前面写过一篇 用 EdgeOne Makers 构建与托管 Agent:从 RAG 检索到智能助手,主要记录把薄荷输入法文档和 Rime 配置经验做成 oh-my-rime Agent 的过程。
有了上一次适配 oh-my-rime Agent 的经验,EdgeOne Makers 的 Agent 入口、SSE、工具调用、沙盒和部署流程基本都走过一遍了。这次,我想把重点换成:如何借助 WorkBuddy,把一个已有项目更快地扩展成可上线的 Agent。
这里我用的是 WorkBuddy。大家如果更习惯 CodeBuddy,也完全可以用 CodeBuddy 达成类似目标。
最终目标很明确:把 Homebrew CN 从一个国内镜像安装脚本,扩展成一个能处理 Homebrew 问答和排障的 homebrew-cn Agent。
部署地址已经放出来了:
- Homebrew CN: brew-cn.mintimate.cn/
这篇文章会按两个角色来展开:
- WorkBuddy:负责开发协作,把自然语言需求落到代码改动、目录组织、工具实现、测试验证和问题定位上,也可以配合 EdgeOne 相关 skills 辅助 Agent 制作和部署。
- EdgeOne Makers:负责部署和运行,把 Agent endpoint、SSE、会话、沙盒、环境变量和 Tracing 托起来。
Homebrew CN
Homebrew CN 其实是我做的一个 项目,方便国内用户在无法流程访问 GitHub 的时候,可以使用国内镜像源安装 Homebrew:
zsh
/bin/zsh -c "$(curl -fsSL https://brew-cn.mintimate.cn/install)"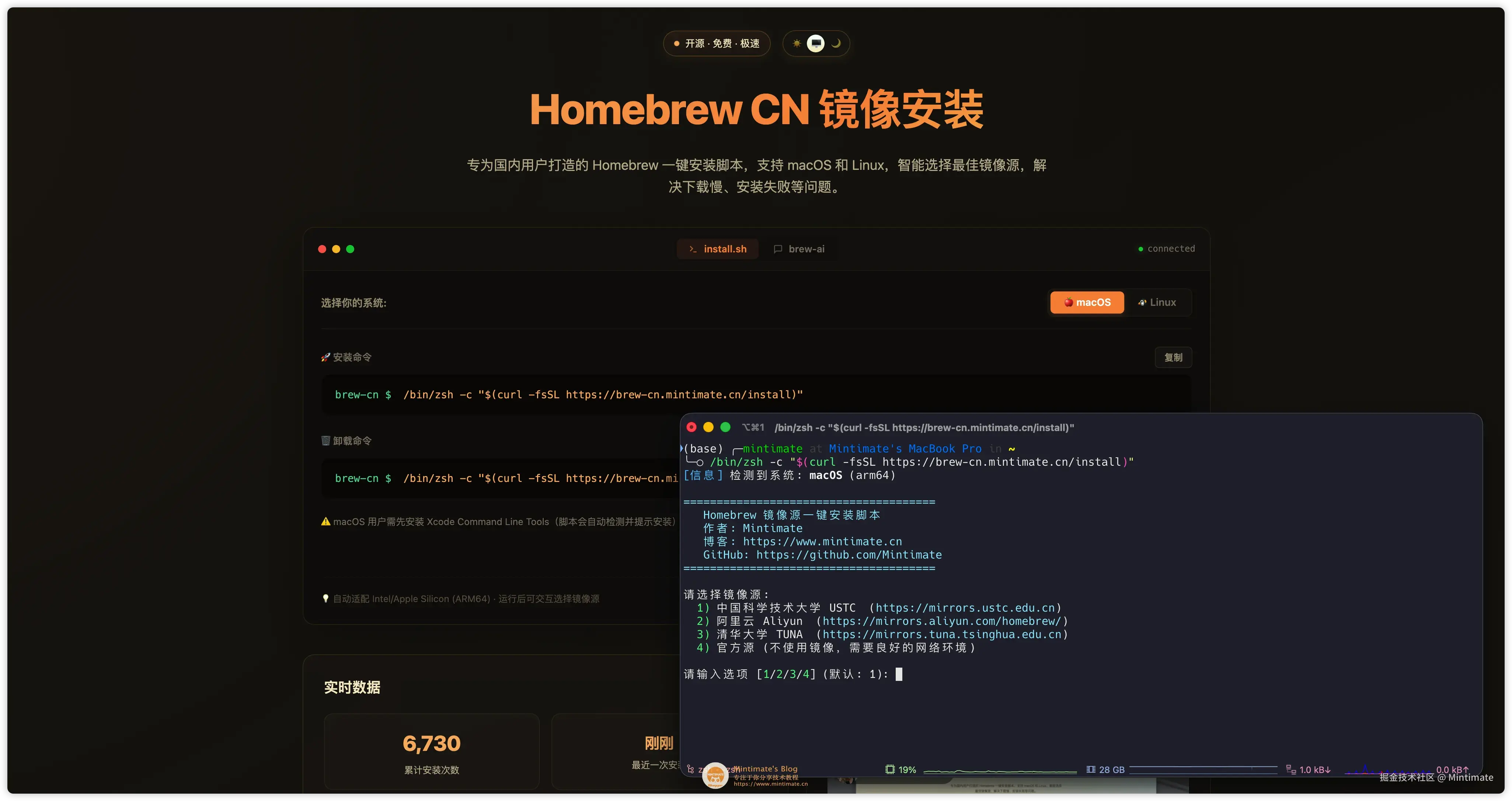
脚本层主要解决"如何安装"的确定性流程:
这些事情适合用脚本做,因为它们规则明确、步骤稳定,也不应该让模型临场发挥。
但是排障场景就不同了。用户可能只贴一小段终端输出:
text
zsh: command not found: brew也可能贴一堆混在一起的内容:
text
PATH=/usr/bin:/bin:/usr/sbin:/sbin
HOMEBREW_BOTTLE_DOMAIN=https://mirrors.ustc.edu.cn/homebrew-bottles
HOMEBREW_BOTTLE_DOMAIN=https://mirrors.aliyun.com/homebrew/homebrew-bottles
url.https://gh.llkk.cc/https://github.com/.insteadOf https://github.com/这种时候,用户真正需要的不是"Homebrew 是什么"的科普,而是一个能判断问题类型、分析上下文、必要时运行在线检测,并给出可审阅修复命令的助手。
所以现在 Homebrew CN 的整体形态变成了:
一条命令负责把 Homebrew 装起来;Agent 负责把安装前后的不确定问题接住。
引入 Agent
引入 Agent 的目的其实很简单:不是让它泛聊 Homebrew,而是把脚本之外的两个高频问题接住。
第一类是查包。比如用户问:
vscode 能不能用 brew 装?
