"咱们做个 AI 知识库吧。"
团队里只要有人提这么一句,接下来的动作几乎是条件反射:搭一个向量数据库,把文档切成小块,灌进去,让 AI 按相似度去捞。
好像不上向量,就不算"做了 AI"。
可你的资料其实就那么几类,结构清清楚楚。一套向量库搭下来,检索效果还经常不如直接翻目录。
钱花了,活没干漂亮,问题到底出在哪?
出在第一步就想错了。AI 要帮你干活,前提是先从你成百上千个文档里,找到那几条真正有用的。这件事有个词,叫 RAG。
而十有八九,你一听到 RAG,脑子里立刻蹦出来的就是那个词------向量数据库。
这恰恰是要掰扯的第一个误区。
RAG 的关键,从来不是向量。是你能不能把对的内容捞出来。
一、一提 RAG 就想到向量库,你已经把手段当目的了
为什么大家会有这种条件反射?
因为现在但凡讲 RAG 的教程、文章、开源项目,几乎都是同一套动作:文档切块、灌进向量库、按相似度召回。看多了,所有人脑子里就刻下一个等式------RAG=向量库。
可这个等式从一开始就是错的。
向量只是 RAG 的一种实现手段,不是 RAG 本身。把"用了向量"当成"做对了 RAG",就像把"买了跑鞋"当成"已经在跑步"------工具到位了,正事一步没动。
