复制集解决了「单点故障」,但没解决「单机装不下」。一台服务器的内存、磁盘、CPU 都有物理上限,当数据量或负载超过单机承受能力,加内存换 CPU 的边际效益越来越低,最终撞上物理天花板。这时候唯一的出路是分片(sharding)------把数据分散到多个节点,让集群整体能力超过任何单机。
这一阶段(24--30)围绕分片集群展开。但开篇要先把一个关键认知摆正:分片不是「让 MongoDB 更好」的功能,而是单机到顶后的无奈手段。它带来巨大的架构复杂度和运维成本,能不用就不用。这一篇讲清楚分片存在的理由,以及什么时候真的该上它。
先把机制边界说清楚
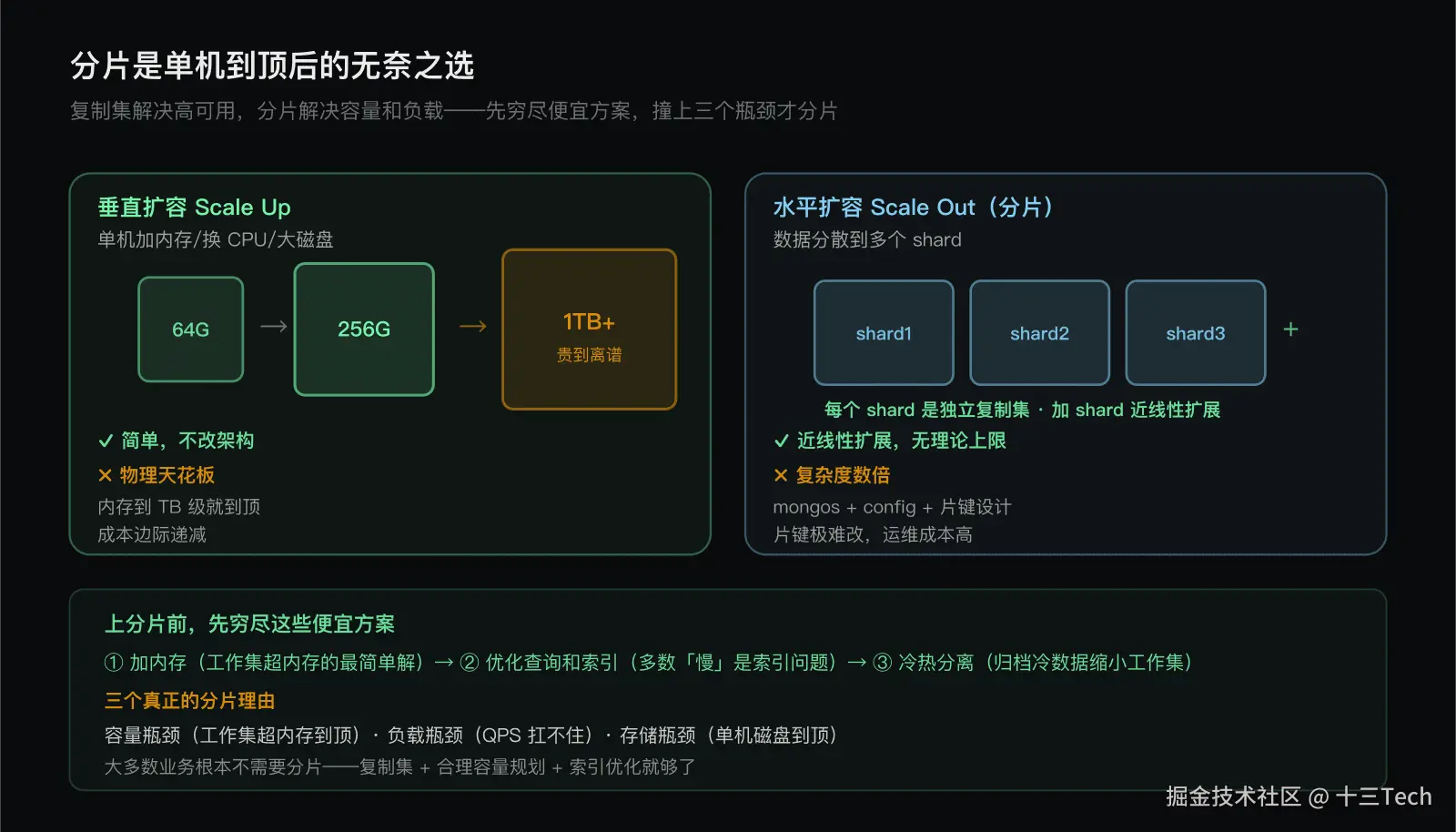
数据库扩容有两种方向:
- 垂直扩容(Scale Up):单机加内存、换更大磁盘、升级 CPU。简单,不用改架构,但有物理上限,且大配置服务器成本极高。
- 水平扩容(Scale Out / 分片):把数据分散到多个节点,每个节点存一部分。近线性扩展,但架构复杂。
MongoDB 的复制集本质还是「数据在多台机器上各有完整副本」,单台的数据量没减少------三节点复制集,每台都存全量数据。所以复制集解决高可用,不解决容量。容量问题要靠分片:分片后,每个 shard(分片)只存一部分数据,单台的数据量减少了。
垂直扩容的天花板

垂直扩容到顶有几个硬限制:
内存上限。单台服务器内存几百 GB 到 TB 级就到顶了(再大要么没有这种规格,要么贵到离谱)。工作集超过这个上限,加内存就无效了。
成本边际递减。内存从 64GB 加到 256GB 还算合理,从 256GB 加到 1TB 成本可能是前者的好几倍,性价比急剧下降。
单点风险随规模上升。单机存的数据越多,它故障的影响越大。虽然复制集能容灾,但单机故障后的恢复(全量初始化)时间也越长。
分片怎么解决问题
分片把数据按某个键(片键)分散到多个 shard,每个 shard 是一个独立的复制集(本身有高可用)。这样:
- 容量分散:1TB 数据分到 4 个 shard,每个 shard 只存 256GB,单机内存装得下工作集。
- 负载分散:写入和查询分散到多个 shard,单 shard 的负载降低。
- 近线性扩展:加 shard 就能扩容,理论上没有上限(实际受片键和跨片查询限制)。
代价是架构复杂度大增,这是接下来几篇要展开的:要引入 mongos(路由)、config server(元数据)、设计片键、处理块迁移、应对跨片查询。分片集群的运维复杂度是复制集的数倍。
什么时候真的该上分片
这是最关键的判断------大多数业务根本不需要分片。上分片前,先问这几个「更便宜的替代方案」能不能解决问题:
- 加内存:工作集超过内存,加内存是最简单的解法。只要单机还能装下,就别分片。