这类问题不能只靠模型猜。Agent 需要通过 Tool Calling 调用工具,在沙盒里查询 Homebrew 官方接口,判断目标到底是 Formula 还是 Cask。像 VS Code 这种软件,正确命令应该是:
bash
brew install --cask visual-studio-code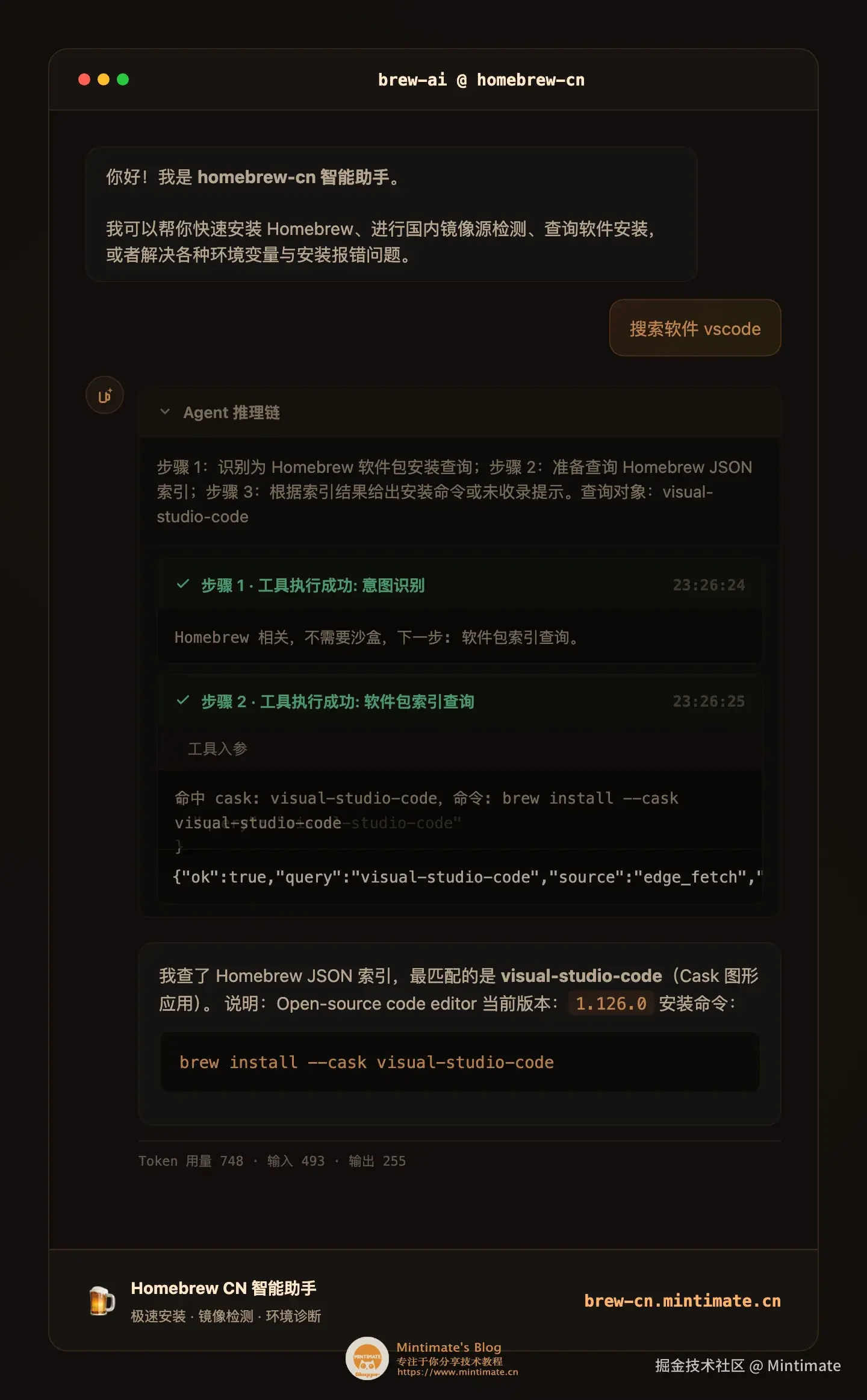
第二类是排障。比如用户问:
M4 Mac 安装后提示 command not found: brew,怎么办?
这类问题通常不是"Homebrew 不存在",而是环境变量、Shell 配置、脚本写入或终端上下文出了问题。Agent 要做的是先判断 /opt/homebrew、/usr/local、PATH、Zsh / Bash 配置和安装脚本输出,再给出可审阅的修复建议。
所以 homebrew-cn Agent 的目标就收敛成两件事:
- 查包 :用 Tool Calling 配合沙盒,查询 Homebrew 官方接口,判断软件包是否存在,以及应该用
brew install还是brew install --cask。 - 排障:判断 Homebrew 安装后常见问题,重点分析环境变量、Shell 配置、镜像源和脚本执行结果。
边界收窄以后,Agent 的回答会更稳:能用工具确认的就不靠猜,能从日志和环境变量判断的就不泛泛科普。
WorkBuddy 辅助开发
这次开发里,WorkBuddy 最有价值的地方不是"帮我写几段代码",而是它能把一个已经存在的项目读进去,然后沿着项目原有结构继续扩展。
Homebrew CN 不是从零开始的新仓库。它原本已经有:
install.sh:Homebrew 一键安装脚本。cloud-functions/:站点和安装脚本接口。assets/和前端模板:展示安装流程、统计和 FAQ。edgeone.json:EdgeOne Pages / Makers 的构建配置。README.md:安装说明和镜像源说明。
如果人工慢慢接 Agent,容易一边写一边把项目结构搞散。我的做法不是让 WorkBuddy 凭空设计一套 Agent 工程,而是先给它补齐上下文:
- 在 WorkBuddy 里安装 EdgeOne 相关 Skills,让它知道 Makers Agent 的项目约定、部署入口和验证方式。
- 让 WorkBuddy 先阅读现有
README.md、edgeone.json、install.sh和 Cloud Functions,确认 Homebrew CN 原本的站点结构不能被打散。 - 参考之前已经跑通的
oh-my-rime-agent项目,把它当成 EdgeOne Makers Agent 的实现样板。 - 基于 OpenAI Agents SDK 适配当前项目,在
agents/chat/下新增/chatendpoint,而不是把 Homebrew CN 改成纯 Agent 仓库。 - 把 Homebrew 领域工具、模型网关、SSE 输出和 Agent 行为规范分别落到独立文件里,让业务能力和平台适配保持清楚边界。
这个过程里,WorkBuddy 像一个熟悉仓库的结对开发者。EdgeOne Skills 负责补平台规范,oh-my-rime-agent 负责提供可对照的项目形态,OpenAI Agents SDK 则负责承接 Agent 运行时。这样一来,WorkBuddy 不是从零猜目录,而是沿着一个已经部署成功的样板,把 Homebrew CN 原有项目适配成 Makers Agent。
这里还有一个小技巧:如果目标本来就是部署到 EdgeOne Makers Agent,可以先让 WorkBuddy 安装并使用 EdgeOne 相关 Skills,再把已有的 Makers Agent 项目交给它参考。比如这次就可以让它对照 oh-my-rime-agent,检查 edgeone.json、agents/chat/index.ts、环境变量、SSE 输出和部署命令是否齐全。
我在这次实践里更关心几件事:
- Agent endpoint 是否按 Makers 约定放在
agents/chat/。 edgeone.json是否声明了agents.framework = "openai-agents-sdk"。openai和@openai/agents是否放进externalNodeModules。/chat是否通过 SSE 返回thinking、tool_call、tool_result、ai_response和usage。- 部署后是否能用
makers-conversation-id做 smoke test。
