Skill 脚本语言选型:Python、Node.js、Shell 到底怎么选?
为 AI Agent 写 Skill 时,很快会撞上一个看似简单、却很容易拖慢团队的问题:脚本到底用什么语言写?
一个 Skill 通常由两部分组成。一部分是给 Agent 看的说明文档,比如 SKILL.md;另一部分是给 Agent 调用的工具脚本,负责下载资料、解析文件、生成图片、调用接口、批量改写、验证输出。说明文档决定 Agent "知道怎么做",脚本决定 Agent "能不能稳定做完"。
脚本语言选错,不一定马上出问题,但会在维护中反复收税:简单任务写得过重,复杂任务靠 Shell 硬拼;本可以用成熟库解决的问题,最后变成一堆脆弱的字符串处理;本该给 Agent 用的自动化脚本,最后只有作者本人看得懂。
本文围绕 Skill 脚本的真实场景,对 Shell、Python、Node.js/TypeScript 做一次选型对比,并给出一套能落地的决策过程和可直接套用的代码骨架。
一、先定义问题:Skill 脚本不是普通业务代码
Skill 脚本的目标不是构建一个完整应用,而是把一类可重复操作沉淀成 Agent 能稳定调用的能力。
典型脚本包括:
- 抓取 URL 内容并转成 Markdown
- 读取
.docx、.xlsx、.pdf、图片等文件并提取信息 - 调用外部 API 生成图片、摘要、翻译或发布内容
- 把 Markdown 转成公众号 HTML、幻灯片、长图或知识卡片
- 批量处理目录,比如压缩图片、重命名、生成索引
- 执行项目检查,比如 lint、test、格式校验、结果比对
- 作为胶水层,串起多个已有 CLI 工具
它们有三个共同特点:
- 被 Agent 调用多于被人手动调用。 参数、输出、错误信息必须清晰稳定,不能依赖大量交互。
