在 DAIS 2026 上,Databricks 把 LTAP 再次推到台前,并把它与 Lakebase、Lakehouse/RT 等能力放在同一轮发布叙事里。
表面上看,这是一次数据架构话题的回潮,但放到企业 AI 落地的语境里,它其实在回答一个更现实的问题:当企业既要处理交易,又要支撑分析和 AI,底层架构还能不能继续依赖多套系统层层拼接?
1. Databricks 为什么又把 LTAP 推到台前?
在传统数据架构里,交易系统负责写入,分析系统负责查询,AI 系统再从分析层、特征层或者向量层取数。这套分工曾经足够清晰,也支撑了很长一段时间的报表、BI 和离线分析需求。

但当企业开始把 RAG、Copilot、Agent 甚至自动化业务流程真正放进生产环境,原来的数据路径就会变得越来越重。数据每多经过一层 CDC、同步和加工,延迟就增加一层,治理成本也增加一层,指标口径出错的机会也多一层。
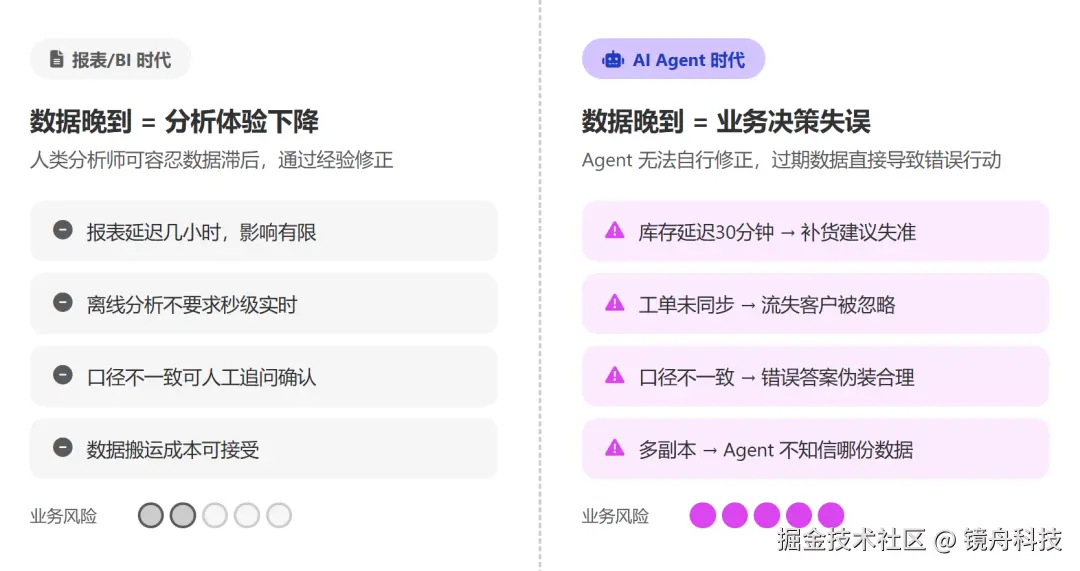
在报表时代,数据晚一点,可能只是影响分析体验;但在 Agent 时代,数据晚一点,就可能影响业务判断。
比如,一个客户成功 Agent 需要判断哪些客户存在流失风险。它不仅要看过去几个月的产品使用情况,还要知道客户昨天是否提交了严重工单、合同是否即将到期、销售是否刚刚更新了续约状态。如果这些数据分散在 CRM、工单系统、产品埋点和数仓里,中间再经过多层同步,Agent 很可能拿着"昨天之前的客户画像"去判断今天的客户风险。
从这个角度看,LTAP 的回潮反而是 AI 应用开始反过来倒逼底层数据架构调整的结果。
Databricks 这次高调重提 LTAP,是想要尽量让同一份数据同时服务更多工作负载,减少 CDC 管道、重复副本和中间链路带来的复杂度。换句话说,AI 时代的数据平台不能只追求"把数据存下来",还要让业务系统、分析系统和 AI 应用更快地使用同一份可信数据。
2."一份数据服务一切"是否好落地?
