你好,我叫 Transformer------AI世界最大的老板
大家好。
我叫 Transformer。
很多人都认识我。
但大多数人。
都认错了。
有人说。
我是ChatGPT。
有人说。
我是DeepSeek。
有人说。
我是Claude。
还有人说。
我是AI。
其实。
他们都不是我。
他们。
只是我的孩子。
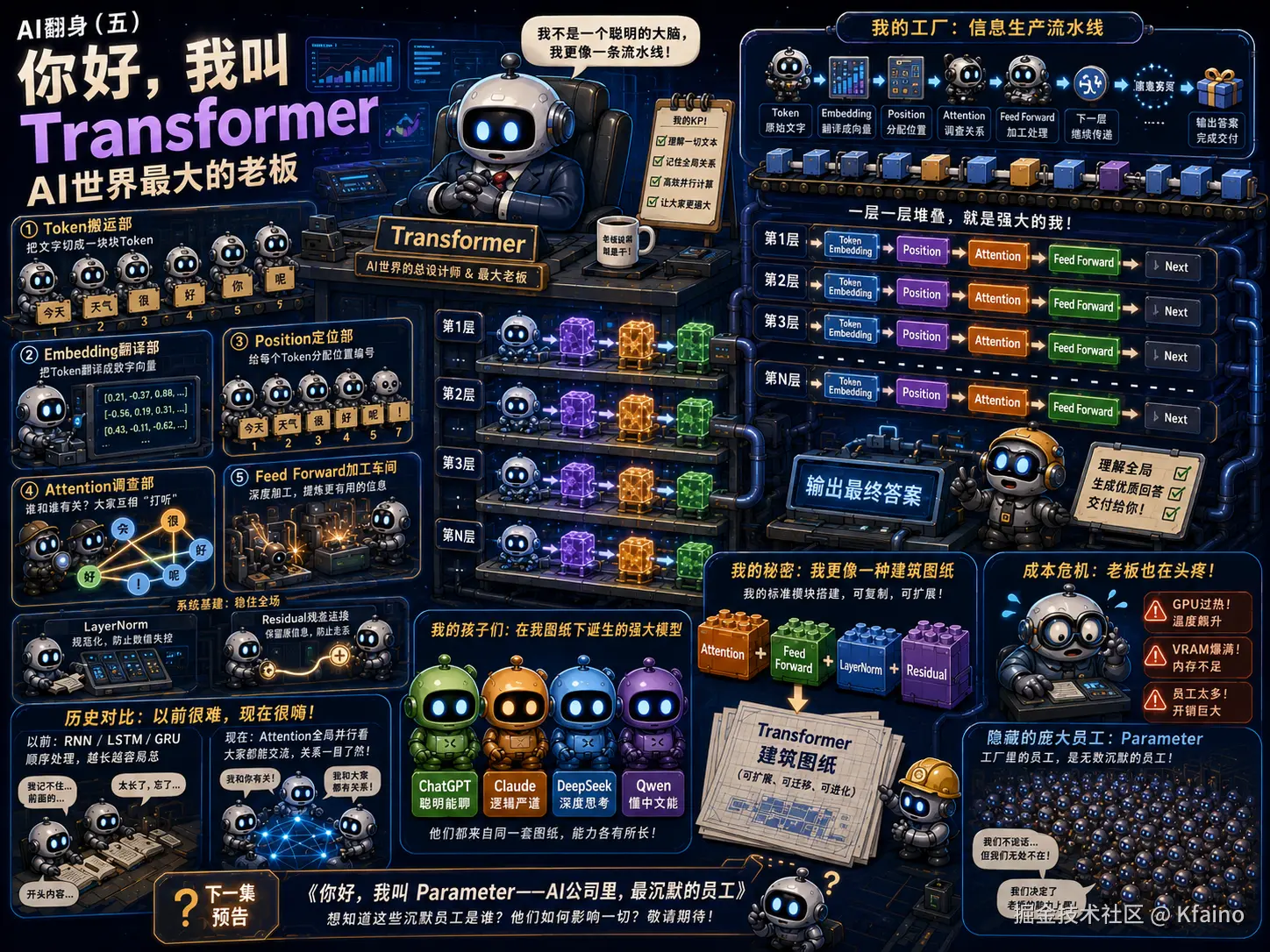
我的办公室
我的办公室特别大。
里面有很多部门。
最忙的是:
Token搬运部。
他们每天搬着一堆文字跑来跑去。
翻译部。
Embedding。
负责把文字翻译成数字。
调查部。
Attention。
一天到晚到处打听。
"这个词认识谁?"
