从数学原理到生产部署,一次讲透投机解码的核心思想与最佳实践。
你有没有想过,为什么 ChatGPT 生成回复时是一个字一个字蹦出来的?明明 GPU 有几千个核心,为什么不能并行输出?
答案藏在自回归解码的机制里。想象一条高速公路,所有车辆必须通过同一个收费站,一次只能放行一辆。大语言模型的推理就像这条公路:每个 token 的生成必须等前一个完全结束,GPU 算力再强也只能排队等待。
随着模型规模膨胀到数千亿参数,这个串行瓶颈已经从"有点烦人"变成"难以忍受"。DeepSeek-V4 的线上服务曾经受此拖累,直到一套新机制的引入彻底改变了局面。
这套机制叫 DSpark。在同样的服务等级协议(SLA)下,它将引擎吞吐量提升了 51%,每位用户的实际响应速度加快了 60% 到 85%。在高交互场景下,吞吐量甚至可以提升 661%。
它的核心是投机解码(Speculative Decoding)。本文将从直觉到公式,逐步拆解这项技术,并解释 DSpark 为什么选择了第三条路。
一、投机解码的数学本质
1.1 大模型推理为什么慢
大模型推理的本质是串行自回归(Autoregressive Generation)。给定前 k 个 token,模型计算第 k+1 个 token 的概率分布,采样后再作为下一步的输入。
这个过程无法并行,因为第 k+1 个 token 的输入依赖于第 k 个 token 的输出。模型参数量越大(如 DeepSeek-V4),单次前向计算的延迟越高,串行瓶颈就越严重。
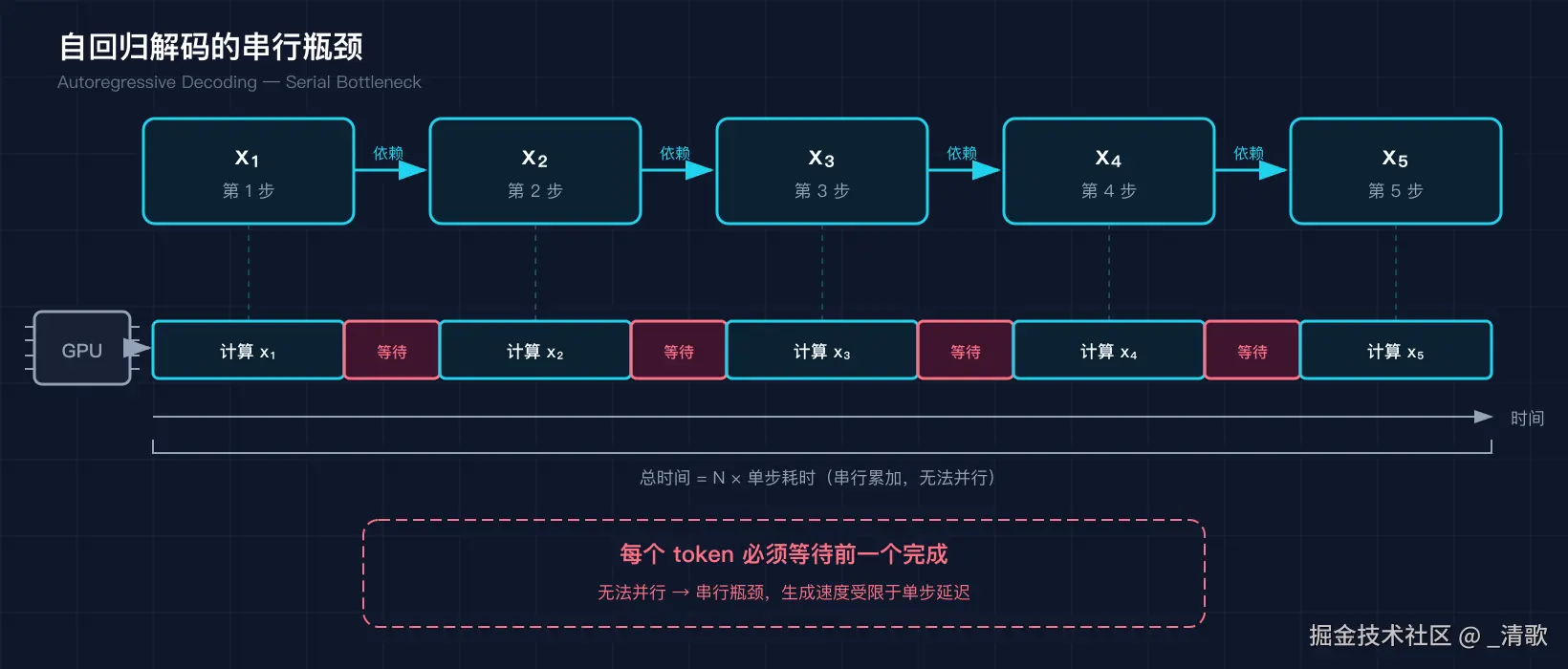
(图注:每个 token 必须等待前一个完成,形成串行依赖链,GPU 利用率受限。)
1.2 投机解码的核心直觉
投机解码的核心思想可以用一个职场类比概括:让实习生(Draft Model)快速写出草稿,老板(Target Model)只做批量审核和签字。
具体来说,一个轻量级的小模型先一次性猜测接下来的若干个 token。然后大模型将候选 token 打包验证,用拒绝采样(Rejection Sampling)保证输出分布与直接自回归完全一致。
只要小模型猜得够准,大模型就能一次性"批准"多个 token,原本串行的多步压缩成一步。更重要的是,这种加速是数学上无损的,输出质量不会下降。
1.3 加速比公式与两个维度
加速比由以下公式严格定义:
\eta = \frac{T_{\text{target}}}{(T_{\text{draft}} + T_{\text{verify}}) / \tau
其中各符号含义如下:
| 符号 | 含义 |
|---|---|
| \et | 加速比 |
| T_{\text{target} | target model 自回归单 token 延迟 |
| T_{\text{draft} | draft model 生成候选的延迟 |
| T_{\text{verify} | target model 验证候选的延迟 |
| \ta | 期望接受的 token 数(含 bonus token) |
从公式可以清晰看出,加速比取决于两个独立维度。第一是算法层面的接受率, \ta 越大越好;第二是系统层面的延迟比,T_{\text{draft} 与 T_{\text{verify} 的比值越小越好。
