FAISS vs Elasticsearch 全面对比:从向量检索、全文搜索到 RAG 选型指南
TL;DR
- 场景:RAG 系统、知识库、商品/日志搜索、AI Agent 记忆等需要"召回"的工程选型
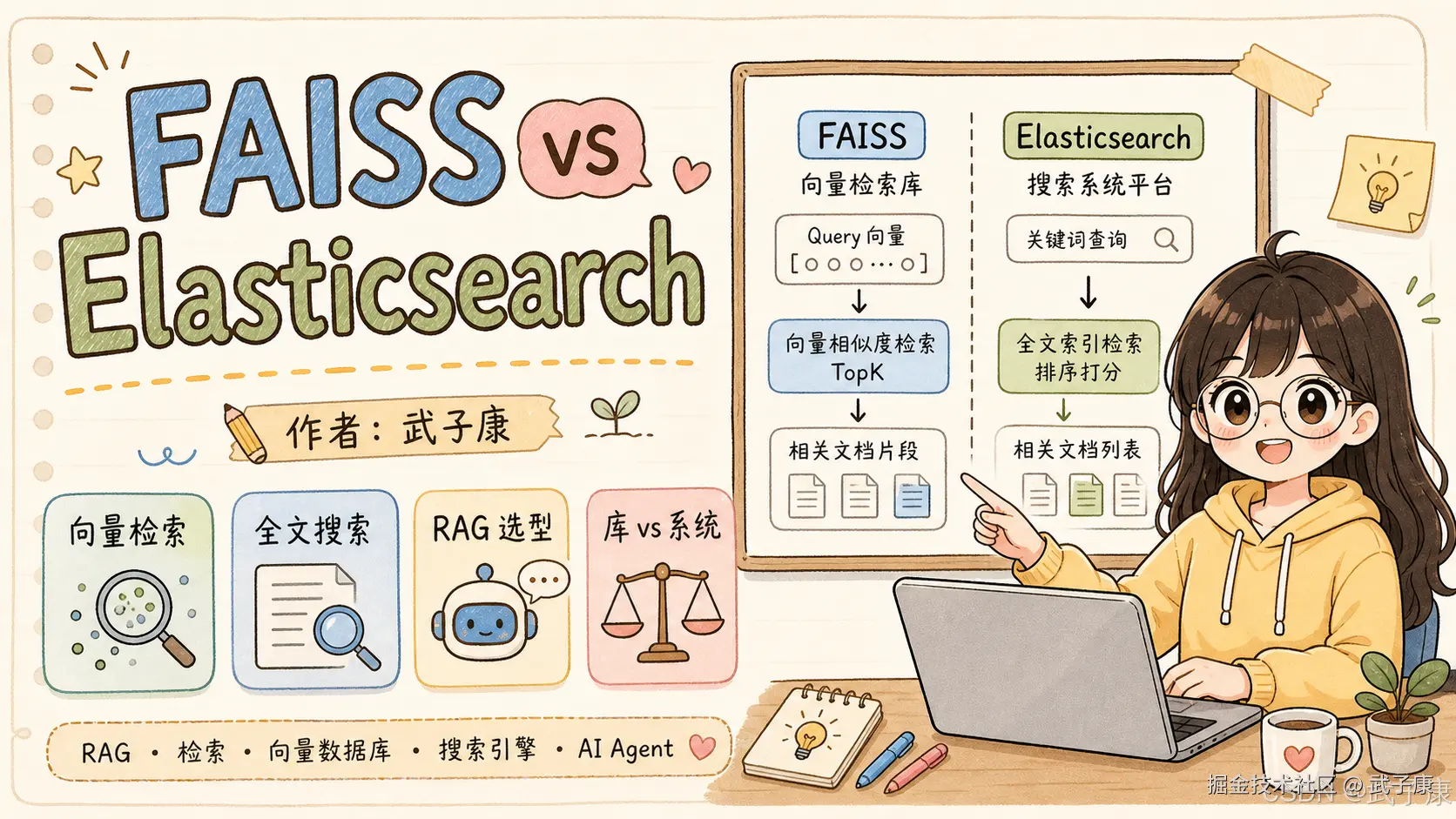
- 结论 :FAISS 是向量检索库 ,Elasticsearch 是搜索引擎+系统;二者边界不同,重叠只在向量检索
- 产出:6 维度对比表 + 6 大典型场景选型建议 + 一套从 Demo 到生产的演进路径
版本矩阵
| 功能/特性 | 状态 | 说明 |
|---|---|---|
| FAISS(faiss-cpu 1.8.x) | ✅ 已验证 | Meta 开源向量检索库,C++ 核心 + Python 绑定,支持 CPU/GPU |
| Elasticsearch 9.2 | ✅ 已验证 | 2025 年发布的最新稳定版,新增 DiskBBQ 磁盘向量索引、Streams、Elastic Agent Builder |
| Elasticsearch kNN + dense_vector | ✅ 已验证 | ES 内置向量检索能力,支持混合搜索(BM25 + kNN) |
| FAISS IndexFlatL2/IVF/PQ/HNSW/GPU | ✅ 已验证 | 多索引结构,覆盖从暴力精确到近似近邻的全谱系 |
| Elasticsearch 8.x → 9.x 跨大版本升级 | ⚠️ 需注意 | 需重点关注兼容性适配、数据安全备份、业务零中断 |
| FAISS GPU 版本与 CUDA 版本对齐 | ⚠️ 需注意 | faiss-gpu-cu11/cu12 对 Python 和 CUDA 版本敏感,常出现 CUBLAS_STATUS_SUCCESS 报错 |
| pgvector / Milvus / Qdrant 等向量数据库 | ✅ 已验证 | 介于 FAISS 和 ES 之间的方案,按业务数据形态选型 |
1. 先说结论:它们不是同一类东西
FAISS 和 Elasticsearch 经常被放在一起比较,但它们本质上不是同一类东西。
FAISS 更像一个"向量检索算法库"。
Elasticsearch 更像一个"搜索系统"。
这句话是理解两者区别的核心。
FAISS 主要解决的问题是:给我一个向量,在海量向量里快速找出最相似的 Top K。
Elasticsearch 主要解决的问题是:给我一段文本、一些过滤条件、一些排序规则,在海量文档里快速找出最相关的一批结果。
后来 Elasticsearch 也支持了 dense_vector、kNN、语义搜索、混合检索,所以很多 RAG 项目会把它和 FAISS 放在一起比较。但从抽象层级看,它们的边界完全不同。
FAISS 偏底层、偏算法、偏单机或自建服务。