- 任务边界通常很窄。 一个脚本最好只做一件事,输入输出明确,便于 Agent 组合。
- 长期维护成本比一次写完更重要。 Skill 会被反复复制、迁移、增强,语言要让后续的人和 Agent 都容易读懂。
所以选型的核心问题不是"哪门语言最强",而是:
对这个 Skill 来说,哪门语言能用最低维护成本,稳定完成最常见的任务?
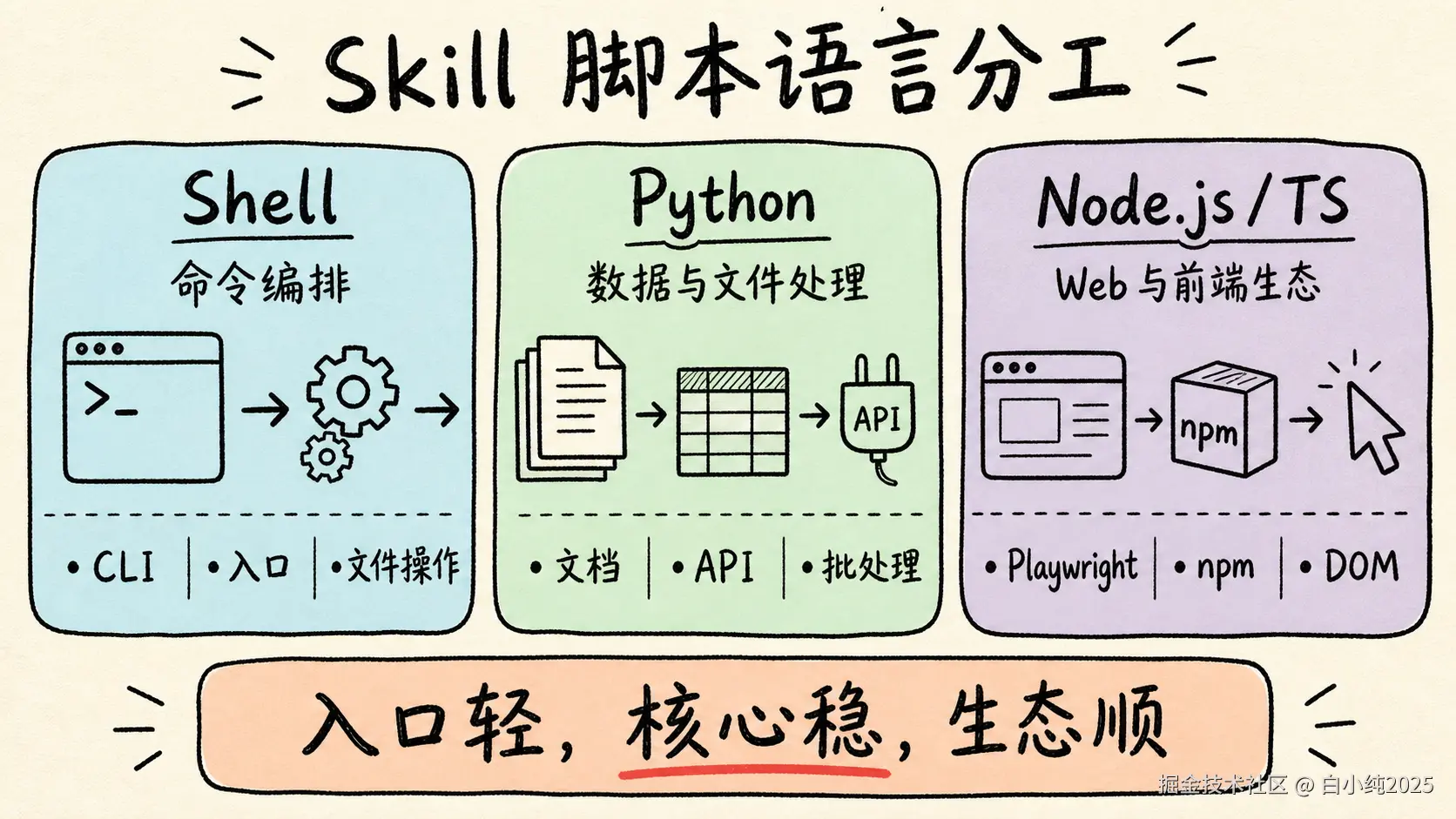
二、三类候选语言的基本定位
1. Shell:最适合做命令编排
Shell 天然贴近操作系统和 CLI 工具。文件移动、目录扫描、调用现成命令、拼接简单流水线,都是它的舒适区。
- 适合: 调用
git、ffmpeg、pandoc、curl、jq等现成命令;做很薄的一层包装(检查参数、建目录、调主程序);简单文件操作;作为入口设置环境变量再调 Python/Node。 - 不适合: 复杂 JSON/XML/HTML 解析;多步骤业务逻辑;高要求的错误处理;跨平台,尤其是要兼容 Windows;需要单元测试或维护复杂数据结构。
Shell 的最大问题是短脚本很爽,长脚本很痛。一旦出现多层条件、数组、字符串转义、并发、重试和结构化数据,就该换语言。
2. Python:最适合数据、文件和自动化处理
Python 是 Skill 脚本里的"默认稳妥选项"。它语法直接,生态成熟,尤其擅长文件、数据、网络请求、文档格式和图片处理。
- 适合: 解析生成 Markdown/HTML/JSON/CSV/YAML;处理 Excel、Word、PDF、图片、音视频元数据;数据清洗、批处理、格式转换;调用 HTTP API 并做重试、缓存、错误处理;有一定复杂度但还没到要做应用的业务逻辑。
