前言
在云原生时代,如何高效管理多种异构数据库引擎,一直是大型互联网企业面临的核心挑战。作为中国领先的特卖电商平台,唯品会(Vipshop) 的业务模式具有典型的瞬时高并发特征(如上新特卖期间)。这种业务形态对底层数据基础设施的弹性、稳定性和运维效率提出了极高的要求。
面对海量的交易数据、日志流和用户请求,唯品会的基础架构团队需要支撑 Kafka、Elasticsearch、MySQL、MariaDB 等多种异构数据库和中间件的稳定运行。本文将深度解析唯品会如何借助 KubeBlocks 构建统一的数据库云原生运维平台,实现从"手动运维"到"声明式自动化"的转型,以及在千级实例规模下的生产实践。
一、生产规模与挑战:为何通过 KubeBlocks 统一管理
📊 生产环境规模一览
截至目前,我们已通过 KubeBlocks 统一管理了 1,000+ 个数据库集群,总实例数超过 3,000 个。
| 数据库引擎 | 业务场景 | 集群数量 | 节点/实例数 | 规模特征 |
|---|---|---|---|---|
| Kafka 2.7 | 消息总线、日志流、交易削峰填谷 | 100+ 套 | ~2,000 Brokers | 超大流量吞吐,需极速扩容 |
| Elasticsearch 7.7 | 日志分析、商品搜索、订单检索 | 40+ 套 | ~200 节点 | 数据量大,配置复杂 |
| MySQL 5.7 / MariaDB 10.2 | 核心交易、用户中心、库存管理 | 1,000+ 复制集 | 1,000+ Pods | 存量巨大,数据一致性要求极高 |
传统运维模式的痛点
在引入 KubeBlocks 之前,面对如此庞大且异构的数据库体系,运维团队面临着"三大难关":
痛点 1:技术栈割裂,运维成本高昂
-
Kafka、ES、MySQL 的运维工具、配置文件、监控指标截然不同
-
DBA 团队需要维护多套脚本和自动化系统,新引擎接入周期长
Plain
┌─────────────────────────────────────────────────────────────┐
│ 传统运维模式 │
│ │
│ Kafka 运维 ES 运维 MySQL 运维 │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ 专用脚本 │ │ 专用脚本 │ │ 专用脚本 │ │
│ │ 专用监控 │ │ 专用监控 │ │ 专用监控 │ │
│ │ 专用文档 │ │ 专用文档 │ │ 专用文档 │ │
│ └─────────┘ └─────────┘ └─────────┘ │
│ ↓ ↓ ↓ │
│ ┌─────────────────────────────────────────────────┐ │
│ │ 3 套体系 × 3 种学习曲线 × N 个版本 = 💀 │ │
│ └─────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘痛点 2:K8s 原生能力不足以支撑有状态应用
-
Kubernetes 的 StatefulSet 难以完美处理数据库的复杂拓扑
-
声明式 API 对传统 DBA 学习曲线陡峭,难以快速进行"重启指定实例"、"主备切换"等精细操作
痛点 3:大规模生产的"可控性"焦虑
-
滚动升级风险:在数千节点的规模下,全自动的滚动升级可能导致"雪崩"。生产环境需要精确控制升级节奏,并与私有 DNS、CMDB 等周边系统联动
-
存量迁移困难:大量运行在物理机上的核心数据库,无法承受"停机上云"的代价
为什么是 KubeBlocks?
