近日,AI行业关于Harness的探讨颇多,行业普遍认为:现在是通过Harness来做大模型创新应用的好时机,但是Harness和以往的应用开发范式有较大不同,需要用一些不同的方法,才能做出好的产品,沿用原有的思维方式可能事倍功半。
本文《Harness即产品》,是网易有道CEO周枫从行业分享和内部实战中总结的一些最佳实践,供大家参考。 (首发自 @周枫 微信公众号)
先界定一下概念。所谓Harness(马具/载体),指的是模型之外、把模型包装成一个可用产品的那一整层工程:上下文管理、工具、记忆、持久化状态、评测、循环控制、可观测性与权限治理。
一个标准的说法是Agent = Model + Harness:模型负责"思考",Harness负责让这份思考变得可理解、可协作、可复现、可长期运行。长程Agent对Harness的依赖,超过它对任何单个模型的依赖。更强的模型并不会自动变成更可靠的Agent服务。简单来说,对于一个复杂的Agent,模型也许只完成20%的工作,剩下80%、让产品持续可靠工作的基础,是Harness。1
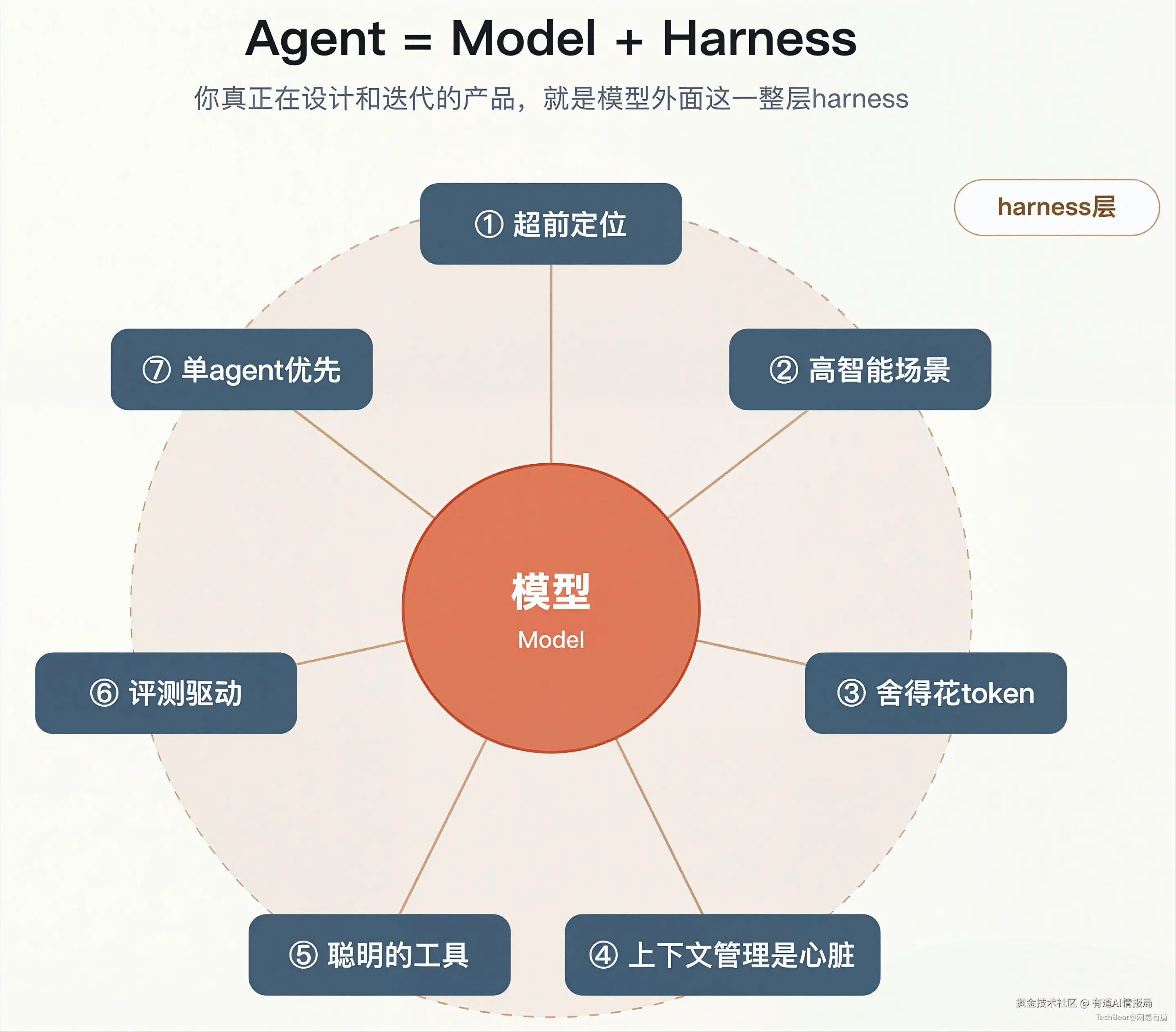
这正是标题"Harness即产品"的含义:在大模型应用里,团队真正在设计和迭代的产品,往往不是一个个具体的功能,而是这一整层Harness本身。
下面七点,是我看到的构建一个好的基于Harness产品的要点。
1. 面向下一代模型能力设计产品
很多团队一开始就犯一个错误:围着模型今天的能力优化和打磨,试图让功能更准、更快、更便宜,结果产品上线没多久就被新模型直接替换。
解决这一问题的一个办法,是做一定的超前定位:产品路线图不该只问模型今天能不能做,更要问"半年后如果模型在规划、工具使用和长上下文上再上一个台阶,我们如何抓住红利"。
工程上,可以先用强模型跑出效果,再逐步尝试小模型替换;业务上,则优先选择会随着模型智能提升而不断放大价值的场景,比如复杂决策场景、需要深度思考的功能、跨系统调度,或者需要深入专业知识的产品。
Claude Code负责人Boris Cherny在Lenny's Podcast的访谈里把这件事讲得很清楚:Claude Code一开始只是个小尝试,团队是在"赌模型半年后的能力"------他们刻意按"模型将会变成什么样"、而不是"模型现在能做什么"来设计产品。
