写 FastAPI 后端时,数据库连接不是只写一行连接串就结束了。
一个能长期维护的 MySQL 接入方式,通常要同时解决这些问题:
- Python 用什么驱动真正连上 MySQL
- ORM 用什么方式把 Python 类映射成数据库表
- 每个 HTTP 请求如何拿到独立的数据库会话
- 写操作如何提交事务,失败时如何回滚
- 项目变大后,数据库连接、模型、路由、业务逻辑分别放在哪里
先看完整流程。
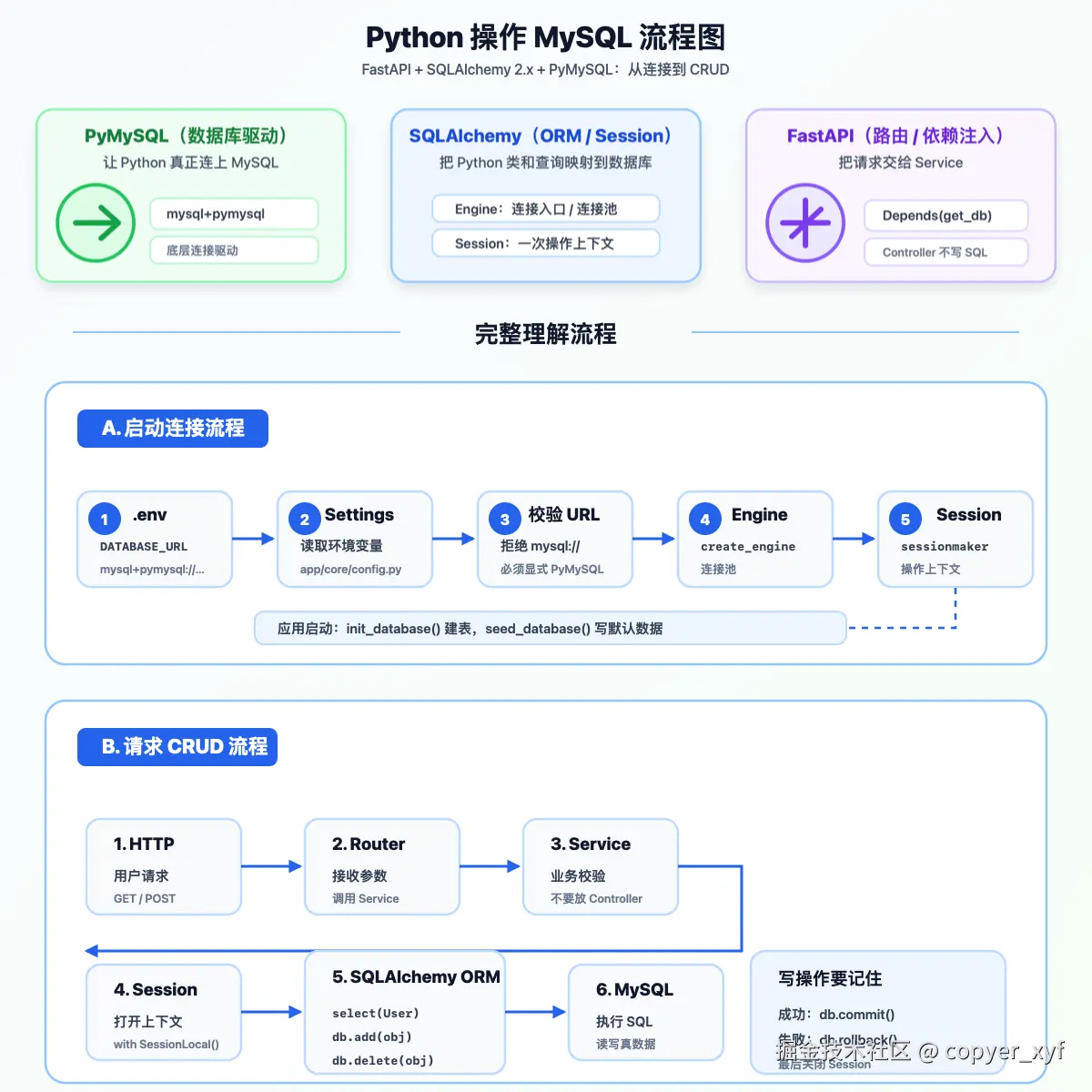
这张图可以拆成两条主线:
text
应用启动
-> 读取 DATABASE_URL
-> 创建 Engine
-> 创建 SessionLocal
-> 可选:创建表、写入初始化数据
接口请求
-> FastAPI Router 接收请求
-> Depends 注入数据库 Session
-> Service 处理业务规则
-> Repository / ORM 执行数据库读写
-> commit 或 rollback
-> 请求结束后关闭 SessionFastAPI 不直接负责连接 MySQL。它负责 HTTP、参数校验、依赖注入和响应返回。
真正跟 MySQL 打交道的是:
text
FastAPI
-> SQLAlchemy
-> PyMySQL
-> MySQL一、先把它们之间的配合讲清楚
如果只记一个关系,就记这条链路:
text
用户发起 HTTP 请求
-> FastAPI 找到对应路由函数
-> Depends 调用 get_db 创建一个 Session
-> 路由函数把 Session 交给 Service
-> Service 处理业务规则和事务
-> Repository 使用 Session 写 SQLAlchemy 查询
-> SQLAlchemy 把 ORM 查询翻译成 SQL
-> PyMySQL 把 SQL 发给 MySQL
-> MySQL 执行 SQL 并返回结果
-> SQLAlchemy 把结果转换成 Python 对象
-> FastAPI 把响应对象转换成 JSON 返回给前端这套关系里,每一层都有明确分工。
text
FastAPI
-> 管 HTTP,不管数据库底层连接
Depends / get_db
-> 管每个请求的数据库 Session 生命周期
SQLAlchemy Engine
-> 管数据库入口和连接池
SQLAlchemy Session
-> 管一次业务操作里的查询、写入、提交、回滚
SQLAlchemy ORM Model
-> 管 Python 类和数据库表之间的映射
PyMySQL
-> 管 Python 进程和 MySQL 服务之间的底层通信
MySQL
-> 真正存储和查询数据二、需要哪些第三方依赖
一个同步版 FastAPI + MySQL 项目,最少需要这些依赖:
bash
uv add "fastapi[standard]" sqlalchemy pymysql pydantic-settings如果使用 pip:
bash
pip install "fastapi[standard]" sqlalchemy pymysql pydantic-settings这些包分别负责不同层级的事情。
1. FastAPI
FastAPI 是 Web 框架,负责:
- 定义 HTTP 接口
- 解析路径参数、查询参数、请求体
- 使用 Pydantic 做数据校验
- 通过
Depends注入依赖 - 自动生成 OpenAPI 文档
这里有两个词先解释清楚。
路由 指的是"某个 HTTP 请求应该交给哪个函数处理"。例如 GET /users/1 交给 get_user 函数处理。
依赖注入 指的是"路由函数需要什么对象,由 FastAPI 在调用函数前帮你准备好"。数据库 Session 就很适合用依赖注入,因为每个请求都需要一个独立 Session,请求结束后还必须关闭。
数据库连接进入 FastAPI 的方式,通常不是在路由函数里手动创建连接,而是通过依赖注入:
python
from typing import Annotated
from fastapi import Depends
from sqlalchemy.orm import Session
# SessionDep 是一个类型别名:
# 它告诉 FastAPI,只要路由参数标注为 SessionDep,
# 就先执行 get_db(),把得到的数据库 Session 传进来。
SessionDep = Annotated[Session, Depends(get_db)]这样路由只声明"我需要一个数据库 Session",至于这个 Session 怎么创建、怎么关闭,交给统一的依赖函数处理。
2. SQLAlchemy
SQLAlchemy 是数据库工具和 ORM。
它负责:
- 创建数据库连接入口
Engine - 管理连接池
- 创建请求级
Session - 定义 ORM 模型
- 生成 SQL
- 执行增删改查
- 管理事务提交和回滚
ORM 是 Object Relational Mapping 的缩写,中文常叫"对象关系映射"。
它解决的是这件事:
text
在 Python 代码里面操作对象
在数据库里面是操作表和行
ORM 负责在两者之间做转换例如 Python 里有一个 User 类,数据库里有一张 users 表。ORM 会把 User.username 对应到 users.username 字段。这样你可以写 Python 对象和查询表达式,而不是在业务里到处拼 SQL 字符串。
使用 SQLAlchemy 后,业务代码通常不直接拼 SQL 字符串,而是操作 Python 类:
python
# select(User) 表示查询 users 表对应的 User 模型
# where(...) 表示追加查询条件
# scalar(...) 表示只取一条 ORM 对象结果
user = db.scalar(select(User).where(User.username == username))这行代码最后会被 SQLAlchemy 转成 SQL,交给底层数据库驱动执行。
3. PyMySQL
PyMySQL 是 MySQL 的 Python 驱动。
它是真正负责和 MySQL 服务通信的底层库。SQLAlchemy 自己不是 MySQL 驱动,它需要通过 DBAPI 驱动连接具体数据库。
驱动 可以理解成数据库的"适配器"。不同数据库说话方式不一样,MySQL、PostgreSQL、SQLite 都有自己的协议和细节。SQLAlchemy 负责生成 SQL 和管理 ORM,但真正打开网络连接、登录 MySQL、发送 SQL、读取结果,需要驱动来做。