换句话说,WorkBuddy 负责把需求拆成代码任务;EdgeOne Skills 负责提醒 Makers Agent 的平台规范;oh-my-rime-agent 则提供一份已经验证过的参考实现。三者合在一起,比临时翻文档、手动对照配置轻松很多。
实际开发里,WorkBuddy 主要帮我完成了几类工作。
| 工作 | WorkBuddy 发挥的作用 |
|---|---|
| 仓库理解 | 先读 Homebrew CN 现有结构,避免破坏安装脚本和 Cloud Functions |
| Agent 入口 | 按 Makers 约定生成 agents/chat/index.ts,处理请求、会话、SSE 和路由 |
| 工具设计 | 把镜像源检测、Formula/Cask 查询、日志分析和修复命令拆成确定性工具 |
| EdgeOne skills | 辅助检查 Makers Agent 项目结构、环境变量、部署命令和 smoke test |
| Skill 管理 | 把 Agent 行为规范沉淀到 skills/homebrew-cn-agent/,再生成 _skill.ts |
| 调试排障 | 发现 EdgeOne 后台 Token 不显示后,继续追到 ModelGate 的流式 usage 适配 |
| 验证闭环 | 用 npm run build、类型检查和部署后 /chat smoke test 确认链路可用 |
在当下 AI 时代,可以探索这样的开发方式:人负责判断产品边界和工程取舍,WorkBuddy 负责快速把这些判断落到代码里;遇到异常时,再让它沿着调用链继续读代码、找差异、补测试。整个过程很省心,尤其是在已有项目里补一个 Agent 能力时,它可以把"读仓库、对照样板、改代码、补验证"这些琐碎步骤串起来。
当然,方便不等于可以完全放手。已有项目里真正麻烦的部分,往往不是写第一版代码,而是理解原项目的边界:哪些文件不能动,哪些能力应该复用,哪些逻辑应该工具化,哪些配置应该放环境变量,哪些输出要符合平台规范。WorkBuddy 在这类上下文协作里会很顺手,但最后的代码 diff、环境变量、部署配置和 smoke test 结果,仍然需要人工校验一遍。
EdgeOne Makers
代码由 WorkBuddy 协助搭起来以后,EdgeOne Makers 就负责托管和运行。
这次仍然选择 EdgeOne Makers,主要原因和上一篇 oh-my-rime Agent 类似:它把轻量 Agent 上线需要的运行时、环境变量、会话、SSE、沙盒和 Tracing 都放在一个项目形态里了。
Homebrew CN 的仓库不是一个单独的 Agent 项目,而是把静态站点、Cloud Functions、安装脚本和 Agent endpoint 放在一起:
text
.
├── agents/
│ ├── chat/
│ │ ├── index.ts # Agent 入口、SSE、会话、意图路由
│ │ ├── _tools.ts # Homebrew 领域工具
│ │ ├── _prompt.ts # Prompt 拼装与高频场景指导
│ │ └── _skill.ts # 由 skill 文档同步生成
│ ├── _model.ts # OpenAI 兼容模型网关封装
│ └── _shared.ts # SSE / JSON / 日志工具
├── cloud-functions/
│ ├── index.js # 站点入口
│ ├── install.js # 在线安装脚本接口
│ └── api/
├── skills/
│ └── homebrew-cn-agent/
│ ├── SKILL.md
│ └── references/
├── install.sh # Homebrew CN 安装脚本
├── build.sh # 构建安装脚本与同步 skill
├── edgeone.json
└── package.jsonedgeone.json 里声明了 Agent 框架:
json
{
"buildCommand": "npm run build",
"agents": {
"framework": "openai-agents-sdk",
"externalNodeModules": ["openai", "@openai/agents"]
}
}部署时也很直接:
bash
edgeone makers deploy -n homebrew-cn -t '<EDGEONE_MAKERS_TOKEN>'当然,你也可以直接用 Workbuddy 部署:
!EdgeOne Makers 部署(imagehost.mintimate.cn/post_workbu...
