本文只对G1机器人进行训练和验证,实现功能:攀升箱子、爬斜坡、搬箱子、空翻、跳舞、行走等等
环境搭建、复现入门:《VLA 系列》UniLab 机器人强化训练 | 复现指导
参考链接:unilabsim.github.io/UniLab-doc/...
示例效果1: 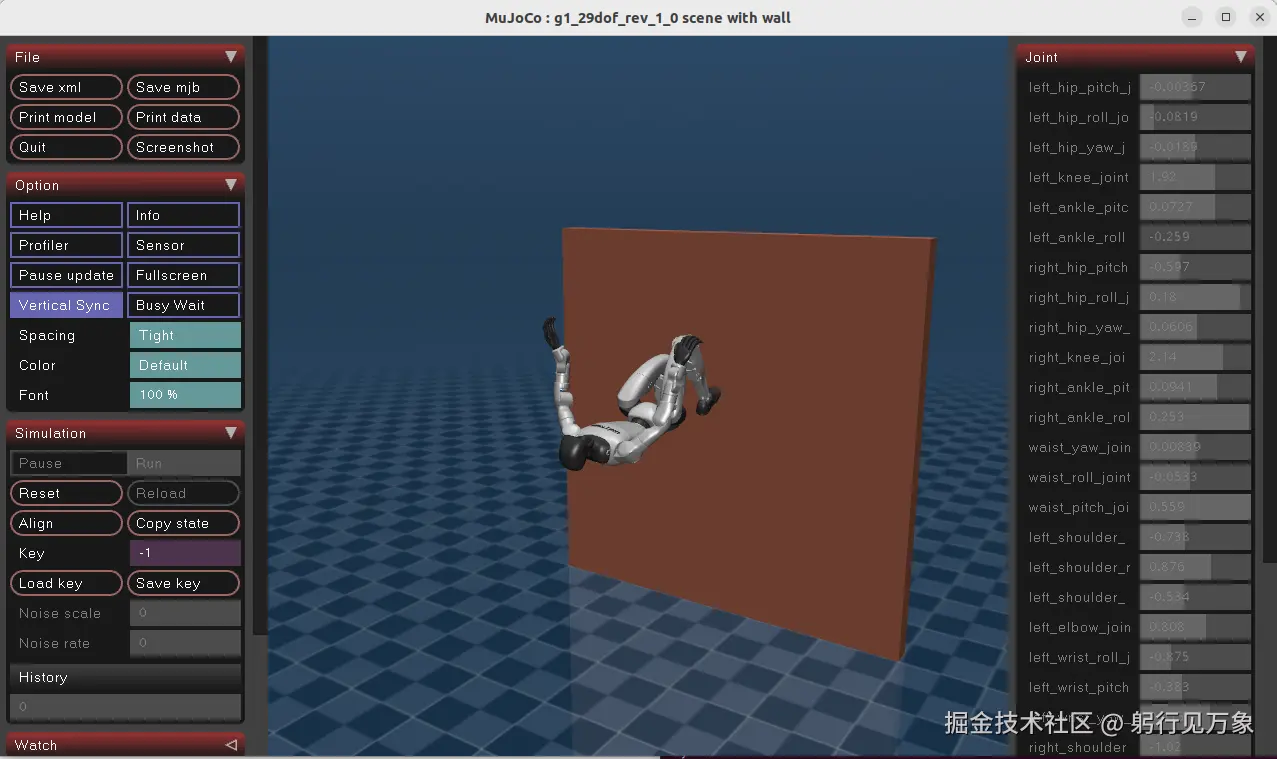
示例效果2: 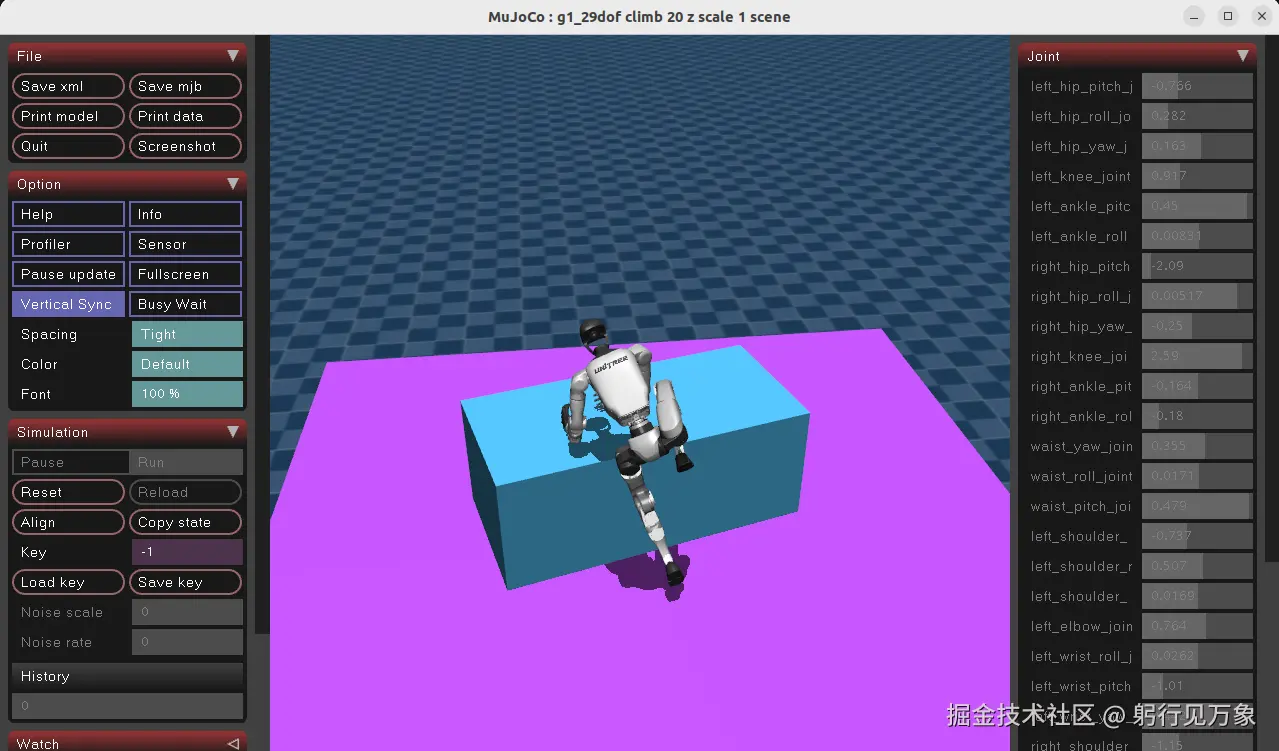
示例效果3: 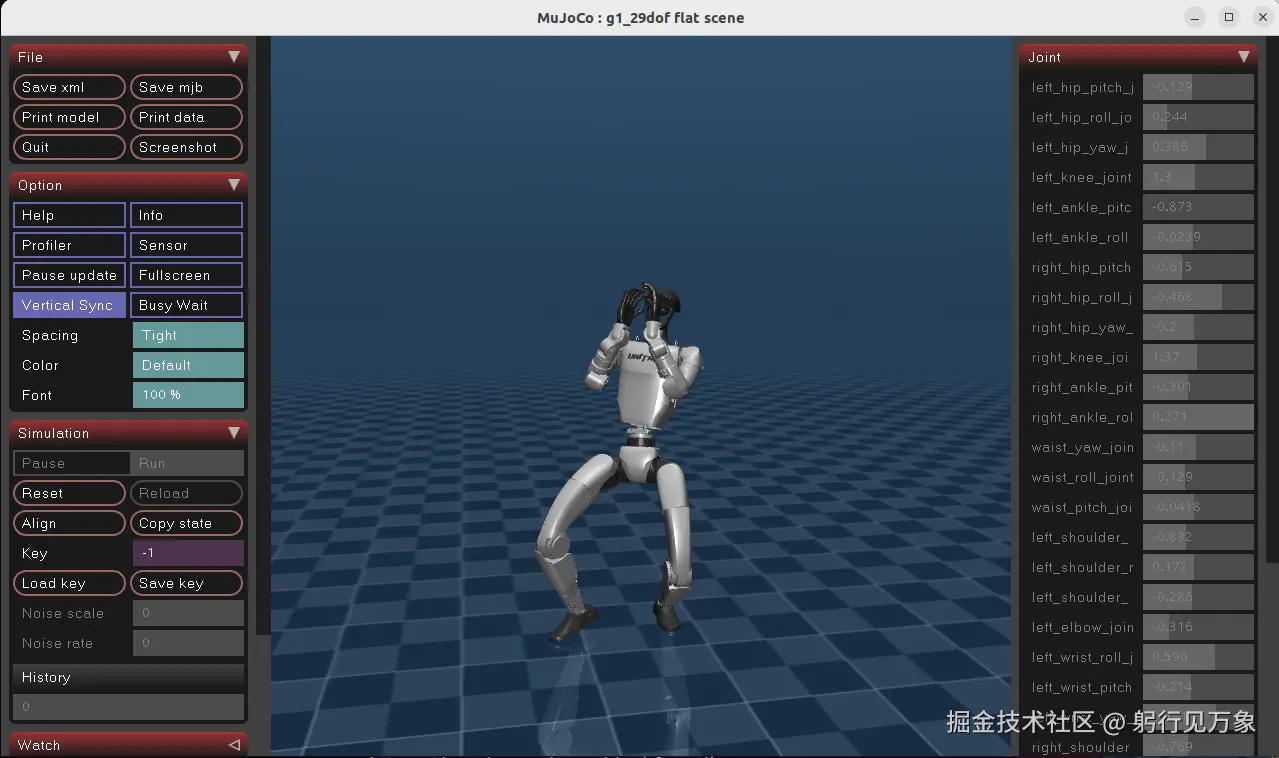
| CLI 任务名称 | 注册环境名称 | 默认动作 | 支持算法的配置文件 |
|---|---|---|---|
g1_motion_tracking |
G1MotionTracking |
dance1_subject2_part.npz |
conf/ppo/task/g1_motion_tracking/, conf/appo/task/g1_motion_tracking/ |
g1_flip_tracking |
G1FlipTracking |
flip_360_001__A304.npz |
conf/ppo/task/g1_flip_tracking/, conf/appo/task/g1_flip_tracking/ |
g1_wall_flip_tracking |
G1WallFlipTracking |
flip_from_wall_104__A304.npz |
conf/ppo/task/g1_wall_flip_tracking/, conf/appo/task/g1_wall_flip_tracking/ |
x2_wall_flip_tracking |
X2WallFlipTracking |
tictacflip_6-3_g1format.npz |
conf/ppo/task/x2_wall_flip_tracking/ (MuJoCo only) |
g1_climb_tracking |
G1 climb tracking env | clip from env config | conf/ppo/task/g1_climb_tracking/, conf/appo/task/g1_climb_tracking/ |
g1_box_tracking |
G1 box tracking env | clip from env config | conf/ppo/task/g1_box_tracking/ |