Elasticsearch 偏工程化、偏系统、偏生产检索平台。
如果只做 embedding 相似度搜索,FAISS 很强。如果要做业务搜索、关键词检索、过滤、聚合、权限、多字段查询、排序、可观测和集群扩展,Elasticsearch 更完整。
如果是 RAG 系统,二者都能用,但适合的阶段不同:
小规模原型、离线实验、算法验证,用 FAISS 更轻。
生产级知识库、复杂业务检索、混合搜索,用 Elasticsearch 更自然。
2. 为什么会把它们放在一起比较?
因为现在大量 AI 应用都需要"召回"。
比如用户问:
text
公司年假制度是什么?系统不能直接让大模型瞎编。它需要先从知识库中找到相关文档片段,再把片段交给大模型生成回答。这个过程通常叫 RAG,也就是 Retrieval-Augmented Generation。
一个简化链路是:
text
用户问题
↓
转成 embedding 向量
↓
在知识库中召回相关文档
↓
把召回结果塞给大模型
↓
大模型生成答案这里的"召回相关文档"会涉及向量检索。
FAISS 能做。Elasticsearch 也能做。
于是问题变成:到底选 FAISS,还是 Elasticsearch?
但这个问题本身有一点误导性。FAISS 和 Elasticsearch 的重叠点主要在"向量检索"。除此之外,Elasticsearch 还承担大量搜索系统能力,而 FAISS 不负责这些。
更准确的问题应该是:
我的场景只需要一个高性能向量索引,还是需要一个完整的搜索平台?
3. FAISS 是什么?
FAISS,全称 Facebook AI Similarity Search,是 Meta 开源的向量相似度搜索库。官方文档对它的定位很明确:用于 dense vector 的高效相似度搜索和聚类。
所谓 dense vector,就是模型生成的稠密向量。
比如一句话:
text
如何申请年假?经过 embedding 模型后,可能变成一个 768 维、1024 维或 1536 维的浮点数组:
text
[0.012, -0.231, 0.087, ...]FAISS 做的事情,就是把大量这样的向量组织起来,然后在查询时快速找到距离最近的一批向量。
比如:
text
query_vector = "年假怎么请?" 的向量
FAISS 返回:
Top1: 员工年假申请流程
Top2: 请假审批规则
Top3: 法定年假与公司福利年假说明FAISS 不天然关心这些向量背后的文档结构。
它不关心标题、作者、时间、权限、状态、分类、租户、部门、标签。
它关心的是:向量 A 和向量 B 有多近?
所以 FAISS 是一个非常纯粹的向量搜索工具。它支持不同索引结构和距离度量,例如 L2、内积、IVF、PQ、HNSW、GPU index 等。你可以围绕召回率、延迟、内存占用、构建时间和更新复杂度做很细的控制。
