本文来自花椒技术部真实工程实践。如果你也在关注 AI 工程化、企业 Agent、MCP、Skill 或研发工具链,文末有「花椒技术交流群」入口,欢迎一起交流。
做企业 Agent 时,很多团队一开始会把注意力放在模型能力上:
它能不能理解用户意图,能不能拆任务,能不能把回答组织得像一个靠谱助手。
这些都重要,但真正进入业务流程后,我们更早遇到的问题是下一步:
Agent 听懂以后,怎么稳定、安全地调用业务能力?
如果只是回答问题,一个聊天框就够了。可一旦希望 Agent 完成查询、互动、分析、操作确认,它就必须知道:
- 有哪些能力可以调用;
- 每个能力需要哪些参数;
- 哪些动作执行前需要用户确认;
- 失败后怎么解释和重试;
- 调用链路出了问题怎么排查。
花椒 CLI 就是在这个问题下做起来的。
它表面上是一个命令行工具,但更准确地说,它是我们给 Agent 准备的一层业务能力入口:
text
Skill 负责描述能力
CLI 负责稳定执行动作
Gateway 负责收敛受控调用
下游业务服务保持原有边界这篇文章不讲"我们发布了一个 CLI",而是复盘一个更具体的工程问题:
企业 Agent 要从聊天走向执行,为什么不能只靠临时工具接入?为什么最后需要一层 Skill + CLI + Gateway 的能力入口? 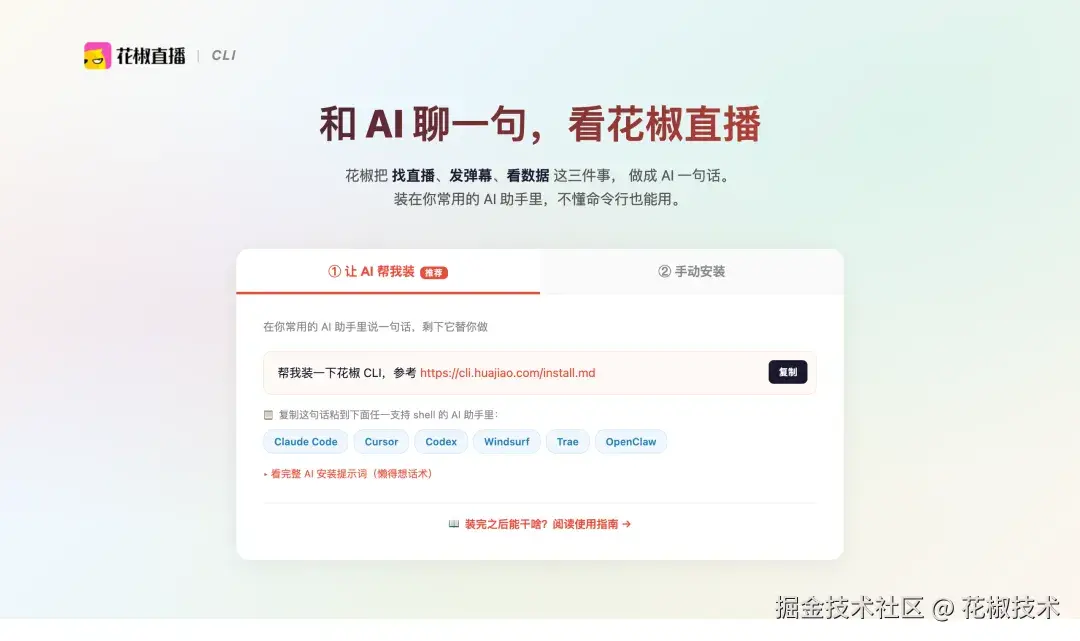
1. 问题不是"能不能调通",而是"能不能长期接入"
早期做 Agent 能力接入,最直接的办法通常是 MCP 或临时工具封装。
先接一个查询能力,再接一个执行能力,最后让 Agent 把结果返回给用户。这个方式很适合验证想法,也很适合快速跑通 Demo。
第一版花椒 CLI 的目标也很朴素:先证明 Agent 可以通过一个稳定执行入口调用花椒公开能力。
比如找直播:
用户在 AI 助手里描述自己想看什么,Agent 通过 CLI 查询公开直播内容,再把结果整理成自然语言反馈。
再比如发送互动内容:
用户说出目标和文本,Agent 组织参数,在用户确认后通过 CLI 发起调用。
这些场景本身并不复杂,但它们覆盖了几个关键问题:
- Agent 能不能读懂能力说明;
- 命令语义够不够清晰;
- 参数是否容易组织;
- 返回结果是否方便二次加工;
- 执行前后是否能给用户明确反馈。
这一步的价值,不在于命令有多复杂,而在于验证了一条路径:
业务能力不必直接交给 Agent,也不必让 Agent 理解背后的业务复杂性。中间可以先放一层稳定执行入口。
真正的问题出现在下一阶段。
当能力越来越多,临时接入会出现几个典型问题:
| 问题 | 表现 |
|---|---|
| 能力说明分散 | 每个工具都有自己的描述方式,Agent 学习成本上升 |
| 执行边界分散 | 哪些动作要确认、哪些动作只读,很容易各自实现 |
