SenseVoice 不只是 ASR:把语音从"转文字"升级成"理解状态"
TL;DR
- 场景:在 AI 语音机器人/智能客服/会议助手/智能硬件中,普通 ASR 只能给出文字,会丢失语种、情绪、环境声音等语音侧信息,导致下游 LLM 缺乏关键上下文。
- 结论:SenseVoice 不是 Whisper 的替代品,而是阿里通义实验室 2024 年开源的轻量级多任务语音理解模型,提供 ASR + LID + SER + AED 四类能力,适合作为语音交互系统的"语音侧 Sidecar"。
- 产出:四类能力对比表;三种工程位置方案(主 ASR / Sidecar / 离线分析);主从异步推荐架构与数据结构;SER/AED 工程化使用边界;与主 ASR 的协作模式。
版本矩阵
| 项目 | 状态 | 说明 |
|---|---|---|
| 阿里通义 FunAudioLLM 体系 2024-07 开源 | ✅ 已验证 | 阿里通义实验室 2024 年 7 月发布,项目地址 github.com/FunAudioLLM |
| SenseVoice-Small 支持 5 种语言 | ✅ 已验证 | 中文、英文、粤语、日语、韩语 |
| SenseVoice-Large 支持 50+ 种语言 | ✅ 已验证 | 中文、粤语识别较 Whisper 提升 50%+ |
| 40 万小时训练数据 | ✅ 已验证 | 官方仓库与 ModelScope 模型卡披露 |
| 10s 音频推理约 70ms | ✅ 已验证 | 非自回归端到端架构,15 倍优于 Whisper-Large |
| 四类能力 ASR/LID/SER/AED | ✅ 已验证 | 官方 README 与 ModelScope 模型卡明确列出 |
| 阿里云百炼 sensevoice-v1 将于 2026-03-09 下线 | ✅ 已验证 | 阿里云 2025-11-13 公告,建议迁移到 fun-asr、fun-asr-mtl、qwen3-asr-flash |
| 情绪/事件检测可达到专业 AED 模型水平 | ⚠️ 待验证 | 官方 README 提醒在专业环境声分类任务上仍有差距,适合做辅助状态 |
| SER 标签与心理学情绪一一对应 | ❌ 不成立 | 官方与社区一致建议把 SER 当弱信号,不做事实级判断 |
SenseVoice 不只是 ASR:把语音从"转文字"升级成"理解状态"

做 AI 语音对话系统时,很多人会先把语音识别理解成一件事:
text
把用户说的话转成文字。这个理解没有错。ASR 的核心任务确实是把音频转换为 transcript。问题是,真实的人机语音交互里,系统真正需要的并不只有"用户说了什么"。
在一个语音机器人、客服机器人、会议助手或智能硬件里,系统还会关心:
text
用户说的是中文、英文、粤语,还是中英混杂?
用户是在平静说话,还是带着明显不耐烦?
背景里有没有笑声、咳嗽、音乐、掌声?
这段音频到底是有效语音,还是某种环境事件?这些信息如果只靠普通 ASR,很容易丢失。ASR 最终给下游大模型的通常是一段文本,而文本会天然抹掉语音里的语气、节奏、能量、环境声音和非语言事件。
SenseVoice 有意思的地方就在这里:它不是一个只做 speech-to-text 的模型,而是更接近一个轻量级语音理解模型。根据官方仓库和模型卡描述,SenseVoice 覆盖自动语音识别、语种识别、语音情绪识别和音频事件检测,也就是 ASR、LID、SER、AED 这几类能力。
