作者:光粒
开篇:桌面端的"监控盲区"
你的 Electron 应用上线了。用户在用,业务在跑,一切看起来挺好------直到某天,客服转来一条用户反馈:"应用突然闪退了,什么都没保存。"
你打开日志,发现主进程一片静默。渲染进程的 window.onerror 倒是配了,但那些数据分散在各个窗口的网络请求里,根本拼不出完整的故障链路。更棘手的是,原生崩溃留下的 .dmp 文件,需要专门的符号服务才能解析,而你甚至还没想好把崩溃数据往哪儿传。
这不是个例,VS Code、1Code、OpenCode、Cherry Studio------这些日活千万的桌面应用,都构建在 Electron 之上。但当我们谈论可观测性时,目光往往聚焦在服务端和浏览器端,桌面端几乎是一片监控盲区。
这篇文章要解决的就是这个问题:如何用一套 SDK,让 Electron 应用从"黑盒"变成"全链路可观测",让桌面 Agent 监控真正触手可及。
Electron 监控为什么难?
在聊方案之前,先理解问题的本质。Electron 的监控挑战,根植于它独特的双进程架构:
第一层难:主进程和渲染进程是两个世界。 主进程跑在 Node.js 上,负责原生 API、系统交互、进程管理;渲染进程跑在 Chromium 上,承载 UI 和业务逻辑。两者通过 IPC(进程间通信)桥接,但在监控视角下,它们是两套独立的运行时环境------异常类型不同、性能指标不同、数据采集方式也不同。传统的前端 RUM SDK 只能覆盖渲染进程,主进程的监控完全缺失。
第二层难:原生崩溃是个"黑盒"。 Electron 应用可能因为 V8 引擎 bug、Native 模块异常、系统资源耗尽等原因发生原生崩溃,留下一个二进制的 .dmp 转储文件。解析它需要 minidump 解析器和符号表服务,这对大多数前端团队来说是完全陌生的领域。
第三层难:数据上报路径不可靠。 渲染进程的网络请求可能因为页面销毁、窗口关闭而中断。如果每个窗口各自上报数据,不仅浪费资源,还容易丢失关键事件------尤其是在崩溃发生的瞬间。
第四层难:IPC 通信缺乏可观测性。 越来越多的 Electron 应用采用 tRPC 等框架实现主进程与渲染进程间的类型安全通信,但这类 IPC 调用的性能、错误和链路追踪,几乎没有现成的监控方案。
这些痛点叠加在一起,让 Electron 监控成了一个"大家都知道该做,但没人愿意先踩坑"的领域。
破局思路:一次init(),全端可观测
我们的解法是 @arms/rum-electron------阿里云云监控 ** **1 的 Electron SDK。核心设计理念可以用一句话概括:主进程一行 init() 调用,自动覆盖主进程与所有渲染进程的全方位监控。
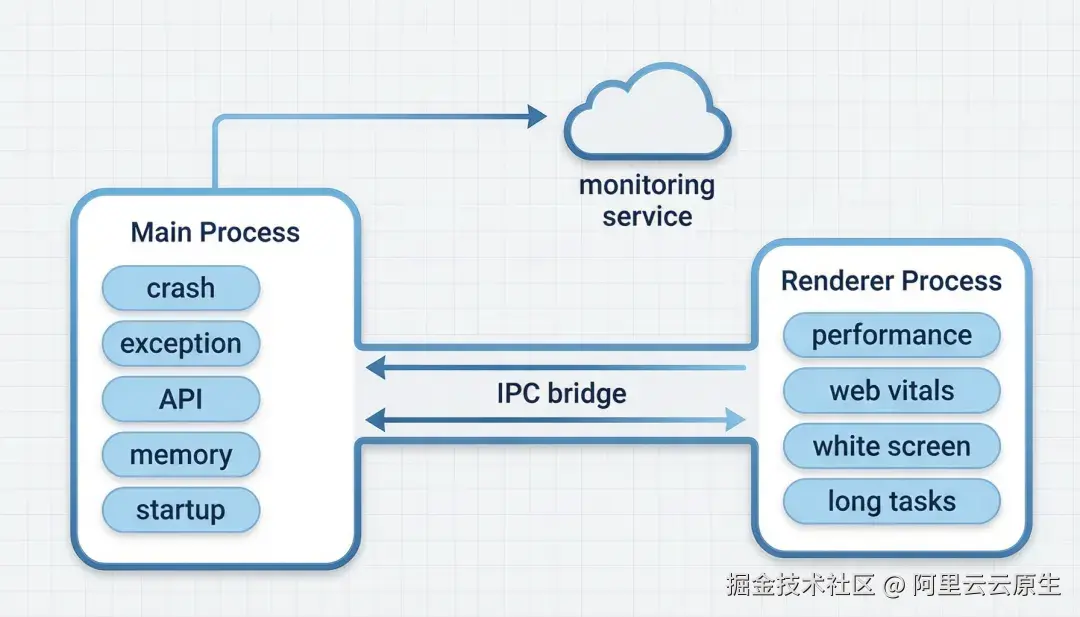
SDK 双进程架构:主进程为数据汇聚中心,渲染进程事件经 IPC Bridge 回流,由主进程统一上报
这套架构的关键设计决策有三个:
主进程作为数据汇聚中心。 所有事件------无论来自主进程自身还是渲染进程------最终都汇聚到主进程,由 ElectronReporter 统一上报。渲染进程的 Browser SDK 不发起任何网络请求,事件通过 arms:rum-bridge IPC 通道回流到主进程。这确保了在窗口关闭、页面崩溃等极端场景下,数据仍然不会丢失。
