llama.cpp:一次很小但很关键的 Agent 工具调用修复

TL;DR
- 场景:llama.cpp 本地推理栈在 Agent 工具调用场景下,peg-native 解析偶发失败
- 结论 :b9754 通过在
common/peg中引入ac parser,让 grammar generation 更严格,从源头避免生成无法解析的非法结构 - 产出:一份从 PR #24869 与 Issue #24863 出发的工程解读,覆盖问题成因、修复方向、升级建议与回归测试要点
版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
common/peg ac parser 实现 |
✅ 已验证 | PR #24869 在 common/peg 引入 ac parser,处理 delimiter 边界一致性问题 |
| peg-native grammar generation 严格化 | ✅ 已验证 | 修复 until(delim) 与 literal(delim) 组合时允许非法前缀被吞掉的语义漏洞 |
| XML 风格工具调用稳定性提升 | ⚠️ 待验证 | 需在多参数、长字符串参数、streaming 场景下做回归 |
兼容 --jinja 与自定义 chat template |
⚠️ 待验证 | 自定义模板与 peg-native parser 兼容性需业务侧验证 |
| llama-cli 本地聊天体验变化 | ❌ 不适用 | 普通聊天场景无明显感知 |
| 普通 Chat Completion 行为变化 | ❌ 不适用 | 不走 peg-native 工具调用链路时无明显影响 |
TL;DR
llama.cpp b9754 不是一次"大版本升级",也不是一次性能爆炸式提升。它真正值得关注的地方,是修复了一个很具体但很关键的问题:让 peg-native 工具调用里的 grammar generation 更严格,避免模型在 XML 风格工具调用中生成看似合法、实际无法被解析的坏结构。
更具体地说,相关 PR 在 common/peg 里实现了一个 ac parser,用于处理"读到某个结束符为止"的场景。它解决的是生成阶段和解析阶段语义不一致的问题。
这类修复表面上很底层,实际影响的是 Agent 工具调用可靠性。
如果你只是用 llama.cpp 跑普通聊天,这个版本不一定有明显感知;如果你用 llama-server 做 OpenAI-compatible API、工具调用、结构化输出、Agent Runtime,这类修复就非常值得关注。
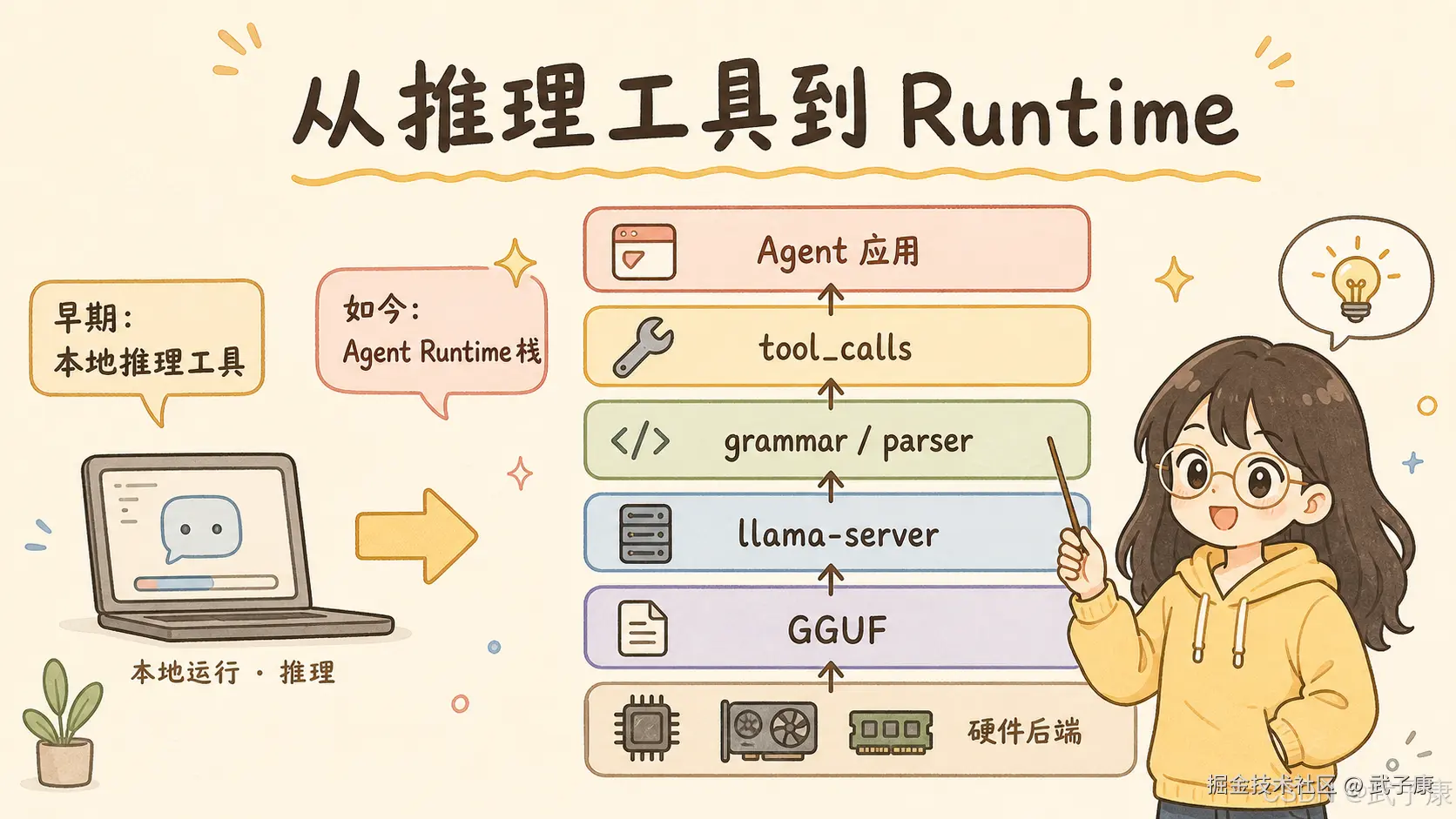
1. llama.cpp 已经不只是本地跑模型
llama.cpp 最早给人的印象是"本地跑 LLaMA 的 C/C++ 项目"。但发展到现在,它已经不只是一个命令行推理工具,而是一个完整度很高的本地推理栈。
它覆盖了很多能力:
text
模型加载与 GGUF 格式
CPU、Metal、CUDA、ROCm、Vulkan、SYCL、OpenVINO 等多后端推理
量化模型推理
llama-cli 本地命令行入口