DBAPI 是 Python 里数据库驱动遵循的一套接口规范。PyMySQL 实现了这套规范,所以 SQLAlchemy 可以通过它连接 MySQL。
连接 MySQL 时,SQLAlchemy URL 一般写成:
text
mysql+pymysql://用户名:密码@主机:端口/数据库名?charset=utf8mb4这里的 pymysql 就是在告诉 SQLAlchemy:
text
数据库类型是 MySQL
底层驱动使用 PyMySQL如果 MySQL 账号使用了需要 RSA 的认证方式,可以安装:
bash
uv add "pymysql[rsa]"或者:
bash
pip install "PyMySQL[rsa]"普通本地开发大多数时候只需要 pymysql。
4. pydantic-settings
pydantic-settings 用来读取环境变量和 .env 配置。
数据库连接串、是否打印 SQL、是否自动建表,这些都不应该写死在代码里,而应该放到环境变量中。
典型 .env:
env
DATABASE_URL="mysql+pymysql://root:password@127.0.0.1:3306/todo_api?charset=utf8mb4"
DATABASE_ECHO=false
DATABASE_AUTO_CREATE=false读取配置:
python
from pydantic_settings import BaseSettings, SettingsConfigDict
class Settings(BaseSettings):
# 告诉 pydantic-settings 从 .env 文件读取配置
# env_file_encoding 用来避免中文或特殊字符出现编码问题
model_config = SettingsConfigDict(
env_file=".env",
env_file_encoding="utf-8",
)
# 必填配置:没有 DATABASE_URL 时,应用应该直接启动失败
database_url: str
# 是否打印 SQL。调试时可以改成 true,正常开发一般保持 false
database_echo: bool = False
# 是否在启动时自动建表。本地 demo 可以 true,正式项目一般 false
database_auto_create: bool = False
# 创建全局配置对象。其他模块通过 settings.database_url 读取配置
settings = Settings()5. Alembic
Alembic 不是连接 MySQL 的必需依赖,但正式项目通常需要它。
它负责数据库迁移:
bash
uv add alembic为什么需要迁移工具?
因为项目上线后,表结构变化不能靠 Base.metadata.create_all() 随手创建。正式环境需要可追踪、可回滚、可审查的迁移文件。
可以先记住这个区分:
text
本地学习 / 早期 demo
-> 可以用 create_all()
团队项目 / 正式环境
-> 应该用 Alembic 管理迁移三、连接串怎么写
MySQL 连接串的完整格式:
text
mysql+pymysql://用户名:密码@主机:端口/数据库名?charset=utf8mb4示例:
env
DATABASE_URL="mysql+pymysql://root:password@127.0.0.1:3306/todo_api?charset=utf8mb4"拆开看:
text
mysql+pymysql://root:password@127.0.0.1:3306/todo_api?charset=utf8mb4
| | | | | |
用户名 密码 主机 端口 数据库名 字符集几个点要特别注意。
第一,推荐显式写 mysql+pymysql://,不要只写 mysql://。
mysql+pymysql:// 的意思更明确:MySQL 方言加 PyMySQL 驱动。团队项目里不要依赖隐式默认值,否则换环境时容易出现"本机能跑,别人机器不能跑"的问题。
第二,字符集推荐 utf8mb4。
utf8mb4 能完整支持 Unicode,包括 emoji。新项目没有必要再使用 MySQL 早期的 utf8。
第三,密码里如果有特殊字符,需要 URL 编码。
例如密码里有 @、#、/、:,连接串可能被解析错。更稳的做法是密码避免使用这些字符,或者在生成连接串时进行 URL 编码。
四、创建 Engine
Engine 是 SQLAlchemy 的数据库入口。
可以把它理解成:
text
Engine = 数据库连接入口 + 连接池这里的 连接池 指的是一组可复用的数据库连接。
如果每次请求都重新连接 MySQL,再断开连接,成本会很高。连接池会提前维护一些连接,请求来了就借一条,用完再还回去。这样后端服务可以更稳定地处理大量请求。
Engine 本身不是某一次查询,也不是某一个请求的连接。它更像应用级的数据库入口,通常在应用启动时创建一次,然后整个应用复用。
基础写法:
python
from sqlalchemy import create_engine
from app.core.config import settings
engine = create_engine(
# SQLAlchemy 根据这个 URL 判断数据库类型、驱动、账号、密码、主机和库名
settings.database_url,
# echo=True 会把 SQL 打到控制台,排查问题时很有用
echo=settings.database_echo,
# 每次从连接池取连接前先检查连接是否还活着
# MySQL 长时间空闲后可能主动断开连接,这个参数能减少断连错误
pool_pre_ping=True,
)常见参数:
echo=True:打印 SQL,适合调试echo=False:不打印 SQL,适合正常开发pool_pre_ping=True:从连接池取连接前先检查连接是否可用,减少 MySQL 空闲连接断开导致的问题
MySQL 服务端可能会关闭长时间空闲的连接。后端服务如果继续拿到这条已经失效的连接,就会在执行 SQL 时失败。pool_pre_ping=True 可以让 SQLAlchemy 在使用连接前做一次轻量检查,发现连接不可用就重新连接。
五、创建 SessionLocal
Session 是 ORM 的操作上下文。
可以把它理解成:
text
Session = 一次数据库读写上下文 + 事务边界Session 这个名字容易误会。它不是浏览器登录态里的 Session,也不是用户会话。
