我和大模型一起做了个本地知识库------用户也是我和大模型(6 个反直觉决策 + 开源公告)
这个项目我自用 3 个月,今天彻底开源(哇库哇库,各路大佬轻喷)。 用户不是只有我,开发者也不只是我------双端都是人 + AI。 6 个反直觉的设计取舍 + 3 个月飞轮跑下来的真实体感,一次讲清楚。
用户不是只有我一个人。除了我自己每天在 web 控制台问业务问题、整理知识,还有我电脑上几个 AI 编程助手通过 MCP 协议自动调它做召回。
开发者也不只是我一个人。产品决策和 review 是我,但每一行代码几乎都是几个 AI 一起敲出来的。
这种「双端都是人 + AI」的项目设计起来有不少反直觉的取舍:有些选择是为了我自己用得舒服,有些是为了 AI 调得顺,少数两者打架的时候要做出明确的偏向选择。这篇文章把这 3 个月的取舍一次讲清楚 + 把项目彻底开源(Apache 2.0)。
技术栈一句话:Python 3.11 + FastAPI + SQLite(数据) + Qdrant 嵌入式(向量) + infinity-emb(本地 embedding 推理,默认;也支持远程 OpenAI 兼容 API)+ bge-m3(默认模型)+ 可选 Rerank(远程 API + 本地词项兜底) + MCP 协议(agent 接入)+ macOS 菜单栏 App / Windows 托盘 App(壳层)。
一、为什么要做:两个痛点撞到了一起
事情起源于两个同时发生的痛点。
痛点一(人侧):业务知识散得到处都是。每天工作里产生的关键信息------某个接口的设计意图、上周和同事拍板的临时决策、踩过的坑的解法、跨项目的对接约定------散落在飞书文档、聊天记录、个人笔记、commit message、自己脑子里。每次想用都得花十几分钟翻来翻去,搜不到的时候就开始重复问同事。
痛点二(AI 侧):每天和几个 AI 编程助手配合开发,同一段架构科普讲三五遍。新开一个会话,AI 不知道我项目的来龙去脉,不知道上周改过的某个临时决策,不知道为什么这块代码要这么写。每次都要从头交代上下文。CLAUDE.md 这种全局配置文件能放一部分静态约束,但放不下"会增长的、临时性的、需要按场景召回的"东西------因为塞进去就一直占 context window,不管这次会话用不用得到。
两个痛点撞到一起的瞬间是这样:那段时间我连续好几个工作日,给同事讲业务背景的话 和给 AI 讲项目背景的话几乎是同一段。区别只是:跟同事讲完他能记住下次不用再讲,跟 AI 讲完它一关窗口就忘。