- 优化查询和索引:很多「性能不够」其实是索引没建对、查询没优化,不是容量问题。先把索引和查询优化做到位(阶段二的内容)。
- 冷热分离:把冷数据归档到单独的集合或实例,让热集合的工作集变小。这通常能争取很多时间。
只有这些手段都用尽,仍然撞上下面三个瓶颈之一,才该考虑分片:
容量瓶颈:工作集持续增长,单机加内存到顶仍装不下。这是最硬性的分片理由。
负载瓶颈:写入 QPS 高到单机扛不住(比如 IoT 海量设备上报、日志收集)。单机的 CPU 和 IO 成了天花板。
存储瓶颈:数据量超过单机磁盘容量,或单机存储成本不合理。
分片的不可逆性
分片有一个特殊性质让它的决策格外慎重:片键一旦选定,极难更改。改片键要重新分布所有数据,是个巨大且危险的工程(虽然新版有 reshardCollection,但仍是大操作)。片键选错,可能导致数据倾斜、热点、查询全广播,且很难回头。
所以分片决策不是「先上了再说」,而是「确信需要,且仔细设计片键」后再上。片键设计是整个分片阶段的核心,第 26 篇会专门展开。
判断框架
- 分片是单机到顶后的手段,不是常规优化手段。
- 先穷尽更便宜的方案:加内存、优化查询索引、冷热分离。
- 三个真正的分片理由:工作集超内存(容量)、QPS 扛不住(负载)、存储到顶。
- 复制集能解决高可用,分片解决容量和负载,不要混淆。
- 分片一旦上线,片键极难改,决策要慎重。
- 分片复杂度是复制集数倍,运维成本要提前评估。

放到生产里看:分片存在理由
我更愿意把它理解成:分片解决单机存储、写入和工作集上限,把数据拆到多个 shard。
做容量或可靠性判断时,分片不是性能银弹,片键差会让集群更慢更难维护。 分片和治理问题不能只看节点数量,要看片键、chunk、路由命中、热点和恢复演练。
把问题再问深一层
追问一:这个设计等到数据增长后会先暴露什么问题?
分片解决单机存储、写入和工作集上限,把数据拆到多个 shard。
追问二:什么情况下这个结论会失效?
分片不是性能银弹,片键差会让集群更慢更难维护。
追问三:用哪些证据确认它真的成立?
看单机瓶颈是否明确,评估片键、查询路由和跨片操作比例。
下一篇讲分片集群的架构三件套:mongos、config server、shard。
关于十三Tech
我是十三,长期关注服务端架构、数据库、中间件和 AI 工程实践。
我相信好的技术文章应该能回到真实系统里,帮人少踩一次坑。
关于十三Tech
All in AI Agent 方向的架构师,专注 AI 工程实践。
相信 AI 是程序员的最佳搭档,帮助每一位开发者驾驭 AI。
邮箱:569893882@qq.com GitHub:github.com/TriTechAI 公众号搜索「十三Tech」