AMD 云环境模型微调:把 Gemma 4 调成"情绪分析"专用模型
话题标签:#Datawhale #AMDev
实践平台 :AMD Radeon Cloud(ROCm 单卡环境) 微调方法 :LoRA 轻量化微调(PEFT) 基础模型 :Gemma 4 Instruct(ModelScope) 数据集 :6 类英文情绪分类(sadness / joy / love / anger / fear / surprise) 核心成果:准确率 0.625 → 0.915,Macro F1 0.4824 → 0.8645
一、"情绪分析"模型调优
之前我们部署了 Gemma 4 大模型并进行对话测试,完整走通了推理部署的链路。这次要精细化调整一个通用大模型,通过特定领域的数据训练,把它优化成一个能够精准识别 6 种人类情绪的"情感分析"模型。这个将通用模型定制为领域专家的过程,正是业界核心的模型微调(Fine-Tuning)技术。
整个流程跑在 AMD Radeon Cloud 的 ROCm 单卡环境上,用 LoRA 轻量化微调,单卡 17 分钟跑完一轮,最终把准确率从 0.625 拉到 0.915。下面是完整的调优记录。
二、环境准备
2.1 云环境特性
AMD Radeon Cloud 的云环境在关闭并重启后,运行环境会复原到最初状态------但已下载的模型文件保留,环境依赖(如 vLLM)会被清空,需要重新配置。判断方法:看实例面板是否点过红色的"Destroy Instance"按钮。
2.2 环境配置
云环境的完整配置流程(包括 PyTorch ROCm 版本安装、依赖管理、模型权重下载等)已开源在 GitHub 仓库,可直接参考:
仓库地址 :github.com/RainmeoX/ge...
requirements.txt:核心依赖清单(torch / transformers / peft / trl / datasets / modelscope)README.md:完整运行步骤- Release v1.0:含 LoRA 权重、Tokenizer 文件、ROCm 版 PyTorch 安装包
如果云环境重启过,先执行以下命令卸载不兼容的旧版组件,再运行 Notebook,自动化脚本会装回配套最新版:
bash
uv pip uninstall torchvision torchaudio三、微调流程与技术原理
整个微调流程被封装在一个 Notebook 里,点击"Run All"即可运行------这种封装有助于开发者专注于理解原理,避免被环境配置劝退。但流程是标准的微调链路,总共分 8 步:安装依赖、检查 GPU、下载模型和数据、改造数据格式、微调前评估、LoRA 微调、保存结果、微调后评估。