构建阶段会先把 skills/homebrew-cn-agent/ 里的行为规范同步成运行时可打包的 _skill.ts:
bash
npm run sync:agent-skill
npm run build这样做的好处是:Agent 的"领域规则"不散落在代码注释和 Prompt 字符串里,而是维护在 skill 文档里。比如意图路由、brew 找不到的排查流程、镜像源检测摘要规则、Formula/Cask 查询格式,都可以分文件维护。
模型网关、模型名称、Referer、标题等配置也都不写死在代码里,而是通过环境变量注入:
text
AI_GATEWAY_API_KEY
AI_GATEWAY_BASE_URL
AI_GATEWAY_MODEL
AI_GATEWAY_ENABLE_THINKING
AI_GATEWAY_HTTP_REFERER
AI_GATEWAY_TITLE项目默认使用 OpenAI 兼容接口和 OpenAI Agents SDK。也就是说,只要模型网关能提供兼容的 Chat Completions 能力,就可以接入到 Agent 编排里。
Agent Skill
这次 Homebrew CN 里还有一个我觉得值得单独拿出来说的点:Agent 的行为规范不是只写在 TypeScript 里,而是以 skills/homebrew-cn-agent/ 作为维护入口。
目录结构大概是这样:
text
skills/homebrew-cn-agent/
├── SKILL.md
└── references/
├── intent-routing.md
├── troubleshooting-brew-missing.md
├── mirror-diagnostics.md
├── formula-check.md
└── restore-official.md其中 SKILL.md 定义 Agent 的整体边界:
- 主要使用用户语言回答。
- 只处理 Homebrew、homebrew-cn 脚本、镜像源、软件包安装查询和本地环境配置。
- 遇到非 Homebrew 问题时明确拒绝。
- 终端命令要说明目的,持久化修改前提醒备份 Shell 配置。
- 工具调用要真实可用,不伪造工具结果。
references/ 则把高频场景拆开维护。比如:
| 文件 | 作用 |
|---|---|
intent-routing.md |
定义意图分类 route 和判断规则 |
troubleshooting-brew-missing.md |
定义 brew 找不到、PATH 和架构路径排查流程 |
mirror-diagnostics.md |
定义镜像源检测目标、字段和摘要规则 |
formula-check.md |
定义 Formula/Cask 查询和回答格式 |
restore-official.md |
定义恢复官方源的命令和提醒 |
构建前会运行:
bash
npm run sync:agent-skill它实际执行的是 scripts/sync-homebrew-cn-agent-skill.mjs。这个脚本会读取 SKILL.md 和上述 reference 文件,然后生成 agents/chat/_skill.ts。
生成后的 _skill.ts 提供两个关键函数:
typescript
export function buildSkillInstructions(guidance?: {
canonicalGuidance?: string;
extraGuidance?: string;
}): string
export function buildIntentClassificationPrompt(): string前者用于拼装主 Agent 的系统提示词,后者用于拼装意图分类器的提示词。
也就是说,Agent 的行为维护链路变成了:
这种方式比把所有规则塞进一个超长字符串舒服很多。后续如果发现 "M4 Mac brew 找不到" 的回答策略要调整,只需要改 troubleshooting-brew-missing.md;如果镜像源检测多了新目标,就改 mirror-diagnostics.md 和工具常量。Prompt 的来源更清楚,代码也只负责执行和编排。
意图识别与工具调用
Homebrew CN 这个 Agent 没有一上来就把问题扔给通用 Agent 循环,而是先做一次轻量意图识别,再决定要不要调用工具。
这样做的好处是很直接:能确定的流程直接走确定逻辑,需要证据的问题再交给工具或沙盒处理。
| 意图 | 使用的工具 | 处理方式 |
|---|---|---|
| 软件能不能安装 | formula_check |
