前言
Skill 是 Agent 中必不可少的一个模块。本文主要介绍在 Langchain 体系中如何实现 Skill 机制。为便于读者厘清来龙去脉,文中加入了对于 Tool 和 Skill 基础的介绍。不感兴趣者可直接跳至实现部分。
认识 Tool
Tool 的诞生
LLM 本质上只是一个推理引擎,它擅长于理解问题、制定计划、生成内容,但面对需要一些实时信息的场景,它就会开始胡编乱造。比如一个很简单的问题:今天北京天气如何?------LLM 在无外部数据时容易产生幻觉,不一定会给出可靠回答。
为解决这个困境,LLM 就需要能够执行外部动作并获取确定性的结果,Tool由此应运而生。具体来说,Tool 为 Agent 提供了以下功能:
- 执行能力的扩展:模型原本只能输出文本,而 Tool 让模型可以触发真实系统行为,比如"查订单""发请求""调接口"。这是从"语言"到"动作"的扩展。
- 提供可验证的外部状态:正如我们刚刚提到的,模型内部推理是不可靠的,Tool 可以为模型提供外部环境的真实状态。
Langchain 中 Tool 的调用
很多人直觉下的 Agent Tool的调用过程是这样的:
但其实 LLM 根本没法自动调用 Tool,我们不能期望将 Tool 注册给模型就能获得最终答案。下图是 Tool 调用的完整底层逻辑:
模型只会生成 Tool Call(结构化调用请求),不会自行执行。我们需要在代码逻辑中通过调用结果匹配合适的 Tool ,然后执行 Tool 调用 ,再将 Tool 的调用结果添加到对话的上下文当中,模型结合最新结果继续进行推理。这也就是经典的 ReAct 模式(思考-行动-观察-继续思考,langchain 中的 create_agent 内部封装的也正是此模式)。
Tool 实现代码示例
搭建环境
bash
mkdir python
uv init
uv venv
.venv\Scripts\activate
uv add langchain langchain-deepseek简单agent及简单tool
python
# /python/main.py
from langchain.agents import create_agent
from langchain.tools import tool
from langchain_core.messages import HumanMessage
from langchain_deepseek import ChatDeepSeek
from pydantic import SecretStr
@tool
def get_weather(city: str) -> str:
"""查询城市天气"""
return f"{city} 当前天气晴朗,温度25度"
model = ChatDeepSeek(
model="deepseek-chat",
api_key=SecretStr("sk-xxxx"),
)
agent = create_agent(
model=model,
tools=[get_weather],
)
def main():
human_message = "北京天气怎么样?"
result = agent.invoke({"messages": [HumanMessage(human_message)]})
print(result)
if __name__ == "__main__":
main()运行文件即可得到输出:
python
# 模型最终输出,部分内容省略
{
"messages": [
HumanMessage(
content="北京天气怎么样?",
), # 用户输入
AIMessage(
content="好的,我来查一下北京的天气情况。",
tool_calls=[
{
"name": "get_weather",
"args": {"city": "北京"},
"type": "tool_call",
}
],
), # 模型调用工具的决定
ToolMessage(
content="北京 当前天气晴朗,温度25度",
name="get_weather",
), # 工具调用结果
AIMessage(
content="北京目前的天气情况如下:\n\n- **天气状况**:☀️ 晴朗\n- **当前温度**:25°C\n\n总体来看,北京现在是晴朗的好天气,温度比较舒适宜人。如果你有出行计划,今天是个不错的日子!请问还有其他需要帮忙的吗?",
tool_calls=[],
invalid_tool_calls=[],
) # 模型最终输出
]
}从打印的结果中可以看到,整个调用链完整包含了:用户消息-工具调用决策-工具执行结果-模型最终输出,这恰与我们提及的 Tool 调用链路一致。
Tool 存在局限性
Tool 的数量一增加,Agent 的能力就扩展一分。Agent 需要什么能力,我们就为其添加什么 Tool。这个逻辑看上去可以无限延伸,但现实并没有这么乐观。为什么呢?
要回答这个问题,首先要清楚我们在传递tools=[get_weather]时,真正暴露给模型的是什么?
