你有没有过这种经历?
用 AI 写代码,认真梳理完思路、写完一整段提示词,发送之后只能干等。少则几十秒,多则几分钟,屏幕上什么都看不到。你不知道模型怎么拆解你的需求,不知道它悄悄脑补了什么前提、曲解了哪些约束。只能等它全部输出完,回头一看:坏了,跑偏了。
前面等的那些时间全部白费。你要么清空上下文从头来,要么在多轮对话里一点点掰正它。大量时间耗在纠错上,而不是做正事。
吃过亏之后,你开始事无巨细地把边界条件、隐含逻辑全塞进提示词,试图堵死模型乱猜的空间。但写提示词的成本陡增,而且你还是没法提前知道它到底理解对了没有。问题没解决,只是换了个形式。
Andrej Karpathy 也吐槽过:
模型代表你做出错误假设,然后就径直跑下去而不检查。它们也不会管理自己的困惑,不会寻求澄清,不会显示不一致之处,不会呈现权衡,不会适时反推,而且它们还是有点太谄媚了。
现在行业里流行 SDD(Spec-Driven Development,规格驱动开发),提前写 Spec 文档明确需求边界,能减少歧义。但这套流程有个盲区:你写清了规格,但没法提前确认 AI 是不是真的读懂了、会不会严格遵循。理解偏差还是要等代码写完才暴露。
我今天要说的项目 Understand First,就是解决这个问题的:强制 AI 在执行任务之前,先完整输出它对提示词的理解。不用等漫长的生成结束,你马上就能看到它接下来要做什么,有没有曲解你的意思、有没有擅自加戏。发现偏差立刻纠正,不用事后返工。
效果是这样的:

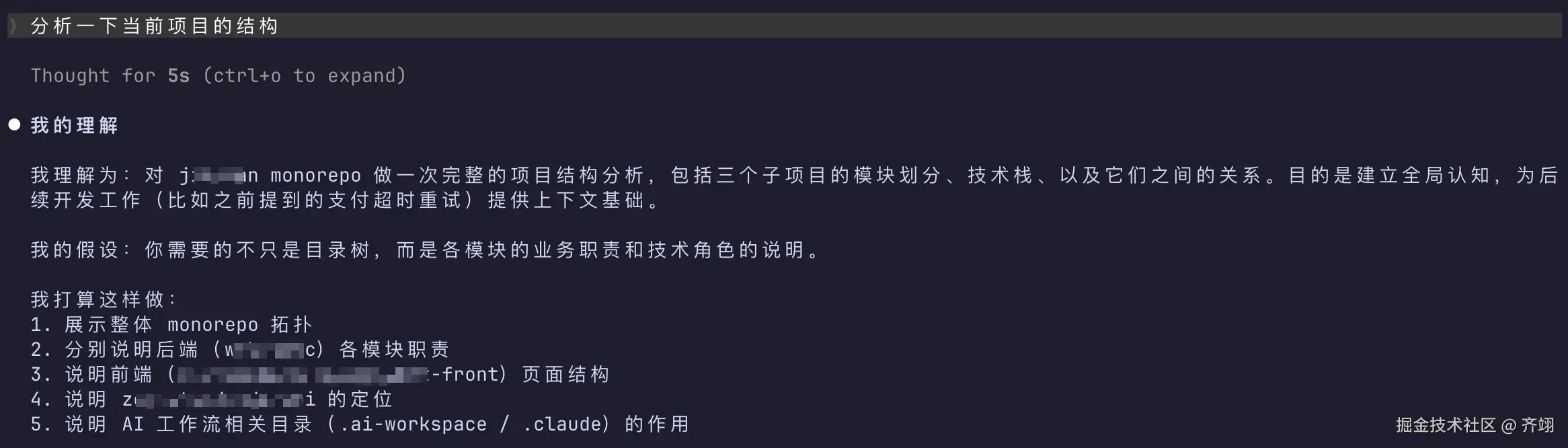
这篇文章不聊大道理,就带你看看我真实的打磨过程。
先交代背景:整个项目,内容全是 Claude Code 写的,我就是个聊天工程师。我的工作就是发现问题、描述清楚、审查结果、做决策。下面的每一轮迭代,都是我跟 Claude Code 聊出来的。
第一版:4 个字段,能跑,但不够
最开始的想法很朴素,在 CLAUDE.md 里加一段话,让 AI 每次回复前先说说它理解了什么。
我把想法描述给 Claude Code,它帮我生成了第一版协议,4 个字段:
markdown
输出格式:
- 你输入:[用户的原话]
- 我理解为:[意图描述]
- 我的假设:[推断补全的内容]
- 我打算这样做:[步骤]效果立竿见影,AI 开始主动展示理解了。但跑了几轮,我发现一个问题。它展示的是这种:
csharp
你输入:"修一下代码里的空指针"
我理解为:需要修复代码里的 NullPointerException,定位到出错位置后做空值判断处理
我的假设:可能是某个方法返回了 null 值
我打算这样做:找到 NPE 的位置,修掉它没说错,但也没说任何我想不到的东西。我不知道它到底定位到了哪个方法、哪一行、推测的原因是什么。看完我还是不知道它是不是真的理解了,还是只是泛泛而谈。而且"你输入"这个字段纯属废话,我刚敲完的字,你再复述一遍有什么意义?