渲染进程零配置自动注入。 SDK 监听 Electron 的 web-contents-created 事件,在每个 BrowserWindow 的 dom-ready 时机自动注入 Browser SDK 脚本和 IPC Bridge。开发者不需要改 preload、不需要在渲染进程 import SDK、不需要手动配置任何东西。
三阶段构建,单包分发。 Preload 脚本、Browser SDK、WASM 崩溃解析引擎在构建时全部内嵌到主包中。用户 npm install @arms/rum-electron 后即可直接使用,没有额外的文件下载或配置步骤。
六大核心能力,逐个击破监控盲区
能力一:零配置自动注入------开箱即用
这可能是你最关心的部分。接入代码就这些:
csharp
// main/index.ts ------ 文件顶部
import armsRum from '@arms/rum-electron';
armsRum.init({
endpoint: '<your-endpoint>',
});没有第二步了。主进程 init() 之后,所有 BrowserWindow 自动获得完整的渲染进程监控能力------PV、性能、Web Vitals、白屏检测、API 请求、长任务、用户交互,一个不落。
SDK 自动适配 contextIsolation 安全策略:开启时用 contextBridge.exposeInMainWorld() 安全暴露 IPC 通道,关闭时直接挂载到 window 对象。使用自定义 partition 的场景,也只需在 init 时多传一个 partition 字段。
能力二:Rust WASM 驱动的本地崩溃解析
当 Electron 应用发生原生崩溃时,系统会生成一个 .dmp 转储文件。传统方案(比如 Sentry)会将这个文件上传到服务端进行符号解析。我们的做法不同------把解析引擎搬到了客户端本地。
具体来说,我们基于 Rust 的 rust-minidump 系列库,通过 wasm-pack 编译为 WebAssembly,在应用重启后直接在本地完成崩溃堆栈回溯和模块解析。WASM 引擎以 Base64 编码内嵌在 JS 模块中(约 1.5MB),不需要额外的文件分发,不需要服务端符号服务,崩溃原始数据不出端。
解析结果包括:崩溃线程识别、所有线程的完整堆栈(模块名、指令地址、偏移量、帧可信度)、加载模块列表(基地址、大小、调试标识符)、系统信息等。这意味着你的安全合规团队可以松一口气------敏感的崩溃堆栈数据完全在本地处理。
能力三:tRPC---IPC 监控不再是盲区
越来越多的 Electron 应用采用 electron-trpc 实现进程间类型安全通信。但在监控层面,tRPC procedure 调用的性能、错误和链路追踪一直是个盲区。
@arms/rum-electron 通过 instrumentTRPC() 轻松解决这个问题:
javascript
import { initTRPC } from '@trpc/server';
import armsRum from '@arms/rum-electron';
// 包一层 t,所有 procedure 自动带监控
const t = armsRum.instrumentTRPC(initTRPC.create());
