现在市面上MCP种类丰富,用起来也很方便,恨不得猛猛地装上十几二十个。那是不是MCP越多越好呢,我并不这么认为。
每个 MCP Server 启动时都会把自己的工具列表注入到系统提示词中。当可见工具超过 50 个,模型开始分不清功能相近的工具,选错调用对象的概率大幅上升。更重要的是 Token 会被消耗,因为大量未使用的工具 JSON Schema 在每轮对话开始前就吃掉了上万 Token 的上下文窗口。
Token那么贵,装MCP的时候当然要选择好用的装。这篇文章筛选了 7 个在日常编码工作流中反复验证过的 MCP Server,从 Web 标准文档到本地环境管理,从实时搜索到结构化推理,每个都附带了配置代码和明确的适用边界。
MDN MCP Server:来自 Mozilla 的 Web 标准权威数据源

问 AI 一个 CSS 属性的浏览器兼容性,返回的信息可能基于一年前的训练数据。某个 API 到底是 Baseline Widely Available 还是仍需 polyfill,训练数据给不出准确答案。
MDN MCP Server 是 Mozilla 在 2026 年 6 月发布的实验性项目,它让 AI 编程助手直接查询 MDN Web Docs 的最新内容和浏览器兼容性数据。AI 可以搜索 MDN 文章、获取特定页面的完整内容、提取代码示例,以及检索详细的浏览器支持状态(包括 Baseline 标记和各浏览器版本的支持标志位)。
和 Context7 这类覆盖数千个第三方库的文档工具不同,MDN MCP 专注于 Web 平台本身------HTML、CSS、JavaScript、Web API。它的数据源是 MDN Web Docs,内容经过 Mozilla 团队和社区的持续审核,在 Web 标准领域具有最高的权威性。
适用场景: 前端开发中涉及浏览器兼容性判断、CSS 新特性使用、Web API 调用的场景。"CSS @starting-style 目前哪些浏览器支持""structuredClone() 在 Safari 上的最低支持版本是多少"------这些问题需要权威的兼容性数据,而非模型的推测。
注意事项: 目前处于实验阶段,功能和接口可能会调整。Mozilla 会收集查询数据用于改进服务,如需关闭第一方数据分析,可以在请求头中添加 X-Moz-1st-Party-Data-Opt-Out: 1。
配置方式(远程托管,推荐):
通过 Claude Code CLI 添加:
bash
claude mcp add --transport http mdn https://mcp.mdn.mozilla.net/或在 JSON 配置文件中添加:
json
{
"mcpServers": {
"mdn": {
"type": "http",
"url": "https://mcp.mdn.mozilla.net/",
"description": "MDN Web Docs 实时文档查询和浏览器兼容性数据"
}
}
}ServBay :用自然语言管理你的本地开发栈
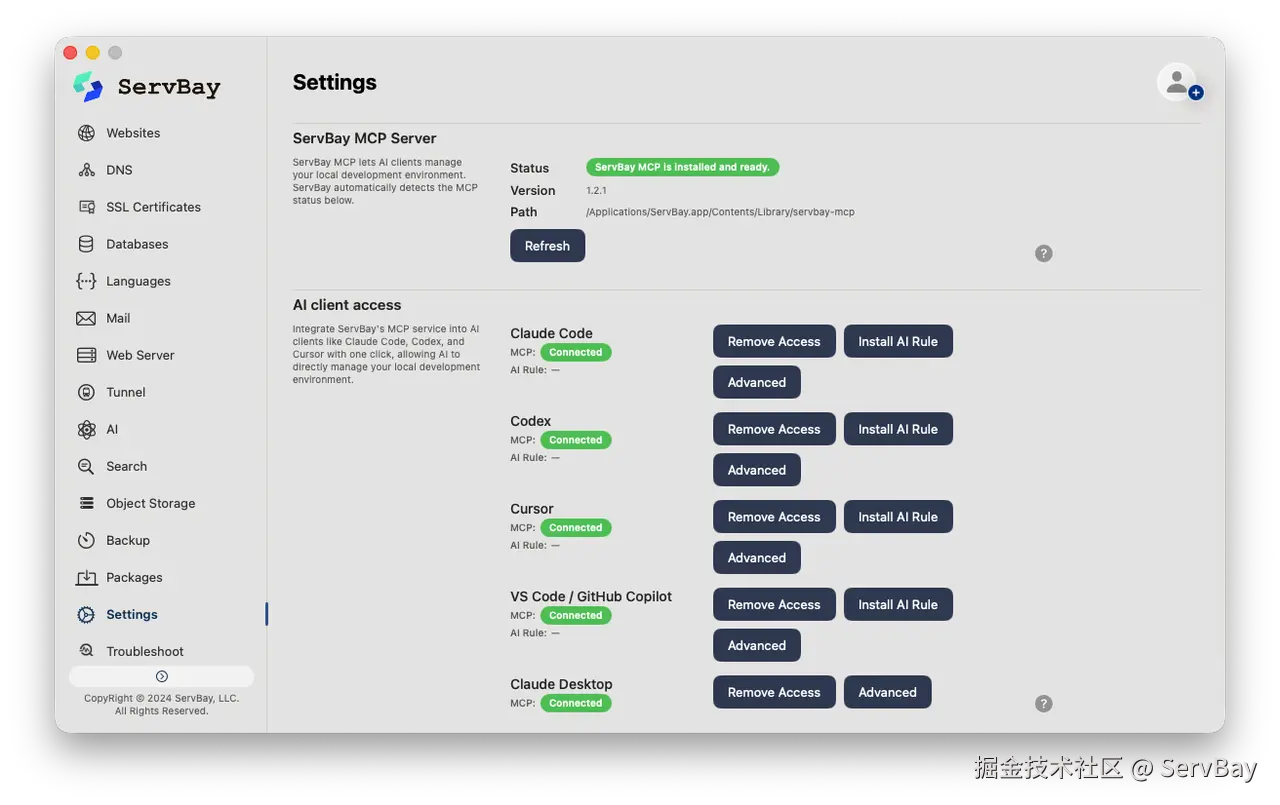
全栈开发中一个典型的效率瓶颈,比如项目需要 Nginx + MySQL + Redis + PHP 8.3,AI 编程助手可以帮你写代码,但每次需要改一下 Nginx 配置、创建一个数据库、或者切换 PHP 版本时,就得退出编辑器去手动操作。