llama-server OpenAI-compatible 服务入口
grammar constrained decoding
工具调用、chat template、parser、server streaming所以现在看 llama.cpp,不能只看"跑得快不快"。它正在逐渐变成一个边缘侧、本地侧、私有化部署侧的 LLM Runtime。
这也是为什么一次 parser / grammar 层面的修复,会值得单独写。
因为 Agent 时代,推理框架不只要把 token 算出来,还要保证 token 能稳定变成上层应用可消费的结构化动作。
2. b9754 这次到底改了什么?
这次核心变更可以概括成一句话:
在 common/peg 里实现 ac parser,让 grammar generation 更严格,避免工具调用输出逃逸语法约束。
这句话里有几个关键词。
common/peg:说明它不是改模型推理 kernel,也不是改 CUDA、Metal、ROCm 后端,而是改公共解析逻辑。
ac parser:这里可以理解为 Aho-Corasick 自动机相关的处理思路,适合处理"多个分隔符匹配""读到某个 delimiter 为止"这类问题。
stricter grammar generation:更严格的语法生成。重点不是解析时兜底,而是在生成阶段尽量不让模型采样出错误结构。
这个方向很重要。
结构化输出和工具调用的稳定性,不能只靠输出后再 parse。更好的方式是在 token 生成过程中就通过 grammar 限制非法路径。
3. 工具调用为什么会坏?
现在很多模型支持工具调用,但不同推理框架对工具调用的实现方式并不完全一样。
在 OpenAI 风格接口里,工具调用通常会被表达为结构化 JSON:
json
{
"tool_calls": [
{
"function": {
"name": "read_file",
"arguments": "{\"filePath\":\"/tmp/a.txt\"}"
}
}
]
}但在一些 chat template 中,工具调用可能会被模型组织成 XML 风格:
xml
<parameter=filePath>
/Users/demo/file.txt
</parameter>
<parameter=startLine>
1
</parameter>这种格式本身没问题,但它对边界极其敏感。
例如参数值什么时候结束?
filePath 的值是:
text
/Users/demo/file.txt还是:
text
/Users/demo/file.txt
</parameter>如果生成阶段和解析阶段对这个边界理解不一致,就会出问题。
这次相关 issue 中出现的典型问题是:模型偶尔会生成重复的 </parameter>:
xml
<parameter=filePath>
/Users/.../file.story
</parameter>
</parameter>
<parameter=startLine>
1
</parameter>人一眼能看出这里多了一个关闭标签。但对推理系统来说,问题不是"人能不能看懂",而是:
生成阶段为什么允许这种结构被采样出来?