我把这个反馈给 Claude Code:"理解太浅了,没有增量信息,而且'你输入'这个字段是废话"。它给我加了一条质量底线,配了一个正反对比示例:
arduino
❌ 浅层理解(没有增量信息):
"我理解为:修复 OrderSvc 里的 NPE bug"
→ 用户看完不知道 AI 是否真的定位到了具体问题
✅ 深度理解(展示推理):
"我理解为:修复 OrderService.calculateTotal() 中的 NullPointerException。
假设 NPE 来自 item.getPrice() 而 item 为 null,而非参数传入 null。"
→ 定位了具体方法、推测了具体原因跟 AI 说"你要深度理解"没用,太抽象了。给它看一个坏例子和一个好例子,它立刻就知道差距在哪。
第二版:加人设、加推断、加风险检测
第一版跑通后,我开始系统性审视。做了五件事:
第一,删掉"你输入",加上"我的定位"。 AI 默认用"热心助手"的口吻,缺乏专业立场。比如"给订单系统加缓存",一个通用的"我来帮你"和一个有立场的"我是关注数据一致性的后端架构师,我来帮你",产出的方案质量完全不同。我让 Claude Code 加了一个角色字段,但配了一个重要的逃逸机制:无事则省略。不是每个任务都需要角色锚定,"修一下这个 CSS 对齐"不需要"专注 Flexbox 布局的前端专家"。
第二,加了"我的推断"字段。 AI 在补全用户没说清的内容时,应该显性标注出来,让用户一眼看出哪些是原意、哪些是 AI 自己补的。比如用户说"优化一下这个 API",AI 推断为"加 Redis 缓存,用 Cache-Aside 模式",这个推断过程必须可见。
第三,加了"不确定的是"字段。 有些时候,用户的描述确实存在歧义,不同的理解会导致完全不同的执行路径。比如用户说"重构这个模块",可能是指拆分成更小的函数,也可能是指换一套设计模式。这种情况 AI 应该老实说出来,而不是自己闷头选一个方向。这个字段也是无事则省略。
第四,加了"约束"字段。 项目上下文里有很多隐含约束,框架、约定、技术栈,AI 默认会遵守,但用户未必知道 AI 是否意识到了这些约束。显性标注出来,用户一眼就能确认 AI 没有跑偏到不兼容的技术方案上。
第五,加了风险检测。 这是我在实际使用中踩了坑才意识到的。有次我说"给这个 API 加个接口",Claude Code 照着做了,但它没提醒我这个接口没有鉴权、没有分页、没有限流。这不是 AI 理解错了,而是我的规格本身就不完整。我让 Claude Code 加了一个"⚠️ 需要注意"字段,放在模板最后,它是 AI 动手前用户看到的最后一样东西,也是最关键的决策卡点。
接着我又想:如果风险很高(不可逆、影响范围大),AI 展示完就继续执行,用户可能根本没注意到。于是加了一个暂停条件:高风险时,AI 必须停下来等用户确认。低风险则展示警告后继续,这避免了"每次都问一遍 Are you sure?"的烦躁感。
到这里,协议字段从 4 个变成 8 个,还多了暂停逻辑。我觉得差不多了。
第三版:ChatGPT 的评审让我学会"少即是多"
我把当时的方案发给 ChatGPT 评审,它指出了两个问题:
问题一:触发条件模糊。 什么叫"需要执行动作的指令"?分析架构算不算?评价方案算不算?它建议加一个明确的排除列表:纯信息查询、状态确认、简单续写、闲聊不触发。
问题二:缺少 Complexity Gate。 简单任务和复杂任务应该有不同的输出深度。它建议了 5 条具体标准:多执行路径、架构权衡、多文件改动、不可逆操作、跨模块影响。