g1_wbt_obs |
G1MotionTrackingSAC |
shared with g1_motion_tracking |
conf/offpolicy/task/sac/g1_wbt_obs/mujoco.yaml |
1、G1机器人 攀升箱子 (跨越高遮挡障碍物)
方案1、使用PPO算法
模型训练
bash
uv run train --algo ppo --task g1_climb_tracking --sim mujoco运行记录:
bash
################################################################################
Learning iteration 19999/20000
Total steps: 491520000
Steps per second: 24262
Collection time: 0.934s
Learning time: 0.079s
Mean value loss: 0.0694
Mean surrogate loss: -0.0086
Mean entropy loss: 45.4856
Mean reward: 92.42
Mean episode length: 724.46
Mean action std: 1.24
reward/motion_global_root_pos: 0.4567
reward/motion_global_root_ori: 0.4555
reward/motion_body_pos: 1.9432
reward/motion_body_ori: 1.1646
reward/motion_body_lin_vel: 0.6290
reward/motion_body_ang_vel: 0.0812
reward/motion_ee_body_pos_z: 1.9754
reward/motion_joint_pos: 0.3240
reward/motion_joint_vel: 0.0001
reward/action_rate_l2: -0.5959
reward/joint_limit: -0.0173
reward/undesired_contacts: 0.0000
--------------------------------------------------------------------------------
Iteration time: 1.01s