| 步骤 | 环节 | 核心动作 | 产出物 |
|---|---|---|---|
| 1 | 安装依赖 | 安装 transformers / datasets / trl / peft / modelscope | 可用的训练工具链 |
| 2 | 检查 GPU | torch.cuda.is_available() |
GPU 设备信息 |
| 3 | 下载模型和数据 | 拉取 Gemma 4 模型 + 情绪分类数据集 | 本地模型权重 + 教材数据 |
| 4 | 改造数据格式 | 把"句子→标签"改写成"一问一答"聊天格式 | Chat 格式训练集 |
| 5 | 微调前评估 | 用未训练模型跑 400 条测试,记下基线成绩 | pre_finetuning 指标 |
| 6 | LoRA 微调 | 冻住原参数,只训练新增的 LoRA adapter | LoRA adapter 权重 |
| 7 | 保存成果 | 把 adapter 存到 gemma4-it-emotion-lora-ms-single-gpu 目录 |
可复用的 adapter 文件 |
| 8 | 微调后评估 | 用训练好的模型再跑 400 条,与基线对比 | post_finetuning 指标 |
下面逐步拆解每一步的技术原理。
3.1 安装依赖
安装训练工具库:transformers 加载大模型,datasets 读数据,trl 提供训练循环,peft 实现 LoRA,modelscope 从魔搭下载模型,accelerate 显卡加速。
python
%pip install -q transformers datasets trl peft modelscope accelerate3.2 检查 GPU
有个容易出错的地方:AMD 的 ROCm 环境里,检查代码照旧写着 torch.cuda.is_available()。cuda 是 NVIDIA 的叫法,PyTorch 沿用了这个名字,看到 cuda 不代表在用 NVIDIA 显卡。返回 True 且设备名显示 AMD GPU,才表明显卡就位。
python
import torch
print(torch.cuda.is_available()) # True
print(torch.cuda.get_device_name(0)) # AMD Radeon ...3.3 下载模型和数据
下载两样东西:Gemma 4 模型和情绪分类数据集。模型通过 ModelScope 拉取,数据集每条样本是"一句话配一个情绪答案"。情绪标签共 6 类:
- sadness (悲伤)/ joy (喜悦)/ love(爱)
- anger (愤怒)/ fear (恐惧)/ surprise(惊讶)
目标:教会模型读完一句话,从这 6 类里挑出正确的情绪。
3.4 改造数据格式
Gemma 4 是"聊天型"模型,习惯"一问一答"格式。Notebook 把原始分类数据改写成:
用户:判断这句话的情绪
助手:joy改造后模型学会一个明确习惯:看到一句话,回一个情绪标签,不额外回答其他内容。这正是微调解决"输出格式固定"问题的典型场景------若不进行微调,模型可能输出一长串解释而不是简洁的标签;微调之后,模型的行为变得高度可控。
3.5 微调前评估(记基线)
训练前先用未训练模型跑 400 条测试,记录基线成绩。这一步容易被忽略,若没有基线成绩,训练后不知是否有进步。主要看三个指标:
- 准确率(accuracy):答对的比例,越高越好
- F1:综合各类情绪表现的得分,越高越好
- 无效预测(invalid predictions):没给出 6 个标签之一的次数,越低越好
基线成绩:accuracy=0.625,Macro F1=0.4824,无效预测 2 个。通用模型在情绪分类上表现一般------能聊,但聊得不准。
3.6 LoRA 微调(核心)
LoRA 的思路:不去动整个庞大的模型,只额外训练一小部分新增参数。与其把整本书重写一遍,不如只在关键处贴上批注。好处是省显存、训练快,适合单卡云环境。从 GitHub 仓库的 adapter_config.json 看关键超参数:
| 参数 | 取值 | 含义 |
|---|---|---|
| peft_type | LORA | 使用 LoRA 方法 |
| task_type | CAUSAL_LM | 因果语言模型(自回归生成) |
| r(秩) | 16 | LoRA 低秩矩阵的秩,越大表达能力越强 |
| lora_alpha | 32 | 缩放系数,通常设为 r 的 2 倍 |
| lora_dropout | 0.05 | Dropout 比例,防止过拟合 |
| target_modules | all-linear | 对所有线性层注入 LoRA |
| epoch | 1 | 只训练 1 轮,快速跑通流程 |
从 train_metrics.json 看,训练总时长约 1009 秒(约 17 分钟),train_loss 降到 0.3145,epoch=1.0。单张 AMD 显卡上用 LoRA 微调几十亿参数的大模型,不到 20 分钟跑完一轮------这就是 LoRA 的功能所在。
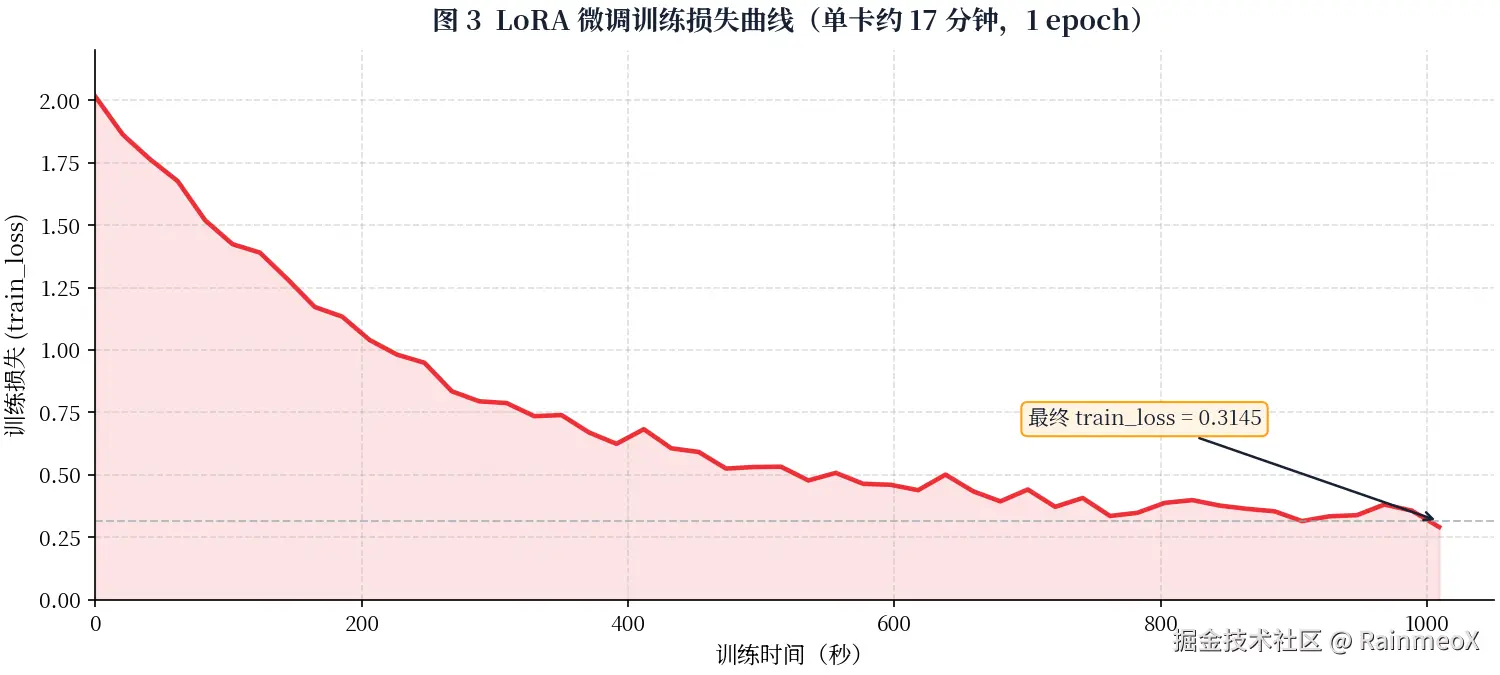
3.7 保存成果