换句话说,它想补上的不是"转写能力"这一点,而是语音交互系统里经常缺失的语音侧上下文。
1. SenseVoice 是什么?
SenseVoice 来自 FunAudioLLM 体系。FunAudioLLM 可以粗略理解成一组面向自然语音交互的模型能力,其中 SenseVoice 负责语音理解,CosyVoice 负责语音生成。
可以简单拆成:
text
SenseVoice:听懂音频
CosyVoice:生成语音SenseVoice 的核心任务不止 ASR。官方介绍里明确提到它具备多种语音理解能力:
text
ASR:Automatic Speech Recognition,自动语音识别
LID:Language Identification,语种识别
SER:Speech Emotion Recognition,语音情绪识别
AED:Audio Event Detection,音频事件检测因此,它更适合被放在"语音理解前端"的位置,而不是简单被当成另一个 Whisper 替代品。
普通 ASR 的输出可能是:
json
{
"text": "今天青岛天气怎么样"
}而 SenseVoice 这类语音理解模型在工程系统里更有价值的输出形态,应该类似:
json
{
"text": "今天青岛天气怎么样",
"language_hint": "zh",
"emotion_hint": "neutral",
"audio_event_hint": null,
"raw_tags": {},
"source": "sensevoice"
}重点不在于字段名是否完全一致,而在于它给下游系统多提供了一层"语音侧 metadata"。
同一句话:
text
你怎么又坏了?如果只看文字,它可能是普通询问,也可能是抱怨。
如果语音侧提示是 angry,系统可以认为用户可能已经不耐烦,回答应该更短、更直接。
如果音频事件里有 laughter,这句话又可能只是玩笑式抱怨。
这就是 SenseVoice 和普通 ASR 的核心区别:普通 ASR 主要回答"说了什么",SenseVoice 试图额外回答"怎么说的"和"环境里发生了什么"。
2. 四类能力分别有什么用?

2.1 ASR:把语音转成文字
ASR 仍然是 SenseVoice 的基础能力。没有可用 transcript,后面的语音交互链路也很难成立。
SenseVoice-Small 官方模型卡强调了多语言识别、低延迟和非自回归端到端架构。对原型系统、本地轻量转写、语音助手、实验型机器人来说,它可以作为一个比较轻的主 ASR 起点。
但这里要有边界感。
如果系统目标是极致 ASR,比如复杂口音、强噪声、长音频、高并发、生产级流式识别、严格转写准确率,仍然需要对比更专注的 ASR 方案,例如 Whisper large-v3、Paraformer、云厂商 ASR 或其他新的专用 ASR 模型。
SenseVoice 的亮点不是"永远替代所有 ASR",而是"在转写之外,还能给出更多语音理解信号"。
2.2 LID:识别用户正在说什么语言
语种识别在真实语音交互里很实用。
用户并不总是严格使用一种语言。尤其在开发者、留学生、跨境客服、多语言家庭和智能硬件场景里,中英混杂很常见:
text
今天天气怎么样?
What's the weather today?
帮我 open the door如果语音前端能返回 language hint,下游可以做很多策略分流:
text
选择不同语言的系统 prompt
选择不同语言的 TTS 音色
决定是否触发翻译
判断是否进入多语言模式
给 ASR 或 LLM 增加语言约束语种信息不一定决定最终答案,但它可以减少下游误判。
2.3 SER:识别语音里的情绪线索
语音情绪识别是 SenseVoice 最有工程想象力的部分之一。
注意,它不是根据文本判断情绪,而是根据音频的声学特征给出提示。比如语调、语速、能量变化、停顿方式,都可能影响模型判断。
常见标签可能包括:
text
neutral
happy
angry
sad
surprised
fearful
disgusted不同模型版本、不同部署方式和后处理逻辑可能会有差异,所以工程上不应该把标签体系写死成业务事实。
更关键的一点是:
text
语音情绪识别只能作为弱信号,不能当成事实。错误用法是:
text
emotion_hint = angry
→ 大模型直接说:我理解你现在非常生气......更好的用法是:
text
emotion_hint = angry
+ 文本包含否定
+ 同一意图重复两次
→ 回答更短,直接给解决步骤,减少寒暄也就是说,SER 不应该让机器人"表演共情",而应该影响交互策略。
2.4 AED:识别音频事件
真实环境里不只有人声。语音机器人现场会遇到:
text
笑声
咳嗽
掌声
音乐
哭声
呼吸声
喷嚏
背景噪声
TTS 外放残留如果系统只做 ASR,这些声音可能被忽略,也可能被错误转写成文本,再被大模型误认为用户指令。
SenseVoice 的音频事件检测可以作为过滤信号。例如:
text
event_hint = music
text 为空或置信度低
→ 不进入 LLM
event_hint = cough
text 很短
→ 不触发工具
event_hint = laughter
text 不完整
→ 不作为正式指令官方 README 也提醒过,SenseVoice 虽然可以做事件检测,但在专门的环境声分类任务上,与专业 AED 模型仍存在差距。这一点反而很重要:它适合做语音交互里的辅助状态,不适合被神化成通用音频理解系统。
3. SenseVoice 在语音机器人里的工程位置
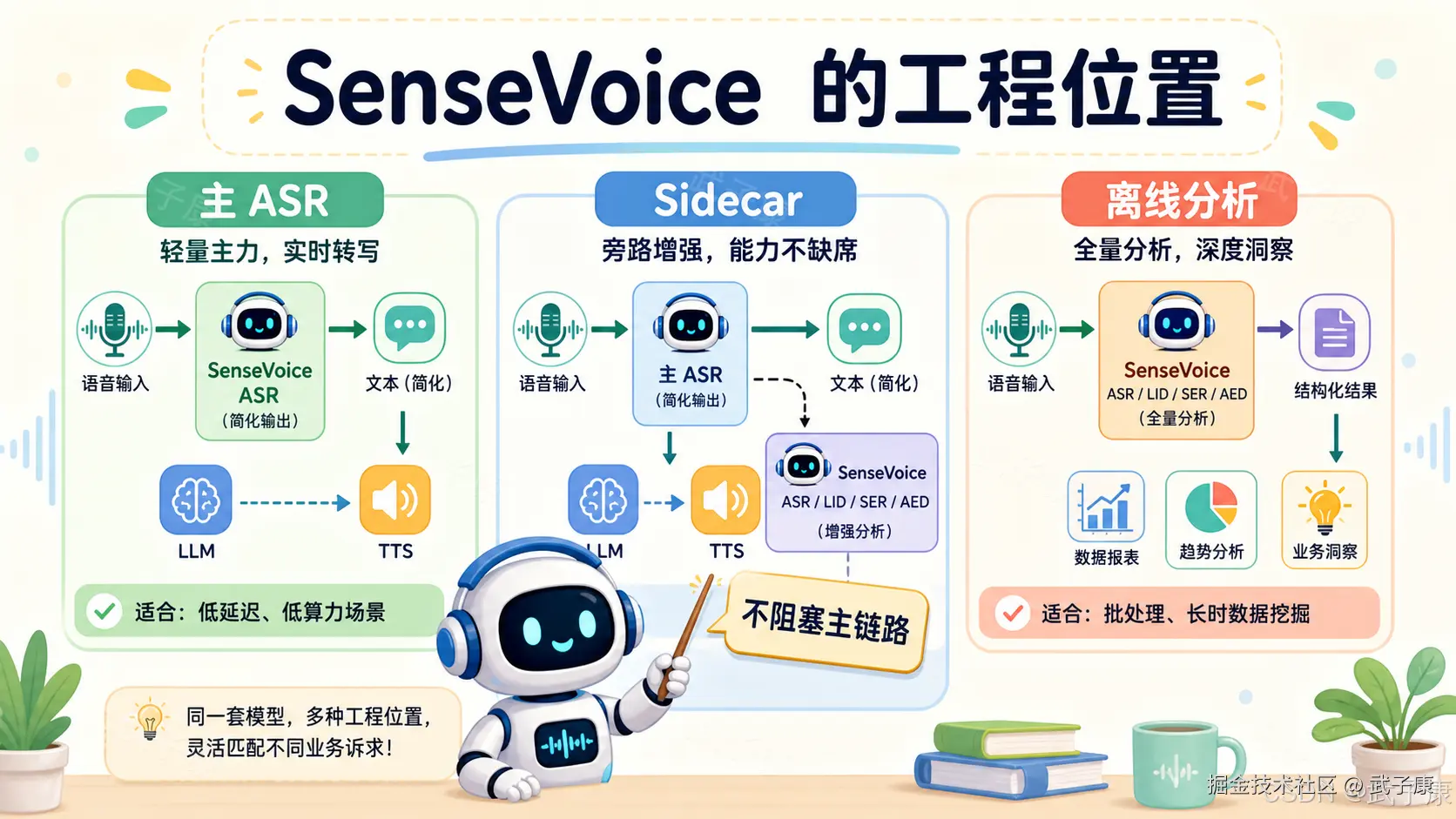
从工程架构看,SenseVoice 至少有三种放法。
3.1 作为轻量级主 ASR
如果系统处在原型期,或者对主转写的生产级要求还没那么高,可以直接把 SenseVoice 放在主链路上:
text
音频输入
→ SenseVoice
→ text
→ LLM / Agent
→ TTS这种方式简单、接入快、链路短。对于本地 demo、轻量机器人、语音助手原型,它很合适。
但一旦系统进入生产,就要重新评估几个问题:
text
长音频如何切分?
强噪声下转写是否稳定?
是否需要流式首字延迟?
是否需要高并发服务化?