这也是 FAISS 的价值:底层可控,适合实验、算法验证、纯向量召回、多模态相似检索和极致性能调优。
4. Elasticsearch 是什么?
Elasticsearch 是一个分布式搜索和分析引擎。
它最早的核心优势是全文检索。比如你有一批文章、商品、日志、订单、文档,希望支持:
text
关键词搜索
多字段匹配
分词
相关性排序
过滤条件
聚合统计
高亮
分页
排序
近实时写入
分布式扩展这些就是 Elasticsearch 的传统强项。
比如搜索商品:
text
关键词:机械键盘
品牌:Keychron
价格:300-800
库存:有货
排序:销量优先Elasticsearch 非常适合这种复杂检索。
随着 AI 应用发展,Elasticsearch 也加入了 dense vector、kNN、语义搜索、混合搜索等能力。它现在不仅能做传统关键词搜索,也能做向量检索。
但它的核心定位依然是搜索系统,不是单纯的向量算法库。
你可以把一个文档写入 Elasticsearch:
json
{
"title": "员工年假制度",
"content": "员工入职满一年后享有年假...",
"department": "HR",
"status": "published",
"embedding": [0.012, -0.231, 0.087]
}然后在同一个系统里做关键词查询、过滤查询、向量 kNN 查询,或者关键词 + 向量的混合查询。
Elasticsearch 不只是检索向量,它还管理文档、索引、分片、副本、过滤、聚合、监控、扩展和生产搜索链路。
所以它不是一个"更慢的 FAISS",也不是一个"带 HTTP 接口的 FAISS"。
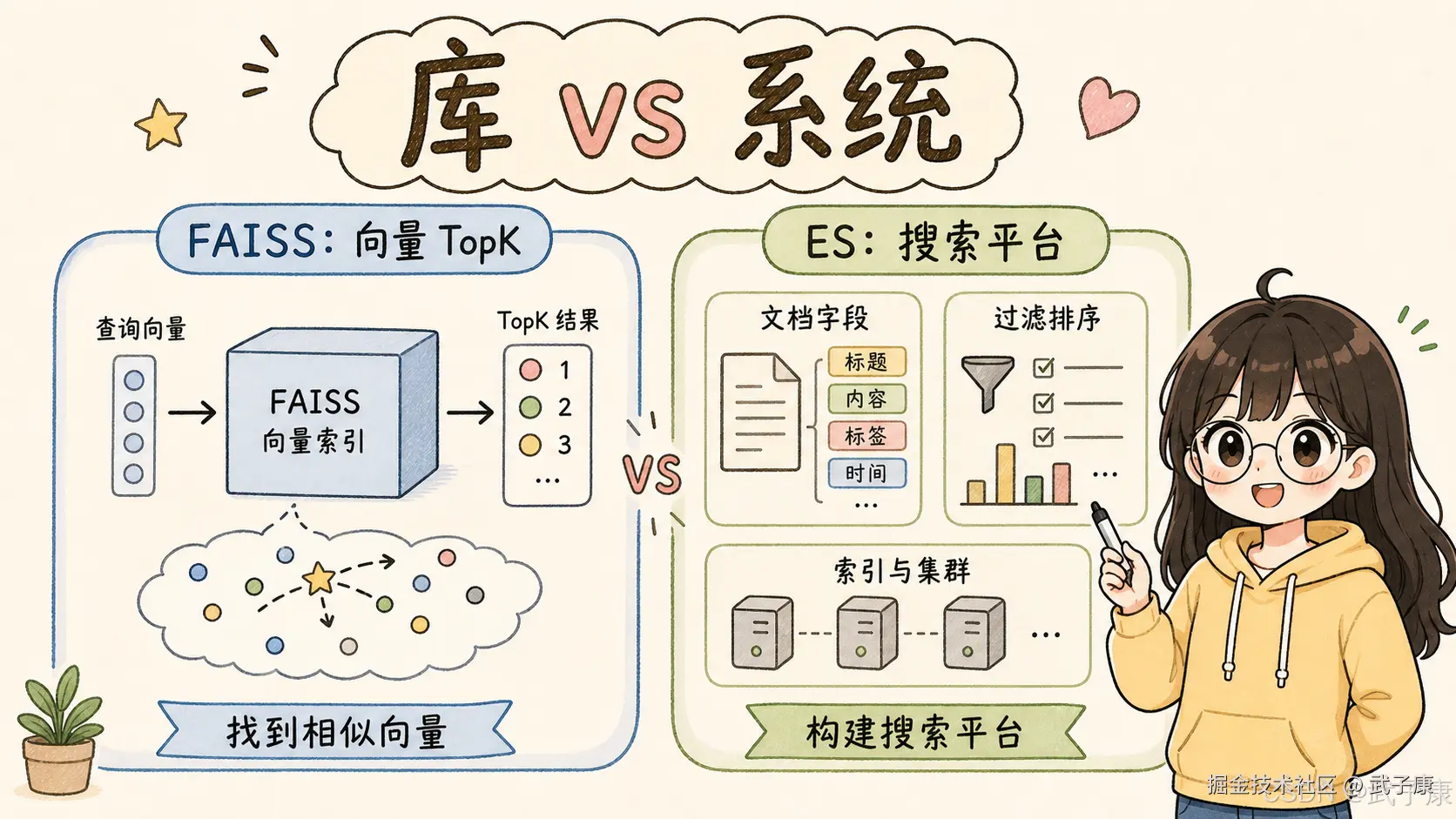
5. 最核心的区别:库 vs 系统
FAISS 是库。
Elasticsearch 是系统。
这个区别很重要。
FAISS 通常作为代码中的一个组件使用:
python