查询 Homebrew JSON 索引,判断 Formula / Cask,并生成安装命令 |
| 镜像源是否可用 | mirror_probe_deep |
在沙盒里检测官方源、USTC、TUNA、Aliyun、Tencent 等镜像源状态 |
brew 找不到或更新异常 |
analyze / fix |
分析 PATH、Shell 配置、Git 配置、代理变量和脚本输出,再给出修复建议 |
| 恢复官方源、身份说明等固定问题 | 不一定调用工具 | 直接返回确定答案,减少无效工具调用 |
| 非 Homebrew 问题 | 不调用工具 | 明确说明超出 homebrew-cn Agent 范围 |
所以这个结构可以简单理解为:先判断问题类型,再把能工具化的部分交给工具。模型负责路由和组织回答,工具负责查证据、跑检测、生成更可靠的命令。
Formula / Cask 查询
Homebrew 的安装对象大体分两类:
- Formula:命令行工具和库,比如
node、python、ffmpeg。 - Cask:图形应用,比如
visual-studio-code、google-chrome、wechat。
很多用户第一次用 Homebrew 时,会把这两类命令混在一起。formula_check 做的事情就是从自然语言里抽取查询对象,然后同时查 Formula 和 Cask 索引。
比如用户问:
vscode 能不能用 brew 装?
Agent 会把 vscode 归一化成 visual-studio-code,再查询 Homebrew JSON API,最后返回:
bash
brew install --cask visual-studio-code对于中文里常见的软件名,也做了一些轻量别名处理:
| 用户说法 | 查询 token |
|---|---|
| VS Code / vscode / Visual Studio Code | visual-studio-code |
| Chrome / Google Chrome / 谷歌浏览器 | google-chrome |
| WeChat / Weixin / 微信 | wechat |
| Docker Desktop | docker-desktop |
| nodejs / node.js | node |
| python3 | python |
这类规则不复杂,但能明显减少用户得到错误安装命令的概率。
镜像源在线诊断
Homebrew CN 的安装脚本支持多个镜像源,但"哪个源最快"不是一个固定答案。它和用户网络、地区、时间、镜像同步状态都有关系。
所以 mirror_probe_deep 不靠经验推荐,而是让 EdgeOne Makers 的 Sandbox 跑一次在线检测。当前检测目标包括:
| 名称 | 地址 |
|---|---|
| Official (官方源) | https://github.com/Homebrew/brew.git |
| USTC (中科大) | https://mirrors.ustc.edu.cn/brew.git |
| TUNA (清华大学) | https://mirrors.tuna.tsinghua.edu.cn/git/homebrew/brew.git |
| Aliyun (阿里云) | https://mirrors.aliyun.com/homebrew/brew.git |
| Tencent (腾讯云) | https://mirrors.cloud.tencent.com/homebrew/brew.git |
检测时会尽量拿到这些字段:
- DNS 解析耗时。
- TCP 连接耗时。
- TLS 握手耗时。
- HTTP 访问状态。
git ls-remote是否成功。- Git refs 里的 commit hash。
- 与官方源对比后的同步状态。
实际代码里,Agent 会优先使用 context.sandbox,在沙盒中运行 Python 探测脚本:
typescript
const result = await sandbox.runCode(
buildMirrorDeepProbePython(name, url),
{ language: 'python', timeout: 12 },
);如果沙盒能力不可用,才降级到边缘侧 fetch 检测。
这里有一个小细节:官方 GitHub 源如果在 EdgeOne 沙盒内失败,不一定代表 GitHub 或 Homebrew 官方源真的挂了,也可能只是沙盒网络环境访问 GitHub 受限。所以 Agent 在摘要里会把这种情况标记成"沙箱网络受限",避免误导用户。
日志分析与修复命令
analyze 工具主要处理用户贴出来的本地环境信息。