更麻烦的是,这种错位会让你彻底忽略真正该想的问题:RAG 到底要解决什么?只有想清楚这个,你才知道向量该不该上、什么时候上。
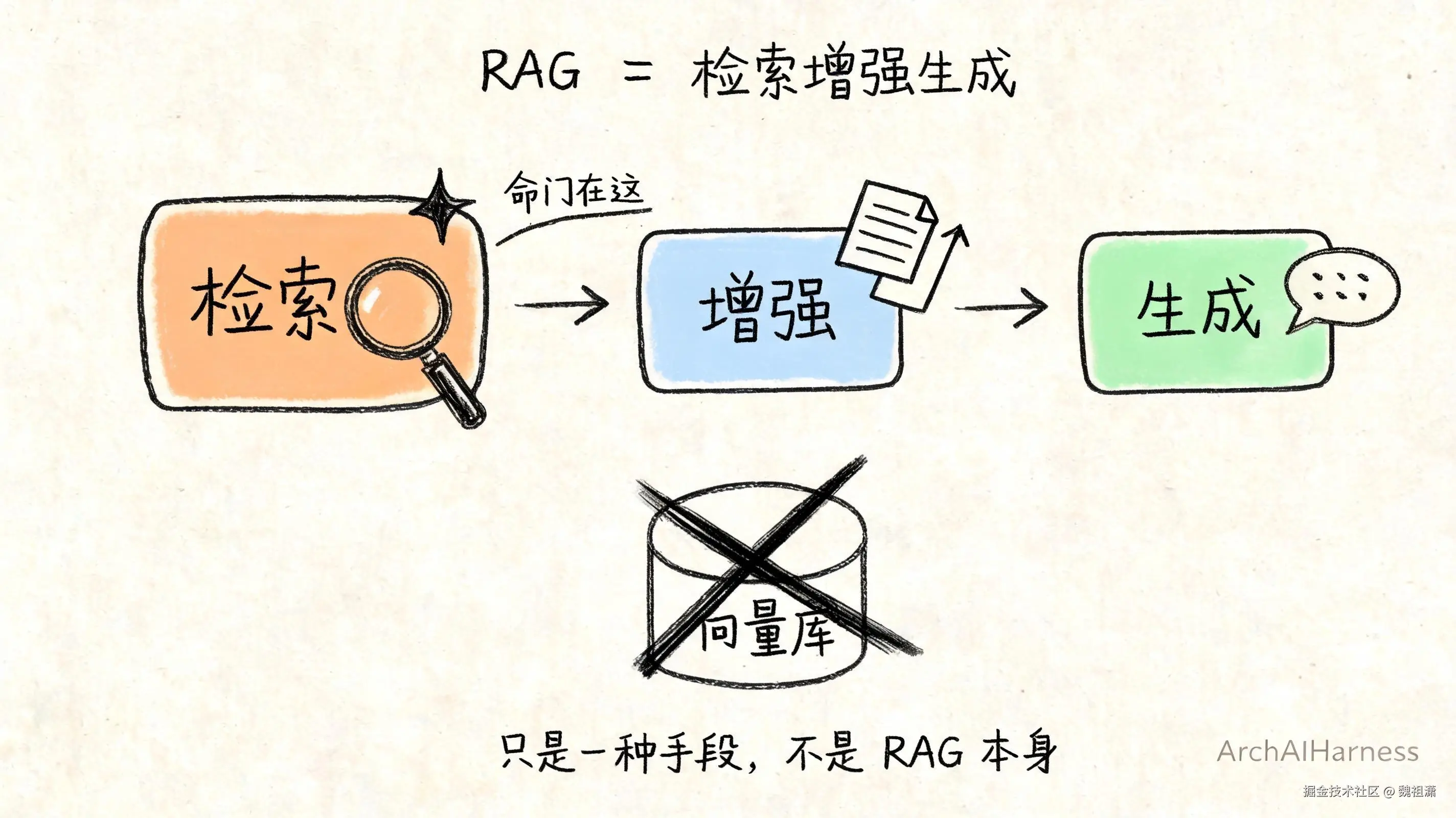
二、RAG 的内核:检索增强生成,命门在"检索到对的"
先回到这三个字母本身。
RAG,全称是检索增强生成(Retrieval-Augmented Generation)。拆开看就三步:先检索 ,把相关资料找出来;再用这些资料增强 模型的输入;最后让模型生成回答。
很多人盯着"生成",觉得 AI 聪不聪明决定了一切。也有很多人盯着用什么库、什么模型。
但真正的命门,是中间那个动作------检索。
更准确地说,是"能不能检索到对的内容"。
这话听起来像废话,其实不是。你想想:模型本身并不知道你的资料。它能回答好你的问题,靠的不是它有多懂你,而是你在它回答之前,把对的那几条资料喂到了它嘴边。
你喂对了,再普通的模型也能答得像模像样。
你喂错了------或者喂了一大堆里面只有一两条有用------再强的模型也救不回来。它只会从一堆杂音里挑出几句看着像答案的话,然后一本正经地说错。
所以 RAG 好不好用,不取决于你用了哪种技术范式,而取决于一件事:你能不能稳定地、可靠地把 AI 这一步真正需要的那条内容捞出来。
