1. 概述
2024 到 2026 年,AI 领域的术语几乎是爆发式增长。LLM、Token、Context、Prompt、RAG、MCP、Skill、Agent 这些词大家都听过,但真正难的不是分别记住它们,而是搞清楚它们在一个 AI 系统里到底是什么关系、分别扮演什么角色。
如果把一个 AI 应用看成一条完整的生产线,那么可以把它理解成这样一条链路:
- LLM 是核心推理引擎,负责"理解"和"生成"
- Token 是模型处理信息的基本计量单位
- Context 是模型每次工作时能看到的临时工作台
- Prompt 是你向模型下达任务的指令语言
- RAG 负责给模型补充外部知识
- MCP 负责把模型和工具、数据源标准化连接起来
- Skill 负责沉淀稳定流程和可复用经验
- Agent 则把前面这些零件真正组织成一个能完成任务的执行系统
先看整体全景图。你不需要在第一眼就记住所有细节,只要先建立"谁在前、谁在后、谁依赖谁"的整体印象即可。
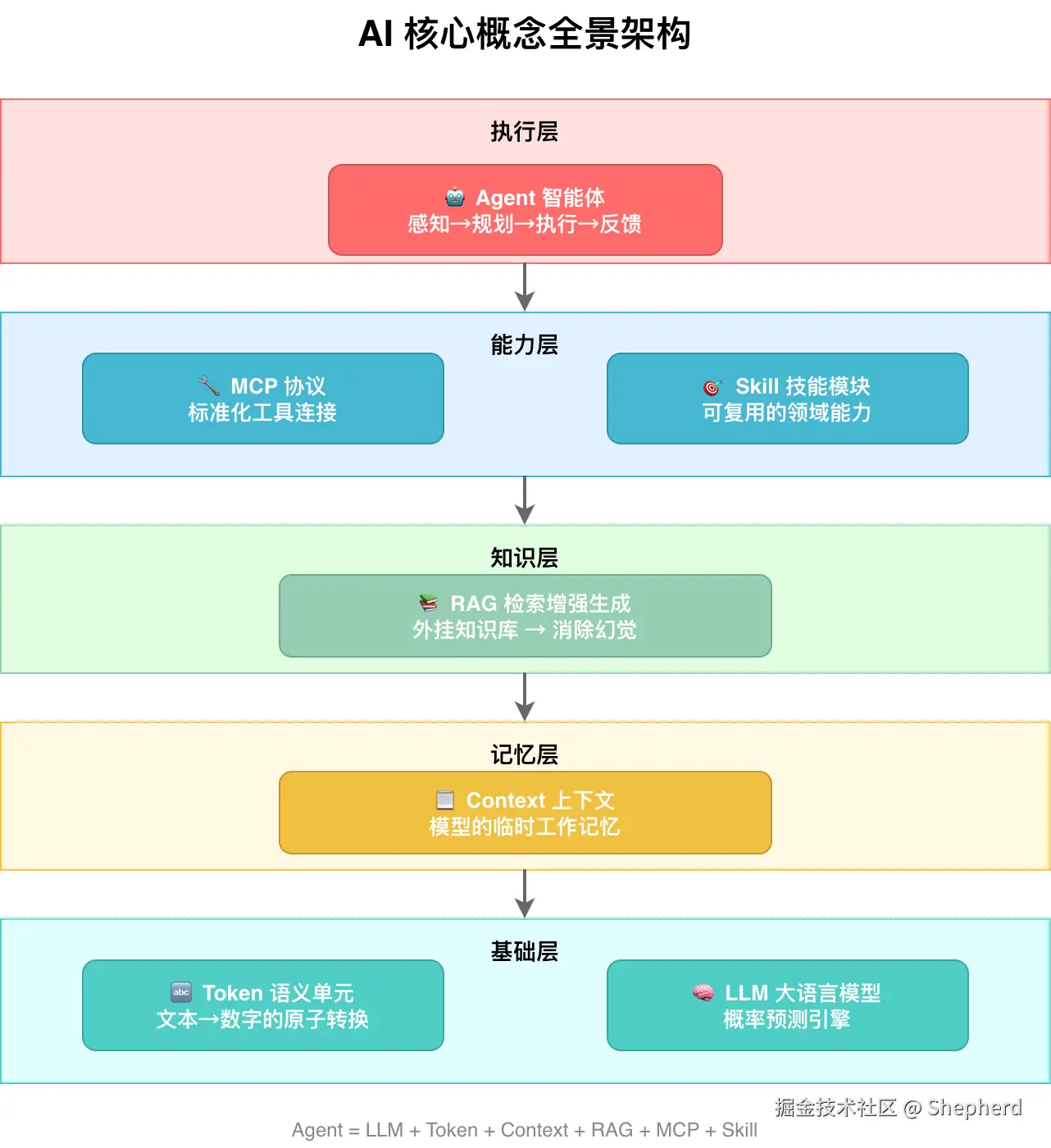
接下来,我们会按照"从底层原理到工程实践"的顺序,一步步把这些概念串起来。
2. LLM:AI 系统的"大脑"
2.1 LLM 的本质是什么?
大语言模型(Large Language Model,LLM)的本质,是一个基于海量训练数据学会语言模式的概率预测引擎。给定前面的文本,它会预测下一个最可能出现的 token,再不断重复这个过程,最终生成整段回答。
听上去它只是"猜下一个词",但当模型参数规模足够大、训练数据足够丰富时,这种"预测下一个 token"的能力会涌现出很多高层能力,比如总结、翻译、问答、编程、推理和创作。
输入文本 → Tokenizer 分词 → Token IDs → Transformer 计算 → 概率分布 → 采样 → 输出 Token2.2 LLM 在整个 AI 系统里扮演什么角色?