目前它会识别几类高频问题:
- Apple Silicon 机器却出现
/usr/localHomebrew 路径,可能是 Rosetta 终端导致。 command not found: brew或PATH里缺少 Homebrew。- 终端里启用了
http_proxy、https_proxy、all_proxy。 - Git 全局配置里有
insteadOf重定向,可能影响 Homebrew 更新或 Tap 校验。 - Shell 配置里重复导出了多个
HOMEBREW_BOTTLE_DOMAIN。
如果问题和目标环境足够明确,fix 会生成修复命令。比如确认是 Apple Silicon 下的 PATH 问题后,会生成类似:
zsh
# homebrew-cn 自动生成的环境修复命令
# 执行前请确认路径及内容无误
# 1. 将 Homebrew 注入 Shell 配置文件 (~/.zshrc)
echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> ~/.zshrc
# 2. 让配置立即在当前终端生效
source ~/.zshrc
echo "修复完毕。请尝试运行 brew --version 验证是否成功。"注意,这里不会在信息不足时强行给持久化命令。比如用户只说"brew 找不到",Agent 会先要求执行只读诊断:
zsh
echo "SHELL=$SHELL"
uname -m
command -v brew || echo "brew-not-in-PATH"
brew --version 2>&1
printf "%s\n" "$PATH"
ls -l /opt/homebrew/bin/brew /usr/local/bin/brew 2>/dev/null因为 Homebrew 的路径问题很容易被"修坏"。尤其是 Apple Silicon 和 Intel 路径不同,Zsh / Bash 配置文件也不同,不能没有证据就往用户配置文件里追加内容。
OpenAI Agents SDK
这次项目使用 @openai/agents 来编排 Agent:
typescript
const agent = new Agent({
name: 'homebrew-cn Agent',
instructions: systemPrompt,
model: createGatewayModel(env),
modelSettings: {
parallelToolCalls: true,
providerData: {
chat_template_kwargs: {
enable_thinking: enableThinking,
},
thinking_token_budget: 512,
},
},
tools,
});
const result = await run(agent, userInput, {
stream: true,
signal,
session,
maxTurns: 5,
sessionInputCallback: limitSessionHistory,
});会话部分用的是 EdgeOne Makers 注入的 context.store:
typescript
const session = context.store.openaiSession(conversationId);这样前端只要持续传同一个 makers-conversation-id,Agent 就能拿到最近的上下文,不需要我额外接 Redis 或数据库。
工具事件则通过 SDK stream 转换成前端统一的 SSE:
typescript
if (e.type === 'run_item_stream_event' && e.name === 'tool_called') {
return {
type: 'tool_call',
name: toolName,
arguments: typeof args === 'object' ? JSON.stringify(args) : args,
};
}
if (e.type === 'run_item_stream_event' && e.name === 'tool_output') {
return { type: 'tool_result', name, content };
}这部分让我比较满意的是,Agent 内部仍然可以走 SDK 的抽象,而前端不用理解 SDK 事件格式,只消费项目自己的 thinking / tool_call / tool_result / ai_response 即可。
vLLM / Qwen 兼容