当时他的判断是,模型独立编程的能力正在快速上升,交互方式因此必须从以人为主的自动补全(auto-complete)转向以Agent为主:"模型能做到很多还没有产品接住的事...... 我们其实不必再做type-ahead了,可以直接让Agent把所有代码都写出来。"这个赌注在2025年5月Opus 4发布时兑现,产品随之取得巨大成功。
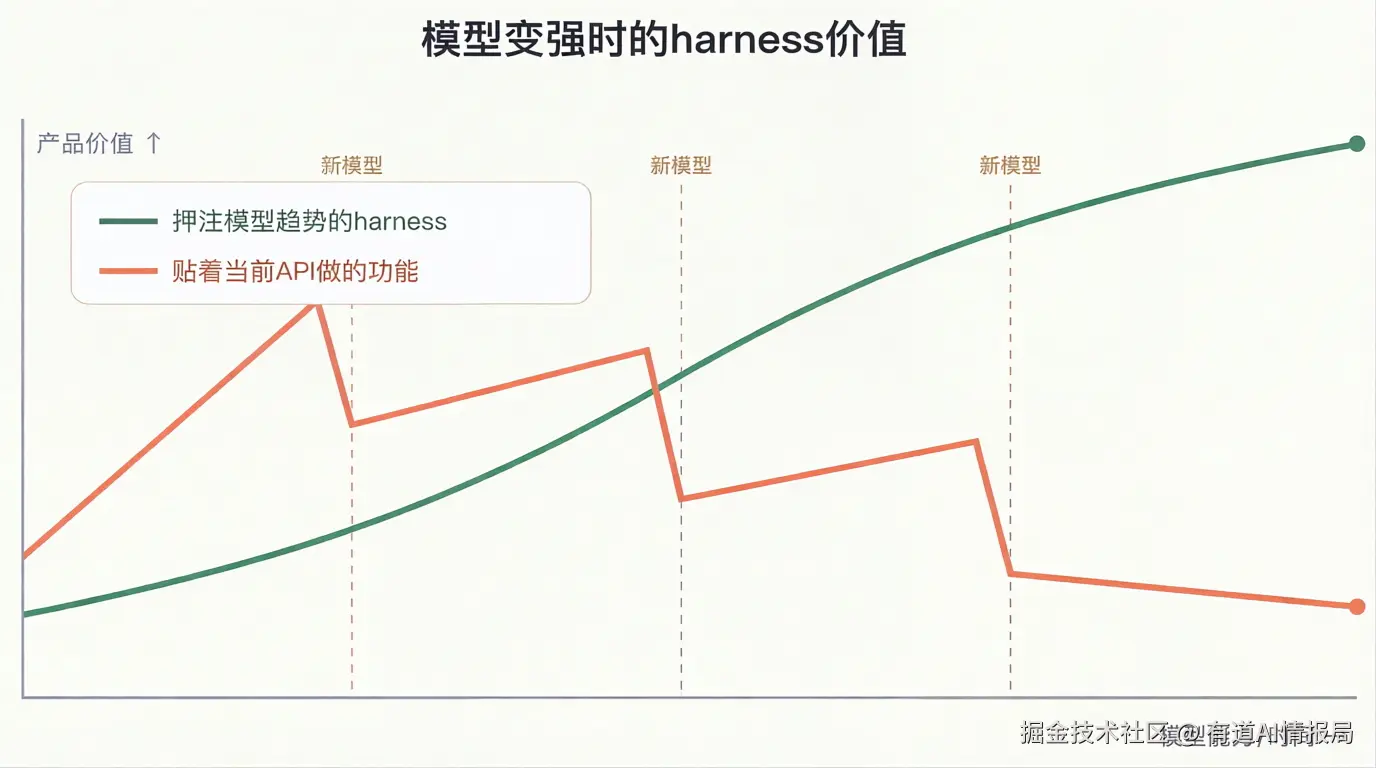
他给出的两条产品原则也值得思考:"别试图把模型框死"(少用僵硬的编排,多给工具和目标让模型自己想),以及"押注更通用的模型"------在模型一夜之间就能改变能力边界的领域里,能随模型一起变强的灵活方案,往往胜过为当下定制的脚手架。
2. 要做高智能产品
不是所有AI功能都值得投入。
一个简单的判断标准是:如果这个问题主要靠规则、搜索和模板就能解决,那它未必值得产品化;如果它依赖模糊判断、跨文档理解、多步骤推理和人与系统之间的复杂协作,那它才更适合为之开发大模型产品。
一个考虑的角度,是"类比一个需要资深员工处理的复杂任务切片"。如果你是产品负责人,最应该优先筛选的场景,不是流量最大,而是单次任务价值最高、判断复杂度最高、人工成本最贵的那些。这类场景虽然起步看起来更难,但一旦做通,用户会把它当真正的生产力工具,而不是新鲜一下的演示玩具。
换个角度说,任务切片越难、价值越高,模型单独能交付的比例就越低,当然最终能不能稳定上线,恰恰取决于Harness建得好不好,对模型能力的判断是否正确,但总的来说,把注意力集中在高智能产品方向上,是成功可能性更大的。
3. 有价值的Agent产品,往往消耗较多tokens
很多团队的第一直觉是"把token用量压到最低",但对真正困难的任务来说,这往往是一上来就设定错了优化目标。对于高价值场景来说,token消耗是创造价值的,因此在一定范围内是越多越好。所以这类场景里,正确的默认态度是舍得花------和上一点呼应,单次任务价值越高、判断越复杂,越不该在token上抠门。一个Agent任务跑下来,累计输入token在数十万到数百万之间,都是比较正常的。
因此Harness的一个重要任务,是让token的花费具有经济上的可核算性------能够统计和优化token的消耗,使得该花的地方花充分,不该花的地方足够节省。这个和公司的增长团队一定要量化计算ROI一样,是团队一个必要的基本功。
这里有一些重要的杠杆: 一是提示词的缓存,是团队要关注和优化的要点;二是分层与路由------用强模型跑出比较好的效果后,把简单节点下放给小模型;也可以用批处理(batch)的方式跑可异步的批量任务、必要时做上下文重置来进一步节省开销。注意,这些手段省的是无谓的浪费,在高价值环节应该放开手脚,放心大胆地花。