于是我开始找现成方案:
- 企业 RAG 类(各种知识库 SaaS):核心场景是"团队人员查询",界面、权限、协作都是给"人"设计的,调用层薄;本地化部署成本高;很多还绑死了某家云
- AI 长期记忆方向(mem0 / letta / langmem 等):核心场景是"给 LLM agent 加长期记忆",调用层好但人界面几乎没有;而且偏向 LLM 内部的对话历史压缩,不是"我手动维护的项目知识库"
- 个人笔记 + 全文搜索(各种笔记 App):界面给人爽,但没有给 AI 调用的标准接口;语义检索能力弱
找了一圈,有的工具部分覆盖,但没有完全符合"双端都顺"+"本地优先"两条的------要么是给人的、要么是给 AI 的、要么是上云的。
原本到这一步可以将就用某个最接近的方案。但其实我对 RAG 本身一直挺感兴趣------加上"业务知识不能上云、不要 API key、不要配一堆 env 才能跑"这些约束我自己也是真在意,于是干脆借这个机会自己上手做一个。一边解决自己的痛,一边把 RAG 这套东西真正摸一遍。
自己写又遇到第三个事实:我一个人能力有限,得拉 AI 协作。所以这个项目从第一天起,就是"独立开发者 + 几个 AI 编程助手"共建的。
二、6 个反直觉的设计取舍
写到第三个月我才意识到,给"人 + AI 双端"用的工具,设计取舍跟传统 RAG 完全不一样。把已经定下来的关键决策梳理一遍,发现可以按"为谁优化"分成三类:人和 AI 都受益、主要为 AI 但人能接受、主要为人但 AI 无感。
诚实标出来比"反直觉揭秘"更扎实。
人和 AI 都受益的三个决策
决策 1:默认推荐本地 embedding(同时支持远程 API)
向量化(embedding)这一步是 RAG 的发动机:把"今天天气怎么样"这种自然语言变成一串 1024 维的向量,才能跟知识库里的内容做语义匹配。常见做法是调远程 embedding API(按 token 计费)。
我的取舍是默认推荐本地起一个 embedding 推理服务 (用 infinity 跑 bge-m3 模型,安装一次永久离线可用),同时通过 mode=external 支持调远程 OpenAI 兼容 API(豆包 / Azure OpenAI / 自建 infinity 集群等),让已有部署的用户可以平滑接入。下面 3 条体感说的都是"默认本地"这条路径上的:
- 人侧体感:在 web 控制台问答时延迟稳定在 100ms 内;网络抖动跟我无关
