导读 :本文介绍 Databend / OpenRaft 中一个轻量级 histogram 实现:仅用约 2KB 内存 ,即可支持 O(1) 延迟记录 ,并在 P50 / P95 / P99 等 percentile 估算中,将典型 latency 场景误差控制在 0.2% 以内。文章亮点是从数据库内核的真实约束出发,讲清楚如何在低内存、低开销和高精度之间取得平衡,适合数据库内核工程师、后端性能优化工程师、SRE、可观测性系统开发者阅读。阅读时间约 8 分钟。
问题:高效追踪 request latency
对云数仓来说,性能不只是平均查询时间,更重要的是 tail latency、可预测性和故障定位能力。在 Databend 这样的云原生数仓里,一个 request 可能经过 SQL planning、distributed execution、remote storage、raft log、state machine apply 等多个阶段。任何一个环节的长尾延迟,都会影响用户感知到的查询稳定性。因此需要一种足够轻量、足够准确、不会拖慢 hot path 的方式,持续追踪系统内部的 latency 分布。
以一条 raft log 的 lifecycle 为例,以下每个阶段的 latency 都需要单独统计:
- 从被接收到写入 storage 的时间
- persist 到本地 storage 的时间
- 本地 persist 后 replicate 到远端的时间
- cluster 中半数以上节点完成 persist 的时间
- 从 commit 到在 state machine 中被 apply 的时间