经过对比测试,我们选择了 KubeBlocks。核心原因:
| 评估维度 | 自研 Operator | KubeBlocks |
|---|---|---|
| 多引擎统一 API | ❌ 每个引擎需单独开发 | ✅ 统一 Cluster/Component API |
| 接入新引擎成本 | 2-3 个月 | 1-2 周(Addon 机制) |
| Day-2 运维封装 | 需自行开发 | ✅ OpsRequest 开箱即用 |
| 社区活跃度 | N/A | ✅ 活跃,响应快 |
二、架构设计:统一管理的技术底座
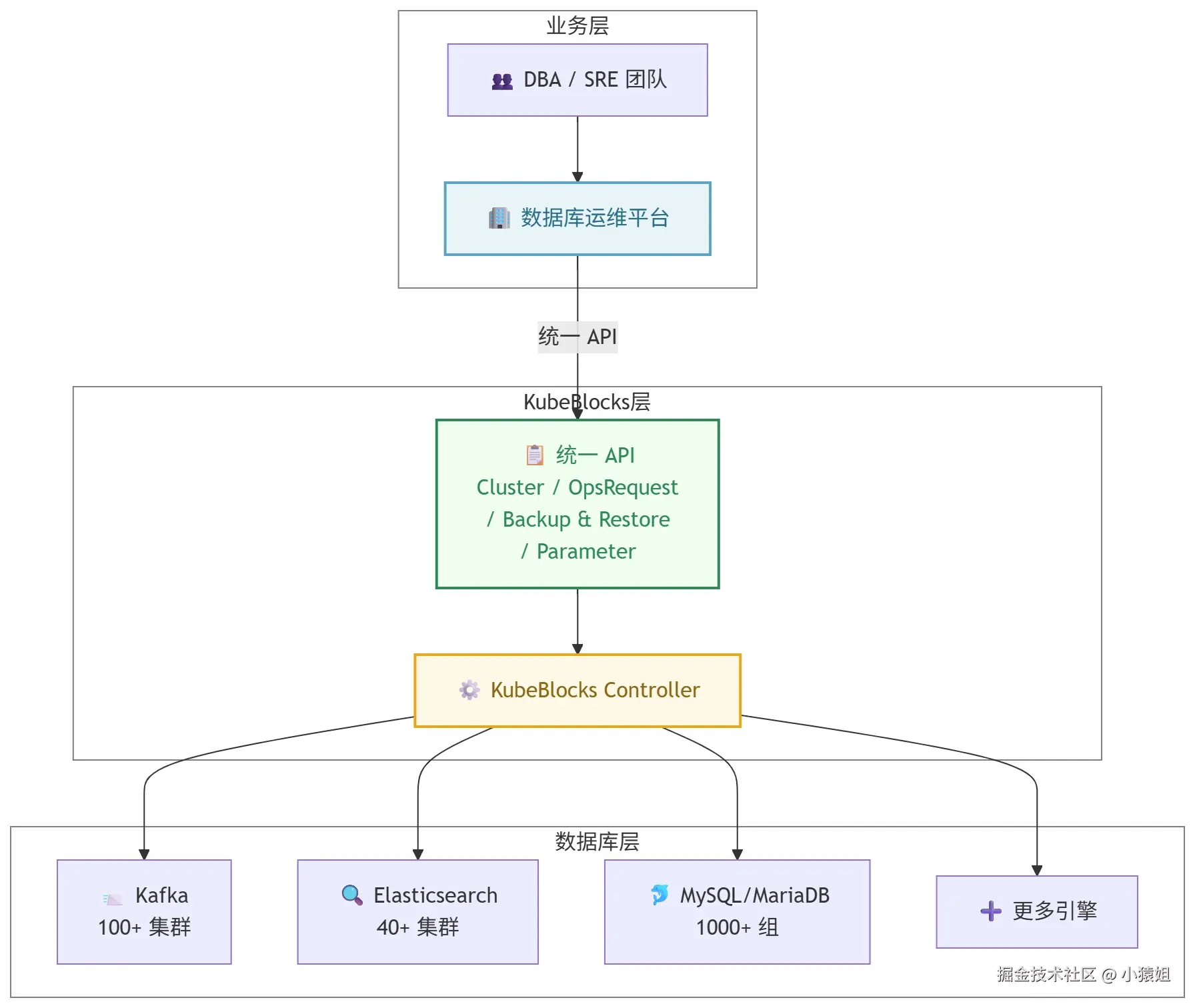
三、深度场景解析:多引擎落地实践
1. Kafka:应对"特卖"流量洪峰的极致弹性
> 规模:100+ 集群,~2,000 Brokers
部署方案:基于官方 Kafka Addon 部署 Kafka 集群,利用 InstanceTemplate 特性支持了异构实例的部署。
挑战与优化:
-
Challenge:目前 Kafka Addon 默认打开了 Per Pod Service 功能,会为每个 Kafka Pod 创建一个 ClusterIP Service。在 2,000+ Broker 规模下,会创建大量的 Service 并占用 Cluster IP,iptables/IPVS 规则维护成本极高
-
Optimization:我们结合私有容器网络方案以及私有 DNS 注册,直接将 Kafka Pod IP 通过 DNS 解析交付业务使用。平台负责 DNS 解析的更新。 并向社区反馈了建议
2. Elasticsearch:大规模搜索集群的稳定性治理
> 规模:40+ 集群,~200 节点
业务痛点:生产环境的 ES 集群配置极度复杂(JVM调优、分片策略、冷热分离),且不同业务线(日志 vs 搜索)需求差异大。
自研 Addon 实践
我们没有直接使用社区版,而是基于 Addon 规范开发了唯品会定制版 ES Addon:
-
支持了更多的 ES 功能和自定义配置
-
支持特定ES版本, 主要是7.7.x
-
目前已经支持生产级规模集群
关键收益:
-
零代码开发:无需学习 Go 语言写 Operator,只需编写声明式 YAML
-
标准化配置:统一管理不同业务线的 ES 集群配置
-
快速迭代:ES 版本升级只需更新 ComponentVersion,无需修改控制器. 配合`Upgrade` OpsRequest实现可控的版本升级
待改进:Parameter API 目前无法支持 JVM Options 格式的配置渲染,无法通过 Reconfigure OpsRequest 进行 ES 的 JVM 配置更新,期待后续版本支持。