- 不适合: 项目本身是前端/Node 生态,复用 npm 包更方便;任务强依赖浏览器自动化且团队已有 Playwright/Node 体系;需要发布成 npm 包并用
npx一键运行;团队没有 Python 运行时或依赖管理基础。
Python 的优势不是某个单点,而是综合平衡:写得快、读得懂、库够多、适合长期演进。
3. Node.js/TypeScript:最适合 Web、前端生态和工具链集成
Node.js 和 Web 生态天然同构。只要脚本涉及 npm 包、前端构建、浏览器自动化、Markdown/HTML 工具链或 CLI 发布,它往往很顺手。
- 适合: 复用 npm 生态(unified、remark、rehype、sharp、playwright);操作前端项目(Vite、Next.js、React、Tailwind、ESLint);浏览器自动化、页面截图、DOM 分析、可视化验证;发布成 npm 包支持
npx;团队主用 TypeScript,想要类型约束和工程化。 - 不适合: 只是简单文件处理,引入 npm 依赖显得过重;要复用大量 Python 数据处理库;不想维护
node_modules、构建步骤和 tsconfig;运行环境不稳定,无法保证 Node 版本和包安装。
Node 的问题不是能力不足,而是容易把一个小脚本写成一个小项目。选 TypeScript 还要额外考虑编译、运行器和依赖管理。
一句话记住三者的分工:
Shell 负责"把命令跑起来",Python 负责"把数据处理对",Node.js/TypeScript 负责"把 Web 和前端生态接顺"。
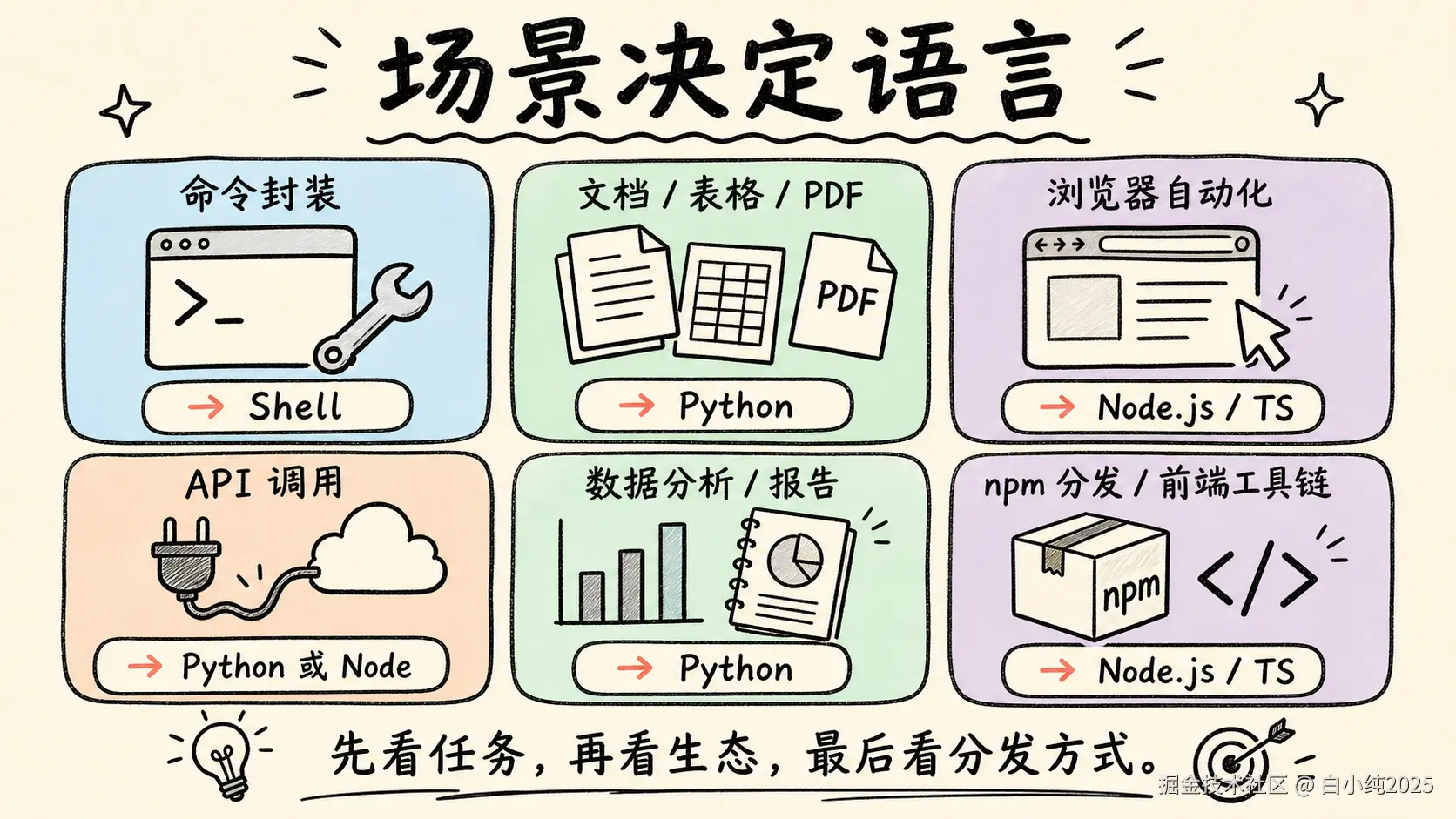
三、使用场景对比:不同 Skill 怎么选?