4. 把上下文工程当成主任务
上下文工程(context engineering),目的是让模型在某一时刻究竟知道什么、不知道什么、记住什么、遗忘什么,而不是写更长、更巧妙的提示词。如果说Harness有一个心脏,那就是上下文管理:前面几点,最终都要落到管理上下文内容这个动作上,而不是简单地使用不断积累对话上下文的默认规则。至少要把上下文拆成几层:系统规则、当前任务、检索知识、用户历史、长期偏好、工具结果。不同层应该有不同的优先级、生命周期和压缩方式(见下图)。Anthropic把上下文工程的目标概括成一句话:找到"能最大化达成目标的、最小的一组高信号token",因为上下文是一种边际收益递减的有限资源。3

关于上下文工程的好文章不少,比如这篇:Agent全面爆发!万字长文详解上下文工程。
5. 工具是给模型看的产品界面
Agent调不好工具,往往不是模型不聪明,而是工具设计得不对。
现在国内外主流模型的Agent能力都已经较强,在绝大多数场景下都有有效地驱动设计良好的工具集合来工作,所以在上下文工程之后,工具的设计是团队应该聚焦的点。对于不熟悉这个方法的团队,这需要一次观念升级:你不只是写一个API给自己的前端或服务端调用,而是在设计一个"模型可消费的能力单元"。如果工具过多、命名相似、参数含糊,模型就容易误选;如果返回结果冗长且噪音大,还会进一步污染上下文。
比较实用的做法是:先收敛工具数量,把高频业务动作做成少数几个高信号、强约束的工具;其次使用严格的schema和结构化输出,避免自由文本在节点之间传递错误指令;最后为关键工具写清"什么时候该用、什么时候不该用、调用成功与失败分别长什么样"。
Anthropic在工具使用文档里也强调,影响调用效果最重要的因素之一,就是工具描述本身。不少一线实践也指向同一组做法:工具一旦超过二十来个,模型就容易在相似工具间选错(比如把"订单查询"和"物流查询"搞混);同时避免"瑞士军刀式"的多功能工具,改用单一职责、强schema的小工具,并在真正调用前先做参数校验、把错误直接"回吐"给模型修正。
6. 用评测驱动开发
做Agent比较容易掉入的一个坑是做出"差不多"能工作的产品,然后碰到问题反复手工调整,但是按下葫芦浮起瓢,陷入打地鼠的困境。这个时候,团队缺乏的就是量化的评测办法。一个真正可上线的Agent,必须有细分任务级的、量化的评测体系。评测至少要覆盖四层:最终答案质量、工具调用正确率、流程完成率和安全样本通过率。更进一步来讲,还应该有边界样本、对抗样本和真实线上日志回灌。一定要把"凭感觉"换成"看数据"。