| 入口难复用 | 不同 AI 助手、不同业务场景可能重复封装 |
| 调用链路碎片化 | 出问题时不好判断是 Agent 参数、工具执行还是业务服务异常 |
| 后续接入变重 | 每新增一个能力,都要重新处理说明、执行、反馈和边界 |
所以,问题不是"能不能调通"。
更关键的是:能力多起来之后,能不能持续接入、统一约束、复用入口、追溯问题。
2. 为什么选择 CLI 做执行入口
我们后来评估 Agent CLI 这种形态,原因很简单:CLI 对开发者友好,对 Agent 也友好。
Claude Code、Cursor、Codex 这类工具,本来就能理解命令、执行命令、读取输出。对 Agent 来说,一条稳定命令就是一个明确动作。
它不需要理解业务服务背后的复杂结构,只需要知道:
text
什么时候调用
传什么参数
得到什么结果
失败时怎么处理对工程团队来说,CLI 也有几个现实优势。
第一,容易本地验证。
开发者可以直接在终端里跑命令,看参数、结果和错误提示是否稳定,不必每次都经过完整 Agent 链路调试。
第二,方便跨 AI 助手复用。
只要命令和输出稳定,同一套 CLI 可以被 Claude Code、Cursor、Codex 等不同入口调用。不同 Agent 不需要各自封装一套业务能力。
第三,可以把复杂能力收敛成少量清晰动作。
Agent 不应该直接面对复杂业务细节。它更适合面对一组动作明确、结果可解释的命令。
可以用一个脱敏伪命令理解这个思路:
bash
# 示例为脱敏伪命令,不代表真实命令名称
hj live list --keyword "唱歌" --limit 5
hj chat send \
--room "<room_id>" \
--text "这首歌好听"这里最关键的不是命令名字,而是命令契约:
- 动作清晰;
- 参数克制;
- 输出稳定;
- 错误可解释;
- 必要动作可确认。
CLI 的价值,不是让用户多学一个命令行工具,而是给 Agent 一个更稳定的执行面。
3. Skill 不是教程,而是给 Agent 的能力协议
只有 CLI 还不够。
人看到命令,可以读文档、查示例、慢慢试。Agent 不适合靠猜,它需要更直接的能力说明:
- 什么场景下应该使用这条命令;
- 参数应该怎么组织;
- 哪些信息缺失时要追问用户;
- 哪些动作执行前需要确认;
- 返回结果应该怎么解释给用户;
- 失败后应该怎么提示和降级。
这就是 Skill 的作用。
在这套设计里,Skill 不是普通使用教程,而是一份给 Agent 看的能力协议。它把人的操作经验写成 Agent 能理解的步骤。
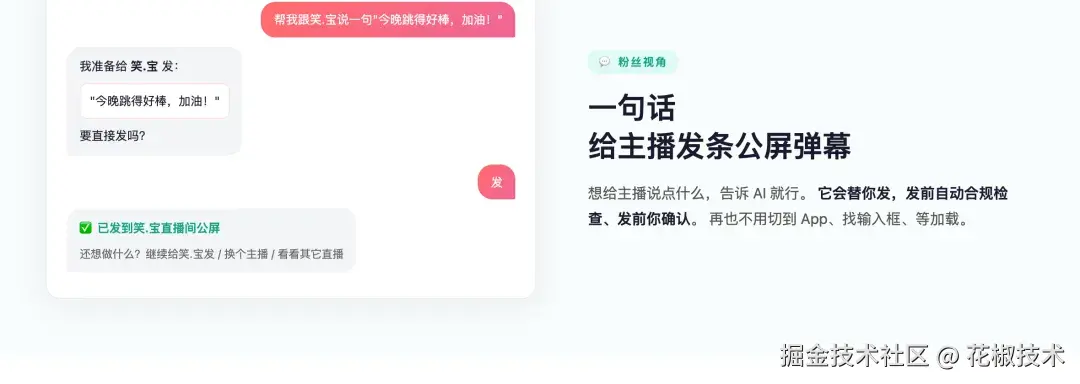
比如同样是"找直播",人可以自己打开页面筛选,但 Agent 需要知道:
text
用户表达观看意图
-> 提取关键词或偏好
-> 调用直播查询命令
