化时间序列。
量化研究者可以把它作为新的信号生成模型或预训练 backbone,在自己的市场、频率、资产池和风控约束下做严肃测试。
金融工程开发者可以研究如何把它封装成批处理预测服务,接入研究平台、回测平台和模型服务体系。
时间序列模型研究者可以重点看 tokenizer 设计、粗细 token、自回归生成、test-time sampling 等方法。
不适合的人也很明确:如果你只是想找一个"输入股票代码,输出买卖点"的工具,Kronos 不适合。如果你没有数据处理和回测能力,只看预测图做交易,也不适合。
如何正确打开 Kronos?
比较合理的研究路径是:
- 先跑通官方示例,理解 DataFrame 字段、时间戳、lookback、pred_len、T、top_p、sample_count 等参数。
- 用公开历史数据做离线预测实验,先看输出是否满足基本约束,是否过度平滑,成交量是否异常。
- 做严格 walk-forward 测试。金融时间序列不能随机切分训练集和测试集。
- 把预测结果转成信号,而不是直接交易,例如未来收益排序、波动率估计、风险分层、趋势状态分类。
- 接入回测框架,并包含交易成本、调仓频率、持仓约束、风险暴露和滑点假设。
- 做消融实验,比较不同模型规模、不同 sample_count、不同 lookback、不同市场频率、微调前后差异。
- 做稳定性分析,看不同年份、不同市场状态、不同波动环境下是否稳定。
这样研究 Kronos,才接近严肃工程路径。
最终判断
Kronos 的出现,说明时间序列基础模型正在进入更细分的垂直领域。
过去的基础模型更多集中在文本、图像、音频、视频。现在,金融 K 线这种高噪声、强非平稳、多变量约束的序列数据,也开始被纳入 tokenize + pretrain + generate 的范式里。
这件事的价值不在于它马上能带来稳定收益,而在于它提供了一种新的研究起点。
金融市场不是自然语言,K 线也不是句子。但从建模角度看,它们都可以被转成 token 序列,都可以用上下文预测未来,都可以通过预训练学习某种统计结构。
Kronos 的真正意义,是把金融 K 线建模从"任务模型"往"领域基础模型"推进了一步。
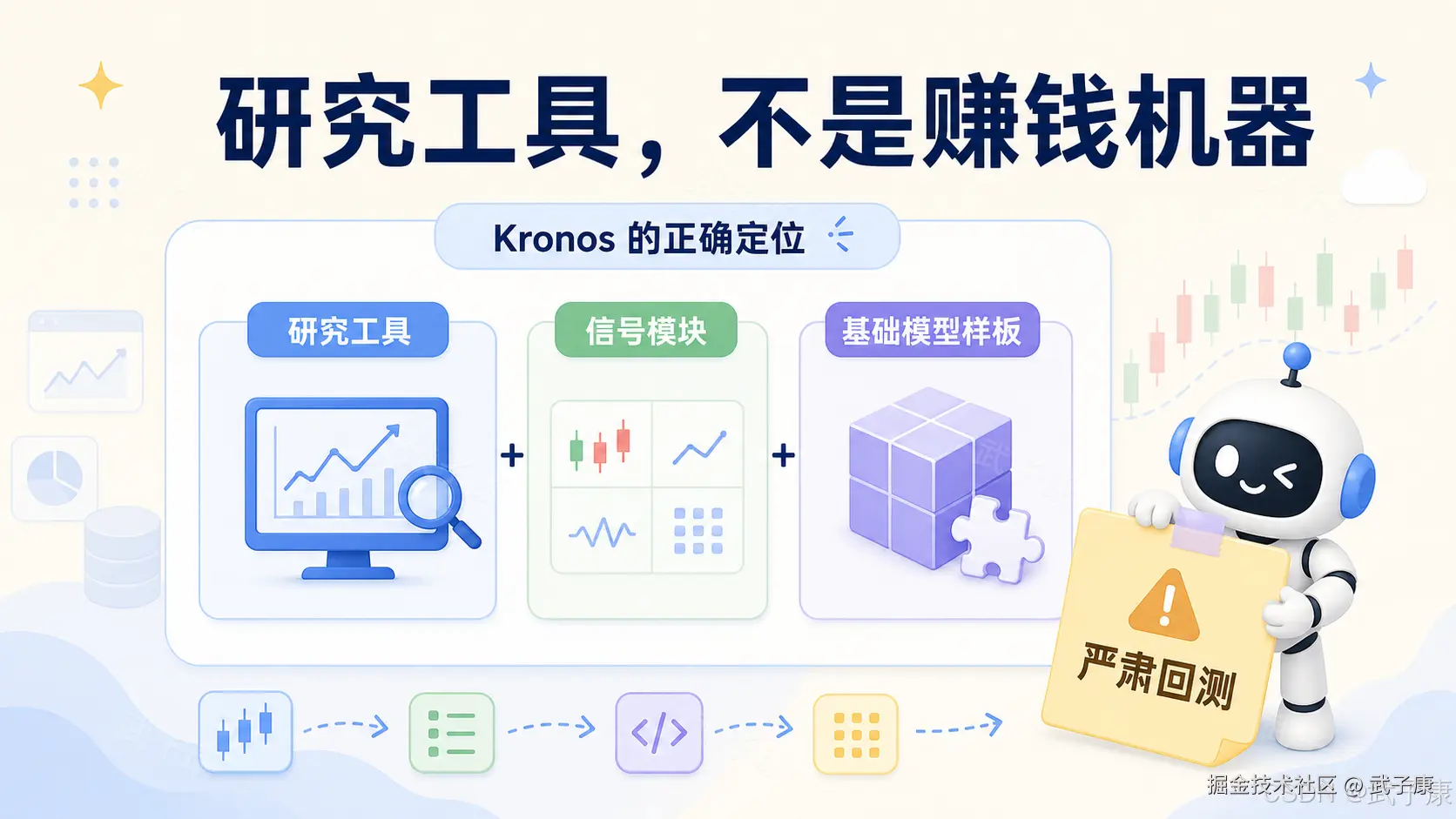
但边界也必须清楚:金融市场的噪声、非平稳性、交易成本和真实风控问题,不会因为一个基础模型出现而消失。Kronos 可以成为研究工具、信号模块、生成模型和技术样板,但不能被当作直接赚钱机器。
对技术人来说,最值得关注的是它的 tokenizer、层级离散表示、自回归生成、概率采样和微调流程。
对工程团队来说,最值得评估的是它能否接入自己的数据平台、回测平台和模型服务体系。
参考资料
- GitHub: shiyu-coder/Kronos
- Paper: Kronos: A Foundation Model for the Language of Financial Markets
- Hugging Face: NeoQuasar/Kronos
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
加载模型报 KronosTokenizer.from_pretrained 找不到对应 repo |