import faiss
index = faiss.IndexFlatL2(768)
index.add(vectors)
distances, ids = index.search(query_vector, 10)它给你的是向量检索能力。
但文档怎么存、元数据怎么存、权限怎么做、增量更新怎么做、服务怎么部署、数据怎么备份、查询怎么审计、接口怎么暴露,这些都需要你自己处理。
Elasticsearch 则是一个独立搜索服务。你把文档和字段写进去,系统负责索引、检索、过滤、排序、分片、副本、近实时搜索和查询 API。
所以二者的工程边界可以这样理解:
text
FAISS:帮你找相似向量
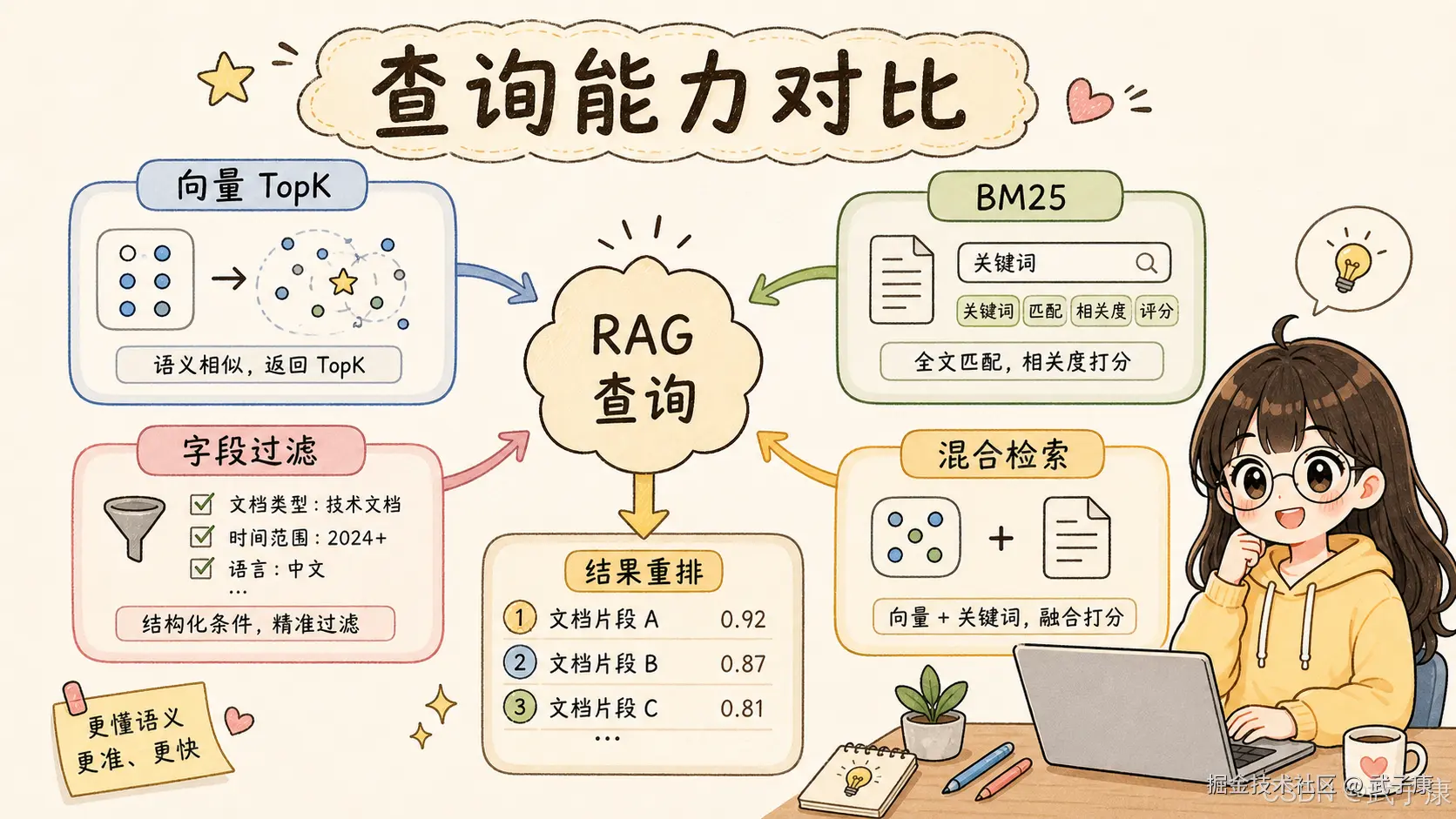
Elasticsearch:帮你建设搜索系统6. 查询能力对比
FAISS 擅长的是向量相似度查询。
典型查询是:
text
给定一个 query vector,找出最相似的 Top K 个 vector它适合:
text
相似句子检索
相似图片检索
音频 embedding 检索
推荐召回
RAG 原型召回
离线向量实验但 FAISS 不擅长复杂业务查询。比如:
text
只查当前用户有权限访问的文档
只查最近 30 天的内容
只查 status=published 的文章
标题必须包含"年假"
内容语义上接近"请假流程"
按发布时间倒序
按部门聚合这些不是 FAISS 的核心能力。你当然可以在 FAISS 外面加过滤逻辑,但系统复杂度会迅速上升。
Elasticsearch 擅长复杂搜索。
它可以做全文检索、短语匹配、多字段权重、过滤查询、范围查询、排序、分页、聚合、高亮、地理位置检索、嵌套文档查询、向量 kNN 查询和混合搜索。
这意味着 Elasticsearch 可以同时处理:
text
语义相关性
关键词精确匹配
业务过滤条件
文档结构
排序策略
聚合分析比如企业知识库搜索:
text
用户问题:怎么申请年假?