Time elapsed: 07:03:13
ETA: 00:00:00模型推理、可视化
bash
uv run scripts/play_interactive.py \
--algo ppo \
--task g1_climb_tracking \
--sim mujoco \
algo.load_run=-1 \
interactive.action_mode=policyG1机器人 攀升箱子的效果: 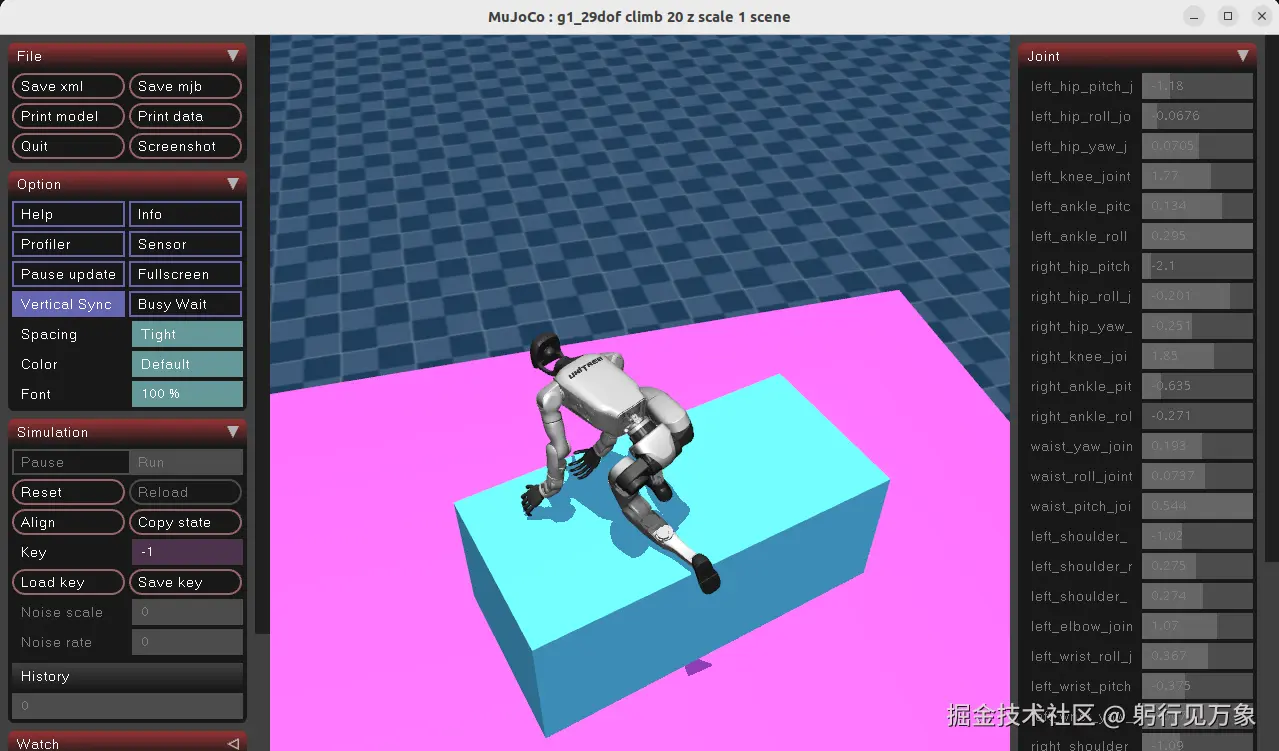
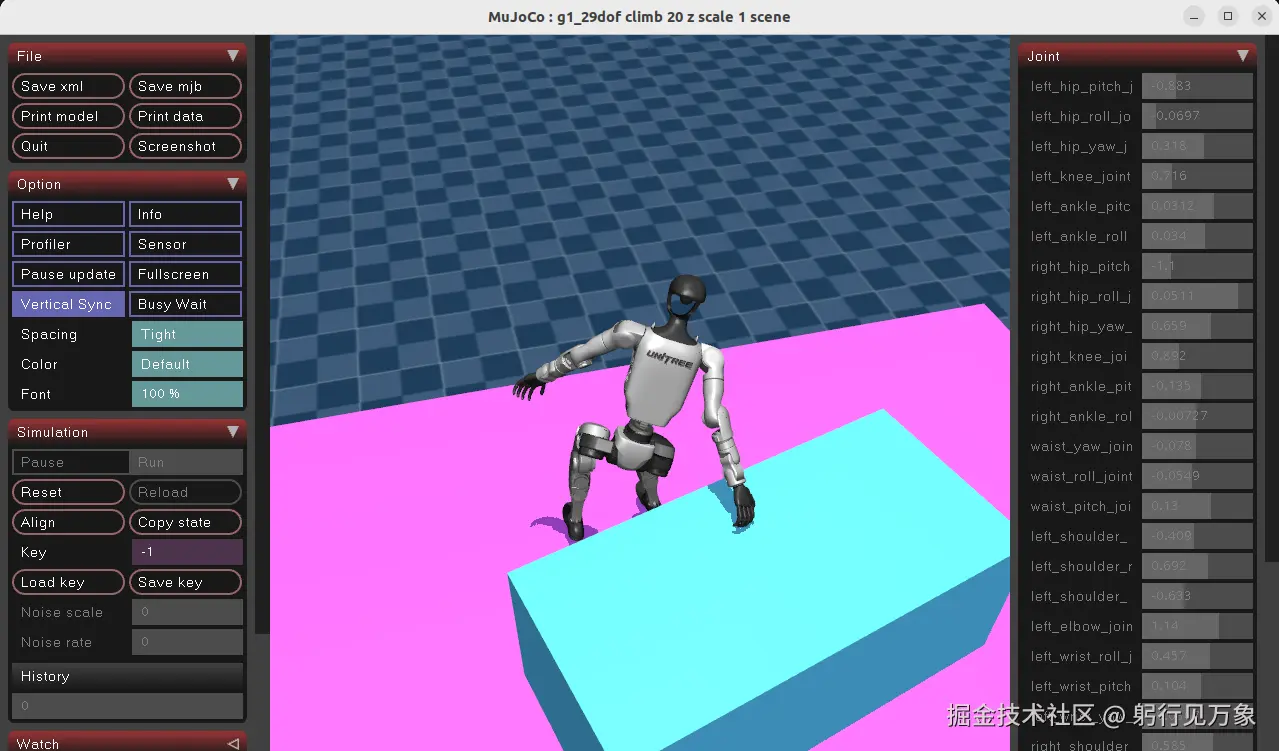
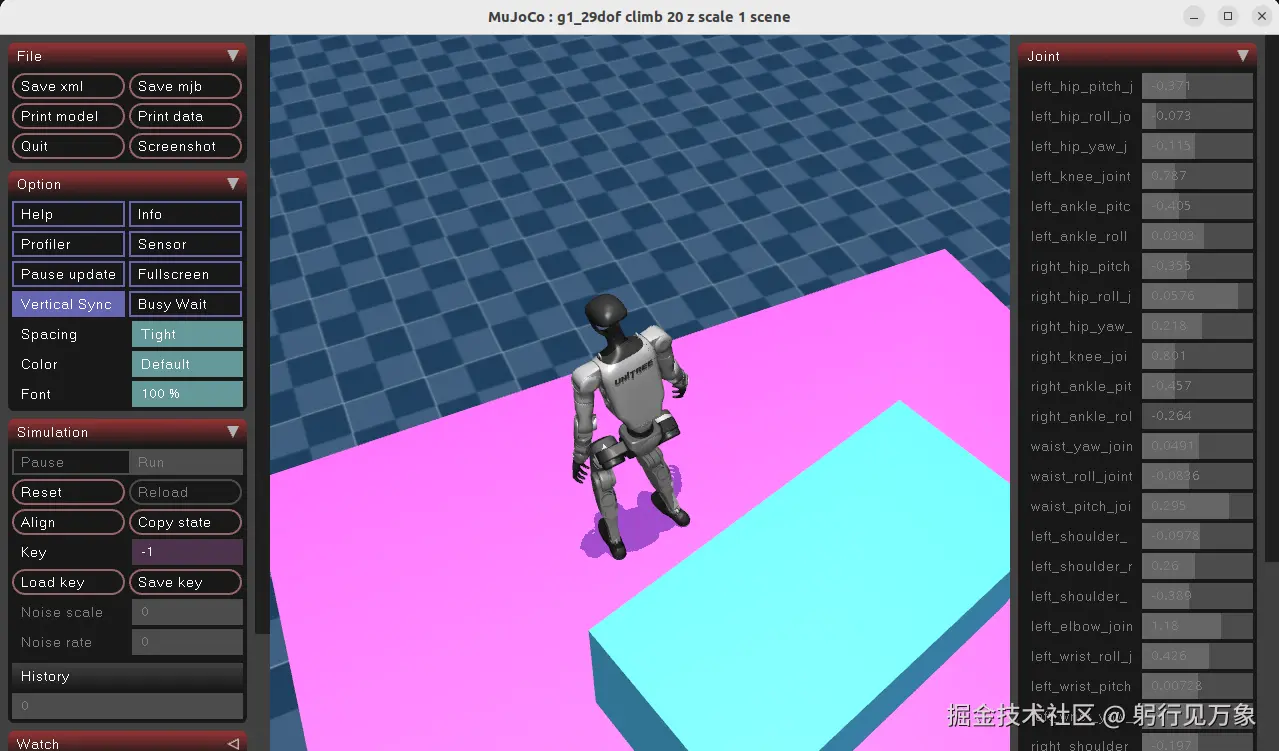
方案2、使用APPO算法
模型训练
bash
uv run train --algo appo --task g1_climb_tracking --sim mujoco运行记录:
bash
╭─────────────────────────────────────── 🚀 UniLab Off-Policy Training ───────────────────────────────────────╮
│ APPO | G1ClimbTracking | iter 20000/20000 | ⏱ 6h12m41s | ETA 0s | Ep Len 691.5 | Steps/s 103,650 | Training │
│ │
│ Losses & Metrics Value Rewards Value │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ Loss/Policy Loss -0.0076 Reward ━ Mean 79.831 / Peak 84.329 │
│ Loss/Value Loss 0.0314 action rate l2 -1.0784 │
│ Appo/Updates Executed 20.000 joint limit -0.0436 │
│ Available On Arrive 1.000 motion body ang +0.0155 │
│ Grad/Global Norm 4.765 vel │
│ Optim/Learning Rate 2.43e-05 motion body lin +0.4878 │
│ Policy/Entropy 55.887 vel │