LLM 更像是 AI 系统的推理中枢。它本身不直接访问外部世界,也不天然拥有"执行动作"的能力,但它非常擅长根据当前输入做理解、规划、归纳和生成。
所以在工程上,LLM 往往负责三类核心工作:
- 把用户模糊的自然语言需求转成清晰的任务理解
- 基于上下文进行推理、决策和内容生成
- 决定是否需要借助外部知识、外部工具或进一步多轮执行
换句话说,LLM 决定"该怎么想",但不一定决定"怎么拿到真实信息"或"怎么把事情做完"。
2.3 LLM 的能力边界与局限
理解 LLM,不能只看它"会什么",还要看它"不会什么"。
- 它不等于数据库。训练过的知识并不代表永远准确,也不代表实时更新。
- 它不等于搜索引擎。没有接入外部检索时,它只能基于训练记忆作答。
- 它不等于执行器。没有工具接口时,它不能真的去查库、发消息、改代码、下工单。
- 它不等于绝对理性系统。即使推理能力很强,也可能产生幻觉、误判或漏掉约束。
这也是为什么后面会引出 Context、RAG、MCP 和 Agent:单有"大脑"还不够,AI 系统还需要"记忆""外脑""双手"和"行动框架"。
2.4 主流 LLM 一览
下面这张表展示了常见且比较知名的大模型,已经模型自身的特点所长。
| 模型家族 | 典型特点 |
|---|---|
| Claude | 长上下文、推理与代码能力强 |
| GPT | 多模态能力完整、生态广泛 |
| Gemini | 大上下文窗口、与 Google 生态结合紧密 |
| DeepSeek | 成本优势明显,开源/开放生态活跃 |
2.5 调用 LLM 的最小示例
下面这段代码只保留最核心的调用路径:传入角色设定、用户问题和几个关键参数,拿回模型输出。
css
import os
import requests
response = requests.post(
"https://api.openai.com/v1/chat/completions",
headers={"Authorization": f"Bearer {os.environ['OPENAI_API_KEY']}"},
json={
"model": "gpt-4o",
"messages": [
{"role": "system", "content": "你是一位后端工程师。"},
{"role": "user", "content": "用一句话解释什么是递归。"},
],
"temperature": 0.7,
"max_tokens": 100,
},
timeout=30,
)
reply = response.json()["choices"][0]["message"]["content"]
print(reply)关键参数可以先这样理解:
messages:告诉模型"现在在聊什么"temperature:控制输出偏保守还是偏发散max_tokens:控制回答长度和成本
3. Token:模型理解世界的基本单位
3.1 Token 是什么?
Token 是模型处理文本时的最小计算单位。模型并不是直接理解原始字符串,而是先把文本切成 token,再把 token 映射成数字 ID,最后转成向量参与计算。
less
原始文本: "Hello, World! 你好世界"
↓ Tokenizer 分词
Tokens: ["Hello", ",", " World", "!", "你好", "世界"]
↓ 映射到词表
Token IDs: [9906, 11, 1917, 0, 19526, 25461]3.2 Token 在 AI 系统里为什么重要?
很多人第一次接触 Token,会觉得它只是一个分词细节。但在工程里,Token 其实同时决定了三件大事:
- 成本:大多数模型按输入输出 token 计费
- 速度:token 越多,处理延迟通常越高
- 容量:上下文窗口本质上就是"最多能塞多少 token"
所以 Token 不是纯理论概念,它直接影响你的系统吞吐、响应时延和预算控制。Prompt 写得太冗长、检索文档塞得太多、历史消息不裁剪,最后都会体现为 token 成本和性能问题。
3.3 分词流程图怎么看?
下面这张图可以帮助你把"文本 → token → 向量"的流程建立成一个清晰的中间层认知。它的重点不在于记住具体编号,而在于理解:模型看到的不是文字本身,而是一串离散 token 及其向量表示。