要描述一个 metric 中多条 log 的 latency 分布,通常使用 histogram:横轴是 latency,纵轴是对应 latency 的 request 数量。这样可以直观地看出每个阶段的 latency 主要集中在哪些范围。
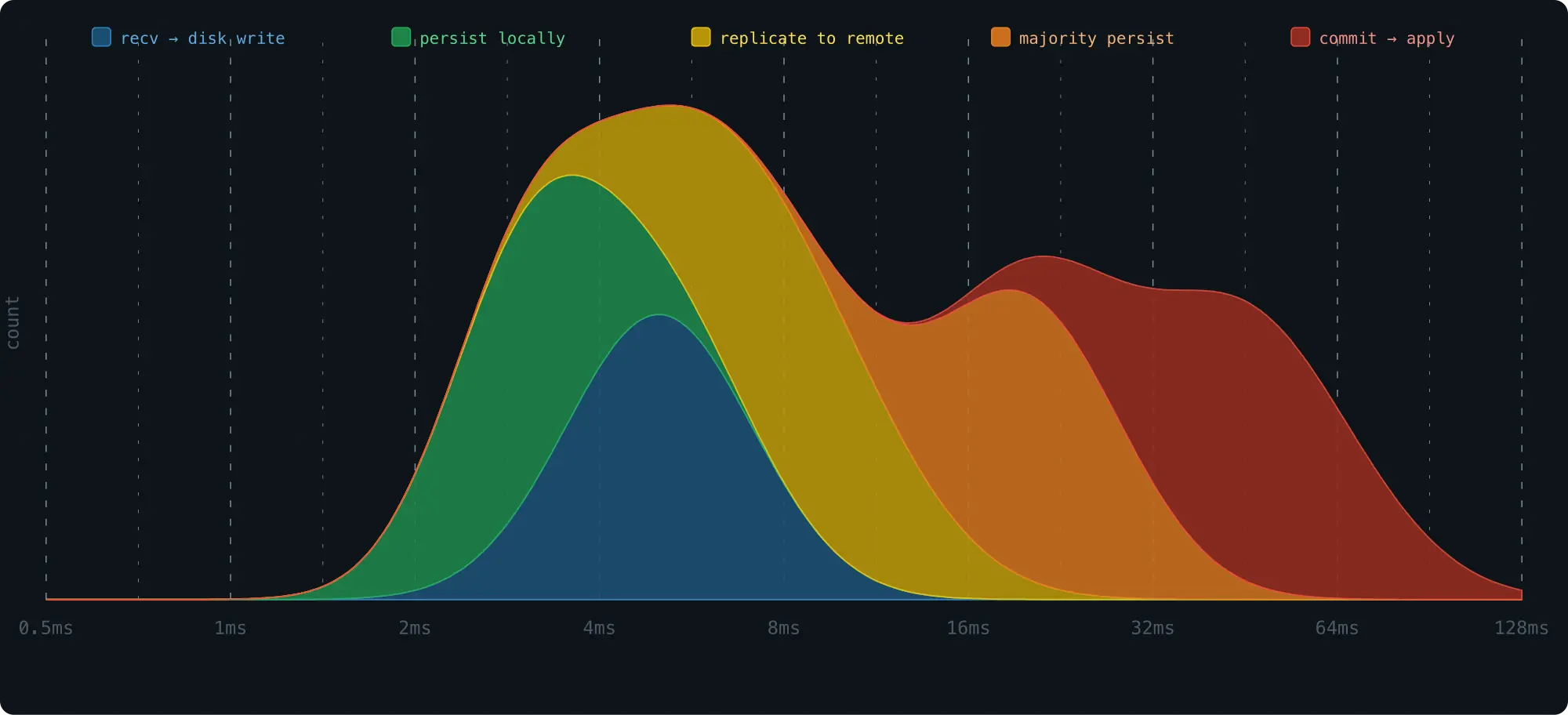
有了这些 latency 分布信息,就能定位各环节的 bottleneck,有目标地优化。
不过 metric 采集不能影响系统正常运行,所以对 histogram 的设计有几个要求:
- 记录操作必须 O(1),不能拖慢 hot path
- memory overhead 要小 ------ 系统中可能有成百上千个 histogram instance
- 支持 percentile 查询(P50, P95, P99)
Databend 内部可能同时维护大量 request、query、storage、Raft、pipeline 相关指标。如果每个指标都使用高内存 histogram,或者采集路径需要浮点计算,就会给 hot path 带来额外压力。
所以这里的目标不是做一个最通用的 histogram,而是做一个适合数据库内核的 histogram:低内存、整数计算、可大量实例化,并且对 P95 / P99 足够准确。我们从需求出发,一步步设计 histogram 方案。
统计:如何记录 latency
Latency 分布与 log2 bucketing
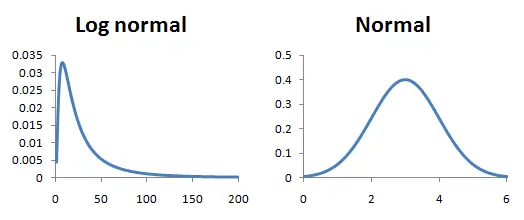