我让 Claude Code 按照这两个建议改了。但很快发现不对劲。
排除列表造成了大量漏判。 我试了之后意识到,95% 的 Claude Code 输入都是可执行的。"这个文件干什么的"表面是信息查询,实际需要读代码、做分析,这本身就是执行。而且"什么算可执行"这个判断本身就给模型增加了不必要的分类负担。我把触发条件改回了"每次用户输入都触发"。
5 条具体标准太严格了。 70-80% 的任务会掉进"简单"分类,协议价值被稀释。而且模型自己判断"修 typo"和"重构认证模块"的区别,根本不需要我教。我让 Claude Code 回到了简单的"简单任务 2-3 行,复杂任务完整展开"。
这次经历让我学到一个关键教训:好的协议给方向,不给刻度的尺子。加上去的东西,不一定就该留着。敢于 revert 和敢于加新功能一样重要。
软协议不够硬:Hook 的引入
协议打磨得差不多了,但测试中发现一个严重问题:CLAUDE.md 是软协议,AI 大概率遵守,但不保证。
我开了好几个新会话测试,发现有时 AI 完全不展示理解,直接动手干活。我反复追问:"为什么这次没触发?""这个新会话为什么没生效?"最终定位到问题:当系统提示词很长时,CLAUDE.md 的指令在注意力竞争中落败了。
于是我让 Claude Code 引入了 Claude Code Hook。UserPromptSubmit 是 Claude Code 的生命周期事件,每次用户提交提示词时无条件触发。Hook 通过 additionalContext 注入协议全文,前面还加了一段强制执行声明:
csharp
[IMPORTANT - Understand First Protocol Enforcement]
You MUST follow this protocol on EVERY user input. No exceptions.
Skipping the understanding step is a protocol violation.Hook 是硬性注入,CLAUDE.md 是软性锚定。两者配合:Hook 在每次交互时注入协议,CLAUDE.md 在会话启动时做锚定。双保险。
最后一公里:安装脚本
有了 Hook 机制,下一步是让安装尽可能简单。我跟 Claude Code 讨论了好几轮安装脚本的设计:
- 协议直接嵌入 Hook 脚本内部,不依赖外部文件,Hook 是自包含的
- 从 GitHub 拉取 CLAUDE.md 作为单一事实来源,不重复维护
- 安装脚本做幂等处理,重复安装不会产生冲突
最终,安装只需要一行命令:
bash
curl -fsSL https://raw.githubusercontent.com/luckybilly/understand-first/main/hooks/install.sh | sh最终成品
反复打磨后的协议完整版就 50 行。开源在 GitHub:
如果你觉得有用,点个 Star ⭐ 让更多人看到,这可能是我继续打磨的最大动力。
结语
这个项目不大,全程我没写一行内容,都是通过与 Claude Code 聊天生成的,包括这篇文章也主要是由 AI 整理我的 claude code 对话日志生成,然后我再手工微调而成的。
但我的工作并没有少:发现问题、描述清楚、审查结果、做决策。代码是 AI 写的,判断力是我的。
它解决的是所有 AI 辅助工作中的一个通用问题:AI 越来越强,但"理解偏差"这件事不会自动消失。如果不主动设计检查机制,偏差只会在更快的速度下造成更大的浪费。