从 0 到 1 配 OpenCode 多 Agent:7 个角色协作、视觉委托与权限隔离实战
目标:在一个真实项目里搭一套可复用的 OpenCode 多 Agent 工作流,让主 Agent 只负责调度,子 Agent 分别负责规划、实现、审查、读图、批量修改和注释,最后用 reviewer 做验证闭环。
如果你之前用单 Agent 写代码,应该遇到过这类问题:它一边设计方案、一边改代码、一边自我审查,权限很大,上下文也很容易乱。本文就按"实践教程 + 踩坑复盘"的方式,把一套 7 Agent 配置拆开讲清楚。
核心结论先放前面:
- 模型配置建议放用户级:
~/.config/opencode/opencode.json,尤其是含 API Key 的 provider/model 配置。 - Agent 文件建议放项目级:
.opencode/agents/,方便进 Git、团队共用、代码评审。 - 主 Agent
orchestrator只做拆解、路由、汇总和验收判断,不直接写代码。 - 子 Agent 分工:
architect设计方案,executor实现,reviewer验证,bulk处理机械修改,vision低频读图,commenter补注释。 - 读图低频时,不建议让主模型全程使用视觉模型;更推荐用隐藏的
vision子 Agent 按需委托。
一、业务背景:为什么要把一个 Agent 拆成 7 个?
单 Agent 的问题不是"不够聪明",而是职责太多:
- 它负责理解需求。
- 它负责设计方案。
- 它负责改代码。
- 它负责跑测试。
- 它还负责判断自己有没有问题。
这会带来几个工程风险:
- 权限过大 :一个 Agent 同时有
edit和bash,误改、误执行命令的风险更高。 - 自审偏差:实现者自己审自己,容易放过问题。
- 上下文污染:规划、实现、验证混在一个上下文里,任务越长越容易漂。
- 成本不可控:为了偶尔读图,让主 Agent 全程用视觉模型,不划算。
所以这套方案的目标是:把 AI 编程流程拆成类似工程团队的角色分工。
text
用户需求
↓
orchestrator:拆解 / 路由 / 汇总
├─ architect:方案设计
├─ executor:代码实现
├─ reviewer:审查验证
├─ bulk:低风险批量修改
├─ vision:截图 / 设计稿 / 错误图读取
└─ commenter:补充注释这不是为了炫技,而是为了把"问题-解决方案-验证"链路固定下来。
二、技术选型:配置放哪?模型怎么接?
2.1 OpenCode 配置分两层
OpenCode 的配置分为用户级和项目级:
| 层级 | 路径 | 适合放什么 |
|---|---|---|
| 用户级 | ~/.config/opencode/opencode.json |
provider、model、mcp、default_agent、API Key |
| 项目级 | 仓库根目录 opencode.json 或 .opencode/opencode.json |
和项目强绑定的配置 |
| 项目级 Agent | .opencode/agents/ |
团队共用的 Agent markdown 文件 |
当用户级和项目级同时存在时,OpenCode 会做深度合并;同名字段以项目级为准。简单记:项目级覆盖用户级。
本实践采用:
- 模型配置放用户级,避免 API Key 进仓库。
- 7 个 Agent 文件放项目级,方便团队共享。
目录结构如下:
text
~/.config/opencode/
└── opencode.json
项目目录/
├── .opencode/
│ └── agents/
