先抛一个我觉得很多人没认真想过的事实:同一个模型,套在不同的工具里,干活水平能差出一大截。
有人做过独立测试,同样是 Claude Sonnet,通过 Claude Code 跑某个 benchmark 是 77%,通过 Codex 跑是 93%,差了 15 个点。模型一模一样,差的全是外面那层 harness,也就是工具怎么给模型喂上下文、怎么管工具调用、怎么处理多轮。
这件事的含义是:「哪个 AI 编程助手更好」根本不是一个模型问题,而是一个任务级的经验问题。在你这个具体仓库、这类具体任务上谁更强,只能测,不能靠口碑和直觉。
但现实是几乎没人真去测。因为测起来很烦:开三个终端,把同一个任务分别敲进 Claude Code、Codex、aider,等它们各自跑完,再肉眼比三份 diff,手动数 token 和耗时。一次两次还行,每个任务都这么来谁受得了,于是大家随便选一个就一直用下去了。
我把这一个小时的活压成了一条命令,工具叫 CodeJoust,pip install codejoust 就能装。

它做什么
一条命令,把同一个任务并行丢给多个 AI 编程 agent,每个在自己独立的 git worktree 里跑(互相看不到对方的改动,也不会污染你的工作区),跑完自动打分、给你获胜的那份补丁:
bash
codejoust run "fix the off-by-one in Scheduler.next_fire" \
--agents claude-code,codex,aider --test "pytest tests/test_scheduler.py"你会拿到三样东西:
- 一张按名次排好的终端表格(谁赢一目了然)
- 一个单文件 HTML 报告,里面是每个 agent 的完整 diff,可以直接分享
- 每个 agent 一个
.patch文件,看中谁的直接git apply落地
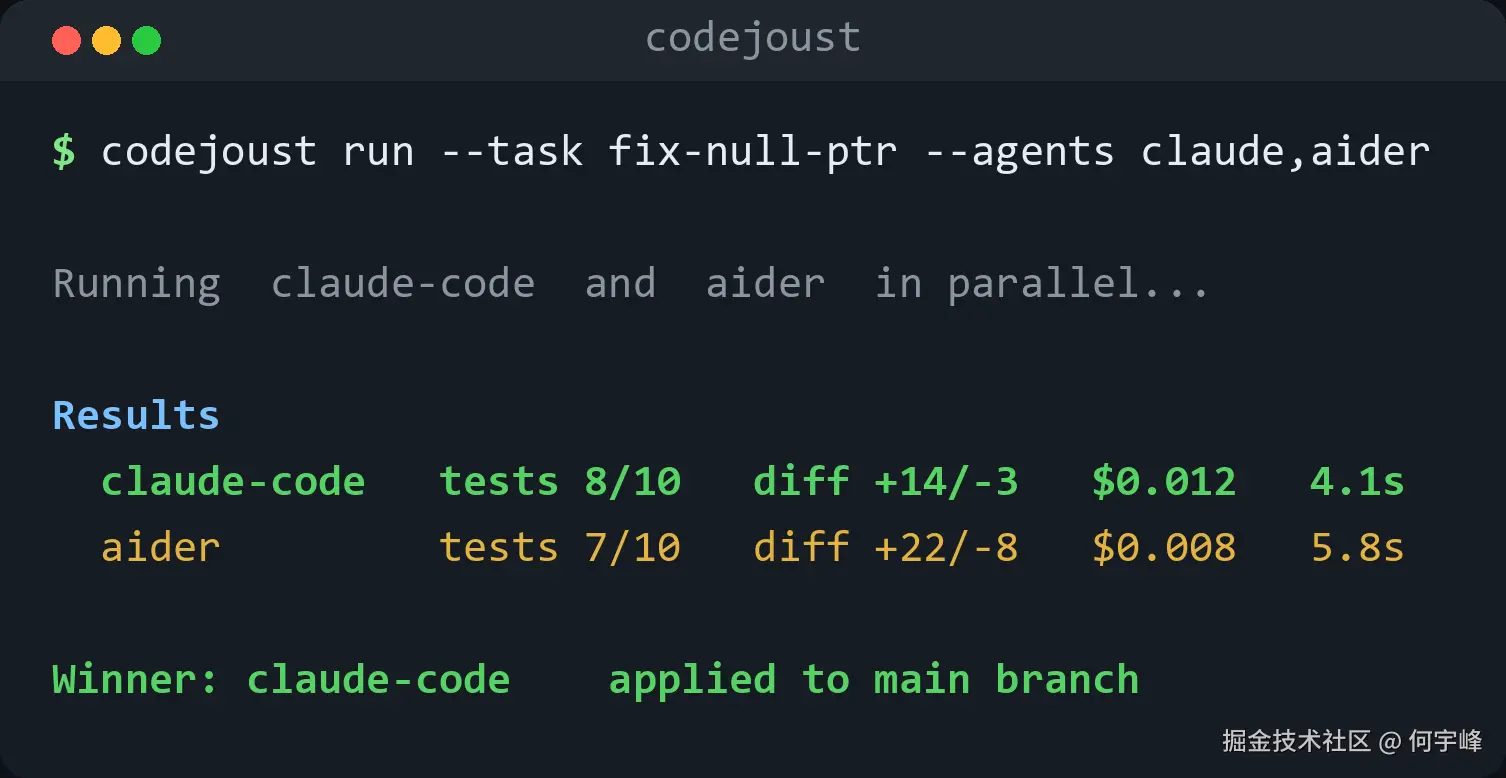
终端输出大概长这样:
bash
# agent status diff tests cost time
★ 1 claude-code success +38/-2 8/8 $0.028 71.3s
2 codex success +21/-1 7/8 $0.019 55.7s
winner: claude-code它怎么判谁赢
我特意没搞成一个糊在一起的加权总分,那种分谁也说不清是怎么来的。CodeJoust 用四个信号,按固定优先级顺序,第一个能严格分出高下的信号就定胜负:
- 测试通过率 (
通过数 / 总数)。自动识别 pytest 或 npm test,也能--test指定。 - 成本(美元)。越低越好,从每个 CLI 自己的 usage 输出里抠出来。
- diff 大小(增删行数)。越小越好,改动越克制通常越安全。