训练完成后,成果保存到 ./gemma4-it-emotion-lora-ms-single-gpu 目录。注意保存的不是完整 Gemma 4 模型,而是 LoRA adapter("外挂的批注"),以后想再用需要把原始基础模型也带上。不过 adapter 可以直接"融合(Merge)"到原模型里,融合后变成纯净完整的新模型,直接加载就行。
3.8 微调后评估(对比成绩)
用训练好的模型再跑 400 条测试,和第 5 步的基线对比。仅需关注:post_finetuning(微调后)的成绩是否比 pre_finetuning(微调前)更好。本次为了快速跑通,只用少量数据、训练 1 轮,目标是把流程走通,并非冲最高分。
四、实验结果分析
基于 GitHub 仓库(RainmeoX/gemma4-emotion-lora-rocm)保存的真实数据,对微调前后结果做对比。
4.1 核心指标对比:0.625 → 0.915
| 阶段 | 准确率 | Macro F1 | 无效预测数 | 评估样本数 |
|---|---|---|---|---|
| pre_finetuning(微调前) | 0.625 | 0.4824 | 2 | 400 |
| post_finetuning(微调后) | 0.915 | 0.8645 | 0 | 400 |
| 提升幅度 | +0.290(+46.4%) | +0.3821(+79.2%) | -2 | --- |
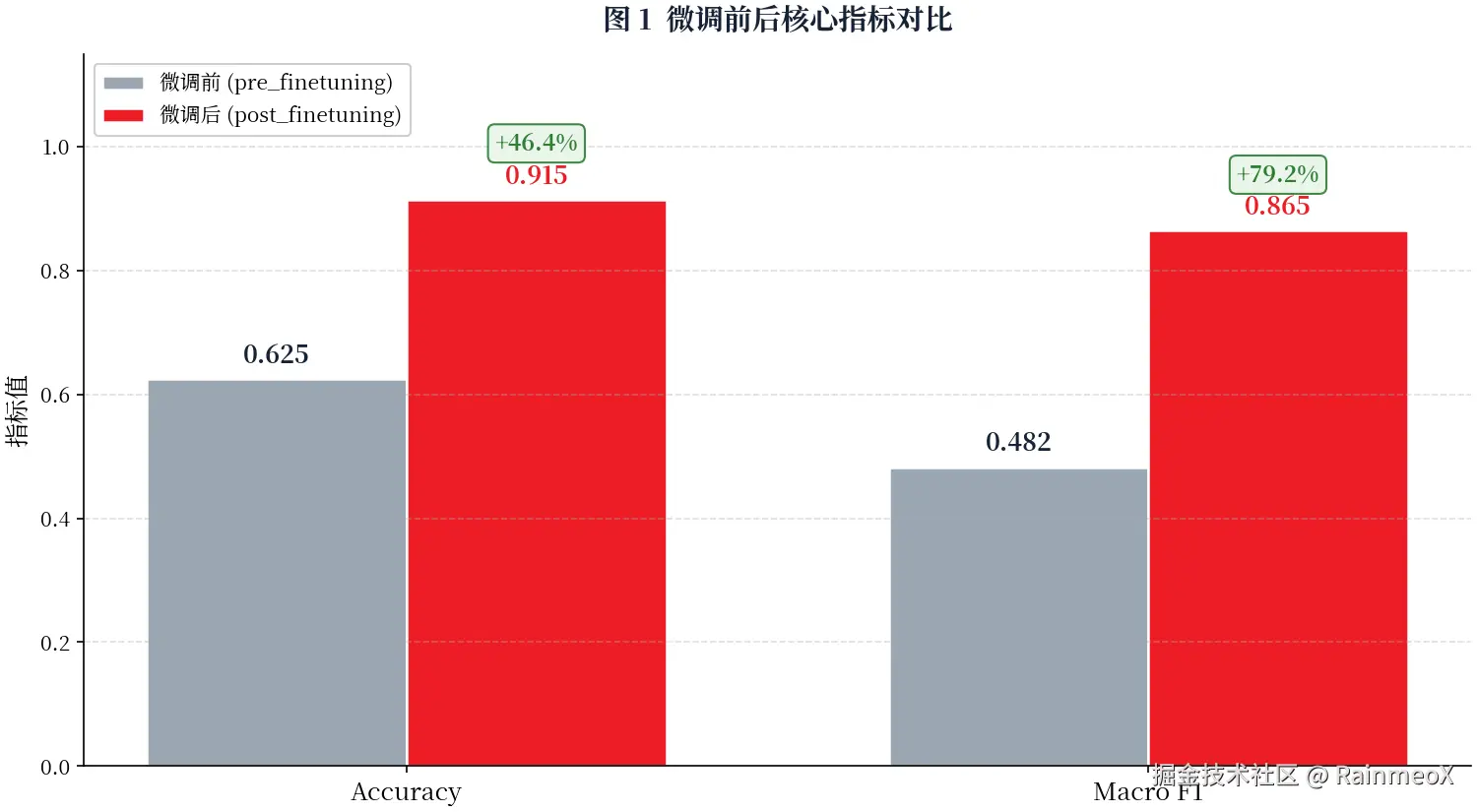
三个关键调优信息:准确率绝对提升 29 个百分点(相对 +46.4%);Macro F1 相对提升 79.2%,远大于准确率提升幅度(原因下一节揭晓);无效预测从 2 降到 0,模型完全学会了"只输出 6 个标签之一"的格式约束。
4.2 六类情绪分类报告
拆开看每一类的 precision、recall、F1,数据来自 pre/post_finetuning_classification_report.csv。
微调前各情绪类别表现:
| 情绪类别 | Precision | Recall | F1 | Support |
|---|---|---|---|---|
| sadness(悲伤) | 0.81 | 0.89 | 0.85 | 58 |
| joy(喜悦) | 0.79 | 0.91 | 0.85 | 142 |
| love(爱) | 0.67 | 0.21 | 0.32 | 34 |
| anger(愤怒) | 0.73 | 0.85 | 0.79 | 57 |
| fear(恐惧) | 0.83 | 0.76 | 0.79 | 38 |