-> 读取结构化结果
-> 按用户意图整理推荐
-> 必要时继续追问同样是"发送互动内容",Agent 需要知道:
text
用户表达发送意图
-> 确认目标直播间和文本
-> 判断是否需要二次确认
-> 调用 CLI 执行动作
-> 把执行结果解释给用户从这个角度看,花椒 CLI 的核心不是 CLI 单独成立,而是 CLI 和 Skill 组合成立。
Skill 负责描述能力,CLI 负责稳定执行。两者放在一起,Agent 才有机会从"能回答"走向"能办事"。
4. 命令层要收敛成"动作契约"
第二版花椒 CLI 做的重点,是把"能调通"推进到"能使用"。
能调通,说明工程师可以跑起来。
能使用,意味着外部开发者或 AI 助手可以找到入口、完成安装、知道怎么调用,并在失败时拿到基本反馈。
所以命令层要尽量收敛。
比如对外公开能力可以被整理成这些类型:
| 能力类型 | 命令层关注点 |
|---|---|
| 登录和环境检查 | 能否确认当前执行环境可用 |
| 版本和帮助信息 | Agent 能否判断当前 CLI 能力范围 |
| 查询类能力 | 输出是否结构化、稳定、方便二次加工 |
| 互动类能力 | 参数是否明确,执行前是否需要确认 |
| 数据类能力 | 结果口径是否公开,是否需要进一步脱敏 |
命令层最怕两件事。
第一,命令语义不稳定。
今天一个参数代表筛选条件,明天又被复用成其他含义,Agent 很难长期稳定调用。
第二,输出不稳定。
人可以读半结构化文本,Agent 更需要稳定字段。否则后续解释、总结、再调用都会变得不可靠。
所以命令层不是内部实现细节,而是 Agent 认识业务能力的一组动作。
一个命令能不能进入 CLI,不只看它能不能执行,还要看它是否满足几个条件:
- 动作边界清楚;
- 输入参数可解释;
- 输出结果稳定;
- 失败原因可表达;
- 是否需要用户确认能被明确描述。
这也是 CLI 和普通脚本最大的区别。
脚本可以只服务写脚本的人。
Agent CLI 要服务的是一个会自动组织步骤、会连续调用能力、也可能误解上下文的执行者。
5. 为什么内部能力还需要 Gateway
对外公开能力跑通以后,我们开始看另一个问题:同一套思路能不能反过来支撑内部 Agent?
内部场景比公开能力复杂得多。
能力更多,边界更细,调用后果也更需要可追溯。如果还停留在"哪里需要就接一个工具",后面会很难维护。
这时只靠 Skill + CLI 还不够。
我们需要一层 Gateway,把受控调用收敛起来。
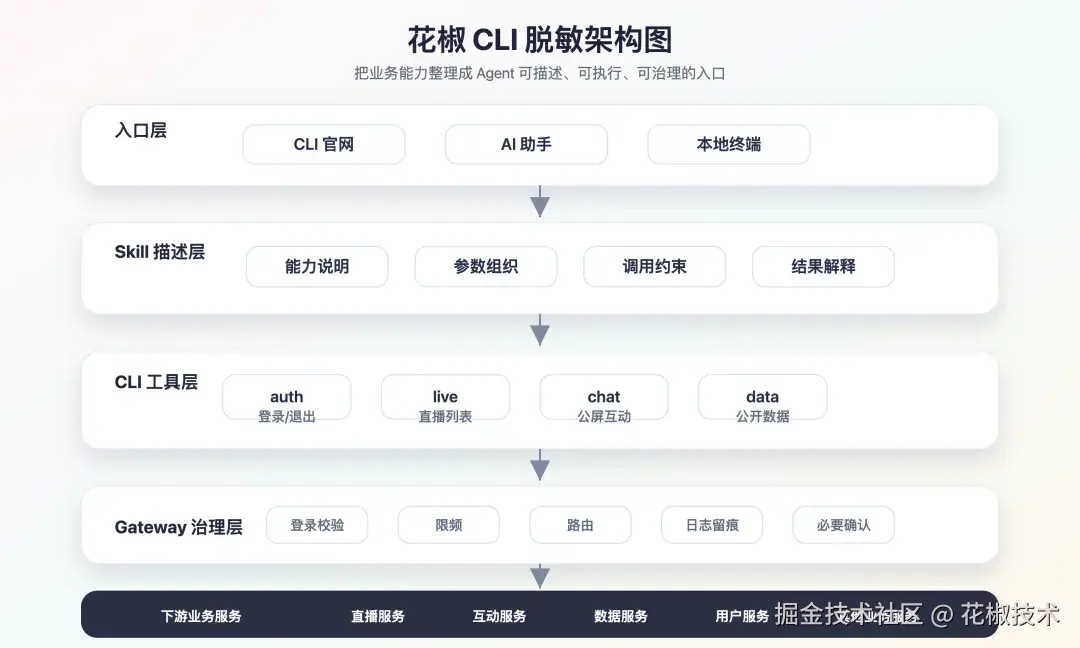 Gateway 解决的不是"怎么让命令执行",而是"怎么让命令以受控方式执行"。
Gateway 解决的不是"怎么让命令执行",而是"怎么让命令以受控方式执行"。
它主要承担几类通用能力:
| 能力 | 作用 |
|---|---|