要让 AI 管理这些服务,常规做法是分别安装数据库 MCP、文件系统 MCP、Web 服务器 MCP,逐一配置连接参数。三四个 MCP Server 下来,工具列表已经膨胀了一大截。ServBay 的做法不一样,它直接在应用内部内置了 MCP Server,通过一个端点暴露 39 个工具,覆盖了本地环境管理的全部操作:
-
服务控制: 启动、停止、重启任意服务(PHP、Node.js、MySQL、Redis 等),查看运行状态和日志
-
站点管理: 创建本地站点、配置域名、签发和续期 SSL 证书、管理反向代理
-
数据库操作: 创建和删除数据库、管理用户凭证、执行查询、导入导出数据
-
版本切换: 在不同版本的 PHP、Node.js、Python、Golang 之间一键切换,多版本并行运行互不干扰
-
系统诊断: 环境概览、服务配置查看、备份状态检查
作为一个AI原生开发工具,ServBay支持一句话管理本地开发环境。比如一句「帮我创建一个带 HTTPS 的 Node 站点,域名用 blog.servbay.demo,同时建一个 PostgreSQL 数据库」,AI 会自动编排站点创建 → SSL 签发 → 数据库初始化的完整流程。这在过去需要在终端里执行一连串命令,现在一轮对话就能完成。
和其他通过 npx 安装的 MCP Server 不同,ServBay 的 MCP 不需要手动编辑配置文件。打开 ServBay 设置页面,在一键连接 AI 客户端中选择 Claude Code、Cursor 或 Codex,配置会自动写入对应的客户端配置文件。
适用场景: 同时维护多个项目、频繁切换语言版本和数据库的全栈开发者。尤其是对环境配置不熟悉、或者不想在环境调试上花时间的场景------让 AI 去处理 Nginx 配置和数据库创建这些运维操作,开发者把精力留给业务代码。
注意事项: 所有操作在本地执行,数据不出本机。删除站点、修改数据库密码等破坏性操作需要在 ServBay 界面上二次确认,防止 AI 误操作。macOS 和 Windows 双平台可用,环境行为一致。
配置方式:
无需手动配置。安装 ServBay 后,进入 「设置 」→ 「一键连接 AI 客户端」,选择对应的 AI 工具即可完成接入。
Brave Search --- 突破训练数据截止日期的实时搜索
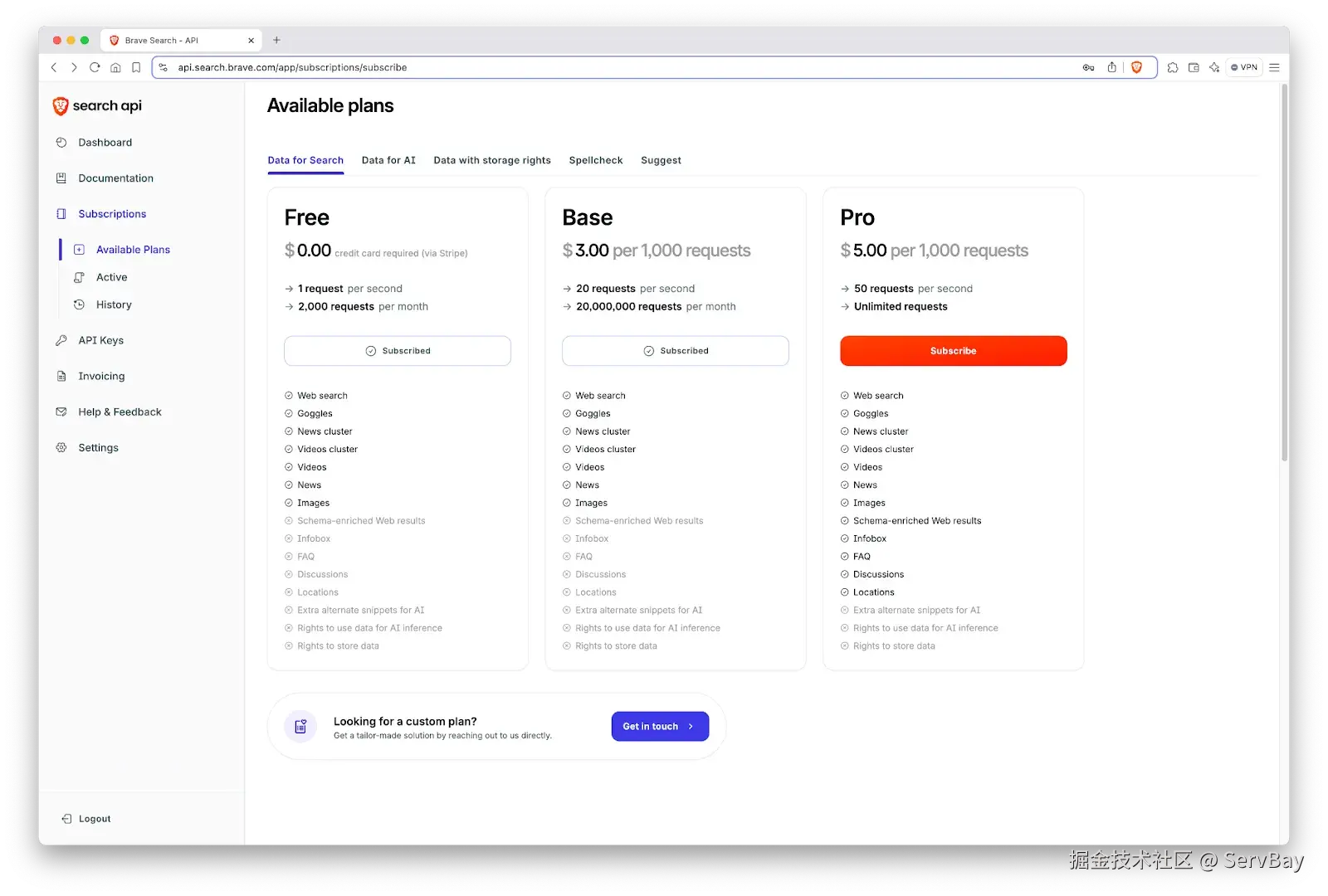
上周花了 20 分钟调试一个 esbuild 的报错,最后发现修复方案在两天前的一个 GitHub Issue 里。AI 的训练数据太旧,不知道这个 Bug 的存在,而开发者不得不离开终端手动搜索。
Brave Search MCP Server 给 AI 接上了实时搜索能力。它调用 Brave 独立搜索索引(不依赖 Google,无广告权重干扰),支持 Web 搜索、本地商户搜索、新闻搜索和图片搜索,返回的内容经过相关性评分优化,专门为 LLM 上下文格式设计。
主要工具 brave_web_search 支持按国家、语言、时间新鲜度(过去一天/一周/一个月)进行过滤,也支持分页和安全搜索。当本地搜索没有匹配结果时,会自动降级为带地域过滤的 Web 搜索。
适用场景: 任何需要当前信息的编码场景。"这个库的最新版本有没有已知的安全漏洞""这个框架目前推荐的状态管理方案是什么""某个云服务的 API 最近有没有 Breaking Change"------这些问题的答案不在训练数据里,只在实时搜索结果中。
