我们首先要了解StarRocks是什么? 不知道大家有没有听说过Doris,那么StarRocks其实是早期的Doris的一个分支,自从分支分离出来之后便独自命名为DorisDB。但是因为跟Apache Doris的命名有冲突,所以后面改名为StarRocks。
他能做什么? StarRocks 是新一代极速全场景 MPP (Massively Parallel Processing) 数据库。StarRocks 的愿景是能够让用户的数据分析变得更加简单和敏捷。用户无需经过复杂的预处理,就可以用 StarRocks 来支持多种数据分析场景的极速分析。
他和MySQL有什么区别? MySQL是通用的关系型OLTP数据库,擅长事务处理,StarRocks是专门的OLAP分析型数据库,擅长数据分析,StarRocks 兼容 MySQL 协议,支持标准 SQL 语法,易于对接使用,全系统无外部依赖,高可用,易于运维管理。StarRocks 还兼容多种主流 BI 产品,包括 Tableau、Power BI、QuickBI、FineBI 和 Smartbi。
那么最重要的是,它跟MySQL一样是开源免费的,也就意味着我们中能够把它作为数据存储的数据库使用,它提供了快速查找的能力。如果我们企业在使用它时,例如做一些报表或者需要大量的select查询,那么StarRocks将是我们的一个非常好的选择。它比MySQL有更快的查询性能,能够处理上亿条的数据。那么数据在它的查询下,就不会跟MySQL一样有性能瓶颈,它能通过大量的查询优化以及它本身的架构,比MySQL强大很多。那么这节课,我们就来带大家入门一下StarRocks。
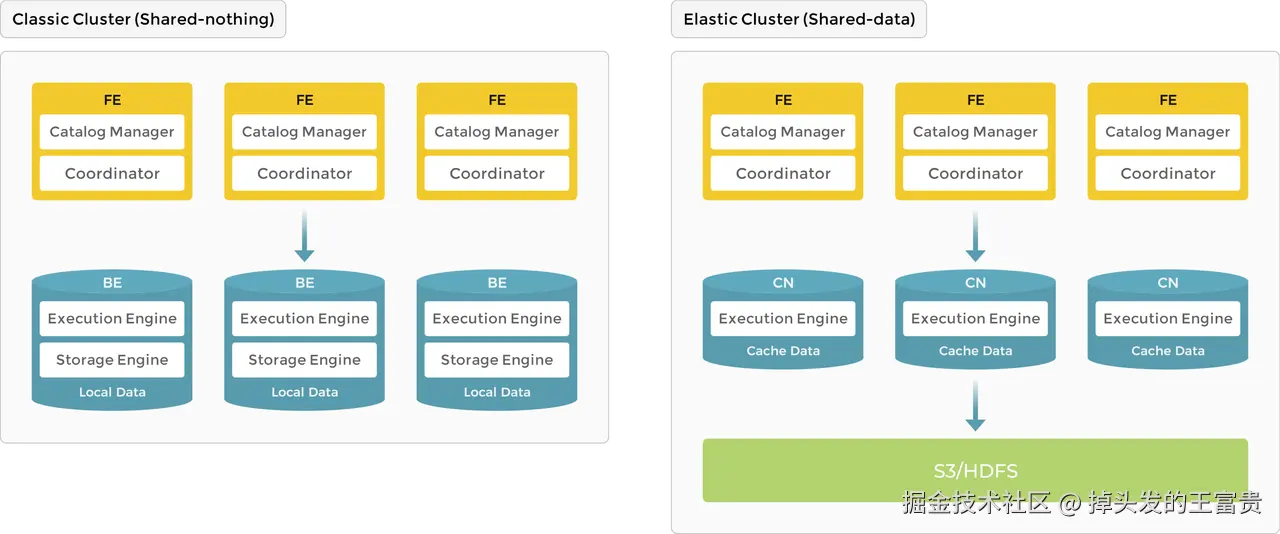 StarRocks 的架构分为存算一体和存算分离两种。
StarRocks 的架构分为存算一体和存算分离两种。
左边的图是存算一体架构。它主要由两种类型的节点组成:一个是 FE,一个是 BE。FE 负责元数据的管理和构建执行计划;BE 负责执行查询计划并存储数据。BE 会利用本地存储加速查询,并通过多副本机制来保证高可用。也就是说,BE 既负责数据存储,也负责 SQL 执行。FE 会根据查询的语义,把每个 SQL 查询解析成逻辑执行计划,然后再把逻辑执行计划转化成可以在 BE 上执行的物理执行计划。
讲完存算一体,我们再来看右边的存算分离架构。
顾名思义,存算一体就是把存储和计算放在同一个节点上处理。而存算分离,是指把数据存储在第三方系统中。怎么理解第三方呢?比如说支持类似 MinIO 这种存储的外部接口。也就是说,我可以把数据完全存储在像 MinIO 这样的文件存储管理器里。
在存算分离架构的第二张图里,其实已经没有 BE 节点了,取而代之的是计算节点 CN。CN 负责数据计算任务和热数据的缓存,而数据本身存储在低成本、可靠的远端存储系统中。
在查询过程中,如果缓存命中,查询性能可以和存算一体架构相媲美。毕竟,如果数据放在第三方存储架构中,势必会增加与第三方交互的耗时。而一旦命中缓存,就能大幅减少这部分开销,性能接近存算一体。
CN 节点可以根据需要,在几秒内完成增加或删除。这种架构降低了存储成本,实现了更好的资源隔离,也具备更高的弹性和可扩展性。
不过,CN 的配置比 BE 要麻烦很多,必须配置一个第三方的后端对象存储,比如把数据存在 S3 或者 HDFS 这种协议里。
这节课我们就通过Docker去快速安装存算一体架构,进行一个快速的入门演示。
准备工作
第一步,安装Docker
本次演示使用Windows进行演示,在此之前呢?我们需要安装Docker。若未安装Docker,可参考作者文章安装Docker,然后进行下一步。
第二步,安装MySQL客户端。
这里的客户端是指能支持mysql命令的客户端。如果本地未安装MySQL数据库,例如博主只安装了DBeaver或Navicat这类工具,该客户端同样适用。博主在此使用DBeaver连接MySQL,因为我们的StarRocks也支持MySQL协议。
安装为傻瓜安装,下载安装包后一直点击下一步即可完成,此处不再赘述。
第三步,安装CURL工具
curl 命令用于向 StarRocks 中导入数据以及下载数据集。可以通过在终端运行 curl 或 curl.exe 来检查您的操作系统是否已安装 curl。 如果未安装 curl:从 curl官网 下载预编译的Windows版本(如curl-x.xx.x-win64-mingw.zip)。 解压后,将bin目录(如C:\Program Files\curl\bin)添加到系统环境变量PATH中。
第四步,安装StarRocks
我们安装好Docker之后,直接使用ocker命令安装StarROS。
bash
docker run -p 9030:9030 -p 8030:8030 -p 8040:8040 -itd --name quickstart starrocks/allin1-ubuntu用 Docker 启动一个 StarRocks 的测试环境,容器名叫 quickstart,把本机的 9030、8030、8040 三个端口映射到容器里对应的端口,这样我们就可以通过 localhost 去连接 StarRocks 了(9030 是 MySQL 协议连接端口,8030 是FE 的 HTTP 管理页面,8040 是后端 BE 的 HTTP 接口)。命令最后指定了镜像 starrocks/allin1-ubuntu,这个镜像把 FE、BE 都打包在一起,方便快速上手,但不适合生产用,仅供演示学习。
第五步,下载测试数据
在写 SQL 的时候,我们需要一个数据集,这个数据集是存储在数据表里的。官方提供的快速上手内容有一套对应的数据,因此我们需要用 curl 工具,把以下两个数据集下载到本地电脑中。另外,我还会演示一下,如何通过 curl 命令把数据导入到 StarRocks 中。
下载纽约市交通事故数据
bash