过滤条件:只查 HR 制度文档
权限条件:只查当前用户可见文档
状态条件:只查已发布文档
排序策略:语义相关性 + 关键词匹配 + 更新时间这种场景 Elasticsearch 明显更自然。
7. 向量检索能力对比
如果只看纯向量检索,FAISS 通常更灵活,也更适合做算法实验和性能极限优化。
FAISS 可以让你更细地控制索引类型,例如:
text
IndexFlatL2:暴力精确搜索,简单但数据大时慢
IndexIVFFlat:倒排聚类,加速搜索
IndexIVFPQ:倒排 + 量化压缩,节省内存
IndexHNSW:图索引,适合近似最近邻
GPU Index:使用 GPU 加速这些索引结构背后对应的是不同取舍:
text
召回率
延迟
内存占用
构建时间
更新复杂度
实现复杂度Elasticsearch 的向量检索能力更偏工程产品化。你通过 mapping、dense_vector、kNN 查询参数来使用。它牺牲一部分底层控制权,换来的是系统集成能力。
比如你可以在同一个索引里同时存:
text
标题
正文
标签
分类
发布时间
权限字段
embedding 向量然后在同一次查询里组合:
text
BM25 关键词检索
向量相似度检索
过滤条件
重排序这对生产系统非常重要。
8. 不要让向量检索替代全文检索
全文检索是 Elasticsearch 的传统强项,也是很多 RAG 系统容易低估的一层。
FAISS 不做传统全文检索。它不理解分词、倒排索引、BM25、短语匹配、字段权重、关键词高亮。
如果用户搜索:
text
Spring Cloud Gateway 401 问题关键词本身非常关键。Spring Cloud Gateway 是技术实体,401 是错误码。语义向量可能能召回相关内容,但未必能稳定命中最准确的文档。
再比如:
text
Qwen3-ASR c=32 p99 是多少?这里的 Qwen3-ASR、c=32、p99 都是强词面信号。只用向量检索,系统可能召回"ASR 性能测试总结",但不一定精确命中包含这些字段的片段。
所以不要以为有了向量检索,BM25 就过时了。
真实生产系统里,最常见的可靠方案不是"只用向量",而是"关键词 + 向量"的混合搜索。
9. 为什么 Elasticsearch 更适合生产 RAG?
RAG 的检索不是只有向量搜索。
一个成熟 RAG 检索链路通常包含:
text
文档解析
切 chunk
清洗
embedding
索引写入
查询改写
关键词召回
向量召回
混合排序
rerank
权限过滤
上下文拼接
答案生成
引用溯源
反馈闭环FAISS 主要覆盖 embedding 向量召回。
Elasticsearch 可以覆盖文档索引、关键词召回、向量召回、过滤、混合搜索、排序和部分聚合分析。
所以在 RAG 场景里,二者的判断方式不是"谁更 AI",而是"你的检索链路复杂到什么程度"。
如果只是本地知识库 Demo,FAISS 很适合。
如果是企业内部知识库,有多部门、多权限、多租户、文档频繁更新、关键词搜索、语义搜索、过滤和审计,Elasticsearch 更合适。