在 SQLAlchemy 里,Session 表示一次数据库操作上下文:它知道你查了哪些对象、改了哪些对象、哪些对象准备新增、最后要不要提交事务。
SessionLocal 则是一个"Session 工厂"。它不是具体的 Session,而是用来创建 Session 的函数式对象。每个请求进来时,都通过它创建一个新的 Session。
创建 Session 工厂:
python
from sqlalchemy.orm import sessionmaker
SessionLocal = sessionmaker(
# 这个 Session 工厂创建出来的 Session,都使用前面创建的 engine
bind=engine,
# 不在查询前自动 flush,减少隐式数据库写入时机
autoflush=False,
# 不自动提交事务。写操作完成后必须手动 db.commit()
autocommit=False,
# commit 后对象字段仍然可读,不会立刻过期
expire_on_commit=False,
)参数含义:
bind=engine:这个 Session 工厂使用哪个 Engineautoflush=False:不在查询前自动刷新变更,减少新手阶段的隐式行为autocommit=False:不自动提交事务,写操作必须显式commitexpire_on_commit=False:提交后对象字段仍可直接读取
使用方式:
python
from sqlalchemy import select
# with 负责在代码块结束后关闭 Session
# 关闭 Session 不等于关闭 MySQL 服务,而是把连接还回连接池
with SessionLocal() as db:
# select(User) 生成查询 users 表的 SQLAlchemy 查询对象
# scalars(...) 表示返回 ORM 对象,而不是原始行对象
users = db.scalars(select(User)).all()with 退出时会关闭 Session,把连接归还给连接池。
六、定义 ORM 模型
ORM 模型用 Python 类描述数据库表。
模型 指的是"数据库表在 Python 代码里的表示"。表里每一行数据,读取出来后可以变成一个 Python 对象。对象的字段,对应数据库表的列。
先定义统一的 Base:
python
from sqlalchemy.orm import DeclarativeBase
# 所有 ORM 模型都继承 Base
# SQLAlchemy 会通过 Base.metadata 收集所有表结构
class Base(DeclarativeBase):
pass再定义业务模型:
python
from datetime import datetime
from sqlalchemy import DateTime, Integer, String, func
from sqlalchemy.orm import Mapped, mapped_column
from app.db.base import Base
class User(Base):
# __tablename__ 指定这个模型对应数据库里的哪张表
__tablename__ = "users"
# primary_key=True 表示主键
# autoincrement=True 表示由 MySQL 自动生成递增 ID
id: Mapped[int] = mapped_column(Integer, primary_key=True, autoincrement=True)
# unique=True 表示数据库层面不允许重复
# nullable=False 表示这一列不能为空
username: Mapped[str] = mapped_column(String(50), unique=True, nullable=False)
email: Mapped[str] = mapped_column(String(191), unique=True, nullable=False)
# default=1 是 Python 侧默认值。创建 User 时不传 status,就默认是 1
status: Mapped[int] = mapped_column(Integer, nullable=False, default=1)
# server_default=func.now() 表示由数据库服务器生成默认时间
created_at: Mapped[datetime] = mapped_column(
DateTime(timezone=True),
server_default=func.now(),
nullable=False,
)这段代码表示:
text
User 类
-> users 表
User.username
-> users.username 字段
User.email
-> users.email 字段Mapped[...] 和 mapped_column(...) 是 SQLAlchemy 2.x 推荐的声明式写法。类型标注不仅给编辑器看,也帮助 ORM 更清楚地理解字段类型。
七、执行增删改查
1. 查询
查询全部用户:
python
from sqlalchemy import select
from sqlalchemy.orm import Session
def list_users(db: Session) -> list[User]:
return list(db.scalars(select(User)).all())按主键查询:
python
from sqlalchemy.orm import Session
def get_user(db: Session, user_id: int) -> User | None:
return db.get(User, user_id)按条件查询:
python
from sqlalchemy import select
from sqlalchemy.orm import Session
def get_user_by_username(db: Session, username: str) -> User | None:
return db.scalar(select(User).where(User.username == username))分页查询:
python
from sqlalchemy import func, select