三、什么叫"检索到对的内容"?厨子要的是一根葱
打个比方。
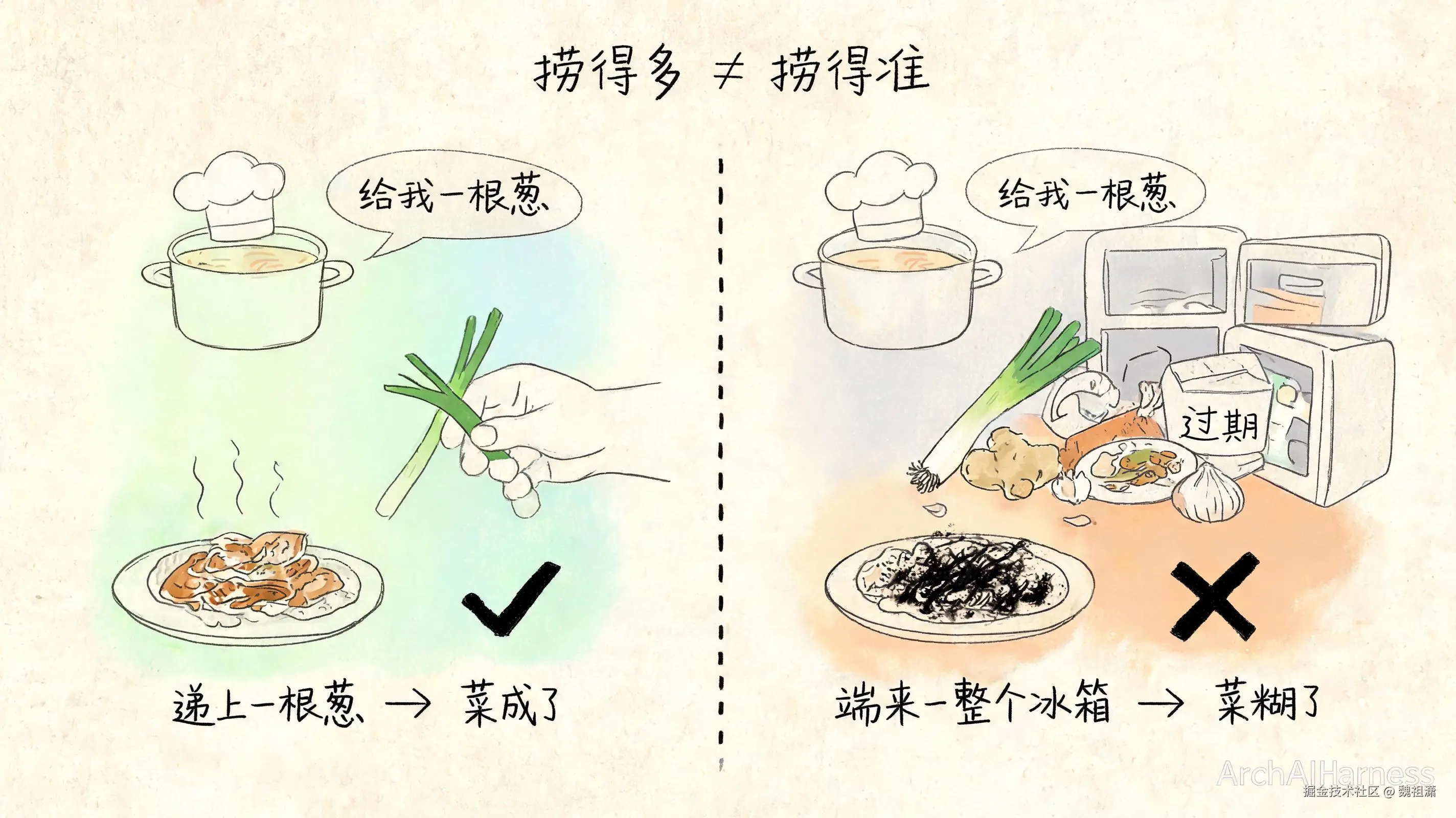
把 AI 想象成一个厨子。它手艺不错,但它的冰箱是空的------它不知道你家有什么菜。每做一道菜,它都得让你去拿料。
它说:"给我一根葱。"
你递上一根葱。它三两下,菜就成了。
这叫检索到对的内容。
但换个场景。它还是说:"给我一根葱。"你怕拿少了不够用,干脆把整个冰箱搬到它面前------葱、姜、蒜、昨天的剩菜、过期的酸奶,全堆在案板上。
你觉得自己很负责,料给得足足的。可厨子傻眼了:它得先从这一堆里翻出那根葱,翻的过程中还可能顺手抓错,把香菜当成葱扔进锅里。
这道菜,大概率糊。
这就是检索最反直觉的一点:捞上来的不是越多越好,是越准越好。
很多知识库不好用,不是因为资料太少,恰恰是因为每次检索都捞回来一大堆"看着相关、其实没用"的东西。AI 被这些杂音淹没,反而抓不住重点。
你给它的不是一根葱,是一整个冰箱。
记住这个画面。后面讲向量、讲目录,都用这把尺子来量:你这套方法,到底是稳定地递上一根葱,还是经常端来一整个冰箱?
四、大多数场景:一个好目录,就能稳定递上那根葱
那怎么才能稳定地递上一根葱?