export const appRouter = t.router({
greeting: t.procedure.input(...).query(...), // 自动监控
chat: t.procedure.input(...).mutation(...), // 自动监控
});底层使用 JavaScript Proxy 拦截 t.procedure 的属性访问,在运行时自动注入监控 middleware。业务侧的 procedure 定义完全不需要修改 ,已有的链式 middleware(如 auth)也不受影响。采集到的数据对齐 OpenTelemetry RPC 语义约定(rpc.system = 'trpc'),与后端 APM 无缝联动。
这是目前市面上唯一原生支持 tRPC server 端监控的 Electron SDK。
能力四:链路追踪
Electron 应用不是孤岛------它需要调用后端 API、访问 AI 推理服务、请求第三方接口。要把客户端到后端的完整调用链串联起来,需要分布式链路追踪。
SDK 支持 W3C Trace Context、B3、B3 Multi、Jaeger、SkyWalking 五种传播协议,主进程的 fetch 请求和 tRPC procedure 共用同一份追踪决策。你可以按域名精细化控制采样策略:
php
armsRum.init({
endpoint: '<your-endpoint>',
tracing: {
enable: true,
sample: 10, // 全局 10% 采样
propagatorTypes: ['tracecontext', 'b3'], // 可选: 'b3multi' | 'jaeger' | 'sw8'
allowedUrls: [
{ match: /^https:\/\/api\.example\.com/, sample: 100 }, // 核心 API 100%
/^https:\/\/cdn\.example\.com/, // CDN 10%(用全局)
],
},
});追踪头自动注入 outbound 请求,业务代码完全无感。这意味着,当一个用户反馈"AI 回复太慢了"时,你可以从 Electron 客户端的 tRPC 调用一路追到后端的大模型推理服务,精准定位慢在哪个环节。
下面是一个完整的从前端 -> Agent -> MaaS 的完整链路。
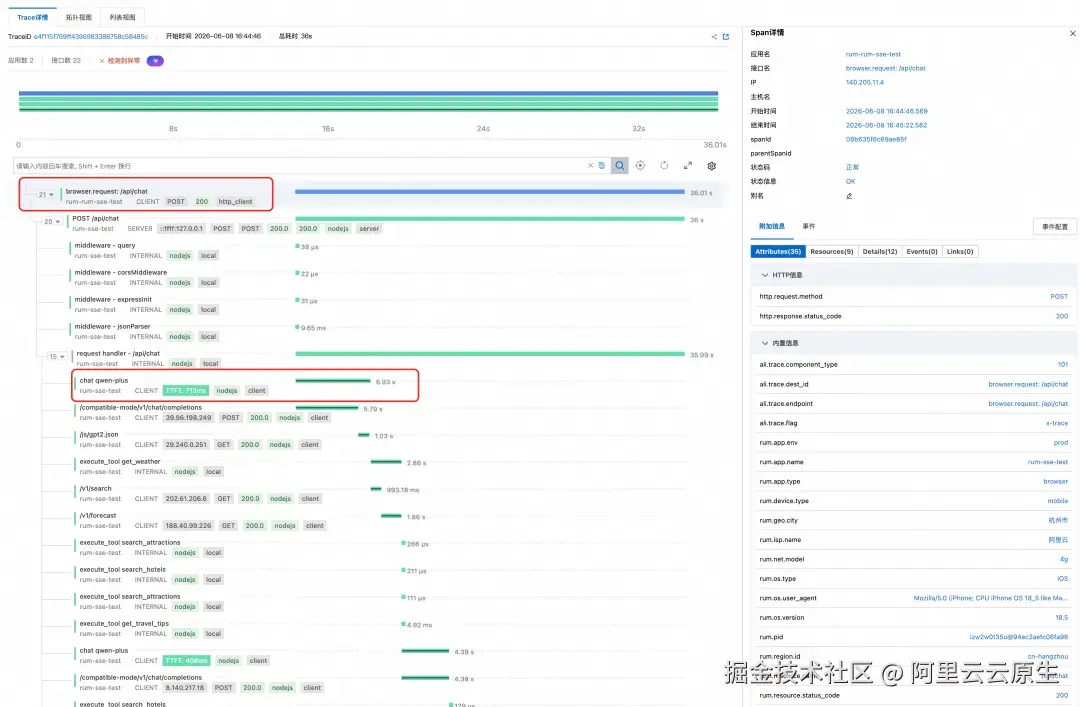
需要前后端同时完成接入链路追踪。
能力五:创新内存聚合窗口------内存泄漏的哨兵
Electron 桌面应用往往长时间运行(IDE、设计工具、IM 客户端),内存泄漏是悬在每个团队头上的达摩克利斯之剑。
我们设计了一套 "高频后台采样 + 低频窗口聚合上报 + 事件触发兜底" 的内存监控方案:
- 每 10 秒 同步采样一次
app.getAppMetrics(),累加到内存中的累加器,CPU 开销 < 0.1%。 - 每 30 分钟 输出两条事件:
memory_max(峰值)和memory_avg(均值),每小时仅约 5 条事件。 - 崩溃或退出时立即 flush 当前内存现场------OOM 分析有据可查。
- 跨窗口均值轨迹追踪 baseline 漂移,提前发现内存泄漏趋势。
