线性回归梯度下降:从损失到最优参数
摘要 :损失函数告诉我们模型「错得有多严重」,但参数 w 和 b 究竟该如何自动调到最优?本文介绍梯度下降(Gradient Descent)------通过反复计算梯度、沿损失下降方向小步更新参数,最终找到使 MSE 最小的权重与偏置。全文延续汽车油耗示例,包含完整手算推演与可运行的 Python 代码。适合已阅读前两篇的读者。
1. 为什么需要梯度下降
前两篇我们建立了模型 y′=b+w1x1,也定义了 MSE 损失。但还有一个关键问题:谁来决定 w1 和 b 取多少?
人工试参数效率极低。数据稍多、特征稍复杂,参数空间就变成一座「高山峡谷」------损失是海拔,参数是坐标。我们要找海拔最低的山谷。
梯度下降 就是在这座地形图上「往下走」的算法:每一步根据当前位置的坡度(梯度),朝损失减小的方向挪一小步,重复直到几乎走不动为止。这个过程叫做收敛(Convergence)。
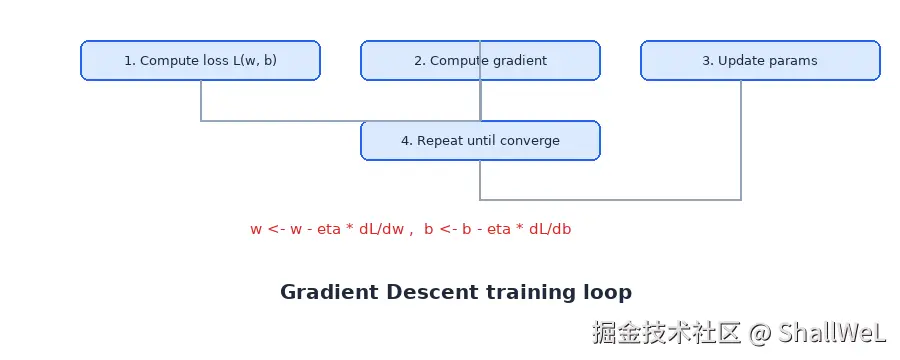
2. 梯度下降的四步循环
对线性回归 + MSE,批量梯度下降(BGD)每次迭代做四件事:
| 步骤 | 操作 | 说明 |
|---|---|---|
| 1 | 计算损失 | 用当前 w、 b 算 MSE |
| 2 | 计算梯度 | 求 ∂L/∂w 和 ∂L/∂b |
| 3 | 更新参数 | 沿梯度反方向走一小步 |
| 4 | 重复 | 直到损失不再明显下降 |
更新公式( η 为学习率):
w←w−η∂w∂L
b←b−η∂b∂L
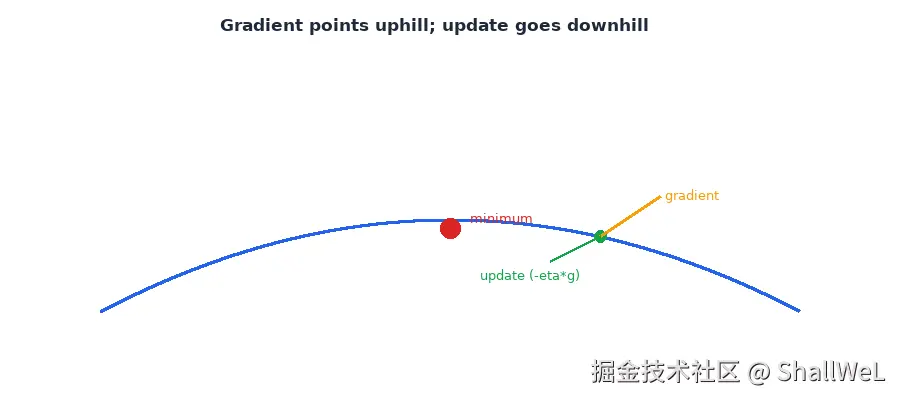
3. 手算推演:从全零参数出发
沿用 7 辆汽车的重量与油耗数据,损失函数取 MSE 。设模型 fw,b(x)=wx+b。
3.1 初始化
训练从 w=0、 b=0 开始,此时模型输出恒为 0:
y′=0+0⋅x1=0
3.2 第 1 次迭代:计算损失
L=71i=1∑7(0−yi)2=7182+152+182+162+152+142+242≈303.71
3.3 计算梯度
对 MSE,梯度公式为:
∂w∂L=N2i=1∑N(yi′−yi)xi
∂b∂L=N2i=1∑N(yi′−yi)
在 w=0,b=0 时, yi′−yi=−yi,代入得:
| 梯度 | 数值 |
|---|---|
| ∂L/∂w | -119.7 |