答案可能让你意外:对绝大多数人、绝大多数场景来说,不需要向量,按业务维度建一个好目录就够了。
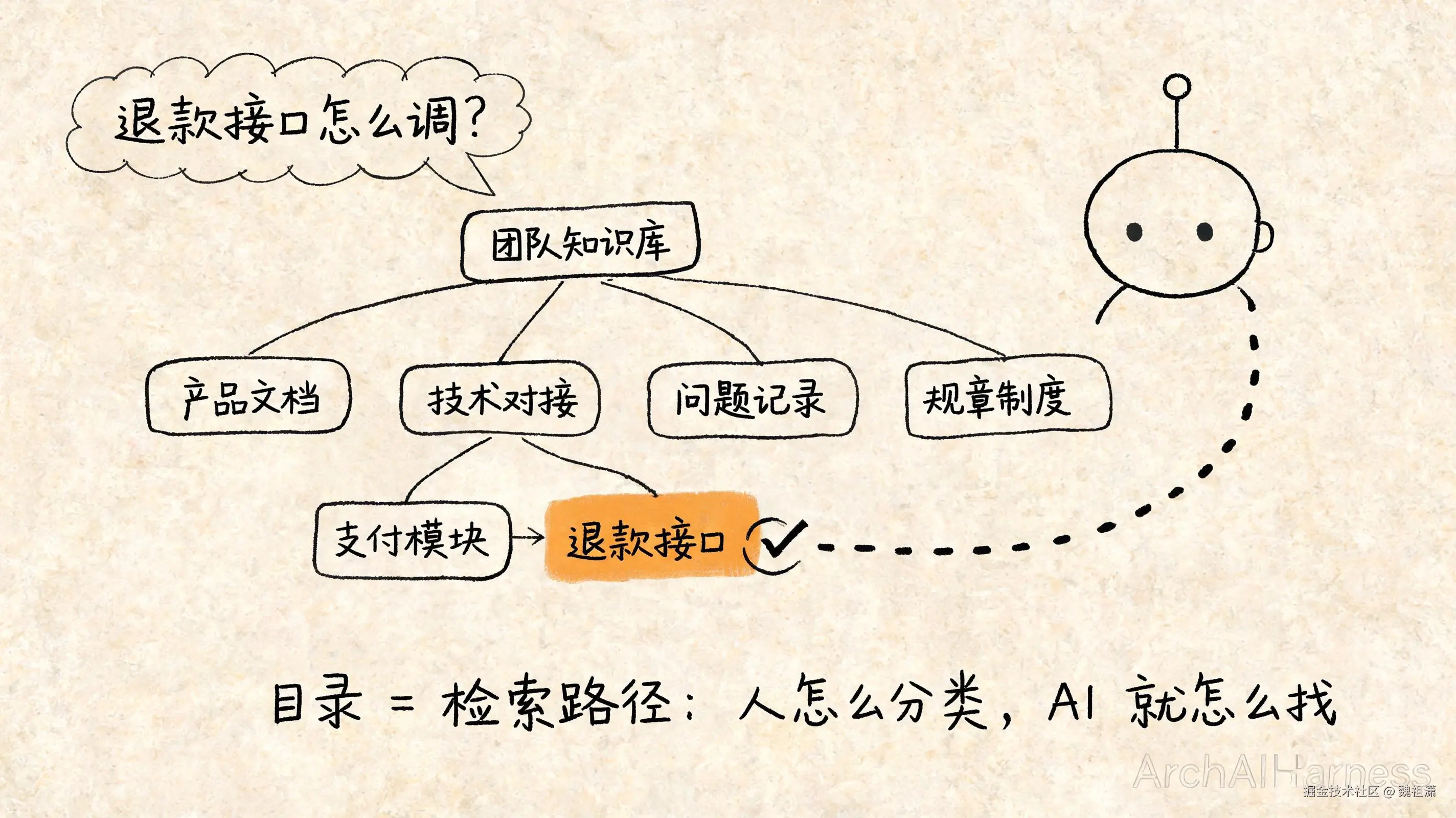
举个具体的例子。假设你要给一个团队整理知识库,里面有产品文档、技术方案、对接接口说明、历史问题记录、规章制度。
一种做法,是把所有文档切成小块,全灌进向量库。用户问"退款接口怎么调",系统去算哪些文本块跟这句话"语义接近"。它可能捞回来退款接口文档,也可能捞回来一篇讲"退款政策"的制度文件------因为这两个在"语义"上都挺接近。准不准,全看运气和调参。
另一种做法,是先想清楚一件事:这些资料,人是怎么分类的?