大部分 request 的延迟集中在某个范围内,特别快和特别慢的较少。 现实中的 latency 分布基本符合 log-normal distribution------对 latency 值取对数之后呈 normal distribution。
log-normal 的特点是:曲线在小数值范围内有一个 peak,形状类似 normal distribution;数值较大时则逐渐变平,形成 long tail。
要统计每个 latency 范围内的 request 个数,最直接的方法是把 x 轴分成若干 bucket,为每个 bucket 统计落在其中的 request 个数。
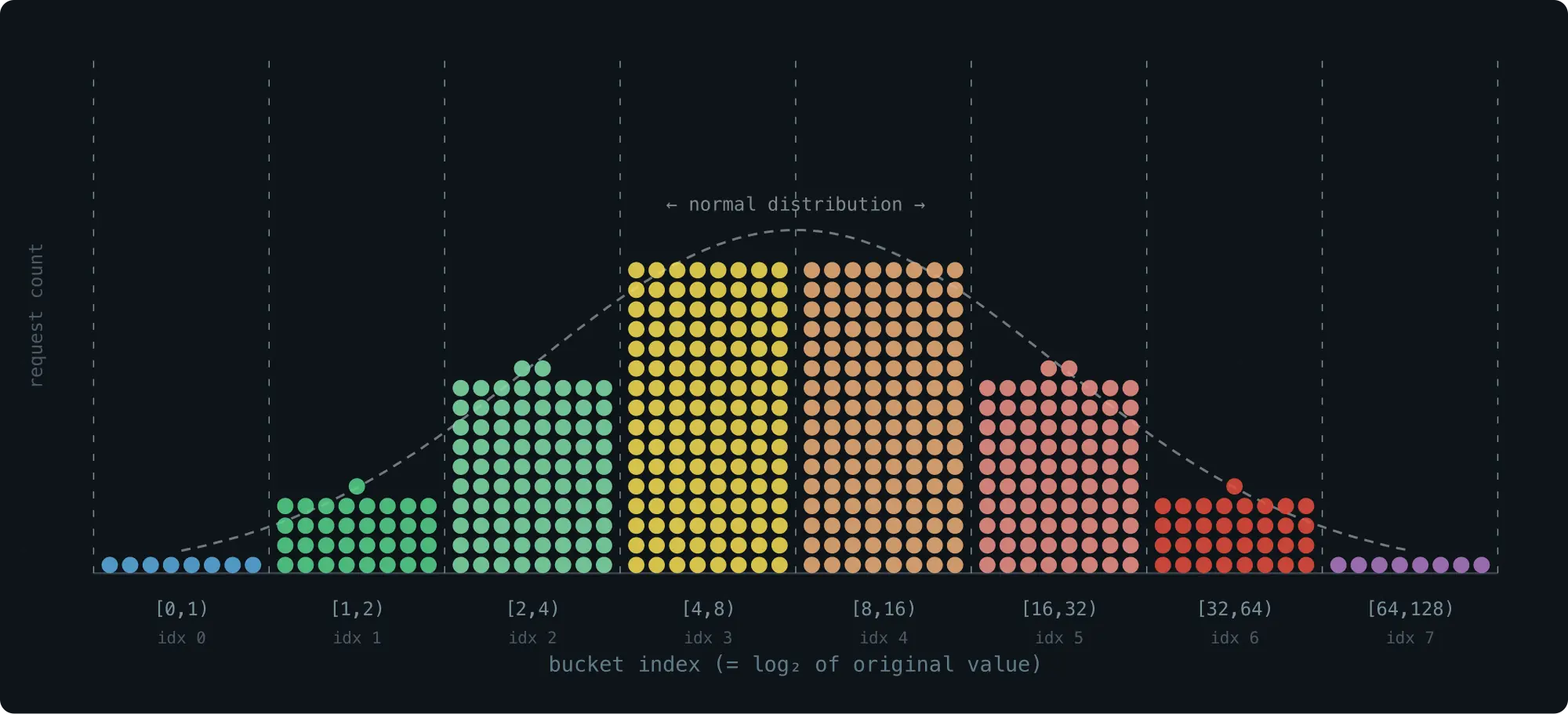
bucket 的划分应该匹配数据的分布。对 normal distribution,等宽 bucket 就够了;但 request latency 是 log-normal 分布------对 x 轴取对数之后才是均匀的,所以横轴应该用 log scale 来划分 bucket,而不是 linear scale。
换句话说,x 轴上的 bucket 应该等比例增长。最简单的方案:让每个 bucket 的大小是前一个的 2 倍:
- 按 2 的幂次划分 bucket:
[0,1), [1,2), [2,4), [4,8), [8,16), ... - 每个 bucket 是前一个的 2 倍 ------ 最简单的指数增长方案。
选择 2 作为倍数,因为乘 2 在计算机中极快,而且给定一个值,计算它落在哪个 bucket 也只需一次 leading zero counting(单条指令)。