这套方案的精妙之处在于:它以极低的开销(每小时 5 条事件、< 0.1% CPU),提供了足够细粒度的内存画像。当你发现某个版本的 memory_avg 逐窗口攀升时,大概率就是内存泄漏的信号。
能力六:全方位异常防护网
主进程层面,SDK 构建了三层异常防护网:uncaughtException 捕获未处理异常、unhandledRejection 拦截 Promise 拒绝、console.error 非侵入式拦截。三层兜底确保主进程错误零遗漏。
渲染进程层面,自动注入的 Browser SDK 覆盖了前端异常、未处理 Promise 拒绝、白屏检测等场景。所有异常事件经 IPC Bridge 回流主进程统一上报,即使渲染进程崩溃,之前采集的事件也不会丢失。
所有函数拦截均采用非侵入式 monkey patch 设计,SDK 卸载后可完全还原------来的时候静悄悄,走的时候不留痕。
和友商比,优势在哪?
下面我们将 @arms/rum-electron 与 Electron 监控领域投入最深的 Sentry 方案,以及国内主流可观测平台的 Electron 支持情况做一个客观对比:
对比一:vs Sentry Electron SDK
Sentry 是目前 Electron 监控领域投入最深、社区最活跃的厂商,拥有专用 SDK @sentry/electron、独立产品页、会话回放(Session Replay)、事件循环阻塞检测等出色能力,在海外开发者群体中有着极高的认知度------超过 75% 的 Electron 开发者在生产环境中集成了 Sentry(官方数据)。
在功能覆盖度上,两者的差异主要体现在以下维度:

简单来说,Sentry 在海外生态、社区规模等方面有明显优势;而 @arms/rum-electron 在数据合规、tRPC 监控、崩溃数据主权、链路追踪协议覆盖这几个维度上,提供了更适合国内企业和对数据安全有严格要求的团队的方案。
对比二:vs 通用前端 RUM SDK
你可能会问:我直接用通用的前端 RUM SDK不行吗?技术上可以,但体验完全不同:

简单来说,通用前端 RUM SDK 能看到 Electron 应用的"半壁江山"(渲染进程),而 @arms/rum-electron 给你的是全景视图。
快速接入:比你想象的简单
以下是完整的接入步骤:
环境要求:Electron >= 28(SDK 使用 session.registerPreloadScript() API,低版本自动降级到 session.setPreloads())。
第一步:安装
bash
npm install @arms/rum-electron第二步:主进程入口初始化
javascript
import armsRum from '@arms/rum-electron';
import { app, BrowserWindow } from 'electron';
armsRum.init({
endpoint: '<your-endpoint>', // 云监控控制台获取
env: 'prod',
version: '1.0.0',
// 可选:启用链路追踪(将 tracing 配置直接放在 init 参数中)
// tracing: {
// enable: true,
// sample: 100,