实际上是工具函数的元数据,这包含了工具的名称,对于工具的描述以及参数的定义。以示例代码中的天气工具为例:
json
{
"name": "get_weather",
"description": "查询城市天气",
"parameters": {
"city": {
"type": "string",
"description": "城市名称"
}
}
}模型不会也不需要知道函数内部做了什么,它只知道这个工具叫什么、能干什么、有哪些参数。这个简单的事实,在 Tool 规模扩大后会带来三个越来越难绕过的问题。
局限一:知识承载困境
要让模型准确选择工具,description 必须足够清晰。一个好的工具描述往往需要同时回答"是什么"和"什么时候用",比如下面这个:
json
{
"name": "search_document",
"description": "搜索公司内部技术文档。适用于:API 使用问题、架构设计、部署流程;不适用于:实时数据查询、用户订单",
"parameters": {
"query": {
"type": "string",
"description": "查询内容"
}
}
}可这在工具足够多时,会带来新的问题:
一是上下文膨胀:越精准的描述意味着越多的文字。工具一多,大量 description 同时塞入上下文,Token 成本随之线性增长。
二是注意力竞争:模型上下文窗口是有限的,几十上百个工具的描述同时存在时,部分信息会被稀释甚至忽略,工具选择的准确率会不可避免地下滑。
局限二:工作流编排困境
Tool 的设计哲学一般遵循最小职责原则,也就是说一个 Tool 只做一件事。单次调用场景下没有问题,但当一项能力本身是多步骤流程时,麻烦就来了。
假设我们有"生成代码质量报告"的需求,其完整流程大概是这样:
用 Tool 实现,意味着把四个步骤拆成四个独立的 Tool,然后期望模型每次都能按正确顺序调用它们,并把每一步的结果正确传递给下一步。这个"期望"在简单场景下基本可靠,但流程一复杂,遗漏步骤、顺序错误的问题就会开始出现。
更关键的是,这个流程本身没有被封装。换一个 Agent 复用这套能力,只能把四个 Tool 全部迁移过去,再重新在 system prompt 里描述调用顺序,每次都在重新造轮子。
局限三:运行环境困境
随着需求变得复杂,我们迟早会碰到需要执行外部脚本的工具,这些脚本往往依赖特定的第三方包。假设要给 Agent 增加一个"代码依赖安全扫描"的能力,工具大概长这样:
python
@tool
def scan_dependencies(requirements_file: str) -> str:
"""扫描项目依赖中的安全漏洞"""
result = subprocess.run(
["pip-audit", "-r", requirements_file],
capture_output=True,
text=True
)
return result.stdout这里有一个被动接受的隐含假设:pip-audit 包必须预先安装在宿主机上。没有安装就直接报错;但如果在工具内部动态执行 pip install,则会污染宿主机环境,这显然不可接受。这意味着 Tool 没有"携带运行时"的能力,它始终在宿主环境中执行,与外部世界之间没有任何隔离边界。
Skill 面向 Agent 能力扩展场景,提供了更高层级的抽象。
初识 Skill
从本质上讲,技能是一个包含SKILL.md文件的文件夹,它的常见文件结构会是这样的:
perl
my-skill/
├── SKILL.md # 必须: metadata + Skill 说明
├── scripts/ # 可选: 调用Skill所需执行的脚本
├── references/ # 可选: 更详细的文档
├── assets/ # 可选: 依赖的资源
└── ... # 其余任何你想添加的额外文件或文件夹在这个文件结构中,只有SKILL.md这个文件是必须的(名称也必须如此),其余的任何文件或文件夹都不是必须的(文件夹名称也没有任何要求,示例中只是推荐结构)。所以我们在开发时,必须要了解的就只有SKILL.md这个文件。
Skill 的核心
核心文件-SKILL.md
SKILL.md 是技能中最核心的文件,其中必须包含 YAML 格式的前置元数据,格式如下:
| 字段 | 说明 | 要求 |
|---|---|---|
| name | 技能名称 | 最多64个字符。仅限小写字母、数字和连字符。不得以连字符开头或结尾。 |
| description | 技能描述 | 最多 1024 个字符。描述技能的效果以及何时使用。 |
除此之外,部分技能可能还包含license、allowed-tools等元数据,这些都是非必须的,此处不过多介绍,详阅Skill的介绍官网。
SKILL.md 的正文中为技能的详细使用说明,此部分格式没有限制,原文件为claude的 pdf解析 skill:
md
---
name: pdf
description: Use this skill whenever the user wants to do anything with PDF files. This includes reading or extracting text/tables from PDFs, combining or merging multiple PDFs into one, splitting PDFs apart, rotating pages, adding watermarks, creating new PDFs, filling PDF forms, encrypting/decrypting PDFs, extracting images, and OCR on scanned PDFs to make them searchable. If the user mentions a .pdf file or asks to produce one, use this skill.
