作者:来自 Elastic Lorenzo Dematte 及 Chris Hegarty

Elasticsearch 向量搜索引擎通过复用神经网络、视频编解码和密码学 CPU 指令,以四种方式实现最高 6 倍的性能提升;本文将深入介绍其中的数学原理、失败的尝试以及基准测试结果。
亲自体验向量搜索,试试这个面向 Search AI 的自助式动手学习。你现在就可以开始免费云试用,或者在你的本地机器上体验 Elastic。
作为一个向量数据库,Elasticsearch 为你提供了一种高效的方式来大规模创建、存储和搜索向量嵌入。其核心构建于 simdvec 之上,相比串行代码可实现最高约 50 倍的向量搜索速度提升,相比 Java 的 Panama Vector API 也可提升 2--3 倍。simdvec 的速度来源于现代 CPU 中实现的单指令多数据(Single Instruction, Multiple Data,SIMD)指令,而其中许多指令最初根本不是 CPU 厂商为向量搜索而设计的。
现代 CPU 拥有速度惊人的执行单元,但它们只会加速一组经过精心选择的有限操作,而你真正需要的操作往往并不存在。真正的挑战不是找到最快的指令,而是重新构造计算过程,使其能够表示为硬件能够高效执行的指令。
本文将介绍四个这种重新构造计算的实际案例:
-
将量化为 int7,以适配神经网络中的无符号 × 有符号乘加(unsigned×signed multiply-accumulate)指令。
-
通过代数偏置(bias)重写,实现 完整 int8 向量评分,利用视频编码中的绝对差值求和(sum of absolute differences)指令。
-
将 bf16 欧几里得距离表示为三个点积(dot product),最大限度利用目前少量可用的 bf16 指令。
-
将二进制向量点积 重新表示为多元素(以及多向量)位运算,在支持时使用 SIMD
popcount,而在不支持时则使用字节重排(byte shuffle)和查找表(lookup)实现。
编译器 看不到的那一位:为什么 int7 能启用最快的整数乘加运算
在我们面向 x86 的字节向量内核中,我们希望使用 vpdpbusd,这是现代 x86 CPU 上最快的整数点积指令。但这里有一个问题:它是为 神经网络 推理设计的,而不是为向量搜索设计的。vpdpbusd 的一个操作数必须是无符号数,另一个必须是有符号数,这与向量嵌入通常的表示方式并不一致。
x86 SIMD 指令集包含多种面向整数字节数据的乘加指令:除了更通用的 maddubs(所有 AVX2 和 AVX-512 处理器均支持)之外,较新的处理器还实现了速度更快的 vpdpbusd(支持Vector Neural Network Instructions(VNNI)的处理器提供),它能够将 maddubs、madd 和累加(add)融合为一条指令。
对于这两条指令,一个操作数会被视为无符号字节 [0,255],另一个会被视为有符号字节 [-128,127]。这种不对称性源于它们最初的深度学习推理用途:经过 ReLU 后的激活值是无符号的,而权重是有符号的。因此,我们不能直接用两个有符号操作数来使用这些指令,否则结果会出错。例如,如果把值为 -1(位模式为 0xFF)的有符号字节传给无符号操作数,该指令会悄悄地把它解释为 255。
那么,我们为什么还要费心使用 vpdpbusd 呢?除了它本身速度极快之外(它能够以单条指令相同的吞吐量完成多个操作),另一种选择是使用 16 位宽的指令:先加载半个寄存器的字节数据,将每个字节扩展为 16 位,再进行 16 位乘法。这会使每个寄存器和每次加载所能处理的元素数量减半;而像 vpdpbusd 这样的字节宽度乘加指令,在相同内存带宽下可以处理 2 倍 的元素。正如我们在上一篇文章中所看到的,这些内核往往受限于数据加载速度,而不是计算速度。因此,使用 vpdpbusd 可以直接带来 2 倍 的优势。
Elasticsearch 的优化标量量化(OSQ)支持多种位宽,其中包括 7 位模式 。在 7 位模式下,每个 量化 值都位于 [0,127] 范围内。最高位始终为 0,这意味着该范围内每个数的有符号解释和无符号解释完全一致。因此,我们可以直接使用无符号 × 有符号乘加指令,而无需进行任何转换,也能够得到正确结果。
