这是苍何的第 519 篇原创!
大家好,我是苍何。
前几天,好基友甲木带我去了趟清华大学,参加一个机器人发布会。

发布方是一念 Unisonmind(清华团队),发布的产品叫 UnisonMind。
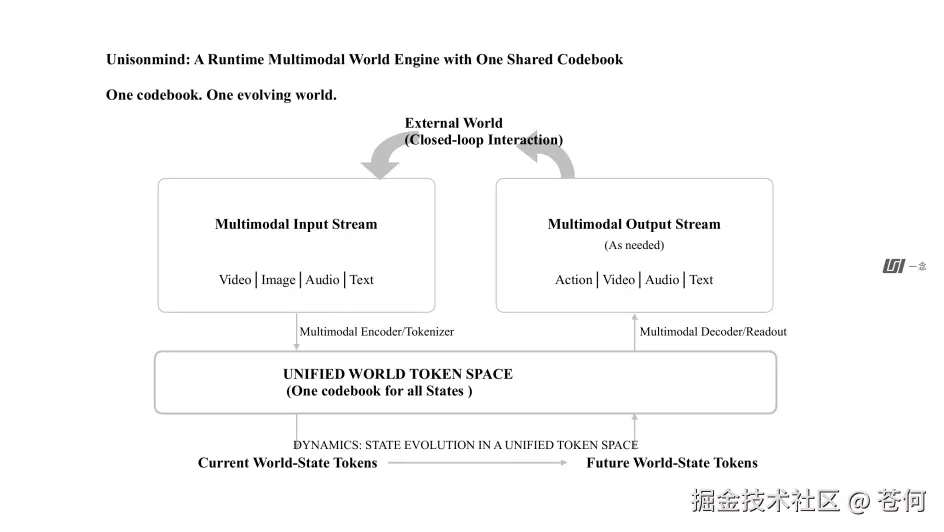
简单说,这是一个端侧部署、实时运行的原生多模态模型。支持流式输入与持续状态更新。
行业首发。
它同时进入了三种完全不同形态的机器:机器狗、人形机器人、电动轮椅。

注意,是同一个认知内核,直接迁移到不同的硬件载体上。
身体和底层运动控制可以不同,但上层大脑共享同一套认知系统,持续判断「我在哪里、周围发生了什么、人希望我做什么、下一步该说什么或做什么」。
这个思路在行业里讨论了很久,但真正做出来并在 20 多人的真实现场演示的,一念是我见到的第一家。
下面聊聊我在现场看到的几个演示。
现场演示
发布会现场的任务,都是由人在运行过程中实时提出的,不是提前编排好的固定脚本。
1、数乒乓球。
工作人员在机器狗面前快速抛撒乒乓球,速度很快,数量不少。
机器狗需要实时追踪每一个球的运动轨迹,边看边数,最后报出准确数量。
这个任务对人来说不算难,但对机器来说就很考验了。
因为球的间隔、速度、轨迹都没有固定规律,稍有遗漏计数就会出错。

这个演示之所以值得单独说,是因为它直接体现了一念在技术上的一个关键差异点,后面会展开聊。
2、倒背数字。
工作人员随机念一长串数字,机器狗听完之后,倒着背出来。
这考验的可不只是「听见了」,还得「记住了,还能倒序处理」。
本质上是实时认知能力的一个测试:系统得在连续输入中保持状态,还能按新的要求重组输出。

3、找人。
告诉机器狗「帮我找穿白衬衫的那个人」,它在一群人里面锁定目标。
没有提前录入人脸信息,纯靠视觉理解和语义匹配,现场实时找。
有意思的是,现场有个人披着外套,机器狗注意到里面穿的也是白衬衫,还主动补充了这个细节。
这种临场的语义补充能力,比单纯的目标识别要有意思得多。

4、轮椅自主导航去买咖啡。
这个演示我个人最关注。
一台搭载了 UnisonMind 的电动轮椅,用户只需要说「我想喝杯咖啡」。
轮椅自动识别标牌、判断空间关系、规划路线、避开障碍,带着用户去到咖啡店。

对于行动不便的人来说,不用再依赖别人推轮椅,不用反复解释「往左、往右、停一下」。
说一句话,轮椅就懂了。
讲真的,这个场景让我在现场沉默了好一会儿。
技术不就应该用在这种地方吗?

理解这次发布的一个关键技术点
看完演示,我比较好奇的是,凭什么一念的机器狗能数清楚快速飞过的乒乓球?
这里面有一个核心的技术差异:流式输入与持续状态更新。

先说一个前提:真实世界不会暂停等模型算完。
人会移动,球会连续起落,声音会重叠,新指令随时到来,原来的判断也可能下一秒失效。
现在大部分多模态模型处理视频的方式是「抽帧」,从视频中按固定间隔抽取若干关键帧,再统一分析。
这种方式更适合视频摘要、内容识别这类事后分析的场景。
但数乒乓球这种任务,颠球的间隔、速度和轨迹没有固定规律,一次有效触球可能只持续很短时间。
如果两个采样点之间刚好漏掉一次触球,累计结果就会出错。
UnisonMind 的做法是流式处理:视频信息持续进入,系统沿着真实时间轴维护一个不断演化的世界状态,每一帧都在更新。
相当于从「收到消息才上线」变成了「始终在场,一直知道刚才发生了什么、现在发生了什么」。
这也是为什么它能在连续运动中数对乒乓球,能在连续输入中记住一长串数字并倒序输出。
感知、推理、表达和行动,跟真实世界共享的是同一条时间线。
「3+1」技术框架
一念科技给 Physical AGI 定义了一个「3+1」的必要条件:

统一的多模态认知。
由一个统一的认知内核来理解不同的信息输入,视频、图像、语音、文本以及设备自身状态,都进入同一个世界表征。
不再是视觉一个模型、语音一个模型、动作交给另一个系统临时拼接。
理解和生成统一。
它不只「看懂」,还要根据任务说话、移动、交互,让理解和输出属于同一个认知过程。
输出也不只是文字,可以按任务需要生成动作、视频、音频或文本,并通过行动再次改变外部世界,形成闭环。
流式输入输出。
就是上面聊的那个,持续接收信息,持续更新内部状态,同时保持原任务不丢失。
任务可以被打断、修正和重组,而不是只能执行预先写好的完整脚本。
加上全端侧部署。
核心大脑完整运行在设备本体上,不把核心认知托管在远程云端。
低延迟,不用等网络往返。
弱网、断网场景也能正常工作。
隐私和安全也更可控。
想想看,如果轮椅每个指令都得先传到云端再传回来,万一网断了怎么办?
端侧部署在这些场景下是刚需。
真实现场,包括不完美的部分
发布会现场有 20 多位来宾,全程录像,持续走动的人群、临时指令、声音干扰和硬件状态,共同构成了一个难以完全预编排的真实环境。
说句公道话,现场演示并不是每一次都完美。
轮椅在演示中出现过一次硬件异常,原地转了好几圈。
但有意思的是,即便在这种状态下,它仍然能围绕自身状态跟人继续对话。
Physical AI 真正面对的考验,不只是「成功完成一次任务」,还包括意外发生后能否感知、回应、调整并安全继续。
物理世界本来就有噪声、遮挡、误解和各种故障,真实现场比精心剪辑的 Demo 更有说服力。
我的一些行业观察
从行业视角聊几点。
目前具身智能赛道的主流做法,还是「感知模块 + 决策模块 + 执行模块」的分层架构,每一层各自训练,中间用规则或接口串起来。
这种方案工程上可控,但上限也明显:模块之间信息损耗大,端到端的响应链路长,很难做到真正的实时。
一念这次的思路是把感知、认知、生成压到一个统一的原生多模态模型里,再加上端侧部署,从架构层面缩短这条链路。
方向上,我认为是对的。
但现阶段的问题也摆在那里。
现场部分场景下响应偏慢,复杂指令的理解准确率有波动。
端侧算力的天花板摆在那里,模型压缩和推理效率的优化还有很长的路要走。
另外,跨本体迁移目前展示的三种载体,运动复杂度差异很大。
统一大脑在认知层做到了共享,但底层运动控制因硬件而异,适配的深度和泛化能力还需要更多场景去验证。
总的来说,一念这次展示的是一条有潜力的技术路径,可能走到了 Physical AGI 的门口,但完整的 Physical AGI 仍需更广泛、严格和长期的验证。
写在最后
具身智能这个赛道,离大规模商用还有距离,这是事实。
但「跨本体统一认知」这个思路,确实值得关注。
以前做机器人,思路是「一种机器人配一套方案」,成本高,周期长,很难规模化。
如果真能做到一个大脑适配多种身体,商业化路径就完全不一样了。
机器狗能用,人形机器人能用,轮椅也能用。
未来扫地机器人、送餐机器人是不是也能用?
这才是平台化的想象空间。
聊点我个人对「端侧实时多模态大脑」这条路线的看法。
目前行业里做具身智能,大部分公司的多模态能力依赖云端大模型。
机器人本地做感知和基础控制,复杂的理解和决策丢给云端处理,再把结果传回来。
这条路能跑,但天花板很明显:网络延迟、隐私风险、离线场景直接趴窝。
一念选的是另一条路,把多模态大脑压到端侧。
这条路难度大得多,因为端侧算力有限,你得在一块芯片上同时跑视觉、语音、认知、生成,还要保证实时性。
但一旦跑通,壁垒也高得多。
因为端侧部署意味着机器人可以在任何网络环境下工作,响应速度由本地硬件决定,不受带宽和服务器排队的影响。
这对于轮椅、机器狗这类需要即时反应的场景来说,几乎是必选项。
再说流式处理这个点。
现在很多所谓的多模态模型,本质上还是「看图说话」,给一张图输出一段文字。
一念做的是持续的视频流理解,模型的状态随着输入不断更新,类似人类的注意力机制,一直在看,一直在处理。
这个能力在实验室里有人在研究,但做到端侧实时跑起来并在真实现场做了验证的,确实少见。
当然,「少见」不等于「成熟」。
端侧算力的瓶颈、模型压缩带来的精度损失、不同载体之间运动控制的适配深度,这些问题都还在路上。
但我觉得,具身智能这个赛道,最终一定会走向端侧化和实时化。
云端方案可以作为过渡,但终局一定是端侧。
就像手机从功能机到智能机,最终所有计算都发生在你手里那块芯片上。
机器人也一样,大脑迟早要长在自己身体里。
一念这次发布,至少让我看到了这个方向上一个可信的进展。
至于能不能跑到终局,时间会给答案。
我一直觉得,技术的终极浪漫,是让普通人的日常生活变得更有尊严。
比起让你刷短视频更上瘾,让一个行动不便的人能自己去买杯咖啡,才更值得投入。
你觉得这种「一个大脑多种身体」的路线能跑通吗?评论区聊聊。