用 log-normal distribution 模拟 request 负载来进行一次统计,以 bucket index 为 x 轴(相当于对原始坐标取了对数),落在每个 bucket 里的 request 个数就会呈 normal distribution。
这个方案存储上非常高效 ------ 覆盖整个 u64 范围只需 65 个 bucket ,但缺点也很明显:粒度太粗。最后一个 bucket 占了整个取值区间的一半,落在这个范围里的 request 几乎无法区分。
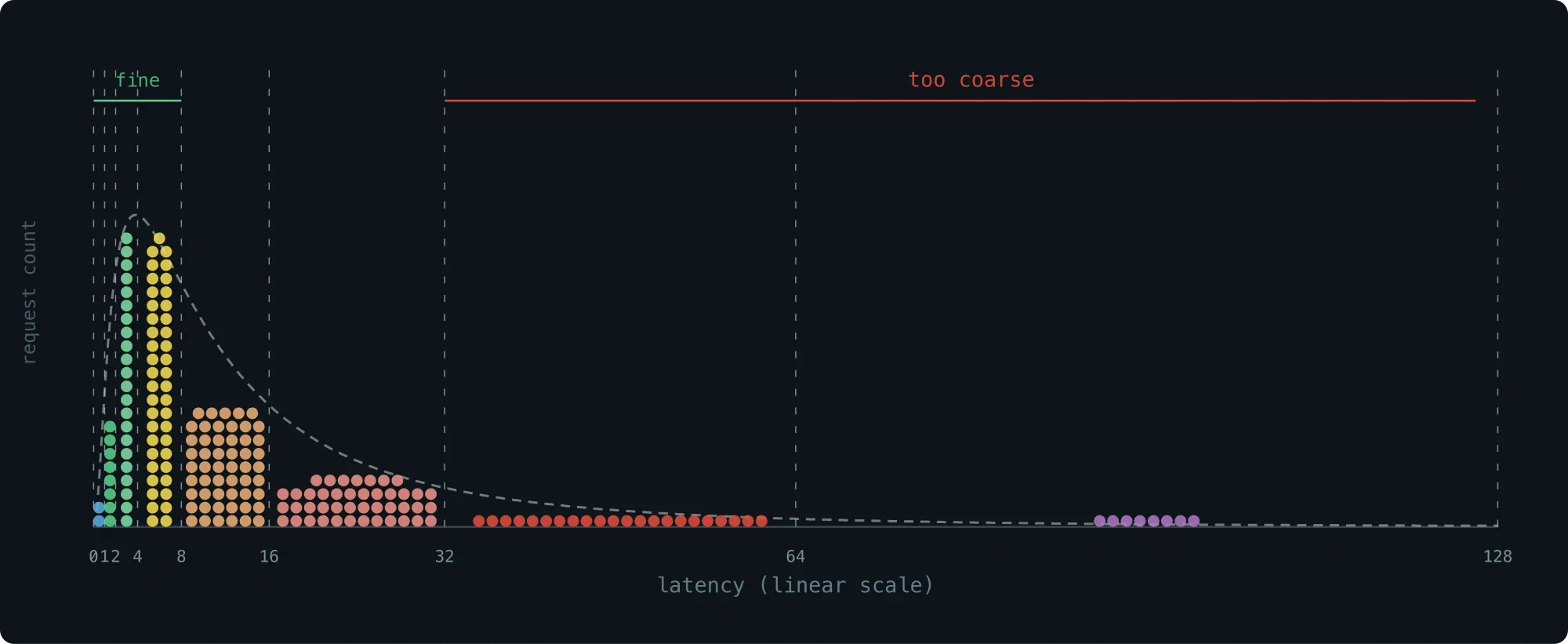
未采纳的改进:减小倍数,提高精度
一个自然的改进想法:不以 2 倍增长,而是以较小的倍数增长,比如 1.1 倍。bucket 划分更细了,精度自然上升:
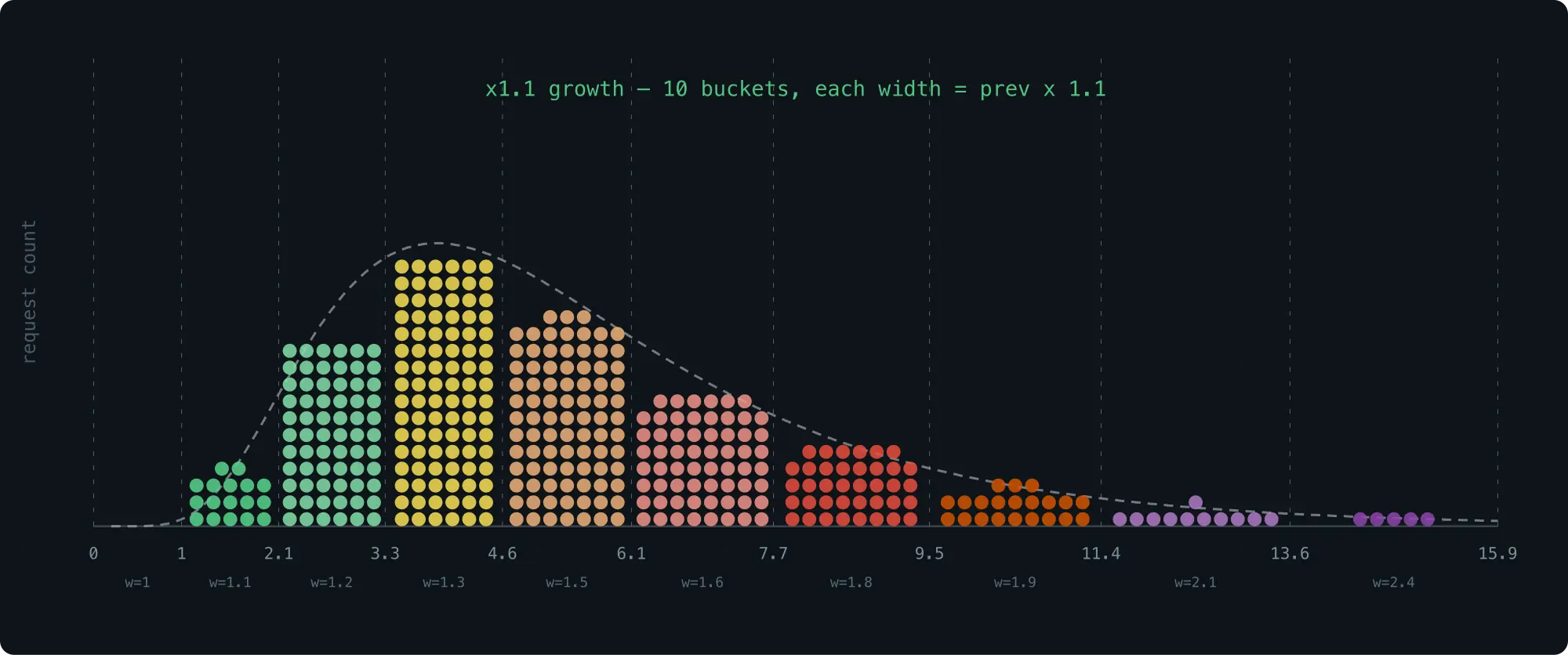
但代价是采集阶段引入了浮点运算。对给定 latency 值 l,要找到对应的 bucket,需要求最小的 x 使得 1 + 1.1 + 1.1^2 + ... + 1.1^x >= l------这涉及浮点的对数运算,overhead 不小。
我们希望避开浮点运算,用整数或 bit 运算完成。
类浮点数编码
换个思路:还是用近似等比的倍数设置 bucket size,但把描述 bucket size 的位数固定为 WIDTH 个 bit。