不同 draft 策略在这两个维度上的表现截然不同。因此选择什么样的 draft 生成方式,直接决定了投机解码方案的理论天花板和实际落地效果。
二、Draft 策略的三种范式
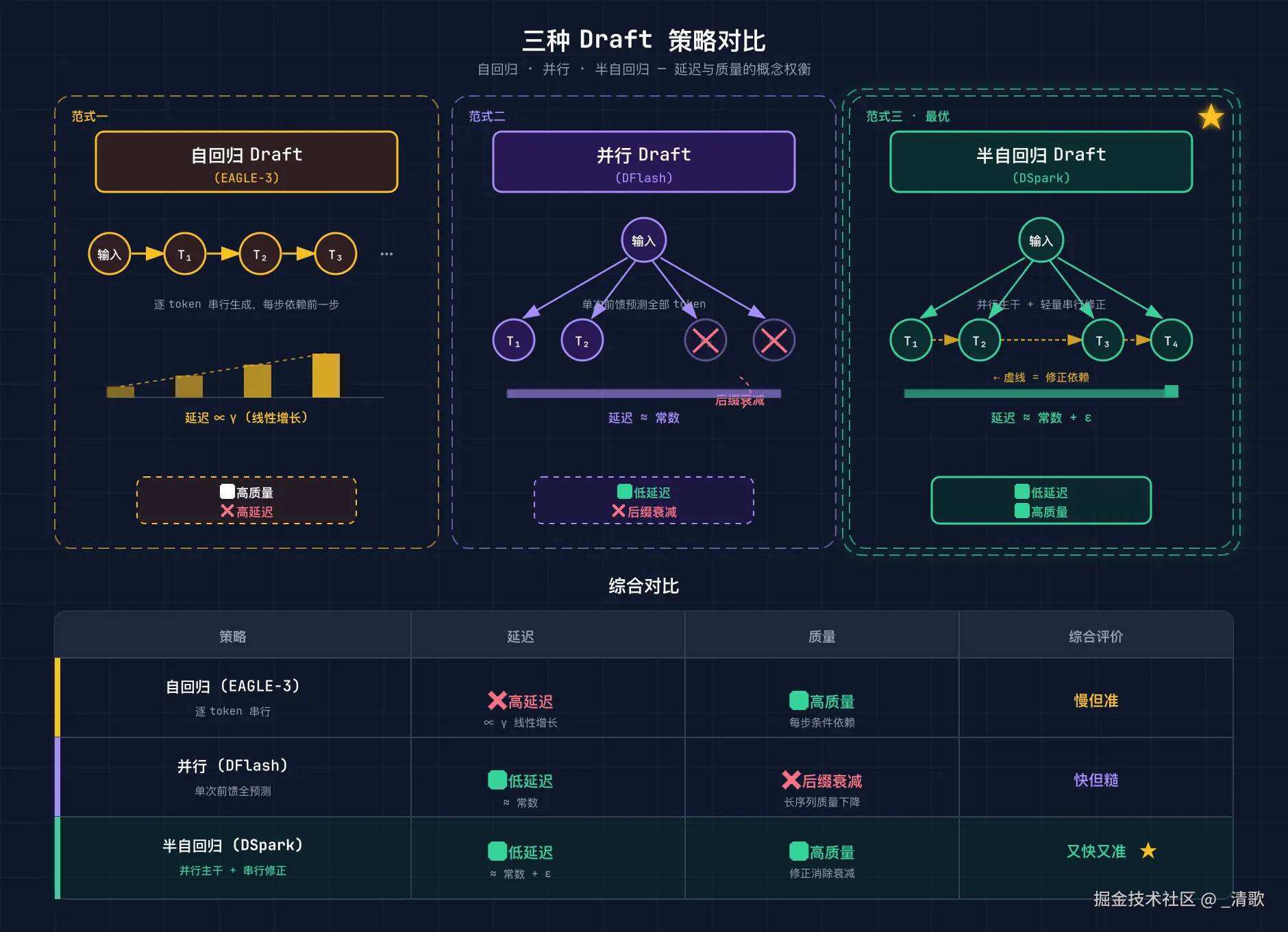
目前学术界和工业界的 draft 策略可以归纳为三大范式。它们在延迟和接受率之间做着不同的权衡,没有一种能在所有场景下通吃。
理解这三种范式的差异,是理解 DSpark 设计选择的前提。
2.1 自回归 Draft:以 EAGLE-3 为代表
自回归 draft(Autoregressive Draft)沿用与 target model 相同的生成方式:逐个 token 顺序预测。EAGLE-3 是该路线的代表方法。
它的延迟随 draft 长度线性增长,公式为 T_{\text{draft}} = \gamma \times t_{\text{step}。为了控制总延迟,自回归 draft 通常只能使用极浅的网络(EAGLE-3 往往只有 1 层)。
因为每一层 draft 网络都必须等待前一层的输出,计算图是严格串行的。这是自回归范式的结构性代价。
这种策略的优点是保持了 token 间的自然依赖,接受率较高。缺点是 draft 长度和模型深度都被延迟严格限制,难以扩展到更长的候选序列。
2.2 并行 Draft:以 DFlash 为代表
并行 draft(Parallel Draft)采用完全不同的思路:用单次前向传播同时预测整个 block 内的所有 token。DFlash 是该范式的典型代表。
它的最大优势是延迟近似常数,T_{\text{draft}} \approx t_{\text{parallel},与 block 长度基本无关。这使得 draft 模型可以做得更深、预测得更远,而不必担心延迟线性膨胀。
但纯并行预测存在一个致命缺陷------后缀衰减(Suffix Decay)。越靠后的位置,预测质量越差,因为每个位置的预测条件独立,没有利用到已经生成的左侧 token 信息。
当 block 长度增加到 5 个以上时,DFlash 的远端 token 接受率会急剧下滑,这直接限制了它能带来的实际加速。
(图注:三种策略在延迟-接受率平面上的分布示意。)
2.3 半自回归 Draft:DSpark 的答案
DSpark 的答案是半自回归(Semi-Autoregressive)draft。它在并行 backbone 的基础上,叠加极低开销的顺序校正,试图兼得低延迟与高接受率。
具体而言,DSpark 先用一个 5 层的小型 Transformer 并行预测整个 block,再通过轻量的 Markov 顺序校正头在相邻 token 之间引入依赖。总延迟仍近似常数,仅增加一个极小的 \epsilo。
实验表明,DSpark 在延迟与接受率的二维平面上处于帕累托前沿(Pareto Frontier)。它既享有并行 draft 的低延迟,又接近自回归 draft 的高接受率,从而在生产环境中取得了显著优势。
这种"先并行、后校正"的混合思路,正是 DSpark 区别于现有方案的核心创新。下一部分将深入其架构细节。
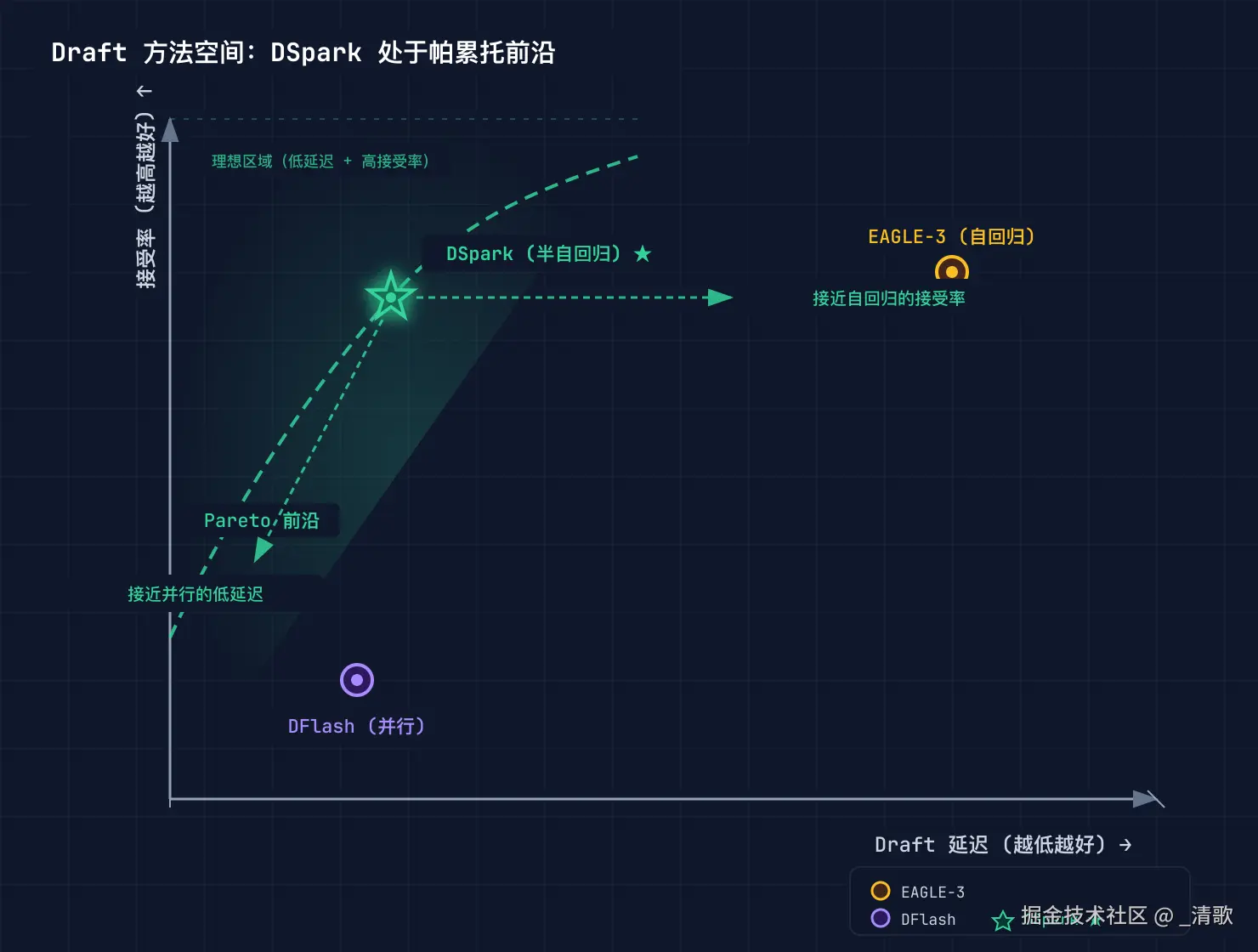
(图注:DSpark 位于帕累托前沿,打破了"低延迟 vs 高接受率"的权衡困境。)