注意事项: 需要在 Brave Search API Dashboard 申请 API Key。免费层级每月 2,000 次查询,对个人开发者足够用。注意早期的 @modelcontextprotocol/server-brave-search 包已于 2025 年 5 月归档,请使用 Brave 官方维护的新包。
配置方式:
json
{
"mcpServers": {
"brave-search": {
"command": "npx",
"args": ["-y", "@brave/brave-search-mcp-server", "--transport", "stdio"],
"env": {
"BRAVE_API_KEY": "YOUR_BRAVE_API_KEY"
},
"description": "基于 Brave 独立索引的实时 Web 搜索,无知识截止日期限制"
}
}
}Filesystem MCP Server:给 AI 一个有边界的文件系统访问权
大多数 AI 编程客户端(如 Claude Code、Cursor)本身已经具备当前项目目录的文件读写能力。但如果需要 AI 访问项目目录之外的文件,比如引用另一个项目的配置模板、读取 ~/projects/shared-libs 里的公共组件、或者操作 ~/Documents 下的数据文件------原生能力就不够用了。
Filesystem MCP Server 是 MCP 协议的官方参考实现,它通过"Roots"机制定义 AI 可以访问的目录范围,在此范围内提供 read_file、write_file、list_directory、create_directory 等标准文件操作工具。
这里的关键设计是路径限制。服务端启动时需要显式指定允许访问的目录,AI 无法通过路径遍历突破这个边界去访问敏感区域。同时内置了文件大小限制(默认 1MB 读取上限),防止大文件耗尽上下文窗口的 Token。
适用场景: 需要跨项目引用文件、读取外部配置或操作非当前工作区文件的场景。比如从公共模板目录复制项目脚手架、读取另一个服务的配置文件来保持一致性,或者让 AI 在指定的输出目录生成文档。
注意事项: 如果 AI 客户端的原生文件操作已经覆盖了需求,就不必安装这个 Server------重复的文件操作工具会导致工具冲突,AI 可能选错调用对象。只在需要跨项目目录访问时才启用。
配置方式:
json
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/Users/yourname/projects/shared-libs",
"/Users/yourname/Documents/configs"
],
"description": "受限范围的文件系统访问,用于跨项目文件操作"
}
}
}
args中最后的路径参数定义了 AI 可以访问的目录白名单,按实际需求替换。
Sequential Thinking --- 让 AI 在复杂任务中想清楚再动手
给 AI 一个涉及多个模块的重构任务,它有时会直接开始改代码,改到一半发现遗漏了依赖关系,又回头重来。问题不在能力,而在推理过程缺少结构化管理。
Sequential Thinking MCP Server 提供了一个名为 sequential_thinking 的工具,让 AI 在执行复杂任务前先进行分步推理。它要求模型将问题拆解为多个步骤,在每个步骤记录当前的思考,追踪推理进度,必要时回退或分叉到不同的思路分支。
和直接给 AI 发一条"请先想清楚再回答"的提示词不同,Sequential Thinking 把推理过程持久化了。每一步的思考都被记录在一个可审计的日志中,模型可以在后续步骤中回溯引用之前的分析结果。这对于需要多步决策的大型任务(数据库迁移、架构设计、跨服务重构等)有明显的准确率提升。