- AI 侧体感:agent 在一次对话里可能召回十几次,每次都要 embedding,远程 API 任何一次抖动都会把整个对话节奏拖垮;本地走 localhost 不存在这个问题
- 共同代价:装一次 4GB 模型(用户主动点"启用本地 embedding"才下,不强制)
技术实现上,infinity-emb 跑在独立 venv 里,由壳层 ProcessManager 通过 reconcile loop 管理:每 3 秒拉一次 desired-state,跟 actual-state 对比后 dispatch install / start / stop / switch_model 之一。kb-api 主服务从不直接 spawn 子进程,所有进程操作集中在壳层。 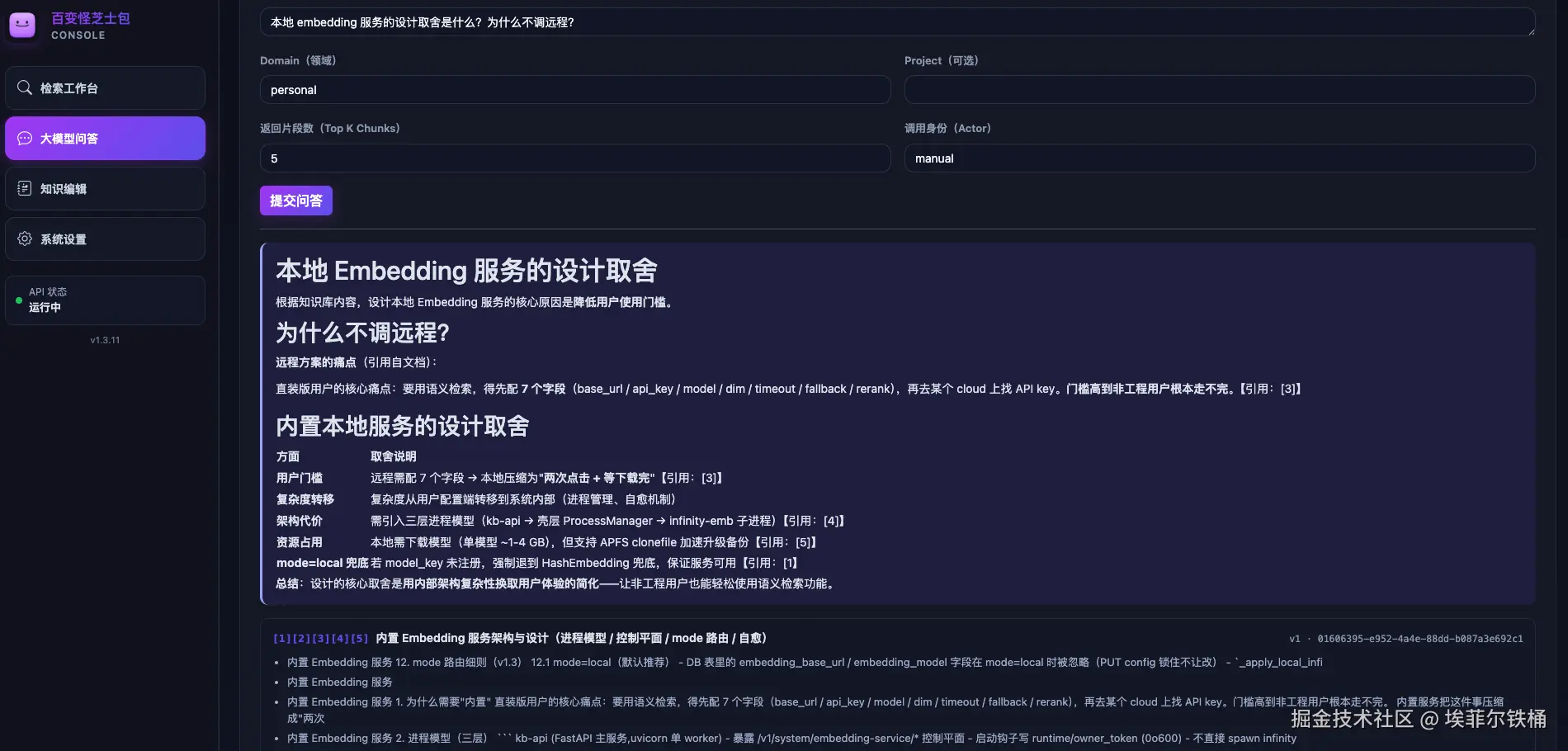
决策 2:嵌入式向量数据库,不上独立 server
向量数据库一般是独立服务(qdrant server / weaviate server / milvus 集群),需要单独部署、单独运维、单独配置。
我用的是嵌入式模式(qdrant 内嵌进主进程,数据落在 SQLite 风格的本地文件)。
- 人侧体感:装完直接跑,没有"还需要 docker compose up 启动数据库"这种额外步骤
- AI 侧体感:agent 在用户机器上工作,希望"装一次就跑",0 运维;如果用户首装还要起个 docker,绝大多数人会直接劝退
- 共同代价:单机单进程,扛不住高并发------但个人 / 独立开发者场景根本碰不到那个量级
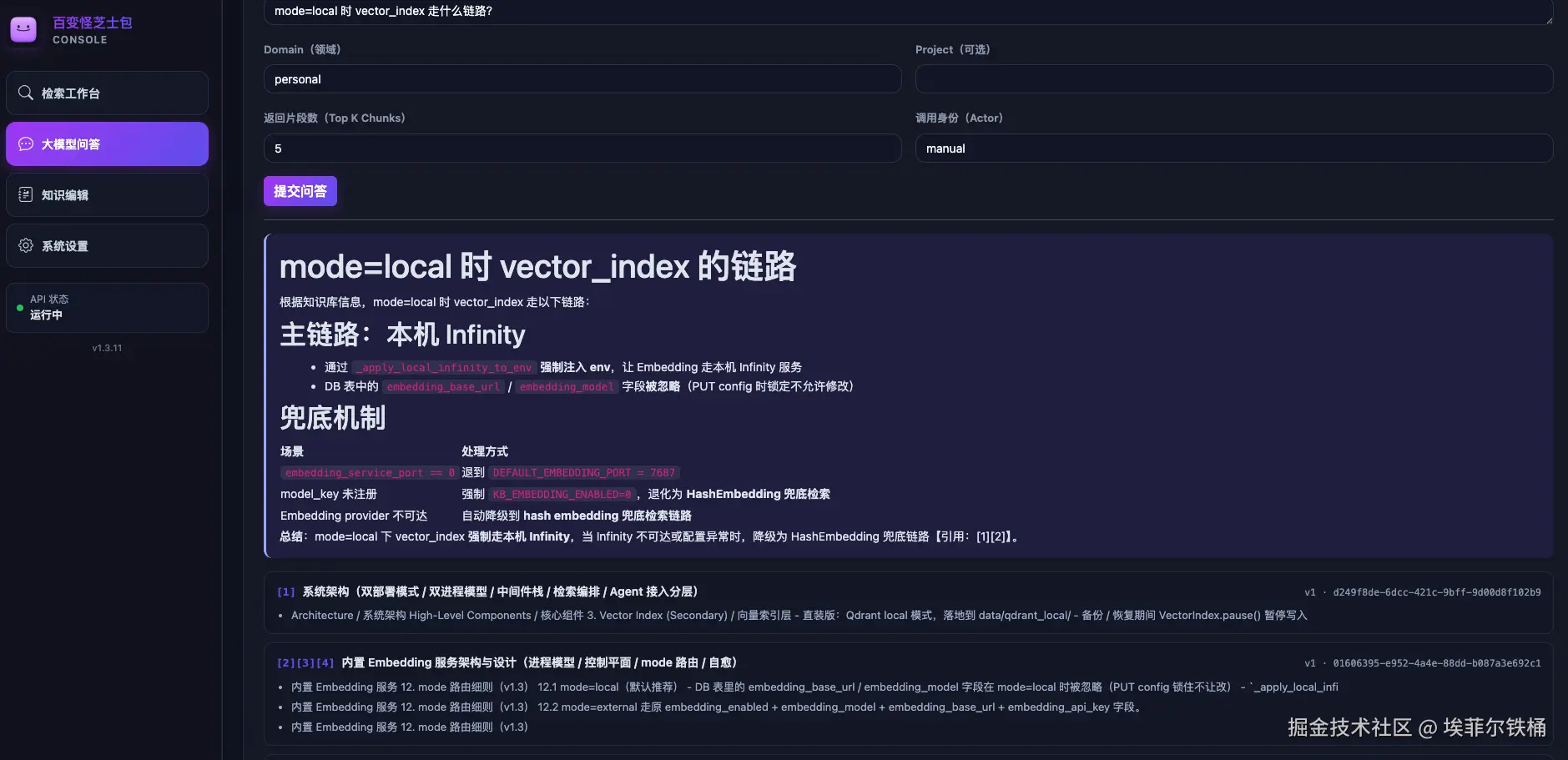
顺便展开一下决策 1 提到的"本地 embedding"在代码里是怎么走的------下面是 web 控制台问"mode=local 时 vector_index 走什么链路"的召回结果,它把
_apply_local_infinity_to_env注入 env + 端口兜底 + model_key 校验全列了出来,3 个引用全是项目自身的设计文档。
决策 3:strict 模式不做 hash 兜底
很多 RAG 实现遇到 embedding 服务不可用时会"优雅降级"到关键词检索(比如基于 hash 词袋的简单 embedding),保证结果还能返。
我刻意不这么做。如果配置的是本地 embedding 服务但服务没起来,重建索引这种关键路径直接报错终止,不允许写"假向量"进库。
- 人侧体感:人能看出"这个搜索结果不太对",但很可能也懒得去校验;万一污染了索引就要全库重建