我们把一个 bucket 的左边界(即它包含的最小值)看作一个 定宽浮点数 ------MSB (most significant bit) 决定 "exponent"(即 bucket group 的 index),紧跟其后的几位决定 bucket 在 group 内的编号。
以 WIDTH=3(默认配置)为例,每个 bucket 的左边界满足如下形式:
text
00..00 1 xx 00..00
|
MSB
<- significant第一个 1 的 位置 决定 bucket 属于哪个 group,后面的 xx(两个 bit)表示 bucket 在 group 内的编号。
下面列出前几个 group 的 bucket 设置 ------ 只用 3 bit 就描述了一个 bucket 的区间:
text
WIDTH = 3:
range bucket index bucket size
[0, 1) 0 0b0 ..... 000 1
[1, 2) 1 0b0 ..... 001 1
[2, 3) 2 0b0 ..... 010 1
[3, 4) 3 0b0 ..... 011 1
[4, 5) 4 0b0 ..... 100 1
[5, 6) 5 0b0 ..... 101 1
[6, 7) 6 0b0 ..... 110 1
[7, 8) 7 0b0 ..... 111 1
[8, 10) 8 0b0 .... 1000 2
[10, 12) 9 0b0 .... 1010 2
[12, 14) 10 0b0 .... 1100 2
[14, 16) 11 0b0 .... 1110 2
[16, 20) 12 0b0 ... 10000 4
[20, 24) 13 0b0 ... 10100 4