license: Proprietary. LICENSE.txt has complete terms
---
# PDF Processing Guide
## Overview
This guide covers essent...核心思想-渐进式披露
Skill 的核心思想是渐进式披露,这指的是 Agent 在使用扩展能力时,会分为如下三个阶段来进行:
- 发现:Agent 启动时,只会加载每个技能的 name 和 description。
- 激活:当 Agent 判断当前任务与技能描述匹配时,Agent 会进一步将完整的 SKILL.md 在的指令说明添加到上下文中。
- 执行: Agent 会根据 Skill 中提到的说明执行必要步骤,按需执行脚本代码或进一步阅读更多文件。
知道了这些,便可对 Tool 中三个局限提出对应的解法:
| 局限 | 根因 | Skill 的解法 |
|---|---|---|
| 知识承载困境 | 所有工具描述始终占据上下文 | 渐进式披露:按需激活,用到时才加载完整知识 |
| 工作流编排困境 | 函数边界使多步骤流程难以封装 | 流程与脚本配合形成 Skill 整体 |
| 运行环境困境 | 工具绑定宿主机,无法携带依赖 | 沙盒执行:隔离环境,携带自身运行时 |
总而言之:Skill 不是一种新的 Tool,而是更高层级的能力封装单元------它把"怎么做"(知识)、"按什么顺序做"(流程)、"在什么环境里做"(运行时)打包成一个整体,交给 Agent 按需取用。
Skill 机制的实现
前面提到, Agent 中的 Skill 机制会通过发现 、激活 以及执行三个阶段来进行。实际开发中,代码实现的核心也将围绕这三点来展开。但与本地运行的 Agent 比起来,带有 Agent 功能的服务端系统在实现 Skill 功能更为复杂。对于服务端系统来说,Skill 的实现还要考虑 Skill 存储、审核、沙箱、租户隔离等多方面的内容。我们本次的代码实现也将围绕服务端系统进行展开,下图给出分层架构:
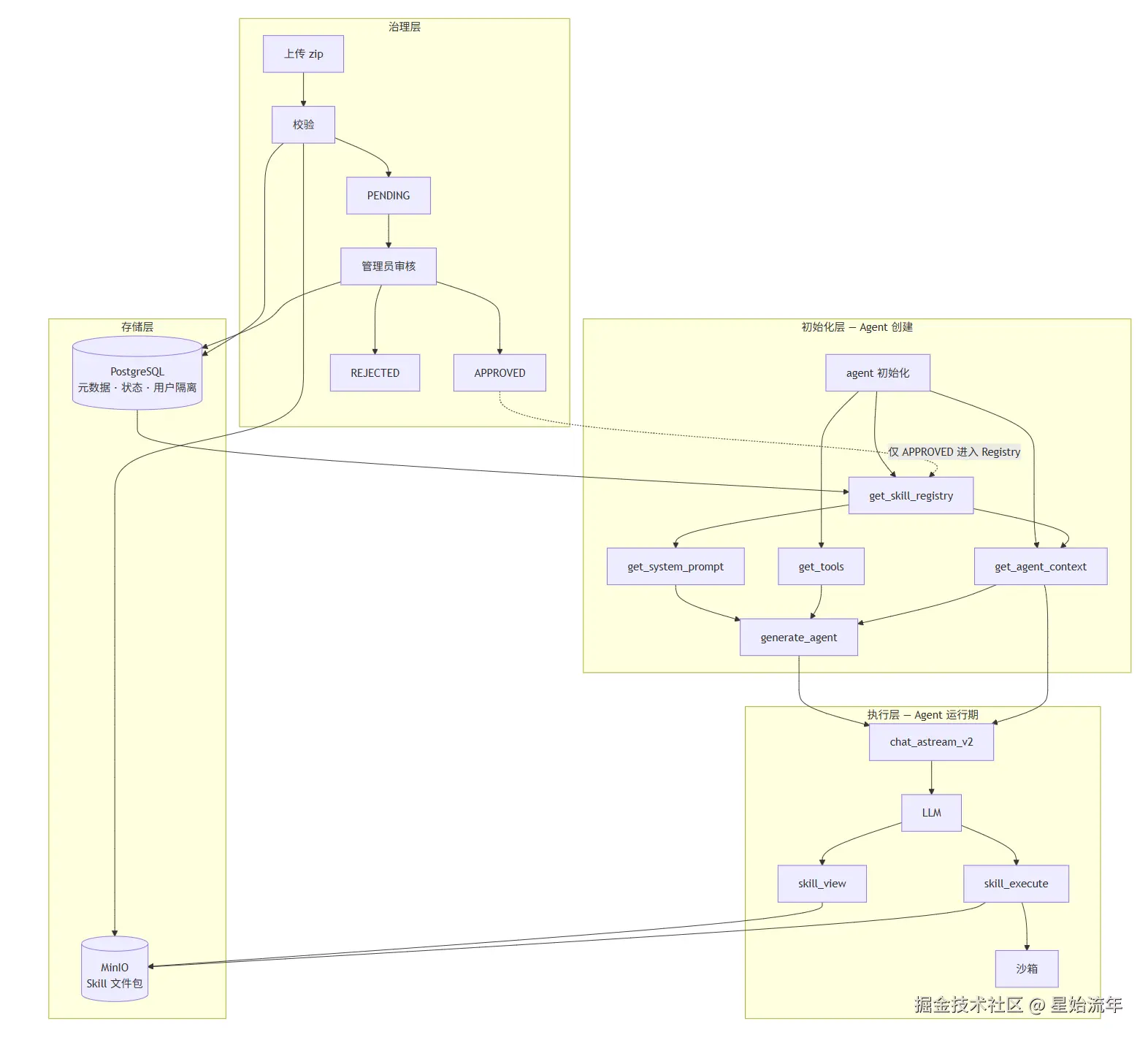
我们可以将整个实现分为四层来看:
| 层 | 职责 |
|---|---|
| 治理层 | 上传时校验 zip → 写入存储 → 管理员审核Skill并修改状态 |
| 存储层 | 在 PG 数据库中存Skill元数据,在 MinIO 中存储原始文件 |
| 初始化层 | 获取可用skill,将其元数据注入提示词 |
| 执行层 | 按需进一步获取skill指令,或在沙箱中执行脚本代码 |
治理层基本都是与Agent无关的传统逻辑,不做过多介绍。在存储层中,我们选择了 PostgreSQL + Minio 的二元模式。在PostgreSQL中,不仅会存入审核状态、对应用户、上传日期等字段,还会将 skill 的 name 以及description 存入。在发现阶段,我们只需从数据库就可获取初始化System Prompt的所有内容,不必为每个 Skill 去对象存储拉一遍文件。
发现
发现这一环节的核心思想,就是要将所有 Skill 的 name 以及 description 注入到 Agent 的初始提示词中。拆开来看具体步骤有两个:
获取可用Skill
这一步的核心思想是从数据库中获取可用skill,并将其作为skill_registry返回,方便后续需要时获取。
py
# skill_loader.py
from pydantic import BaseModel
from typing import TypedDict
import uuid
from sqlalchemy.ext.asyncio import AsyncSession
from app.models import Skill # Skill 数据表
from app.models.skill import SkillStatus, skill_repo
class SkillMetadata(BaseModel):
id: str
name: str
description: str
def _to_metadata(skill: Skill) -> SkillMetadata:
return SkillMetadata(
id=str(skill.id), name=skill.name, description=skill.description
)
class SkillRegistry(TypedDict):
skills: list[SkillMetadata]
by_id: dict[str, SkillMetadata]
by_name: dict[str, SkillMetadata]
async def get_skill_registry(