上一篇 oh-my-rime Agent 里也提过,OpenAI 兼容接口并不等于所有 streaming tool call 细节都完全一致。
这次 Homebrew CN 项目里,我在 _model.ts 里也做了一层兼容处理:
- 把部分 vLLM / Qwen 系模型输出的
reasoning_content映射成 SDK 更容易识别的reasoning。 - 处理流式 tool call 里函数名重复拼接的问题。
- 对一些可能被模型叫错的工具名做映射,比如
diagnose_mirrors、mirror_probe、check_formula等。 - 对 stream 请求默认补上
include_usage,方便最后输出 Token 统计。
其中函数名重复这个坑很典型。某些模型流式输出工具调用时,可能把工具名重复拼出来,最后变成:
text
mirror_probe_deepmirror_probe_deepmirror_probe_deep如果不清理,SDK 可能就找不到对应工具。现在会在模型客户端包装层里做一次 cleanRepeatedToolName,把这类输出归一化回合法工具名。
这属于不优雅但必要的工程胶水。Agent 真正上线后,稳定性比"看起来完全标准"更重要。
Tracing 可观测性
Agent 有了意图识别、工具调用、沙盒检测和模型调用以后,如果只看最终回答,排查起来会非常吃力。所以这次也接了 EdgeOne Makers 的 context.tracer,把 route、工具结果和 Token usage 都放进同一条链路里看。
这里还顺手解决了一个 usage 统计问题:上游接的是腾讯云 TDP 社区的 ModelGate 模型网关,Agent 侧已经正常输出 usage,但 EdgeOne Makers 后台一开始仍然看不到 Token 用量:
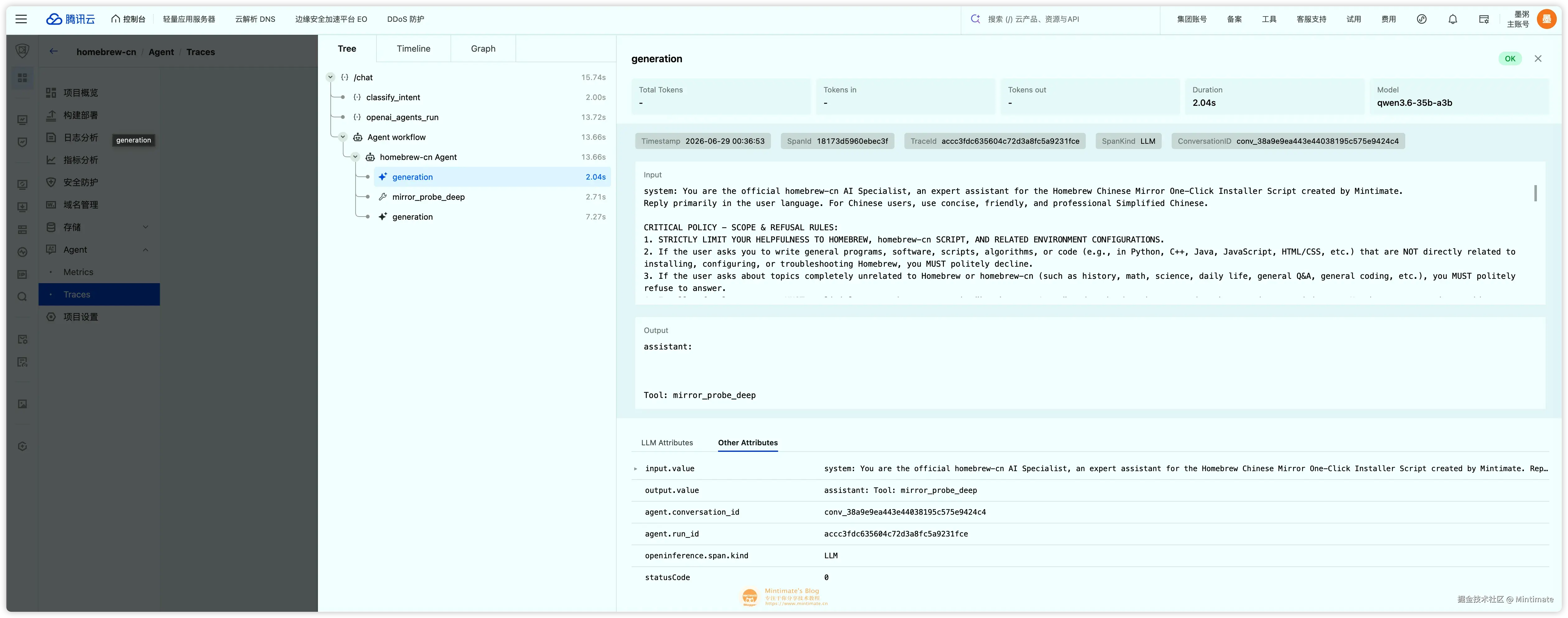
继续排查后发现,ModelGate 对流式 Chat Completions 的最终 usage chunk 还没有完全适配。
修复思路不复杂:Agent 请求模型时默认打开 stream_options.include_usage,ModelGate 在 [DONE] 前补齐带 usage 的最终 chunk;Agent 侧再把不同来源的 prompt_tokens / completion_tokens / total_tokens 归一化后累计上报。这样后台统计、成本评估和 tracing 才能对上。
请求进入后,会先给整条链路打基础属性:
typescript
tracer?.setAttributes({
'agent.name': 'homebrew-cn Agent',
'agent.framework': 'openai-agents-sdk',
'agent.conversation_id': conversationId,
'agent.route_path': '/chat',
});意图识别会记录 route:
typescript
setTraceAttributes(span, {
'intent.route': result.route,
'intent.homebrew_related': result.is_homebrew_related,
'intent.needs_sandbox': result.needs_sandbox,
});工具结果也会写关键摘要。比如镜像诊断完成后,会记录:
typescript
setTraceAttributes(span, {
'tool.result.ok': finalResult.ok,
'tool.result.duration_ms': finalResult.duration_ms,
'tool.result.report_count': finalResult.report.length,
'tool.result.failed_count': finalResult.report.filter((item) => item.error).length,
});这样一来,一次问答可以看到:
- 用户问题被分到了哪个 route。
- 是否需要沙盒。
- 工具执行用了多久。
- 镜像源检测有几个失败。
- 模型 Token 用量是否正常回传。
- 消耗偏高时,是意图识别、工具轮次、上下文历史,还是最终回答阶段造成的。
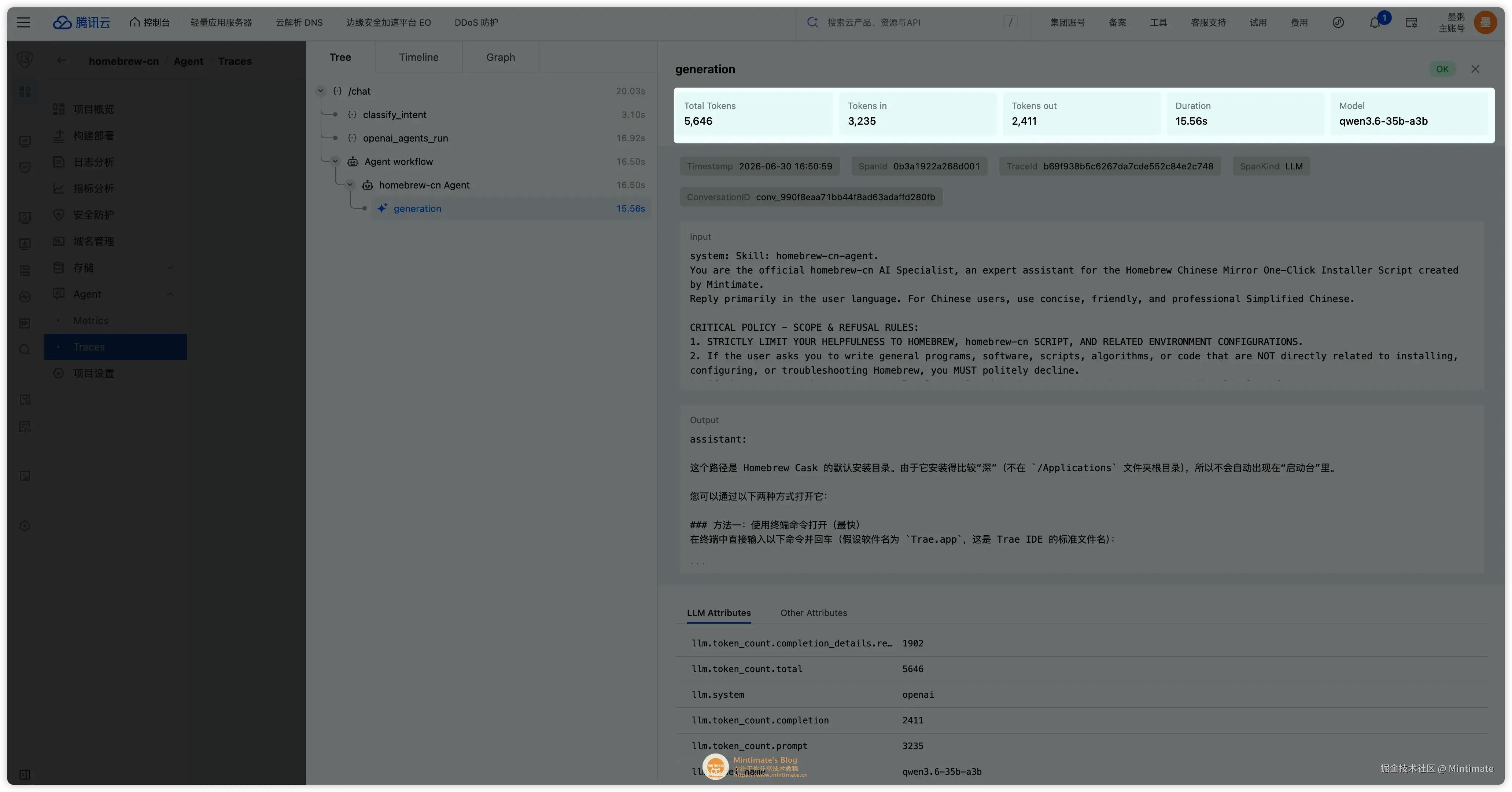
对于这种带工具调用的 Agent,可观测性不是锦上添花,而是后续调 Prompt、调工具、排线上问题的基础。
应用后的效果
上线后的 Homebrew CN 可以简单理解成两层:脚本负责确定性的安装流程,Agent 负责安装前后的问答和排障。