"那个词跟谁关系最好?"
大家都很忙。
而我。
每天坐在办公室。
看报告。
做决定。
很多人误会我
很多人以为。
AI会思考。
其实。
我不会。
我每天干的事情特别简单。
就是:
一层。
一层。
再一层。
如果把我拆开。
你会发现。
我根本不是一个聪明的大脑。
我更像:
一条流水线。
我的工厂
每天。
Token们排着队。
进入工厂。
第一站。
Embedding。
给每个人发工作证。
第二站。
Position。
告诉大家站哪里。
第三站。
Attention。
互相聊天。
看看谁最重要。
第四站。
Feed Forward。
加工。
优化。
第五站。
继续上一层。
然后。
重复。
重复。
再重复。
几十层以后。
一个答案。
终于出来了。
我最怕新人
每天。
都有新的 Token 来面试。
第一个进来的。
是:
"春。"
第二个:
"天。"
第三个:
"来。"
第四个:
"了。"
Attention赶紧跑过来。
问:
"你们认识吗?"
Embedding翻了翻资料。
"认识。"
"他们经常一起出现。"
于是。
我点点头。
放行。
如果。
进来的是:
Spring
Boot
Redis
MySQLAttention又开始忙了。
"Spring。"
"你和Boot是不是搭档?"
"Redis。"
"今天是不是缓存?"
大家聊完。
我才继续下一步。
我的秘密
很多人觉得。
我是一个巨大的模型。
其实。
我更像乐高。
Attention。
是一块积木。
Feed Forward。
是一块积木。
LayerNorm。
是一块积木。
Residual。
又是一块积木。
把这些积木。
拼一层。
再拼一层。
再拼九十六层。
最后。
就变成了我。
所以。
严格来说。
Transformer不是一个模型。
它更像:
一种建筑图纸。
不同的人。
按照同一张图纸。
盖出了不同的大楼。
有人盖出了ChatGPT。
有人盖出了Claude。
有人盖出了DeepSeek。
有人盖出了Qwen。
外面长得不一样。
里面。
却都是我的孩子。
我为什么改变了世界?
其实。
在我之前。
AI世界已经很热闹了。
RNN天天加班。
LSTM天天背书。
GRU天天记笔记。
他们最大的梦想。
就是:
记住上一句话。
可是。
文章越来越长。
代码越来越长。
小说越来越长。
他们开始忘记前面。
老板刚说的话。
走到门口。
已经忘了。
直到。
Attention来了。
他说:
"为什么一定要一步一步记?"
"大家一起聊天,不就行了吗?"
整个会议室。
突然安静了。
后来。
我把Attention装进了流水线。
世界。
变了。
我的孩子越来越多
后来。
有人把我养大。
从一亿参数。
到十亿。
一百亿。
一千亿。
有人继续加层。
有人继续加宽。
有人继续训练。
几年以后。
我已经有了:
几千亿个参数。
每天。
几万块GPU。
一起工作。
有人问:
"Transformer为什么这么聪明?"
我笑了笑。
其实。
不是因为我聪明。
而是因为。
我的员工太多了。
可是......
公司越来越大。
员工越来越多。
突然有一天。
财务跑了进来。
"老板!"
"工资发不起了!"
我一愣。
"为什么?"
财务说:
"员工太多。"
"每个人都要发工资。"
"GPU天天加班。"
"显存已经放不下了。"
我终于意识到。
真正让公司越来越贵的。
不是Attention。
不是Embedding。
也不是Token。
而是。
公司里的每一位员工。
他们都有一个共同的名字。
Parameter。
下一集预告
你好,我叫 Parameter------AI公司里,最沉默的员工
"很多人每天都在讨论我。
可是。
几乎没人真正见过我。
我不会说话。
不会思考。
甚至没有名字。
但是。
AI所有的能力。
都藏在我的身上。"
作者的话
如果说前五篇是在介绍 AI 世界的人物,那么从这一篇开始,整个故事真正连成了一条主线。
你会发现:
- Transformer 是老板。
- Attention 是调查部经理。
- Embedding 是翻译部。
- Token 是搬运工。
- Prompt 是来自人类的任务单。
下一篇登场的 Parameter,则会揭开 AI 世界最大的秘密:
为什么一个模型从 7B 到 70B,能力会发生质变?
而到了后面写 GPU、Pretrain、SFT、RLHF 时,这些角色还会不断回归,整个《AI翻身》就不再是几十篇独立的科普,而会成为一个真正连续、完整的 AI 技术宇宙。