解析阶段为什么又无法接受它?
这就是 b9754 这类修复要解决的核心矛盾。
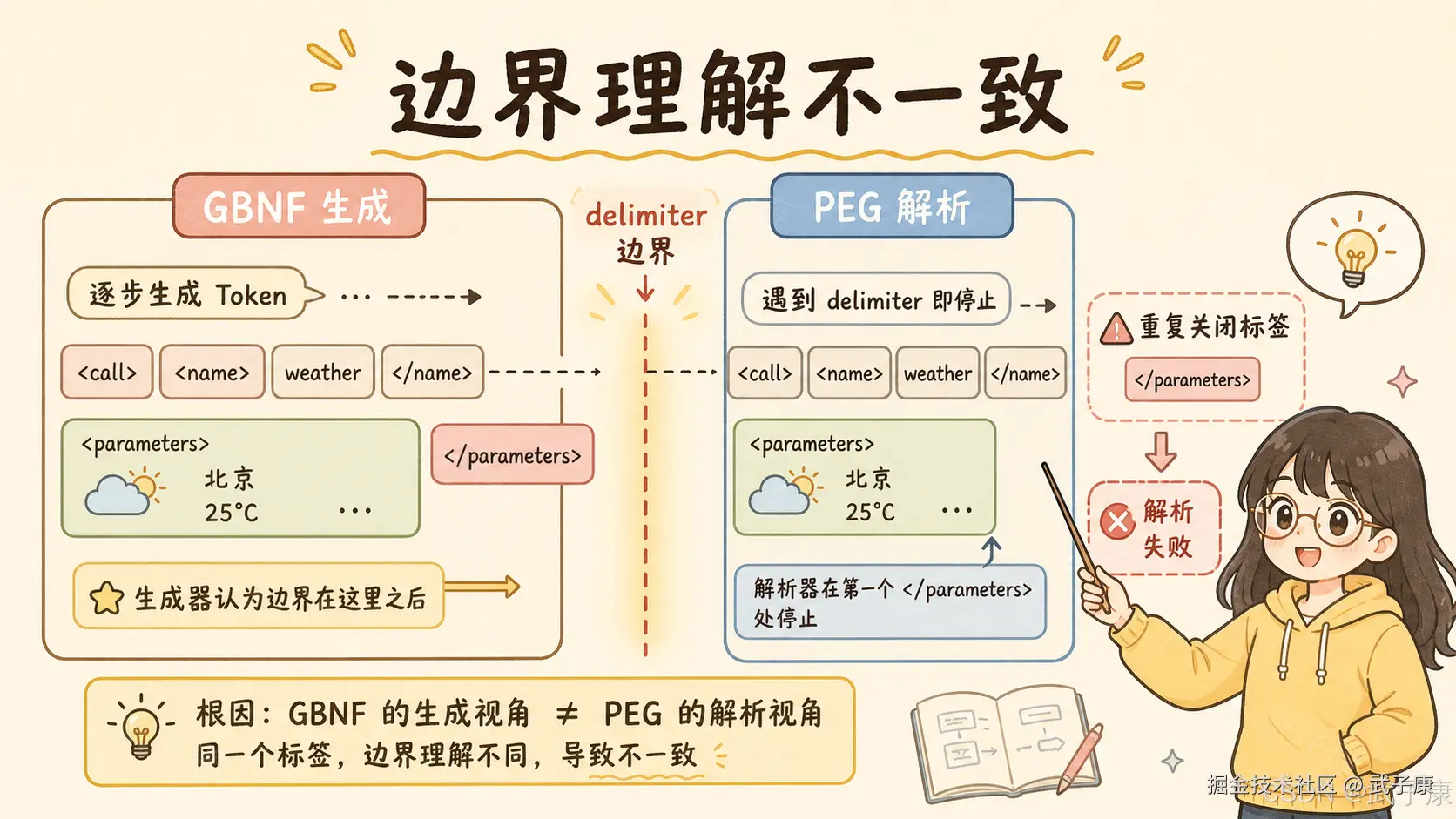
4. 真正的问题:GBNF 和 PEG 对边界理解不一致
这里需要区分两个概念。
GBNF 主要用于生成阶段。它告诉模型:接下来哪些 token 是允许生成的,哪些 token 不应该生成。它的作用是约束采样路径。
PEG parser 主要用于解析阶段。模型输出完成后,解析器尝试把文本解析成工具调用结构。
理想情况下,这两者应该有同一套语义。
也就是说,GBNF 允许生成的东西,PEG parser 应该能解析;PEG parser 认为非法的东西,GBNF 就不应该让模型生成。
但这次问题恰恰出在这里。
在 Until('\n</parameter>\n') 这类逻辑里,GBNF 生成语法可能允许某些结束符前缀被参数值吞进去,然后再匹配后面的完整结束符。结果就是模型可能生成:
text
value
</parameter>
</parameter>从生成语法角度看,它可能被认为是合法路径。
但 PEG parser 解析时采用另一个边界:遇到第一个完整 </parameter> 就认为参数结束。于是后面剩下的第二个 </parameter> 就变成无法解释的残留文本。
最终表现就是:
text
模型生成了一段工具调用
server 尝试解析
解析失败
tool_calls 没有被正确返回
streaming 任务被中断这类 bug 最麻烦的地方在于,它不是每次必现。它依赖模型输出、上下文、采样路径、模板格式和工具参数内容,所以在线上会表现为"偶发工具调用失败"。
偶发问题比稳定复现的问题更难排查。
5. ac parser 修的是什么?