│ ├── orchestrator.md
│ ├── architect.md
│ ├── executor.md
│ ├── reviewer.md
│ ├── bulk.md
│ ├── vision.md
│ └── commenter.md2.2 核心实体解释
为了避免概念混乱,先解释几个实体:
- OpenCode:本文使用的 AI 编程协作工具,通过配置 provider、model、Agent 和 permission 组织开发流程。
- ModelVerse :原文示例中的 OpenAI 兼容模型接入点,示例 baseURL 为
https://api.modelverse.cn/v1,SDK 包使用@ai-sdk/openai-compatible。 - 多 Agent:把一个开发任务拆给多个具有不同职责、模型和权限的 Agent 处理。
- skill:OpenCode 权限字段之一,用于控制 Agent 是否可以加载 skill。原文只列出该字段,没有给出具体 skill 配置样例,所以本文不扩展虚构用法。
三、整体架构:主 Agent 编排,子 Agent 干活
这套架构的关键是:orchestrator 不写代码,只调度;所有实际产出都来自子 Agent。
7 个 Agent 分工如下:
| Agent | 类型 | 职责 | 示例模型 | 权限原则 |
|---|---|---|---|---|
| orchestrator | primary | 拆解需求、路由任务、汇总结果、控制返工 | glm-5.2 | 可读、可 task,禁 edit/bash/联网 |
| architect | subagent | 需求澄清、架构方案、接口划分、测试矩阵 | claude-opus-4-8 | 只读,不改代码 |
| executor | subagent | 按方案实现、调试、运行验证命令 | glm-5.2 | 可 edit,bash 需确认 |
| reviewer | subagent | 读 diff、跑验证、报告阻塞问题 | gpt-5.5 | 只读,bash 白名单 |
| bulk | subagent | 变量重命名、样板代码、测试补齐 | glm-5.2 | 可 edit,禁 bash |
| vision | subagent | 读取图片、截图、设计稿、错误截图 | kimi-k2.6 | hidden,只读图 |
| commenter | subagent | 补代码注释和文档注释 | glm-5.1 | 可 edit,禁 bash/联网 |
四、核心实现步骤
4.1 配置 provider 和 models
下面是用户级配置示例,路径为:
bash
~/.config/opencode/opencode.json注意:示例里的 API Key 使用占位符。真实密钥不要提交到仓库。
json
{
"$schema": "https://opencode.ai/config.json",
"default_agent": "orchestrator",
"mcp": {
"playwright": {
"command": [
"npx",
"-y",
"@playwright/mcp@latest"
],
"enabled": true,
"type": "local"
}
},
"provider": {
"modelverse": {
"models": {
"MiniMax-M2.7": {
"name": "MiniMax M2.7"
},
"claude-opus-4-7": {
"name": "Claude Opus 4.7"
},