│ Policy Kl/Behavior To Current Kl 0.0268 motion body ori +0.9366 │
│ Ppo/Approx Kl 0.0094 motion body pos +1.9112 │
│ Ppo/Clip Fraction 0.2410 motion ee body +1.9736 │
│ Rollouts Read 1.000 pos z │
│ Staging Pool Capacity 3.000 motion global +0.4243 │
│ Staging Pool Len 3.000 root ori │
│ Vtrace/Rho Clip Fraction 0.4617 motion global +0.4448 │
│ Vtrace/Rho Raw P99 1.683 root pos │
│ motion joint +0.1988 │
│ pos │
│ motion joint +0.0000 │
│ vel │
│ undesired +0.0000 │
│ contacts │
│ │
│ Learner Value Collector Value System Value │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ Wait 844.9ms env_step_total_ms 41.9ms Buffer 0 │
│ H2D 26.2ms mlp_infer_ms 1.3ms Timeout Rate 92.9% │
│ Train 210.1ms Terminated Rate 7.1% │
│ Weight Sync 0.8ms Envs 1,024 │
│ Sync Collect ✓ (24576) │
│ Staging Pool 3/3 │
╰───────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭────────────────────────────────────────────── Training Summary ───────────────────────────────────────────────╮
│ Training complete │
│ Algo: APPO | Env: G1ClimbTracking │
│ Iterations: 20000/20000 │
│ Total time: 6h12m41s │