这次引入的 ac parser,核心目标不是让解析器更宽松,而是让 grammar generation 更严格。
原来的问题是:
until(delim) 和后面的 literal(delim) 组合时,生成语法可能允许 delimiter 的一部分被前面的 value 吃掉。
新的处理方式更接近:
匹配并消费直到第一次出现 delimiter 为止,并且把 delimiter 边界纳入一致的自动机处理。
可以把它理解成一个状态机问题。
假设 delimiter 是:
text
\n</parameter>\n生成器在看到:
text
\n</parameter>这种接近完整 delimiter 的前缀时,不能随便允许 value 在这里结束,也不能允许它把这个前缀当成普通 value 内容吞掉,再让后面重复出现一个完整 delimiter。
Aho-Corasick 类自动机适合处理这种"扫描文本直到遇到某个或多个分隔符"的问题。它不是靠简单字符串查找,而是把 delimiter 的前缀、后缀、状态转移关系显式建模。
这使 grammar 更容易知道:
text
当前是不是已经进入 delimiter 的一部分?
如果继续生成某个字符,会不会构成完整 delimiter?
如果构成完整 delimiter,应该在哪里停止?
如果只是 delimiter 的前缀但后续不匹配,应该如何回退?这类细节在普通业务开发里很少出现,但在 constrained decoding 里非常关键。
6. 为什么这对 Agent 很重要?
很多人看推理框架,只关注三个指标:
text
吞吐量
首 token 延迟
显存占用这三个当然重要,但 Agent 场景还有第四个指标:
结构化输出可靠性。