| 使用场景 | 推荐语言 | 原因 | 不推荐做法 |
|---|---|---|---|
| 简单命令封装 | Shell | 启动快,贴近 CLI,适合做薄入口 | 为几行命令引入完整项目 |
| 多工具串联 | Shell + Python/Node | Shell 调度,核心逻辑交给更稳的语言 | 在 Shell 里写大量解析和分支 |
| JSON/YAML/CSV 处理 | Python | 标准库和数据处理库成熟,错误处理清晰 | 用 sed/awk 硬切结构化数据 |
| Markdown/HTML 转换 | Node.js 或 Python | Node 有 unified/remark,Python 适合轻量解析和模板 | 用正则大规模改 HTML |
| Word/Excel/PDF 处理 | Python | python-docx、openpyxl、pypdf、pdfplumber 成熟 |
Shell 拼命令处理复杂文档结构 |
| 图片压缩和格式转换 | Python 或 Node.js | Python 用 Pillow,Node 用 sharp;看团队生态 | Shell 调多个工具却缺错误兜底 |
| 浏览器自动化和截图验证 | Node.js/TypeScript | Playwright 在 Node 生态体验完整 | 用 Shell 调浏览器解析脆弱输出 |
| 调用大模型或外部 API | Python 或 Node.js | 看官方 SDK、团队栈和部署方式 | 用 curl 写复杂重试、鉴权和分页 |
| 前端项目检查和修复 | Node.js/TypeScript | 直接复用项目依赖和 npm scripts | Python 绕远路调前端工具链 |
| 数据分析和批量报告 | Python | 数据处理、图表、表格、统计生态更顺 | 用 Node 重造数据分析轮子 |
| 跨平台开发者工具 | Node.js/TypeScript | npm 分发和 npx 入口更自然 |
让 Windows 用户跑依赖 Bash 特性的脚本 |
| 仅 macOS/Linux 内部小工具 | Shell 或 Python | Shell 轻,Python 稳;看复杂度 | 为内部小工具搭复杂工程 |
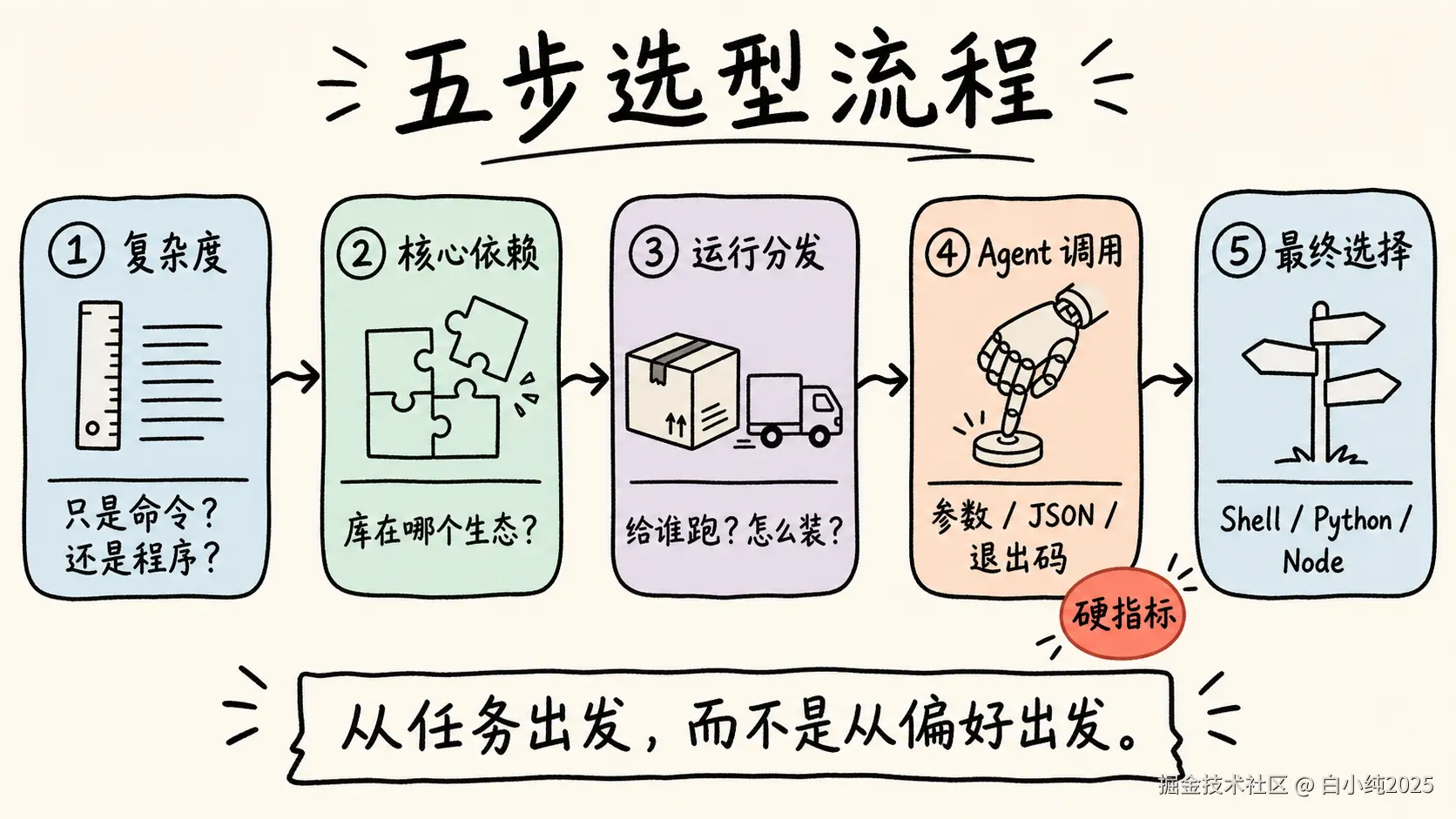
四、决策过程:从任务而不是偏好出发
选型最怕的不是选错,而是先有语言偏好再反向解释需求。更稳的方法是按下面顺序判断。
第一步:判断脚本复杂度。 只调用几个现成命令、逻辑少于 50 行,优先 Shell;要处理结构化数据或有复杂分支,优先 Python 或 Node;预计会持续扩展,从一开始就别写成长 Shell。