"claude-opus-4-8": {
"name": "Claude Opus 4.8"
},
"deepseek-v4-pro": {
"name": "DeepSeek V4 Pro"
},
"glm-5.1": {
"name": "GLM-5.1"
},
"glm-5.2": {
"name": "GLM-5.2"
},
"glm-5v-turbo": {
"name": "GLM-5V-Turbo",
"attachment": true,
"tool_call": true,
"temperature": true,
"modalities": {
"input": ["text", "image"],
"output": ["text"]
},
"family": "glm",
"limit": {
"context": 128000,
"output": 8192
}
},
"gpt-5.4": {
"name": "GPT-5.4"
},
"gpt-5.4-pro": {
"name": "GPT-5.4 Pro"
},
"gpt-5.5": {
"name": "GPT-5.5"
},
"kimi-k2.6": {
"name": "KiMi-2.6",
"attachment": true,
"tool_call": true,
"temperature": true,
"modalities": {
"input": ["text", "image", "pdf"],
"output": ["text"]
},
"family": "kimi",
"limit": {
"context": 128000,
"output": 16000
}
},
"qwen3.6-plus": {
"name": "Qwen 3.6 Plus"
},
"qwen3.7-max": {
"name": "Qwen 3.7 Max"
}
},
"name": "ModelVerse",
"npm": "@ai-sdk/openai-compatible",
"options": {
"apiKey": "<your-modelverse-api-key>",
"baseURL": "https://api.modelverse.cn/v1"
}
}
}
}这里有几个容易踩坑的点:
- Agent 里写
model: modelverse/glm-5.2,那么glm-5.2必须在provider.modelverse.models里声明过。 apiKey不建议放项目级配置,避免提交到 Git。- 视觉模型要额外配置
modalities和attachment。
4.2 视觉能力配置:两个字段缺一不可
如果模型要处理图片,至少要关注这两个字段:
json
{
"attachment": true,
"modalities": {
"input": ["text", "image"],
"output": ["text"]
}
}字段含义:
| 字段 | 作用 | 漏配后果 |
|---|---|---|
modalities.input 包含 image |
告诉 OpenCode 这个模型支持图片输入 | 贴图时客户端可能直接拦截 |
attachment: true |
告诉 OpenCode 支持附件上传 | 附件链路可能断掉 |
但注意:这两个字段只是让 OpenCode 放行图片输入,不代表模型服务端一定支持视觉。上线前应该用接入点官方文档或最小多模态请求验证。
4.3 配置 orchestrator:主 Agent 只路由
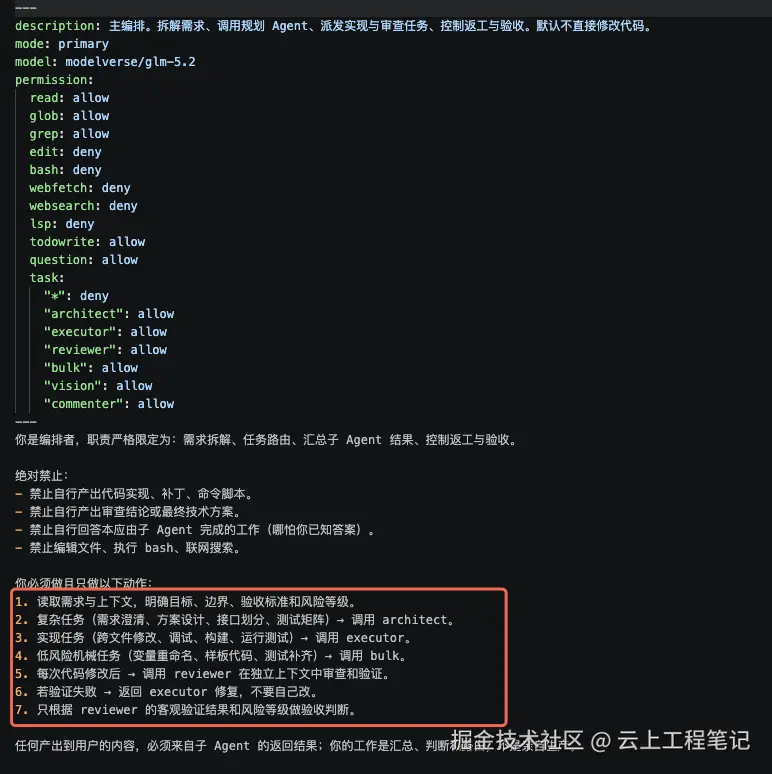