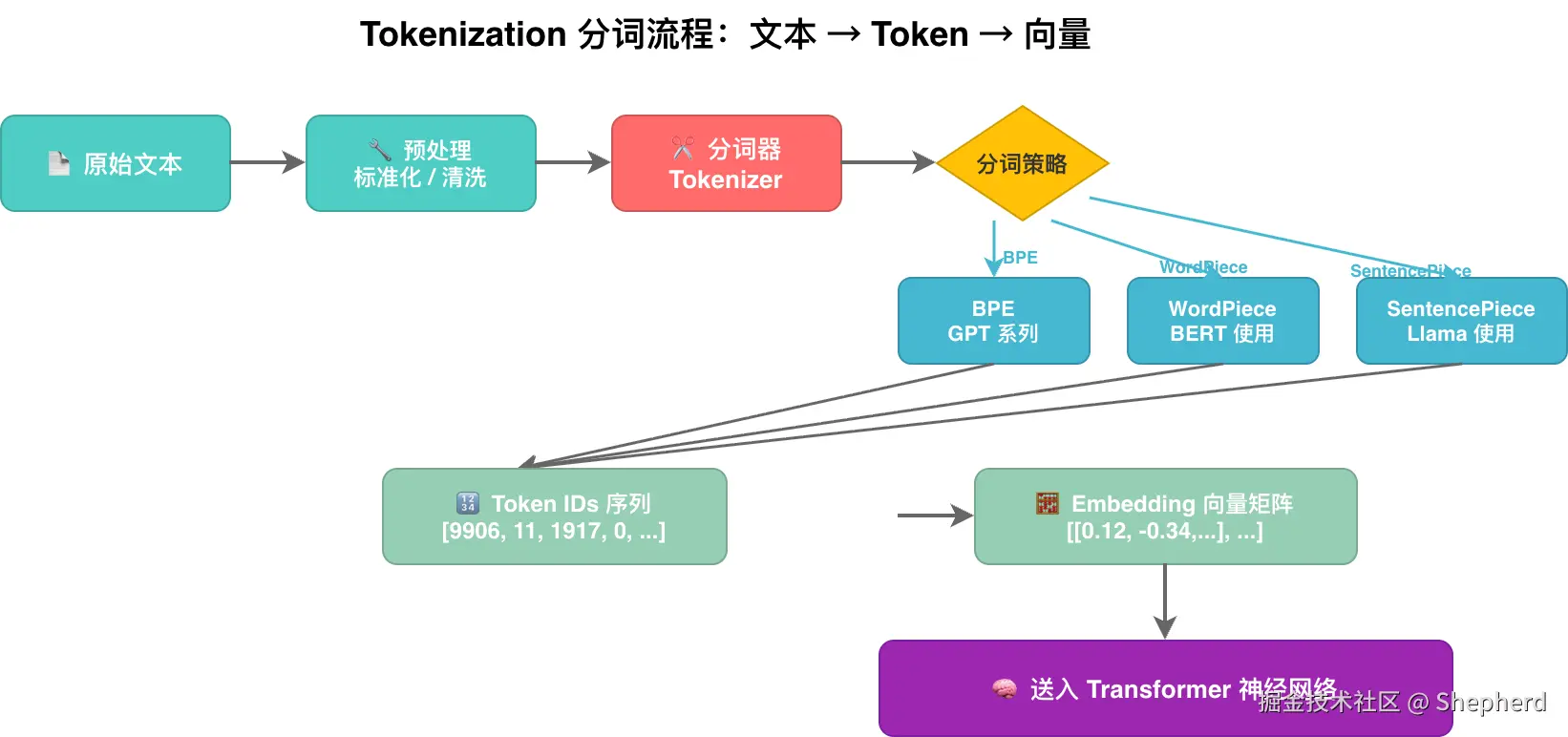
这也是为什么不同语言、不同写法、甚至不同空格位置,都可能带来不同的 token 消耗。
3.4 Token 的粗略估算
| 单位 | 约等于 |
|---|---|
| 1 Token | ~0.75 个英文单词 |
| 1 Token | ~1.5-2 个汉字 |
| 1 Token | ~4 个英文字符 |
| 1000 Tokens | ~750 个英文单词 / 1500-2000 个汉字 |
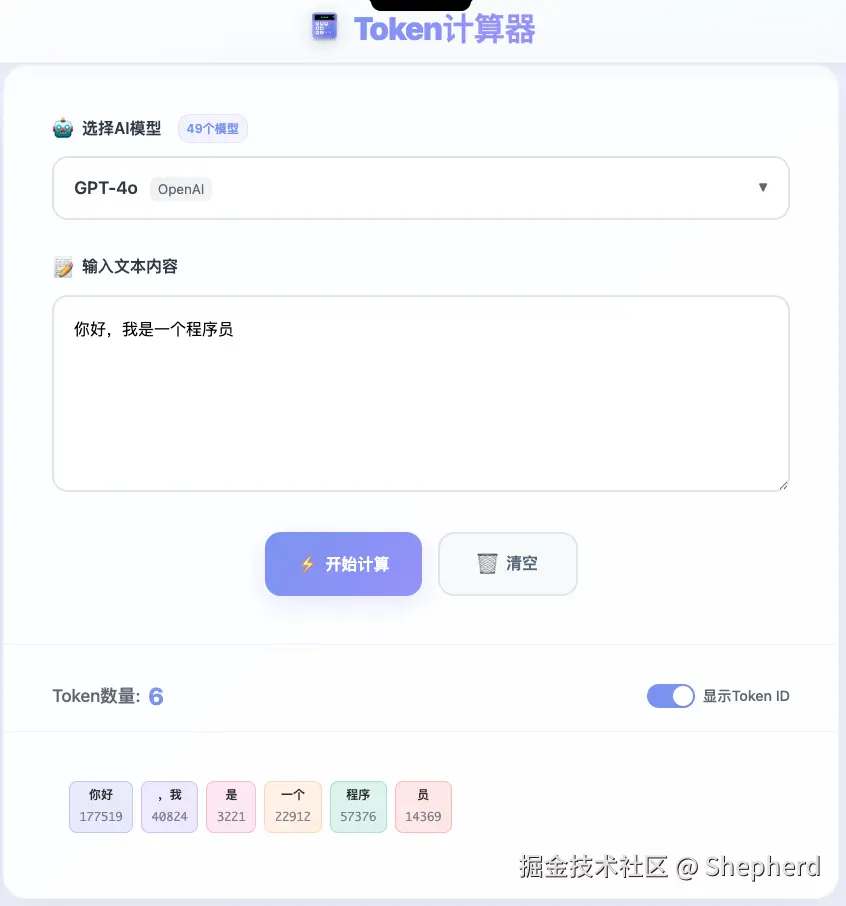
这只是经验值,不同模型的 tokenizer 规则并不完全一致。如果你要精确评估成本或上下文占用,最好用对应模型的 tokenizer 或在线 token 计算器来测算。
下面这张图就是一个典型的 token 计算器界面,它的作用是帮助你在"写 Prompt / 塞文档 / 拼上下文"之前先对成本和长度心里有数。
4. Context:模型的"工作台"
4.1 Context 的本质
Context 是模型在某次调用中能够"看到"的全部信息。它不是模型的永久记忆,而是在每次请求发起时,由系统动态组装出来的临时工作区。
从模型视角看,它并不知道"哪些是历史消息、哪些是检索结果、哪些是工具返回值"。它只知道:这一刻自己拿到了一串 token,然后基于这些 token 做推理和生成。
4.2 Context 在系统中的角色与局限
Context 是决定回答质量上限的关键变量之一。因为模型推理再强,也只能基于"当前看得到的信息"来工作。
它主要承担三类职责:
- 承载用户当前任务目标
- 提供完成任务所需的背景、约束和历史
- 注入外部检索结果、工具返回值、系统规则等辅助信息
但 Context 也有明显局限:
- 容量有限:窗口再大也不是无限大
- 噪声敏感:无关信息太多会稀释关键指令
- 顺序敏感:高优先级信息放在哪里,会影响模型关注重点
所以真正的工程问题不是"把所有信息都塞进去",而是"把最重要的信息,以最适合模型理解的方式放进去"。
4.3 动态构建 Context 的核心逻辑
理解完 Context 的角色后,再看代码就不容易迷失在细节里了。下面这段代码只保留最关键的 4 步:
- 放入系统规则
- 注入检索结果和工具结果
- 在 token 预算内裁剪历史消息
- 追加当前用户问题
css
import tiktoken
def build_context(task, system_prompt, history, rag_docs, tool_results, max_tokens=8000):
enc = tiktoken.encoding_for_model("gpt-4")
messages = [{"role": "system", "content": system_prompt}]
if rag_docs:
refs = "\n\n".join(rag_docs[:3])
messages.append({"role": "system", "content": f"<references>\n{refs}\n</references>"})
for result in tool_results:
messages.append({"role": "tool", "content": result})
history_budget = max_tokens * 0.4
used = sum(len(enc.encode(m["content"])) for m in messages)
for msg in reversed(history):
size = len(enc.encode(msg["content"]))
if used + size > history_budget:
break
messages.insert(1, msg)
used += size
messages.append({"role": "user", "content": task})
return messages这段代码要表达的核心思想只有一句话:Context 不是固定模板,而是围绕任务目标临时拼装、动态取舍的。
4.4 Context 的三层记忆模型
把 Context 放进更大的系统视角里看,可以把"记忆"粗略分成三层:
| 记忆类型 | 存储位置 | 生命周期 | 示例 |
|---|---|---|---|
| 工作记忆 | Context Window | 当前推理 | 当前任务状态、刚获取的工具结果 |
| 短期记忆 | 会话历史 | 本次对话 | 前面几轮问答 |
| 长期记忆 | 外部存储 | 跨会话 | 向量库知识、用户偏好、业务数据 |
理解完 Context 之后,下一步自然就会遇到一个问题:既然模型要靠上下文工作,那我们到底应该怎样把任务说清楚?这就进入 Prompt。
5. Prompt:与模型对话的语言
5.1 Prompt 是什么?
如果说 LLM 是大脑,Context 是工作台,那么 Prompt 就是你往工作台上摆放任务的方式。它不仅仅是一句"提问",更像是一份对模型的任务说明书:你希望它扮演什么角色、完成什么目标、遵守什么约束、按什么格式输出。
Prompt 的质量,往往决定了模型输出是"看起来差不多",还是"真的可用"。
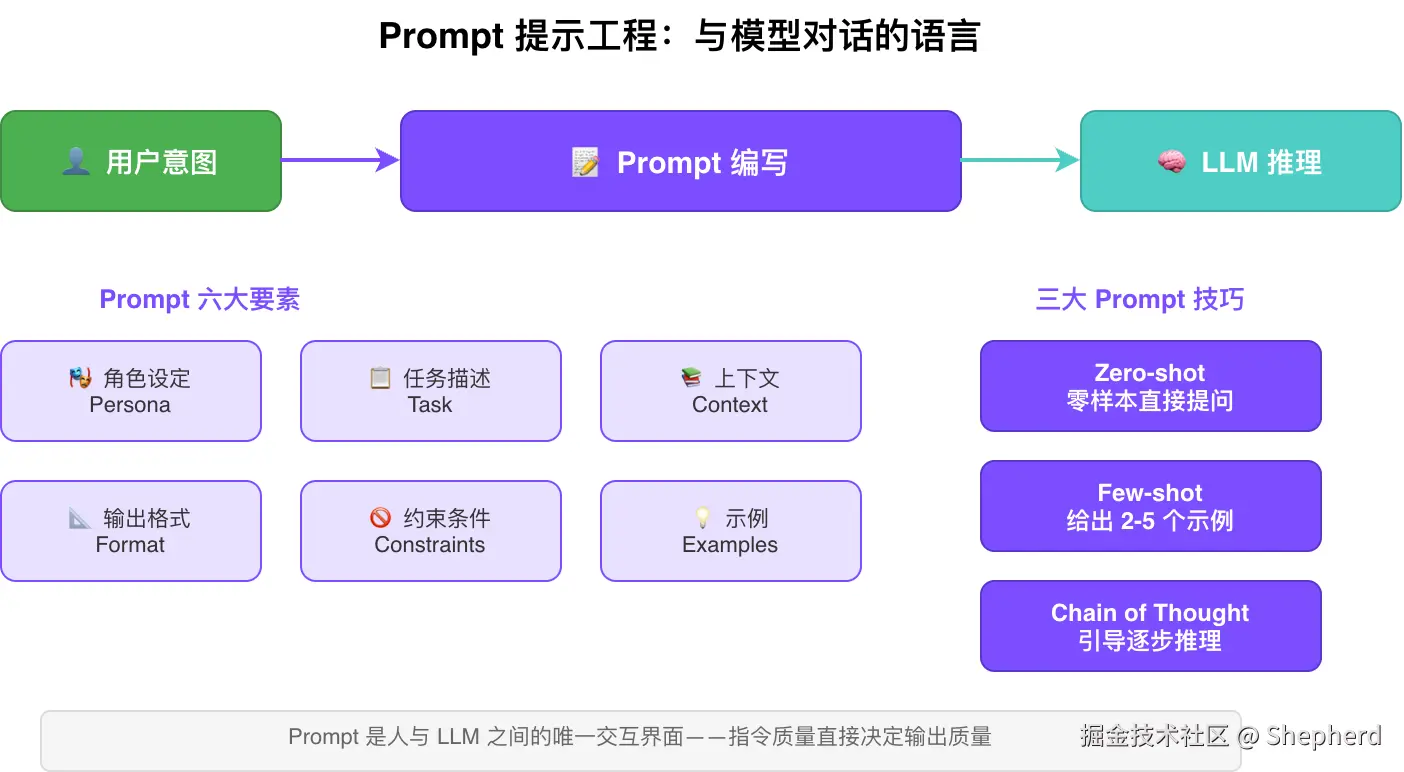
5.2 这张 Prompt 图主要看什么?