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/quickstart/datasets/NYPD_Crash_Data.csvcurl 利用 URL 定位资源,通过 HTTP 协议向服务器发送 GET 请求,服务器返回文件内容,curl 再将其写到本地。
下载天气数据
bash
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/quickstart/datasets/72505394728.csv使用StarRocks
第一步,连接StarRocks
因为StarRocks是支持mysql协议去连接的,所以我们使用前面安装好的dbeaver的连接mysql协议去连接他。 
端口选择9030,用户名:root,密码:无 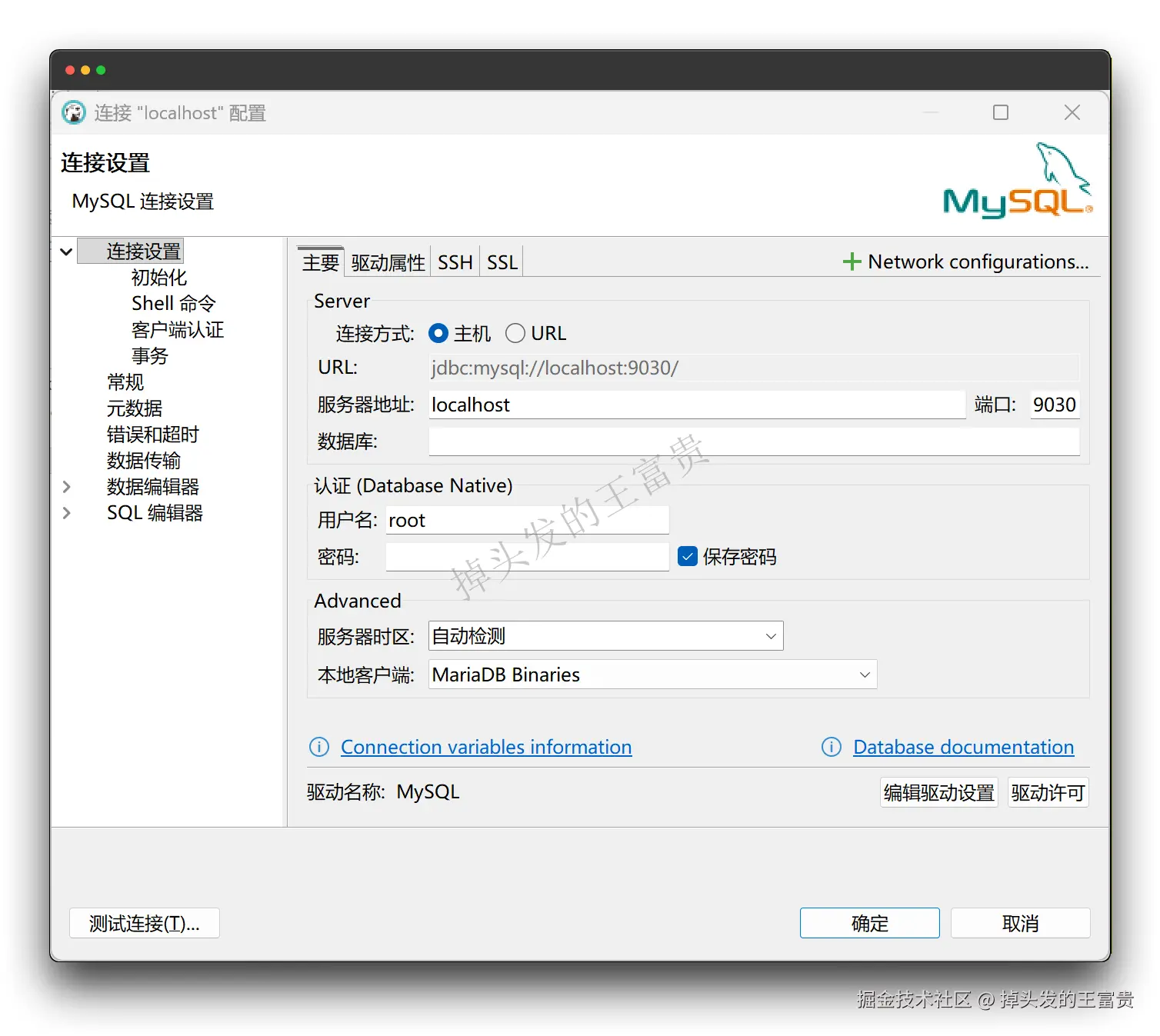
第二步,创建数据库
ini
CREATE DATABASE IF NOT EXISTS quickstart;
USE quickstart;这一步创建数据库和mysql是一样的,先创建,后使用他,我创建好之后就需要创建表
第三步,创建表
sql
CREATE TABLE IF NOT EXISTS crashdata (
CRASH_DATE DATETIME,
BOROUGH STRING,
ZIP_CODE STRING,
LATITUDE INT,
LONGITUDE INT,
LOCATION STRING,
ON_STREET_NAME STRING,
CROSS_STREET_NAME STRING,
OFF_STREET_NAME STRING,
CONTRIBUTING_FACTOR_VEHICLE_1 STRING,
CONTRIBUTING_FACTOR_VEHICLE_2 STRING,
COLLISION_ID INT,
VEHICLE_TYPE_CODE_1 STRING,
VEHICLE_TYPE_CODE_2 STRING
);
CREATE TABLE IF NOT EXISTS weatherdata (
DATE DATETIME,
NAME STRING,
HourlyDewPointTemperature STRING,
HourlyDryBulbTemperature STRING,
HourlyPrecipitation STRING,
HourlyPresentWeatherType STRING,
HourlyPressureChange STRING,
HourlyPressureTendency STRING,
HourlyRelativeHumidity STRING,
HourlySkyConditions STRING,
HourlyVisibility STRING,
HourlyWetBulbTemperature STRING,
HourlyWindDirection STRING,
HourlyWindGustSpeed STRING,
HourlyWindSpeed STRING
);这两个表就是用于存放我之前使用curl下载下的的csv文件,用于把里面的数据导入到我们的数据表里面来。
第四步,导入csv数据
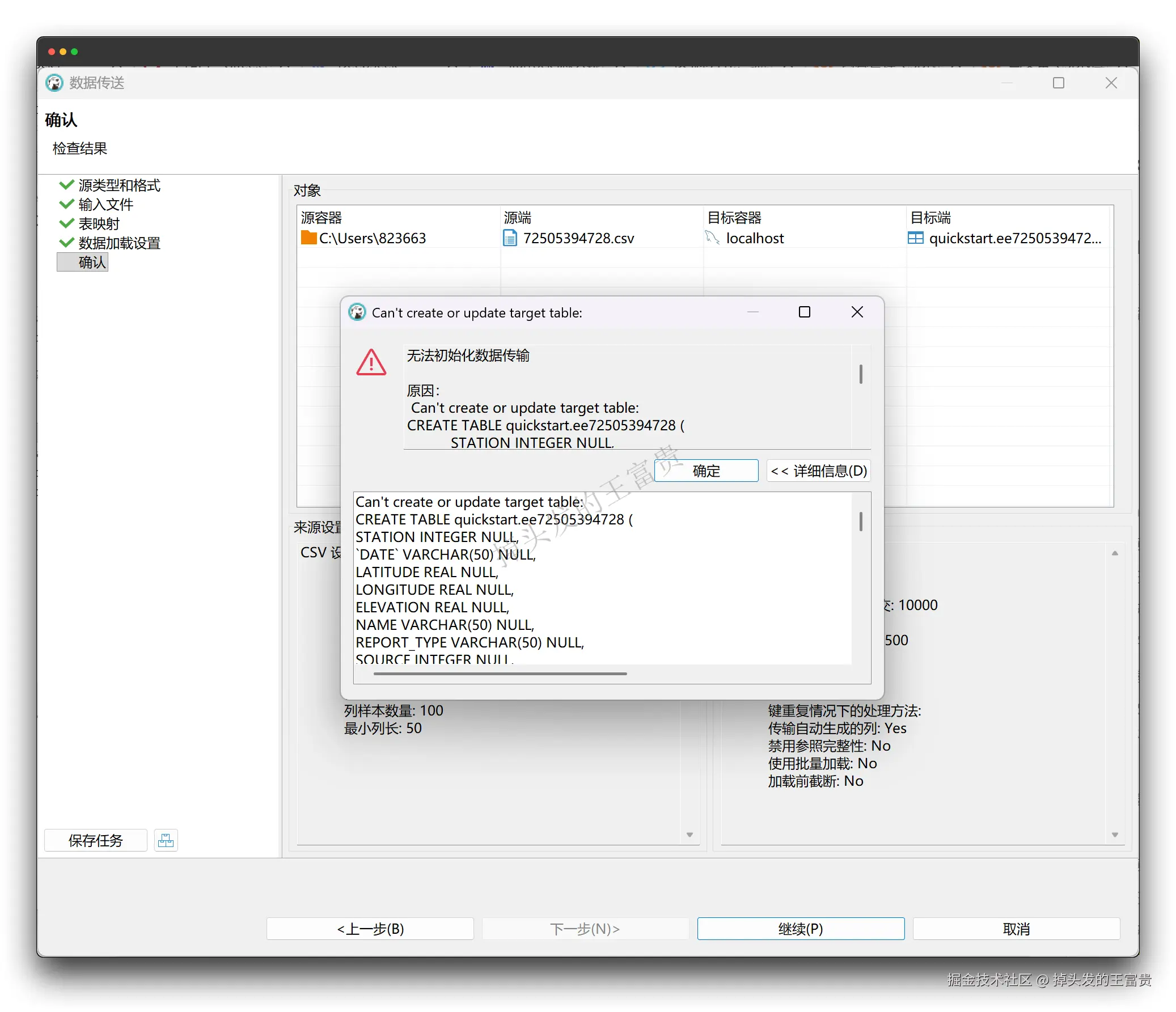 如果直接用 DBeaver 的导入 CSV 功能,实际上是导不进去的,可以看到它有报错提示。所以,对于 StarRocks 的数据,需要采用它自身的导入方式(导入方式:包括 Insert、Stream Load、Broker Load、Pipe、Routine Load、Spark Load。)。这里以 Stream Load 为例。
如果直接用 DBeaver 的导入 CSV 功能,实际上是导不进去的,可以看到它有报错提示。所以,对于 StarRocks 的数据,需要采用它自身的导入方式(导入方式:包括 Insert、Stream Load、Broker Load、Pipe、Routine Load、Spark Load。)。这里以 Stream Load 为例。
Stream Load 是同步导入(实时、小批量),它通过 HTTP 协议同步导入本地文件或数据流,是最常用的方式之一。支持 CSV、JSON、Parquet 等格式。适合几 GB 以下的小批量数据。
打开cmd命令行输入下面命令:
bash
curl --location-trusted -u root \
-T ./NYPD_Crash_Data.csv \
-H "label:crashdata-0" \
-H "column_separator:," \
-H "skip_header:1" \
-H "enclose:\"" \
-H "max_filter_ratio:1" \
-H "columns:tmp_CRASH_DATE, tmp_CRASH_TIME, CRASH_DATE=str_to_date(concat_ws(' ', tmp_CRASH_DATE, tmp_CRASH_TIME), '%m/%d/%Y %H:%i'),BOROUGH,ZIP_CODE,LATITUDE,LONGITUDE,LOCATION,ON_STREET_NAME,CROSS_STREET_NAME,OFF_STREET_NAME,NUMBER_OF_PERSONS_INJURED,NUMBER_OF_PERSONS_KILLED,NUMBER_OF_PEDESTRIANS_INJURED,NUMBER_OF_PEDESTRIANS_KILLED,NUMBER_OF_CYCLIST_INJURED,NUMBER_OF_CYCLIST_KILLED,NUMBER_OF_MOTORIST_INJURED,NUMBER_OF_MOTORIST_KILLED,CONTRIBUTING_FACTOR_VEHICLE_1,CONTRIBUTING_FACTOR_VEHICLE_2,CONTRIBUTING_FACTOR_VEHICLE_3,CONTRIBUTING_FACTOR_VEHICLE_4,CONTRIBUTING_FACTOR_VEHICLE_5,COLLISION_ID,VEHICLE_TYPE_CODE_1,VEHICLE_TYPE_CODE_2,VEHICLE_TYPE_CODE_3,VEHICLE_TYPE_CODE_4,VEHICLE_TYPE_CODE_5" \