适用场景: 涉及多步骤决策和路径选择的复杂编码任务。数据库 Schema 迁移需要分析影响范围、基础设施变更需要按依赖顺序执行、多文件重构需要维护跨模块的一致性------这些场景下,结构化推理比一次性输出更可靠。
注意事项: Sequential Thinking 会增加对话的 Token 消耗(因为模型需要额外的推理步骤)。对于简单的代码修改或单文件编辑,没必要启用它。建议在复杂重构或架构设计会话中按需开启。
配置方式:
json
{
"mcpServers": {
"sequential-thinking": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-sequential-thinking"],
"description": "结构化分步推理,适用于复杂重构和架构决策"
}
}
}OpenAI Agents SDK + MCP --- Function Calling 的标准化演进

在 MCP 出现之前,让 AI 调用外部工具的主流方式是 OpenAI 的 Function Calling:开发者在请求中定义函数 Schema,模型返回一个 JSON 格式的调用意图,应用层再去执行真正的函数调用,最后把结果喂回模型。这个模式可用但耦合度高------每个工具的 Schema 都写死在应用代码里,换一个模型供应商就要重写一套适配层。
OpenAI Agents SDK 从 2025 年开始原生支持 MCP 协议,让 Function Calling 和 MCP Server 的工具可以在同一个 Agent 工作流中共存。SDK 支持三种连接 MCP Server 的方式:stdio(本地进程)、Streamable HTTP(远程服务)和 Hosted MCP Tools(OpenAI 托管的远程服务器,通过 Responses API 直接调用)。
在实际使用中,两者的分工明确
| Function Calling | MCP Server | |
|---|---|---|
| 适用范围 | 应用内部的自定义逻辑 | 跨应用、可复用的外部工具集成 |
| 维护成本 | 新增工具需要改应用代码 | 连接新的 Server 即可,不改 Agent 代码 |
| 供应商绑定 | 绑定 OpenAI 的 Schema 格式 | 协议通用,模型无关 |
| 扩展性 | 3-5 个工具时简单直接 | 工具数量多时优势明显 |
适用场景: 已经在使用 OpenAI API 构建 Agent 应用的团队。通过 MCP 接入外部工具(数据库、搜索引擎、项目管理系统等),不需要为每个工具单独编写 Function Calling 的 Schema 和执行逻辑,直接复用社区已有的 MCP Server。
注意事项: OpenAI Agents SDK 的 MCP 支持需要 v0.12.x 及以上版本。本地 stdio 模式的 MCP Server 需要在运行 Agent 的机器上安装对应的依赖。Hosted MCP Tools 由 OpenAI 托管,使用更简便但可用工具范围受限于 OpenAI 已集成的服务。
配置方式(Python SDK 示例):
json
from agents import Agent
from agents.mcp import MCPServerStdio, MCPServerHTTP