│ Total env steps: 491,520,000 模型推理、可视化
bash
uv run scripts/play_interactive.py \
--algo appo \
--task g1_climb_tracking \
--sim mujoco \
algo.load_run=-1 \
interactive.action_mode=policyG1机器人 攀升箱子的效果: 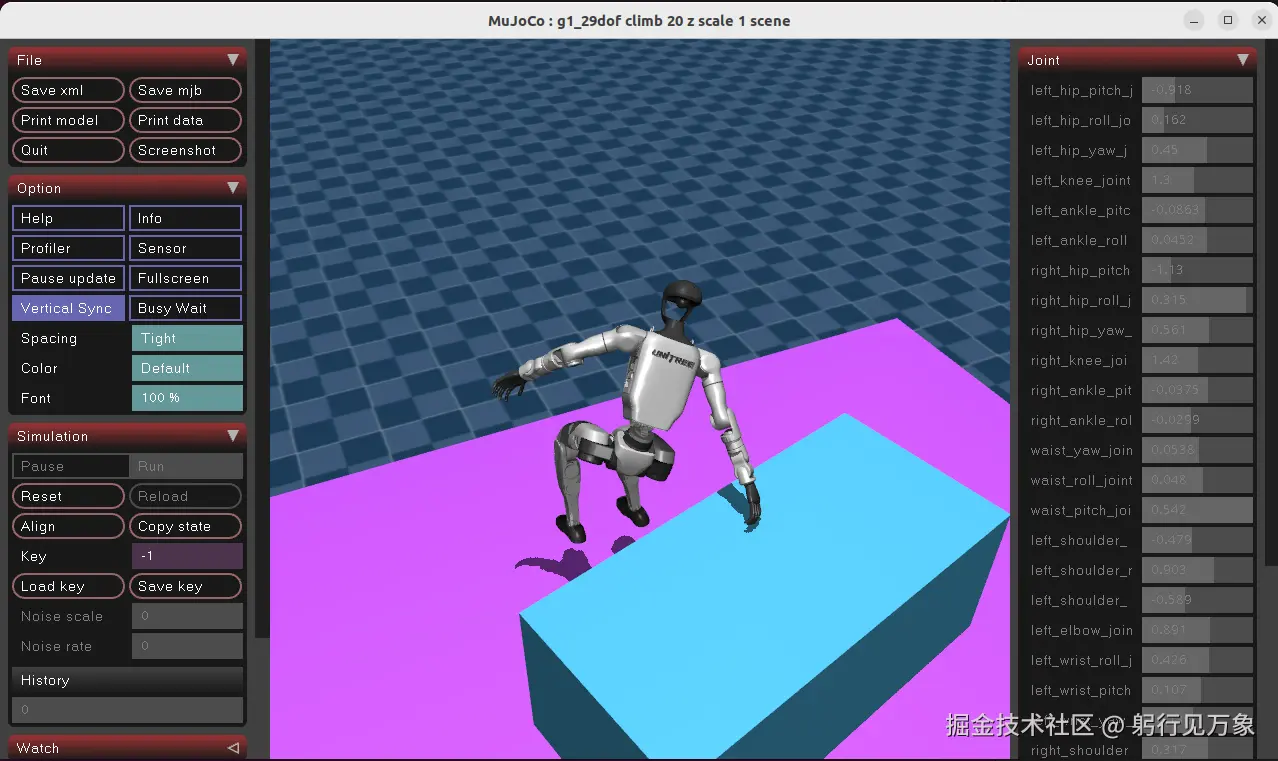
2、G1机器人 搬运箱子
模型训练
bash
uv run train --algo ppo --task g1_box_tracking --sim mujoco运行记录:
bash
################################################################################
Learning iteration 29999/30000
Total steps: 737280000
Steps per second: 35430
Collection time: 0.638s
Learning time: 0.056s
Mean value loss: 0.4026
Mean surrogate loss: -0.0153
Mean entropy loss: 29.2703
Mean reward: 31.05
Mean episode length: 330.47
Mean action std: 0.67
reward/motion_global_root_pos: 0.3922
reward/motion_global_root_ori: 0.4297
reward/motion_body_pos: 0.9134
reward/motion_body_ori: 0.5521
reward/motion_body_lin_vel: 0.8563
reward/motion_body_ang_vel: 0.5513
reward/action_rate_l2: -2.3668
reward/joint_limit: -0.0105
reward/undesired_contacts: 0.0000
reward/object_global_ref_position_error_exp: 1.5199
reward/object_global_ref_orientation_error_exp: 1.7236