第二步:看核心依赖在哪个生态。 选型常常不由语法决定,而由依赖决定。依赖系统命令(ffmpeg、git、pandoc),Shell 做入口可以接受;依赖 openpyxl、python-docx、pdfplumber、Pillow、pandas,选 Python;依赖 Playwright、remark、rehype、Vite、ESLint、sharp,选 Node。不要为了"统一语言"放弃最成熟的库,Skill 脚本最重要的是稳定完成任务,不是语言洁癖。
第三步:看运行和分发方式。 脚本写完还要被 Agent、同事、CI 或其他 Skill 调用。先问:用户机器一定有 Python 或 Node 吗?依赖好装吗?要支持 npx 一键运行吗?要进 Docker、CI 或云函数吗?要跨 macOS/Linux/Windows 吗?一般来说,内部可控环境 Python 或 Shell 成本低,面向前端开发者分发 Node 更自然,面向数据/文档团队 Python 更自然,极轻量工具用 Shell 入口加明确依赖检查即可。
第四步:看 Agent 调用体验。 这一条几乎是 Skill 脚本的硬指标,下一节单独展开。
第五步:用决策表收口。
| 判断问题 | 选择倾向 |
|---|---|
| 只是包装命令、准备环境、移动文件? | Shell |
| 处理文档、表格、PDF、图片、数据? | Python |
| 浏览器自动化、前端工具链、npm 分发? | Node.js/TypeScript |
| 复杂业务逻辑且长期维护? | Python 或 TypeScript |
| 需要强类型和团队工程约束? | TypeScript |
| 需要最少依赖、最短启动路径? | Shell 或 Python 标准库 |
| 已有项目主语言非常明确? | 跟随项目生态 |
五、写给 Agent 的脚本长什么样
无论选哪门语言,给 Agent 用的脚本都要满足同一组约定:支持清晰的命令行参数;成功时输出稳定结果,最好是 JSON;失败时返回非零退出码;错误信息说明原因和修复建议;不要求交互式输入;能用 --help 查看用法;关键中间产物有明确路径。
下面是一个"压缩目录下图片"脚本的 Python 骨架,把这些约定都落到代码上:
python
#!/usr/bin/env python3
"""压缩目录下的图片,输出每个文件的体积对比(JSON)。"""
import argparse
import json
import sys
from pathlib import Path
from PIL import Image
def compress(src: Path, quality: int) -> dict:
before = src.stat().st_size
img = Image.open(src)
img.save(src, optimize=True, quality=quality)
after = src.stat().st_size
return {"file": str(src), "before": before, "after": after}