[24, 28) 14 0b0 ... 11000 4
[28, 32) 15 0b0 ... 11100 4
[32, 40) 16 0b0 .. 100000 8
[40, 48) 17 0b0 .. 101000 8
[48, 56) 18 0b0 .. 110000 8
[56, 64) 19 0b0 .. 111000 8可以看到:
- 每个 bucket group 有
2^(WIDTH-1) = 4个 bucket - MSB 后的 2 位选择 group 内的 bucket
- 本质上是一个 3 bit 的浮点数:1 bit 隐含前导 1 + 2 bit 小数部分
这样既得到了近似对数增长的 bucket size,计算 bucket index 也只需对给定 latency 值的二进制表示取最高 WIDTH 个 bit,做几步整数和 bit 操作即可。记录一个 sample 只需 O(1) 操作。
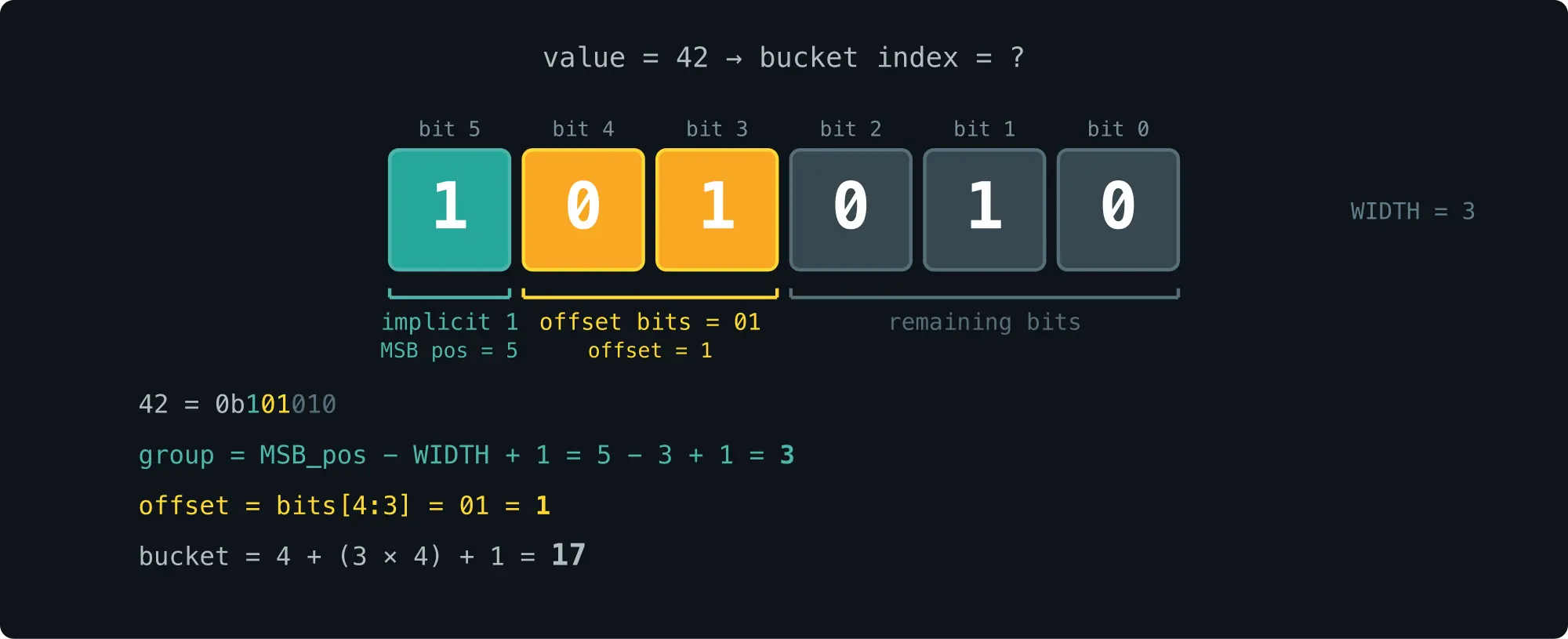
举例:latency = 42
text
值 = 42 (binary: 0b101010)
MSB position: 5
group: 5 - 2 = 3
MSB 后 2 位: 01 (来自 1[01]010)
offset in group: 1
Bucket index: 4 + (3 × 4) + 1 = 17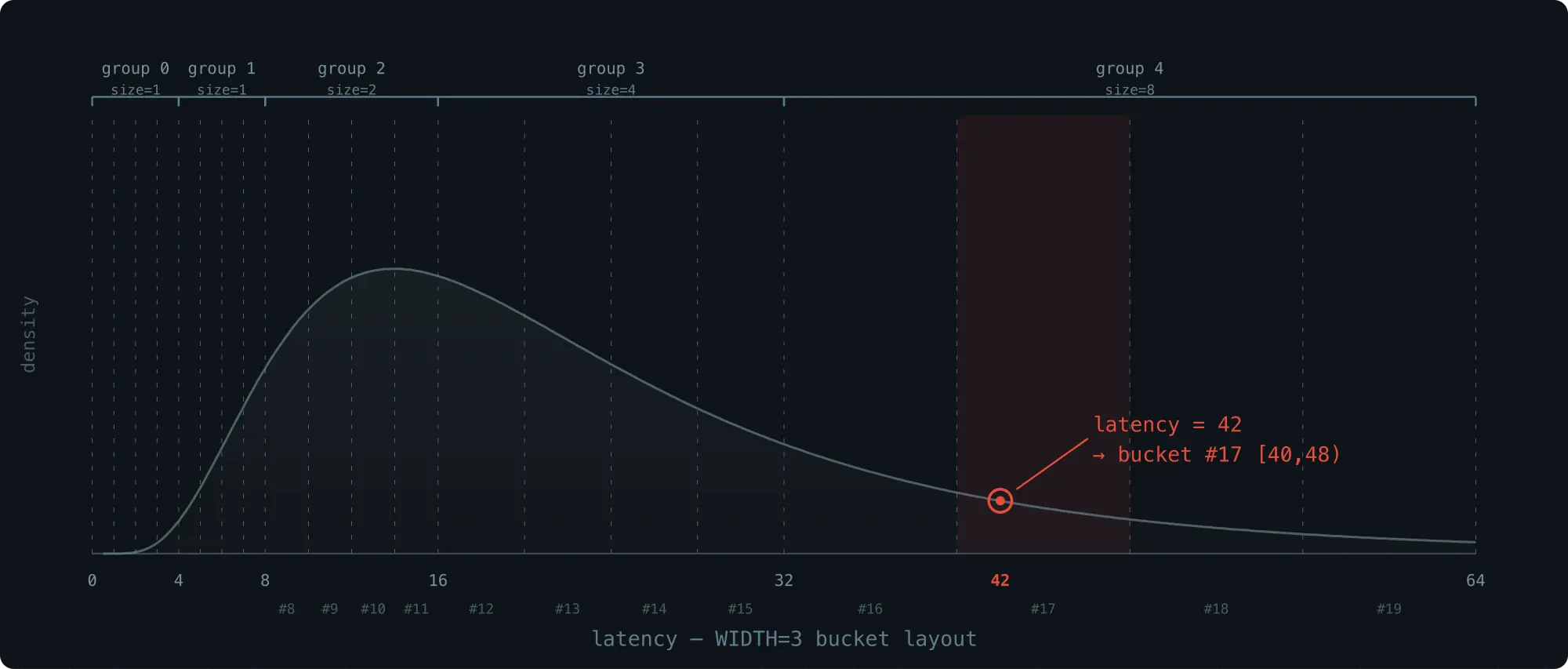
WIDTH 参数:精度与 memory 的权衡