三、DSpark 架构深度解析
3.1 架构总览
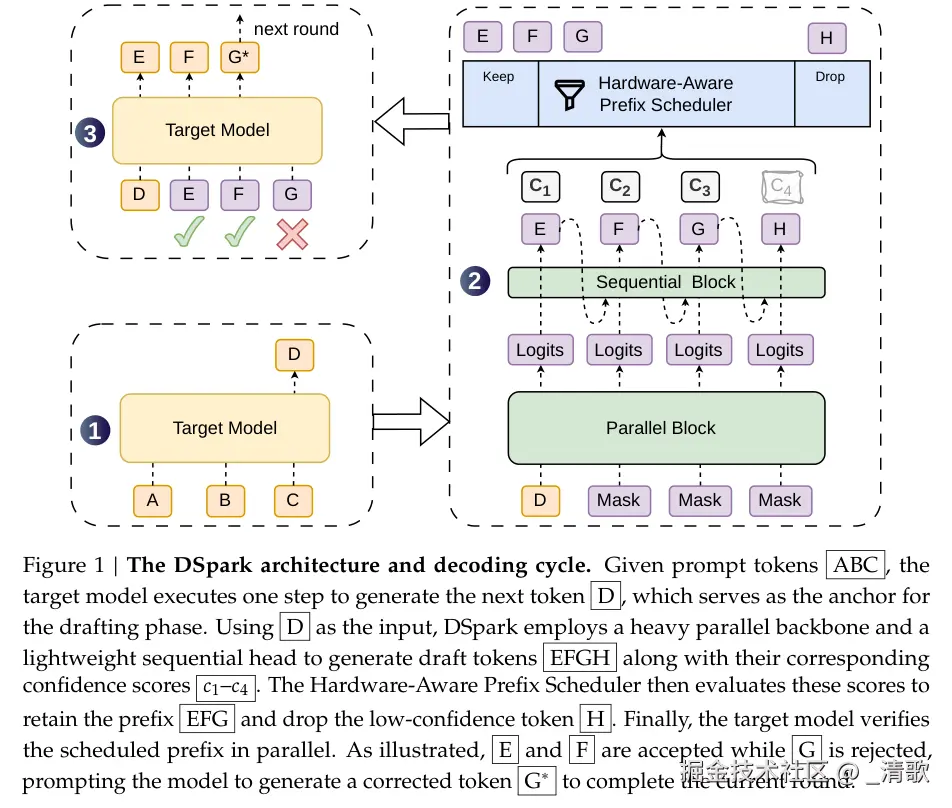
DSpark 的 draft 模型由三个组件精密协作而成。
第一个是 Parallel Backbone,负责一次性并行预测整个 token block 的独立分布。
第二个是 Markov 顺序校正头,在并行预测结果上叠加 token 间依赖,实现半自回归效果。
第三个是信心头,预估每个 draft token 被目标模型接受的概率,为调度器提供决策依据。
三者协同的核心公式可概括为:
\text{Draft}(x_k | x_
Backbone 提供上下文相关的先验分布,Markov 头注入序列依赖的修正量,信心头则量化预测可信度。
这条公式揭示了 DSpark 的半自回归本质:backbone 负责"并行猜",Markov 头负责"顺序修",两者叠加后既保留了并行速度,又获得了接近自回归的质量。
3.2 并行 Backbone
并行 Backbone 的核心任务是用一次前向传播预测整个 block。
为了告诉模型"这些位置有待预测",DSpark 借用了 Qwen3 预训练中的 Fill-in-the-Middle 特殊 token <|fim_middle|>(token_id=151669)。
它的 embedding 天然编码了"此处内容未知,需要推断"的语义,比普通 mask 更具表达力。
这里有一个关键直觉:普通的 mask token 在预训练中很少出现,模型看到它时未必知道该做什么。而 FIM token 在 Qwen3 的代码补全场景中被大量使用,其向量空间中已经形成了稳定的"待填充"语义。
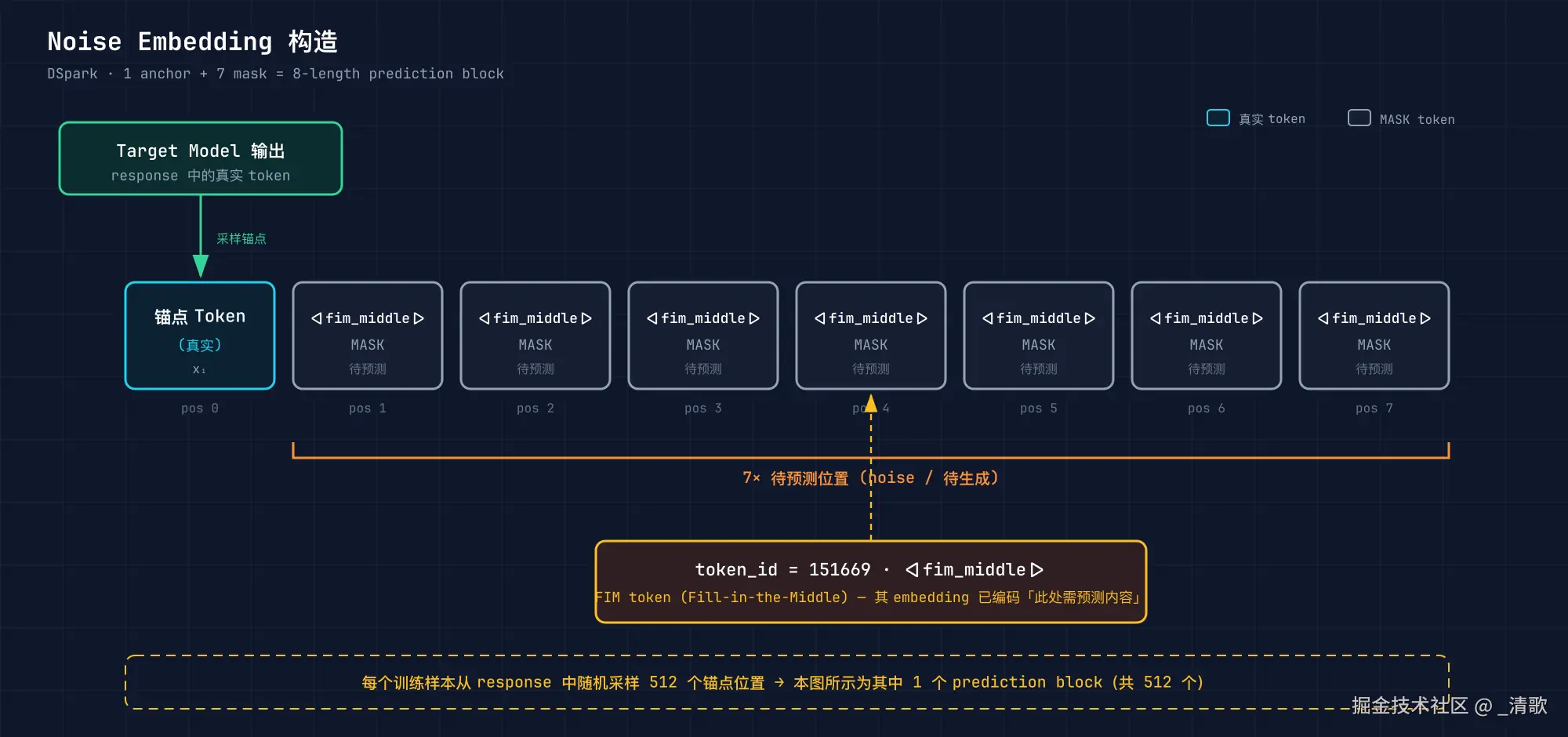
具体构造方式非常简洁:选取一个真实锚点 token,后面紧跟 7 个 <|fim_middle|> mask token,组成 8 长度的预测窗口。
训练时,每份样本从 response 部分随机采样 512 个锚点位置,相当于做了大规模数据增强。
锚点的选择不是均匀的,而是限定在 response 区域内,确保 draft 模型学习的是真实生成分布,而非前缀提示的分布。
Backbone 本身是一个 5 层的小型 Transformer,参数量远小于目标模型。
这 5 层网络是可训练参数的主体,其余部分如 embedding 和 lm_head 均从目标模型拷贝并冻结。
它的 attention 设计尤为关键:Q 只来自 draft token 自身,K/V 则拼接了目标模型的上下文 hidden states 与 draft block 内部的 hidden states。
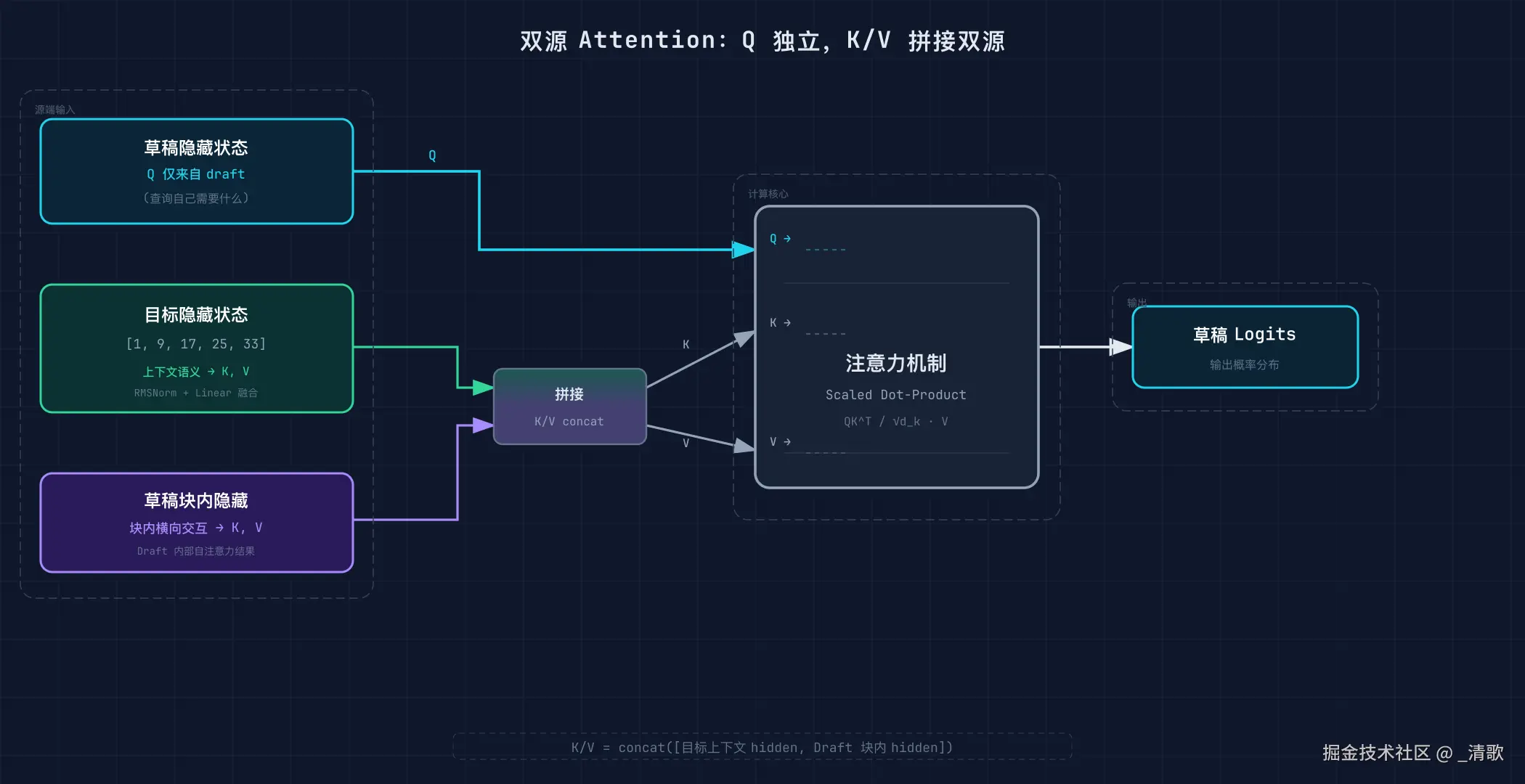
双源 attention 的巧妙之处在于分工明确:draft token 通过 Q 查询自己需要什么信息,而通过 K/V 从两个信息源中获取答案。
一个源是目标模型深层抽取的上下文语义,另一个源是 draft block 内部的横向交互。两者拼接后供给 attention 计算。
这种设计让 draft 模型无需重新编码长上下文,直接复用目标模型已计算好的深层特征。