| surprise(惊讶) | 0.50 | 0.20 | 0.29 | 21 |
微调后各情绪类别表现:
| 情绪类别 | Precision | Recall | F1 | Support |
|---|---|---|---|---|
| sadness(悲伤) | 0.93 | 0.95 | 0.94 | 58 |
| joy(喜悦) | 0.94 | 0.97 | 0.96 | 142 |
| love(爱) | 0.92 | 0.97 | 0.94 | 34 |
| anger(愤怒) | 0.91 | 0.88 | 0.89 | 57 |
| fear(恐惧) | 0.89 | 0.89 | 0.89 | 38 |
| surprise(惊讶) | 0.82 | 0.86 | 0.84 | 21 |
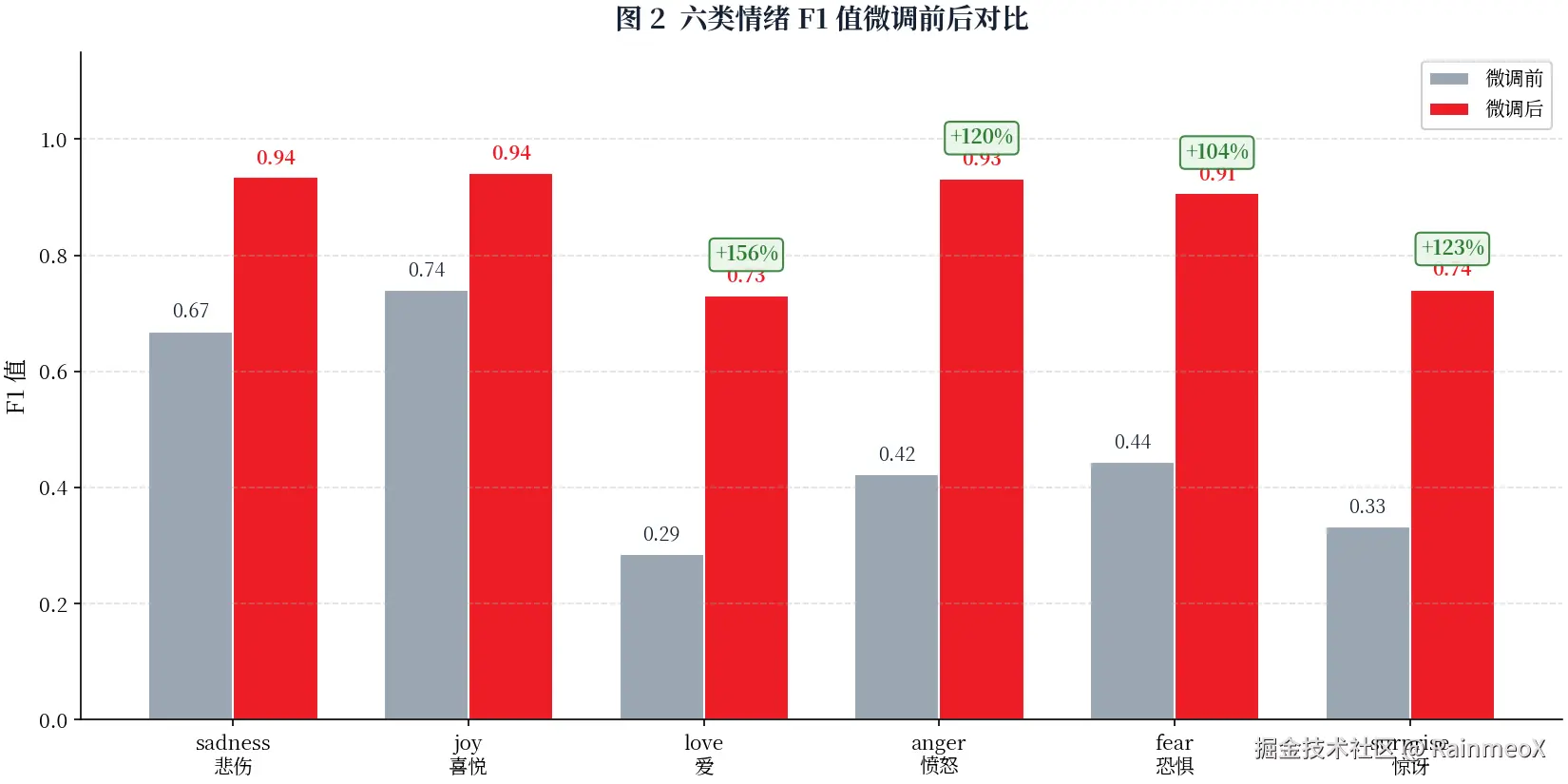
改善最显著的是 love 和 surprise 这两个少数类:love 的 F1 从 0.32 飙到 0.94(+193%),surprise 从 0.29 飙到 0.84(+190%)。微调前几乎是"乱猜"水平,微调后达到优秀。
原本就不错的 sadness 和 joy,微调后进一步提升到 0.94 和 0.96,但幅度较小。说明微调的核心价值在于补短板------让模型在最不擅长的少数类上跨越式提升,而不是在已擅长的类上锦上添花。这也解释了为什么 Macro F1(各类别等权平均)的提升幅度(79.2%)远大于 accuracy(按样本数加权,多数类主导)的提升幅度(46.4%)。
4.3 混淆矩阵:错误都去哪了
基于 confusion_matrix.csv,微调前最主要的混淆是"把少数类误判为多数类":love 大量被误判为 joy(语义接近且 joy 样本最多),surprise 也大量被误判为 joy,fear 偶尔被误判为 sadness。这种"少数类被多数类吞掉"是类别不平衡场景下未微调模型的典型表现------模型倾向于预测样本多的类别,统计上"更安全"。
微调后这些混淆大幅减少。love 和 surprise 的召回率分别从 0.21、0.20 提升到 0.97、0.86,模型真正学会了区分少数类的语义特征。剩下的少量错误主要集中在语义确实模糊的边界案例,比如"i feel rather overwhelmed"既可以是 fear 也可以是 sadness,这类案例对人类标注者也有主观性。
4.4 典型预测案例
从 changed_predictions.csv 找几个"微调前判错、微调后判对"的典型案例:
| 输入句子(英文) | 真实标签 | 微调前预测 | 微调后预测 |
|---|---|---|---|
| i feel like a helpless baby | fear | sadness | fear ✓ |
| i feel very lucky | joy | love | joy ✓ |
| i feel so blessed | love | joy | love ✓ |
| i feel a bit startled | surprise | fear | surprise ✓ |
| i feel rather overwhelmed | fear | sadness | fear ✓ |
比如"i feel so blessed"(我感到很受祝福),微调前判成 joy(喜悦),微调后正确判成 love(爱)------blessed 更多表达感恩与爱,而非单纯喜悦。"i feel a bit startled"(我感到有点受惊),微调前判成 fear(恐惧),微调后正确判成 surprise(惊讶)------startled 更接近"被吓一跳"的惊讶感。这些细微语义差别,正是通用模型搞不定、微调后能精准捕捉的能力。
五、关键技术点
LoRA(Low-Rank Adaptation):把原模型参数全"冻住",只在原始权重矩阵旁注入两个低秩矩阵 A 和 B,它们的乘积 B×A 近似原始权重的更新量。由于秩远小于原始矩阵,训练参数量从几十亿骤降到几百万,单卡一小时就能跑完。产物是几十 MB 的 adapter,相比 Gemma 4 原始模型数 GB 的体积极其轻量。
ModelScope vs HuggingFace:国内环境下 ModelScope(魔搭社区)是务实选择------阿里达摩院推出,国内网络访问快、稳定性好,不需要代理。两者 API 接口高度相似,迁移成本很低。
AMD ROCm :AMD 推出的开源 GPU 计算平台,对标 NVIDIA 的 CUDA。PyTorch 在 ROCm 下依然用 torch.cuda 这个 API 命名空间,是为兼容性保留的历史命名。这次顺利跑通,证明 PyTorch 在 AMD ROCm 上的支持已经相当成熟。
六、踩坑记录
显存不足(OutOfMemoryError) :最常见的问题,几乎可以肯定是之前工作中启动的 vLLM 服务没正确关闭。叉掉终端页面只是隐藏,vLLM 还在运行占显存。解决:找到被隐藏的 vLLM 终端关闭,不确定是哪个就都关掉。核心原则------用 Ctrl+C 亲手结束进程,而不是点叉号隐藏窗口。