3. MySQL/MariaDB:存量核心库的"混合云"平滑迁移
> 规模:1,000+ 复制集,1,000+ Pods(混合架构)
业务痛点:这是最棘手的场景。数千个核心数据库运行在物理机上,数据量巨大,业务绝对不允许停机迁移。如何让 K8s 中的新实例与物理机老实例共存?
创新方案:物理机 + 容器的混合复制集
核心思路:不做全量迁移,而是让新老系统共存。
Plain
┌────────────────────────────────────────────────────────────────┐
│ MySQL 混合复制架构 (1,000+ 复制集) │
│ │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ MySQL Master │◄────复制────► │ MySQL Slave │ │
│ │ 物理机 🖥️ │ │ KubeBlocks ☸️ │ │
│ │ (继续服务) │ │ (新副本) │ │
│ └────────┬────────┘ └────────┬────────┘ │
│ │ │ │
│ └──────────────┬─────────────────┘ │
│ ▼ │
│ ┌─────────────┐ │
│ │ MHA │ ← 继续使用成熟的 HA 工具 │
│ │ 角色管理 │ │
│ └─────────────┘ │
│ │
│ 迁移路径: 物理机 Master + 物理机 Slave │
│ ↓ │
│ 物理机 Master + 容器 Slave (当前阶段) │
│ ↓ │
│ 容器 Master + 容器 Slave (未来) │
└────────────────────────────────────────────────────────────────┘关键设计:
-
自研 Addon:通过开发自定义脚本与容器完成初始化数据及备份恢复,实现 KubeBlocks 容器实例加入物理机复制集
-
角色外置:主从选举继续由外部 MHA 负责,KubeBlocks 只管生命周期
-
渐进式接管:
-
Step 1:容器 Slave 加入物理机复制集,同步数据
-
Step 2:验证稳定后,读流量切至容器
-
Step 3:未来通过 MHA 切换 Master(目前处于 Step 1-2)
💡 MariaDB 10.2 采用类似方案实现。
这种混合架构是我们在大规模存量系统迁移中探索出的最佳实践:
-
降低迁移风险:不需要一次性切换,可以逐步验证
-
保留运维经验:MHA 等成熟工具继续发挥作用
-
业务无感知:对上层应用完全透明
💡 MySQL/MariaDB 目前未接入 Parameter API 实现参数更新,未来版本会支持.