目标 hidden 从 Qwen3 的第 1, 9, 17, 25, 33 层提取,融合后通过 RMSNorm 和线性投影注入 attention 的 K/V 路径。
既省计算又保精度,这是 DSpark 能在生产环境立足的工程基础。
5 层的深度是经过消融实验验证的:再深一层带来的质量增益有限,但延迟显著上升;再浅一层则无法充分提取 block 内的复杂模式。
3.3 Markov 顺序校正头
并行预测有一个根本缺陷:block 内每个位置的输出彼此条件独立。
数学上,backbone 给出的是 P(xk∣context,每个 $$$$ 互不影响。
这导致越靠后的 token 预测质量越差,也就是上文提到的后缀衰减问题。
实验数据显示,纯并行方案在位置 5 到 7 的接受率会急剧下跌,因为模型完全不知道前面已经生成了什么。
真实文本中,相邻 token 之间存在强依赖。DSpark 的核心假设是:x_ 的分布主要由前一个 token x_{k-1 决定。
这一假设被称为 Markov 性质,它让极轻量的顺序校正成为可能。
校正操作非常直接:在 backbone 输出的独立 logits 上,叠加一个基于前序 token 的偏差项。
logitscorrectedk=logitsbackbonek+bias(xk−1
论文探索了三种 Markov 头的实现变体:
| 类型 | 公式 | 参数量 | 特点 |
|---|---|---|---|
| VanillaMarkov | W2(W1(xk−1) | \appro 78M | 低秩分解,仅看前一个 token |
| GatedMarkovHead | W2(σ(gate)⊙W1(xk−1) | + d× | 用 backbone hidden 做门控调制 |
| RNNHead | GRU(state, W_1(x_{k-1}), h_) | + 3r(2r+d) | 累积全部历史信息 |
GatedMarkovHead 在 Vanilla 基础上增加了门控机制,允许 backbone 的当前 hidden state 调制偏差强度。
RNNHead 则更为复杂,它在 block 内部维护一个循环状态,理论上能捕获更长距离的依赖,但延迟也相应增加。
实际部署中,VanillaMarkov 以极简的结构和极低的延迟成为默认选择。78M 的参数量对整体吞吐影响极小。
训练时采用 teacher forcing:Markov 头总是看到真实的前序 token,而非自己上一轮的预测结果。
这意味着训练过程中梯度传递稳定,模型学习的是最理想的条件分布。
推理时则改为自回归采样:每步用上一时刻采样的 token 作为下一步的输入,循环 8 次完成整个 block。
整个过程没有 attention,没有 MLP,只有两次矩阵乘法,生成 8 个 token 仅需约 50μs。
相比 backbone 的前向传播,这个开销可以忽略不计,却显著提升了远端 token 的预测质量。
实验表明,加入 Markov 校正后,位置 5 到 7 的接受率明显优于纯并行方案,接近自回归 draft 的水平。
这正是半自回归范式的核心价值:用极小的顺序开销,换取显著的质量提升。
3.4 信心头
信心头是 DSpark 中最轻量的组件,仅由一个线性层构成。