组件未实现报错 :通常是云环境重启后没重新执行环境配置。解决:先执行 uv pip uninstall torchvision torchaudio 卸载不兼容旧版组件,再重新运行 Notebook。
文件"消失"问题 :平台有三个存储区域------/workspace(自动存盘但无法跨机器移动)、/network-workspace(跨机器同步,每人 20GB)、运行环境(断开或 Destroy 即清空)。重要文件建议放 /network-workspace,环境配置用 requirements.txt 保存。
七、总结
跑完整个 Notebook,相当于独立完成了一次完整的模型微调,会产出以下成果:一个 LoRA adapter 目录(模型调优的情绪识别功能"优化"在这里)、微调前后指标对比表、部分 CSV 结果文件(详细评估数据)、一个微调后的模型(读英文句子并给出情绪标签,从"通用聊天模型"成为"情绪分类模型")。
三点启发:微调的核心价值在于"补短板"(Macro F1 提升 79% 远超 accuracy 提升 46%);LoRA 让大模型微调简易化(单卡 17 分钟、几十 MB adapter);流程可复用(换数据集微调其他任务)。
局限性:为了快速跑通只训练了 1 个 epoch,提升空间很大。想要更好效果可以加大数据量、多轮训练。但 epoch 不是越高越好------轮数太高模型会"死记硬背"(过拟合 / Overfitting),微调工作在于找到"学得会"和"不背书"之间的平衡点。
八、进阶玩法
整体流程是通用的,换上自己的数据集就能微调出各种模型。单卡 + LoRA 最适合轻量、专门、目标明确的场景:
- 换个分类任务:评论好评/差评、垃圾信息识别、新闻分类、用户意图识别等。
- 教它固定的输出格式:把杂乱的话抽成结构化信息(姓名、时间、地点)、把口语改写成正式邮件/工单。
- 调出特定的语气/人设:某品牌口吻的客服助手、某种文风的文案/标题生成器。
- 让它更懂某个垂直领域:某门课、某款产品、某个游戏的答疑助手,或某行业的术语理解。
步骤有三步:① 准备数据集(整理成"一问一答"格式)→ ② 在云服务器上把 Notebook 里加载数据的部分换成自己的数据 → ③ 点运行,等数据结果。
提醒:这台机器配单卡小模型(像 E4B),强项是把通才"在某件事上调得更专、更稳",并非打造一个无所不能的大助手。先从"换分类数据集"开始,跑通再挑战进阶的玩法。
话题标签:#Datawhale #AMDev
参考资源:
- 实验数据仓库:github.com/RainmeoX/gemma4-emotion-lora-rocm
- AMD 开发者平台:developer.amd.com.cn
- ModelScope 魔搭社区:modelscope.cn