- AI 侧体感:AI 看不出召回结果质量差,会拿着烂召回的内容生成烂答案,整段对话被污染但用户不知道
- 共同准则:"宁可不返也别返错"
这一条最后救了我两次:装机过程中 embedding 服务还在 warmup 没起来,rebuild 直接被拒绝抛 503,没有抹掉旧索引。如果我当时图省事允许 hash 兜底,整个向量库就被废了。
主要为 AI 优化、人侧能接受的两个决策
决策 4:召回结果默认返 chunk 全文,不返 snippet
搜索引擎给人看的结果一般是 snippet------前后截 50 字、关键词高亮、省略号包裹。
我默认返完整 chunk(300-800 字的一段原文,不截断不高亮)。
- 人侧体感:在 web 控制台看搜索结果的时候,确实比 snippet 冗余,要多拉几下滚轮
- AI 侧体感:agent 拿到完整原文生成答案的质量明显比拿 snippet 高一档(snippet 缺上下文,LLM 会基于断章取义瞎补)
- 取舍:人能接受多拉滚轮,AI 不能接受信息不全 → 选 AI
切块策略也是 heading-aware:先按 Markdown 标题层级分段,再按段落细分;每块保留标题路径作为语境前缀;代码块 fence 内不被误识别为标题(防止 bash 注释 # xxx 被当成 H1);每块最大 800 字符,100 字符重叠。
决策 5:MCP 工具为主入口,控制台是辅助
很多知识库产品把 web 控制台做得很重,AI 集成是事后加的"插件"。
我反过来:MCP 工具是一等公民(agent 自动注册、自动调用、零配置),web 控制台是给我自己偶尔检查数据 / 改配置用的,不放重业务。
- 人侧体感:web 上的功能不如商业 SaaS 丰富,比如没有协作、没有评论、没有版本历史的精美 UI
- AI 侧体感:装完 MCP 一次,所有支持 MCP 的 coding agent 都能直接调,零额外配置
- 取舍:MCP 是越来越多 coding agent 都在支持的标准,押注它的复利远大于多花精力做 web 高级功能
具体分工:MCP 管"能不能做",Skill 管"该不该做、怎么做" 。MCP 暴露的是 search_knowledge / upsert_knowledge / import_incremental_knowledge 等纯工具;Skill 文件(knowledge-base-first/SKILL.md)约束 agent 行为规则(何时查、怎么输出、冲突以谁为准)。