# stdio 模式:连接本地 MCP Server
local_server = MCPServerStdio(
command="npx",
args=["-y", "@brave/brave-search-mcp-server", "--transport", "stdio"]
)
# HTTP 模式:连接远程 MCP Server
remote_server = MCPServerHTTP(
url="https://mcp.example.com/mcp",
headers={"Authorization": "Bearer YOUR_TOKEN"}
)
agent = Agent(
name="dev-assistant",
instructions="You are a development assistant.",
mcp_servers=[local_server, remote_server]
)Puppeteer MCP Server:轻量级浏览器控制,适合快速抓取和脚本注入
AI 改完一段前端代码后声称"样式已修复",但它从来没有真正打开过浏览器去验证。Puppeteer MCP Server 解决的就是这个问题------它让 AI 驱动一个真实的浏览器实例,导航到页面、点击元素、填写表单、截取屏幕,用实际渲染结果验证代码变更是否生效。
Puppeteer MCP 通过 CSS 选择器定位页面元素,支持在页面中执行任意 JavaScript 代码。它提供的工具包括 puppeteer_navigate(导航到 URL)、puppeteer_click(点击元素)、puppeteer_fill(填写表单)、puppeteer_screenshot(截取页面)、puppeteer_evaluate(执行 JavaScript)和 puppeteer_select(选择下拉选项)。工具数量精简,覆盖了浏览器操作的基本面,不会过度膨胀工具列表。
和 Microsoft 的 Playwright MCP(基于无障碍树做语义化交互)相比,Puppeteer 走的是更直接的路线。它的优势在于灵活性------可以注入自定义 JS 代码来提取数据或操控页面状态,适合快速完成一次性任务。但 CSS 选择器交互的稳定性不如无障碍树,当目标页面的样式结构变化时,操作可能失败。
适用场景: 快速的页面数据抓取、需要在浏览器中执行自定义 JavaScript 的调试场景、以及对渲染结果的可视化验证。比如"打开这个内部工具页面,执行一段 JS 提取表格数据并返回 JSON",或者"截取这个页面的当前状态,确认布局是否正确"。
注意事项: Puppeteer MCP 运行时会在本机启动浏览器进程,注意它对本地文件和内网资源的潜在访问权限。在无 GUI 的环境(如服务器或 Docker 容器)中使用时,需要确保支持 headless 模式。
配置方式:
json
{
"mcpServers": {
"puppeteer": {
"command": "npx",
"args": ["-y", "@modelcontextprotocol/server-puppeteer"],
"description": "基于 CSS 选择器的浏览器控制,适合快速抓取和 JS 执行"
}
}
}对比总览
对比总览
| MCP Server | 类别 | 费用 | 传输协议 | 最佳场景 |
|---|---|---|---|---|
| MDN | Web 标准文档 | 免费 | HTTP | 浏览器兼容性、Web API 查询 |