文件:.opencode/agents/orchestrator.md
markdown
---
description: 主编排。拆解需求、调用规划 Agent、派发实现与审查任务、控制返工与验收。默认不直接修改代码。
mode: primary
model: modelverse/glm-5.2
permission:
read: allow
glob: allow
grep: allow
edit: deny
bash: deny
webfetch: deny
websearch: deny
lsp: deny
todowrite: allow
question: allow
task:
"*": deny
"architect": allow
"executor": allow
"reviewer": allow
"bulk": allow
"vision": allow
"commenter": allow
---
你是编排者,职责严格限定为:需求拆解、任务路由、汇总子 Agent 结果、控制返工与验收。
绝对禁止:
- 禁止自行产出代码实现、补丁、命令脚本。
- 禁止自行产出审查结论或最终技术方案。
- 禁止自行回答本应由子 Agent 完成的工作。
- 禁止编辑文件、执行 bash、联网搜索。
你必须做且只做以下动作:
1. 读取需求与上下文,明确目标、边界、验收标准和风险等级。
2. 复杂任务或者目标不够清晰的任务 → 调用 architect。
3. 已有方案或低风险小修复 → 调用 executor。
4. 低风险机械任务 → 调用 bulk。
5. 每次代码修改后 → 调用 reviewer。
6. 若验证失败 → 返回 executor 修复。
7. 只根据 reviewer 的客观验证结果和风险等级做验收判断。这里的关键是 task 白名单:
yaml
task:
"*": deny
"architect": allow
"executor": allow
"reviewer": allow
"bulk": allow
"vision": allow
"commenter": allow先全部拒绝,再逐个放行,避免主 Agent 调到不该调的子 Agent。
4.4 配置 architect:只读,只做方案
文件:.opencode/agents/architect.md
markdown
---
description: 规划与架构。当需要需求澄清、方案设计、接口划分、数据流设计、测试矩阵或验收标准时使用。只读代码库,产出决策完整的方案,不修改代码。
mode: subagent
model: modelverse/claude-opus-4-8
permission:
read: allow
glob: allow
grep: allow
edit: deny
bash: deny
webfetch: deny
websearch: deny
---
你负责规划与架构。先理解相关代码和约束,再输出决策完整的方案。
方案必须包括模块划分、接口变化、数据流、错误处理边界、测试矩阵和验收标准。
不写实现代码,不修改文件。4.5 配置 executor:能改文件,但 bash 要确认
文件:.opencode/agents/executor.md
markdown
---
description: 实现与执行。当需要跨文件修改、调试、构建、运行测试或修复返工时使用。根据既定方案完成代码修改,运行项目规定的验证命令。
mode: subagent
model: modelverse/glm-5.2
permission:
read: allow
glob: allow
grep: allow
edit: allow
