系统是改出来的,不是设计出来的。DeepSeek 这次改的,不是模型,是模型被跑起来的方式。
6 月 27 号,DeepSeek 和北大联手扔出一个东西,叫 DSpark。
一晚上,全网都在传一句话------「提速 85%」。
说实话,我刷到的时候也愣了一下。但翻了半天讨论,发现一个挺尴尬的事:八成的人在转,但没几个说得清这玩意儿到底干了啥。有人说是新模型,有人说是新芯片,还有人说是 DeepSeek 又搞了个 GPT 杀手。
都不对。
这篇文章,我就把 DSpark 一次性讲透。不绕弯子,看完你就明白:它既不是新模型,也不是什么芯片,而是 DeepSeek 给自家大模型装的一个**「加速外挂」------发动机没换,但跑起来快了一大截,而且一个字都不会写错**。
下面说人话。
一、先泼盆冷水:DSpark 不是新模型
这是最大的误区,也是最容易翻车的地方,我必须放最前面讲。
打开 HuggingFace 上 DSpark 的模型卡,DeepSeek 自己写的第一句话是:
DeepSeek-V4-Pro-DSpark is NOT a new model. It is the same checkpoint with an additional speculative decoding module attached.
翻译过来:它不是新模型,是原来那个 V4,外加了一个投机解码模块。
打个比方。你的车还是那辆车,发动机没换、零件没换。但修理厂给你加了个涡轮增压------进气方式变了,燃烧效率上去了,速度自然就快。你人还是你,车还是那车,只是跑起来的方式变了。
