先从一个爆栈的报错说起
昨天在写一个数组工具函数,需要把深层嵌套的数组拍平。我顺手写了个递归版本,自测用个三层嵌套的数组没问题,就丢进去测了个十几层的大数组。结果控制台直接红了一片,报 Maximum call stack size exceeded。
说实话当时我有点懵。写递归也不是一天两天了,平时写个深拷贝、树遍历都顺得很,怎么今天说炸就炸。我对着代码盯了十分钟,改来改去还是不对,才反应过来:我好像一直只会套递归的模板,根本没真的搞懂它到底是怎么跑的。
索性当天下午啥也没干,从最基础的例子开始,一点点把递归拆了个明白。今天就顺着我当时的思路,跟大家唠唠。
从最简单的求和,看懂递归到底在干嘛
我没一上来就啃扁平化,先退回到最基础的问题:求 1+2+3+...+n 的结果。这种题正常人第一反应都是写循环,对吧?我也一样,几行代码的事,跑起来稳得很。
javascript
// 迭代写法,怎么跑都不会炸
function sum(n) {
let res = 0;
for (let i = 1; i <= n; i++) {
res += i;
}
return res;
}那如果用递归写呢?当时我脑子里的第一反应是:要求 n 个数的和,不就是 n 加上前面 n-1 个数的和吗?比如 sum(5) = 5 + sum(4),sum(4) = 4 + sum(3),这样一层层拆下去,拆到什么时候是个头?到 1 的时候,sum(1) 就等于 1,不用再拆了。
想着想着我就敲出了第一版代码,运行,直接卡页面,过两秒就爆栈了。你们猜为啥?我光顾着写递归逻辑,把终止条件给忘了。
javascript
// 错误示范:没有终止条件,直接无限递归
function sum(n) {
// 注意这里,没写停止条件,会一直调用下去,直到栈溢出
return n + sum(n - 1);
}后来加上了终止条件,才算跑通。
javascript
// 正确的递归求和
function sum(n) {
if(n === 1){
return 1; // 到最小的子问题就返回,不能再拆了
}
return n + sum(n - 1);
}就这么个简单的例子,我来回折腾了两版,才静下心来想:递归这玩意儿,到底是个啥逻辑?其实掰碎了看,核心就三件事,跟俄罗斯套娃一模一样。你想打开一套套娃,就得一个个往外拿,每个娃娃结构都一样,只是大小不同。拿到最小的那个,拿不动了,就开始往回装,装完一个得到一个结果,直到装完最大的那个,整件事就做完了。
对应到递归里:
- 每一层的问题结构完全一样,只是规模变小了(每个套娃长得一样,只是尺寸不同)
- 有一个明确的终止点,到这就不能再拆了(最小的套娃,里面没东西了)
- 每一层都等着下一层返回结果,再拼成自己的结果往回传(把小娃娃装回大娃娃里)
换个角度看,这也是个自顶向下的树状结构。最顶上的是原来的大问题,往下拆出一层一层的子问题,最底下的叶子节点就是不能再拆的终止条件。
我当时特意对着调用栈捋了一遍 sum(5) 的执行过程,才真的明白 "栈溢出" 到底是啥意思。
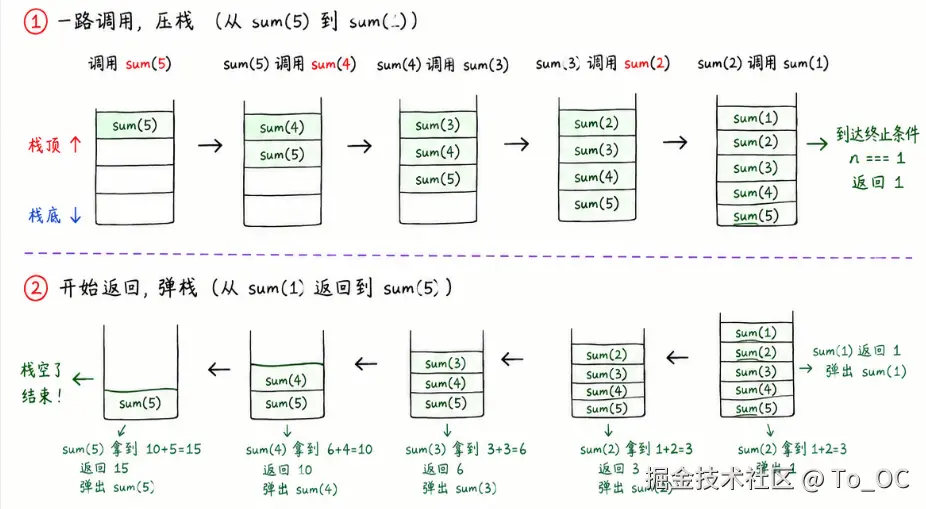
调用 sum(5) 的时候,浏览器会把这个函数压到调用栈里;然后 sum(5) 调用 sum(4),再压一层;一直压到 sum(1),这时候到了终止条件,开始返回结果,返回一个就从栈里弹出一层,直到 sum(5) 拿到结果弹出,整个过程结束。为啥会爆栈?因为浏览器给调用栈留的空间是有限的,你嵌套个几千层,栈装不下了,自然就报错了。
再进阶点:手写数组扁平化
搞懂了基础的求和,我就回头去改那个数组扁平化的代码。说起来挺丢人的,平时写业务我从来都是一把梭 ES6 的 flat 方法,根本没细想过它是怎么实现的。真到要手写的时候,脑子一片空白。
javascript
const arr = [1, [2, [3, 4, 5]]];
// 业务里我都这么写,方便是真方便
console.log(arr.flat(Infinity));日常业务开发里,如果只是普通的数组扁平化,优先用原生的 flat 方法。JS 引擎对原生方法做过深度优化,性能比我们自己手写的递归版本好得多。
趁这个机会我也好好翻了下 flat 的用法,人家设计得其实挺细的。默认只扁平化一层,你传个数字 2 就拆两层,传 Infinity 就把所有嵌套都拆完。我之前不管啥场景都写 Infinity,现在想想挺浪费的,知道嵌套深度的话,传具体的数字性能会好不少,也能避免一些意料之外的问题。
那自己用递归实现的话,该怎么写?思路其实跟求和差不多:遍历数组的每一项,如果这一项还是数组,那就继续拆;如果不是,就放进结果里。我第一版写得特别顺,写完一跑,结果不对。