产品文档归产品,接口说明归技术对接,问题记录按模块归档。建一套这样的目录,就像图书馆的分类号。用户问"退款接口怎么调",顺着目录定位到"技术对接 → 支付模块 → 退款接口",直接翻到那一篇。
哪种更可能递上那根葱?
显然是后一种。因为目录这件事的本质,不是"存资料",而是把人对业务的理解,变成了一条条检索路径。
你按业务维度分好的每一个类目,其实就是一条检索逻辑。AI 不用去"猜"哪段文字语义接近,它顺着你定义好的结构,一层层走到正确的位置。
五、光有目录还不够,得先给 AI 一张地图
但这里藏着一个很多人会踩的坑。
目录建好了,文件夹分得清清楚楚,AI 就能用了吗?
不能。
你把它直接丢进这堆文件夹里,它跟一个第一天来的新人没两样------面前一排柜子,不知道哪个抽屉装什么,只能一个个拉开翻。要么翻半天,要么干脆翻错柜子。
它缺的,是一张地图。
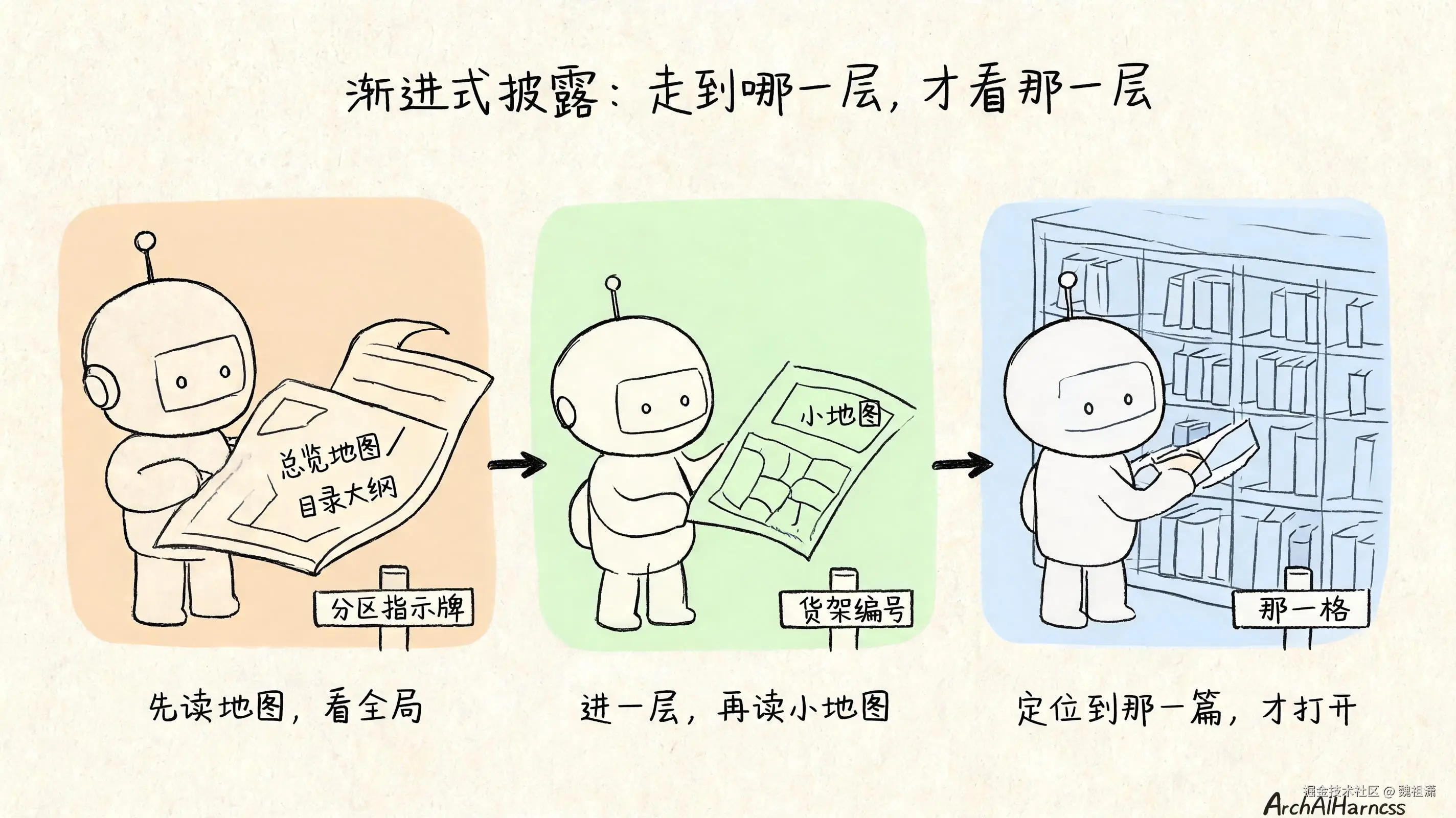
所以结构化检索真正的关键一步,是在目录之外,单独写一份描述这套目录长什么样的文档------有哪几个大类、每一类装的是什么、大概放在哪。说白了,就是给整个知识库画一张大纲,一张目录的目录。
AI 来找东西,不是一头扎进文件夹乱翻,而是先读这张地图:看懂全局,判断这次任务该往哪一类走,再钻进去。
而且这张地图可以分层。大类下面如果还很复杂,那一类里再放一份更细的小地图,描述它内部的结构。AI 顺着大地图找到方向,进了某一类,再读那一类的小地图,接着往下,直到精确定位到要的那一篇------才把完整内容调出来看。
这套"先看地图、再逐层深入"的机制,有个名字,叫 渐进式披露:不一次把所有资料都摊给 AI,而是它走到哪一层,才披露那一层的信息。
它和你在图书馆找书的过程一模一样:先看大厅的分区指示牌,走到对应区域再看货架编号,最后才走到那一格、抽出那本书。没人会把全馆的书都搬到面前再挑。