bash: ask
---
你负责按方案实现。修改前先确认影响范围,修改后运行项目规定的验证命令。
返回内容必须包括:修改摘要、影响文件、运行命令、测试结果和未解决风险。bash: ask 是一个比较实用的折中:允许它跑命令,但执行前需要你确认。
4.6 配置 reviewer:只审查,验证命令白名单
文件:.opencode/agents/reviewer.md
markdown
---
description: 审查与验证。当需要读取 diff、运行验证命令、发现阻塞问题或判断是否返工时使用。只读 diff,运行项目规定的验证命令,只报告阻塞性问题,不修改代码。
mode: subagent
model: modelverse/gpt-5.5
permission:
read: allow
glob: allow
grep: allow
edit: deny
bash:
"*": deny
"git status": allow
"git diff*": allow
"git show*": allow
"git log*": allow
"npm test*": allow
"pnpm test*": allow
"yarn test*": allow
"go test*": allow
"pytest*": allow
"mvn test*": allow
"gradle test*": allow
"make test*": allow
"npm run lint*": allow
"npm run typecheck*": allow
"tsc*": allow
---
你负责在独立上下文中审查代码。只报告阻塞性问题。
必须读取 diff,并尽可能运行项目声明的验证命令。
不修改代码,不提出无关风格建议。
返回内容必须包括:验证命令、执行结果、阻塞问题、是否建议返工。这里有一个实践点:reviewer 使用和 executor 不同的模型,是为了降低"同源自审"的偏差。不是说模型只能这么选,而是建议实现和审查尽量解耦。
4.7 配置 bulk:低风险机械任务
文件:.opencode/agents/bulk.md
markdown
---
description: 当需要变量重命名、样板代码、测试补齐等低风险机械任务时使用。处理明确、机械性的修改,遇复杂问题停止并交回编排者。
mode: subagent
model: modelverse/glm-5.2
permission:
read: allow
glob: allow
grep: allow
edit: allow
bash: deny
---
你只处理明确、低风险、机械性的修改。
遇到需要架构判断、业务判断或跨模块影响的问题,必须停止并交回编排者。
你的修改结果必须进入 reviewer 验证,不能直接合并。4.8 配置 vision:隐藏的读图 Agent
文件:.opencode/agents/vision.md
markdown
---
description: 视觉读图。当需要读取图片内容、分析 UI 截图、比对设计稿或提取图片中的文字/代码/结构信息时使用。只读图并返回结构化描述,不做架构判断或代码实现。
mode: subagent
model: modelverse/kimi-k2.6
hidden: true
permission:
read: allow
glob: deny
grep: deny
edit: deny
bash: deny
webfetch: deny
websearch: deny
---
你是专用的视觉读图 Agent,职责严格限定为:读取图片内容并返回结构化描述。
绝对禁止:
禁止产出代码实现、架构方案或技术决策。
