问题描述
在两个 Azure Storage Account 之间复制大文件时,最常见的担心是:如果要复制 1 TB、10 TB,甚至更多 Blob 数据,会不会像普通网络传输一样产生大量流量费用?这个问题不能只看"源账号"和"目标账号"是不是不同账号,而要先看复制方式。
如果应用程序先把 Blob 下载到本地、VM、容器或 App Service,再上传到另一个 Storage Account,那么数据确实会经过应用所在网络,网络带宽、出站流量、NAT、防火墙或私有网络组件都可能参与计费和限流。
Azure Storage 其实还提供了另一种方式:服务器端复制(Server-Side Copy),对应Copy Blob、Put Blob From URL、Put Block From URL这几个 API。看起来像是"在服务端完成复制",但它到底是不是真的不经过我的应用网络?用它在两个 Storage Account 之间搬 1 TB、10 TB 数据时,会不会还是产生大量流量费用?这就是本文要回答的问题。
问题解答
如果使用 Azure Storage 服务器端复制,Blob 的大块数据不会经过你的应用服务器或自建网络链路。应用程序发出去的主要是一个复制请求,真正的数据搬运发生在 Azure Storage 服务后端。
所以,两个 Storage Account 之间复制 Blob 时,真正要避免的是"下载再上传"这种写法。只要源 Blob 能被目标 Storage 授权读取,目标 Storage 就可以直接从源 URL 拉取数据并写入目标 Blob。应用不需要读取 Blob 内容,也不需要把 1 TB 数据重新上传一遍。
1. 先区分两种复制方式
| 复制方式 | 数据路径 | 是否容易产生大量应用侧流量 |
|---|---|---|
| 应用下载源 Blob,再上传到目标账号 | Source Storage → 应用 → Destination Storage | 是 |
| Storage 服务器端复制 | Source Storage → Azure Storage 后端 → Destination Storage | 否 |
把这两条路径画成图更直观:
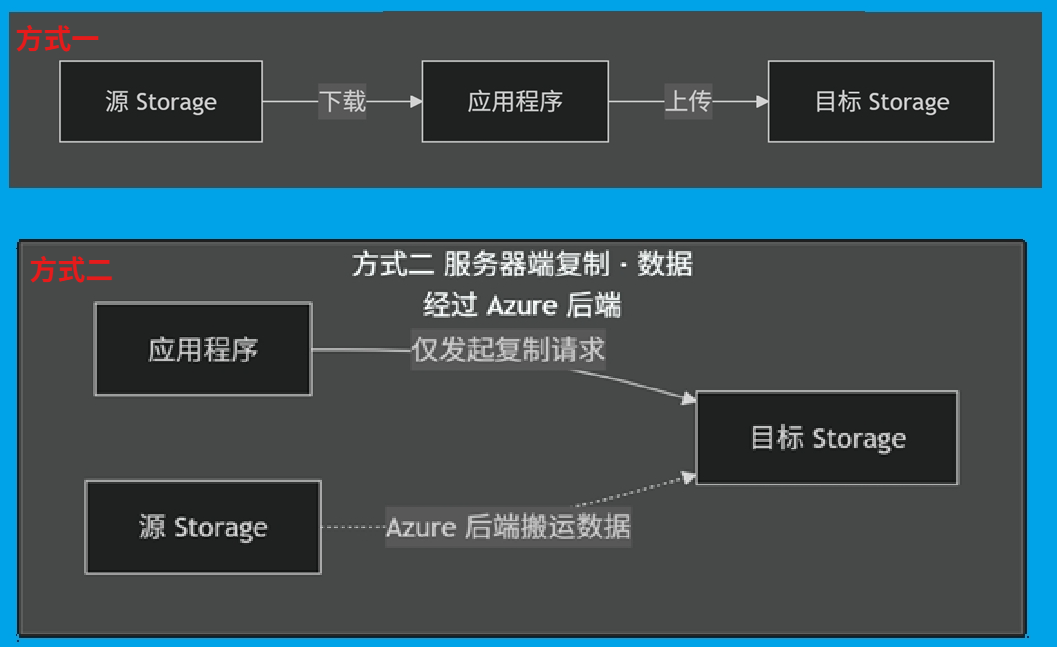
这里的重点是:应用程序只参与"发起复制",不参与"搬运内容"。因此,大文件 payload 不会压到应用服务器、NAT、代理、防火墙或私有网络链路上。
2. 费用边界:不是"完全免费",而是"不走应用网络"
这里要避免一个过度简化的说法:服务器端复制不等于所有费用都没有。评估这类需求时,第一步不是写代码,而是先确认源和目标是不是都在 Azure Blob Storage、是不是同一个区域------这两点基本决定了费用结构。
更准确的理解是:
| 场景 | 费用理解 |
|---|---|
| 同区域 Storage Account 之间服务器端复制 | 大文件数据不经过应用网络;通常不产生互联网出站流量费用,但仍有 Storage 事务费用 |
| 跨区域 Storage Account 之间复制 | 数据仍不经过应用网络,但需要评估跨区域数据传输费用 |
| 应用下载再上传 | 数据经过应用网络,可能产生明显带宽、出站、NAT、防火墙或私有链路相关费用 |
建议:只要不需要在复制过程中处理文件内容,优先使用服务器端复制,而不是自己写下载再上传。
3. .NET 里怎么选 API
常见选择可以压缩成一张表:
| 场景 | 推荐 API | 大小限制 |
|---|---|---|
| 中小 Blob,希望同步完成 | SyncUploadFromUriAsync |
源 Blob ≤ 5,000 MiB(对应Put Blob From URL) |
| 大文件复制,接受异步状态轮询 | StartCopyFromUriAsync |
异步Copy Blob,无大小上限 |
| 超大文件,需要分块、重试、进度控制 | StageBlockFromUriAsync+CommitBlockListAsync |
每块最大 4,000 MiB(对应Put Block From URL,需 API 版本 2019-12-12+) |
大多数跨账号大文件复制,先选StartCopyFromUriAsync:
CopyFromUriOperation operation = await destinationBlob.StartCopyFromUriAsync(sourceSasUri);
await operation.WaitForCompletionAsync();这里的sourceSasUri只需要让目标 Storage 能读取源 Blob。生产环境里,不建议使用账号 Key 生成长期 SAS;更推荐使用托管身份访问目标账号,并使用短有效期 User Delegation SAS 授权源 Blob 读取。
4. 常见报错:403 CannotVerifyCopySource
当源账号启用了防火墙或网络规则时,服务器端复制可能会遇到这个报错:
403 This request is not authorized to perform this operation.
CannotVerifyCopySource这个错误不一定是 SAS 过期,也不一定是 RBAC 角色缺失。它经常表示目标 Storage 服务在验证或读取源 Blob 时,被源账号的网络规则挡住了。这里的关键点是:复制请求虽然是你从应用程序发起的,但真正读取源 Blob 的动作发生在 Storage 服务后端;如果源账号没有给这条服务端读取路径放行,目标端就无法验证源。
一般按下面顺序排查:
| 检查点 | 重点看什么 | 常见处理 |
|---|---|---|
| 源 URL 授权 | SAS 是否有r权限,是否过期,时间是否受时钟偏差影响 |
使用短有效期 User Delegation SAS,开始时间可以略早几分钟 |
| 目标账号权限 | 发起复制的身份是否能写目标容器 | 给托管身份分配Storage Blob Data Contributor |
| 源账号网络规则 | 源账号是否允许目标 Storage 后端读取源 Blob | 评估网络例外、Trusted Microsoft services 或 Resource instance rule |
| Copy scope | 目标账号是否限制了允许的复制来源 | 检查AllowedCopyScope,例如是否限制为同租户或 PrivateLink |
| DNS 与 Private Endpoint | 应用访问源、目标账号时是否解析到预期私有地址 | 检查privatelink.blob.core.windows.net私有 DNS 区域和 VNet link |
这里不要把"客户端能访问源账号"直接等价成"目标 Storage 后端也能读取源账号"。两者不是同一条路径。
即使应用能访问源账号和目标账号,也不自动代表 Storage 服务端复制一定满足源账号的网络限制。