-XPUT http://localhost:8030/api/quickstart/crashdata/_stream_load这里推荐大家使用git的bash工具,否则到cmd命令行里面会一行一行执行导致报错
bash
curl --location-trusted -u root \
-T ./72505394728.csv \
-H "label:weather-0" \
-H "column_separator:," \
-H "skip_header:1" \
-H "enclose:\"" \
-H "max_filter_ratio:1" \
-H "columns: STATION, DATE, LATITUDE, LONGITUDE, ELEVATION, NAME, REPORT_TYPE, SOURCE, HourlyAltimeterSetting, HourlyDewPointTemperature, HourlyDryBulbTemperature, HourlyPrecipitation, HourlyPresentWeatherType, HourlyPressureChange, HourlyPressureTendency, HourlyRelativeHumidity, HourlySkyConditions, HourlySeaLevelPressure, HourlyStationPressure, HourlyVisibility, HourlyWetBulbTemperature, HourlyWindDirection, HourlyWindGustSpeed, HourlyWindSpeed, Sunrise, Sunset, DailyAverageDewPointTemperature, DailyAverageDryBulbTemperature, DailyAverageRelativeHumidity, DailyAverageSeaLevelPressure, DailyAverageStationPressure, DailyAverageWetBulbTemperature, DailyAverageWindSpeed, DailyCoolingDegreeDays, DailyDepartureFromNormalAverageTemperature, DailyHeatingDegreeDays, DailyMaximumDryBulbTemperature, DailyMinimumDryBulbTemperature, DailyPeakWindDirection, DailyPeakWindSpeed, DailyPrecipitation, DailySnowDepth, DailySnowfall, DailySustainedWindDirection, DailySustainedWindSpeed, DailyWeather, MonthlyAverageRH, MonthlyDaysWithGT001Precip, MonthlyDaysWithGT010Precip, MonthlyDaysWithGT32Temp, MonthlyDaysWithGT90Temp, MonthlyDaysWithLT0Temp, MonthlyDaysWithLT32Temp, MonthlyDepartureFromNormalAverageTemperature, MonthlyDepartureFromNormalCoolingDegreeDays, MonthlyDepartureFromNormalHeatingDegreeDays, MonthlyDepartureFromNormalMaximumTemperature, MonthlyDepartureFromNormalMinimumTemperature, MonthlyDepartureFromNormalPrecipitation, MonthlyDewpointTemperature, MonthlyGreatestPrecip, MonthlyGreatestPrecipDate, MonthlyGreatestSnowDepth, MonthlyGreatestSnowDepthDate, MonthlyGreatestSnowfall, MonthlyGreatestSnowfallDate, MonthlyMaxSeaLevelPressureValue, MonthlyMaxSeaLevelPressureValueDate, MonthlyMaxSeaLevelPressureValueTime, MonthlyMaximumTemperature, MonthlyMeanTemperature, MonthlyMinSeaLevelPressureValue, MonthlyMinSeaLevelPressureValueDate, MonthlyMinSeaLevelPressureValueTime, MonthlyMinimumTemperature, MonthlySeaLevelPressure, MonthlyStationPressure, MonthlyTotalLiquidPrecipitation, MonthlyTotalSnowfall, MonthlyWetBulb, AWND, CDSD, CLDD, DSNW, HDSD, HTDD, NormalsCoolingDegreeDay, NormalsHeatingDegreeDay, ShortDurationEndDate005, ShortDurationEndDate010, ShortDurationEndDate015, ShortDurationEndDate020, ShortDurationEndDate030, ShortDurationEndDate045, ShortDurationEndDate060, ShortDurationEndDate080, ShortDurationEndDate100, ShortDurationEndDate120, ShortDurationEndDate150, ShortDurationEndDate180, ShortDurationPrecipitationValue005, ShortDurationPrecipitationValue010, ShortDurationPrecipitationValue015, ShortDurationPrecipitationValue020, ShortDurationPrecipitationValue030, ShortDurationPrecipitationValue045, ShortDurationPrecipitationValue060, ShortDurationPrecipitationValue080, ShortDurationPrecipitationValue100, ShortDurationPrecipitationValue120, ShortDurationPrecipitationValue150, ShortDurationPrecipitationValue180, REM, BackupDirection, BackupDistance, BackupDistanceUnit, BackupElements, BackupElevation, BackupEquipment, BackupLatitude, BackupLongitude, BackupName, WindEquipmentChangeDate" \
-XPUT http://localhost:8030/api/quickstart/weatherdata/_stream_load通过这两行命令,我们下载下来的csv文件里面的内容就分别导入了我们StarRocks的两张表去了
 这里有两个脚本,但是第一个脚本有点复杂了,不助于理解,我们就先来讲一下第二个脚本他到底干了哪些事?
这里有两个脚本,但是第一个脚本有点复杂了,不助于理解,我们就先来讲一下第二个脚本他到底干了哪些事?
--location-trusted 此参数用于允许 curl 将认证凭据传输给任何重定向的 URL。
-u root 用于登录 StarRocks 的用户名。
-T filename T 代表传输(Transfer),用于指定需要传输的文件名。
label:name-num 与此 Stream Load 作业关联的标签。标签必须唯一,因此如果多次运行作业,您可以添加一个数字保持递增。
column_separator:, 如果导入的文件使用单个 , 作为列分隔符,则设置如上所示。如果使用其他分隔符,则在此处设置该分隔符。常见分隔符包括 \t、, 和 |。
skip_header:1 某些 CSV 文件会在首行(Header)记录所有的列名,还有些会在第二行记录所有列的数据类型信息。如果 CSV 文件有一或两个 Header 行,需要将 skip_header 设置为 1 或 2。如果您使用的 CSV 没有 Header 行,请将其设置为 0。
enclose:" 如果某些字段包含带有逗号的字符串,则需要用双引号括起该字段。本教程使用的示例数据集中,地理位置信息包含逗号,因此需将 enclose 设置为 ",其中 \ 用于转义 "。
max_filter_ratio:1 导入数据中允许出现错误行的比例。理想情况下,应将其设置为 0,即当导入的数据中有任意一行出现错误时,导入作业会失败。本教程中需要将其设置为 1,即在调试过程中,允许所有数据行出现错误。
columns: 此参数用于将 CSV 文件中的列映射到 StarRocks 表中的列。当前教程中使用的 CSV 文件中有大量的列,而 StarRocks 表中的列经过裁剪,仅保留部分列。未包含在表中的列在导入过程中都将被跳过。
我们来看一下columns 中写了什么:
vbnet
columns: STATION, DATE, LATITUDE, LONGITUDE, ELEVATION, NAME, REPORT_TYPE, SOURCE, HourlyAltimeterSetting, HourlyDewPointTemperature, HourlyDryBulbTemperature, HourlyPrecipitation, HourlyPresentWeatherType, HourlyPressureChange, HourlyPressureTendency, HourlyRelativeHumidity, HourlySkyConditions, HourlySeaLevelPressure, HourlyStationPressure, HourlyVisibility, HourlyWetBulbTemperature, HourlyWindDirection, HourlyWindGustSpeed, HourlyWindSpeed, Sunrise, Sunset, DailyAverageDewPointTemperature, DailyAverageDryBulbTemperature, DailyAverageRelativeHumidity, DailyAverageSeaLevelPressure, DailyAverageStationPressure, DailyAverageWetBulbTemperature, DailyAverageWindSpeed, DailyCoolingDegreeDays, DailyDepartureFromNormalAverageTemperature, DailyHeatingDegreeDays, DailyMaximumDryBulbTemperature, DailyMinimumDryBulbTemperature, DailyPeakWindDirection, DailyPeakWindSpeed, DailyPrecipitation, DailySnowDepth, DailySnowfall, DailySustainedWindDirection, DailySustainedWindSpeed, DailyWeather, MonthlyAverageRH, MonthlyDaysWithGT001Precip, MonthlyDaysWithGT010Precip, MonthlyDaysWithGT32Temp, MonthlyDaysWithGT90Temp, MonthlyDaysWithLT0Temp, MonthlyDaysWithLT32Temp, MonthlyDepartureFromNormalAverageTemperature, MonthlyDepartureFromNormalCoolingDegreeDays, MonthlyDepartureFromNormalHeatingDegreeDays, MonthlyDepartureFromNormalMaximumTemperature, MonthlyDepartureFromNormalMinimumTemperature, MonthlyDepartureFromNormalPrecipitation, MonthlyDewpointTemperature, MonthlyGreatestPrecip, MonthlyGreatestPrecipDate, MonthlyGreatestSnowDepth, MonthlyGreatestSnowDepthDate, MonthlyGreatestSnowfall, MonthlyGreatestSnowfallDate, MonthlyMaxSeaLevelPressureValue, MonthlyMaxSeaLevelPressureValueDate, MonthlyMaxSeaLevelPressureValueTime, MonthlyMaximumTemperature, MonthlyMeanTemperature, MonthlyMinSeaLevelPressureValue, MonthlyMinSeaLevelPressureValueDate, MonthlyMinSeaLevelPressureValueTime, MonthlyMinimumTemperature, MonthlySeaLevelPressure, MonthlyStationPressure, MonthlyTotalLiquidPrecipitation, MonthlyTotalSnowfall, MonthlyWetBulb, AWND, CDSD, CLDD, DSNW, HDSD, HTDD, NormalsCoolingDegreeDay, NormalsHeatingDegreeDay, ShortDurationEndDate005, ShortDurationEndDate010, ShortDurationEndDate015, ShortDurationEndDate020, ShortDurationEndDate030, ShortDurationEndDate045, ShortDurationEndDate060, ShortDurationEndDate080, ShortDurationEndDate100, ShortDurationEndDate120, ShortDurationEndDate150, ShortDurationEndDate180, ShortDurationPrecipitationValue005, ShortDurationPrecipitationValue010, ShortDurationPrecipitationValue015, ShortDurationPrecipitationValue020, ShortDurationPrecipitationValue030, ShortDurationPrecipitationValue045, ShortDurationPrecipitationValue060, ShortDurationPrecipitationValue080, ShortDurationPrecipitationValue100, ShortDurationPrecipitationValue120, ShortDurationPrecipitationValue150, ShortDurationPrecipitationValue180, REM, BackupDirection, BackupDistance, BackupDistanceUnit, BackupElements, BackupElevation, BackupEquipment, BackupLatitude, BackupLongitude, BackupName, WindEquipmentChangeDate我们先来看我们的csv文件:
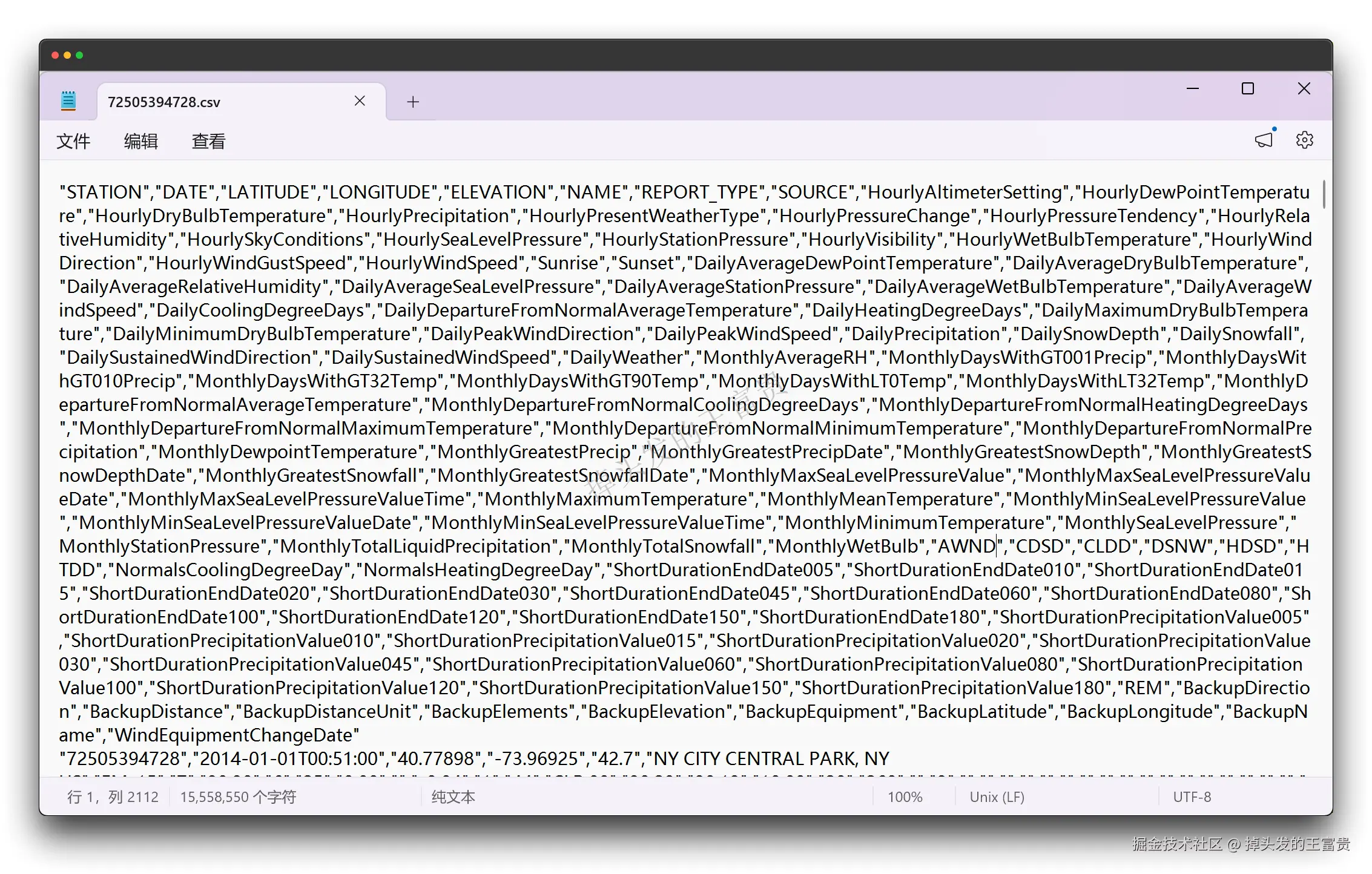 可以看到,他和我们的csv中的列一一对应:
可以看到,他和我们的csv中的列一一对应:
css
CSV文件的一行(第1个字段)──┐
│
CSV文件的一行(第2个字段)──┼──→ curl脚本的columns参数(顺序一一对应)──→ 按列名匹配到SQL表──→ 入库
│
CSV文件的一行(第3个字段)──┘其他CSV里的几百列(包括STATION, LATITUDE, LONGITUDE等)全部被丢弃。
那么第一个脚本我们看里面还有其他的东西,他又做了哪些事情呢?