这是一个协同设计(co-design)决策:通过将量化位宽从 8 位降到 7 位,我们牺牲了 1 位精度,却能够直接使用硬件提供的最快整数乘加指令。这个权衡非常值得:基准测试显示,在召回率几乎没有损失的情况下,可获得约 6 倍的性能提升。(所有详细信息和 JMH 基准测试均可在链接中的 PR 查看。)
这种性能提升来自直觉和设计决策,而不是编译器优化。编译器永远无法做出这样的选择。对于编译器而言,数据只是一个 int8_t,即取值范围为 [-128,127] 的有符号类型。它无法证明这些值一定是非负数,也无法推断 vpdpbusd 可以安全地用于非负数,因此它永远不会生成 vpdpbusd 指令。这一决策需要了解量化方案本身,而这些知识超出了编程语言类型信息所能表达的范围。
当数值不匹配时:如何用无符号操作处理有符号 int8
完整的 int8 向量仍然会遇到这个问题:两个操作数都可能包含负值,而 vpdpbusd 要求其中一个操作数必须是无符号数。
Elasticsearch 支持字节格式的输入向量数据;对于这类数据,我们无法控制输入范围,因此必须支持操作数覆盖完整的 [-128,127] 范围。我们最初的 kernel 使用的是前面提到的朴素扩展路径:将 byte 做符号扩展到 16 位,然后在双倍宽度下进行乘法。这种方式是正确的,但会使吞吐量减半。
然而,其实有一种方法可以让 vpdpbusd 用于有符号数据。关键在于一个代数恒等式:

将 a 中的每个元素都加 128,可以把取值范围从 [-128, 127] 平移到 [0, 255],从而让 a 可以作为 vpdpbusd 期望的无符号字节操作数。在实践中,这种平移可以通过对每个寄存器执行一次 0x80 的 XOR 来实现(翻转符号位在二进制补码中等价于加 128)。代价是需要一个修正项 128 * sum(b),必须从结果中减去。
这种技术在 深度学习 推理领域早已存在:Intel 的 oneDNN 库使用相同的恒等式,用来在 vpdpbusd 中处理带符号激活值。
这个修正项可以用另一个"为别的问题而设计"的指令来计算:vpsadbw 用于计算无符号字节之间的绝对差之和,最初是为视频编码中的运动估计设计的。当其中一个操作数是零向量时,这些绝对差就退化为 b 的字节值本身,因此 vpsadbw 实际上可以计算 b 的部分字节和。这些部分和可以累加形成修正项。
一条为完全不同用途设计的指令,通过一点代数重构,变得意外可用。
这里,上一篇文章 中的批量评分架构再次发挥作用。如果把 b 视为我们的查询向量 ,那么修正项就是只依赖查询的标量,而与任何文档 无关。在批处理路径中,我们可以在评分循环之前预先计算这个修正项,每个文档向量只需要执行 XOR + vpdpbusd,完全没有逐文档的修正开销。
相比之下,单对(single-pair)路径必须在每次调用时计算修正项,其开销会完全抵消 vpdpbusd 的加速收益。
我们进行了真实测量:在 AMD Turin(AWS c8a.xlarge,Zen 5 核心)上的 JMH 基准测试显示,批量评分提升约 20%,但单对没有优势。(详细信息见链接 PR。)因此 simdvec 同时使用两条路径:批量场景使用带 bias 技巧的 vpdpbusd,单对场景使用宽化(widening)路径。我们让基准测试决定方案,而不是让技巧的 "优雅性" 来决定。
三条指令比一条更快:如何用点积计算欧几里得距离
这本来应该是最简单的一部分:CPU 已经有专门的 bf16 点积指令。不幸的是,并不存在所谓"bf16 欧几里得距离指令"。
BFloat16(bf16)正在成为向量嵌入的一种流行格式:它在降低精度的同时覆盖了与 float32 相同的数值范围,使存储减半,也就意味着每个向量的内存带宽减半。硬件厂商已经提供了专用指令(AVX-512 上的 vdpbf16ps 和 ARM Scalable Vector Extension SVE 上的 bfdot),可以直接将 bf16 点积计算到 32 位浮点累加器中。在 AVX-512 上,这意味着每个 512-bit 寄存器可以处理 32 个 bf16 元素,且无需转换步骤。