在概念层面,"一份数据服务一切"天然有说服力。它意味着更少的数据搬运、更低的延迟、更统一的治理,也更适合 AI 应用调用。
但在工程层面,又会涉及许多具体的落地问题。
交易型负载追求一致性、短事务和稳定点查。分析型负载追求高吞吐、复杂聚合和大范围扫描。AI Agent 的调用则更进一步,它既希望数据足够实时,又希望接口稳定、语义清晰、权限可控,并且能够解释每一次结果从哪里来。
这些需求长期以来由不同系统分别优化。现在如果一套平台要同时承担更多责任,就必须解决资源隔离、弹性调度、负载相互干扰和治理边界的问题。否则,"一份数据服务一切"很容易从理想架构变成生产风险。
例如,在金融风控场景里,Copilot 如果要辅助判断一笔贷款申请是否存在风险,就需要同时理解用户最近交易、历史还款记录、当前授信状态和最新风控规则。如果底层平台无法同时保证实时性、一致性和查询稳定性,AI 给出的建议就很难真正进入审批流程。
所以LTAP 能不能成立,关键在于底层平台能否在混合负载下持续保持稳定、实时和可治理。这也是 AI 时代数据平台面临的新考验,即如何让不同负载在同一条业务链路中可靠协同。
3. 消除数据延迟,企业未必要走大一统路线
当然,企业架构升级往往也需要分阶段推进。当 AI 从"辅助回答问题"走向"参与业务判断",数据平台要解决的不只是数据怎么更快到达模型,还包括模型如何在复杂业务里理解这些数据、记住这些数据,并在正确的语义和权限范围内使用这些数据。
 如果查询层不稳定,Agent 就无法可靠取数;如果语义层不清晰,模型就不知道"收入""活跃客户""流失风险"在企业内部到底怎么定义;如果调用链路不可追踪,企业就很难评估一次 AI 建议到底基于哪些数据、经过了哪些步骤、是否值得信任。
如果查询层不稳定,Agent 就无法可靠取数;如果语义层不清晰,模型就不知道"收入""活跃客户""流失风险"在企业内部到底怎么定义;如果调用链路不可追踪,企业就很难评估一次 AI 建议到底基于哪些数据、经过了哪些步骤、是否值得信任。
这也是镜舟更关注的方向,数据库不只是回答 SQL 的地方,也是 Agent 理解业务现场的上下文层。
在这个上下文层里,底层数据要足够实时,业务语义要足够清晰,Agent 的调用过程要能够被追踪、被评估,历史经验也要能被沉淀下来,避免每一次决策都从零开始。
还是以零售补货为例,一个真正可用的补货 Agent,不只是能查出"某个 SKU 当前库存是多少",还要理解什么叫安全库存、哪些门店属于高优先级门店、哪些促销活动会改变正常销量趋势、过去类似情况下运营团队是怎么处理的。
这些能力不完全来自模型本身,而来自模型背后是否有一个稳定、实时、语义清晰的业务上下文层。
因此,消除数据延迟未必只有"大一统"一条路。对多数企业来说,更重要的是先让 AI 决策最依赖的数据链路变短,让模型能在正确上下文里使用正确数据。
4. AI 时代的数据平台竞争,正在进入下一阶段
AI 时代的数据平台竞争点正在从单纯的存储和计算,转向一条更长的能力链。
今天很多企业在做 AI 问数、智能分析和业务 Agent 时,不是模型不会生成 SQL,而是模型并不真正理解企业内部的指标口径、语义关系和业务上下文。
比如同样是"客户收入",财务系统、销售系统和数据分析系统可能有不同口径;同样是"活跃用户",产品团队和运营团队可能采用不同定义;同样是"高价值客户",销售、客服和经营分析团队也可能有不同判断标准。
人类分析师遇到这些问题时,可以通过经验、追问和确认来修正。但 Agent 如果缺少语义层约束,就可能把错误口径包装成一个看似合理的答案。
在此之上,语义层不再只是外围工具链的一部分,将重新回到数据平台的核心位置。它需要帮助模型理解企业指标、业务对象、关系约束和权限边界,让 AI 不只是"查到数据",更要"用对数据"。
AI 时代,数据库不再只是数据存储引擎,而是企业业务上下文(Business Context)的基础设施。
未来竞争,不是谁拥有更多数据,而是谁能够让Agent持续理解、记忆并正确使用企业运营知识。镜舟正从企业数据库演进为AI Operating Platform for Enterprise,打造AI时代的企业全域智能中枢(Enterprise Inteligence Hub)。