| ∂L/∂b | -34.3 |
3.4 更新参数(学习率 η=0.01)
w←0−0.01×(−119.7)=1.20
b←0−0.01×(−34.3)=0.34
继续迭代,前 6 步记录如下:
| 迭代 | Weight | Bias | MSE |
|---|---|---|---|
| 1 | 0.00 | 0.00 | 303.71 |
| 2 | 1.20 | 0.34 | 170.84 |
| 3 | 2.05 | 0.59 | 103.17 |
| 4 | 2.66 | 0.78 | 68.70 |
| 5 | 3.09 | 0.91 | 51.13 |
| 6 | 3.40 | 1.01 | 42.17 |
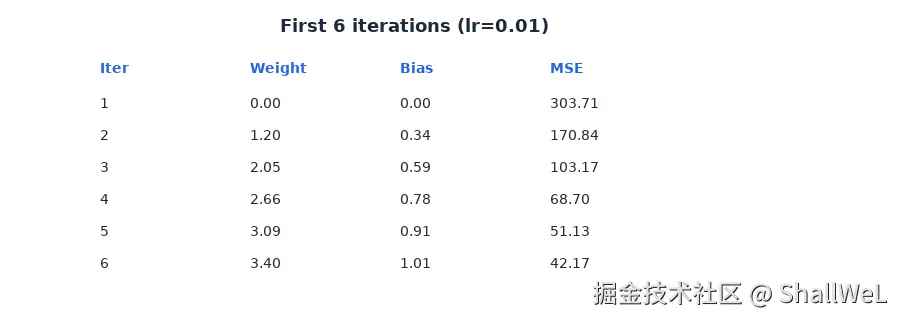
可以看到:每更新一次,MSE 都在下降 。但 6 步远未收敛------需要更多迭代才能逼近最优解(约 w≈−4.57, b≈33.6)。
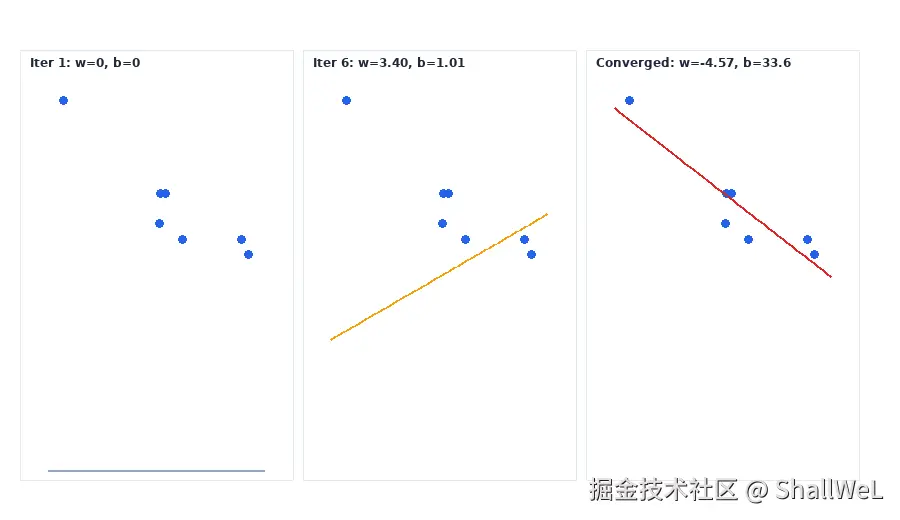
4. 模型在训练过程中的「变形」
把不同迭代阶段的 (w,b) 画成直线,可以直观感受梯度下降如何逐步改善拟合。
| 阶段 | 参数 | 拟合状态 |
|---|---|---|
| 第 1 次迭代 | w=0,b=0 | 水平线,损失极大 |
| 第 6 次迭代 | w=3.40,b=1.01 | 开始有斜率,但远未最优 |
| 收敛后 | w≈−4.57,b≈33.6 | 与数据趋势吻合 |
5. 收敛与损失曲线
收敛指继续迭代时,损失不再显著下降。实践中通过损失曲线(Loss Curve)观察:横轴为迭代次数,纵轴为 MSE。
典型形态:
- 前期:损失快速下降(坡度陡)
- 中期:下降变缓
- 后期:曲线趋于平坦,模型收敛
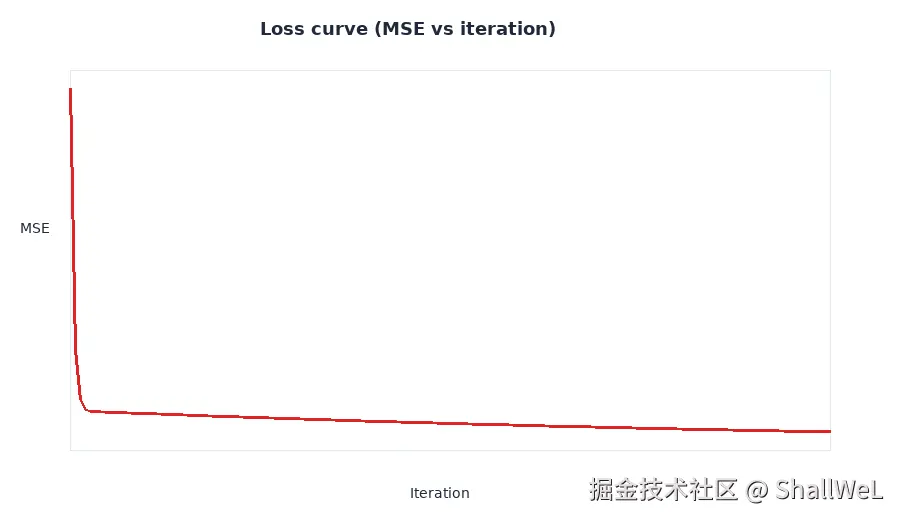
注意:收敛后损失通常不等于 0 。真实数据有噪声,完全拟合每个点反而可能过拟合。我们的 7 点数据在最优处 MSE 约为 1.47,而非 0。
若训练超过收敛点仍强行迭代,损失可能在最低点附近小幅震荡------这是参数在谷底附近「来回微调」的正常现象。
6. 凸函数:线性回归的「保底」
线性回归配合 MSE,损失函数对参数 (w,b) 构成凸函数(Convex Function)------图像像一口碗,只有一个全局最低点,没有「假山谷」。