乍一看,这里似乎没什么可优化的:这些指令刚好做的就是我们需要的事情。事实上,bf16 点积内核确实可以直接映射到这些指令。但 Elasticsearch 还需要计算平方欧几里得距离:|a − b|²。
在我们开始实现 AVX-512 bf16 支持 时,最初的平方距离实现走的是最直接的路径:将两个 bf16 向量都转换为 float32,做减法,再平方:
ini
`
1. __m512 diff = _mm512_sub_ps(bf16_to_f32(a), bf16_to_f32(b));
2. sum = _mm512_fmadd_ps(diff, diff, sum);
`AI写代码512-bit 寄存器可以容纳 32 个 bf16 值,但只能容纳 16 个 float32 值。经过转换之后,后续所有操作的元素密度都会减半。而 bf16_to_f32 转换函数本身使用的是整数 ALU 操作(将 16 位零扩展为 32 位,然后左移 16 位)。这意味着每一步只能处理一半数量的元素(16 个);此外,这些转换操作还会占用执行资源,从而与真正的数学计算争用 ALU 端口(它们会竞争执行端口;见我们上一篇文章中的"Ports, pipes, latency, throughput")。
当查询本身已经是 float32 时,这条路径是合理的:无论如何内核都必须以 32 位宽度运行。但当两个向量都是 bf16 时,我们可以通过一个代数等价变换做得更好。
平方欧几里得距离可以展开为:
∣a−b∣² = a⋅a + b⋅b − 2(a⋅b)
每一项都是一个点积,这意味着每一项都可以直接映射到 CPU 已经加速的硬件原语(vdpbf16ps / bfdot)。新的 kernel 使用三个原生 bf16 点积,不需要任何转换,并且可以在完整的 32 元素寄存器宽度下运行:
scss
`
1. sum_self = _mm512_dpbf16_ps(sum_self, av, av); // a·a
2. sum_self = _mm512_dpbf16_ps(sum_self, bv, bv); // b·b
3. sum_cross = _mm512_dpbf16_ps(sum_cross, av, bv); // a·b
4. // after the loop:
5. result = reduce(sum_self) - 2.0f * reduce(sum_cross);
`AI写代码我们执行了更多的算术指令,但每条指令都在满密度的 bf16 数据上运行。基线方案执行的算术指令更少,但每次处理的宽度只有一半。此外,整个 inner loop 都是纯浮点运算:没有整数 ALU 操作,因此减少了资源争用。同样的恒等式在 ARM SVE 上通过 svbfdot_f32 也可以完全一致地工作。
成本取决于目标微架构上 vdpbf16ps 的执行代价,或者换句话说,CPU 厂商在这条指令上投入了多少晶体管资源。在 AMD Zen 5 上,vdpbf16ps 得到了高度优化:每条指令是一个微操作(uop),并且吞吐量为每周期两条指令;每个 step 三次调用即可处理 32 个元素,总计 3 个 uop。相比之下,转换路径每个 step 只能处理 16 个元素,而且指令链更长(每次转换需要 2 个整数操作,再加 1 个减法和 1 个融合乘加 [FMA](https://link.juejin.cn?target=https%3A%2F%2Fen.wikipedia.org%2Fwiki%2FMultiply%25E2%2580%2593accumulate_operation "https://en.wikipedia.org/wiki/Multiply%E2%80%93accumulate_operation"))。这使得在该 CPU 上,三点积路径相比原有 AVX2 实现,在 bf16 欧几里得距离计算上带来了约 2.1--2.4 倍加速。
在 Intel Emerald Rapids 上,vdpbf16ps 是4 个 uop,吞吐量 0.5,也就是每两个周期一条指令。优势相对较小,但点积重写仍然胜出,带来1.3--1.4 倍加速,因为它在整个 loop 中保持了 bf16 的高密度。所有细节和 JMH 基准测试都可以在链接 PR中查看。
批量评分:将仅查询项提升到循环外