WIDTH 控制每个 group 有多少个 bucket(2^(WIDTH-1) 个)。group 的数量不超过 64 个(因为 group 还是以 2 倍方式增长,覆盖 u64 范围)。
WIDTH 可以根据精度需要来调整:
| WIDTH | Buckets | Mem/slot | 每 group bucket 数 |
|---|---|---|---|
| 1 | 65 | 520 B | 1 |
| 2 | 128 | 1.0 KB | 2 |
| 3 | 252 | 2.0 KB | 4 (默认) |
| 4 | 496 | 3.9 KB | 8 |
| 5 | 976 | 7.6 KB | 16 |
| 6 | 1920 | 15.0 KB | 32 |
默认
WIDTH=3,只需 2 KB memory 即可统计一个 metric 的 latency 分布,记录过程 O(1)。
到这里,记录的问题解决了。
Percentile 估算:如何读取
下一步是把统计信息转换成 percentile ------ 前 50% 的 request 在多少时间内完成(P50),前 90% 在多少时间内完成(P90),依此类推。
定位目标 bucket
Percentile 的计算很直接。以 P50 为例:先算出总 sample 数,取其 50% 得到目标值 p,然后从第一个 bucket 开始累加其中的 sample 数,当累加和超过 p 时,就找到了目标 bucket。
但 bucket 覆盖的是一个 latency 范围,不是一个精确值。找到目标 bucket 之后,还需要在 bucket 内部定位:估算 percentile 对应的具体 latency 值。
