上一篇讲 explain 时,提到一个理想状态:totalDocsExamined = 0。意思是查询根本没回表读文档,所有需要的数据都在索引里拿到了。这个状态叫覆盖查询(covered query),是 MongoDB 查询优化的一个重要终点------它把查询从「索引定位 + 回表读取」压缩成「索引定位即完成」,少一次 B-tree 跳转、少一次页读取。
但覆盖查询不是免费的,它要求索引里塞进返回字段,索引会变大。所以它不是「所有查询都该追求」的目标,而是「特定高频查询值得做」的优化。这一篇讲清楚覆盖查询怎么达成、有什么前提,以及它和查询路由(readPreference)的关系。
先把机制边界说清楚
普通查询的执行链路是 IXSCAN → FETCH → PROJECTION:先用索引定位到一批 RecordId,再回集合页读完整文档,最后投影出需要的字段。覆盖查询把这个链路缩短成 IXSCAN → PROJECTION:索引条目里已经包含查询条件和返回字段,直接投影返回,跳过 FETCH。
达成覆盖查询的条件很严格:
- 查询条件和返回字段,全部出现在同一个索引里。索引必须有查询用的字段(等值/范围/排序),也必须有要返回的字段。
- 投影显式排除
_id(除非_id在索引里)。_id默认会被返回,而它通常不在业务索引里,所以必须{_id: 0}排除。 - 没有会触达文档的操作。某些情况会强制回表:返回的字段不在索引里、用了某些不能利用索引的操作符、多键索引的数组场景等。
覆盖查询 vs 普通查询
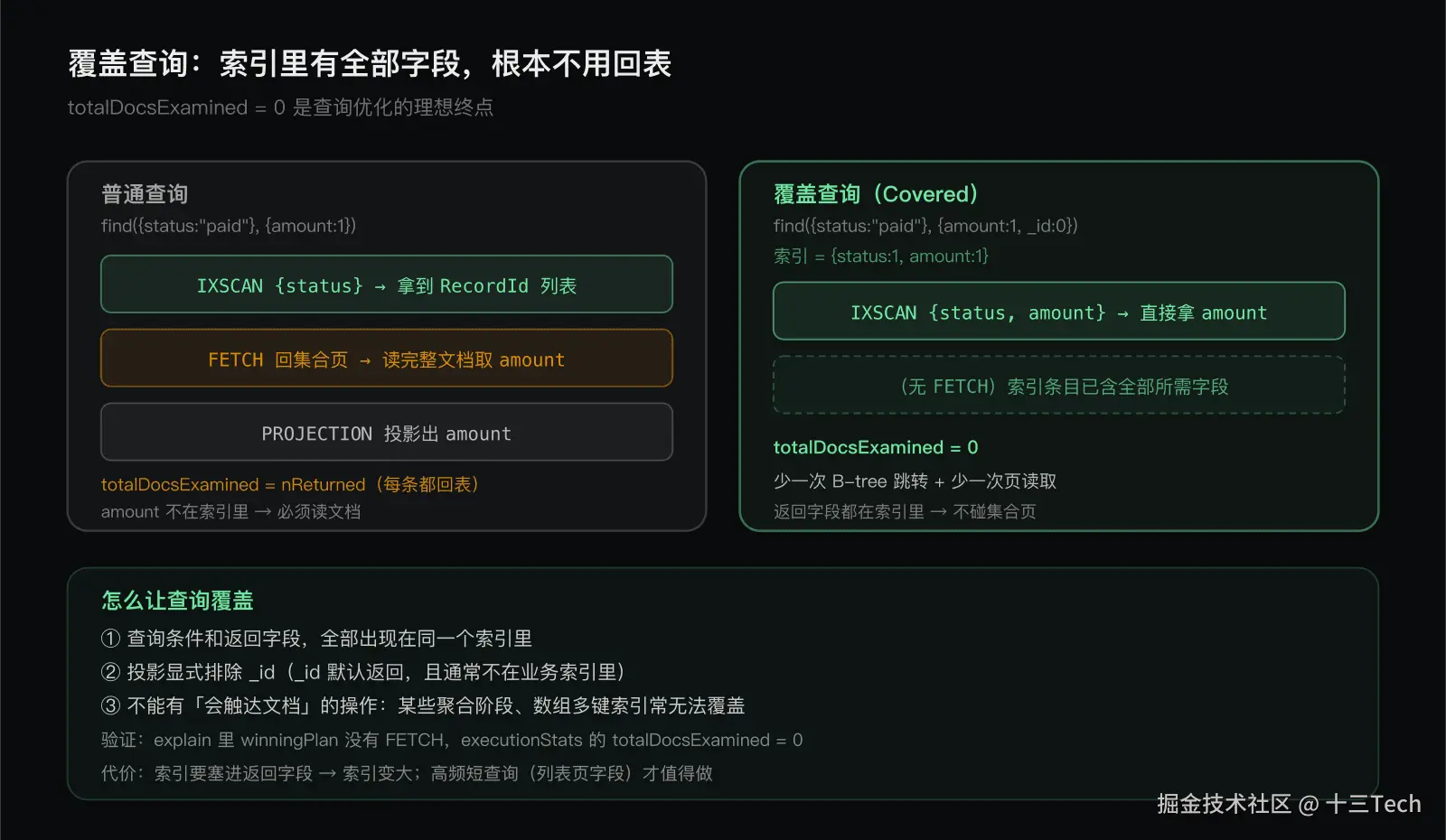
把两种查询的执行链路并排,覆盖查询的优势清晰:少一个 FETCH 阶段,totalDocsExamined = 0。
一个具体的例子
假设有个订单集合,频繁执行的查询是「按状态查订单号和金额」:
javascript
// 普通做法
db.orders.find({ status: "paid" }, { orderNo: 1, amount: 1 })
// 索引:{ status: 1 }
// 链路:IXSCAN(status) → FETCH(回表读 orderNo, amount) → PROJECTION
// totalDocsExamined = 命中数,每条都回表要让这个查询覆盖,把返回字段纳入索引:
javascript
db.orders.createIndex({ status: 1, orderNo: 1, amount: 1 })
db.orders.find({ status: "paid" }, { orderNo: 1, amount: 1, _id: 0 })
// 链路:IXSCAN(status, orderNo, amount) → PROJECTION
// totalDocsExamined = 0,索引条目里就有 orderNo 和 amount验证方法是 explain:winningPlan 里没有 FETCH stage,executionStats.totalDocsExamined 为 0,就说明覆盖成功了。
覆盖查询的代价
覆盖查询不是没有成本。把返回字段塞进索引,意味着:
- 索引变大。索引条目从「status → RecordId」变成「status, orderNo, amount → RecordId」,每个条目多占空间。文档越多,索引膨胀越明显。
- 写入成本上升。索引变大了,维护它的写放大也增加(每个返回字段变化都要更新索引)。
- 索引数量可能变多。不同查询要返回不同字段,可能要为不同查询建不同覆盖索引。
所以覆盖查询不是「能做就做」,而是「高频、返回字段固定、且数量大的查询才值得做」。典型的受益场景:列表页只展示几个字段、状态看板只统计关键字段、高频的配置查询。这类查询执行次数多,省下的 FETCH 累积起来很可观。
反过来,低频查询、返回大量字段的详情页查询,不值得为覆盖查询专门建大索引------直接回表读完整文档更简单。
容易让覆盖失败的几个坑

忘了排除 _id。 这是最常见的失败原因。_id 默认返回,而它通常不在业务复合索引里(除非显式加入),所以只要不 {_id: 0},查询就会因为要返回 _id 而被迫回表。
返回字段里有数组。 多键索引(数组字段)往往无法做覆盖查询,因为索引条目和文档不是一一对应,MongoDB 需要回表确认。
用了某些操作符。 部分操作符(如某些 $expr、$regex 的特定形式)会让优化器无法判断能否从索引取值,退化成回表。用 explain 验证最可靠。
字段不在同一个索引里。 查询条件在索引 A、返回字段在索引 B,不能拼成覆盖查询------覆盖要求所有字段在同一个索引里。
覆盖查询与查询路由
讲完覆盖查询,顺带说查询路由(readPreference),因为它影响「查询发到哪个节点」:
- primary(默认):所有读发到主节点,强一致。
- primaryPreferred:优先主,主挂了读从。
- secondary:只读从节点,分担主节点压力,但可能读到稍旧数据。
- secondaryPreferred:优先从,从都没有才读主。
- nearest:读延迟最低的节点,不管主从。
查询路由和覆盖查询是两个独立的优化维度:覆盖查询优化「单次查询多快」,查询路由优化「查询发到哪、分摊多少负载」。两者可以叠加------比如把统计类查询用 secondaryPreferred 发到从节点,再让它走覆盖查询,既分摊了主节点压力又让单次查询更快。
但要注意:读从节点意味着读到的是稍旧的数据(复制延迟决定的)。对一致性敏感的查询(比如下单后立刻查订单状态),必须读主,不能为了分摊负载读从。
判断框架
- 高频、返回字段固定、数量大的查询 → 值得做覆盖查询,把返回字段纳入索引。
- 低频、返回字段多的详情查询 → 不值得,直接回表。
- 实现三条件:字段在同一索引、排除
_id、避开会触达文档的操作。 - 验证:explain 没有 FETCH、
totalDocsExamined = 0。 - 查询路由是另一个维度:统计类查询可读从,一致性敏感查询必须读主。
- 覆盖查询 + 合理路由 = 查询优化的两个叠加杠杆。
下一篇会把前面讲的所有索引和查询优化知识,收束成一套慢查询排查闭环。
关于十三Tech
All in AI Agent 方向的架构师,专注 AI 工程实践。
相信 AI 是程序员的最佳搭档,帮助每一位开发者驾驭 AI。
公众号搜索「十三Tech」