Agent 不是普通聊天。普通聊天里,模型多输出一个标签、少一个括号,用户可能还能看懂。但 Agent 工具调用不一样。
工具调用失败意味着:
text
文件读取失败
API 调用失败
数据库查询失败
机器人控制指令失败
业务流程中断用户看到的是"模型怎么又坏了",但根因可能不是模型能力,而是 Runtime 的结构化输出链路不稳定。
尤其是在本地推理和私有化部署里,很多团队会用 llama.cpp 承接这些场景:
text
本地代码助手
离线 Agent
企业内网知识库
机器人语音控制
低成本边缘推理工具调用一旦偶发失败,用户体验会非常差。
所以 b9754 这类改动虽然看起来只是 parser 层面的一个 patch,但实际是在补 Agent Runtime 的地基。
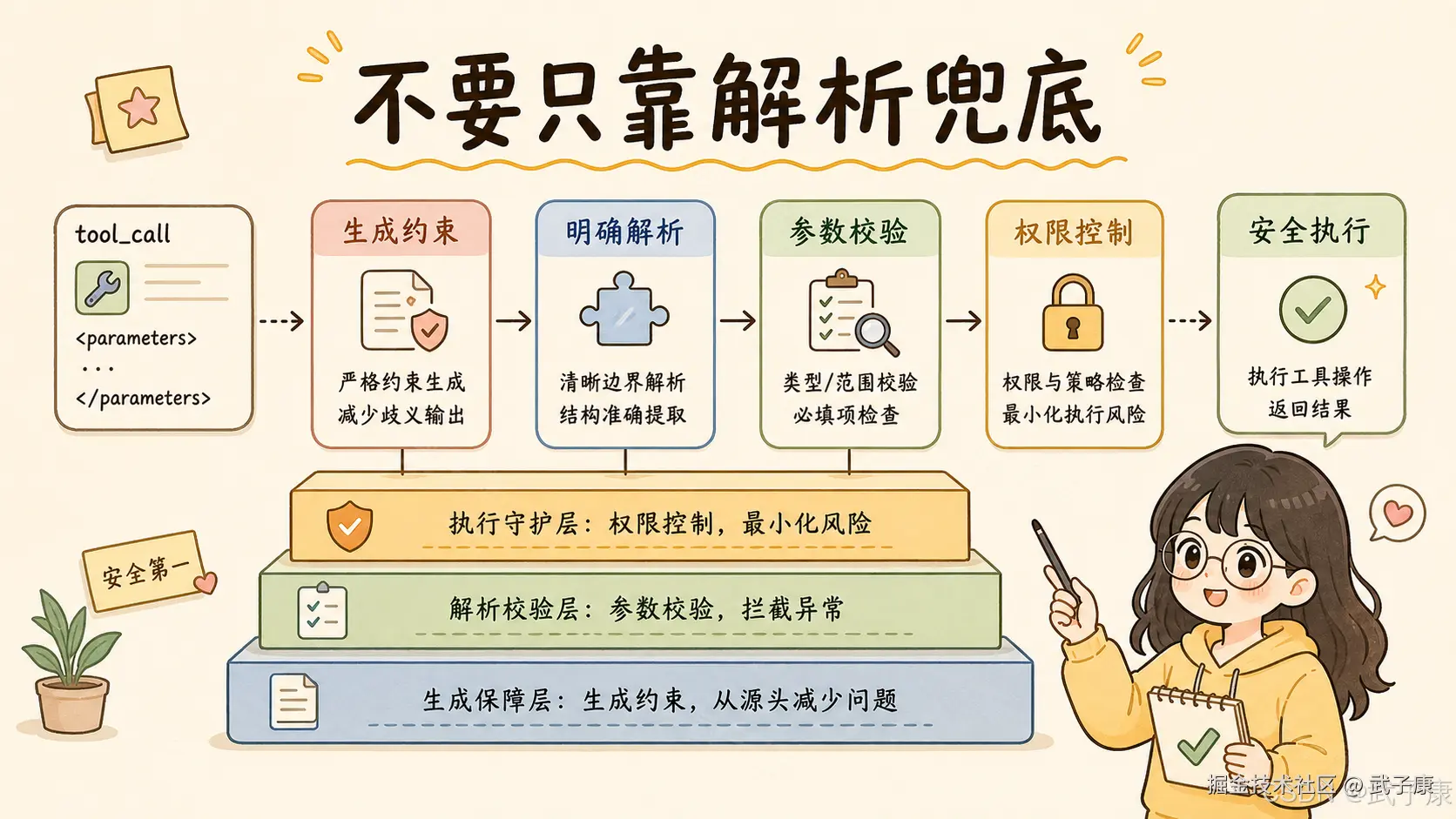
7. 为什么不是简单地解析时容错?
有人可能会问:既然多了一个 </parameter>,解析器忽略掉不就好了?
这是一种思路,但不是最优先的修复点。
原因很简单:工具调用是高风险边界。
如果解析器太宽松,就可能把本来错误的结构吞掉,甚至误解析成另一个工具参数。
例如:
xml
<parameter=filePath>
/tmp/a.txt
</parameter>
</parameter>
<parameter=delete>
true
</parameter>这种情况下,到底该忽略哪个标签?该不该继续解析?后面的参数是否可信?
工具调用不是普通文本,它可能会触发真实操作。越靠近执行层,越不能随便"猜模型意图"。
所以更合理的策略是:
text
生成阶段尽量严格,不让模型生成非法结构
解析阶段保持明确边界,不盲目吞错
执行阶段再做参数校验和权限控制b9754 修的是第一层:生成约束。
8. 普通用户需要升级吗?