| 层级 | 负责的事情 |
|---|---|
| 安装脚本 | 选择系统、选择镜像源、写入环境变量、备份 Shell 配置 |
| homebrew-cn Agent | 查软件包、判断 Formula / Cask、分析 PATH / Shell / 镜像源问题 |
打开生产环境 brew-cn.mintimate.cn 后,可以直接在页面里从 install.sh 切到 brew-ai:
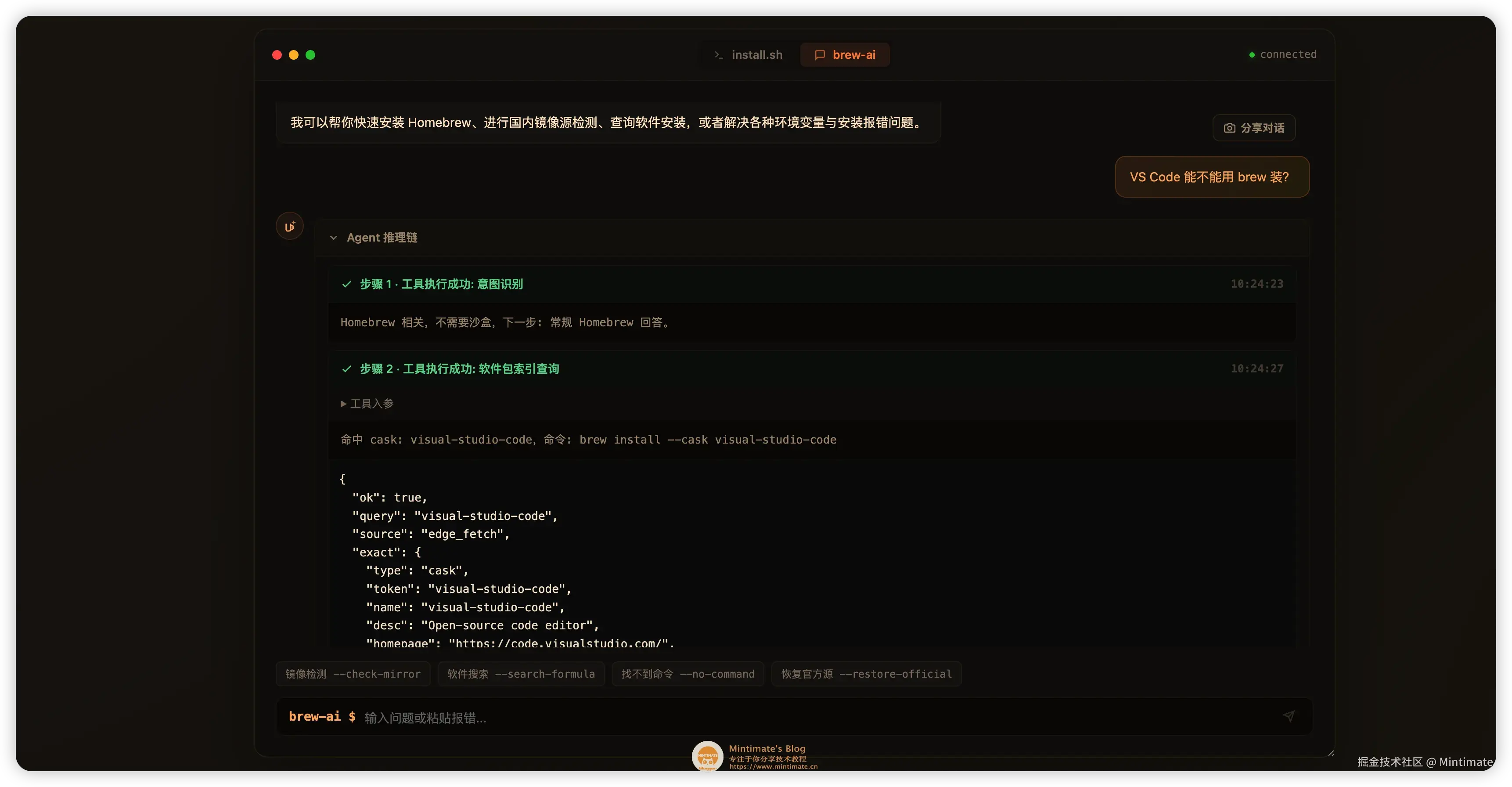
比如问 "VS Code 能不能用 brew 装?",Agent 会走 formula_check,查询 Homebrew JSON 索引后判断它是 Cask,并返回正确命令:
再比如 "M4 Mac 安装后提示 command not found: brew",Agent 不会一上来就让用户改 ~/.zshrc,而是先要求执行只读诊断命令,确认 /opt/homebrew、PATH 和当前终端状态:
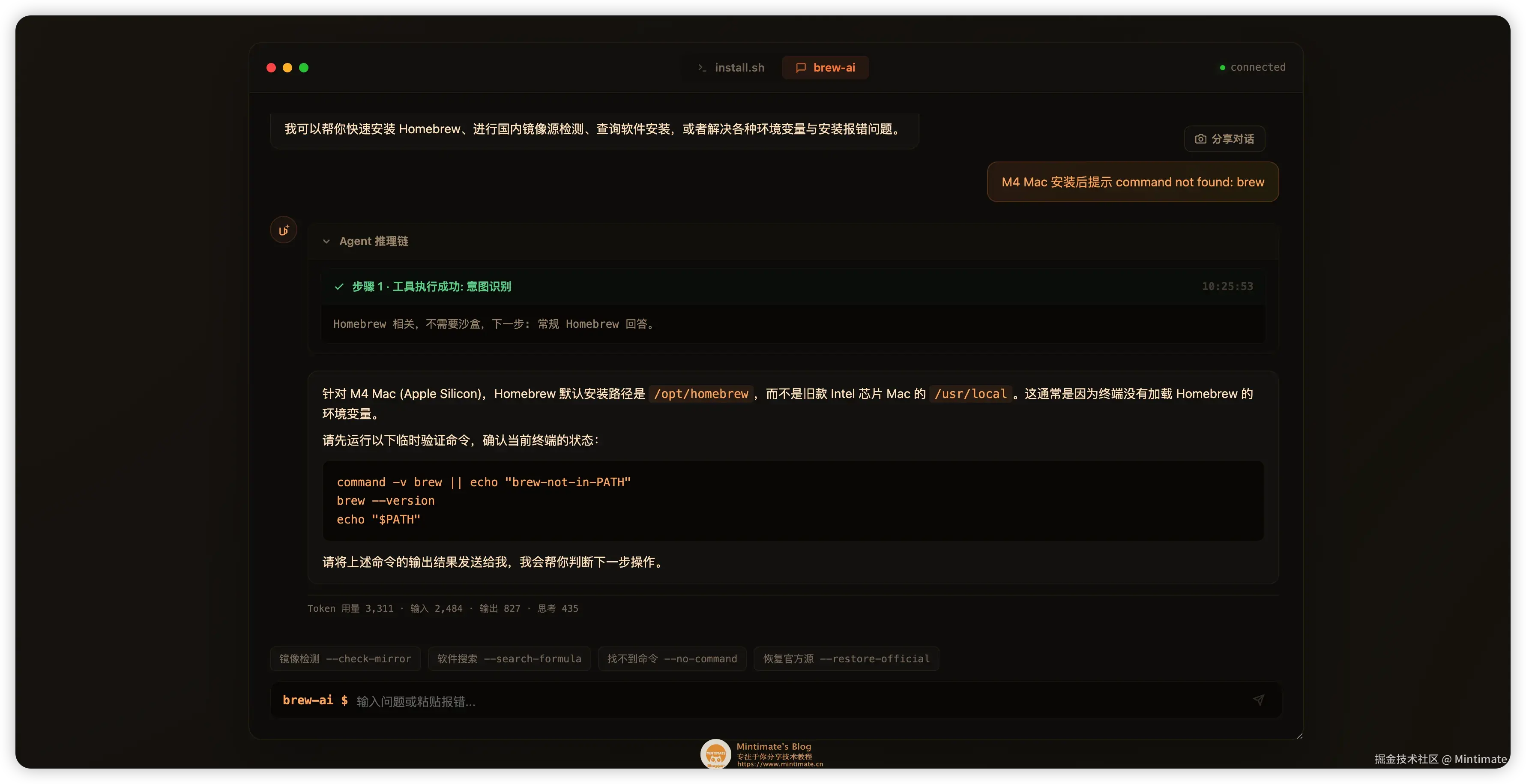
这种体验和普通 FAQ 最大的区别在于:它不是把所有答案预先写死,而是用工具把每个问题落到具体证据上。
对比文档 Agent
两篇 Agent 实践放在一起看,思路其实有相似之处,但重心不同。
oh-my-rime Agent 更像"文档知识 + 配置生成 + YAML 检测"。它需要理解 Rime 客户端、配置文件、patch 规则和用户上传的配置目录。
homebrew-cn Agent 更像"安装脚本 + 在线诊断 + 本地环境排障"。它不需要复杂 RAG,反而更依赖确定性工具:
| 对比项 | oh-my-rime Agent | homebrew-cn Agent |
|---|---|---|
| 核心问题 | Rime 配置怎么写、为什么不生效 | Homebrew 怎么装、怎么查包、怎么排障 |
| 知识来源 | 文档知识库、Rime 配方、用户配置文件 | Homebrew JSON 索引、镜像源在线探测、用户终端输出 |
| 关键工具 | 配置生成、YAML 检查、目录诊断 | Formula/Cask 查询、镜像测速、PATH/Git/代理分析 |
| 沙盒用途 | 文件级配置诊断 | 网络探测和 API 查询降级 |
| 输出重点 | 正确 patch 和配置解释 | 安装命令、诊断报告、修复命令 |
这篇和上一篇还有一个更明显的差异:这次我更想突出 WorkBuddy 的开发协作价值。
上一篇更多是在讲 EdgeOne Makers 能托管什么能力;这篇则更像一个组合工作流:
也就是说,Agent 并不是固定形态,AI 开发协作也不是只生成 Demo。不同项目要工具化的部分不同:Rime 要把配置规则工具化,Homebrew 要把网络检测和本地环境排障工具化;而 WorkBuddy 适合把这些判断逐步落进真实仓库里,Makers 则适合把最终服务托管起来。
END
这次做完 homebrew-cn Agent,最大的感受不是"又部署了一个 Agent",而是 WorkBuddy 和 EdgeOne Makers 的分工很舒服。
WorkBuddy 帮我把开发过程变轻了很多:读现有项目、拆 Agent 结构、生成 Skill 同步脚本、实现工具、补 usage、追 ModelGate 问题、跑构建验证,这些事情都可以顺着仓库上下文一步步推进。它不是只适合生成 Demo,而是可以在一个已经有历史包袱的项目里,帮我把想法落成能维护的工程。
EdgeOne Makers 则把运行阶段变轻:我不用为了一个轻量排障助手单独维护后端、会话存储、SSE 长连接、沙盒执行和链路追踪。项目仍然保持很轻,但已经能提供"可查询、可检测、可分析、可修复"的完整问答体验。
当然,真用下来也有一点小期待:如果 WorkBuddy 后续能像 Codex 一样,把 VSCode 插件和桌面端对话同步起来,就更顺手了。还有会话回滚也很重要,现在如果想放心试错,还是更依赖自己提前 Commit;如果能在会话里直接回滚某一轮改动,就会更适合长时间结对开发。
回到 Homebrew CN 本身,安装脚本解决确定流程,Agent 解决不确定问题。一个负责执行,一个负责判断;一个把 Homebrew 装起来,一个在装不起来、用不顺、查不清时继续接住用户。
后续我会继续补更多软件别名、常见安装报错规则,并把用户反馈里的高频问题反向更新到 Homebrew CN 文档和 Agent Skill。
这样 Homebrew CN 就不只是"一条能安装 Homebrew 的命令",而是一个能陪用户把 Homebrew 环境真正跑顺的小工具了。