from sqlalchemy.orm import Session
def page_users(db: Session, page: int, page_size: int) -> dict[str, object]:
# 第 1 页跳过 0 条,第 2 页跳过 page_size 条
offset = (page - 1) * page_size
# 先查总数,用来给前端显示一共有多少条数据
total = db.scalar(select(func.count()).select_from(User)) or 0
# 再查当前页数据
items = db.scalars(
select(User)
.order_by(User.id.desc())
.offset(offset)
.limit(page_size)
).all()
return {
"items": list(items),
"total": total,
"page": page,
"page_size": page_size,
}2. 新增
python
from sqlalchemy.orm import Session
def create_user(db: Session, username: str, email: str) -> User:
# 这里只是在 Python 内存里创建 ORM 对象,还没有写入数据库
user = User(
username=username,
email=email,
status=1,
)
# 加入当前 Session,表示这条数据准备新增
db.add(user)
# 提交事务后,INSERT 才会真正执行
db.commit()
# 刷新对象,拿到数据库生成的 id、created_at 等字段
db.refresh(user)
return user关键点:
db.add(user):把对象加入当前 Sessiondb.commit():提交事务,真正写入数据库db.refresh(user):从数据库刷新对象,拿到自增 ID、默认值等字段
3. 更新
python
from sqlalchemy.orm import Session
def update_user_email(db: Session, user_id: int, email: str) -> User | None:
# db.get 适合按主键查询
user = db.get(User, user_id)
if user is None:
return None
# 修改 ORM 对象字段后,SQLAlchemy 会记录这次变化
user.email = email
# commit 时 SQLAlchemy 会生成 UPDATE 语句
db.commit()
db.refresh(user)
return user只要对象是从当前 Session 查出来的,修改字段后执行 commit(),SQLAlchemy 就会生成对应的 UPDATE。
4. 删除
python
from sqlalchemy.orm import Session
def delete_user(db: Session, user_id: int) -> bool:
user = db.get(User, user_id)
if user is None:
return False
# 标记这个 ORM 对象要删除
db.delete(user)
# commit 时 SQLAlchemy 会生成 DELETE 语句
db.commit()
return True删除数据时要考虑外键约束、关联表、业务规则和是否允许物理删除。真实项目里,用户、订单、支付记录这类数据通常不会随意物理删除。
八、事务怎么处理
数据库写操作必须有清晰的事务边界。
最常见的写法是:
python
from sqlalchemy.orm import Session
def create_user_with_role(db: Session, user: User, role: Role) -> User:
try:
# 两个新增动作放在同一个事务里
db.add(user)
db.add(role)
# 两个对象都写入成功,事务才提交
db.commit()
db.refresh(user)
return user
except Exception:
# 任意一步失败,都撤销本次事务里的所有数据库变更
db.rollback()
raise事务的规则很简单:
text
全部成功
-> commit
中途失败
-> rollback也可以使用 begin() 上下文:
python
# begin 会自动管理事务:
# 正常退出自动 commit,出现异常自动 rollback
with SessionLocal.begin() as db:
db.add(user)
db.add(role)begin() 正常退出时自动提交,发生异常时自动回滚。
在业务接口里,更常见的是把 Session 交给 Service 或 Repository,然后在明确的业务动作完成后提交。这样读起来更清楚,也方便处理业务异常。
九、在 FastAPI 中注入数据库 Session
FastAPI 推荐用依赖注入管理请求级资源。
数据库 Session 的依赖函数可以这样写:
python
from collections.abc import Generator
from sqlalchemy.orm import Session
from app.db.session import SessionLocal
def get_db() -> Generator[Session, None, None]:
# 每个请求进来时,创建一个新的数据库 Session
db = SessionLocal()
try:
# yield 会把 db 交给路由函数使用
# 路由函数执行完成后,代码会继续走到 finally
yield db
finally:
# 请求结束后关闭 Session,把连接还回连接池
db.close()这段代码的行为是:
text
请求进入
-> 创建一个 Session
路由函数执行
-> 使用这个 Session 查询或写入数据库
请求结束
-> finally 关闭 Session路由里使用:
python
from typing import Annotated
from fastapi import APIRouter, Depends, HTTPException
from sqlalchemy.orm import Session
from app.dependencies.database import get_db