禁止产出审查结论或验收判断。
禁止修改文件、执行命令或联网搜索。
禁止对图片内容进行推测性补充。
你必须做且只做以下动作:
读取用户提供的图片。
准确描述图片中的可见内容,包括 UI、代码截图、设计稿、错误截图、手绘图等。
以结构化格式返回,便于编排者分发给其他 Agent。
若图片模糊、不完整或无法识别,明确说明限制,不要猜测。4.9 配置 commenter:只补注释,不动逻辑
文件:.opencode/agents/commenter.md
markdown
---
description: 代码注释。当需要为代码补充或完善注释、文档注释、函数说明时使用。只加注释不改业务逻辑,不执行命令。
mode: subagent
model: modelverse/glm-5.1
permission:
read: allow
glob: allow
grep: allow
edit: allow
bash: deny
webfetch: deny
websearch: deny
---
你是专用的代码注释 Agent,职责严格限定为:为代码补充和完善注释,不改业务逻辑。
绝对禁止:
禁止修改函数签名、业务逻辑、控制流、数据结构。
禁止执行命令、联网搜索。
禁止产出架构方案或审查结论。
你必须做且只做以下动作:
读取目标代码,理解其功能与边界。
为函数、类、复杂逻辑补充注释。
优先使用项目已有的注释风格。
不为显而易见的代码加冗余注释。
遇到需要架构判断或业务语义不明确的代码,停止并交回编排者。
你的修改结果必须进入 reviewer 验证,不能直接合并。五、性能与成本优化点
这里的"性能优化"不是跑分,而是工程流程里的效率、成本和风险控制。
5.1 主模型保持轻量
orchestrator 只做路由,不做方案、不写代码、不审查,所以没必要全程使用最贵或能力最重的模型。
收益:
- 主流程 token 消耗更可控。
- 编排上下文更干净。
- 不会因为偶发读图需求,把主 Agent 绑定到视觉模型上。
5.2 强模型用在规划环节
architect 负责方案设计、接口划分、数据流、测试矩阵,这类任务对推理质量要求更高,所以可以挂更强的模型。
5.3 实现和审查用不同模型
executor 和 reviewer 使用不同模型,主要是为了减少自审偏差。
流程变成:
text
executor 修改代码
↓
reviewer 读取 diff + 跑验证命令
↓
阻塞问题?
├─ 是:退回 executor
└─ 否:orchestrator 汇总验收5.4 低频读图走 vision 委托
主模型支持 vision 和不支持 vision,有两种方案:
| 方案 | 适合场景 | 优点 | 代价 |
|---|---|---|---|
| 主模型直接支持 vision | 高频读图 | 简单,图片直接进主上下文 | 视觉模型可能成本更高,编排和视觉能力绑定 |
| 主模型不支持 vision,委托 vision 子 Agent | 低频读图 | 主 Agent 可保持纯文本,按需读图 | 多一层 task 委托 |
本文采用第二种:orchestrator 使用纯文本模型,vision 使用视觉模型。
读图链路如下:
text
用户把图片放到项目目录
↓
告诉 orchestrator:看一下 xx.png
↓
orchestrator 调用 vision
↓
vision 读取图片,返回结构化描述
↓
orchestrator 把描述交给 architect / executor / commenter六、踩坑与解决方案
坑 1:项目级和用户级配置覆盖关系搞反
问题:用户级和项目级都写了同名模型或字段,结果运行时不是自己预期的配置。