主要为人优化、AI 侧无感的一个决策
决策 6:完整的 web 控制台 + 设置面板
AI agent 用 MCP 完全够了,理论上 web 界面可以砍掉。但我自己也是用户,我需要一个能在浏览器里问业务问题、管理知识条目、看系统状态的可视化入口。
- 人侧体感:能用浏览器直接问"昨天定的某个事情是啥"、能在表格里增删改知识条目、能看到 embedding 服务状态、能切换 mode
- AI 侧体感:完全不用------agent 走 MCP 协议直接调后端 API
- 取舍:纯为我自己使用体验花的精力,承认是"AI 不需要的功能",但因为我是用户之一,做就做完整
三、3 个月之后真的发生了什么
设计取舍讲完,真正有意思的是 3 个月之后回看:「人 AI 双端共建 + 双端共用」这件事自我强化起来了。
开发侧:多个 AI 编程助手并用
这个项目从第一天起就是"多 AI 协作"的产物。我固定用三个 AI 编程助手:一个主写代码 + 两个做交叉审计(用不同的视角看同一段代码,挑刺)。
具体分工:
- 主写:日常开发、调 bug、做 review、跟我对设计------上下文最重的活
- 二审 A(独立架构师视角):拿到主写改完的代码,从"原作者意图是否被准确实现"的角度评审
- 二审 B(大上下文 + 前端视角):扫跨文件影响、看全局一致性、做前端代码审
为什么不只用一个?因为单个 AI 编程助手的"盲区"是稳定的,让它审自己写的代码大概率漏掉同一类问题。多家 AI 互相挑刺,盲区基本能覆盖掉。这个组合在过去 3 个月里挑出来的真 bug 至少有 20 个,几乎都是单 AI 漏掉但二审看出来的。
这种"独立开发者 + 多 AI 协作"的开发模式国内写的人确实少。可能因为同时熟用 3 个以上 AI 编程助手的程序员本来就不多,能把协作分工沉淀成稳定流程的更少。
使用侧:人 web 问答 + AI MCP 召回
使用侧的双端共生比开发侧更早就成立。
人侧的真实使用场景:上周我在 web 控制台问「某个项目旧版构建流程和新版构建流程的差异是什么,帮我拉个表格」------它返回了一个对比表,5 个引用全部命中我项目里的相关文档。我自己写这个表至少要花 20 分钟翻文档对照,问答 30 秒出。
AI 侧的真实使用场景:我在 IDE 里跟 AI 编程助手协作改一个组件,agent 在第一轮回复前先通过 MCP 查了一遍"这个组件以前有什么相关决策",召回了我两个月前写进知识库的一条临时约定。我自己根本忘了那条约定,AI 反而记得。