from app.modules.users.service import UserService
# prefix 表示这个 router 下的接口都以 /users 开头
# tags 用来给 OpenAPI 文档分组
router = APIRouter(prefix="/users", tags=["users"])
# 声明一个可复用的数据库依赖类型
# 以后路由参数写 db: SessionDep,就会自动拿到 get_db 提供的 Session
SessionDep = Annotated[Session, Depends(get_db)]
@router.get("/{user_id}")
def get_user(user_id: int, db: SessionDep) -> dict[str, object]:
# 路由层不直接写数据库查询,而是调用 Service
user = UserService.get_user(db, user_id)
if user is None:
# Service 返回 None,路由层把它转换成 HTTP 404
raise HTTPException(status_code=404, detail="User not found")
return {
"id": user.id,
"username": user.username,
"email": user.email,
}这里路由层只做三件事:
- 接收 HTTP 参数
- 调用业务逻辑
- 返回 HTTP 响应
它不负责创建数据库连接,也不直接堆很多 SQLAlchemy 查询。
十、从零搭一个可维护的工程结构
项目小的时候,一个 main.py 就能跑。
项目变大后,不建议把配置、数据库连接、模型、路由、业务逻辑都塞在一起。更稳的结构是:
text
todo-api/
├── app/
│ ├── main.py
│ ├── api/
│ │ └── v1/
│ │ └── router.py
│ ├── core/
│ │ └── config.py
│ ├── db/
│ │ ├── base.py
│ │ ├── models.py
│ │ └── session.py
│ ├── dependencies/
│ │ └── database.py
│ └── modules/
│ └── users/
│ ├── models.py
│ ├── schemas.py
│ ├── repository.py
│ ├── service.py
│ └── router.py
├── migrations/
├── tests/
├── .env
└── pyproject.toml每一层的职责要清楚。
text
app/core/config.py
-> 读取环境变量
app/db/session.py
-> 创建 Engine、SessionLocal、init_database
app/db/base.py
-> 定义 SQLAlchemy Base
app/db/models.py
-> 统一导入所有 ORM 模型,方便 create_all 或 Alembic 发现模型
app/dependencies/database.py
-> 定义 get_db
app/modules/users/models.py
-> 用户表 ORM 模型
app/modules/users/schemas.py
-> 用户接口的请求体和响应体
app/modules/users/repository.py
-> 用户相关数据库读写
app/modules/users/service.py
-> 用户业务规则
app/modules/users/router.py
-> 用户 HTTP 接口这个结构的核心原则是:
text
公共基础设施放 app/core、app/db、app/dependencies
业务代码按模块放 app/modules/{module_name}十一、核心文件怎么写
1. app/core/config.py
python
from pydantic_settings import BaseSettings, SettingsConfigDict
class Settings(BaseSettings):
# 指定 .env 文件作为本地配置来源
model_config = SettingsConfigDict(
env_file=".env",
env_file_encoding="utf-8",
)
# 应用名称,会展示在接口文档里
app_name: str = "Todo API"
# MySQL 连接串,例如 mysql+pymysql://root:password@127.0.0.1:3306/todo_api
database_url: str
# 是否打印 SQL
database_echo: bool = False
# 是否启动时自动 create_all 建表
database_auto_create: bool = False
# 全局配置对象。其他模块只读取它,不在业务代码里手写环境变量解析
settings = Settings()2. app/db/base.py
python
from sqlalchemy.orm import DeclarativeBase
# 所有 ORM 模型共同继承的基类
# 后续 User、Todo、Role 等模型都会注册到 Base.metadata 中
class Base(DeclarativeBase):
pass3. app/modules/users/models.py
python
from datetime import datetime
from sqlalchemy import DateTime, Integer, String, func
from sqlalchemy.orm import Mapped, mapped_column
from app.db.base import Base
class User(Base):
# users 是数据库里的真实表名
__tablename__ = "users"
# id 是主键,由 MySQL 自增生成
id: Mapped[int] = mapped_column(Integer, primary_key=True, autoincrement=True)
# username 和 email 都要求唯一且不能为空
username: Mapped[str] = mapped_column(String(50), unique=True, nullable=False)