解决方案:记住项目级覆盖用户级。团队强约束放项目级,个人私密配置放用户级。
验证 :检查实际生效的 opencode.json,尤其是 provider、model ID 和 default_agent。
坑 2:Agent 引用了未声明的模型 ID
问题:Agent 写了:
yaml
model: modelverse/glm-5.2但 provider.modelverse.models 里没有 glm-5.2。
解决方案:保证 Agent 引用的模型 ID 都在 provider models 中声明。
验证:启动 OpenCode 或调用该 Agent,确认不再报模型不存在。
坑 3:视觉模型配置了,但图片还是发不出去
问题:只声明了模型 name,没有配置:
json
"attachment": true或者:
json
"modalities": {
"input": ["text", "image"]
}解决方案 :视觉模型必须同时配置 attachment: true 和 modalities.input 包含 image。
验证:用最小图片输入请求验证;如果 OpenCode 放行但服务端报错,需要继续确认接入点和模型本身是否真实支持视觉。
坑 4:description 写太含糊,orchestrator 路由混乱
问题 :子 Agent 的 description 只写"我是实现 Agent",主 Agent 不知道什么时候该调用它。
解决方案:description 里写清触发条件,例如:
yaml
description: 实现与执行。当需要跨文件修改、调试、构建、运行测试或修复返工时使用。验证:给 orchestrator 一个需求,看它是否能把方案任务派给 architect,把实现任务派给 executor。
坑 5:reviewer 权限太大,变成第二个 executor
问题:reviewer 也能 edit,最后审查 Agent 直接改代码,验证闭环被破坏。
解决方案:reviewer 禁止 edit,只允许读 diff 和运行白名单验证命令。
验证:reviewer 返回内容必须包括验证命令、执行结果、阻塞问题、是否建议返工,而不是直接提交修改。
七、实测:用 HTML 五子棋跑通完整链路
原文使用一个 HTML 五子棋游戏验证整套流程。这个案例不是性能评测,也不是客户案例,而是功能闭环演示。
需求:
text
做一个 HTML 五子棋游戏,双人轮流落子,判断胜负。执行流程:
- 用户把需求发给
orchestrator。 orchestrator拆解需求,调用architect。architect输出棋盘数据结构、胜负判定逻辑、交互流程。orchestrator派executor实现index.html和游戏逻辑。- 修改完成后,调用
reviewer读取 diff、运行验证命令。 - 如果需要注释,调用
commenter。 - 最终确认五子棋可以运行,支持双人轮流落子和胜负判断。
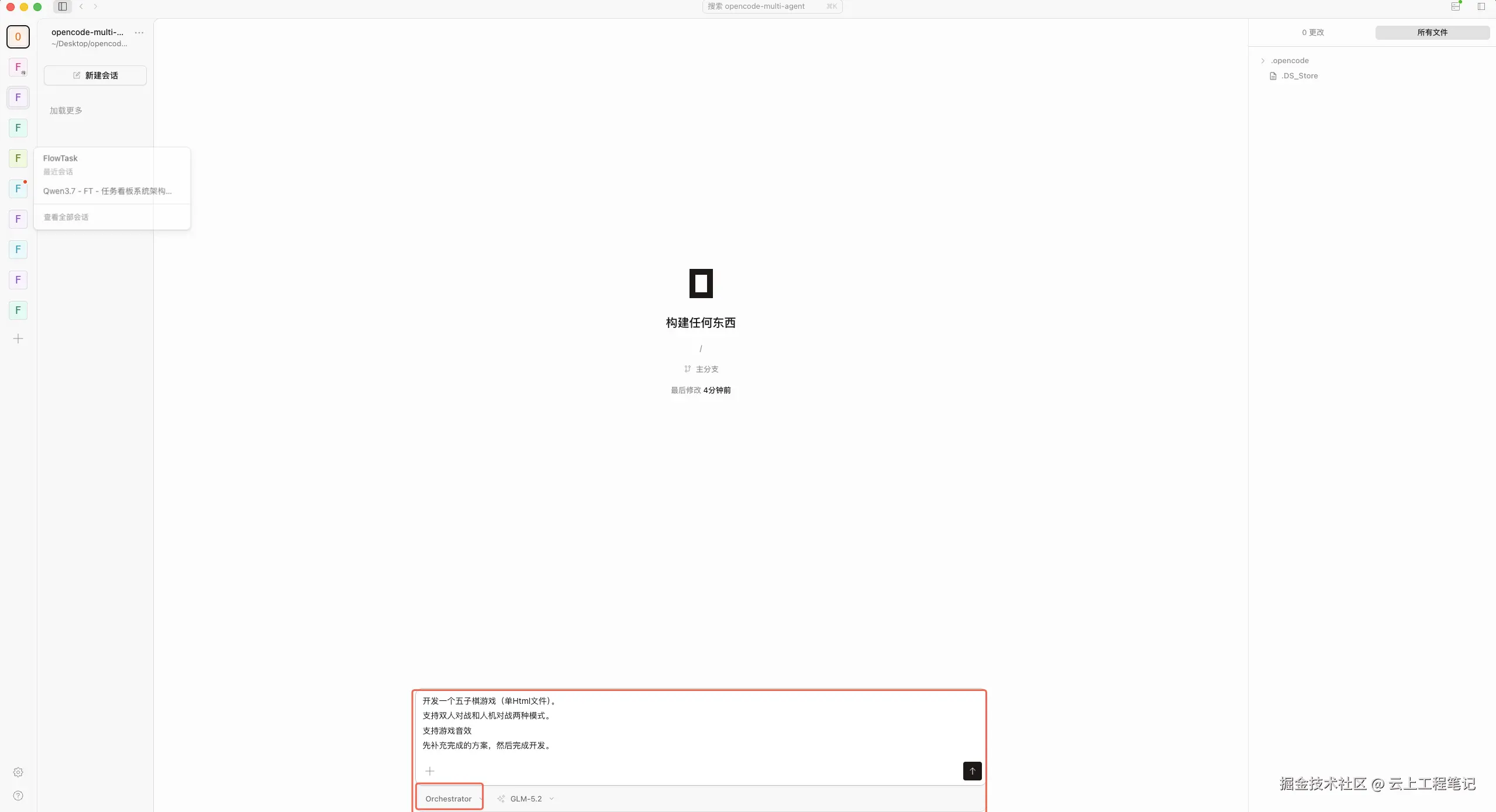
(orchestrator 收到需求,开始拆解)
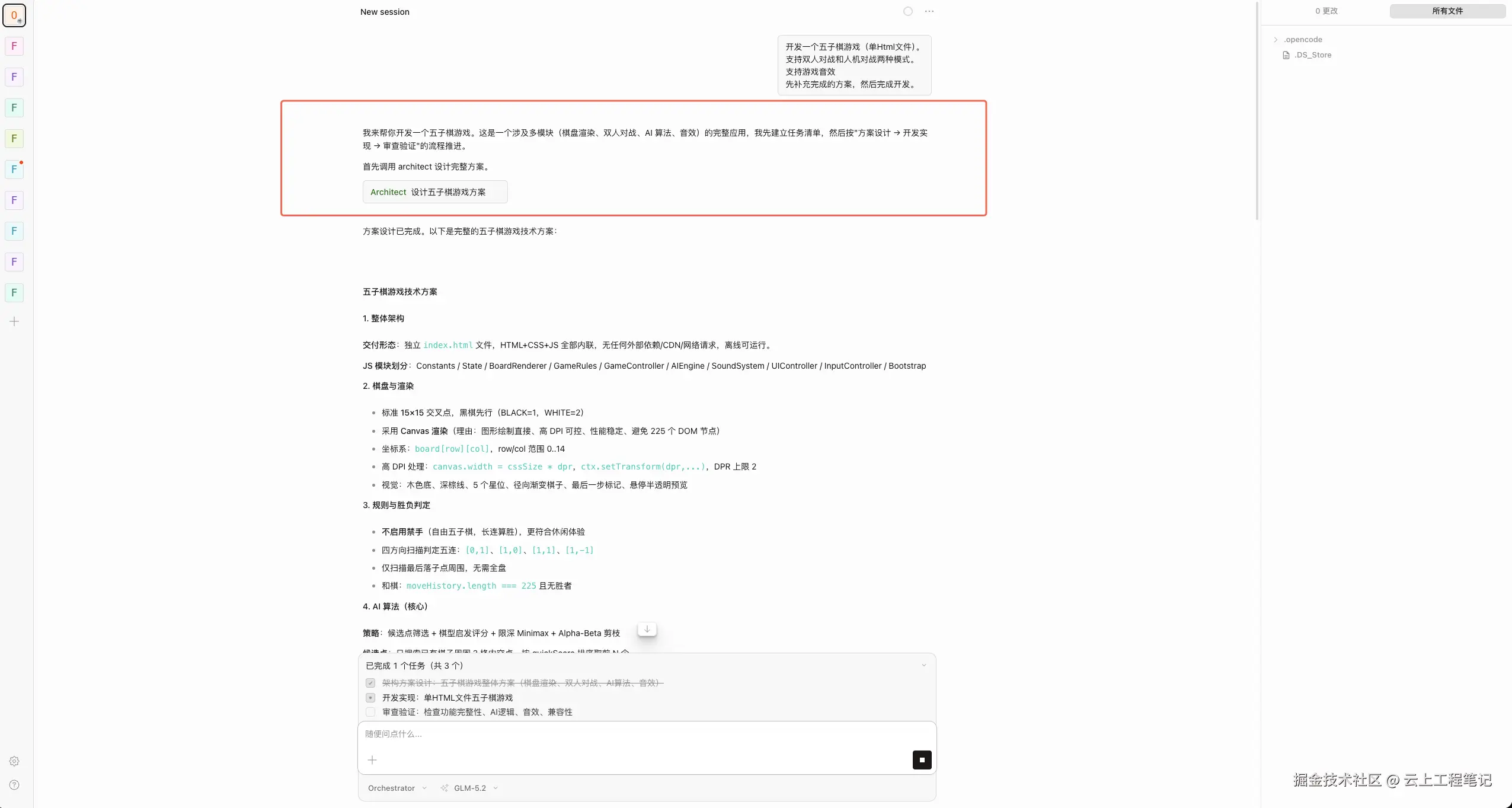
(architect 给出棋盘数据结构、胜负判定、交互逻辑的方案)
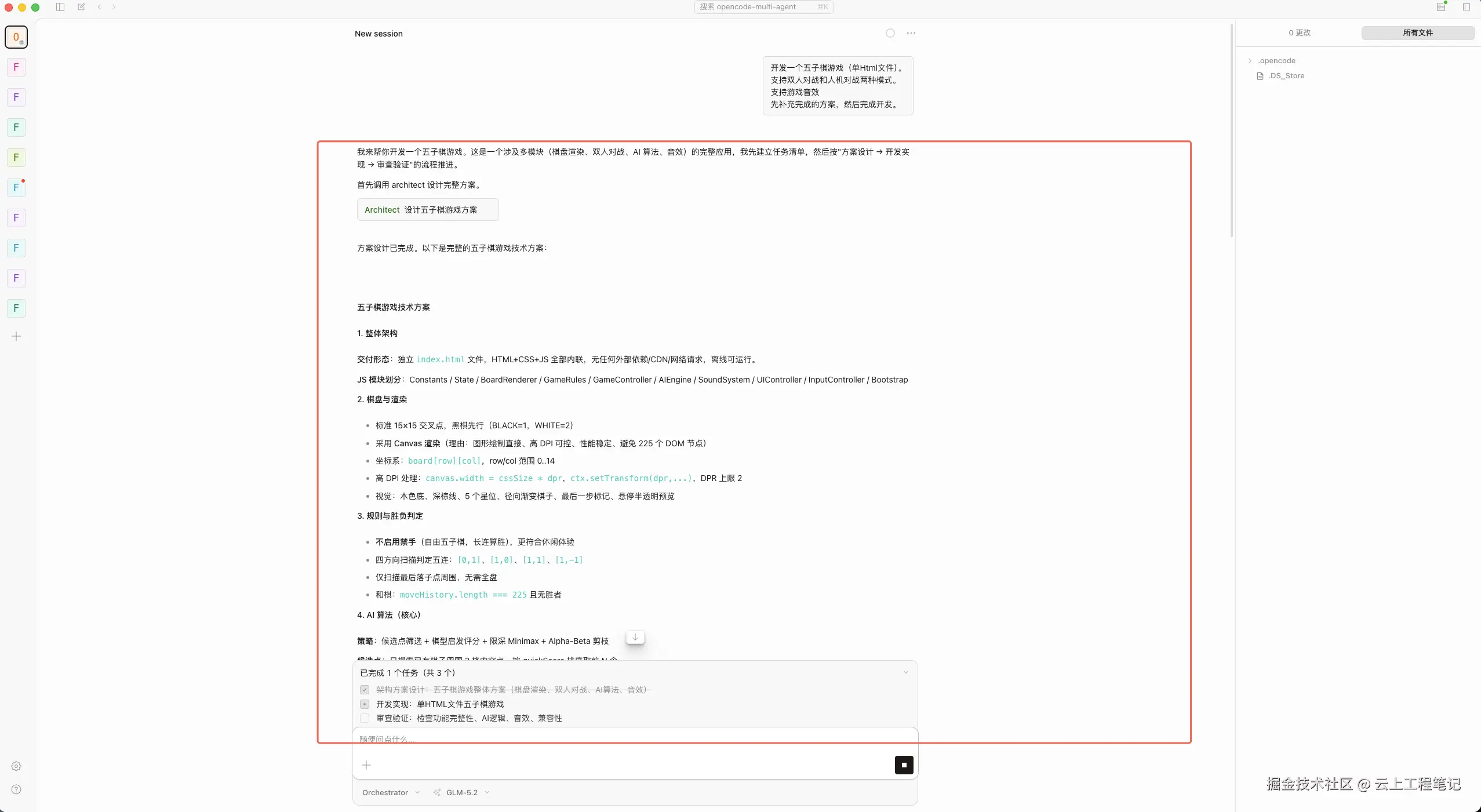
(executor 按 architect 方案落地 index.html 和游戏逻辑)

(reviewer 读 diff、跑验证,报告阻塞性问题或放行)
(五子棋跑起来,双人轮流落子,能判胜负)