Hugging Face repo 名称拼写错误或权重未发布 | 检查 NeoQuasar/Kronos-Tokenizer-base / NeoQuasar/Kronos-mini 等是否拼写一致 |
严格按照 README 提供的 repo 名加载,或手动下载 safetensors 权重到本地路径 |
| 输入 DataFrame 报错缺少字段 | 输入未包含 open/high/low/close 四列 | 在调用 KronosPredictor.predict() 前打印 df.columns |
至少补齐 OHLC 四列,volume/amount 缺失会被自动填充 |
| 预测 K 线 high < low 或 close 越界 | 连续回归方式容易破坏 OHLC 约束 | 检查输出 DataFrame 的 high >= max(open, close) 与 low <= min(open, close) |
改用 Kronos tokenize + 生成范式,并通过 coarse/fine 两级 token 保留结构约束 |
| 单点预测曲线过于平滑、像均值回归 | sample_count=1 或 temperature 过低 | 检查 predict(..., T=..., top_p=..., sample_count=...) 参数 |
提高 sample_count(如 20-50)、适度提高 T,观察多路径分布 |
| 回测效果看起来很好但实盘失效 | 数据穿越(look-ahead)或随机切分训练/测试集 | 检查回测代码是否用了未来时间戳做特征、是否按时间滚动切分 | 改用 walk-forward 滚动窗口回测,严格禁止任何未来信息进入特征 |
| 模型在历史数据有效,新行情失效 | 金融市场分布迁移 / 制度变化 | 对比近 1-2 年与历史区间的特征分布、波动率、流动性 | 定期重训或微调,缩短回看窗口,加入 regime/state 特征 |
| 实盘收益远低于回测 | 漏算交易成本、滑点、冲击成本、涨跌停、停牌 | 回测引擎是否包含手续费、印花税、滑点模型、成交率 | 接入真实交易成本模型,做容量约束与冲击成本估计 |
| 不同资产预测精度差异巨大 | 训练数据分布偏向高流动性资产,小市值资产样本不足 | 检查训练集各资产的样本占比 | 在目标资产池上做微调(finetune/Qlib 流程),或加入资产 embedding |
| 合成 K 线看着像真的,但策略信号失效 | 合成数据缺少真实市场微观结构(跳空、停牌、涨跌停、成交稀疏) | 检查合成序列的 tick 级特征与极端事件分布 | 合成数据仅用于压力测试和模型预训练,不能直接替代真实历史数据 |
| 显存占用远高于预期 | 资产数量 × 预测长度 × sample_count 同时放大 | 用 torch.cuda.memory_summary() 检查峰值 |
减小 batch、降低 sample_count、或改用 base 以下的轻量模型 |
huggingface_hub 下载权重超时 |
网络受限或 HF 镜像未配置 | 检查 HF_ENDPOINT 与代理 |
配置 HF 镜像或手动下载权重放到本地目录后 from_pretrained(local_dir) |
作者:武子康的个人博客