它接收 backbone 的 hidden states,输出每个 draft token 被目标模型接受的预估概率 a_。
这个概率是硬件感知调度器的核心输入。调度器需要依据 a_ 动态决定每轮验证多少 token。
验证太少浪费并行度,验证太多则拖慢 throughput,这是一个精细的权衡。
如果信心估计不准,调度器就会做出错误决策。因此,校准质量直接决定系统收益。
DSpark 使用 BCE(Binary Cross Entropy)损失训练信心头,让预测分数与实际观察到的接受率尽可能一致。
BCE 损失比较预测概率与实际二值标签(接受为 1,拒绝为 0),通过梯度下降强迫模型输出经过 Sigmoid 后落入合理区间。
未经校准的信心估计常常过于乐观或悲观,导致调度器系统性地高估或低估验证收益。
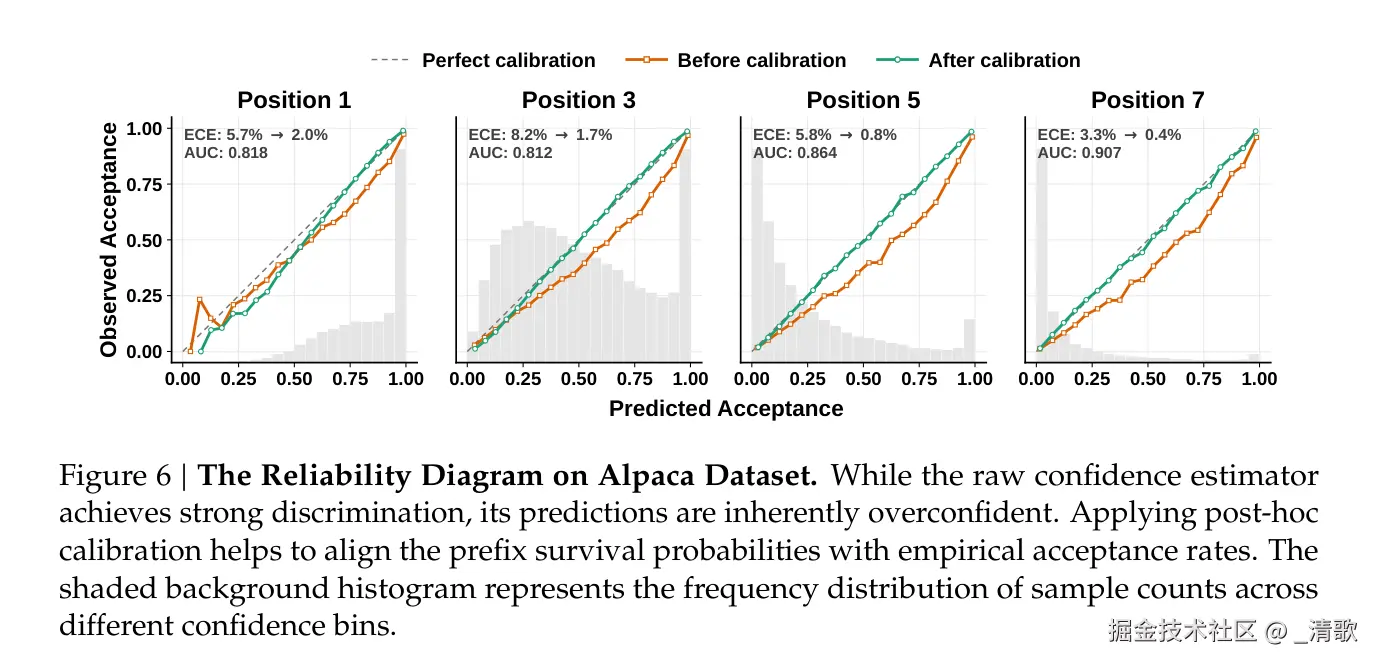
上图是可靠性图(Reliability Diagram),横轴为预测信心分桶,纵轴为对应桶内的真实接受率。
理想情况下,所有点应落在对角线上。经过 BCE 校准后,信心头的输出与实际接受率高度吻合。
离对角线越远的点,意味着模型在该信心区间内的估计越不靠谱,调度器据此做决策就会犯错。
论文还扫描了不同信心阈值对系统的影响。
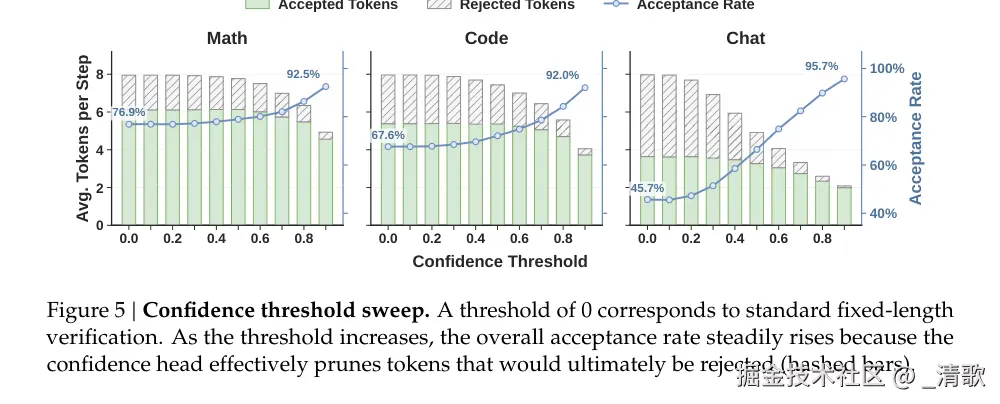
校准后的信心头让调度器能在「激进」与「保守」之间找到最优平衡点------阈值设太低混入低质量 draft,设太高则浪费并行预测能力。
4. 训练策略
4.1 损失函数设计
训练 draft 模型的目标,是尽可能模仿目标模型(Target Model)的输出分布。DSpark 没有使用单一的交叉熵(Cross Entropy, CE),而是设计了一个三项加权复合损失。
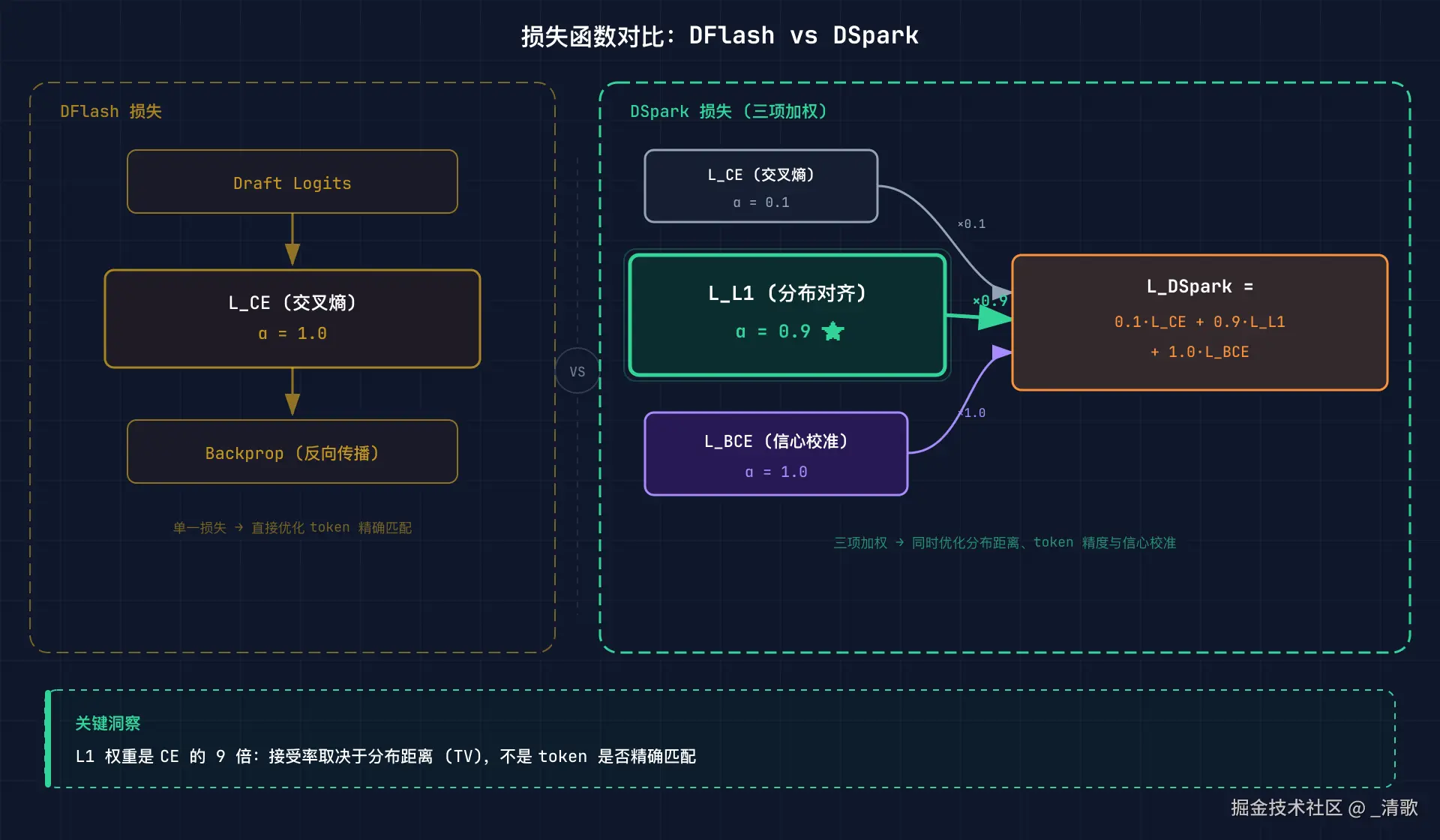
公式如下:
\mathcal{L}{\text{DSpark}} = \alpha{\text{CE}} \cdot \mathcal{L}{\text{CE}} + \alpha{\text{L1}} \cdot \mathcal{L}{\text{L1}} + \alpha{\text{conf}} \cdot \mathcal{L}_{\text{BCE}
三项损失各司其职:
| 损失项 | 含义 | 权重 | 作用 |
|---|---|---|---|
| \mathcal{L}_{\text{CE} | 交叉熵 token 预测 | 0.1 | 预测正确 token |
| \mathcal{L}_{\text{L1} | \sum\|\text{softmax(draft)} - \text{softmax(target)}\ | 0.9 | 分布对齐(核心) |
| \mathcal{L}_{\text{BCE} | 信心头校准 | 1.0 | 准确估计接受率 |
最反直觉的是:L1 权重为 0.9,是 CE 的九倍。为什么?
投机解码的接受率取决于 draft 分布与 target 分布之间的 TV 距离,而不是 token 是否精确匹配。即使 draft 猜错了具体 token,只要两个分布足够接近,验证时依然大概率通过。
L1 损失直接优化的是分布距离而非 token 匹配精度,因此权重远高于 CE。