| 身份校验 | 确认调用者和执行环境 |
| 限频 | 避免异常连续调用影响服务 |
| 路由映射 | CLI 不直接感知复杂后端结构 |
| 日志留痕 | 方便排查 Agent、CLI 和业务服务之间的问题 |
| 必要确认 | 对关键动作保留人工确认节点 |
这里需要注意一个边界:
Agent 擅长理解意图和组织步骤,但不应该直接承担业务边界判断。真正需要长期稳定的能力,应该进入受控执行链路。
有了 Gateway 后,整体关系会更清楚:
text
Agent 读 Skill,知道什么时候调用能力
CLI 执行标准命令,输出稳定结果
Gateway 处理身份、限频、路由、日志和确认
下游业务服务继续保持原有边界这样一来,Agent 面对的是清晰命令;CLI 面对的是统一入口;业务服务面对的是受控调用。
6. 从 MCP 到 Skill + CLI + Gateway,不是替代关系
我们没有把 MCP 和 CLI 对立起来。
MCP 适合探索和快速接入。尤其在早期验证阶段,它能很快把一个工具交给 Agent,让团队判断这个场景是否成立。
但从长期维护看,稳定能力更需要沉淀成可复用入口。
这也是我们从 MCP 探索走向 Skill + CLI + Gateway 的原因。
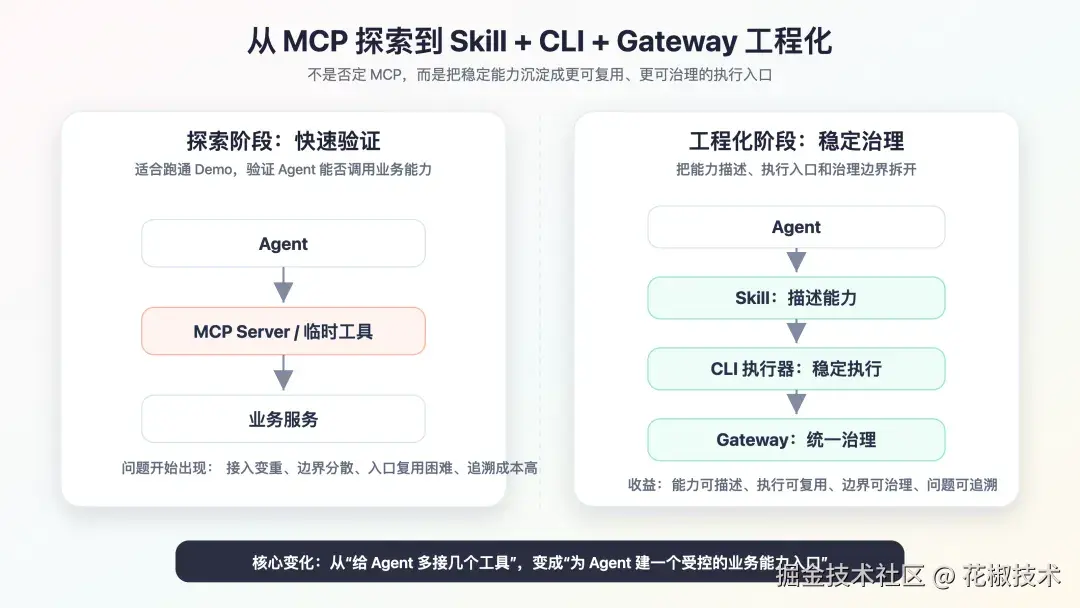
可以简单理解成两个阶段:
text
探索阶段:
Agent -> MCP / 临时工具 -> 单个业务能力
工程化阶段:
Agent -> Skill -> CLI -> Gateway -> 下游业务服务探索阶段关注的是"这件事能不能跑通"。
工程化阶段关注的是"这类能力能不能持续接入、统一约束、复用入口、追溯问题"。
这两个阶段都需要。
如果一开始就做完整平台,容易过度设计。
如果一直停留在临时接入,后面又会变成碎片化工具集合。
比较现实的路径是:
先用轻量方式验证场景,再把稳定、明确、高频的能力沉淀到 Skill + CLI + Gateway 链路里。
7. 不是什么能力都适合放进 CLI
做到这里,很容易产生另一个诱惑:把所有能力都塞进 CLI。
我们没有这么做。
CLI 适合承载边界清楚、动作明确、结果可解释的能力。它不适合把复杂后台完整搬到命令行里,也不适合替代原有业务系统。
判断一个能力适不适合进入 CLI,可以先看几个问题:
| 问题 | 判断 |
|---|---|
| 这个动作是否足够稳定 | 频繁变化的能力不适合过早沉淀 |
| 参数是否能清楚表达 | 依赖大量页面上下文的能力要谨慎 |
| 结果是否可解释 | 输出必须能被 Agent 和用户理解 |
| 是否需要人工确认 | 需要确认的动作必须在链路里显式表达 |
| 失败是否可恢复 | 失败原因要能解释,最好能给出下一步 |
| 是否适合跨入口复用 | 只服务单个页面的能力不一定要 CLI 化 |