是否需要专门的热词、数字、实体优化?如果这些要求变得很重,主 ASR 可能需要换成更专门的服务。
3.2 作为语音理解 Sidecar
更推荐的生产化用法,是把 SenseVoice 作为异步辅助服务。
例如系统已经有一个更强的主 ASR:
text
音频输入
├── 主 ASR:负责 transcript
└── SenseVoice:负责 emotion / event / language hint主路径:
text
主 ASR text → LLM / Agent → TTS辅助路径:
text
SenseVoice metadata → Turn Merger / Trace / Interaction State这类架构的原则是:
text
主 ASR 决定用户说了什么
SenseVoice 补充用户怎么说、环境里发生了什么SenseVoice 的结果不应该阻塞主链路。如果主 ASR 已经返回,SenseVoice 还没返回,可以直接跳过本轮辅助信息;如果 SenseVoice 晚到,可以写入 trace,用于下一轮策略或离线分析。
这比把所有能力都塞进一个同步调用里更稳定。
3.3 作为离线音频质量分析工具
SenseVoice 还可以不参与在线链路,而是用于离线分析。
例如把历史语音交互数据跑一遍,统计:
text
哪些场景用户容易出现负面语气?
哪些指令经常伴随重复提问?
哪些环境噪声容易导致 ASR 错误?
哪些机器人动作触发后用户更容易打断?
哪些音频事件最容易造成误识别?这对机器人产品迭代很有价值。
很多时候,AI 语音系统的问题并不只在模型,而在"没有观察到失败发生在哪里"。SenseVoice 提供的语音侧标签,可以帮你把语音交互日志从纯文本日志升级成多模态交互日志。
4. 推荐的系统架构
一个更稳的工程结构可以这样设计:
text
Audio Gateway
├── VAD / 音频分段
├── 主 ASR 服务
│ └── 输出 text / language
├── SenseVoice Sidecar
│ └── 输出 emotion / event / raw tags
├── Turn Merger
│ └── 合并 transcript 和 speech metadata
├── LLM / Agent / Tool
└── TTS关键原则是:
text
主 ASR 是同步关键路径
SenseVoice 是异步辅助路径工程上可以设置一个很小的等待窗口:
text