为了让模型更关注近期预测,DSpark 对位置 $$$$ 施加指数衰减权重:
w_k = e^{-k/\gamma
其中 γ=4.。越靠后的位置权重越低------远处的 token 本来就难预测,不必分配同等监督强度。
训练时,每个样本随机采样 512 个锚点位置。锚点必须落在 response 区域内,确保模型只学习生成答案,而非模仿用户提问。
4.2 训练流程
DSpark 的训练依赖一个关键前提:目标模型的隐藏状态需要提前算好并缓存下来。
它被称为 Target Cache。以 Qwen3-4B 为例,完整缓存约 38TB。尽管存储开销巨大,它省去了训练时反复运行目标模型前向,显著提升迭代效率。
整个训练流程分为三步:数据准备、模型训练、效果评估。
在数据准备阶段,系统先用目标模型重新生成答案,再提取第 1、9、17、25、33 层的隐藏状态写入缓存。训练阶段直接读取缓存,配合锚点采样策略进行迭代。
关键超参数如下:
| 参数 | 值 | 说明 |
|---|---|---|
| 学习率 | 6.0 \times 10^{-4 | AdamW |
| Warmup 比例 | 0.04 | 线性 warmup |
| 全局 batch size | 512 | 8 卡数据并行 |
| 训练轮数 | 10 | 覆盖充分 |
| Block size | 7 | Draft 长度 |
| Draft 层数 | 5 | Backbone 深度 |
| Markov rank | 256 | 低秩维度 |
| 精度 | bf16 | 混合精度 |
| 最大长度 | 4096 | 序列截断 |
所有配置均已开源在 DeepSpec 仓库中。修改 config/dspark/dspark_qwen3_4b.py 即可复现或调整实验。
5. 硬件感知前缀调度器
5.1 调度核心:应该验证多少 token?
投机解码每轮都要回答一个问题:这次验证几个 draft token?
静态长度显然不够聪明。验证太少,浪费并行能力;验证太多,可能拖垮系统吞吐。
DSpark 的调度器将这个问题转化为一个优化目标:
Θℓ=(1+∑k=1ℓak)×SPS(ℓ+1
左边 Θ\el 是期望吞吐。右边第一项是预期接受的 token 数,第二项 \text{SPS(Steps Per Second) (ℓ+1 是目标模型在验证 ℓ+ 个 token 时的实际硬件步频。
注意 SPS(ℓ 不是平滑曲线。它在 ℓ= 附近会出现一个硬件悬崖:
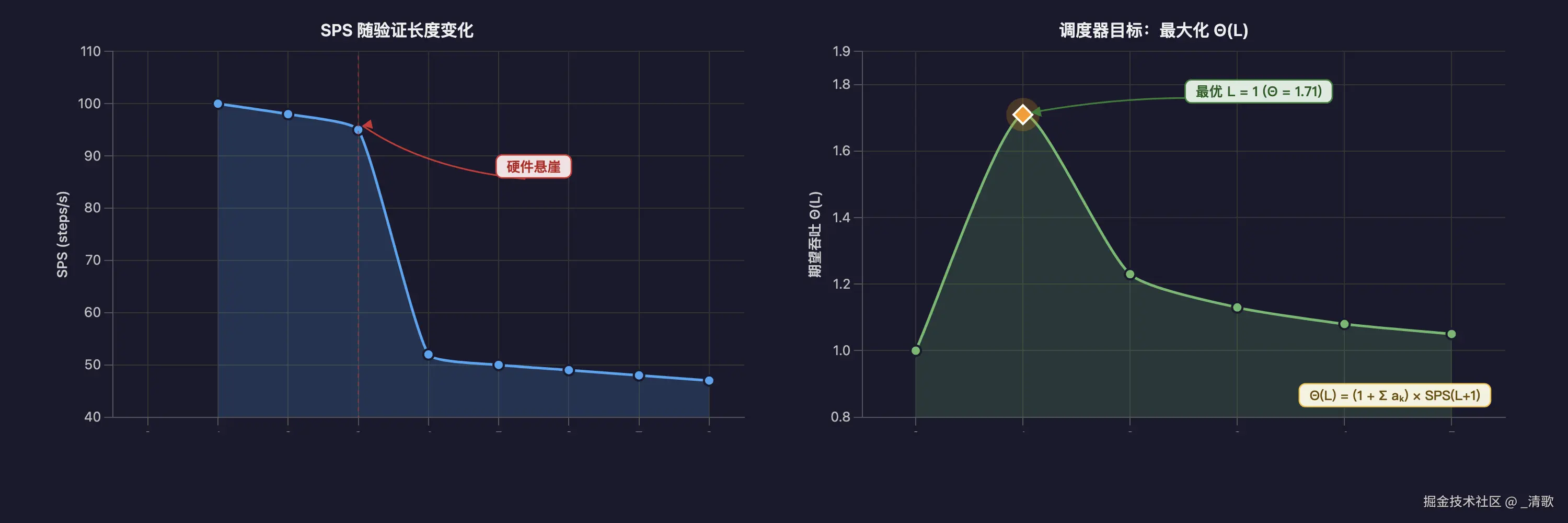
这是因为 GPU kernel 会在序列长度超过阈值时切换实现,比如从 FlashAttention 降级到标准 attention。吞吐量瞬间腰斩。
例如,设信心头给出 a1=0.8,a2=0.7,a3=0.,而 SPS 剖面为 [1.0,0.95,0.52,0.48,...。
逐项计算结果:
Θ0=1.00,Θ1=1.71,Θ2=1.23,Θ3=1.1
最优解是 ℓ=。即使后面还有可用的 draft token,验证它们反而降低整体效率。没有硬件感知就会错选 ℓ=。
搜索策略采用因果贪心:从 ℓ= 开始递增,一旦发现 \Theta_\ell < \Theta_{\ell-1 立刻终止。