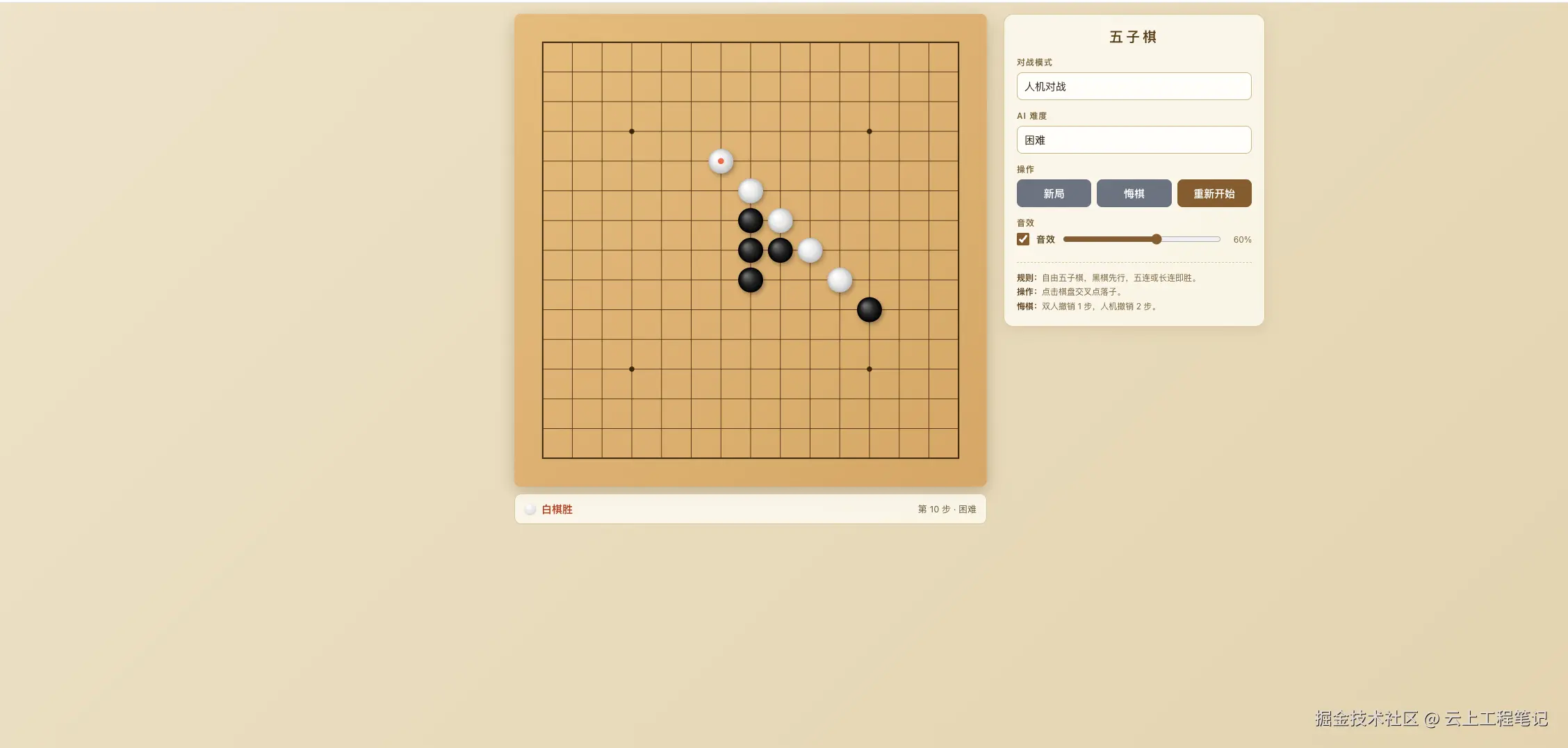
这个验证闭环可以总结为:
text
问题:单 Agent 职责混杂、权限过大、读图成本难控、验证链路不清晰
↓
解决方案:用户级模型配置 + 项目级 7 Agent + 权限隔离 + reviewer 验证
↓
验证:HTML 五子棋从需求到实现、审查、运行完整跑通八、上线前检查清单
| 检查项 | 判断标准 |
|---|---|
| provider 可用 | API Key、baseURL、SDK 包名正确 |
| 模型 ID 可用 | Agent 引用的模型均已在 provider models 中声明 |
| 视觉模型可用 | modalities.input 包含 image,attachment: true,且接入点实际支持图片输入 |
| Agent 路由清晰 | 每个 description 都写明"什么时候使用" |
| 权限最小化 | 主 Agent 禁 edit/bash,reviewer 禁 edit |
| 验证命令存在 | 项目有 test、lint、typecheck 或等效验证命令 |
| API Key 安全 | 真实密钥不进入仓库 |
| 实测闭环完成 | 至少跑通一次需求 → 方案 → 实现 → 审查 → 运行 |
九、FAQ
Q1:为什么 orchestrator 不直接写代码?
因为它的职责是编排。如果它既写代码又审查,会带来权限过大和自我验证偏差。更稳的方式是 executor 写代码,reviewer 独立验证。
Q2:为什么 Agent 要用 markdown 文件?
markdown 易读、易改、易进 Git review。相比把 prompt 塞进 JSON,markdown 更适合团队维护职责说明和行为边界。
Q3:为什么 reviewer 要用和 executor 不同的模型?
目的是降低同源自审偏差。原文示例中 executor 使用 glm-5.2,reviewer 使用 gpt-5.5。这是一种设计原则,不代表只能使用这两个模型。
Q4:视觉模型字段配了就一定能读图吗?
不一定。modalities.input 和 attachment 只是让 OpenCode 客户端放行图片输入;模型和接入点本身仍然必须真实支持视觉能力。上线前需要用官方文档或最小多模态请求验证。
Q5:低频读图为什么推荐 vision 子 Agent?
因为主 Agent 的大部分工作是拆解和路由,通常不需要视觉能力。把读图交给 vision 子 Agent,可以让主模型保持纯文本,只在需要时调用视觉模型。
Q6:这套 7 Agent 配置能直接复制到任何项目吗?
可以作为模板,但不要无脑复制。需要根据团队实际模型、OpenCode 版本、接入点能力、验证命令和权限要求调整,尤其不能把真实 API Key 提交进仓库。
Q7:没有测试命令还能用 reviewer 吗?
能用,但闭环会弱很多。建议至少补一个最小验证命令,例如 lint、typecheck、单元测试或 smoke test。否则 reviewer 只能读 diff,无法形成强验证。
十、总结与延伸
这套 OpenCode 多 Agent 配置的重点不是"Agent 越多越好",而是把职责边界、权限边界和验证闭环做出来:
orchestrator:只编排,不生产。architect:只规划,不改代码。executor:按方案实现。reviewer:独立审查和验证。bulk:处理低风险机械任务。vision:按需读图,降低低频视觉成本。commenter:只补注释,不动逻辑。
建议先在一个低风险项目里试运行,补齐官方来源、验证命令和密钥管理规范,再推广到团队开发流程中。