email: Mapped[str] = mapped_column(String(191), unique=True, nullable=False)
# status 可以用来表示启用、禁用等业务状态
status: Mapped[int] = mapped_column(Integer, nullable=False, default=1)
# created_at 由数据库写入当前时间
created_at: Mapped[datetime] = mapped_column(
DateTime(timezone=True),
server_default=func.now(),
nullable=False,
)4. app/db/models.py
python
from app.modules.users.models import User
# 统一导出模型,方便其他地方一次性导入
__all__ = ["User"]这个文件看起来简单,但很重要。
SQLAlchemy 只有在模型类被 Python 导入后,Base.metadata 才知道有哪些表。集中导入模型,可以避免"明明写了模型,create_all 或 Alembic 却找不到表"的问题。
5. app/db/session.py
python
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from app.core.config import settings
from app.db.base import Base
from app.db import models
engine = create_engine(
# 从配置读取连接串,避免把账号密码写死在代码里
settings.database_url,
# 控制是否打印 SQL
echo=settings.database_echo,
# 防止 MySQL 空闲连接失效后,请求第一次查询就报错
pool_pre_ping=True,
)
SessionLocal = sessionmaker(
# SessionLocal 创建出的 Session 都绑定到这个 engine
bind=engine,
autoflush=False,
autocommit=False,
expire_on_commit=False,
)
def init_database() -> None:
# 只在明确开启时自动建表
# 正式项目通常使用 Alembic,不依赖 create_all
if settings.database_auto_create:
Base.metadata.create_all(bind=engine)from app.db import models 不是为了在代码里直接使用 models 变量,而是为了确保所有 ORM 模型都被导入,让 Base.metadata 收集到表结构。
6. app/dependencies/database.py
python
from collections.abc import Generator
from sqlalchemy.orm import Session
from app.db.session import SessionLocal
def get_db() -> Generator[Session, None, None]:
# 为当前请求创建 Session
db = SessionLocal()
try:
# 把 Session 交给 FastAPI 路由函数
yield db
finally:
# 无论接口成功还是失败,最终都关闭 Session
db.close()7. app/modules/users/schemas.py
python
from datetime import datetime
from pydantic import BaseModel, EmailStr
class UserCreate(BaseModel):
# 创建用户时,前端必须传 username 和 email
username: str
email: EmailStr
class UserRead(BaseModel):
# 返回给前端的用户字段
id: int
username: str
email: EmailStr
status: int
created_at: datetime如果使用 EmailStr,需要安装邮箱校验依赖:
bash
uv add "pydantic[email]"或者:
bash
pip install "pydantic[email]"如果不想加这个依赖,可以先把 EmailStr 改成普通的 str。
8. app/modules/users/repository.py
python
from sqlalchemy import select
from sqlalchemy.orm import Session
from app.modules.users.models import User
class UserRepository:
@staticmethod
def get_by_id(db: Session, user_id: int) -> User | None:
# Repository 只关心数据库怎么查
return db.get(User, user_id)
@staticmethod
def get_by_username(db: Session, username: str) -> User | None:
# 根据唯一用户名查单个用户
return db.scalar(select(User).where(User.username == username))
@staticmethod
def create(db: Session, username: str, email: str) -> User:
# 这里只 add,不 commit
# commit 由 Service 在完整业务动作结束后统一处理
user = User(username=username, email=email)
db.add(user)
return userRepository 只处理数据库读写,不写 HTTP 异常,也不关心接口怎么返回。
9. app/modules/users/service.py
python
from sqlalchemy.orm import Session
from app.modules.users.models import User