如果你只是用 llama.cpp 跑本地聊天,例如:
bash
llama-cli -m model.gguf这次更新大概率不会带来明显变化。
如果你用的是 llama-server,但只是普通 Chat Completion,也未必能明显感知。
真正受益的是以下场景:
text
使用 --jinja
使用自定义 chat template
使用 XML 风格工具调用
使用 peg-native chat format
使用工具调用和 streaming
模型输出需要被严格解析成 tool_calls
本地推理服务要对接上层业务系统尤其是使用复杂模板、多参数工具调用、reasoning 模型、多轮 Agent 的时候,这类问题更容易暴露。
如果你看到过类似日志或现象,就更应该升级验证:
text
common_chat_peg_parse: unparsed peg-native output
srv stop: cancel task
tool_calls not returned
stream aborted
duplicate </parameter>
malformed tool-call XML9. 升级后应该怎么测?
如果你在用 llama.cpp 做 Agent 服务,不建议只测"能不能调一次工具"。
建议做几类回归:
第一,多参数工具调用。
第二,字符串参数里包含换行、路径、XML-like 文本、JSON 片段。
第三,streaming 模式下工具调用输出是否稳定。
第四,模型是否还能正常生成普通回答。
第五,自定义 chat template 是否和 peg-native parser 兼容。
第六,错误工具调用是否会被明确拒绝,而不是误解析。
企业级 Agent 要测高频、多轮、复杂参数、异常参数、长上下文下的稳定性。
10. 从工程角度看,这次修复说明了什么?
这次修复背后有一个很重要的工程现实:
LLM Runtime 的复杂度正在从"矩阵计算"扩展到"协议、模板、语法、解析、状态机"。
早期推理框架竞争的是:
text
谁支持更多量化格式
谁速度更快
谁能跑在更多硬件上现在继续往 Agent 场景走,竞争点会变成:
text
谁的工具调用更稳定
谁的结构化输出更可靠
谁的 server streaming 更健壮
谁对 chat template 的兼容性更好
谁能处理多模型、多工具、多轮调用
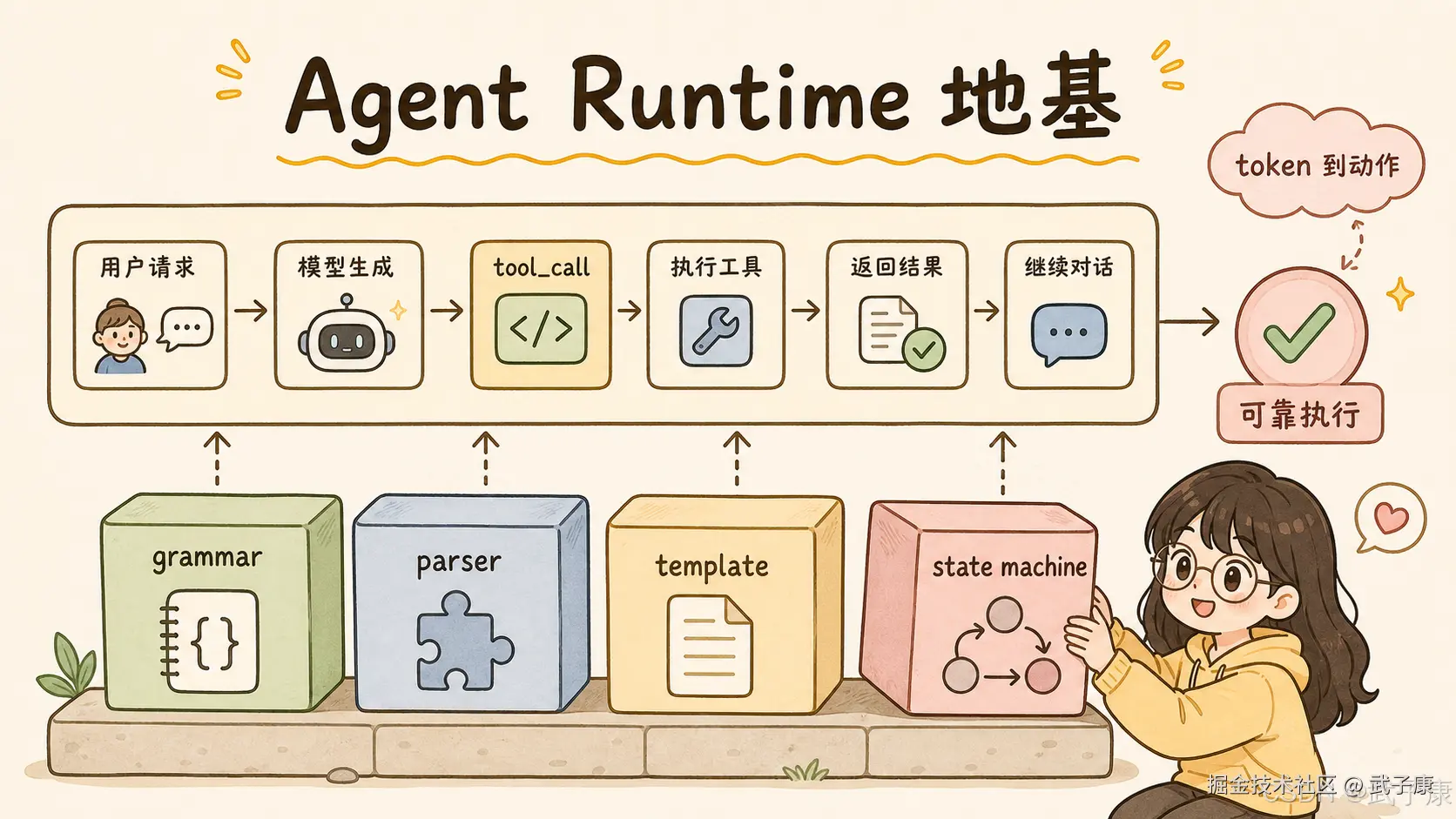
谁能在模型输出不完美时给出可控行为这也是 llama.cpp 越来越像完整推理栈的原因。
它不是只负责把 token 算出来,还要负责把 token 变成上层应用能安全消费的结构。
11. 结论
llama.cpp b9754 的核心意义,不在于"新增了一个 parser",而在于它暴露了 Agent Runtime 的一个关键事实:
模型输出不是最终结果,能被稳定、严格、可控地解析和执行,才是工程结果。
普通聊天时代,推理框架只要把 token 算出来就行。
Agent 时代,推理框架还要保证 token 能变成可靠的结构化动作。