和 int8 评分一样,bf16 欧几里得距离也存在一个只依赖查询的项,可以在每个 query 计算一次,而不是在每个 document 中重复计算。如果把 b 视为查询向量,那么 b·b 只依赖查询本身,而与任何文档无关。bulk kernel 会将 b·b 从 per-document loop 中提出,在单一共享流中累加,从而将每个文档的 inner loop 从三个点积减少为两个(a·a 和 a·b)。
bulk bf16 欧几里得 kernel 在单对评分基础上实现了 1.25--1.8 倍提升。(同样,所有细节和 JMH 基准测试见 PR。)部分收益来自常规 bulk 优势(更好的指令级并行和预取),但在我们的测量中,被提升出去的 b·b 项贡献了约 10--20% 的提升,具体取决于向量布局。
未被选择的路径:我们尝试过(但最终放弃)的另一种 bf16 距离计算方法
三点积分解并不是唯一一种用 vdpbf16ps 表达平方距离的方法。我们还探索了另一种方式:使用 unpacklo/unpackhi 将两个 bf16 向量交错为 [a₀, b₀, a₁, b₁, ...] 这样的成对结构,然后再与常量向量 [1, −1, 1, −1, ...] 做点积。
这样硬件会计算 aᵢ × 1 + bᵢ × (−1) = aᵢ − bᵢ,从而直接在 float32 中得到逐元素差值,因此不需要任何转换。随后再用一次 FMA 对结果进行平方并累加。
这同样是对同一条指令的创造性使用:一种方法是把平方距离拆成三个点积;另一种方法是把点积重新用于实现"bf16 减法"。两者都完全避免了 bf16_to_f32 转换。从纸面计算量来看,这种交错路径似乎更轻量:每一步只需要一次 dpbf16 加一次 FMA,而三点积方案需要三次 dpbf16。
但在实际中,用于交错 a 和 b 的 shuffle 指令带来了额外开销,而且整个循环中可用的独立累加器更少,从而限制了指令级并行性。相比之下,三点积版本具有更清晰的"加载-计算-累加"结构,在我们的基准测试中明显更优,因此我们最终回退了这个实验。
这里没有所谓"显然正确的方法"和"技巧性 hack":两种都是对同一数学恒等式的有效重写。我们在硬件能力的边界内探索不同表达方式,然后用测量结果决定取舍:直觉和对指令数量的分析只是起点,而不是最终答案。
点积作为位运算:二进制向量、AND 与 SIMD popcount
在一个理想的指令集架构中,我们应该会有专门用于二进制量化向量的点积指令。但现代 CPU 并没有提供这样的指令。幸运的是,当向量被压缩为单比特之后,算术运算本身开始"消失"了。
到目前为止的所有重写方法都处理的是完整整数和浮点数。但 Elasticsearch 也支持二进制量化向量(Better Binary Quantization BBQ),其中每个维度 都被压缩为一个 bit。乍一看,在 1-bit 文档向量和多-bit 查询向量之间计算点积,似乎需要先把 bit 解包为整数、再做乘法、再累加。但由于取值被限制为 0 和 1,乘法和加法可以简化为更基本的操作:两个 bit 的乘积等价于 AND(只有当两个输入都是 1 时结果才为 1),而所有乘积之和等价于结果中 1 的个数,也就是population count(人口计数)。
对所有维度求和:
dot(a, b) = popcount(a AND b)。
这个恒等式并不新,它已经是几十年来位运算算法的经典技巧,广泛用于信息检索、密码学和机器学习中。它的优雅之处在于它与硬件的映射非常自然。
使用 AVX-512 popcount 计算二进制向量点积
标量 popcnt 指令一次只能处理一个 64-bit word,也就是每条指令处理 64 个二进制维度。但支持 VPOPCNTDQ 扩展的 AVX-512 处理器可以在一个 512-bit 寄存器中并行对 8 个 64-bit word 进行 popcount。结合位与(AND)操作,一个 1-bit 文档与查询 bit plane 的 inner loop 可以变为两条指令:
ini
`
1. __m512i res = _mm512_popcnt_epi64(
2. _mm512_and_si512(value, query_plane)
3. );