--------------------------------------------------------------------------------
Iteration time: 0.69s
Time elapsed: 09:13:21
ETA: 00:00:00模型推理、可视化
bash
uv run scripts/play_interactive.py \
--algo ppo \
--task g1_box_tracking \
--sim mujoco \
algo.load_run=-1 \
interactive.action_mode=policyG1机器人 搬运箱子的效果: 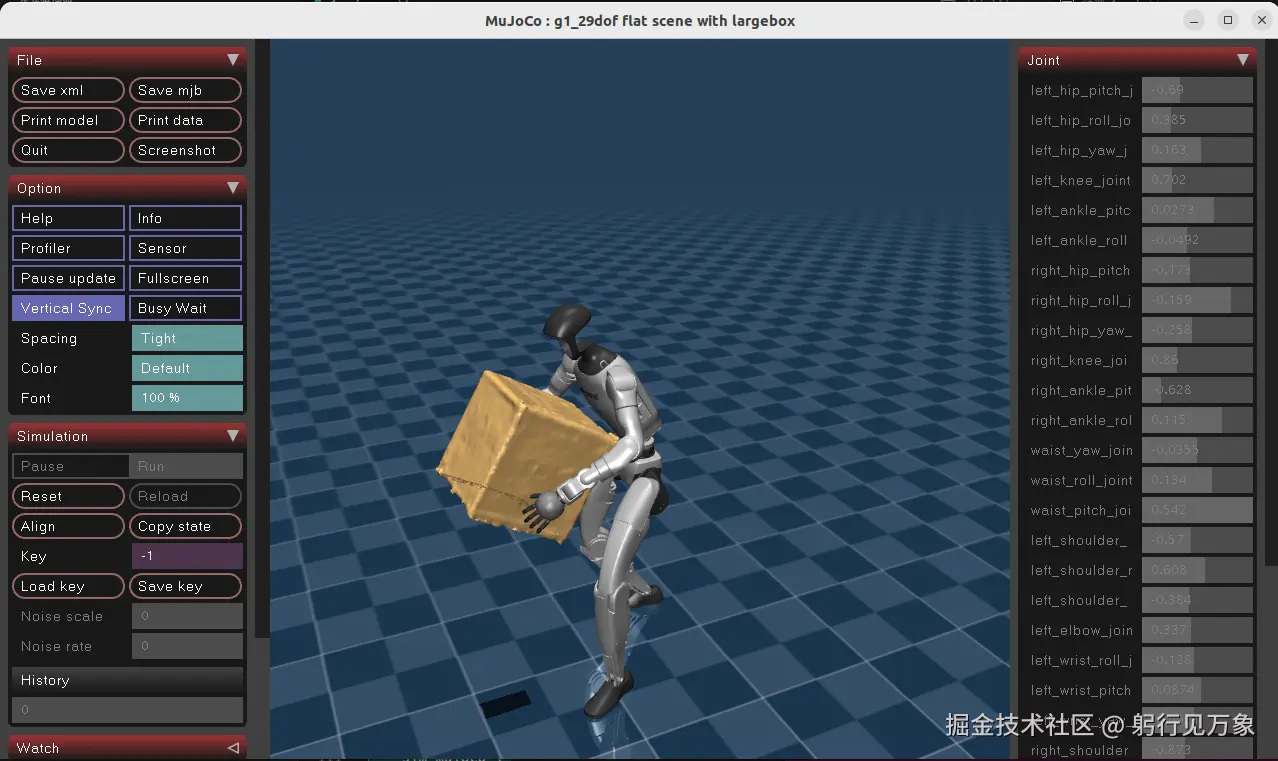
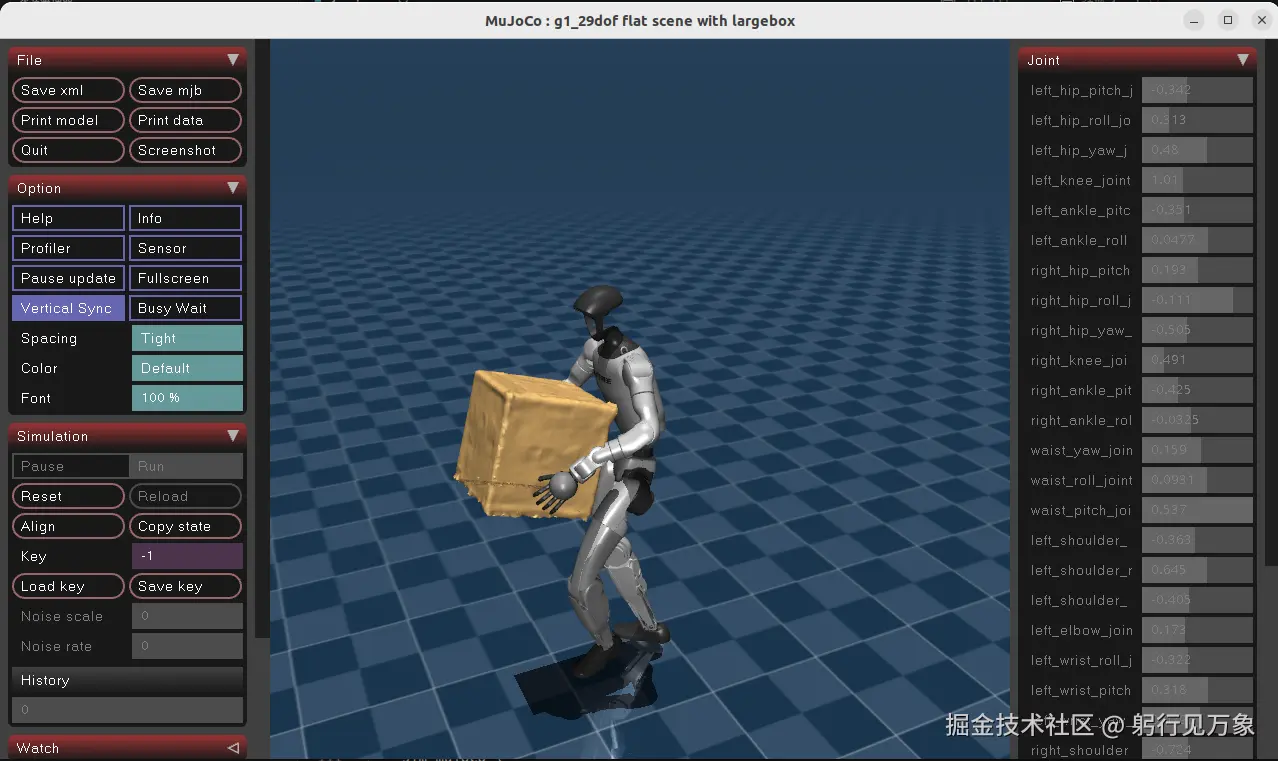
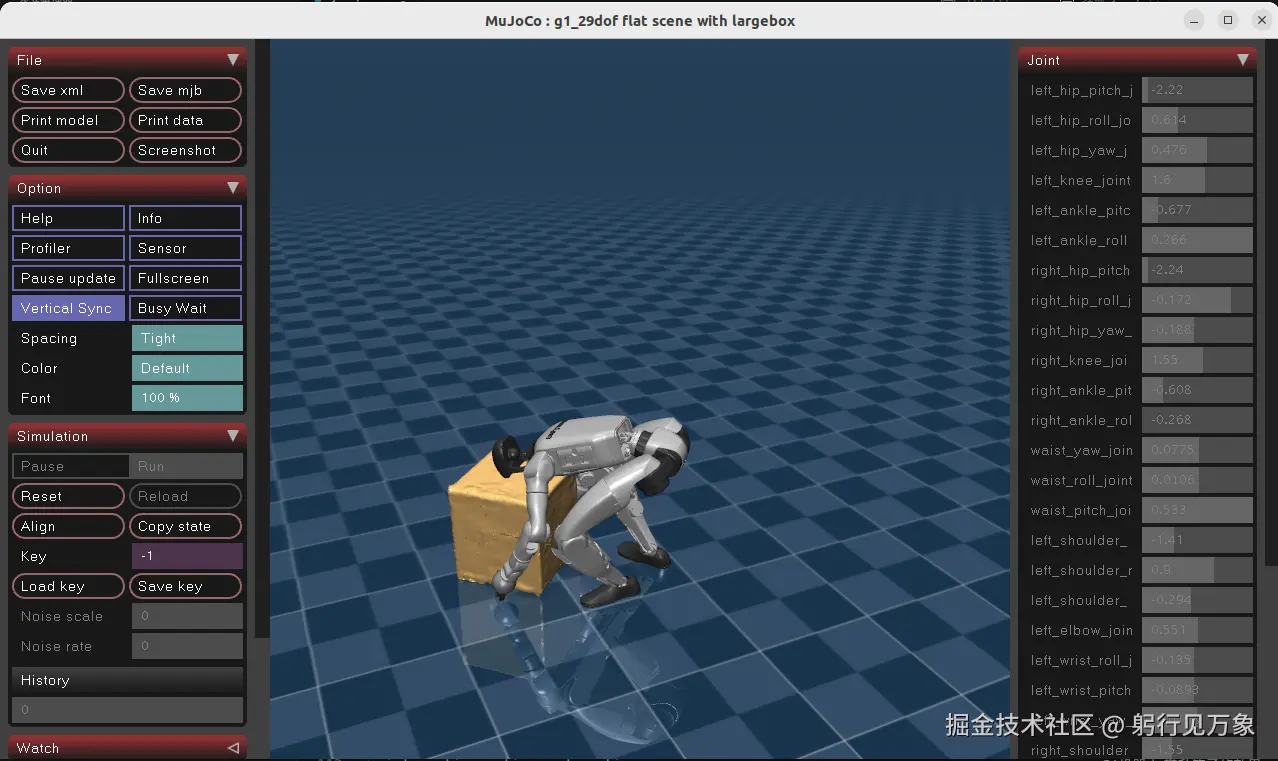
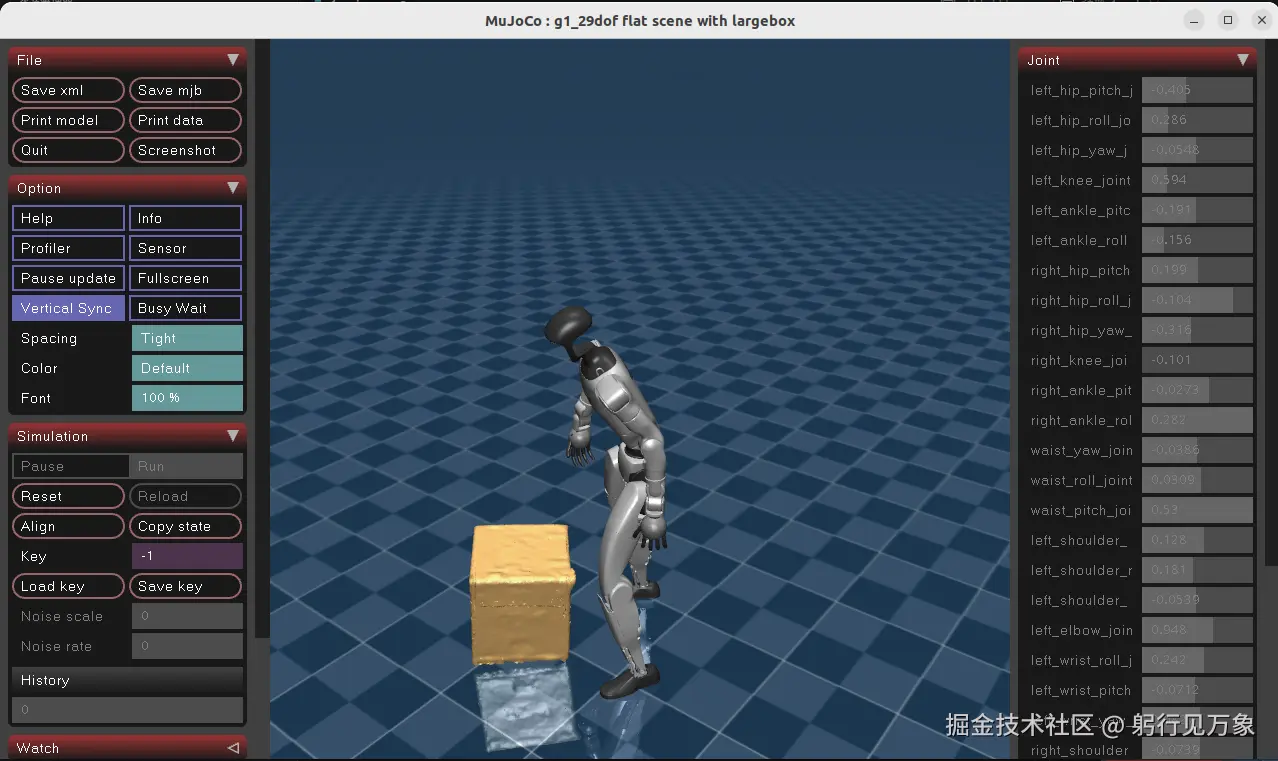
3、G1机器人 全身跟踪
模型训练
bash
uv run train --algo sac --task g1_wbt_obs --sim mujoco training.use_amp=true运行记录:
bash
这里会训练14万轮,大约需要9个小时左右
.......模型推理、可视化
bash
uv run scripts/play_interactive.py \
--algo sac \
--task g1_wbt_obs \
--sim mujoco \
algo.load_run=-1 \
interactive.action_mode=policyG1机器人 全身跟踪 跳舞的效果: 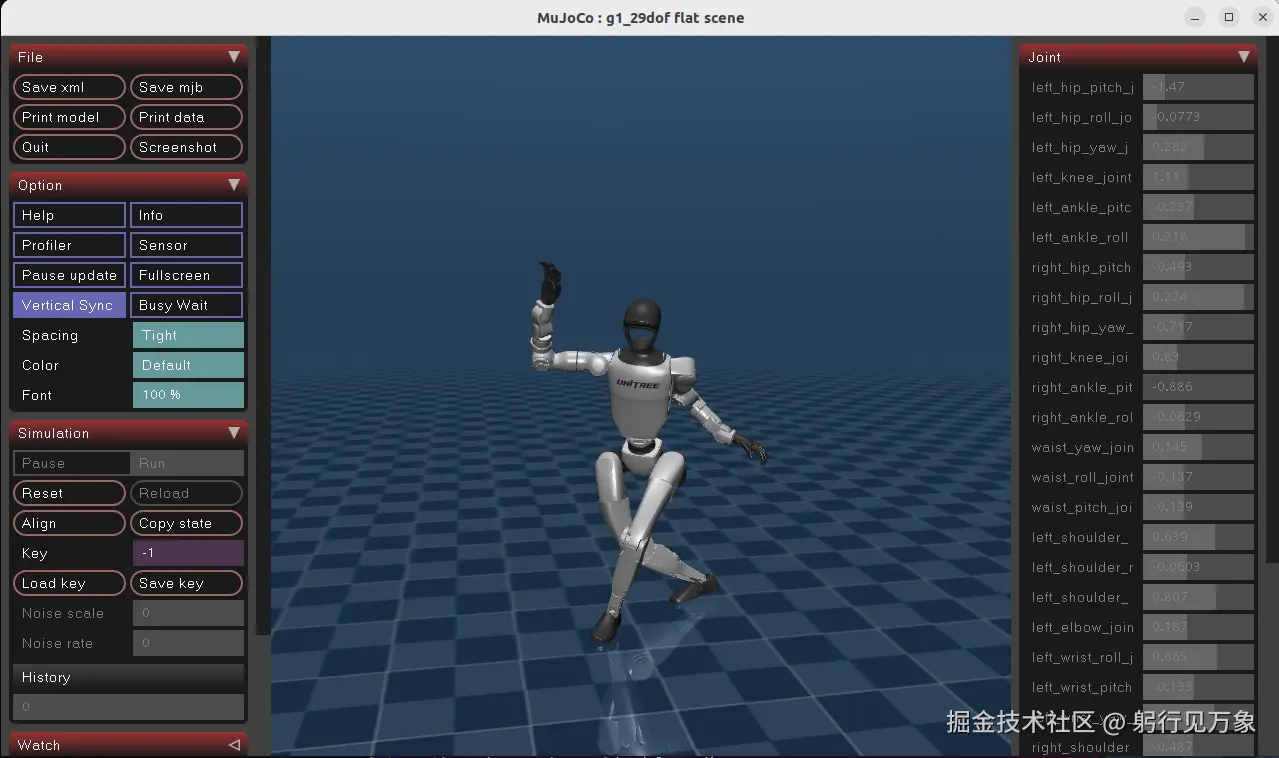
4、G1机器人 攀爬斜坡
模型训练
bash
CUDA_VISIBLE_DEVICES=1 uv run train --algo sac --task g1_motion_tracking --sim mujoco \
training.use_amp=true algo.seed=1 \
+env.motion_file=src/unilab/assets/motions/g1/climb_20_z_scale_1.0.npz \
+env.scene.model_file=src/unilab/assets/robots/g1/scene_crawl_slope.xml \