def main() -> int:
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument("directory", help="待处理的目录")
parser.add_argument("--quality", type=int, default=80, help="JPEG/WebP 质量,默认 80")
args = parser.parse_args()
root = Path(args.directory)
if not root.is_dir():
# 错误写到 stderr,正常结果留给 stdout,Agent 不会把两者混淆。
print(f"目录不存在:{root}", file=sys.stderr)
return 1
results, failed = [], []
for img_path in sorted(root.glob("**/*")):
if img_path.suffix.lower() not in {".png", ".jpg", ".jpeg", ".webp"}:
continue
try:
results.append(compress(img_path, args.quality))
except Exception as exc: # 单个文件失败不拖垮整批。
failed.append({"file": str(img_path), "error": str(exc)})
# 结构化输出:Agent 直接解析,不靠读日志猜状态。
json.dump({"compressed": results, "failed": failed}, sys.stdout, ensure_ascii=False)
return 0 if not failed else 2 # 用退出码区分"全成功"和"部分失败"。
if __name__ == "__main__":
sys.exit(main())关键点不在 Pillow,而在那几处约定:argparse 自带 --help;正常结果走 stdout,错误走 stderr;退出码区分成功、参数错误和部分失败;单文件异常被收集而不是中断全程。Node.js 版本同理:用 process.argv 或 commander 解析参数,console.log 输出 JSON,process.exit(code) 返回状态。
如果某门语言让这些约定很难满足,那它就不适合这个脚本。
六、依赖与运行:让脚本在别人机器上也能跑起来
脚本能在作者机器上跑,不代表能在 Agent、CI 或同事的机器上跑。依赖怎么声明、怎么安装,直接决定 Skill 的可移植性。
Python:把依赖钉死,别裸用全局环境。 推荐用 uv,它能快速创建隔离环境并锁定版本,Agent 调用前不必关心机器上装了什么。依赖可以声明在脚本头部:
python