perl
curl --location-trusted -u root \
-T ./NYPD_Crash_Data.csv \
-H "label:crashdata-0" \
-H "column_separator:," \
-H "skip_header:1" \
-H "enclose:\"" \
-H "max_filter_ratio:1" \
-H "columns:tmp_CRASH_DATE, tmp_CRASH_TIME, CRASH_DATE=str_to_date(concat_ws(' ', tmp_CRASH_DATE, tmp_CRASH_TIME), '%m/%d/%Y %H:%i'),BOROUGH,ZIP_CODE,LATITUDE,LONGITUDE,LOCATION,ON_STREET_NAME,CROSS_STREET_NAME,OFF_STREET_NAME,NUMBER_OF_PERSONS_INJURED,NUMBER_OF_PERSONS_KILLED,NUMBER_OF_PEDESTRIANS_INJURED,NUMBER_OF_PEDESTRIANS_KILLED,NUMBER_OF_CYCLIST_INJURED,NUMBER_OF_CYCLIST_KILLED,NUMBER_OF_MOTORIST_INJURED,NUMBER_OF_MOTORIST_KILLED,CONTRIBUTING_FACTOR_VEHICLE_1,CONTRIBUTING_FACTOR_VEHICLE_2,CONTRIBUTING_FACTOR_VEHICLE_3,CONTRIBUTING_FACTOR_VEHICLE_4,CONTRIBUTING_FACTOR_VEHICLE_5,COLLISION_ID,VEHICLE_TYPE_CODE_1,VEHICLE_TYPE_CODE_2,VEHICLE_TYPE_CODE_3,VEHICLE_TYPE_CODE_4,VEHICLE_TYPE_CODE_5" \
-XPUT http://localhost:8030/api/quickstart/crashdata/_stream_load我们的csv表头是:
css
CRASH DATE,CRASH TIME,BOROUGH,ZIP CODE,LATITUDE,LONGITUDE,LOCATION,ON STREET NAME,CROSS STREET NAME,OFF STREET NAME,NUMBER OF PERSONS INJURED,NUMBER OF PERSONS KILLED,NUMBER OF PEDESTRIANS INJURED,NUMBER OF PEDESTRIANS KILLED,NUMBER OF CYCLIST INJURED,NUMBER OF CYCLIST KILLED,NUMBER OF MOTORIST INJURED,NUMBER OF MOTORIST KILLED,CONTRIBUTING FACTOR VEHICLE 1,CONTRIBUTING FACTOR VEHICLE 2,CONTRIBUTING FACTOR VEHICLE 3,CONTRIBUTING FACTOR VEHICLE 4,CONTRIBUTING FACTOR VEHICLE 5,COLLISION_ID,VEHICLE TYPE CODE 1,VEHICLE TYPE CODE 2,VEHICLE TYPE CODE 3,VEHICLE TYPE CODE 4,VEHICLE TYPE CODE 5Stream Load 映射原理:
规则1:CSV 没有列名,只有列位置
Stream Load 导入时,CSV 文件的表头行被 skip_header=1 直接跳过,完全不参与映射。系统只关心 CSV 每一列的物理顺序(第1列、第2列、第3列...),不关心它叫什么名字。 所以位置决定一切,名字无关紧要。
那么意思就是说:tmp_CRASH_DATE对应读取第一列,tmp_CRASH_TIME对应读取第二列。。。
规则2:columns 参数是"位置占位符 + 计算列"的混合列表
columns 参数中的每个元素,按逗号分隔,依次对应。
| 类型 | 格式 | 作用 | 是否消耗 CSV 列位置 |
|---|---|---|---|
| 位置占位符 | 变量名 |
依次读取 CSV 的一列,存入这个变量 | ✅ 是 |
| 计算列 | 列名 = 表达式 |
用已有变量计算新值,赋值给表的列 | ❌ 否 |
示例:
sql
columns: A, B, C = A + B, DA→ 读取 CSV 第1列B→ 读取 CSV 第2列C = A + B→ 计算列,不读 CSV,不消耗位置D→ 读取 CSV 第3列
规则3:计算列可以出现在任意位置,但建议放末尾
下面的两种写法完全等价:
写法一(计算列插中间):
sql
columns: tmp_DATE, tmp_TIME, CRASH_DATE = str_to_date(...), BOROUGH, ZIP_CODE- 计算列不消耗位置,所以
BOROUGH仍然对应 CSV 的第3列
写法二(计算列放最后,更清晰):
sql
columns: tmp_DATE, tmp_TIME, BOROUGH, ZIP_CODE, CRASH_DATE = str_to_date(...)tmp_DATE→ CSV第1列tmp_TIME→ CSV第2列BOROUGH→ CSV第3列ZIP_CODE→ CSV第4列CRASH_DATE = ...→ 计算列,用tmp_DATE和tmp_TIME计算
所以我们看到这种有=的就认为他不占读取位置就对了
规则4:列名匹配决定最终入库
经过前面的步骤,现在里面是这样的数据:
- 一些"位置占位符"变量(如
BOROUGH、ZIP_CODE) - 一些"计算列"的结果(如
CRASH_DATE)
StarRocks 会把这些变量的名字,与目标表的列名进行匹配:
- 如果变量名 = 表的列名 → 该变量的值入库
- 如果表的某个列没有对应的变量 → 该列为
NULL(如果允许)或报错 - 如果变量没有对应的表列 → 忽略
sql
-- 表有列:CRASH_DATE, BOROUGH, ZIP_CODE, LATITUDE
-- 导入时:
columns: BOROUGH, ZIP_CODE, LATITUDE, CRASH_DATE = now()
-- 结果:
-- BOROUGH → 入库到 BOROUGH 列
-- ZIP_CODE → 入库到 ZIP_CODE 列
-- LATITUDE → 入库到 LATITUDE 列
-- CRASH_DATE → 入库到 CRASH_DATE 列我们在columns找到对应的列名就是对应了表中的字段名,而里面的数据就是对应读取的csv中的列数
查询数据
那么导入之后呢,我们就可以正常使用StarRocks进行查询了,我们目前暂且就可以把他当做mysql去使用,例如单表查询每小时交通事故数量