如果 SenseVoice 在预算内返回,就合并 metadata。
如果超时,就本轮不使用。
如果晚到,就写 trace 或用于下一轮。推荐的数据结构可以这样设计:
json
{
"user_text": "你怎么又坏了",
"asr": {
"provider": "main_asr",
"language": "zh",
"latency_ms": 180
},
"speech_metadata": {
"source": "sensevoice",
"language_hint": "zh",
"emotion_hint": "angry",
"audio_event_hint": null,
"raw_text": "...",
"tags": {},
"latency_ms": 120,
"status": "ok",
"confidence_policy": "weak_signal"
}
}然后在系统 prompt 或 Agent policy 里明确写:
text
speech_metadata 是语音侧弱信号,只用于调整交互策略。
不要把 emotion_hint 当作确定事实。
当文本语义和 emotion_hint 冲突时,以文本语义为主。
涉及高风险动作时,必须以文本确认和业务状态为准。这条约束很重要。
否则大模型很容易过度解读情绪,把一个弱标签放大成"用户现在一定很愤怒",最终回复会显得不自然。
5. 更有价值的是 Interaction State
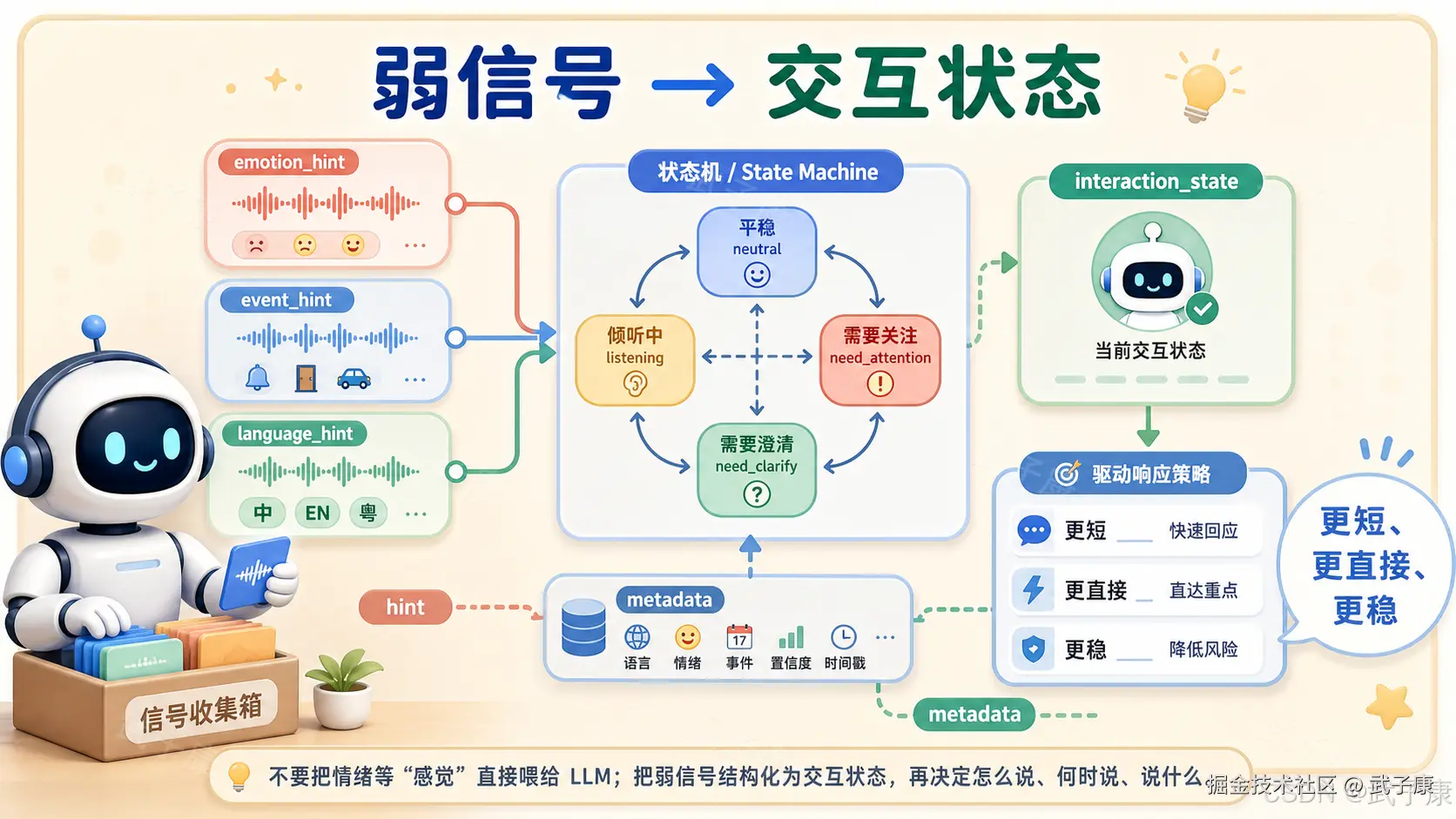
SenseVoice 的输出不应该只是被塞进 prompt:
text
用户情绪:angry更好的做法,是把这些信号和上下文一起转成系统状态。
例如:
text
emotion_hint = angry
+ 用户连续两次否定
+ 同一 intent 重复
+ 工具调用失败一次
→ interaction_state = frustrated然后策略变成:
text
回答变短
直接给步骤
减少寒暄
必要时复述确认
降低 TTS 语速
禁止开玩笑
高风险动作再次确认一个更实用的状态机可以包含:
text
normal
confused
frustrated
interrupted
noisy_environment
uncertain_command
high_risk_commandSenseVoice 的情绪和事件信息,只是状态机的输入之一。真正决定系统行为的,应该是:
text
文本语义
历史轮次
工具调用结果
用户重复次数
语音情绪提示
音频事件提示
场景风险等级这样做的好处是,模型不会因为一个 angry 标签就开始夸张安慰,而是通过更稳定的策略规则改变交互。
6. SenseVoice 不适合做什么?
任何模型都有边界。SenseVoice 也不例外。
6.1 不要把情绪识别当心理判断
语音情绪识别不是心理诊断。
它最多说明:
text
从音频特征上看,这段语音像某种状态。它不能说明:
text
用户一定生气
用户一定难过
用户一定需要安慰所以在客服、陪伴、医疗、教育等场景中,尤其要避免把情绪标签写成确定事实。
6.2 不要让辅助识别拖慢首响
实时语音对话最怕延迟。
如果主 ASR 已经识别完成,系统却还在等 emotion/event,那么用户会感到卡顿。正确策略是:
text
能拿到就用
拿不到就跳过
晚到就记日志在语音交互里,首响体验通常比"每轮都拿满 metadata"更重要。
6.3 不要默认它适合所有 ASR 场景
SenseVoice 的优势是多任务语音理解,不是无条件成为所有识别任务的最佳选择。
如果你只追求最高转写准确率、强口音鲁棒性、复杂热词、超长音频、强实时流式体验,仍然要把它和专用 ASR 做横向评估。
更合理的判断是:
text
SenseVoice 是很好的语音理解模型,
但不一定永远是最强主 ASR。7. 和 Qwen3-ASR 这类主 ASR 怎么搭配?
如果用一句话区分:
text
主 ASR 更适合做"听清楚"
SenseVoice 更适合做"补充语音状态"在生产系统里,可以这样分工:
text
音频输入
├── 主 ASR:输出可靠 transcript
└── SenseVoice:输出语种、情绪、音频事件等弱信号然后下游合并成:
json
{
"user_text": "不是这个,我说的是回充",
"speech_metadata": {
"emotion_hint": "angry",
"audio_event_hint": null,
"source": "sensevoice",
"confidence_policy": "weak_signal"
},
"interaction_state": "frustrated"
}Agent 不需要"相信用户很生气",只需要知道当前交互可能进入了不耐烦状态,于是减少解释、直接确认动作、必要时复述关键参数。
这才是 SenseVoice 真正适合发挥作用的位置。
8. 总结
SenseVoice 最值得关注的地方,不是"又来了一个 ASR 模型"。
它更重要的定位是:
text
轻量级语音理解模型。它能给语音系统提供:
text
语音识别
语种识别
语音情绪识别
音频事件检测在 AI 语音机器人里,它的价值不是单纯替代主 ASR,而是让系统从"只听文字"升级到"理解语音状态"。
但使用时要保持边界:
text
不要把情绪识别当事实
不要让它阻塞主链路
不要用它替代所有专用 ASR
不要把 metadata 直接变成大模型表演素材如果系统还处在原型期,SenseVoice 可以直接作为主 STT。
如果系统进入生产化,尤其已经接入更强的主 ASR,那么 SenseVoice 更适合作为异步语音感知 Sidecar:
text
主 ASR 负责听清楚用户说了什么;
SenseVoice 负责补充用户怎么说、环境里发生了什么。它能拿到信息,就增强上下文。
拿不到,就跳过。
这是它在真实语音系统里的最佳位置。
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
把 emotion_hint=angry 当事实写进 prompt |
误把语音弱信号当业务事实 | 大模型回复出现"我理解你现在很生气"等共情台词 | 改为"speech_metadata 是弱信号,不作为事实" |
| 让 SenseVoice 阻塞主 ASR 链路 | 同步等待 SER/AED 结果 | 首字延迟从 200ms 涨到 1s+ | 主 ASR 同步、SenseVoice 异步,超时即跳过 |
| 把 SenseVoice 写成 Whisper 替代品 | 忽略它是"多任务语音理解"而非"更强 ASR" | 转写准确率在强噪声/口音场景明显下滑 | 区分主 ASR 与 Sidecar 角色,生产用专用 ASR |
| 把 AED 当通用环境声分类模型 | 误用 SenseVoice 替代专业 AED | 专业环境声任务(如工业声学)准确率不足 | 写"辅助过滤信号,不做通用 AED" |
| 写"SenseVoice-v1 长期可用" | 忽略阿里云百炼下线公告 | 阿里云 2025-11-13 公告 sensevoice-v1 将于 2026-03-09 下线 | 写"已上线业务建议迁移到 fun-asr / fun-asr-mtl / qwen3-asr-flash" |
| 情绪标签与心理学情绪一一对应 | 误把 SER 当成心理诊断 | 客服/陪伴/医疗场景出现过度共情 | 写"SER 只能作为弱信号,不可作为事实级判断" |
单一 angry 标签直接驱动 TTS 语速/语气 |
没有 interaction_state 状态机 | 不同情绪标签直接拼接到 prompt | 用 emotion + 文本 + 重复次数 + 工具结果联合生成 interaction_state |
| 把 SenseVoice 输出当成 LLM 主输入 | 把 metadata 抬高到与 text 同等地位 | 大模型过度解读情绪标签 | 明确"以文本语义为主,metadata 只调整交互策略" |
作者:武子康的个人博客