+env.sampling_mode=start \
env.truncate_on_clip_end=true \
+env.max_episode_seconds=20.0 \
'+env.pose_randomization={x:[0,0],y:[0,0],z:[0,0],roll:[0,0],pitch:[0,0],yaw:[0,0]}' \
'+env.velocity_randomization={x:[0,0],y:[0,0],z:[0,0],roll:[0,0],pitch:[0,0],yaw:[0,0]}' \
'+env.joint_position_range=[0,0]'运行记录:
bash
这里会训练2.5万轮,大约需要11个小时左右
╭─────────────────────────────────── 🚀 UniLab Off-Policy Training ───────────────────────────────────╮
│ FastSAC | G1MotionTrackingSAC | iter 25000/25000 | ⏱ 11h02m04s | ETA 0s | Ep Len 410.6 | Steps/s 1,... │
│ │
│ Losses & Metrics Value Rewards Value │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ Actor Loss -4.446 Reward ━ Mean 24.729 / Peak 25.726 │
│ Alpha Loss -5.90e-04 action rate -0.2899 │
│ Qf Loss 5.099 l2 │
│ Action Std 0.3334 joint limit -0.0272 │
│ Actor Grad Norm 0.0337 motion body +0.3151 │
│ Alpha 8.96e-04 ang vel │
│ Critic Grad Norm 0.1059 motion body +0.6645 │
│ Policy Entropy -15.257 lin vel │
│ Target Q Max 6.364 motion body +0.0027 │
│ Target Q Min -0.6225 ori │
│ motion body +1.3401 │
│ pos │
│ motion global +0.3006 │
│ root ori │