DSpark 干的就是这个事。DeepSeek-V4 那个 1.6 万亿参数、能吃下 100 万字上下文的大脑原封不动,外面套一层「投机解码」的壳,让它吐字更快、吞吐更高。
所以别再纠结「DSpark 比 V4 强多少」了------它就是 V4,只是换了个跑法。至于 V4 自己那套混合注意力(把超长上下文的算力和显存开销压到前代 V3.2 的十分之一,这是 DeepSeek 官方数据),那是 V4 本身的功夫,跟 DSpark 没关系。
那 DSpark 这层「壳」到底改了啥?这才是真正有意思的部分。
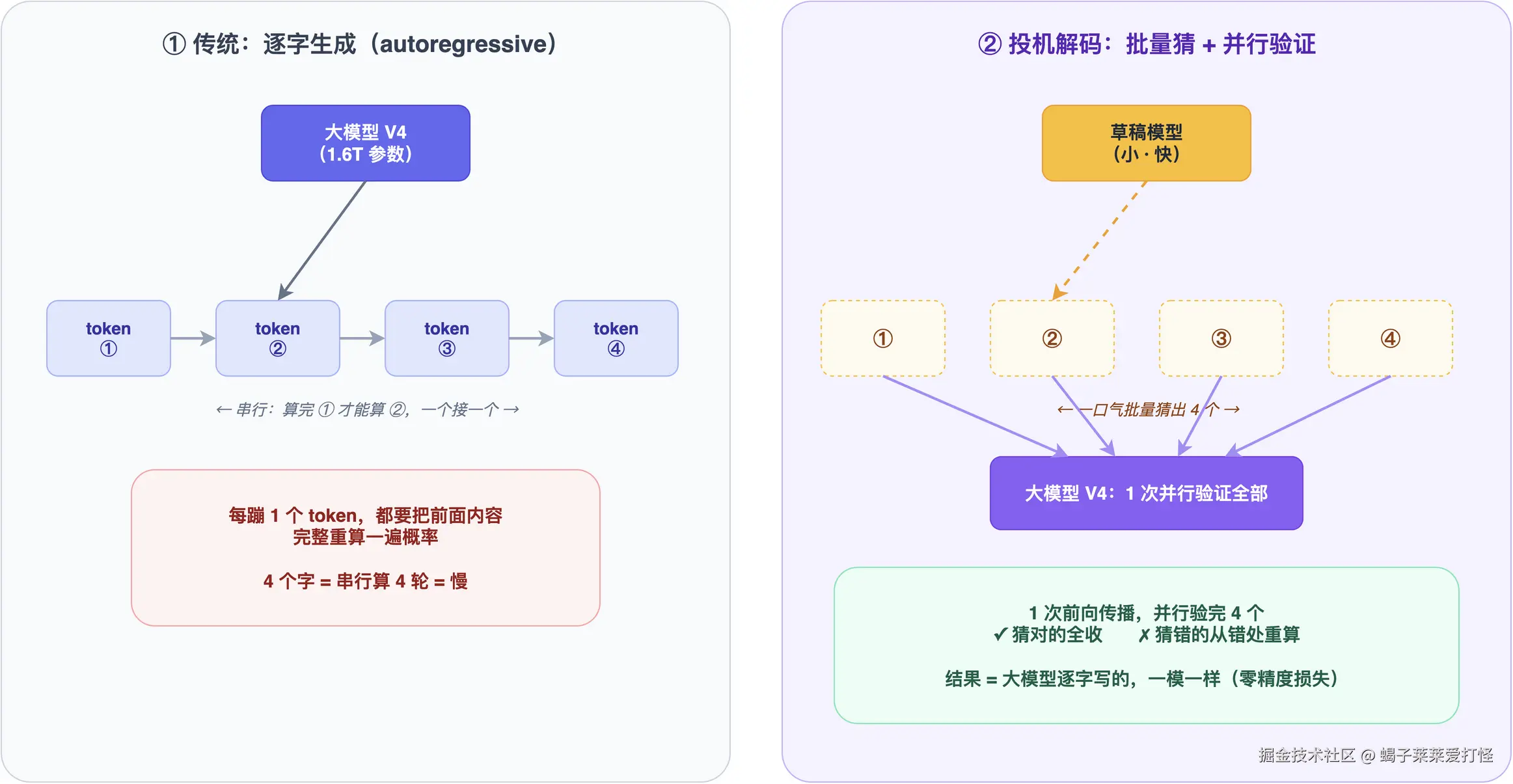
二、投机解码:让大模型从「一个字一个字蹦」变成「批发」
要懂 DSpark,先得懂它背后的核心技术------投机解码(Speculative Decoding)。
这词听着唬人,原理其实特朴素。
大模型本来是怎么吐字的?
你跟大模型聊天,它回你一段话。你看着是一句句往外冒,背后其实是一个字一个字蹦出来的(严格说是 token,大致等于一个词或半个汉字)。
每蹦一个字,它都要把前面的内容重新过一遍脑子,算一遍概率,挑出下一个最可能的字。一个一个来,串行的。
这就叫自回归生成(autoregressive)。慢,就慢在这------它是个十足的慢性子,蹦一个字,回一次头。
投机解码怎么破?
思路特别巧:别让大模型自己从头猜,先派个「小弟」去批量猜。
具体是这样:
- 先让一个又小又快的「草稿模型」,一口气猜出接下来好几个字(比如连猜 4 个)。
- 然后让真正的大模型,一次性把这 4 个字都验证一遍------猜对的全收下,猜错的,从错的地方开始重算。