如果既要强业务搜索,又要极致向量召回,可以考虑 Elasticsearch + FAISS 组合:Elasticsearch 负责关键词召回、过滤、元数据查询;FAISS 负责高性能向量召回;reranker 负责统一重排。
但大多数团队不应该一开始就上组合架构。正确顺序通常是:
text
先用 Elasticsearch 或 FAISS 跑通
再根据瓶颈拆分
最后才考虑组合架构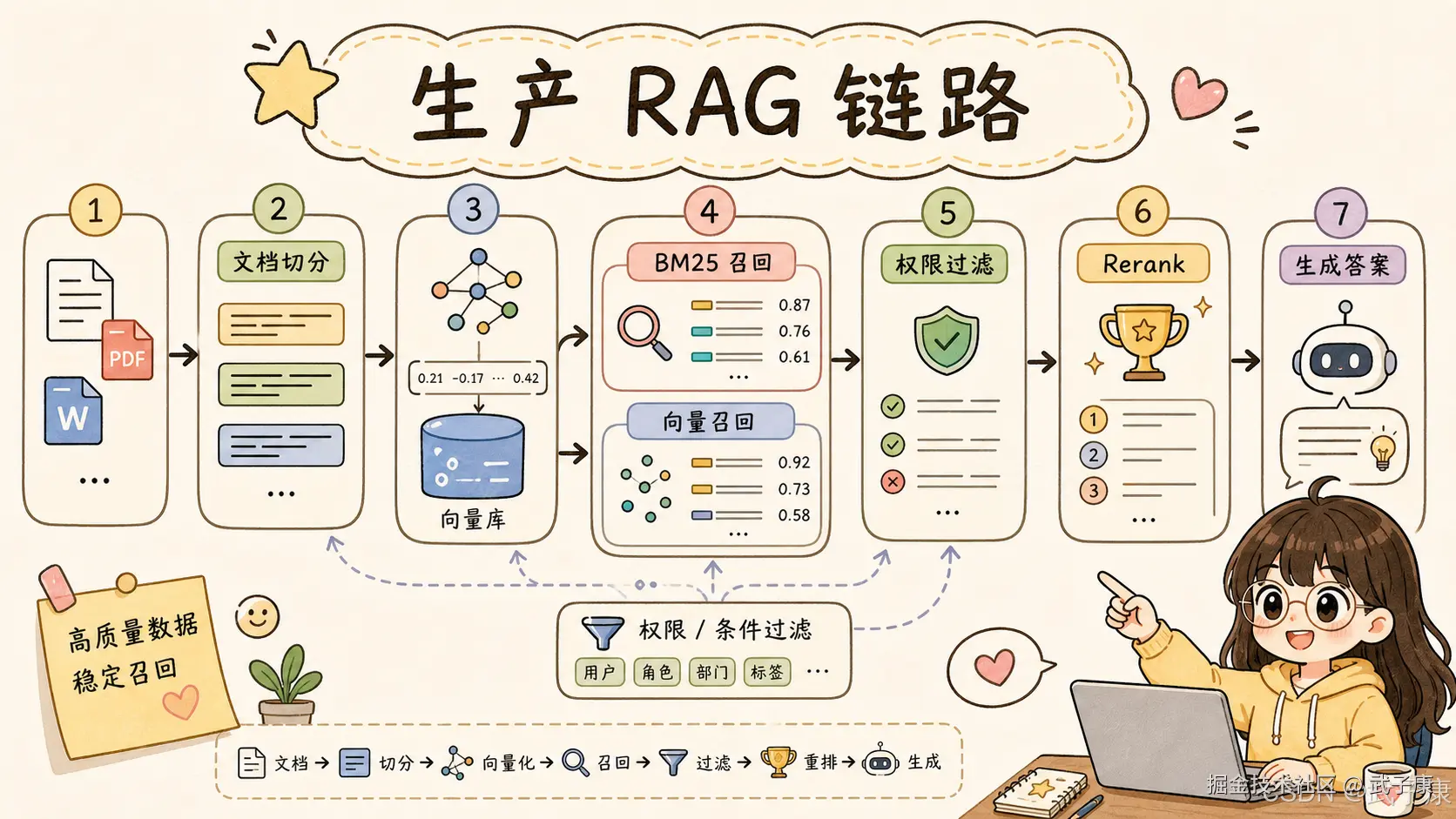
10. 数据存储与更新能力
FAISS 不应该被当成完整数据库使用。
它主要存向量索引。通常你会在 FAISS 里存:
text
vector_id -> vector然后在其他地方存:
text
vector_id -> document
vector_id -> metadata
vector_id -> permission
vector_id -> source典型组合是:
text
FAISS:负责找相似向量
MySQL/PostgreSQL:负责存文档元数据
对象存储:负责存原始文件
Redis:负责缓存
业务服务:负责权限过滤和结果组装这意味着 FAISS 往往是系统里的一个模块,而不是完整的数据平台。
Elasticsearch 则可以直接存文档和元数据,并在查询时直接做字段过滤:
text
tenant_id = company_a
visibility contains employee
department = HR
status = published这就是 Elasticsearch 对业务系统更友好的地方。
更新与删除也是同理。
FAISS 在批量静态数据检索上很舒服。比如你有 1000 万条向量,离线构建索引,然后线上只查不改,这种场景 FAISS 很适合。
但如果数据频繁更新、删除、权限变化、文档状态变化,FAISS 的使用复杂度会上升。你需要自己处理 ID 映射、删除标记、索引重建、增量合并、版本切换、冷热索引和数据一致性。
Elasticsearch 对文档更新、删除、近实时搜索、索引别名、滚动重建这些工程问题支持更完整。
如果你的知识库每天都在变,权限也在变,文档状态也在变,Elasticsearch 的工程优势会更明显。
11. 性能不能只看向量 TopK
"谁更快"不能简单回答。
如果是纯向量检索,且你愿意认真调索引结构、内存、GPU、批处理,FAISS 很可能更快、更省、更可控。
尤其是以下场景:
text
数据主要是向量
查询逻辑简单
过滤条件少
可以离线构建索引
追求极致延迟
需要 GPU 加速
团队能掌控索引参数FAISS 很强。
但如果是业务搜索,性能不能只看向量检索耗时。
真实查询通常是:
text
关键词召回
向量召回
权限过滤
字段过滤
排序
分页
高亮
聚合
结果组装这时候 Elasticsearch 的整体工程性能更有意义,因为它快在完整搜索链路,而不是只快在"找向量"。
所以性能选型要看问题定义:
text
只比 vector topK:FAISS 通常更有优势
比完整业务搜索:Elasticsearch 通常更有优势12. 典型场景怎么选?