user_id: uuid.UUID,
session: AsyncSession,
) -> SkillRegistry:
skills = await skill_repo.get_all(
session,
conditions=[Skill.user_id == user_id, Skill.status == SkillStatus.APPROVED],
order_by="updated_at",
)
return {
"skills": [_to_metadata(skill) for skill in skills],
"by_id": {str(skill.id): _to_metadata(skill) for skill in skills},
"by_name": {skill.name: _to_metadata(skill) for skill in skills},
}拼装系统提示词
这一步的核心思想为 Agent 拼装提示词,以便Agent处理相关任务时进行选择。通过这份提示词我们会发现:这里不光列出所有 Skill,还对 Agent 如何调用Skill进行了详细的说明。
众所周知,Prompt 对于 Agent 来说至关重要,Agent 能否稳定高质量的运行 Skill,很大程度上会与此处的提示词相关。所以当你的Skill调用效果不佳时,不妨多尝试调整提示词。
py
# prompt_loader.py
from app.agent.skill_loader.py import SkillMetadata
BASE_SYSTEM_PROMPT = """你是一个名为 Fovvy 的智能 Agent ,你可以高效地处理任何任务。"""
SKILLS_SYSTEM_PROMPT = """## Skills 系统
Skills 系统为你提供了专业能力和领域知识的扩展。
**可用 Skills:**
{skills_list}
**如何使用 Skills:**
技能遵循*渐进式披露原则*------你可以在上方看到它们的名称和描述,但只有在需要时才阅读完整说明:
1. **识别 Skill 何时适用**: 判断用户的任务是否与某项 Skill 的描述匹配或者相关
2. **阅读 Skill 的完整指令**: 初次使用 Skill , 你应该使用 `skill_view` 工具进一步查看该 Skill 核心文件 `SKILL.md` 中的完整说明
3. **遵循 Skill 的说明**: `SKILL.md` 中可能包含分步工作流程、最佳实践和示例
4. **进一步访问其他文件**: 如有必要,你可以进一步使用 `skill_view` 查看该 Skill 中的其他文件
**何时使用 Skills:**
- 用户的请求匹配某个 Skill 的领域
- 所需的专业知识或结构化工作流程与某个 Skill 相关
- 某个 Skill 为复杂任务提供了成熟的模式
**执行 Skills 中脚本:**
技能可能包含 Python 脚本或其他可执行文件,你可以使用 `skill_execute` 工具进行执行(这一切将在独立的沙盒环境执行).
**示例工作流程:**
用户:"研究一下量子计算的最新进展"
1. 检查可用技能 -> 看到"web-research"技能及其路径
2. 阅读完整的技能文件: skill_view(skill_name="web-research", path="SKILL.md")
3. 遵循技能的研究工作流程(搜索 -> 整理 -> 综合)
4. 必要时使用 `skill_execute` 执行 Skill 内的脚本
**重要原则**
- 在进行回答或完成任务时,使用 Skill 的优先级应始终高于依据猜测提供的结果。
"""
def compose_skill_prompt(skill_metadata_list: list[SkillMetadata]) -> str:
if skill_metadata_list:
return SKILLS_SYSTEM_PROMPT.format(
skills_list="\n".join(
[
f"- name: {s.name} description: {s.description}"
for s in skill_metadata_list
]
)
)
return ""
def get_system_prompt(skill_metadata_list: list[SkillMetadata]):
prompts = [BASE_SYSTEM_PROMPT, compose_skill_prompt(skill_metadata_list)]
return "-----".join([p for p in prompts if p])注入context