从实操角度,Anthropic的《Demystifying Evals for AI Agents》是目前最权威的Harness/Agent评测指南,同时也已经有多个开源的框架出现,大家可以选择参考和使用。4
7. 默认从单Agent开始
多Agent很容易让人兴奋,因为看上去更像"组织协作"。但很多有经验的团队都建议先把单Agent做到极致,只有当prompt逻辑过于复杂、工具集合拥挤、权限等级不同、任务目标天然分离时,再拆成多Agent。
原因很简单:多Agent会带来handoff、状态同步、权限分层、成本叠加和调试复杂度。拆对了,系统会更清晰;拆错了,只会让问题在更多节点里来回传递。真正值得拆的,是那些边界清楚且目标不同的角色,比如"分诊---执行---质检""检索---分析---操作"或者"客服---退款---物流"。2
这件事社区里有一场很有代表性的争论:Cognition(Devin背后的团队)写过《Don't Build Multi-Agents》,主张默认就用单Agent------多个Agent之间很难共享完整上下文、容易决策冲突,对"写"类的强一致性任务(比如写代码)尤其脆弱;而Anthropic在《How we built our multi-agent research system》里给出了反例:在"读"类的开放式研究任务上,主从式(orchestrator-worker)多智能体比单个Claude Opus 4高出90.2%,但代价是token消耗约为普通对话的15倍。两边其实指向同一条分界线------任务偏"读"还是偏"写"、能不能共享上下文,决定了该不该拆。
小结:你迭代的产品,就是Harness
把这七点连起来看,它们其实是同一个工程的七个侧面:超前定位定方向、高智能场景定取舍、舍得花token求价值、上下文管理是心脏、工具是手、评测是免疫系统、循环编排是骨架。
模型会一代代变强,而且只会越来越强------但更强的模型不会自动变成更可靠的Agent服务,从demo到完整产品的鸿沟,始终要靠Harness来填。
所以做大模型应用,真正在持续设计、打磨、积累壁垒的,是这一整层Harness。模型是可更换的引擎,Harness才是你自己造的车。
参考链接
1 Anthropic, Harness design for long-running application development.
2 OpenAI, A practical guide to building agents.