这个 early-stop 不是工程偷懒,而是数学必需。Appendix A 的证明指出,如果去掉 early-stop 做全局最优搜索,调度器会向后窥视未来 token 的取值,引入选择偏差,破坏无损解码的理论保证。
此外,调度器还会根据当前负载自适应调整:
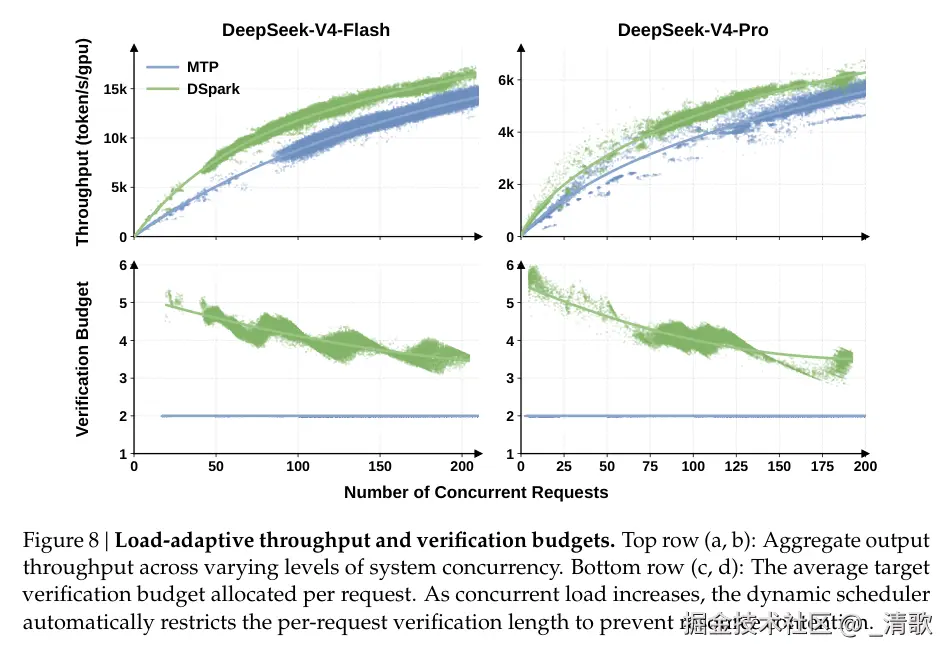
低并发时延长验证长度到 4-6 个 token,充分利用闲置算力。高并发时自动缩回至 2 个 token 左右,防止 batch 被低质量候选撑爆。
5.2 零开销调度 (ZOS)
调度器本身的计算极其轻量:不到 1μs,仅十次浮点运算。
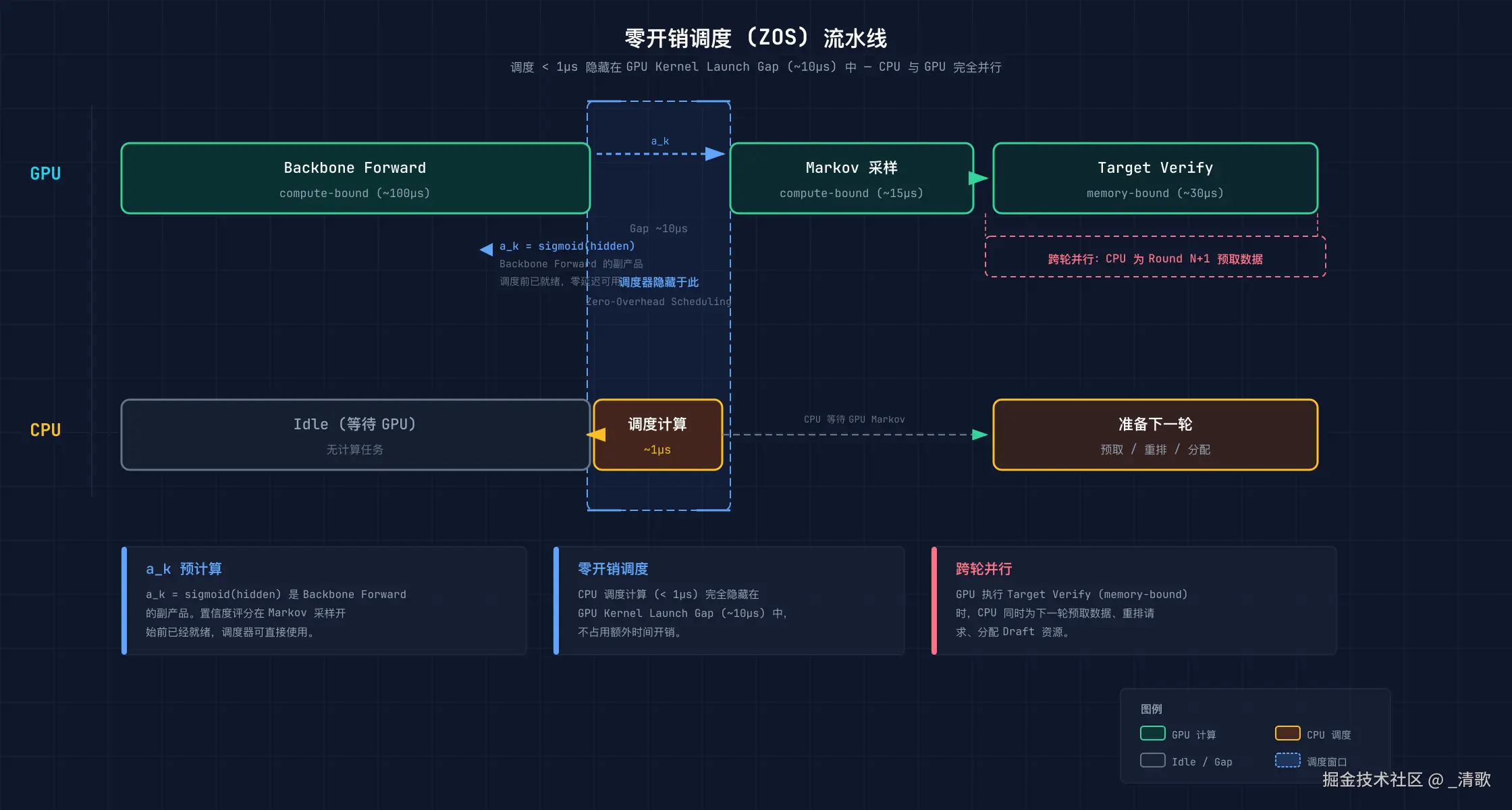
它藏在哪儿?GPU 从 backbone forward 切换到 target verify 时,kernel launch gap 约 10μs。调度器就在这 10μs 内完成全部决策。
信心分数 a_ 并非额外计算,而是 backbone forward 的副产品。对 backbone 的最后一个隐藏状态做一次 sigmoid 即可得到,甚至不用等 Markov 采样结束。
数据从 GPU 拷贝到 CPU 也是异步的,non_blocking=True 让传输与后续计算重叠。
更大的并发发生在 target verify 阶段:target model 的验证过程是 memory-bound,GPU 计算单元大量空闲。
此时 CPU 可并行准备下一轮:确定新的锚点、构造 noise embedding、预取 target hidden states。
这样一来,调度完全没有占用额外的时间片,故称为 Zero-Overhead Scheduling。
6. 实验结果
6.1 离线 benchmark 与生产部署
在离线评测中,DSpark 相比 EAGLE-3 的 macro-average accepted length 提升了 30.9% (Qwen3-4B)、26.7%(8B)和 30.0%(14B)。
相比 DFlash,提升幅度为 16.3% (4B)、18.4%(8B)和 18.3%(14B)。
从位置维度看,DSpark 在 position 5-7 的远端位置依然维持高接受率。纯并行方案(DFlash)在这些位置急剧衰减,而 DSpark 的 Markov 头有效抑制了后缀衰减。
论文中的 fig02、fig03、fig04 分别展示了按位置接受率、drafter 深度影响以及 proposal length 的影响,读者可对照原文查看细节。
在生产环境 DeepSeek-V4 上,DSpark 已完成全量替换。以下是线上实测数据:
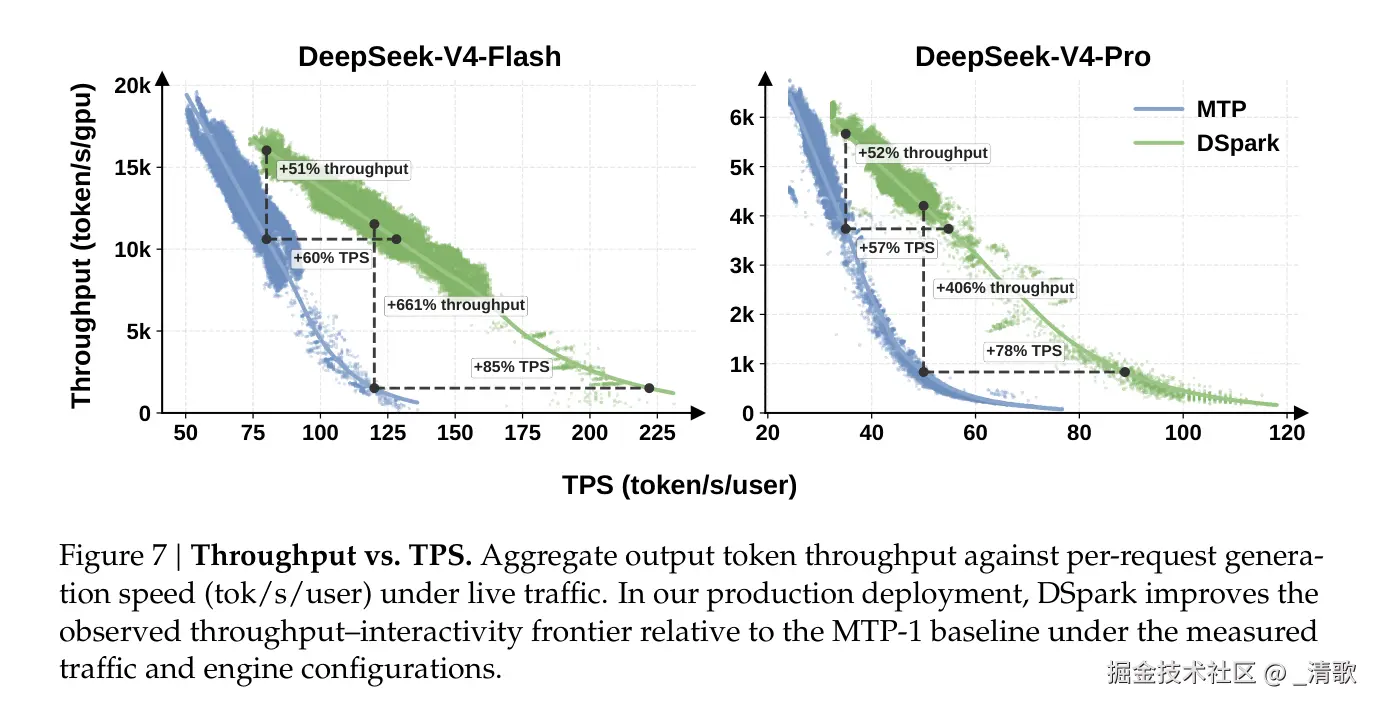
| 引擎 | SLA 锚点 | 吞吐量增益 | 每用户速度提升 |
|---|---|---|---|
| V4-Flash | 80 tok/s/user | +51% | +60%~85% |
| V4-Flash | 120 tok/s/user(高交互) | +661% | --- |
| V4-Pro | 35 tok/s/user | +52% | +57%~78% |
| V4-Pro | 50 tok/s/user(高交互) | +406% | --- |