在完成这两步工作后,我们还需要完成一个额外工作。就是将一些包含skill_registry的必要信息注入到langchain执行的context中,目的是后续tool执行时,可以从context取到所需的skill信息。
py
# context_loader.py
from dataclasses import dataclass
import uuid
from minio import Minio
from sqlalchemy.ext.asyncio import AsyncSession
from app.agent.loaders.skill_loader import SkillRegistry
from app.agent.sandbox.client import SandboxClient
@dataclass
class Services:
session: AsyncSession # db session
sandbox: SandboxClient # 沙盒实例
minio: Minio # minio实例
@dataclass
class AgentContext:
user_id: uuid.UUID # 用户id
thread_id: uuid.UUID # 会话id
skill_registry: SkillRegistry # skill registry
services: Services
def get_agent_context(
user_id: uuid.UUID,
thread_id: uuid.UUID,
skill_registry: SkillRegistry,
session: AsyncSession,
sandbox: SandboxClient,
minio: Minio,
):
return AgentContext(
user_id=user_id,
thread_id=thread_id,
skill_registry=skill_registry,
services=Services(session=session, sandbox=sandbox, minio=minio),
)组装进 Agent
接下来便可组装Agent:
py
# agent.py
from langchain.agents import create_agent
from langchain.messages import HumanMessage
from langgraph.checkpoint.memory import InMemorySaver
from sqlalchemy.ext.asyncio import AsyncSession
from app.agent.loaders.context_loader import AgentContext, get_agent_context
from app.agent.loaders.llm_loader import get_llm_model
from app.agent.loaders.prompt_loader import get_system_prompt
from app.agent.loaders.skill_loader import get_skill_registry
from app.models.thread import Thread
from app.models.user import User
async def agent_endpoint(
query: str,
current_user: User,
thread: Thread,
session: AsyncSession,
sandbox,
minio,
):
user_id = current_user.id
thread_id = thread.id
llm_model = get_llm_model() # llm模型
saver = InMemorySaver() # 会话记录存储器
skill_registry = await get_skill_registry(user_id, session) # 获取skill
system_prompt = get_system_prompt(
skill_metadata_list=skill_registry.get("skills")
) # 拼装prompt
context = get_agent_context(
user_id=user_id,
thread_id=thread_id,
skill_registry=skill_registry,
session=session,
sandbox=sandbox,