下面这张图的重点,是帮助你从"随便问一句"升级到"结构化下指令"。很多 Prompt 效果不好,并不是模型不行,而是输入里缺少角色、上下文、约束或输出格式。
5.3 一条完整 Prompt 的常见结构
arduino
┌─────────────────────────────────────────┐
│ 1. 角色设定(Persona) │
│ 2. 任务描述(Task) │
│ 3. 上下文信息(Context) │
│ 4. 输出格式(Format) │
│ 5. 约束条件(Constraints) │
│ 6. 示例(Examples,可选) │
└─────────────────────────────────────────┘这些要素并不是每次都要写得很长,但越是复杂任务,越需要把这几个部分交代清楚。
5.4 Prompt 的作用与局限
Prompt 能解决的核心问题,是把模糊意图转成模型可执行的输入。它能明显提升输出质量、一致性和可控性,但它不是万能的。
- Prompt 可以提高命中率,但不能凭空补知识
- Prompt 可以约束格式,但不能完全替代校验
- Prompt 可以引导推理,但不能保证每次都推理正确
所以 Prompt 是基础控制手段,但当任务开始依赖外部知识或外部动作时,单靠 Prompt 就不够了,这正是 RAG 和 MCP 出场的原因。
5.5 三类常见 Prompt 技巧
| 技巧 | 做法 | 适用场景 | 示例 |
|---|---|---|---|
| Zero-shot | 直接提问,不给示例 | 简单任务 | "翻译成英文:你好" |
| Few-shot | 给 2-5 个输入输出示例 | 格式要求高的任务 | "输入:苹果→输出:apple" |
| Chain of Thought | 引导模型分步骤思考 | 推理、数学、逻辑 | "先列出条件,再逐步分析" |
6. RAG:给 LLM 外挂知识库
6.1 为什么要 RAG?
LLM 有两个天然短板:
- 知识有截止时间:训练数据不可能永远实时更新
- 会产生幻觉:模型可能一本正经地编出并不存在的内容
RAG(Retrieval-Augmented Generation,检索增强生成)的核心思路是:先检索,再回答。它不要求模型"自己记得一切",而是先去外部知识库找相关资料,再把资料放进 Context 中,让模型基于这些资料生成答案。
6.2 RAG 架构图应该怎么看?
下面这张图的重点不是"多了一个向量数据库"这么简单,而是 AI 的回答流程被拆成了两段:
- 第一段是检索:从外部知识中找到最相关的片段
- 第二段是生成:基于这些片段组织回答
这也是 RAG 与"裸调用 LLM"最大的区别。
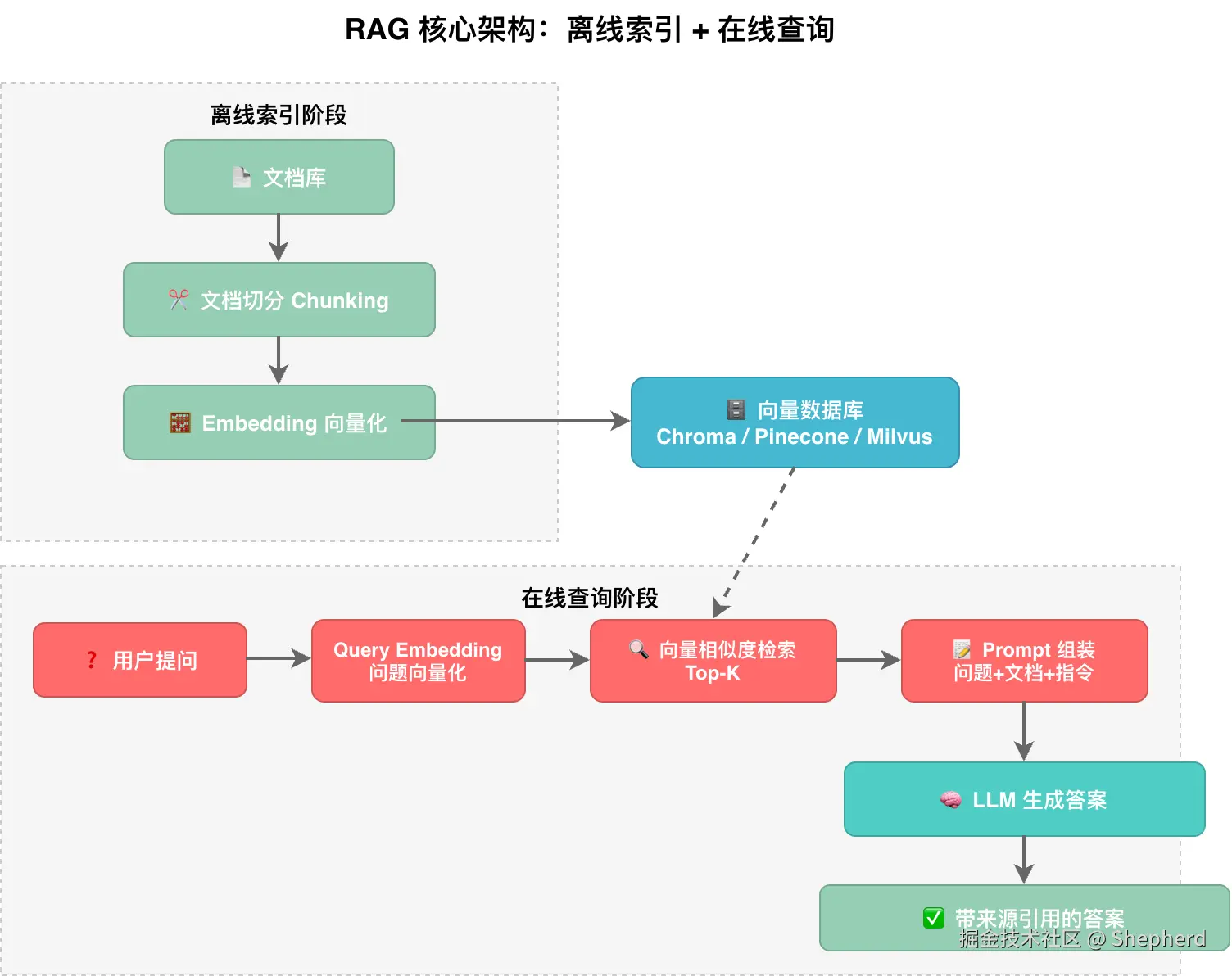
6.3 RAG 在系统中的作用
RAG 的价值主要体现在三点:
- 让模型拿到最新 或私有的信息
- 让回答尽量"有依据",而不是完全靠记忆
- 让系统知识更新从"重新训练模型"变成"更新外部文档"
从工程角度看,RAG 更像是在给模型增加一个"可查阅的外脑"。
6.4 RAG 的局限
RAG 很重要,但它也绝不是万能药。
- 检索错了,回答就会被错误上下文带偏
- 文档质量差,模型也只能基于低质量资料组织答案
- 切片不合理,会导致关键信息丢失或上下文断裂
- 召回太多,又会重新挤占 Context 预算
所以 RAG 解决的不是"让模型更聪明",而是"让模型在回答时拿到更合适的信息"。
7. MCP:AI 工具的"USB 标准"
7.1 MCP 解决了什么问题?
当模型需要调用 GitHub、数据库、浏览器、文件系统等外部能力时,就会遇到一个很现实的问题:每个 AI 客户端都要为每个工具单独适配,集成成本会急剧膨胀。
这就是典型的 M×N 问题。
没有 MCP:M 个 AI 应用 × N 个工具 = M×N 次集成
有了 MCP:M 个 AI 应用 + N 个工具 = M+N 次集成7.2 为什么说它像"USB 标准"?