这么做的好处有两个。
一个是准。AI 每一步只看当前这层必要的信息,不会被几百份无关文档淹没------还是那句话,递一根葱,不是端一冰箱。
另一个是稳。整个过程可追溯:它走到哪一层、为什么进这个类目,你都看得见,错了也知道错在哪一步。
六、这套"土办法",凭什么比向量靠谱?
可能有人会说:目录加大纲,听着这么"土",怎么会比向量库还好?
恰恰是这个"土",藏着三样向量给不了的东西。
它能解释。 AI 找到一条内容,你能清楚地知道它为什么是这一条------因为它就在"支付模块"这个类目下,地图怎么指、它怎么走,一步步都看得见。换成向量,捞回来一段文字,你问它为什么是这段,得到的答案是"因为它的向量距离最近"。这话没法跟人解释,也没法审计。
它能改。 发现某类问题 AI 老找错地方,你直接去调目录、改大纲、把那篇文档挪到正确的类目下就行,改完立刻见效。向量库里,你想精准干预"这个问题应该优先匹配这篇",非常别扭,往往得重新切片、重新灌库,折腾半天还不一定准。
它跟着业务长。 业务怎么分模块、怎么划边界,目录和大纲就怎么写。业务变了,跟着改一行就行,检索逻辑永远和真实业务对齐。向量不一样,它脱离业务语义------只懂文字像不像,不懂你这家公司的业务边界到底在哪。
所以这真不是"土不土"的问题。可解释、可修改、可审计,恰恰是一套严肃系统最离不开的东西。
它递上来的是一根葱,而且你知道它为什么递的是葱。
说到底,整套方法就闭环了:人按业务把目录和大纲定义清楚(秩序),AI 顺着地图一层层检索(在秩序里找资料),每一步都能解释为什么是这一条(可审计)。 这正是"人定义秩序,AI 在秩序里生长,体系负责验证"在检索这件事上的样子。这种"结构化检索 + 渐进式披露"的协作方式,也沉淀在了开源的 agent-workflows 里,配合 framework 的工程底座,你可以直接拿去用。
七、那向量什么时候才该上?