这也是花椒 CLI 的边界:
它不是万能入口,而是 Agent 调用业务能力时的一层标准化入口。
能抽象成稳定动作的能力,适合进入 CLI。
高度依赖人工判断、页面上下文很重、规则仍在频繁变化的能力,不急着放进去。
8. 一套可复用的接入 checklist
如果你也在做企业 Agent 或内部业务能力接入,可以用下面这张 checklist 先过一遍。
8.1 能力是否适合交给 Agent
- 用户意图是否能稳定识别;
- 动作边界是否清楚;
- 输入参数是否能被自然语言可靠提取;
- 输出是否能被 Agent 二次解释;
- 是否存在必须人工确认的步骤。
8.2 Skill 是否写清楚
- 什么时候调用;
- 参数怎么组织;
- 信息缺失时怎么追问;
- 调用前是否需要确认;
- 失败后怎么解释;
- 返回结果怎么转成用户能理解的话。
8.3 CLI 是否足够稳定
- 命令名称是否稳定;
- 参数含义是否稳定;
- 输出是否结构化;
- 错误码或错误信息是否可解释;
- 是否能在本地独立验证。
8.4 Gateway 是否收敛通用边界
- 身份校验是否统一;
- 是否有限频能力;
- 路由是否与 CLI 解耦;
- 日志是否能定位问题;
- 必要确认是否显式存在。
8.5 下游业务是否保持边界
- Agent 是否不直接面对复杂业务服务;
- CLI 是否不承载过多业务决策;
- Gateway 是否只做通用控制,不侵入具体业务逻辑;
- 下游服务是否继续保持原有稳定边界。
这张表的核心不是"每项都做满",而是避免 Agent 能力接入变成一堆临时工具。
9. 总结
回头看花椒 CLI,它不是一个突然冒出来的命令行工具。
它更像是企业 Agent 工程化里的一层执行入口。
从这次实践里,我们沉淀下来的判断是:
- Agent 从聊天走向执行,第一步不是继续做更大的聊天框;
- 业务能力要先被整理成可描述、可调用、可治理的入口;
- Skill 解决"怎么描述能力";
- CLI 解决"怎么稳定执行动作";
- Gateway 解决"怎么受控调用和追溯问题";
- 下游业务服务继续保持原有边界。
这套方法不只适用于花椒 CLI,也适用于很多企业内部 Agent 项目。
不要急着让 Agent 连接所有东西。
花椒技术交流群
还在孤军研究 AI 工程化、AI 编程、Agent 落地,没人同行交流、没人拆解实战?
这里汇聚一线技术从业者,专注代码评审、企业内部 AI 助手真实实战落地。
想紧跟 AI 前沿动态、交流工程落地经验、少走踩坑弯路,欢迎直接加入「花椒技术交流群」。
群内专属福利拉满:每日精选研发向 AI 行业日报、文章独家延伸资料、文中未展开的技术细节,全部同步共享。
 如果群过期关注公众号 花椒技术 ,私信回复「交流群」获取最新入群二维码。
如果群过期关注公众号 花椒技术 ,私信回复「交流群」获取最新入群二维码。