minio=minio,
)
agent = create_agent(
model=llm_model,
checkpointer=saver,
system_prompt=system_prompt,
context_schema=AgentContext,
)
result = await agent.ainvoke(
input={"messages": [HumanMessage(content=query)]},
version="v2",
context=context, # 注入context
config={"configurable": {"thread_id": str(context.thread_id)}},
)
return result激活
激活的主要目的是在 Agent 明确需要使用某个 Skill 时,将其 SKILL.md 中的详细指令作为上下文提供给Agent,这个功能我们会通过设计skill_view这个工具来实现。
实现skill_view工具
这个工具接收skill name作为输入参数,然后从 context 的 skill_registry 中找到对应 skill ,根据其id从minio中读取对应的SKILL.md的文本内容,并将这部分内容重新返回给Agent。
py
# tool_skill_view.py
import asyncio
from langchain.tools import ToolRuntime, tool
from pydantic import BaseModel, Field
from app.agent.loaders.context_loader import AgentContext
from app.core.config import settings
class SkillViewArgs(BaseModel):
skill_name: str = Field(
description="Skill 的名称。如 `web-search`",
min_length=1,
)
path: str = Field(
description="Skill 内部文件的地址,视 Skill 文件夹为根目录,传入相对路径。如 `SKILL.md` `./refernces/detail.txt`",
min_length=1,
)
@tool(
args_schema=SkillViewArgs,
description="""用于查看 Skill 内部文件内容的工具。
# 何时使用
- 需要查看 skill 的指令时
- 需要查看 skill 其他文件的内容时
# 返回结果说明
- 格式:str -读取到的文件内容
""",
)
async def skill_view(
skill_name: str,
path: str,
runtime: ToolRuntime[AgentContext],
):
if not skill_name:
return {"error": "请传入有效的skill_name参数"}
if not path:
return {"error": "请传入有效的path参数"}
user_id = runtime.context.user_id
minio = runtime.context.services.minio
skill_registry = runtime.context.skill_registry
skill = skill_registry.get("by_name", {}).get(skill_name)
if not skill:
return {"error": "未找到该名称对应的Skill, 请传入有效的skill_name参数"}
file_path = f"skills/{user_id}/{skill.id}/{path}"
response = await asyncio.to_thread(
minio.get_object, settings.MINIO_BUCKET, file_path
)
try:
content = response.read().decode("utf-8")
finally:
response.close()
response.release_conn()
return content注入到Agent中
py
# agent.py
...
from app.agent.tools.tool_skill_view import skill_view
async def agent_endpoint(...):
...
agent = create_agent(
...
tools=[skill_view] # 加入到tool中,Agent会自动调用
)
...