javascript
// 错误示范:我当时脑子抽了,直接push递归结果
const flatten = (arr) => {
let result = [];
arr.forEach((item) => {
if(Array.isArray(item)) {
result.push(flatten(item)); // 坑就在这!flatten返回的是数组,直接push就嵌套了
}else {
result.push(item);
}
})
return result;
}跑出来的结果是啥样的?[1, [2, [3, [4, [5]]]]],等于没拆平。我盯着这行代码看了快二十分钟,才反应过来:flatten 函数返回的是一个一维数组,你把一个数组 push 进另一个数组,可不就又嵌套了吗。
改的方法也简单,不用 push,用 concat 就行,或者用展开运算符把结果拆开再 push。
javascript
// 正确的递归扁平化
const flatten = (arr) => {
let result = [];
arr.forEach((item) => {
if(Array.isArray(item)) {
// 别问我为什么知道要用concat,试了三次才改对
result = result.concat(flatten(item));
}else {
result.push(item);
}
})
return result;
}
console.log(flatten([1, [2, [3, [4, [5]]]]])); // [1,2,3,4,5]改完跑通的那一刻,我还挺有成就感的。不过转头测了个二十层嵌套的数组,又爆栈了。得,又回到最开始的问题了。
我踩过的三个递归的坑,别再往里跳了
这一下午写代码改 bug,踩了好几个实打实的坑,说出来大家避避雷,反正我是每个都掉进去过。
坑一:先写递归逻辑,后补终止条件
这是我最常犯的毛病。脑子里先想清楚了怎么拆问题,上来就写递归调用,写着写着就把终止条件给忘了。结果就是一运行直接死循环,轻的页面卡几秒,重的直接浏览器无响应。
写递归一定要先写终止条件,再写递归逻辑。这不是什么代码规范,是我无数次爆栈攒出来的经验。
现在我写递归的习惯改了:第一行先写 if 判断,把终止条件写上,再去写后面的递归逻辑。别嫌麻烦,这一步能帮你避开 80% 的递归 bug。
坑二:类型判断写错,边界兜不住
写扁平化的时候,我最开始没用 Array.isArray,图省事写了 typeof item === 'object'。结果呢?数组是对象没错,可 null 也是对象啊,普通对象也是对象啊。万一数组里有个 null,代码直接就往递归里走,然后就报错了。
后来我就学乖了,判断数组老老实实⽤ Array.isArray,别整那些花里胡哨的简写。不止是递归,平时写代码也一样,类型判断越严谨,后面出 bug 的概率越低。
坑三:为了递归而递归,徒增复杂度
不知道有没有人跟我一样,刚学会递归的时候,啥都想用递归写。明明一个 for 循环就能搞定的事,非要整个递归,觉得显得高级。结果就是,代码写得绕,出了 bug 半天查不出来,性能还不如循环。
比如刚才的求和,递归写得再漂亮,n 一大就爆栈,还不如 for 循环稳,更别说直接用高斯公式 n*(n+1)/2 了,一步出结果。
最后说句实在的:递归不是万能的
以前我总觉得递归是个很高级的写法,写出来代码短,看着优雅。真的踩了几次坑才明白,它就是个普通的解题思路,有适合的场景,也有很多不适合的地方。
什么时候用递归合适?比如树结构遍历、深拷贝、多层嵌套数据处理这种,天然就是嵌套结构,用递归写逻辑清晰,代码也好读。什么时候别硬上递归?第一是深度特别大的场景,比如几千几万层的嵌套,很容易爆栈;第二是对性能要求特别高的地方,每次函数调用都有开销,递归层数多了,性能不如循环;第三是边界条件特别复杂的,拆来拆去容易乱,不如老老实实写循环。
回头捋这一下午的折腾,其实最大的收获就三点。第一,递归的本质从来不是 "函数自己调用自己",而是把一个大问题,拆成若干个结构完全相同的小问题。调用自己只是实现形式,拆解问题才是核心。第二,终止条件是递归的命根子。写不对,轻则结果出错,重则直接干崩页面。写递归先写边界,这是血的教训。第三,优雅不能当饭吃。不要为了写递归而写递归,哪种写法简单、好维护、性能好,就用哪种。
我之前学东西总喜欢背模板,背完就觉得自己会了。真遇到问题才发现,模板背得再熟,不懂原理,一踩坑就懵。反而像这样,从一个报错入手,一步步拆,一步步踩坑,最后搞懂的东西,记得才最牢。
你写递归的时候踩过最蠢的坑是什么?评论区说出来让我找找平衡。要是看完觉得对你有点启发,也可以留个言,我看看有多少人跟我一样,是踩坑踩明白的。