你想想,关键在哪?在于验证这步是并行的。大模型本来要老老实实一个一个算 4 次,现在一次前向传播就把 4 个字都验完了。猜对的那部分,等于白捡的速度。
再打个比方,你立刻就懂:
主编自己写文章,得一个字一个字抠,慢,但准。 现在让实习生先哗哗哗打一份草稿,主编扫一眼,对的直接过,错的红笔一改。 最终稿的质量,还是主编的水平。但出稿速度,快了。
这就是投机解码的全部精髓。
这里还有个特别硬的数学保证:因为是大模型自己在做最终验证,所以它吐出来的内容,跟它老老实实一个字一个字写出来的一模一样。这就是「零精度损失」------不是「差不多」,是数学上能证明的完全等价。
说白了:投机解码是用「聪明地多算一点」,换「整体快很多」,结果一个字都不差。
那问题来了------既然这么好,为啥不早用?因为老办法有个解不开的死结。这个死结,恰恰就是 DSpark 要干掉的东西。
三、DSpark 的两把刀:又快又准,还能省
传统的投机解码,卡在一个两难上。
你想让草稿快,就得用并行 的方式一口气猜------但并行有个毛病,它只看得到局部,准头差,猜错的多,错了大模型还得推翻重来,白白浪费算力。
你想让草稿准,就得用串行 的方式一个一个认真猜------但串行慢啊,本来就是为了提速,结果草稿自己先拖了后腿。
**快的不准,准的不快。**这就是老式投机解码的死穴,猜错那部分的算力,全打了水漂。
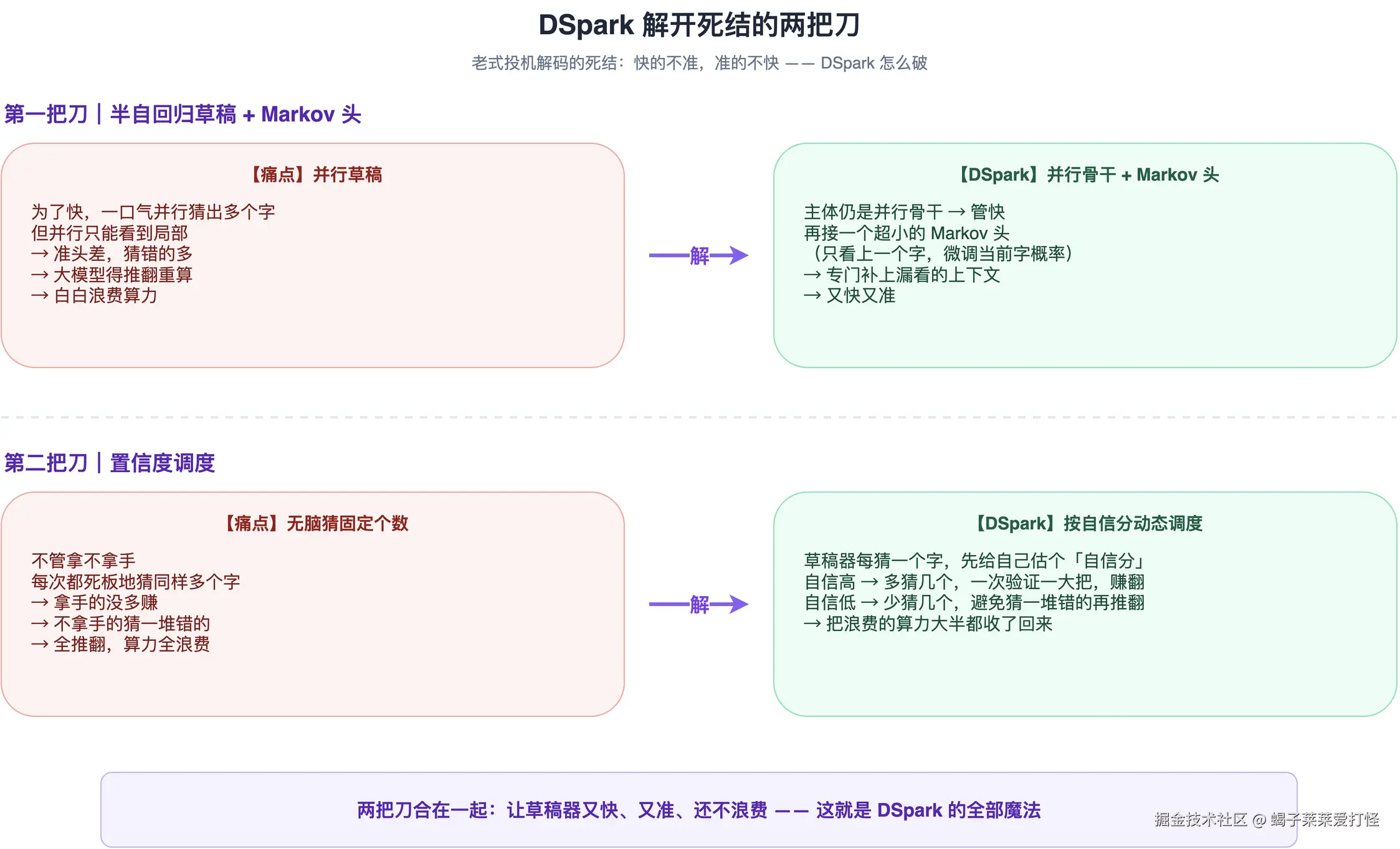
DSpark 上了两把刀,把这个结给解了。
第一把刀:半自回归草稿 + Markov 头
DSpark 的草稿器是个「混合体」:主体是一个并行的骨干,管快------一口气把好几个字猜出来。但并行容易看不全,怎么办?