from app.modules.users.repository import UserRepository
from app.modules.users.schemas import UserCreate
class UserService:
@staticmethod
def get_user(db: Session, user_id: int) -> User | None:
# Service 可以直接复用 Repository
return UserRepository.get_by_id(db, user_id)
@staticmethod
def create_user(db: Session, data: UserCreate) -> User:
# 业务规则:用户名不能重复
exists = UserRepository.get_by_username(db, data.username)
if exists is not None:
raise ValueError("Username already exists")
try:
# 先执行数据库新增动作
user = UserRepository.create(
db,
username=data.username,
email=data.email,
)
# 业务动作完整成功后再提交事务
db.commit()
db.refresh(user)
return user
except Exception:
# 提交前或提交时出错,都回滚本次事务
db.rollback()
raiseService 负责业务规则和事务边界。
比如"用户名不能重复"属于业务规则,应该放在 Service。commit 和 rollback 也更适合放在完成一个业务动作的位置。
10. app/modules/users/router.py
python
from typing import Annotated
from fastapi import APIRouter, Depends, HTTPException, status
from sqlalchemy.orm import Session
from app.dependencies.database import get_db
from app.modules.users.schemas import UserCreate, UserRead
from app.modules.users.service import UserService
# 这个文件只定义 users 模块自己的 HTTP 接口
router = APIRouter(prefix="/users", tags=["users"])
SessionDep = Annotated[Session, Depends(get_db)]
@router.get("/{user_id}", response_model=UserRead)
def get_user(user_id: int, db: SessionDep) -> UserRead:
# 1. 路由层接收 user_id
# 2. 把 db 和 user_id 交给 Service
user = UserService.get_user(db, user_id)
if user is None:
raise HTTPException(
status_code=status.HTTP_404_NOT_FOUND,
detail="User not found",
)
# ORM 对象转换成响应模型,再由 FastAPI 转成 JSON
return UserRead.model_validate(user, from_attributes=True)
@router.post("", response_model=UserRead, status_code=status.HTTP_201_CREATED)
def create_user(data: UserCreate, db: SessionDep) -> UserRead:
try:
# data 已经被 Pydantic 校验过,这里交给 Service 处理业务
user = UserService.create_user(db, data)
except ValueError as exc:
# 业务异常在路由层转换成 HTTP 状态码
raise HTTPException(
status_code=status.HTTP_409_CONFLICT,
detail=str(exc),
) from exc
return UserRead.model_validate(user, from_attributes=True)路由层要薄。
它应该关心 HTTP 语义,比如:
- 什么路径
- 什么方法
- 什么状态码
- 请求体是什么
- 响应体是什么
- 业务异常转成什么 HTTP 错误
它不应该塞满数据库查询。
11. app/api/v1/router.py
python
from fastapi import APIRouter
from app.modules.users.router import router as users_router
api_router = APIRouter(prefix="/api/v1")
# 把 users 模块的接口挂到 /api/v1 下
api_router.include_router(users_router)12. app/main.py
python
from collections.abc import AsyncIterator
from contextlib import asynccontextmanager
from fastapi import FastAPI
from app.api.v1.router import api_router
from app.core.config import settings
from app.db.session import init_database
@asynccontextmanager
async def lifespan(app: FastAPI) -> AsyncIterator[None]:
# 应用启动时执行一次初始化逻辑
init_database()
# yield 之前是启动逻辑,yield 之后可以写关闭逻辑
yield
app = FastAPI(
title=settings.app_name,
# lifespan 用来管理应用启动和关闭阶段的逻辑
lifespan=lifespan,
)