本地知识库 Demo:选 FAISS。几千篇文章、几十万 chunk、单机运行、不需要复杂权限,FAISS 简单、轻量、成本低。
企业内部知识库:选 Elasticsearch。多部门、多权限、多租户、文档频繁更新、需要关键词搜索和语义搜索,Elasticsearch 更接近生产系统。
商品搜索:选 Elasticsearch。商品搜索高度依赖关键词、类目、品牌、价格、库存、销量、排序策略和运营干预。FAISS 可以作为向量召回模块辅助使用,但很难单独承担商品搜索系统。
图片、视频、音频相似检索:优先 FAISS。如果主要是向量相似度搜索,FAISS 很适合。但如果还需要复杂元数据过滤,可以考虑 FAISS + 数据库,或者直接用 Elasticsearch / 专用向量数据库。
日志搜索:选 Elasticsearch。日志搜索依赖时间范围、关键词、服务名、trace_id、level、聚合和上下文,FAISS 不适合做主系统。
AI Agent 工具记忆:如果只是轻量长期记忆,FAISS 足够;如果需要多用户隔离、权限管理、时间过滤、标签过滤、关键词检索、可观测和分析,Elasticsearch 更合适。
13. 和向量数据库的关系
除了 FAISS 和 Elasticsearch,还有 Milvus、Qdrant、Weaviate、Pinecone、Vespa、pgvector 等方案。
它们大多位于 FAISS 和 Elasticsearch 之间。
可以粗略理解为:
text
FAISS:向量检索库
Milvus/Qdrant/Weaviate:向量数据库
Elasticsearch:搜索引擎 + 向量检索
PostgreSQL + pgvector:关系数据库 + 向量扩展如果你只需要向量检索服务,但不想自己封装 FAISS,可以考虑向量数据库。
如果你的核心是业务搜索和文档搜索,Elasticsearch 仍然很有竞争力。
如果你的数据本来就在 PostgreSQL,且规模不大,pgvector 也可能更简单。
选型不是看谁更"AI 原生",而是看谁最贴近你的业务数据形态。
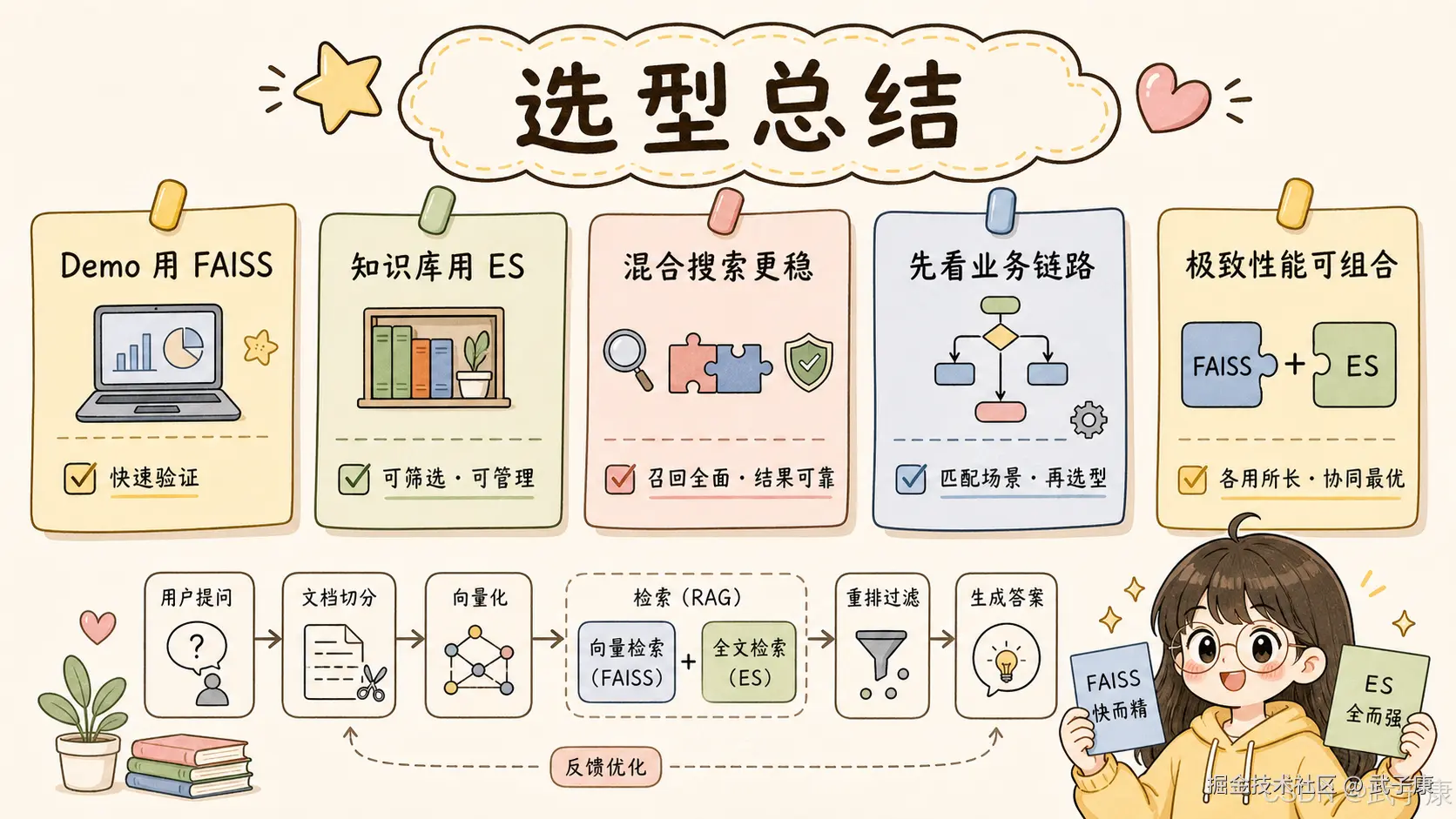
14. 最后给一个实用判断表
| 问题 | 更偏 FAISS | 更偏 Elasticsearch |
|---|---|---|
| 主要需求 | 相似向量 TopK | 完整搜索系统 |
| 查询类型 | 语义相似 | 关键词 + 过滤 + 排序 |
| 数据形态 | 向量为主 | 文档 + 字段 + 向量 |
| 更新频率 | 静态或批量重建 | 频繁更新删除 |
| 权限过滤 | 自己实现 | 字段过滤更自然 |
| 全文检索 | 不擅长 | 强项 |
| 混合搜索 | 需要组合 | 更方便 |
| 运维方式 | 库轻,外围自建 | 系统重,能力完整 |
| 适合阶段 | Demo、实验、纯向量召回 | 生产搜索、企业知识库、复杂 RAG |
我的建议是:
个人项目 / Demo:选 FAISS。
企业知识库 / 文档搜索:选 Elasticsearch。
多模态相似检索:优先 FAISS。
已经有 Elasticsearch 技术栈:优先 Elasticsearch。
极致向量性能场景:优先 FAISS,或者 FAISS + 搜索系统。
不确定怎么选:先用 Elasticsearch。
原因很简单,大多数业务系统最后都会需要关键词、过滤、权限、排序、更新、运维和可观测。
FAISS 和 Elasticsearch 的区别,不是"谁更先进",而是"你到底要一个向量检索内核,还是一个搜索系统"。