# /// script
# dependencies = ["pillow>=10,<11"]
# ///然后用 uv run 执行:
bash
uv run compress.py ./imgs --quality 75如果不用 uv,至少提供一个钉了版本的 requirements.txt(用 pillow>=10,<11 这样的范围,而不是裸 pillow),并在入口脚本里检查依赖是否就位。面向终端用户分发命令行工具时,pipx install 比 pip install 更安全,它会把工具装进独立环境,不污染系统 Python。
Node.js:优先 npx 让用户免安装。 发布成 npm 包后,Agent 和用户都能一行运行,不必先 npm install:
bash
npx your-skill-cli verify --url http://localhost:5173本地开发则用 package.json 锁定依赖,并用 npm ci(而非 npm install)在 CI 里按 package-lock.json 精确还原。.mjs 后缀可以省掉一部分 ESM/CJS 配置纠结。
Shell 入口:先检查,再执行。 Shell 脚本最常见的崩溃来源是"假设某个命令存在"。薄入口应该先验证依赖和参数,再调主程序:
bash
#!/usr/bin/env bash
set -euo pipefail # 出错即停、未定义变量即报错、管道错误不吞掉。
command -v ffmpeg >/dev/null || { echo "缺少 ffmpeg" >&2; exit 127; }
[ $# -ge 1 ] || { echo "用法:run.sh <输入文件>" >&2; exit 2; }
exec python3 "$(dirname "$0")/process.py" "$@"set -euo pipefail 是 Shell 入口脚本的标配,它把"静默出错继续跑"这个最危险的默认行为关掉了。
跨平台是另一条隐线:依赖 Bash 特性(数组、[[ ]]、set -o pipefail)的脚本不要指望 Windows 用户能跑。需要真正跨平台时,选 Node 或 Python,而不是给 Shell 打补丁。
七、典型决策案例
把前面的判断套到几个常见 Skill 上:
- 公众号文章发布 → Python。 涉及读 Markdown/HTML、上传图片、调用 API 创建草稿、区分 token/图片/格式/接口错误。文件、HTTP 和错误处理密集,后续还会扩展成批量发布和素材复用。Shell 可做入口检查环境变量,但核心逻辑不该写在 Shell 里。
- 前端页面截图验证 → Node.js/TypeScript。 启动 dev server、打开页面、截图、检查 canvas、验证移动端和桌面端布局。Playwright 和前端项目同生态,能复用 npm scripts、Vite、Next.js,DOM/CSS/截图处理更直接。Python 也能跑 Playwright,但项目已是前端工程时 Node 更顺。
- 图片压缩 → Python 或 Node.js。 熟 Python 用 Pillow,追求性能和 Web 图片处理用 Node 的 sharp。Shell 可做遍历,但一旦要汇总报告和错误统计,Python/Node 更稳(参见第五节骨架)。
- 下载 URL 转 Markdown → Node.js 或 Python。 依赖浏览器渲染、DOM 清理、Readability、HTML 到 Markdown 工具链时选 Node;主要是请求、解析和文本清洗时 Python 也够。不要用 Shell 加正则处理 HTML,HTML 不是普通字符串,越处理越碎。
- 项目初始化 → Shell 或 Node.js。 建目录、复制模板、装依赖、初始化 git、打印下一步。仅面向内部 macOS/Linux,Shell 最简单;要公开跨平台分发,Node 更适合做 CLI 并用 npm 管版本。
八、推荐的组合模式
实际项目里不必强行单语言。更健康的结构是按职责分层:
text
skill/
├── SKILL.md
├── scripts/
│ ├── run.sh # 薄入口:检查参数、设置环境、调主脚本
│ ├── publish.py # 核心逻辑:文档、图片、API、错误处理
│ └── verify.mjs # 需要浏览器或前端生态时用 Node
└── templates/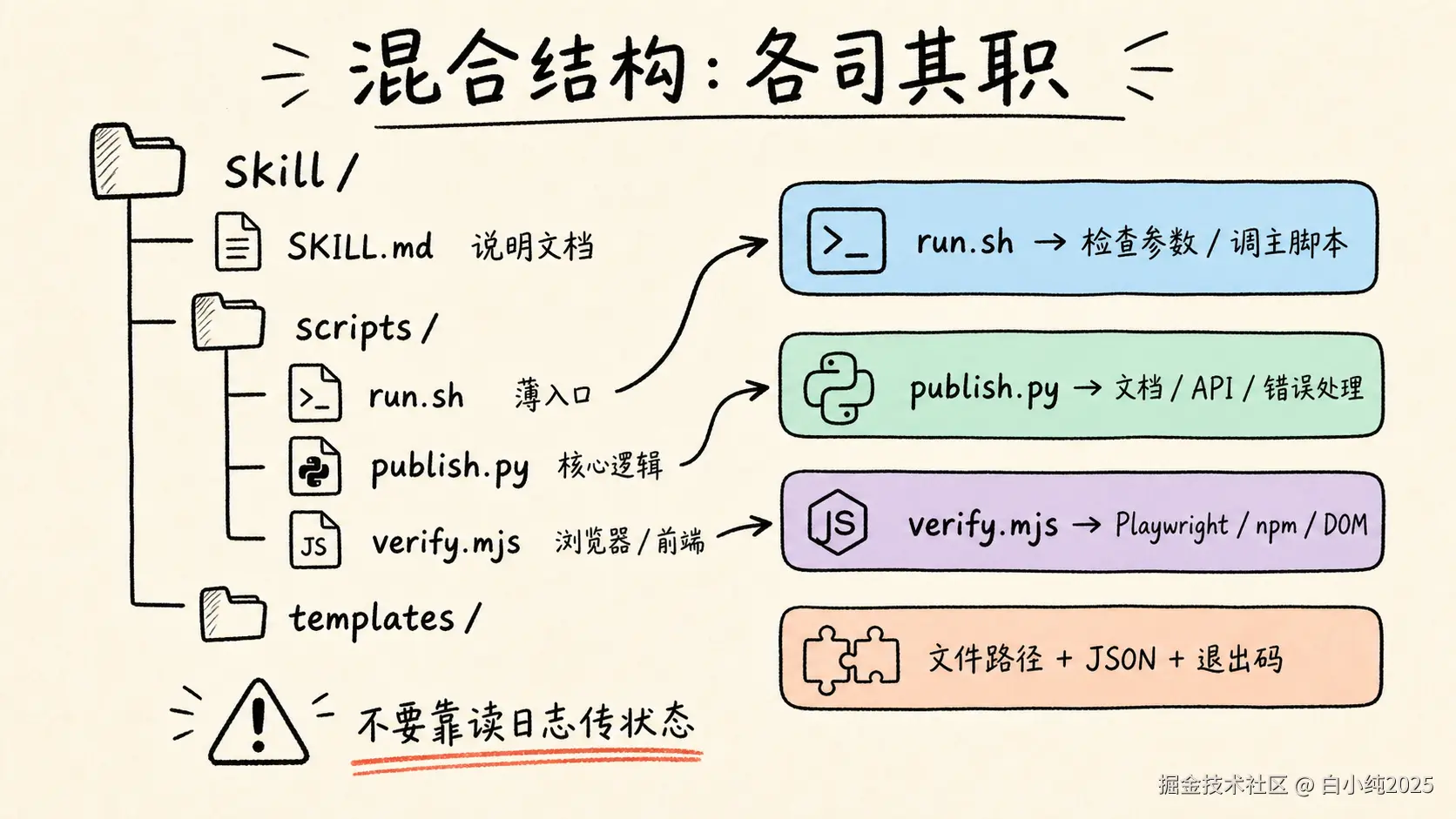
混合结构的关键是边界清楚:Shell 不写复杂业务逻辑,Python/Node 不重复做系统命令编排;每个脚本都有独立 --help;脚本之间通过文件路径、JSON 或明确参数通信,不靠"读某段日志文本"传递关键状态。
九、给团队的默认规则
为了减少每次争论,可以把上面的判断固化成一套默认规则:
- 复杂脚本默认用 Python。 文件解析、数据转换、API 调用、批处理、报告生成,优先 Python。
- 薄入口默认用 Shell。 只做环境检查、命令编排、调主脚本,不堆业务逻辑;开头加
set -euo pipefail。 - Web/前端/浏览器自动化用 Node.js/TypeScript。 Playwright、前端构建、Markdown/HTML AST、npm 分发优先 Node。
- 超过 100 行的 Shell 必须重新评估。 不是硬上限,但通常说明它已从"胶水"变成"程序"。
- Agent 调用体验优先于个人偏好。 参数、日志、退出码、结构化输出和可复现性,比语言喜好重要。
- 跟随核心依赖,而不是流行度。 哪个生态有最成熟、坑最少的库,就选哪个。
归根到底,成熟的选型不是押注某一门语言,而是让每个脚本都站在最适合的位置上:入口轻、核心稳、依赖顺、输出清楚。 这样 Agent 调用起来稳定,人维护起来也不累。