sql
SELECT COUNT(*),
date_trunc("hour", crashdata.CRASH_DATE) AS Time
FROM crashdata
GROUP BY Time
ORDER BY Time ASC
LIMIT 200;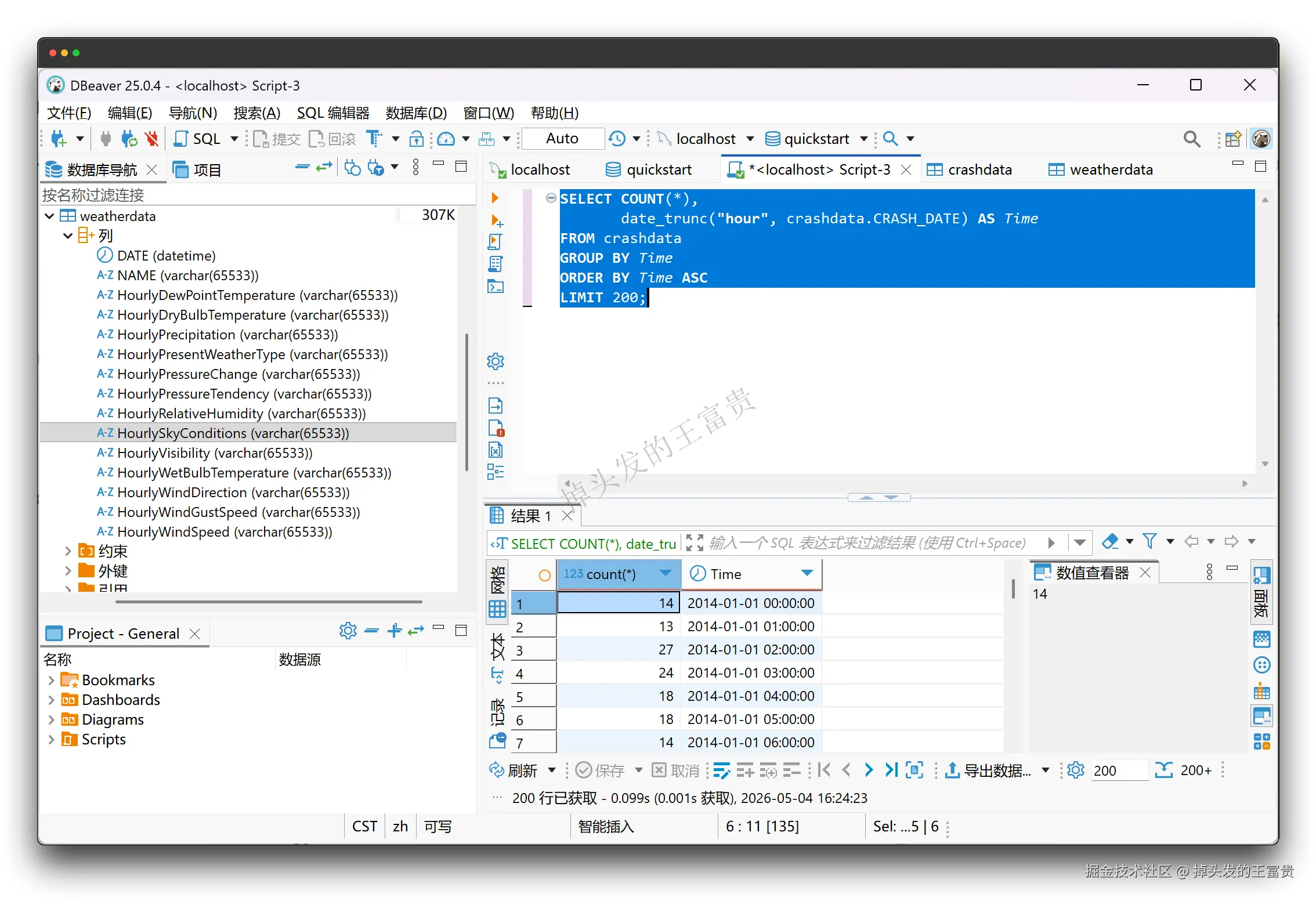 也可以多表查询把交通事故发生的时间,按"小时"对齐,去匹配气象数据。
也可以多表查询把交通事故发生的时间,按"小时"对齐,去匹配气象数据。
vbnet
SELECT c.BOROUGH ,w.`DATE`
FROM crashdata c
LEFT JOIN weatherdata w
ON date_trunc("hour", c.CRASH_DATE)=date_trunc("hour", w.DATE)
LIMIT 200;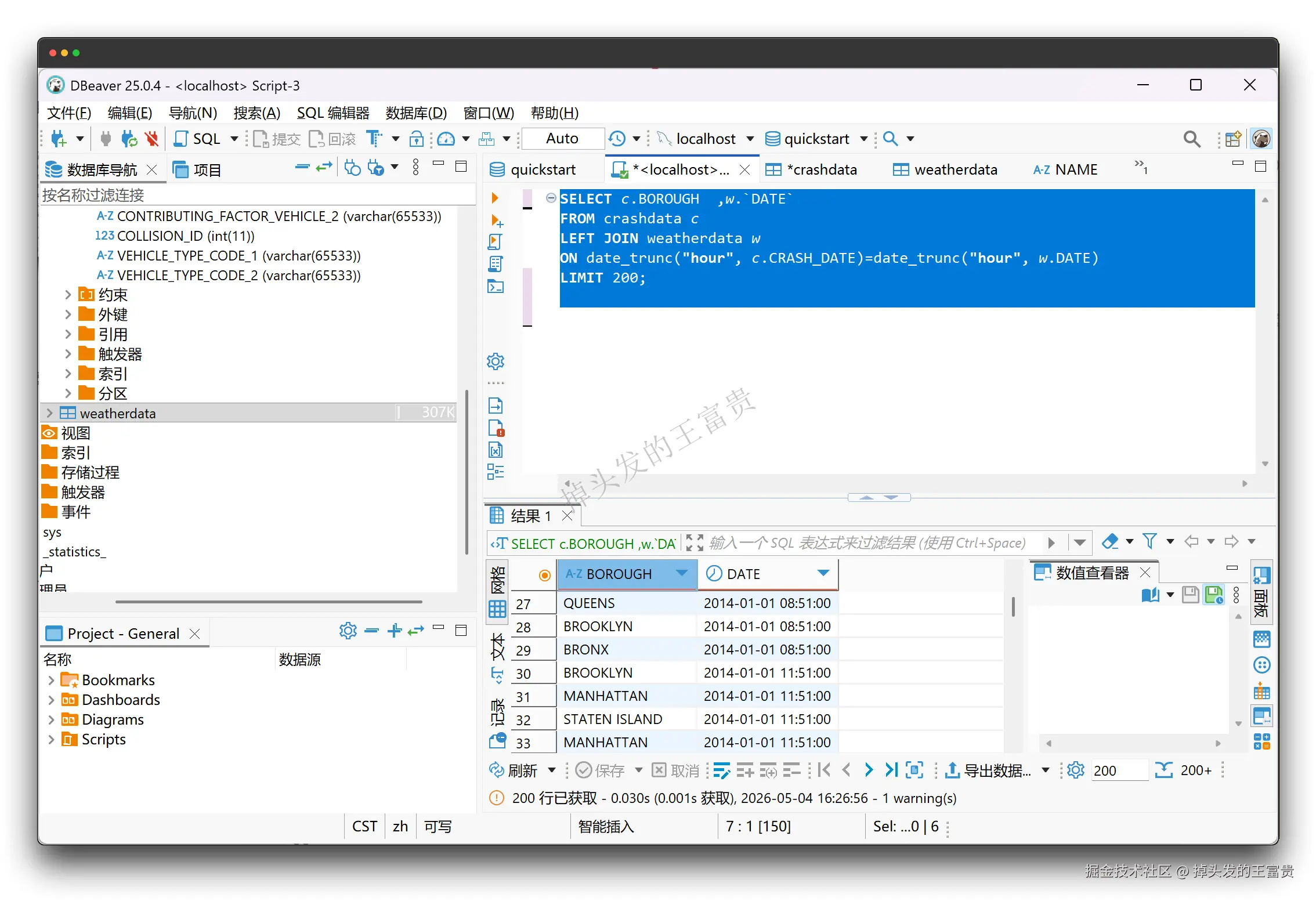
也可以做一些更复杂的查询:能见度情况对驾驶安全的影响 为了解能见度情况对驾驶安全的影响,需要对两张表格的 DATETIME 列进行 JOIN,分析在能见度不佳的情况下(0 到 1.0 英里之间)时的交通事故数量。
sql
SELECT COUNT(DISTINCT c.COLLISION_ID) AS Crashes,
truncate(avg(w.HourlyDryBulbTemperature), 1) AS Temp_F,
truncate(avg(w.HourlyVisibility), 2) AS Visibility,
max(w.HourlyPrecipitation) AS Precipitation,
date_format((date_trunc("hour", c.CRASH_DATE)), '%d %b %Y %H:%i') AS Hour
FROM crashdata c
LEFT JOIN weatherdata w
ON date_trunc("hour", c.CRASH_DATE)=date_trunc("hour", w.DATE)
WHERE w.HourlyVisibility BETWEEN 0.0 AND 1.0
GROUP BY Hour
ORDER BY Crashes DESC
LIMIT 100;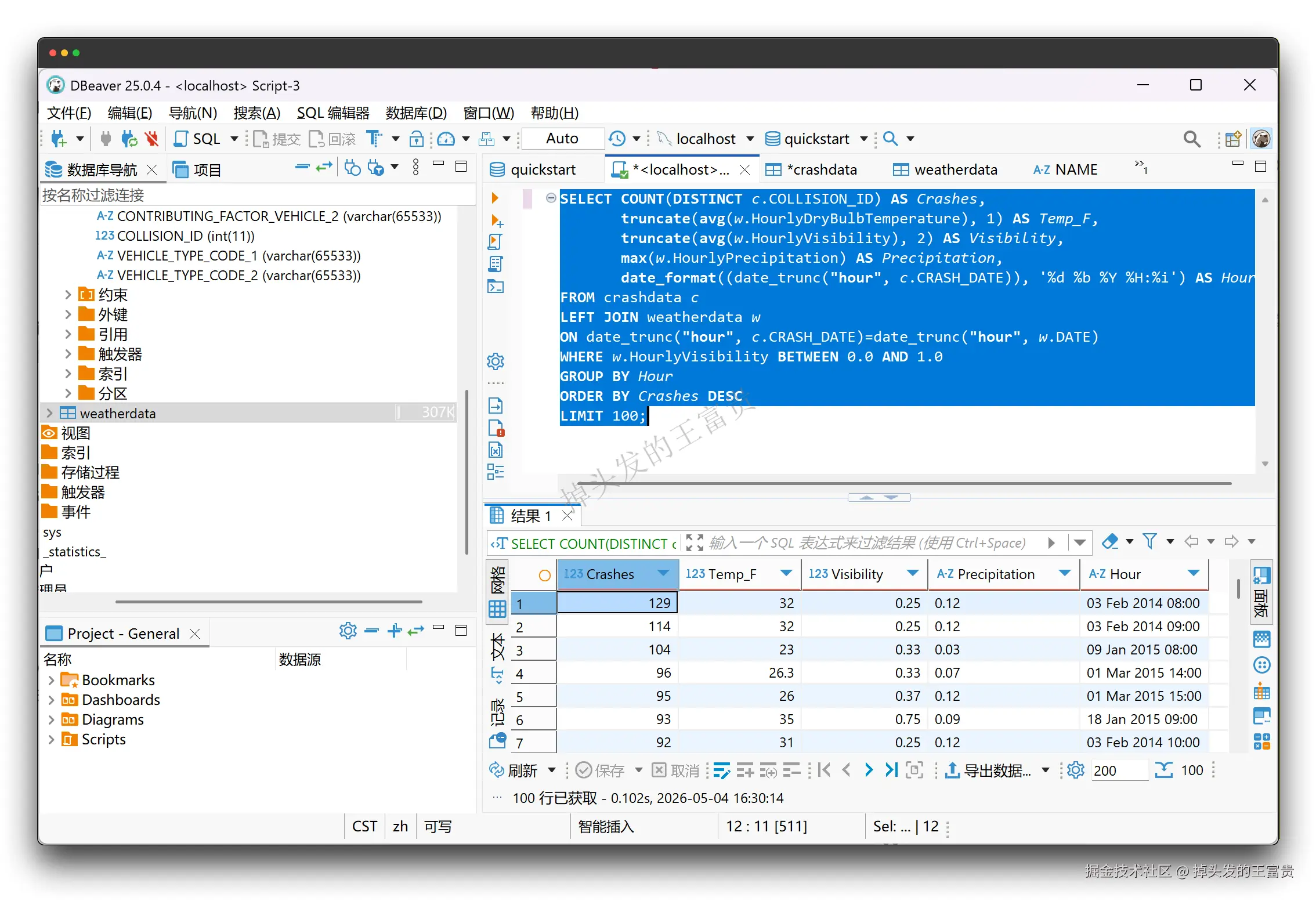
ok,以上就是我们的StarRocks入门教程·壹。关于他的更多玩法与讲解,我后面会持续更新的。最后提一句:
StarRocks 和 MySQL 虽然都支持 SQL,但定位很不一样。MySQL 是传统的事务型数据库(OLTP),擅长处理频繁的增删改和小规模查询;而 StarRocks 是专门为分析场景(OLAP)设计的。它的核心优势在于面对海量数据(比如几亿甚至几十亿行)时,秒级甚至毫秒级就能完成复杂的聚合、排序、多表关联查询,而 MySQL 在这种场景下很容易跑不动或者超时。StarRocks 支持向量化执行、列式存储、智能物化视图、实时数据更新等特性,可以一边实时写入数据一边做极速分析,不需要像传统方案那样提前做复杂的 ETL 预处理。简单说,如果你的业务是"对大量历史数据做快速统计和报表",StarRocks 比 MySQL 合适得多;但如果你是做订单录入、用户注册这类事务操作,MySQL 才是正确选择。两者往往搭配使用,MySQL 处理业务交易,StarRocks 用来分析交易数据。