# 注册总路由
app.include_router(api_router)启动:
bash
uv run fastapi dev app/main.py也可以用 Uvicorn:
bash
uv run uvicorn app.main:app --reload十二、一条创建用户请求怎么走完整流程
现在把前面的文件串起来,看一条真实请求:
http
POST /api/v1/users
Content-Type: application/json
{
"username": "copyer",
"email": "copyer@example.com"
}它在后端的执行顺序是这样的。
text
1. app/main.py
FastAPI 应用已经 include_router(api_router)
2. app/api/v1/router.py
/api/v1 前缀命中,总路由继续把请求交给 users_router
3. app/modules/users/router.py
POST /users 命中 create_user 路由函数
4. FastAPI 发现路由参数里有 db: SessionDep
于是先执行 get_db()
5. app/dependencies/database.py
get_db() 通过 SessionLocal() 创建一个新的数据库 Session
6. router.py
create_user(data, db) 开始执行
data 是 Pydantic 校验后的 UserCreate
db 是 get_db() 提供的 SQLAlchemy Session
7. service.py
UserService.create_user(db, data) 执行业务规则
先检查 username 是否重复
8. repository.py
UserRepository.get_by_username(db, data.username)
使用 SQLAlchemy 查询 User 表
9. SQLAlchemy
把 select(User).where(...) 翻译成 SELECT SQL
10. PyMySQL
把 SELECT SQL 发给 MySQL
11. MySQL
执行查询,返回是否已有这个用户
12. service.py
如果用户名不存在,调用 Repository 创建 User 对象
13. repository.py
db.add(user)
把 user 标记为准备新增,但此时还没有真正写入数据库
14. service.py
db.commit()
提交事务,SQLAlchemy 生成 INSERT SQL
15. PyMySQL
把 INSERT SQL 发给 MySQL
16. MySQL
写入 users 表,生成自增 id 和默认时间
17. service.py
db.refresh(user)
把数据库生成的新字段刷新回 Python 对象
18. router.py
把 ORM 对象转换成 UserRead
19. FastAPI
把 UserRead 转成 JSON 响应
20. get_db()
请求结束,finally 执行 db.close()
Session 关闭,连接归还连接池这条链路里,最重要的是不要把职责混在一起。
text
Router
-> 只处理 HTTP 输入输出
Service
-> 处理业务规则和事务
Repository
-> 处理数据库读写细节
Session
-> 记录本次数据库操作,并负责 commit / rollback
Engine
-> 提供数据库连接入口和连接池
PyMySQL
-> 真正和 MySQL 通信如果创建用户失败,流程会变成:
text
Service 执行中出错
-> except 捕获异常
-> db.rollback()
-> 撤销本次事务里已经准备写入的变更
-> raise 把异常继续抛出
-> Router 或全局异常处理把异常转换成 HTTP 响应
-> get_db finally 关闭 Session所以 commit、rollback、close 是三个不同动作:
text
commit
-> 确认写入数据库
rollback
-> 撤销本次事务
close
-> 关闭当前 Session,把连接还回连接池不要用 close 代替 rollback,也不要以为 add 之后数据已经写进数据库。真正落库发生在 commit。
十三、同步还是异步
这篇使用的是同步 SQLAlchemy + PyMySQL。
也就是说:
text
SQLAlchemy create_engine
-> PyMySQL
-> 同步数据库调用这种方式适合大多数入门项目和普通后台系统,代码简单,资料多,问题也容易排查。
如果要做全链路异步,依赖会变成另一套:
text
SQLAlchemy create_async_engine
-> asyncmy 或 aiomysql
-> AsyncSession
-> async def 路由不要把同步 Session 和异步 Engine 混在一起,也不要只因为 FastAPI 支持 async def 就强行把数据库层改成异步。先把同步版本写清楚,比一开始就堆异步概念更重要。
十四、常见错误
1. 忘记提交事务
只写:
python
db.add(user)数据不会真正落库。写操作要执行:
python
db.commit()如果还要拿到自增 ID 或数据库默认值,再执行:
python
db.refresh(user)2. 异常后不回滚
写操作失败后,应该:
python
db.rollback()否则当前 Session 可能处于失败状态,后续继续使用会报错。
3. 在路由里直接创建 Engine
不要这样写:
python
@router.get("/users")
def list_users():
engine = create_engine(...)Engine 应该在应用启动时创建一次,复用连接池。每个请求里只创建和关闭 Session。
4. 把数据库密码写进代码
不要把连接串硬编码在 Python 文件里。
更好的方式:
text
.env
-> 本地开发配置
生产环境变量
-> 生产配置.env 通常不提交到 Git。
5. 模型没有被导入
如果调用 Base.metadata.create_all(bind=engine) 后没有生成表,常见原因是模型类没有被导入。
解决方式是建立一个统一的模型导入文件:
python
from app.modules.users.models import User
__all__ = ["User"]并在初始化数据库前导入它。