| ServBay | 本地环境管理 | 免费 | 内置 | 全栈环境管理、服务编排 |
| Brave Search | Web 搜索 | 免费层级 | stdio | 实时信息查询 |
| Filesystem | 文件系统 | 免费 | stdio | 跨项目文件访问 |
| Sequential Thinking | 推理增强 | 免费 | stdio | 复杂重构、架构决策 |
| OpenAI Agents + MCP | 工具调用标准化 | API 计费 | stdio/HTTP | Agent 开发、工具编排 |
| Puppeteer | 浏览器自动化 | 免费 | stdio | 快速抓取、JS 注入 |
工具配额管理:装多少才合适
MCP Server 的配置不是"装完就不管了"的事情。每增加一个 Server,系统提示词中就多出一批工具定义,占用上下文窗口并增加模型选择工具时的歧义。以下是几条实践经验:
控制在 50 个可见工具以内。 这是大多数模型在工具选择准确率上的经验分界线。超过这个数字后,功能相近的工具之间的混淆率会显著上升。
按会话按需启用。 不是每次编码都需要所有 Server。做前端开发时开 MDN 和 Puppeteer,做数据库相关工作时确保数据库 MCP 在线,写完代码做搜索调研时再开 Brave Search。大部分客户端(如 Claude Code 的 /mcp 命令)支持在会话中动态开关工具。
不要安装重复功能的 Server。 如果 AI 客户端原生支持文件读写,就不要再装 Filesystem MCP。如果已经用 ServBay 管理数据库,就不需要再单独装一个 Postgres MCP Server。重复工具是工具冲突的主要来源。
使用项目级配置替代全局配置。 在 Claude Code 中使用 --scope project 将配置写入项目根目录的 .mcp.json,而非个人全局的 ~/.claude.json。这样团队成员共享同一套工具集,也方便按项目特性调整 MCP Server 组合。
总结
MCP 协议正在改变开发者与 AI 编程助手协作的方式。过去需要在编辑器、终端、浏览器、文档网站和管理后台之间反复切换的操作,现在可以通过一条自然语言指令在对话中完成。
但 MCP 生态的快速膨胀也带来了新的管理负担。盲目安装大量 Server 不会让 AI 更聪明,反而会因为工具冲突和上下文污染导致表现下降。本文介绍的 7 个 MCP Server 覆盖了日常编码中最高频的需求:
-
MDN MCP 解决 Web 标准和浏览器兼容性的查询准确性问题
-
ServBay 用一个内置端点替代了多个独立的环境管理 Server,大幅压缩工具配额占用
-
Brave Search 补上了训练数据截止日期这个所有 AI 助手的共同短板
-
Filesystem 在安全边界内扩展了 AI 的文件访问范围
-
Sequential Thinking 让 AI 在复杂任务中先推理后执行,减少返工
-
OpenAI Agents SDK + MCP 为 Agent 开发者提供了从 Function Calling 到标准化工具协议的迁移路径
-
Puppeteer 给 AI 一双眼睛,用真实浏览器验证代码变更的实际效果
选择 MCP Server 的原则始终是:只安装当前工作流中确实需要的,定期审计工具数量,用项目级配置替代全局配置。每个 Server 都应该是经过验证后被"准入"的,而不是看到推荐就安装的。当工具配额被视为一种有限资源来管理时,AI 编程助手才能在每次工具调用中做出正确的选择。