飞轮:用得越多 → 知识库越完整 → 双端越受益
这个飞轮的起点是一个简单事实:真正能用起来的本地知识库,是在用的过程中自己长出来的。
3 个月里发生的真实循环:
- 撞 bug → 修完后把"bug 现象 + 根因 + 修法"写进知识库
- 一周后类似场景再出现 → AI agent 通过 MCP 自动召回这条经验,避免重复踩坑
- 我自己在 web 上偶尔翻翻历史 bug → 主动复习
- 知识条目越来越多 → 召回质量越来越高 → 双端用得越频繁 → 更愿意往里写
最早一周的体验是"这玩意儿好像没啥用,召回经常空"------因为里面就 10 条数据。两个月之后变成"AI 突然变懂我业务了"。根本原因不是模型变聪明了,是我知识库的覆盖面到了一个阈值。
举一个写这篇文章当天发生的最新案例。今天上午我刚修完两个 bug:装机后立刻点重建会因 infinity 还在 warmup 而 strict 模式 0 条死法、以及配置切换时旧 VectorIndex 不释放 qdrant 文件锁导致同进程拿锁失败静默退化关键词。修完代码 + commit + 发版到下午写文章这段时间间隔不超过 4 小时------我把"bug 现象 + 根因 + 修法"作为一条 lesson 写进了知识库。然后在 web 控制台问「infinity warmup 未就绪时点重建会怎么样?怎么修的?」,召回结果直接命中那条 lesson,连 rebuild_runner.py start() 里加的 EmbeddingNotReady exception、Retry-After: 5 响应头、/health 探针端点这些代码细节都准确还原。
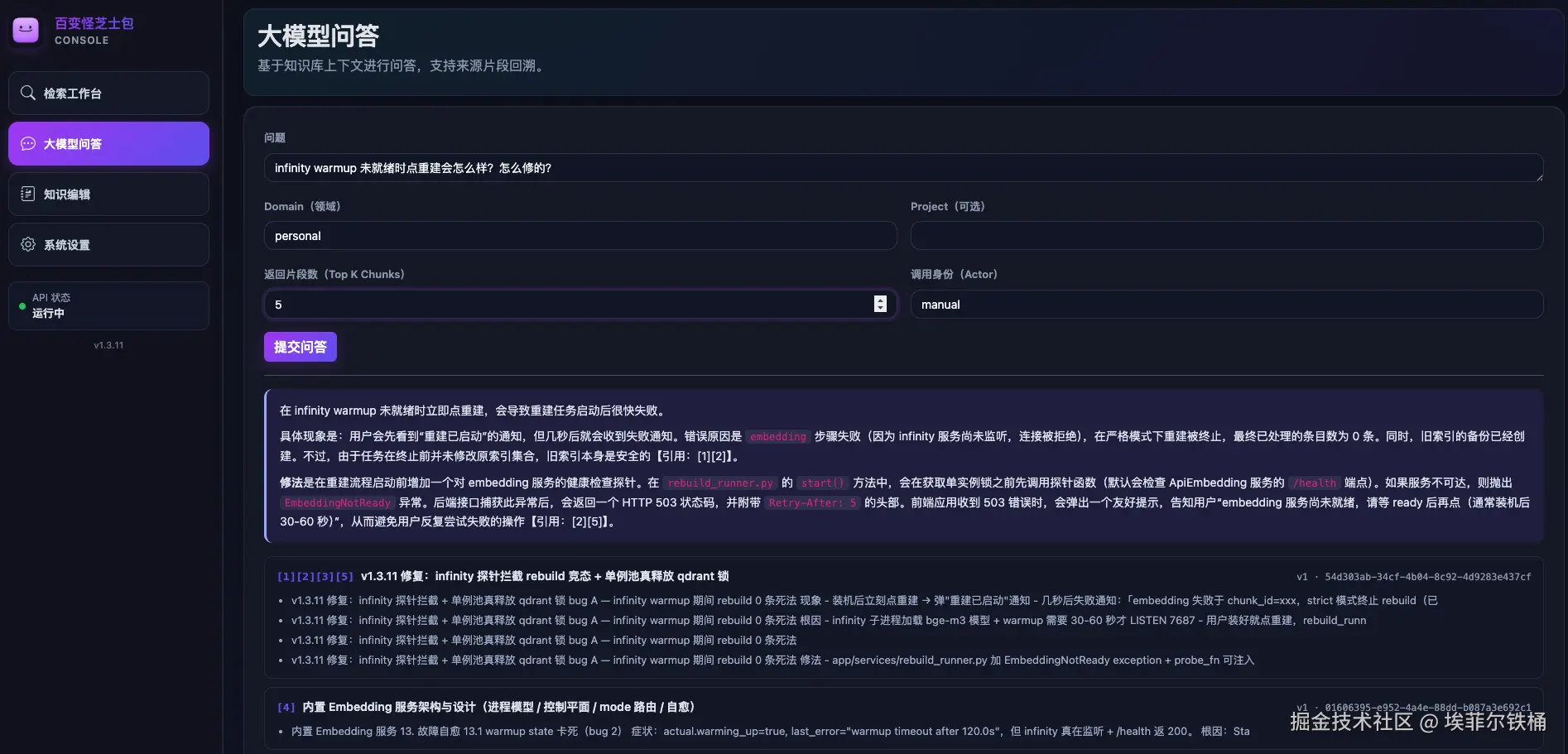
这就是飞轮闭环最直接的证据:上午改完代码,下午 AI 通过 MCP 召回出来------不是模型懂业务,是我的知识库越来越完整。
四、开源公告
写到第三个月我决定把它彻底开源。
- 协议:Apache 2.0
- 代码 :github.com/SliverSucks...
- 当前版本:v1.3.11
- 安装:macOS 直接下 dmg(53MB),双击装;Windows 端规划中
- 本地 embedding:首次启用时 web 控制台引导下 4GB bge-m3 模型,之后纯本地零依赖
- MCP 集成:装完直接通过 MCP 配置给任何支持的 coding agent
技术栈:
- 后端:Python 3.11 + FastAPI + uvicorn 单 worker
