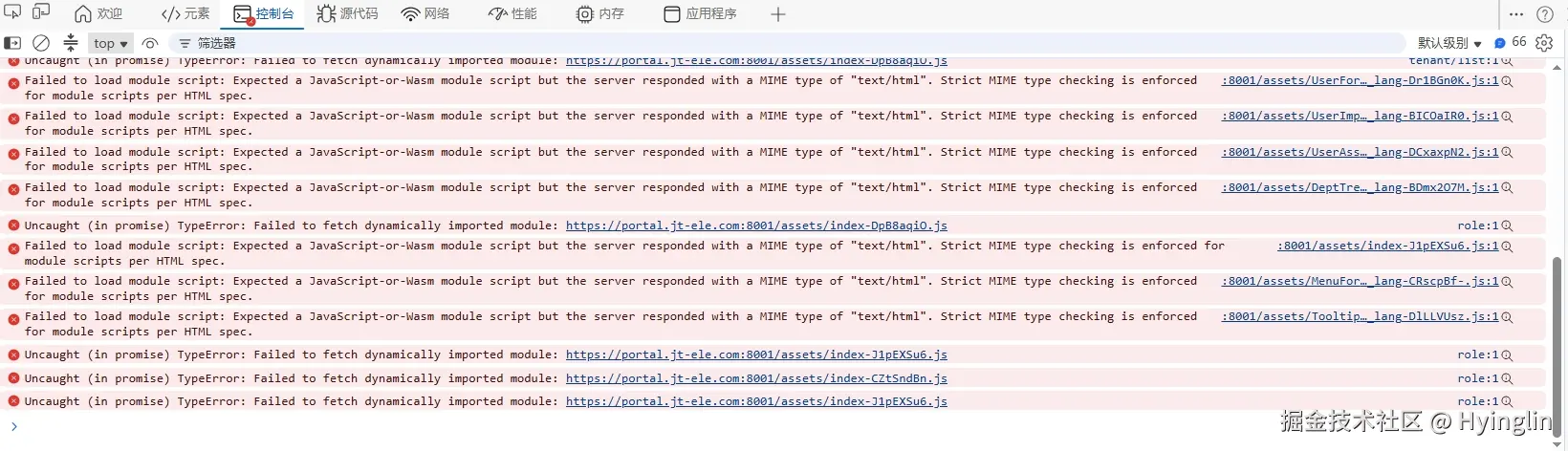
原因:
部署后主应用或子应用重新构建后,JS/CSS 文件名 hash 会变。但用户浏览器里可能还留着旧页面或旧入口 HTML,继续请求已经不存在的老 chunk。
这时服务端通常会把 404 回退成 index.html,浏览器本来要加载 JS,却拿到了 HTML,于是控制台出现:
Failed to fetch dynamically imported moduleExpected a JavaScript-or-Wasm module script but the server responded with a MIME type of "text/html"
页面就会一直停在 loading/遮罩层。清缓存后正常,说明不是业务逻辑 bug,而是前端版本缓存错配。
解决方案
1. 前端自动恢复(核心)
在三个项目里加了统一的 chunk 加载失败兜底:
- 主应用
jt-ui-admin - 售后子应用
jt-web-support - 档案子应用
jt-web-archive
统一处理这些场景:
- Vite 预加载失败
vite:preloadError - Vue Router 懒加载失败
router.onError - qiankun 当前子应用加载失败
一旦识别到是"旧 chunk / 资源版本不匹配"错误,就自动刷新页面一次,让用户拿到最新入口和新资源,避免长期卡 loading。
同时加了 15 秒冷却,防止网络异常时无限刷新。
2. 发布侧缓存策略(辅助)
补充了部署说明 docs/deploy-cache-policy.md,建议:
- 先上传新
assets,再替换index.html - 旧 hash 静态资源保留一段时间,不要一发布就删光
index.html不强缓存,带 hash 的assets/*可长期缓存
这样可以从源头减少"旧页面请求不到新 chunk"的概率。
效果
部署后如果用户还开着旧页面:
- 请求旧 chunk 失败
- 前端识别错误
- 自动刷新一次
- 加载新版本,页面恢复正常
用户基本无感,不需要手动清缓存。
一句话总结
这不是 nginx 或服务器故障,而是部署后旧前端缓存还在引用已失效的 chunk。我的方案是:前端自动刷新兜底 + 发布时保留旧静态资源 + 入口 HTML 不强缓存,双管齐下解决部署后偶发卡 loading 的问题。
上线后预期
部署后若用户仍开着旧页面:
-
请求旧 hash chunk → 拿到 HTML fallback → 报错
-
触发 reloadOnChunkLoadError → 页面自动刷新
-
拿到新 index.html 和新 chunk → 恢复正常
若 15 秒内连续失败(例如真网络问题),不会无限刷新,而是走 qiankun 的错误提示。
建议
发布侧仍建议配合 docs/deploy-cache-policy.md:
• 先上传新 assets,再换 index.html
• 旧 hash 文件保留 1--7 天
这样大部分用户甚至不会触发自动刷新。