│ motion global +0.8061 │
│ root pos │
│ undesired +0.0000 │
│ contacts │
│ │
│ Learner Value Collector Value System Value │
│ ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ │
│ Wait 0.1ms Weight Sync 13.5ms Buffer 1,048,576 │
│ H2D 8.4ms Action Select 144.1ms Timeout Rate 0.0% │
│ Train 1368.6ms Env Step 41.6ms Terminated Rate 100.0% │
│ Weight Sync 0.2ms Replay 42.5ms Envs 2,048 │
│ Sync Coordination 1328.7ms Sync Collect ✓ (1) │
╰───────────────────────────────────────────────────────────────────────────────────────────────────────╯
.......模型推理、可视化
bash
uv run scripts/play_interactive.py \
--algo sac \
--task g1_motion_tracking \
--sim mujoco \
algo.load_run=-1 \
interactive.action_mode=policyG1机器人 攀爬斜坡效果比较差,还得改进训练参数或者算法。
5、G1机器人 空翻
模型训练
bash
uv run train --algo ppo --task g1_wall_flip_tracking --sim mujoco运行记录: 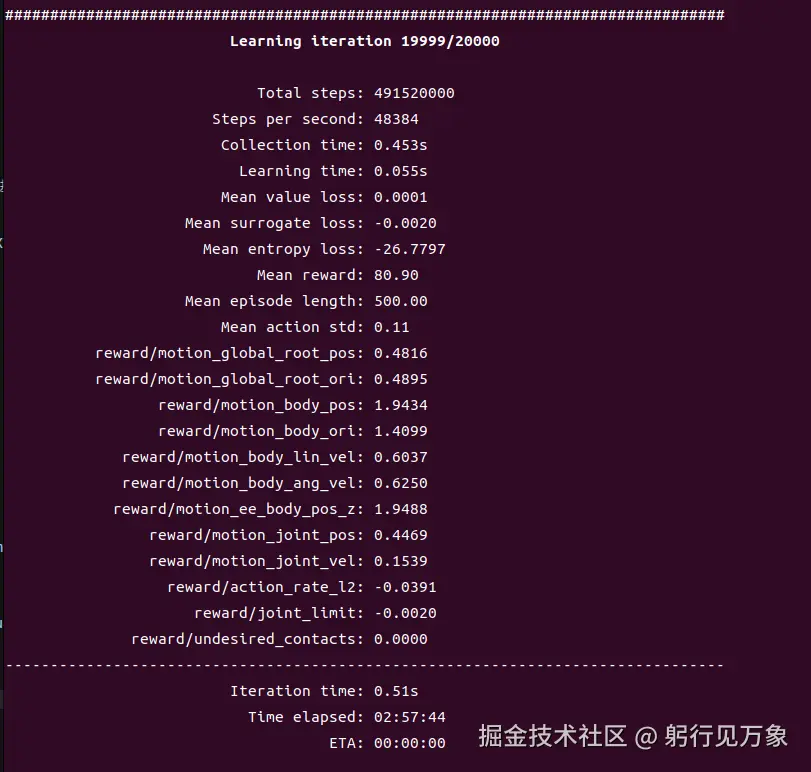
模型推理、可视化
bash
uv run scripts/play_interactive.py \
--algo ppo \
--task g1_wall_flip_tracking \
--sim motrix \
algo.load_run=-1 \
interactive.action_mode=policyG1机器人空翻效果: 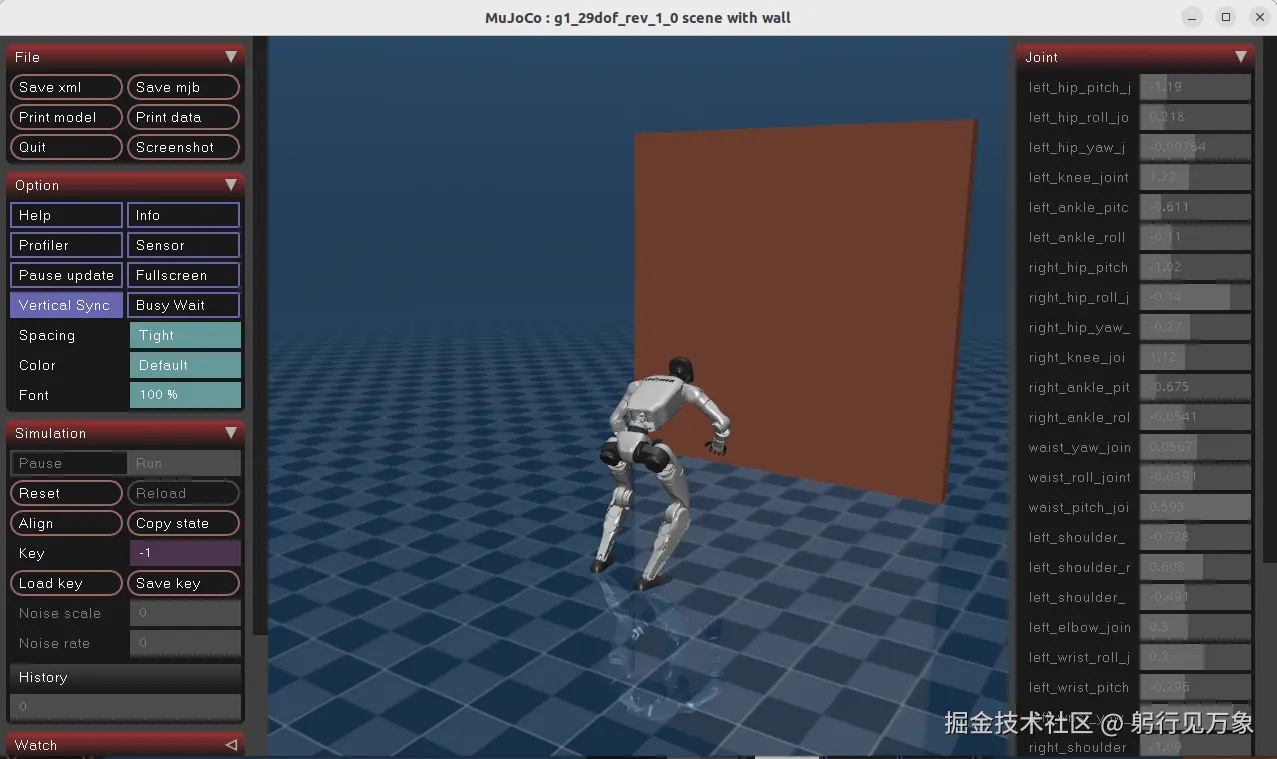
整体效果比较丝滑~
分享完成~