// propagatorTypes: ['tracecontext'],
// },
});
app.whenReady().then(() => {
const win = new BrowserWindow({
webPreferences: {
// 不需要任何 SDK 相关配置
}
});
win.loadURL('https://your-app.com');
});第三步(可选):启用 tRPC 监控
ini
const t = armsRum.instrumentTRPC(initTRPC.create());就这么简单。不需要改 preload、不需要在渲染进程 import 任何东西。零配置、零侵入、零额外手动安装。
性能与开销:轻量到可以忽略
监控 SDK 的价值在于帮助发现问题,而不是成为问题本身。以下是 @arms/rum-electron 的资源开销数据:
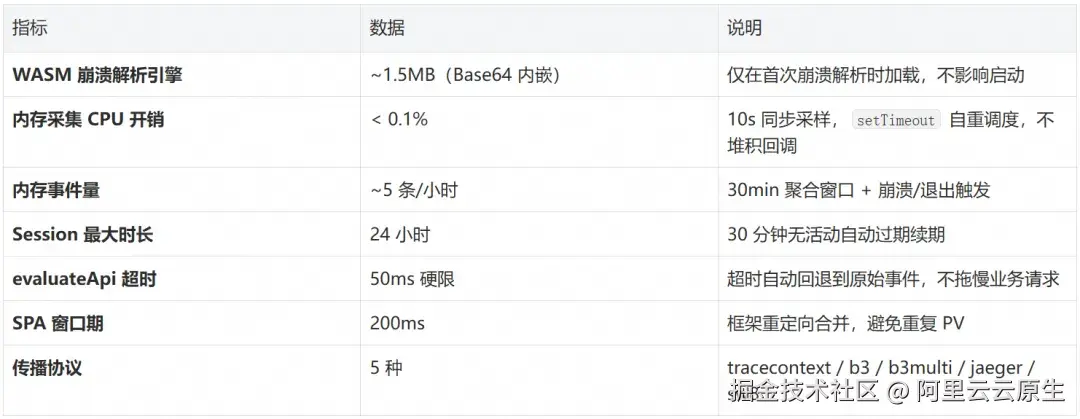
SDK 在设计上处处遵循"最小干扰原则 ":内存采集用 O(1) 分配的累加器、WASM 延迟到首次使用时才初始化、远程配置采用 launch-first 模式不阻塞应用启动。所有函数拦截均支持 restore 还原,确保 SDK 的存在不会成为应用的"负担"。
适用场景
@arms/rum-electron 面向的场景包括但不限于:
企业级 Electron 桌面应用。 Slack、Discord、Notion 等协作工具,以及各类企业内部工具、低代码平台------统一监控健康度、性能和稳定性,远程配置动态调整采样率。
AI 桌面应用。 AI 对话助手、AI 编程工具、AI 设计工具------tRPC 监控覆盖 AI 推理调用链路,内存水位追踪发现大模型加载导致的内存泄漏,分布式链路追踪串联客户端到 AI 后端。
长生命周期桌面应用。 IDE、设计工具、交易平台------30 分钟聚合窗口追踪 baseline 漂移,崩溃时立即 flush 内存现场,提前发现内存泄漏。
对数据安全有严格要求的行业。 金融、政府、医疗等------崩溃堆栈本地 WASM 解析,原始数据不出端;阿里云 ARMS 部署在国内,满足等保要求。
结语
Electron 让 Web 开发者有能力构建跨平台桌面应用,但也引入了双进程架构、原生崩溃、IPC 通信等独特的监控挑战。在过去,这些挑战要么被忽视,要么需要拼凑多套工具来勉强覆盖。
@arms/rum-electron 的目标很简单:让 Electron 应用的监控像 Web 应用一样简单。 开箱即用的接入体验、主进程+渲染进程全覆盖、崩溃数据本地解析、tRPC 原生支持、五协议链路追踪------这些能力整合在一个 npm 包里,安装即用。
桌面 Agent 监控,从此触手可及。
立即体验: 前往云监控 ** **1 创建用户体验监控应用,获取 endpoint 后即可开始接入。
技术文档: 完整的配置参考 ** **2 文档见。
社区交流: 加入钉钉群 ** **3 ,与阿里云可观测团队交流 Electron 监控实践。
相关链接:
1 阿里云云监控 / 云监控
2 配置参考
help.aliyun.com/zh/arms/use...
3 钉钉群
qr.dingtalk.com/action/join... 光粒邀请你加入钉钉群聊RUM 用户体验监控支持群,点击进入查看详情