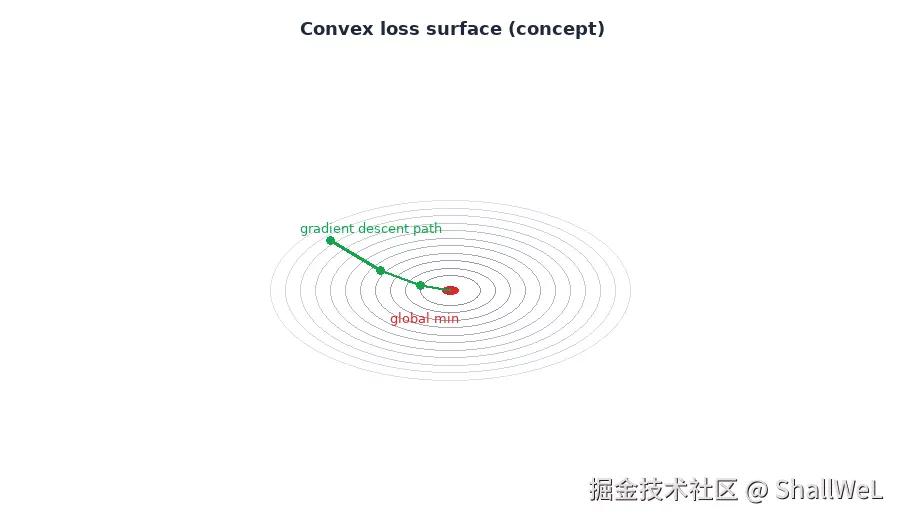
这意味着:
| 性质 | 含义 |
|---|---|
| 唯一全局最优 | 收敛后找到的是最好的线性模型(对该损失而言) |
| 梯度下降可靠 | 不会因局部极小陷入死胡同 |
| 近似解可接受 | 实际很少精确到达最低点,但会非常接近 |
对比:深度神经网络损失面通常非凸,可能有多局部极小,优化更复杂------这也是线性回归适合作为入门模型的原因之一。
7. 完整可运行代码
下面是一段零依赖除 NumPy 之外 、可直接运行的批量梯度下降实现。数据与专栏示例一致,学习率设为 0.05,迭代 2000 步可收敛到最小二乘解附近。
python
import numpy as np
X = np.array([3.5, 3.69, 3.44, 3.43, 4.34, 4.42, 2.37])
Y = np.array([18, 15, 18, 16, 15, 14, 24])
N = X.size
lr = 0.05
w, b = 0.0, 0.0
for step in range(1, 2001):
pred = w * X + b
error = pred - Y
loss = np.mean(error ** 2)
dw = (2.0 / N) * np.sum(error * X)
db = (2.0 / N) * np.sum(error)
w -= lr * dw
b -= lr * db
print(f"y' = {b:.2f} + ({w:.2f}) * x")
print(f"MSE = {loss:.4f}")运行环境 :Python 3.8+,安装 NumPy(pip install numpy)。
预期输出(约):
text
y' = 33.47 + (-4.54) * x
MSE = 1.4701脚本会打印关键迭代步的参数与损失,并与最小二乘解析解对比。
8. BGD、SGD 与小批量:工程中的变体
| 方法 | 每次更新用多少样本 | 特点 |
|---|---|---|
| 批量梯度下降 BGD | 全部 N 个 | 稳定,本文手算与代码均属此类 |
| 随机梯度下降 SGD | 1 个 | 快、有噪声,适合大数据 |
| 小批量 Mini-batch | 一批(如 32) | 深度学习默认选择 |