4. acc = _mm512_add_epi64(acc, res);
`AI写代码这就实现了每次迭代计算一个 512 维的二进制点积块。一个 4-bit 查询会被拆分为四个独立的 bit plane,每个 bit 位置对应一个 plane。每个 plane 会贡献不同的权重(1、2、4 或 8),因此最后一步通过移位并累加这些 popcount,就可以重建完整的点积结果。整个 inner loop 只需要少量指令,却能在一次遍历中处理数千个维度。
构建缺失的指令:在 AVX2 硬件上合成 popcount
VPOPCNTDQ 从 Intel Ice Lake 和 AMD Zen 4 开始的 AVX-512 处理器中可用。但 simdvec 也需要在没有任何向量 popcount 指令的旧 AVX2 硬件上运行。解决方案来自 Muła、Kurz 和 Lemire(2018):使用 vpshufb 字节 shuffle 指令作为并行 4-bit 查找表。其核心思想是用 SIMD 寄存器模拟 popcount 查找表:预先计算所有可能 4-bit 值(0 到 15)的 popcount,并将这 16 个结果存入一个 SIMD 寄存器中。然后对于每个输入字节,将其拆分为高低两个 nibble,并使用 vpshufb 同时查表得到两个计数:
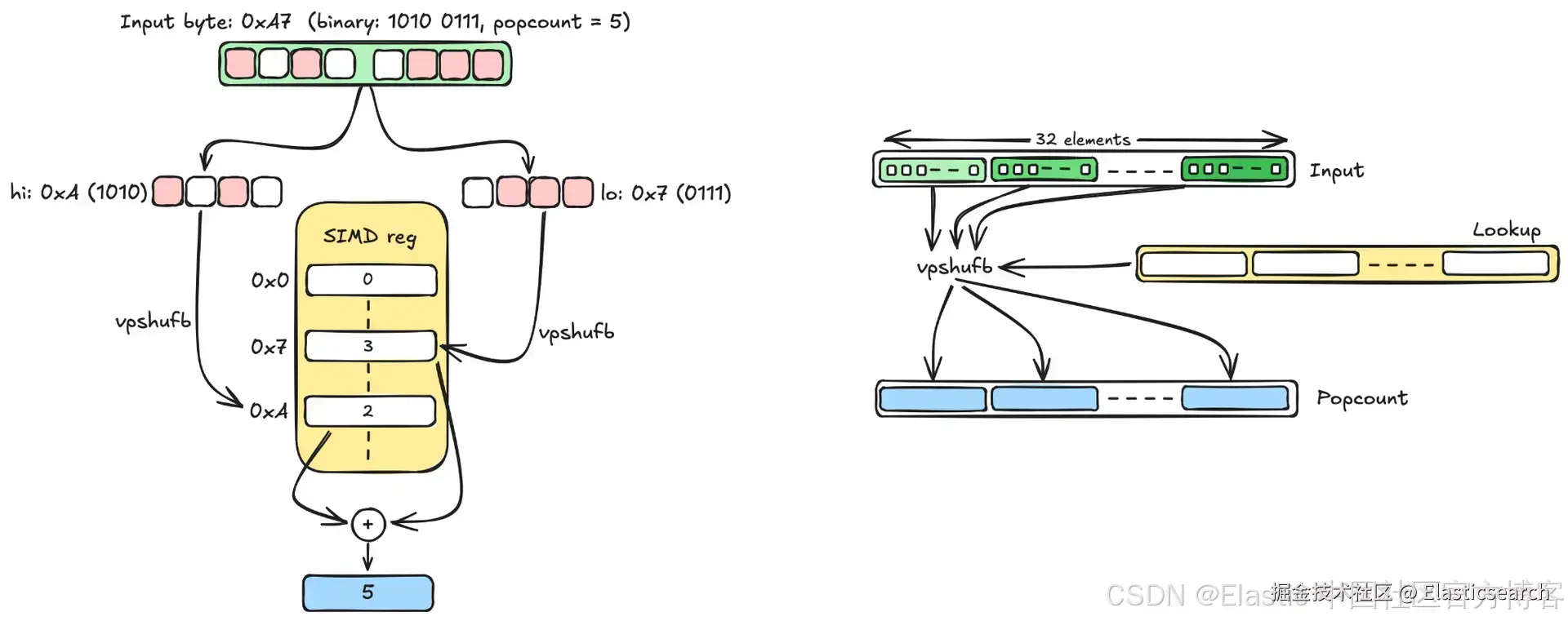
由于 vpshufb 可以并行执行 32 次独立的查表操作,只需要两次 shuffle、两次 mask 和一次加法,就可以在没有专用 popcount 指令的情况下,计算 32 个字节的 popcount(也就是 256 个二进制维度):
ini
`
1. const __m256i lookup = _mm256_setr_epi8(
2. 0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4,
3. 0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4);
5. // lookup low and high nibble popcounts separately
6. const __m256i lo = _mm256_and_si256(vec, low_mask);
7. const __m256i hi = _mm256_and_si256(_mm256_srli_epi16(vec, 4), low_mask);
8. const __m256i popcnt1 = _mm256_shuffle_epi8(lookup, lo);
9. const __m256i popcnt2 = _mm256_shuffle_epi8(lookup, hi);
10. local = _mm256_add_epi8(local, _mm256_add_epi8(popcnt1, popcnt2));
`AI写代码在这种情况下,指令集架构(ISA)并没有提供我们需要的操作,所以我们只能用现有指令"拼"出来。在带有 VPOPCNTDQ 的 AVX-512 上,硬件直接提供了这个原语;而在 AVX2 上,我们可以通过字节 shuffle 和查找表来合成它。我们的原生 AVX2 实现相比 Java 标量评分带来了约 ~4x 的性能提升。升级到带 VPOPCNTDQ 的 AVX-512在此基础上又提升了约 1.3--2.1x,因为单条指令替代了整段 popcount 序列。(同样,更多细节和 JMH 基准测试见对应 PR。)
单指令,多向量:将多个文档向量打包进一个 SIMD 寄存器,用于低维 embedding
有了 VPOPCNTDQ,每次 popcnt 可以处理整个 512-bit 寄存器,也就是一次处理 512 个二进制维度。然而,128 或 256 维的 embedding 模型非常常见;在 1-bit 表示下,128 维向量只有 16 字节,只占 512-bit 寄存器的四分之一。
利用 bulk 处理的思路,我们可以做得更好:如果向量足够小,可以把多个文档向量压缩进同一个寄存器。例如在 128 维(16 字节)的情况下,一个 512-bit 寄存器可以容纳四个文档向量。我们将查询 bit plane 广播四份到寄存器中,然后一次 AND + POPCNT 就能同时处理四个文档:
scss
`
1. // Broadcast query bit plane 4x into a 512-bit register
2. __m512i b = _mm512_broadcast_i32x4(
3. _mm_maskz_expandloadu_epi8(mask, query)
4. );
5. // Load 4 contiguous document vectors in one 512-bit load
6. __m512i docs = _mm512_maskz_expandloadu_epi8(dataByteMask, ...);
7. // AND + POPCNT: four dot products in one instruction pair
8. __m512i res = _mm512_popcnt_epi64(_mm512_and_si512(docs, b));
`AI写代码一次加载、一次 AND 和一次 POPCNT,就可以同时计算四个文档的分数。对于 256 维向量(每个 32 字节),每个寄存器可以容纳两个文档。
JMH 基准测试展示了一个有趣的现象。在 Intel Granite Rapids 上,这个新 kernel 可以完美扩展:在 128 维时比 AVX2 快 4.4x(相对于单向量实现是 3.88x),在 256 维时为 2.4x(相对于单向量实现是 2.79x)。但在 AMD Zen 5 上,收益要小得多;我们测试了不同实现,发现多向量实现相较单向量在该 CPU 上几乎没有优势。
这目前只是一个假设,但可能原因是 Zen 5 在内部用 128-bit uops 来实现 VPOPCNTDQ,把 512-bit 寄存器拆成四个顺序执行的块来处理。这与我们的 benchmark 结果是一致的:如果硬件本身就是按四段分别处理,那么把四个 128-bit 向量塞进一个寄存器并不会带来收益。无论如何,这再次说明不同 CPU 在硅实现上的设计取舍会直接影响最优策略。
在更高维度下,两个平台仍然都能受益于 AVX-512 的更宽寄存器(前面提到的 1.3--2.1x 提升仍然成立)。
一个后续改动通过带掩码加载(expandloadu)把这种打包方法扩展到了非 2 的幂维度(96、192),使其与 128 和 256 维达到了同等性能表现。
Elasticsearch simdvec 经验总结:让 CPU 指令适配向量搜索
在这篇文章中,我们分析了多种优化方式:使用 int7 以适配 unsigned*signed 硬件、用代数重写处理 signed int8 的偏置问题、将欧几里得距离拆解为三个 bf16 点积、用位运算重构二进制向量点积、以及通过字节 shuffle 合成 popcount。
| 用例 | 技术 | 关键指令 | 典型加速比 |
|---|---|---|---|
| int7 向量 | 7-bit 量化,使 unsigned×signed 乘加得以成立 | vpdpbusd |
相比 widening path 约 ~6x |
| int8 向量 | 代数 bias + 预计算修正项 | vpdpbusd + vpsadbw |
bulk 场景约 +20% |
| bf16 向量 | 将平方距离展开为三个 dot product | vdpbf16ps / bfdot |
1.3--2.4x |
| 二进制向量 | 通过 shuffle 查表或 SIMD popcount 计算 popcount(a AND b) | vpshufb / vpopcntd |
AVX2 相比标量约 ~4x;AVX-512 再提升 1.3--2.1x |
硅资源是稀缺的,所以 CPU 只能加速一小部分有限的操作。这些操作往往是为完全不同的用途设计的:神经网络推理、视频编码、密码学或图形计算。本篇中的每一个优化都遵循同一个模式:从硬件能够高效执行的指令出发,然后重新表述计算,使其能够用这些指令来表达。
原文:SIMD vector search: Elasticsearch simdvec's 6x speedup - Elasticsearch Labs