它在骨干上接了一个超小的 Markov 头 。这个头很轻,只看上一个字,用它来微调当前字的概率。相当于给那个粗心的并行骨干配了个「纠错小助理」,专门补上它漏看的上下文。
又快又准,就是这么来的------主干负责速度,Markov 头负责补准。
第二把刀:置信度调度
这把刀更妙。
草稿器每次猜字,会给自己估一个「自信分」。DSpark 让它按这个分数,动态决定这次猜几个字:
- 拿手、高分的段落,多猜几个,一次验证一大把,赚翻;
- 没把握、容易错的地方,少猜几个,避免猜一堆错的再全推翻。
你别说,这招特别像高手做事------猜之前先掂量掂量自己,有把握的多来、没把握的少碰,而不是闷头平均用力。
老办法是「无脑猜固定个数」,猜错的算力全浪费。DSpark 这么一调度,浪费的算力大半都收了回来。
两把刀合在一起,就是 DSpark 的全部魔法:让草稿器又快、又准、还不浪费。
四、真金白银:到底快了多少,准不准
数据摆在这,都是 DeepSeek 官方论文里的,对标的是它自家之前的 MTP 方案(MTP 就是投机解码的早期版,一次只能预测一个字,DSpark 是它的升级进化):
- 单用户生成速度 :提升 60%~85%。你用 DeepSeek 聊天,它回你的速度,快了一大截。
- 吞吐量 :提升 51%~400%。这是服务器端的指标------同样一块显卡,能同时伺候的人多了好几倍。对高并发的 API 服务来说,这就是实打实的钱。
- 精度:零损失。前面讲过,数学保证输出和原模型分毫不差。
关于成本,我得说实话。Reddit 上有实测帖传「便宜 5 倍、7.6 倍」,这个数是社区测出来的,不是 DeepSeek 官方公布的,我先标清楚,别拿这个去吹翻了车。但方向是确定的:吞吐上去了,单次成本必然往下走,这是物理规律。
还有一点容易被误读:DSpark 不是 取代了之前的 MTP,它俩是互补的。MTP 是地基,DSpark 是在那地基上盖起的高楼。
一句话:模型一个字没换,速度翻着倍地涨,结果一点没变。

五、这事为什么值得你关注
数据看完了,你可能会想:快是快了,但跟我有啥关系?
关系大了。DSpark 本质上是个推理工程的活儿,它不碰模型能力本身,碰的是「怎么把同样的模型,更便宜地跑起来」。
你可能觉得这没那么性感------又没出新模型,又没破啥纪录。但你换个角度想:
**大模型的能力,正在快速趋同。**顶级那几家,模型层面的差距,越来越小。当模型本身拉不开身位的时候,下一个战场在哪?
在「谁把同样强的模型,跑得更便宜」。
我看到一句挺狠的话:**投机解码每快 2 倍,都是直接变成了利润率。**快一倍,你要么把价格砍一半去抢市场,要么把成本省一半闷声赚钱------比再卷 0.5 个 benchmark 分数实在多了。
而 DeepSeek 这次最狠的,不是技术------是姿态 。论文、代码库(DeepSpec,MIT 协议)、模型权重,全部开源 。顺手提一句,这个 DeepSpec 仓库里不止 DSpark,还有 DFlash 和业界经典的 Eagle3,是个通用的投机解码训练框架,连竞品的 Qwen3 都能拿来当目标模型练草稿器。开源开到这份上,是真想把桌子掀了大家一起玩。
对开发者:用 DeepSeek 的 API 会更便宜、更快;想自己部署的,代码和权重都现成。 对普通人:体感就是 DeepSeek 回答更快了,尤其那种长篇大论的生成,提速最明显。
系统是改出来的,不是设计出来的------DeepSeek 这回改的不是模型,是整个推理的打法。
AI 是放大器,不是替代品。DSpark 这种工程优化,放大的是 DeepSeek 那条「模型够强、还卖得够便宜」的路子------这条路,别人已经越来越难追。往后大模型这局,拼的可能不是谁的脑子更聪明,而是谁的脑子,跑得更便宜。
我是 蝎子莱莱爱打怪,全网同名,欢迎关注我的公众号/星球/稀土掘金/知乎