四、运维自动化:OpsRequest 重新定义 Day-2 操作
OpsRequest 是我们最常用的 KubeBlocks 能力。得益于 KubeBlocks OpsRequest 对日常运维操作的封装,自建平台可以非常方便地将以往 SRE 常用的操作转换为OpsRequest API 并进行操作封装。
常用操作速查
| 场景 | OpsRequest 类型 | 一句话描述 |
|---|---|---|
| 水平扩缩容 | HorizontalScaling | 应对计划性或突发性的集群规模变更,以应对业务流量 |
| 垂直扩缩容 | VerticalScaling | 应对集群规模、业务增长导致的性能不足问题 |
| 节点上/下线 | HorizontalScaling + Offline/Online | 精确控制指定实例上下线 |
| 版本升级 | Upgrade | 升级容器镜像版本 |
| 启停集群 | Start/Stop | 资源回收,保留数据 |
| 参数变更 | Reconfiguring | 更新配置参数 |
| 故障重建 | RebuildInstance | 故障节点快速恢复 |
场景一:本地存储故障恢复(最高频场景)
背景 :在生产环境中,我们采用本地存储来满足性能要求。但在 K8s 中,本地存储意味着 Pod 与 Node 强绑定,一旦 Node 宕机,Pod 无法漂移。
传统 K8s 处理:人工介入,过程复杂漫长且且易错。
KubeBlocks 处理:利用 RebuildInstance 能力,支持本地存储故下的快速恢复。
Plain
故障发生 → SRE 提交 RebuildInstance OpsRequest → KB 准备新PVC/数据 → KB 重建 Pod → KB 集群恢复 → 业务完全恢复效果:将故障恢复流程标准化、自动化,大幅减少人工干预和操作失误。 可将故障恢复时间从小时级缩短到分钟级。
实例重建不仅常用于故障场景,还常用于主动运维场景, 例如 主机故障 或者主机运维时, 可通过实例重建讲使用本地盘的实例迁移到指定节点. 以实现主机运维时, 业务不中断.
场景二:指定节点精确下线
需求:硬件维护或者节点故障时需要下线特定节点,但 K8s 默认按序号倒序缩容。
问题:我想下线 `mysql-3`(有坏盘),但 K8s 会先删 `mysql-5`。
解决:
YAML
apiVersion: operations.kubeblocks.io/v1alpha1
kind: OpsRequest
metadata:
name: offline-specified-instance
spec:
clusterName: dev-mysql
type: HorizontalScaling
horizontalScaling:
- componentName: mysql
scaleIn:
onlineInstancesToOffline:
- 'dev-mysql-mysql-3' # 精确指定!恢复上线(维护完成后):
YAML
spec:
type: HorizontalScaling
horizontalScaling:
- componentName: mysql
scaleOut:
offlineInstancesToOnline:
- 'dev-mysql-mysql-3' # 原地恢复,秒级启动关键优势:
-
✅ 精准定位,避免误删健康节点
-
✅ Offline 可选择保留 PVC,数据安全
-
✅ Online 秒级恢复,无需数据重建
场景三:集群启停实现资源调度
Stop 操作不仅仅是简单的"关机",它在唯品会的资源治理中扮演了多重角色:
-
峰值资源让渡:在特卖大促等计算资源极其紧张的时刻,通过批量 Stop 非核心的开发测试集群,将宝贵的 CPU/内存资源瞬间释放给核心交易链路,实现"错峰"资源调度。
-
数据安全缓冲 :`Stop` 操作仅释放计算资源(Pod),完整保留存储数据(PVC)。对于长期未使用的"僵尸集群",先执行 Stop 观察,待确认无业务依赖后再 Delete,有效防止误删导致的数据灾难。
-
极速现场恢复 :由于数据卷就在原地,相比于"删除后重建+恢复数据",`Start` 操作只需拉起 Pod 并挂载 PVC,可实现秒级的服务恢复。
这种机制让我们在成本控制和数据安全之间找到了完美的平衡。
五、生产级安全保障:OnDelete 可控升级
在 3,200+ 实例规模下,我们拒绝"黑盒"式自动滚动升级。
为什么不用默认的 RollingUpdate?