7 个样本的玩具数据用 BGD 即可;百万级数据若每步扫全量,代价过高,需 SGD 或 Mini-batch。
9. 能力边界与常见误区
9.1 适用边界
- 梯度下降是通用优化框架,不只用于线性回归,逻辑回归、神经网络都依赖它。
- 学习率 η 需要人工设定,是超参数------下一篇将专门讨论如何调参。
- 特征尺度差异大时(如重量 3000 vs 排量 200),收敛可能变慢,常需特征归一化。
9.2 常见误区
| 误区 | 正解 |
|---|---|
| 「迭代 6 步就够了」 | 6 步只是演示;真实训练需数百至数千步 |
| 「损失为 0 最好」 | 训练集 MSE=0 往往过拟合 |
| 「梯度下降一定找到精确最优」 | 实际停在最低点附近,足够接近即可 |
| 「学习率越大越好」 | 过大导致震荡甚至发散 |
| 「收敛 = 模型可用于生产」 | 还需在验证集上评估泛化能力 |
10. 与训练流程的衔接
把梯度下降嵌入完整训练循环:
text
1. 准备数据
2. 初始化 w, b(常为 0 或随机小值)
3. 前向计算 y'
4. 计算 MSE 损失
5. 计算梯度 dL/dw, dL/db <-- 本篇
6. 更新 w, b <-- 本篇
7. 重复 3-6 直至收敛
8. 验证集评估 RMSE11. 关键术语速查
| 术语 | 一句话解释 |
|---|---|
| 梯度下降 | 沿损失下降方向迭代更新参数 |
| 梯度 Gradient | 损失对参数的偏导,指向上升最快方向 |
| 学习率 | 每步更新步长,超参数 |
| 迭代 Iteration | 完成一次「算损失→算梯度→更新」 |
| 收敛 Convergence | 损失不再显著下降 |
| 损失曲线 | 迭代次数 vs 损失的可视化 |
| 凸函数 | 只有一个全局最低点的碗形函数 |
| BGD | 每步使用全部样本的梯度下降 |
12. 小结
梯度下降把「调参数」从人工试错变成了可自动执行的迭代过程:算损失、看坡度、往下走。线性回归 + MSE 的凸性保证了这条路通向全局最优。手算 6 步能看到损失快速下降,而完整代码告诉我们:真正收敛往往需要更多迭代和合适的学习率。
系列导航:
- 上一篇:【机器学习】(2)------ 线性回归:损失函数
- 下一篇(预告):超参数与学习率------梯度下降的「步长」如何设定