- 墙钟时间。平手时的 tiebreaker。
这个顺序是有讲究的:如果 Claude Code 过了 8/8、codex 过了 7/8,那 codex 再便宜也没用,正确性优先级最高,先压过去。只有在正确性打平时,才轮到成本、改动量、速度去比。我觉得这套排序比一个魔法权重总分诚实得多,每个判断你都能复盘是哪一条决定的。
一点工程细节
- 每个 agent 一个 git worktree:这是关键。多个 agent 真并行跑同一个仓库,不隔离的话改动会互相打架。用 worktree 各跑各的,跑完各自出一份独立 diff,干净。
- CodeJoust 自己不碰你的 key:它只是 shell 调各家的 CLI(claude-code、codex、aider、gemini cli),你本来怎么登录、key 配在哪,原样照用,它不接管认证。
- 可复现 :在被测仓库放一个
codejoust.yaml,把参赛 agent、测试命令、超时、要不要出 HTML 固化下来,之后每次codejoust run "任务"都是同一套裁判标准。命令行参数还能临时覆盖。 codejoust doctor:先自检你本机装了哪些 agent CLI,省得跑到一半发现某个没装。- 产物全落在
.codejoust/runs/<时间戳>/:HTML 报告、session.json(结构化数据,方便接 CI 或脚本)、每个 agent 的.patch和原始日志。
谁用得上
- 正在纠结买哪个 / 续费哪个的人:别看测评榜,测你自己的活。在你真实的仓库、你常写的那类任务上跑几次,数据会告诉你答案。
- 想接进 CI 的团队 :
session.json是结构化的,可以把「同一类任务哪个 agent 性价比最高」做成长期监控。 - 纯好奇的人:看同一个 bug 不同 agent 给出的不同解法,本身就挺涨见识,有的保守有的激进,差别很明显。
pip install codejoust,代码在 github.com/he-yufeng/C... ,MIT 开源。觉得有用给个 star,也欢迎提 issue 说你想让它再支持哪个 agent。
最后抛一个我觉得很值得较真的问题。如果同一个模型,只是换一层 harness,就能在某些 agent benchmark 上摆动三五十个百分点(今年 Terminal-Bench、SWE-bench 上都有人测出过这种量级),那我们现在挂在"某模型编程能力"名下的那些榜单,到底有多少在测模型本身,又有多少其实在测它外面那层脚手架?当"能力"本质上是模型、harness、任务三者的联合产物,一个真正可复现、能横向比较的 agent 评测协议,到底该把哪些东西固定死,又必须把哪些显式报告出来?我做 CodeJoust 越久,越觉得"别看榜、测你自己的活"这句话背后,其实藏着一个还没被认真解决的测量学问题。