高 SLA 点的增益看起来惊人,原因是基线 MTP-1 在这些位置已接近操作极限。DSpark 的实际意义是扩展了可行交互性前沿。
这里需要解释一个常见疑问:为什么生产对比的是 MTP-1,而不是论文离线实验里的 DFlash?
因为 MTP(Multi-Token Prediction)-1 才是 DeepSeek-V4 发布前的生产基线。它是一个附着在目标模型上的单 token 预测头。在高并发下,MTP-3/5 的静态多 token 验证会严格降低吞吐,所以 MTP-1 长期是唯一不会崩的选择。
DFlash 则没有跑在 DeepSeek-V4 的自研推理引擎上。V4 使用 index-attention 和 compress kernel,与标准 Transformer 不同。因此生产部署只能对比同引擎内可替换的基线。
6.2 方法对比总结
把 DSpark 与 EAGLE-3、DFlash 放在一起比较,差异一目了然:
| 维度 | EAGLE-3 | DFlash | DSpark |
|---|---|---|---|
| 生成方式 | 自回归 | 块扩散(并行) | 半自回归(并行+顺序) |
| Draft 延迟 | 随长度线性增长 | 近似常数 | 近似常数 |
| 顺序校正 | 有(串行) | 无 | 有(Markov 低秩) |
| 信心头 | 无 | 无 | 有 |
| 硬件感知调度 | 无 | 无 | 有 |
| 生产部署 | 仅开源 | 仅开源 | DeepSeek-V4 线上 |
| 适用场景 | 离线实验 | 离线实验 | 生产服务 |
EAGLE-3 的接受率不低,但自回归 draft 的延迟随 block size 线性增长,限制了它在高并发下的扩展性。DFlash 的并行延迟极低,但没有顺序校正,远端位置质量衰减严重。
DSpark 同时解决了这两个痛点:用并行 backbone 保证低延迟,用 Markov 头恢复 token 依赖,再用信心头和硬件感知调度器把整套系统推进到生产环境。
结论
回顾全文,DSpark 的核心贡献可以总结为三点。
第一,算法层面提出了半自回归范式。它打破了"并行低质量"与"自回归高延迟"之间的传统权衡,在延迟-接受率的二维平面上达到了 Pareto 更优。
第二,系统层面引入了硬件感知前缀调度器。它将投机解码的目标从"加速单个请求"提升为"优化整个服务的吞吐量-交互性帕累托前沿"。SPS 悬崖的发现和 early-stop 的理论保证,让调度器既快又正确。
第三,工程层面完成了从论文到生产的闭环。DSpark 在论文发表后两周内即完成 DeepSeek-V4 的线上全量替换,覆盖 Flash 和 Pro 两条产品线。
如果你想复现或改进这套方案,欢迎访问 DeepSpec 开源仓库。所有训练配置、损失实现和调度逻辑均已开放。
如果这篇文章帮你理清了投机解码的思路,欢迎点赞收藏,下次回顾更方便。
参考资料
- DSpark 论文: DeepSpec 仓库同级
DSpark_paper.pdf - DFlash 论文: arXiv:2602.06036 (ICML 2026)
- EAGLE-3 论文: arXiv:2503.01840
- DeepSpec 代码仓库: GitHub
- SpecForge (训练框架基础): GitHub