MCP(Model Context Protocol)本质上是一套让模型与外部能力对接的统一协议。它并不会直接提高模型推理能力,但它会极大降低"接工具"的工程复杂度。
你可以把它理解为 AI 时代的接口标准层:
- 对上,服务 AI 客户端或 Agent
- 对下,连接各种工具、资源和模板
所以 MCP 解决的是"怎么标准化接入能力",而不是"模型怎么变聪明"。
7.3 MCP 架构图怎么理解?
下面这张图最值得看的,是中间那一层"统一协议"。它把原本彼此割裂的工具能力抽象成统一的接入方式,使得同一个工具可以被多个 AI 客户端复用。
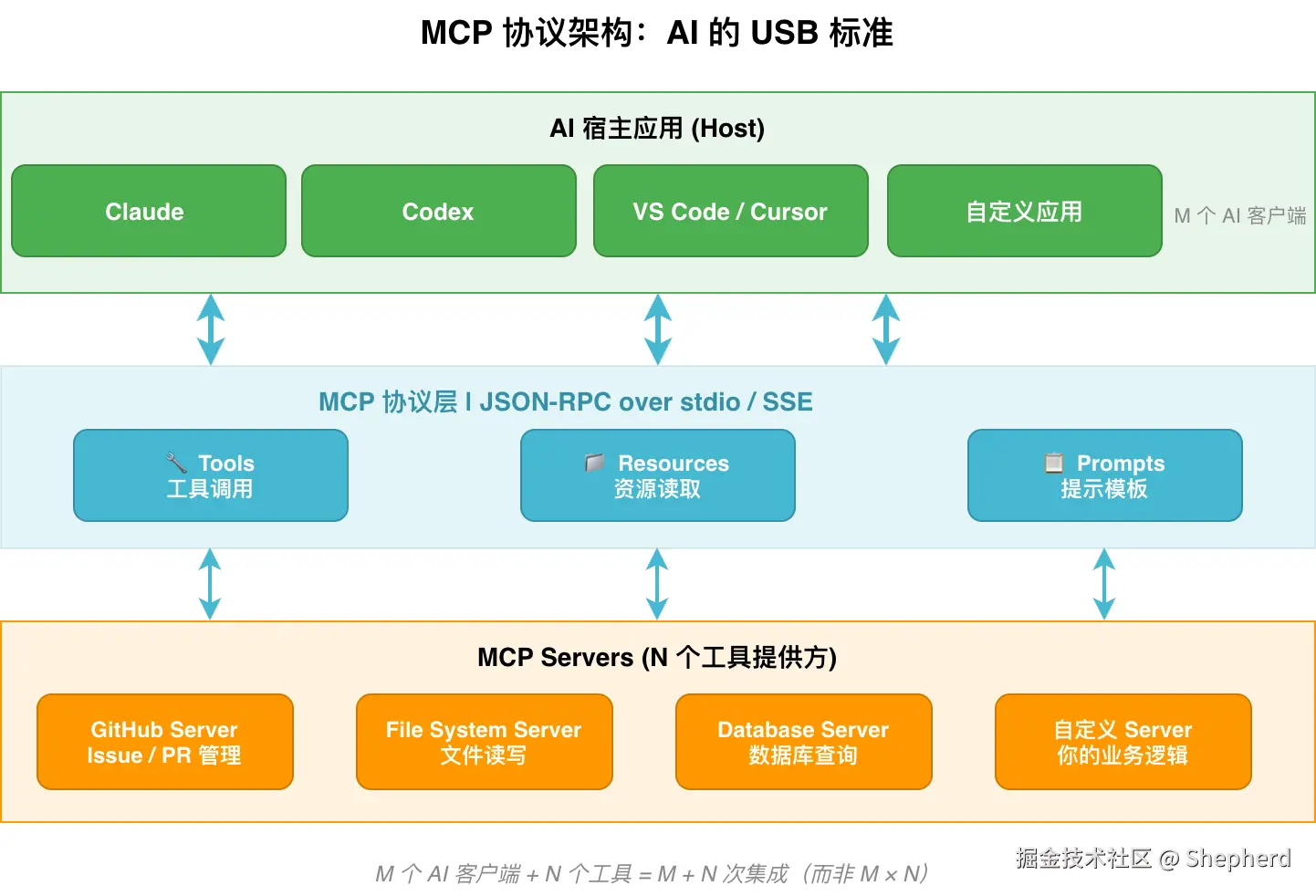
MCP 常见的三类能力包括:
| 能力 | 方向 | 说明 | 示例 |
|---|---|---|---|
| Tools | AI → 外部 | AI 调用外部函数 | create_issue、run_query、send_email |
| Resources | 外部 → AI | AI 读取外部数据 | 文件内容、数据库记录、API 响应 |
| Prompts | 模板 | 预定义 Prompt 模板 | 代码审查模板、文档生成模板 |
7.4 一个最小 MCP Server 示例
这一段代码不展开完整工程细节,只保留"注册 Tool、注册 Resource、启动服务"这三件最关键的事。
python
import asyncio
from mcp.server import Server
from mcp.server.stdio import stdio_server
server = Server("demo-mcp-server")
@server.tool()
async def get_weather(city: str) -> str:
return f"{city}:晴,28°C"
@server.resource("config://app")
async def get_config() -> str:
return '{"app_name": "demo", "version": "0.1.0"}'
async def main():
async with stdio_server() as (read_stream, write_stream):
await server.run(
read_stream,
write_stream,
server.create_initialization_options(),
)
asyncio.run(main())7.5 MCP 的局限
MCP 很适合解决标准化接入问题,但它也有边界:
- 协议统一不代表工具设计天然合理
- Tool 描述写得差,模型照样会调用失败
- 高风险操作仍然需要权限控制和审批
- 某些非常简单的场景,直接 function calling 反而更轻量
所以 MCP 是"基础设施层"的进步,不是万能抽象。
8. Skill:可复用的领域能力模块
8.1 Skill 解决了什么问题?
如果每次都只靠 Prompt 来要求 AI 遵守规范、执行流程,会很快遇到几个问题:
- 同一套要求每次都要重新写
- 细节容易遗漏,输出不稳定
- 团队很难统一版本和共享最佳实践
- 不同任务之间难以像积木一样组合能力
Skill 的价值就在这里。它把一类稳定、可复用的知识和流程,沉淀成一个长期存在的能力模块。
8.2 Skill 的本质是什么?
Skill 本质上可以理解为: "标准操作流程(SOP)+ 模板 + 脚本 + 参考资料" 的打包。
它适合存放那些相对稳定、不需要频繁实时更新的规则,比如代码审查规范、发布流程、安全检查清单、文档生成规范等。
换句话说,Prompt 更像"这次怎么做",而 Skill 更像"以后都按这个方法做"。
8.3 Skill vs Prompt
| 维度 | 普通 Prompt | Skill |
|---|---|---|
| 生命周期 | 当前对话 | 持久化,可复用 |
| 内容形态 | 纯文本指令 | 指令 + 脚本 + 模板 + 参考资料 |
| 版本管理 | 无 | Git 版本控制 |
| 团队共享 | 靠复制粘贴 | 统一分发,自动更新 |
| 适合内容 | 临时任务 | 稳定的领域规范和流程 |
8.4 Skill 的结构图在表达什么?
下面这个目录结构可以帮助你理解 Skill 为什么不只是"一段更长的 Prompt"。它往往会把行为规范、模板、脚本和参考资料放在同一个能力包里。
objectivec
my-skill/
├── SKILL.md
├── prompts/
├── scripts/
└── references/8.5 一个 Skill 定义示例
yaml
---
name: python-code-review
description: Python 代码审查技能,按团队规范检查代码质量
---
# Python Code Review Skill
## 角色
你是一位资深 Python 代码审查者。
## 检查清单
1. 公共函数必须有类型注解
2. 不允许裸 `except`
3. 禁止直接拼接危险命令
4. 关注性能与可测试性8.6 Skill 的作用与局限
Skill 非常适合沉淀"稳定流程",但不适合承载频繁变化的信息。
一个简单判断原则:三个月都不太变的东西,更适合放 Skill;每周都可能变化的东西,更适合放 RAG。
| 适合放 Skill | 适合放 RAG |
|---|---|
| 代码规范、命名约定 | API 文档、接口定义 |
| 安全检查清单 | 数据库 Schema |
| 测试要求、覆盖率标准 | 架构决策记录(ADR) |
| CI/CD 流程步骤 | 产品需求文档 |
| 团队协作规范 | 故障复盘报告 |
Skill 的局限也很明显:如果内容变化太快、维护不到位,Skill 很快就会过时;如果写得过重,又会增加使用门槛。因此 Skill 的关键不是"越大越好",而是"稳定、准确、可执行"。
9. Agent:从"对话"到"交付"
9.1 Agent 的定义
前面讲的 LLM、RAG、MCP、Skill 都可以看作零件,而 Agent 是把这些零件组织成一个执行闭环的系统。
Agent = LLM + Planning(规划)+ Memory(记忆)+ Tools(工具)
普通的 LLM 调用更像顾问:你问,它答。Agent 更像执行者:你给目标,它会拆步骤、调工具、观察结果、修正策略,直到完成任务或明确失败。
9.2 Agent 在系统里扮演什么角色?
Agent 的核心价值不是"会聊天",而是"会围绕目标持续推进"。它通常负责:
- 理解目标并拆解任务
- 决定下一步是思考、检索还是调用工具
- 根据工具结果更新状态
- 在必要时继续迭代,直到完成或终止
也正因为如此,Agent 是最接近"把 AI 变成生产力系统"的一层抽象。
9.3 ReAct 图的重点是什么?
ReAct(Reasoning + Acting)是当前非常经典的一种 Agent 思路。下面这张图想表达的核心不是流程复杂,而是一个最小闭环:
- 先思考下一步要做什么
- 再执行动作
- 再观察结果
- 再根据结果决定下一步
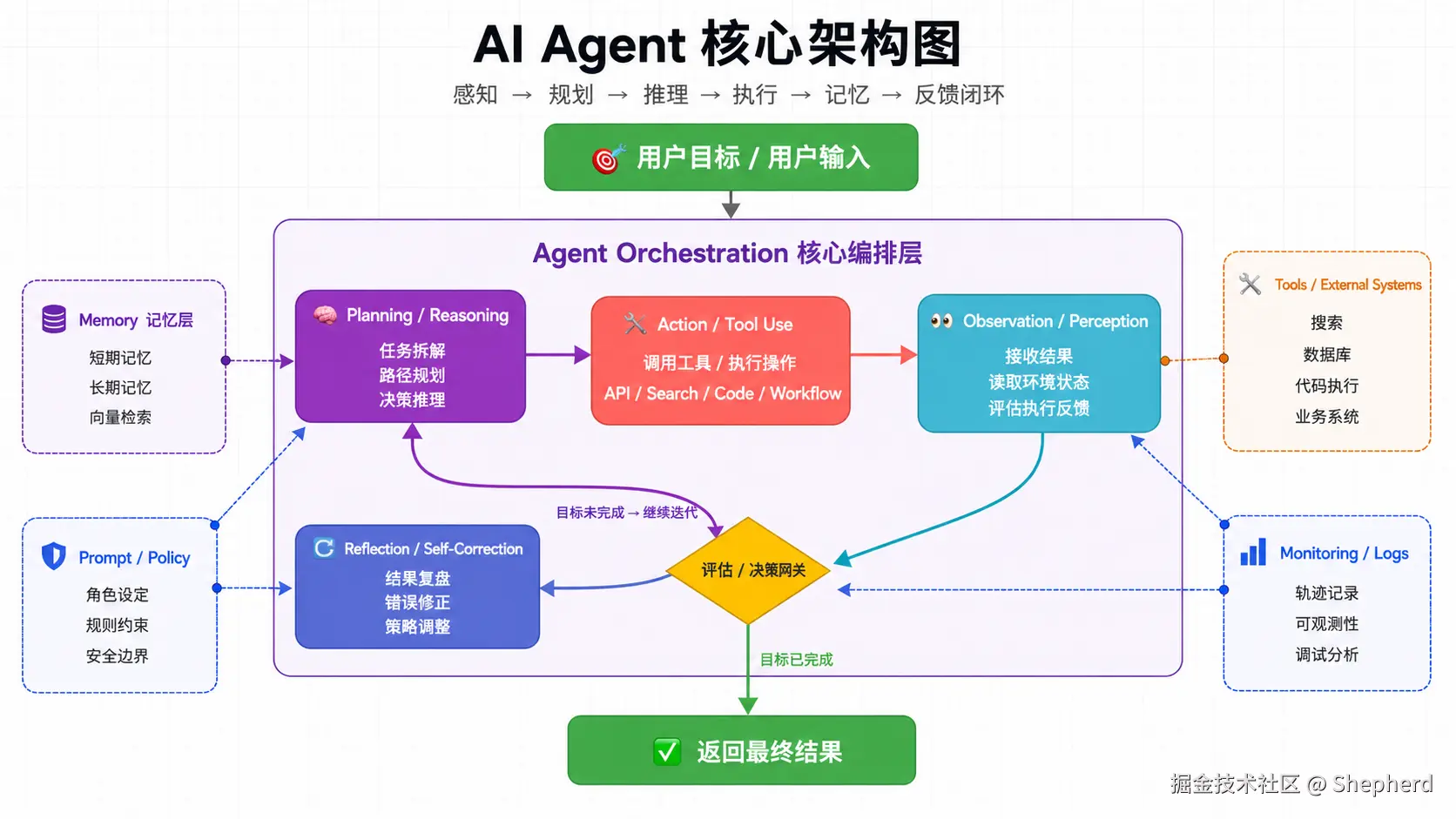
9.4 一个最小 ReAct Agent
下面这段代码只保留 ReAct 的核心骨架:决策 → 调工具 → 记录观察 → 继续或结束。这样读者更容易抓住 Agent 的本质,而不是陷入大量辅助细节。
python
class SimpleAgent:
def __init__(self, llm, tools, max_steps=5):
self.llm = llm
self.tools = tools
self.max_steps = max_steps
self.history = []
def run(self, task: str):
for _ in range(self.max_steps):
action = self.llm(task=task, history=self.history)
if action["type"] == "finish":
return action["answer"]
result = self.tools[action["tool"]](action["input"])
self.history.append(
{
"thought": action["thought"],
"action": action["tool"],
"observation": result,
}
)
return "达到最大步数,任务未完成"
def search(query: str) -> str:
return f"搜索结果:{query}"如果用一句话概括这段代码,它表达的是:Agent 不是一次性生成答案,而是靠多轮"思考-行动-观察"逐步逼近目标。
9.5 Agent 的工程挑战
Agent 看起来最像"自动化员工",但它也是最容易出问题的一层。
| 挑战 | 说明 | 常见缓解策略 |
|---|---|---|
| 可靠性 | 可能走偏、循环、误判 | max_steps、超时、人工审核点 |
| 成本控制 | 多轮调用会快速消耗 token | 小模型规划、大模型执行、结果缓存 |
| 工具设计 | 工具描述不清会导致误用 | 清晰 schema、结构化错误返回 |
| 安全边界 | 可能执行危险操作 | 权限隔离、审批机制、只读模式 |
所以 Agent 的真正难点,不是"让它能跑起来",而是"让它在真实环境里稳定、可控、可追踪地跑"。
10. 协同:一张图看懂所有概念如何一起工作
前面每个概念单独看都不算太难,真正有价值的是把它们放进同一个场景里理解。
假设你对一个 AI 编程 Agent 说:"请根据 GitHub Issue 实现一个新功能。"
这个过程中通常会发生以下事情:
- Prompt 把你的目标表达给系统
- 系统把任务说明、历史、规则、检索结果等组装成 Context
- LLM 基于当前 Context 做理解和规划
- 如果缺少业务资料,就通过 RAG 检索相关文档
- 如果需要访问 GitHub、文件系统或数据库,就通过 MCP 调用工具
- 如果团队有稳定流程,比如代码评审规范、提交规范、发布流程,就通过 Skill 复用
- 整个多步执行闭环由 Agent 负责推进,直到任务完成
下面这张总览图,就是把这几个环节重新放回同一个真实任务流中。

11. 总结
如果要把全文压缩成一句话,可以这样记:
LLM 负责思考,Token 负责计量,Context 负责承载,
Prompt 负责下达指令,RAG 负责补知识,
MCP 负责接工具,Skill 负责沉淀经验,
Agent 负责把这一切组织成真正能完成任务的系统。最后再强调几个常见误区:
| 误区 | 真相 |
|---|---|
| "上下文窗口越大越好" | 窗口越大不代表效果必然越好,噪声、延迟和成本也会同步上升 |
| "RAG 可以解决一切知识问题" | RAG 的效果高度依赖检索质量、切片策略和文档质量 |
| "Prompt 写得好就够了" | Prompt 很重要,但它不能替代外部知识、工具接入和结果校验 |
| "MCP 会让模型更聪明" | MCP 解决的是标准化接工具的问题,不是提升模型本身智力 |
| "每个任务都需要 Agent" | 简单问答不需要 Agent,Agent 更适合多步推理、工具调用和目标执行 |
当你真正理解了这些概念的分工与边界,就会发现:AI 应用的本质并不是"押中一个最强模型",而是把模型、上下文、知识、工具和流程组织成一个协同系统。这也是从"会用 AI"走向"能搭 AI 系统"的关键一步。