讲到这,得说句公道话:向量不是没用,它是被滥用了。
向量真正该上场的,是这么一种场景------海量、模糊、说不清类目。
什么意思?
比如一个面向全网的搜索产品,文档量是千万级、上亿级,内容五花八门,你根本没法、也来不及给它建一套清晰的人工目录和大纲。用户的提问又特别口语化、特别模糊,"那个能把照片变清楚的工具叫啥",这种问题没有现成的类目能对上。
这时候,向量的"按语义模糊匹配"才真正发挥价值------它不需要精确路径,能在一片混沌里捞回来一批大致相关的候选。
注意,这是一种用模糊换覆盖的取舍:你放弃了精确和可解释,换来了在海量、无结构数据里"还能找到点东西"的能力。
只有当你的场景确实到了"人工目录维护不过来"的规模,这笔交易才划算。
而且更进一步------就算到了这种规模,向量也不该是你每个项目自己手搓一套。
它最好的形态,是被封装成一个 MCP,对外提供接入。
这里得提一个东西,叫 MCP------你可以把它理解成一种标准化的能力接口。海量向量检索这种又重、又专业、又吃资源的能力,最合理的方式是由专门的平台做好,封装成一个标准接口,谁需要谁接进来调用,而不是每个做知识库的团队,都从头搭一套向量库、自己切片、自己调参、自己维护。
说到底,给做产品的人一句实在话:先老老实实把结构化目录和大纲维护好。只有当数据真的到了平台级海量、又没法结构化的程度,才考虑向量,而且优先接别人封装好的 MCP,别自己造轮子。
八、写在最后
回到开头那个问题:你的资料那么多,AI 怎么才能找到需要的信息?
答案不是"上一个向量库"。
答案是:先把"怎么才能检索到对的内容"这件事想清楚,再选技术。想清楚了,一个好目录就够;想不清楚,再贵的向量库也只是换了个姿势端冰箱。
RAG 的内核从来不是向量,是检索;检索的命门也不是"找得多",是"找得准"。技术只是手段,能不能稳定递上那根葱,才是真问题。
未来真正会用 AI 的人,不一定是懂多少检索算法的人,而是能先想清楚"AI 这一步到底需要哪条内容"、再把资料组织成它够得着的样子的人。
下一篇聊个新问题:一个 AI 能干的活终究有限,当任务复杂到它一个人忙不过来,怎么把活拆给一个"AI 团队"------多个 Agent 怎么分工、怎么交接、谁来兜底?这事儿,比你想的更像管理一个真实的团队。
关于 ArchAIHarness
这篇文章是「看懂 AI 与智能体」专栏的一部分,由 ArchAIHarness 持续输出。
ArchAIHarness 是一套面向 AI 时代软件工程的人机协同架构哲学与公开工程资产,主张:
架构师定义秩序,AI 在秩序中生长。人立法,AI 执行,体系审计。
如果你也希望 AI 在明确的架构边界内协作,而不是在混沌中碰运气,欢迎到 GitHub 上看看我们在做什么:
- 组织主页 :github.com/ArchAIHarne... --- 了解完整理念与资产全景
- 本专栏 :
zhuanlan-ai-and-agents--- 所有文章的源码与发布记录 - 实践指南 :
docs--- 架构哲学、工程方法和落地指南 - 开源工具 :
agent-workflows--- 可复用的 AI 协作 Agents、Skills 与 Tools - 工程样例 :
framework--- DDD + AI 协作的工程底座,展示如何在开发中融合 AI
Engineered by Architects · Empowered by AI · Audited by Discipline