把这个问题想清楚,RAG 选型就不会乱。
参考资料
- FAISS 官方文档:faiss.ai/
- Elasticsearch kNN search 官方文档:www.elastic.co/docs/soluti...
- Elasticsearch dense_vector 官方文档:www.elastic.co/docs/refere...
- Elastic Practical BM25:www.elastic.co/blog/practi...
- Elasticsearch 9.2 Release Notes(DiskBBQ / Streams / Elastic Agent Builder)
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
No module named '_swigfaiss' |
直接 pip install faiss,旧版 Windows/SWIG 兼容问题 |
检查 Python 版本与 numpy 版本冲突 | 改用 pip install faiss-cpu 或 conda install -c pytorch faiss-cpu |
FAISS GPU 报 Faiss assertion 'err == CUBLAS_STATUS_SUCCESS' |
faiss-gpu 版本与 CUDA 驱动 / cudatoolkit / PyTorch 不兼容 | nvidia-smi、nvcc --version、conda list cudatoolkit 对比 |
切换 faiss-gpu-cu11 / faiss-gpu-cu12 wheel,或升级 CUDA 驱动;A100/V100 等注意 Tensor Core 兼容 |
undefined symbol: cublasLtGetEnvironmentMode, version libcublasLt.so.12 |
预编译 wheel 的 CUDA 版本与系统 libcublasLt 不一致 | 看报错符号所属的 libcublas 路径 | 安装与驱动匹配的 faiss-gpu-cuXX 版本,避免混用 conda 与 pip 源 |
| Elasticsearch 8.x → 9.x 升级后查询失败 | 跨大版本兼容问题(mapping、字段类型、客户端 SDK) | 升级前跑 compatibility check;先在测试环境单节点验证 | 备份 → 灰度 → 参考官方"准备-执行-验证-回退"流程升级 |
| 向量召回相关性差,关键词又匹配不上 | 单一向量检索或单一 BM25,无法兼顾语义与词面 | 对比纯向量、纯 BM25、混合召回三路结果 | 引入混合搜索(BM25 + kNN 融合打分),关键词类用 BM25,语义类用向量 |
| FAISS 增量更新导致结果不一致 | FAISS 不擅长动态删除/权限变化 | 观察 vector_id 命中漂移、删除后仍被召回 | 引入 IDMap + 删除标记位,或将元数据切到 MySQL/PG 做二次过滤 |
| FAISS-gpu 计算 jaccard_distance 返回全 0 | faiss-gpu 版本过旧与新 CUDA 驱动不兼容 | 报 attribute 找不到或数值异常 |
升级到 faiss-gpu-cu11 并对齐 PyTorch、CUDA 版本 |
| RAG 召回文档答非所问 | 缺权限过滤,召回出用户无权限访问的文档 | 对比召回结果与用户实际可见文档 | 在 ES / 业务层加权限字段过滤 + rerank 阶段二次过滤 |
作者:武子康的个人博客