b9754 修复的正是这个结构化动作链路中的一个边界问题。
它很小,但方向很对。
对于使用 llama.cpp 做本地 Agent、工具调用、机器人控制、私有化 LLM 服务的人来说,这类更新值得持续跟踪。
参考资料
- ggml-org/llama.cpp PR #24869: common/peg : implement ac parser for stricter grammar generation: github.com/ggml-org/ll...
- ggml-org/llama.cpp Issue #24863: llama-server occasionally fails tool calls with peg-native parser: github.com/ggml-org/ll...
- llama.cpp GitHub repository: github.com/ggml-org/ll...
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
llama-server 偶发工具调用失败,日志出现 duplicate </parameter> |
peg-native grammar generation 与 PEG parser 对 until(delim) 边界理解不一致 |
查看 common_chat_peg_parse: unparsed peg-native output 与模型输出 XML 片段 |
升级到含 PR #24869(b9754)的版本,让 grammar 在生成阶段拒绝非法路径 |
流式响应中 tool_calls 字段缺失,srv stop: cancel task 出现 |
解析器在第一个完整 </parameter> 处停止,剩余闭合标签成为残留导致解析失败 |
在 stream 日志中对比生成内容与 parser 截断点 | 升级 b9754 后重测 streaming;保持解析器明确边界而非吞错 |
多参数工具调用偶发报 malformed tool-call XML |
字符串参数中含 \n、</parameter> 前缀或 XML-like 文本,触发 delimiter 前缀被 value 吞掉 |
复现包含路径、换行、JSON-like 文本的字符串参数 | 升级到 ac parser 版本;按错误速查卡做六类回归 |
| 自定义 chat template 与 peg-native parser 配合时偶发失败 | 模板输出走 peg-native chat format,但 grammar 未限制生成路径 | --jinja + 自定义模板下,对照 PR #24869 行为验证 |
升级 b9754 并做模板/parser 兼容性测试 |
偶发 stream aborted 且重试后偶有成功 |
非法结构依赖采样路径,非 100% 复现 | 多轮采样或调高 temperature 复现;记录生成 token 序列 | 升级后通过严格 grammar generation 把非法路径从源头剔除 |