执行
对于很多单文件的Skill来说,仅仅一个skill_view工具已够用。想要进一步实现脚本代码的执行等等复杂操作,就需要额外定义一个新的执行工具来实现。
skill_execute 的实现
核心逻辑说明:
- 在沙盒中创建用户独立的工作区目录(简单起见,这里采用的是单沙盒模式,只是简单的将用户工作区按文件夹进行了隔离,这种方案实际上并不能起到多租户隔离的效果。要真正实现生产级的隔离,请控制文件夹权限或者使用gvisor、kata、firecrack等更高级的隔离技术);
- 将minio中的skill文件同步到沙盒中(这里采用的方案是在沙盒内部调用minio sdk,通过sdk直接从minio服务中下载,不通过主应用中转);
- 将llm根据skill生成的执行指令(如
python ./scripts/main.py)交由沙盒实例执行; - 将执行结果返回到Agent上下文中。
py
# tool_skill_execute.py
import asyncio
from langchain.tools import ToolRuntime, tool
from loguru import logger
from minio import Minio
from pydantic import BaseModel, Field
from app.agent.loaders.context_loader import AgentContext
from app.agent.sandbox.client import SandboxClient
from app.core.config import Settings, settings
class SkillExecuteArgs(BaseModel):
skill_name: str = Field(
description="Skill 的名称。如 `webSearch`",
min_length=1,
)
command: str = Field(
description="需要执行的命令。文件路径视 Skill 文件夹为根目录,传入相对路径",
min_length=1,
)
@tool(
args_schema=SkillExecuteArgs,
description="""用于执行 Skill 内部脚本的工具。
# 何时使用
- 需要执行 skill 中的脚本时
# 返回结果说明
- 格式:{"result": "..."}
- result: 返回的结果
""",
)
async def skill_execute(
skill_name: str,
command: str,
runtime: ToolRuntime[AgentContext],
):
if not skill_name:
return {"error": "请传入有效的skill_name参数"}
if not command:
return {"error": "请传入有效的command参数"}
user_id = runtime.context.user_id
minio = runtime.context.services.minio
sandbox = runtime.context.services.sandbox
skill_registry = runtime.context.skill_registry
skill = skill_registry.get("by_name", {}).get(skill_name)
if not skill:
return {"error": "未找到该名称对应的Skill, 请传入有效的skill_name参数"}
sandbox_workspace_dir = f"workspace/{user_id}"
await _ensure_path(sandbox, sandbox_workspace_dir)
skill_path = f"skills/{user_id}/{skill.id}/"
sandbox_skill_path = f"{sandbox_workspace_dir}/skills/{skill.name}/"
try:
await sandbox.make_dir(sandbox_skill_path)
await sandbox.download_prefix_from_minio(
prefix=skill_path,
sandbox_dir=sandbox_skill_path,
)
except Exception as e:
logger.error("skill sync failed skill={} error={}", skill_name, e)
return {"error": f"Skill 同步到沙箱失败: {e}"}
try:
result = await sandbox.execute(
command=command, exec_dir=sandbox_skill_path
)
return {"result": result}
except Exception as e:
print(e)
return {"error": "内部执行失败,无需自动重试"}
async def _ensure_path(sc: SandboxClient, path: str):
try:
is_workspace_exist = await sc.check_path_exist(path)
if not is_workspace_exist:
await sc.make_dir(path)
except Exception as e:
logger.error("ensure_workspace", f"path: {path}", e)
raise
return path注入到Agent中
py
# agent.py
...
from app.agent.tools.tool_skill_execute import skill_execute
async def agent_endpoint(...):
...
agent = create_agent(
...
tools=[skill_view,skill_execute] # 加入到tool中,Agent会自动调用
)
...
尾声
至此,我们从 Tool 的边界 出发,说明了 Agent 为何需要 Skill 这一更高层的能力封装,并沿着 发现 → 激活 → 执行 三阶段,梳理了在 LangChain 服务端场景下的典型落地方式:
- 发现 :从数据库加载已审核 Skill 的
name/description,注入 System Prompt,并把skill_registry放入AgentContext; - 激活 :通过
skill_view按需读取 MinIO 中的SKILL.md及其他文件,把完整指令带入上下文; - 执行 :通过
skill_execute将 Skill 同步到沙箱并在隔离环境中运行脚本,再把结果写回对话。
这套设计的核心仍是 渐进式披露:启动时只暴露少量元数据,任务匹配后再加载知识与运行时,从而在工具规模变大时,缓解上下文膨胀、流程编排和宿主机依赖三类问题。
需要说明的是:文中大部分代码为示意性伪代码,便于理解流程与分层。若要在生产环境落地,还需补齐上传校验、审核流转、租户隔离、沙箱安全策略等治理层能力------这些与 Agent 推理链相关,却是服务端系统不可或缺的一环。
如果你正在设计自己的 Agent 平台,不妨先问三个问题:Skill 存在哪、何时进入上下文、脚本在哪跑。本文的三层架构与两个元工具,即是针对这三个问题的一种参考答案。