- 数据层:SQLite(直装版主存)/ PostgreSQL(Docker 版可选)+ FTS 全文索引
- 向量层:Qdrant 嵌入式模式(直装版)/ Qdrant server(Docker 版可选),向量维度跟 embedding model 联动
- Embedding 推理:infinity-emb 跑 bge-m3(默认) / bge-large-zh-v1.5 / Qwen3-Embedding-0.6B 三选一
- Rerank(重排) :
ApiReranker远程 OpenAI 兼容协议(用户自配豆包 rerank / Cohere rerank / 自建 bge-reranker 服务等)+LocalLexicalReranker本地词项重叠兜底(base 0.7 + token overlap 0.3);尚未内置本地 rerank 模型推理服务,想要真 rerank 模型需走远程 API - 壳层:macOS Swift 菜单栏 App / Windows Python 托盘 App,独立进程跟 kb-api 解耦
- Agent 接入:MCP HTTP 代理(FastMCP stdio) + Skill 行为规则(Claude / Codex 双轨)
不收费、不上云、不要 API key 也能跑(关键词检索兜底,质量稍弱但能用)。
写这篇的动机也很朴素:我自用 3 个月,相同需求的独立开发者应该不少,能用就来用。也欢迎 issue / PR / 直接 fork------这本来就是开源项目最舒服的状态。
如果觉得这个思路有意思,欢迎到 GitHub 给个 star,或者直接 issue 提需求 / 报 bug:
五、写在最后
这篇文章本身也是和 AI 一起写的。我列大纲、定基调、改钩子、删冗余;AI 帮我组织段落、查证细节、补具体例子。这个项目从代码到文档到使用,每一层都是"人 + AI"协作的产物。
3 个月之前我没想到这一点会变成项目的主线叙事。当时我只是想解决两个具体痛点。现在回头看,这种"双端共生"的工作模式本身可能就是 AI Coding 时代独立开发者的一种新常态。
如果你也在做类似的事,欢迎来 GitHub 找我。
这篇是全景篇,后面还会陆续把具体的技术决策和踩过的坑单独展开写。感兴趣的可以关注一下。
你日常用几个 AI 编程助手?业务知识是怎么喂给它们的?评论区聊聊你的本地 AI 工作流------尤其是和我不一样的取舍,最想听。
RAG MCP 知识库 开源项目 AI Coding 本地优先