| 问题 | 说明 |
|---|---|
| 外部联动 | Pod 重启前后必须更新私有 DNS |
| 风险控制 | 需要观察窗口,发现问题能立即暂停 |
OnDelete 策略实践
YAML
apiVersion: apps.kubeblocks.io/v1
kind: Cluster
metadata:
name: prod-mysql
spec:
componentSpecs:
- name: mysql
updateStrategy: OnDelete # 关键配置我们的升级流程:
Plain
┌───────────────────────────────────────────────────────────────┐
│ 自研运维平台编排流程 │
│ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ 选择Pod │───►│ 摘除DNS │───► │ 等待流量 │─► │ 删除Pod │ │
│ │ │ │ 流量 │ │ 归零 │ │ │ │
│ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │
│ │ │
│ ┌────────────────────────────────────────────┘ │
│ ▼ │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ 等待新Pod│──►│ 健康检查 │──►│ 注册DNS │───►│ 下一个 │ │
│ │ 就绪 │ │ 通过 │ │ │ │ Pod │ │
│ └─────────┘ └─────────┘ └─────────┘ └─────────┘ │
│ │
│ 💡 任意环节发现异常可立即暂停,不影响其他节点 │
└───────────────────────────────────────────────────────────────┘效果 :虽然牺牲了部分效率,但换来了整个滚动过程的自主可控------这对生产环境至关重要。
六、经验总结与最佳实践
📈 生产规模验证
经过在唯品会大规模生产环境的验证,KubeBlocks 展现了出色的稳定性和扩展性:
| 引擎类型 | 集群规模 | 实例规模 | 运行状态 |
|---|---|---|---|
| Kafka 2.7 | 100+ 套 | ~2,000 Brokers | ✅ 稳定运行 |
| Elasticsearch 7.7 | 40+ 套 | ~200 节点 | ✅ 稳定运行 |
| MySQL 5.7 / MariaDB 10.2 | 1,000+ 复制集 | 1,000+ Pods | ✅ 稳定运行 |
| 合计 | 1,100+ 集群 | 3,200+ 实例 | - |
📊 我们的收获
| 维度 | 改进效果 |
|---|---|
| 运维效率 | 多引擎统一管理,学习成本降低,一个团队即可管理数千实例 |
| 变更安全 | OpsRequest 封装,误操作风险大幅降低 |
| 扩展能力 | Addon 机制灵活,快速适配企业需求 |
最佳实践清单
1. 善用 Addon 扩展机制
-
零代码开发 Operator :KubeBlocks 的核心控制器已经通过 ComponentDefinition 抽象了数据库通用的生命周期管理(如扩缩容、故障转移),通过 ComponentVersion 抽象了版本管理等能力。无需为引入一个新引擎而去学习 Go 语言开发复杂的 Operator,只需编写声明式的 YAML 配置即可完成接入
-
兼顾通用性与个性化:Addon 的 API 设计不仅覆盖了主从、分片等主流数据库架构,还允许灵活注入特有的 Sidecar(监控、安全审计等)、自定义初始化和运行逻辑、自定义参数列表等, 实现了标准产品与定制需求的完美融合。
2. OpsRequest 是运维利器
-
所有变更操作通过 OpsRequest 执行
-
便于审计、回溯和自动化
-
复杂操作可定义为
OpsDefinition
3. 生产环境务必使用 OnDelete
-
可控的滚动升级更安全
-
异常可随时暂停
-
可与现有运维体系集成
4. 积极参与社区
-
遇到问题及时反馈
-
贡献 Addon 回馈社区
七、未来展望
随着 KubeBlocks 的持续演进,我们期待:
-
Parameter API 增强:支持更多配置格式(如 JVM Options),实现更全面的参数和配置管理,以便通过 Reconfigure OpsRequest 进行配置更新
-
InstanceTemplate 优化:进一步提升复杂场景下的稳定性。我们在使用 InstanceTemplate 的集群中偶遇 OpsRequest Reconciler 卡住的问题
我们也将持续参与 KubeBlocks 社区建设,分享更多生产实践经验,与社区一起推动数据库云原生技术的发展。
结语
KubeBlocks 为唯品会的数据库云原生之路提供了坚实的基础。通过统一的 API 抽象、灵活的 Addon 机制、强大的 OpsRequest 能力,我们成功构建了一套管理 1,100+ 集群、3,200+ 实例 的高效、可靠、可扩展的数据库运维平台。这不仅证明了 KubeBlocks 的技术成熟度,也为更多企业的数据库云原生化转型提供了可参考的实践路径。
如果你也面临类似挑战:
-
多种数据库引擎需要统一管理
-
存量系统需要平滑迁移
-
大规模集群需要可控变更
欢迎尝试 KubeBlocks,也欢迎加入社区交流!
作者:唯品会基础架构团队
*🔗 *快速上手
*> - GitHub: github.com/apecloud/kubeblocks(https://github\\.com/apecloud/kubeblocks*\\) ⭐ Star 支持我们
*> - 官方文档: kubeblocks.io/docs(https://kubeblocks\\.io/docs*\\)
*> - Addons 仓库: github.com/apecloud/kubeblocks-addons(https://github\\.com/apecloud/kubeblocks\\-addons*\\)
*> - 社区 Slack: 加入讨论(https://kubeblocks\\.io/community*\\)