我们来看几种精度递增的估算方法。以下误差数据均来自 log-normal distribution (API latency 场景),WIDTH=3,1,000,000 sample。
方法一:取 midpoint
返回 bucket 的 (min + max) / 2。这是很多 histogram 库的默认做法(例如 iopsystems/histogram)。
它的问题是盲猜 ------ 完全没有利用 bucket 内 sample 的分布规律。在 log-normal 分布上实测误差:
| P50 | P95 | P99 | |
|---|---|---|---|
| midpoint | 5.018% | 7.732% | 4.861% |
方法二:均匀插值
比 midpoint 好一步:假设 bucket 内的 sample 均匀分布(矩形),根据 rank 在 bucket 内的位置做线性插值: 估算值 = min + (max - min) × rank / count。
这比 midpoint 好,因为它至少利用了 rank 在 bucket 内的相对位置,但"均匀分布"仍然是一个粗糙的假设 ------ 实际上 log-normal 分布在每个 bucket 内也有倾斜。
方法三:梯形插值(本项目采用)
均匀插值假设 bucket 内部的 density 是一个常数(矩形)。但实际上 density 是有倾斜的 ------ 靠近分布 peak 的一侧 density 更高。
如果我们能知道这个倾斜方向,就可以把矩形变成一个梯形,得到更精确的估算。
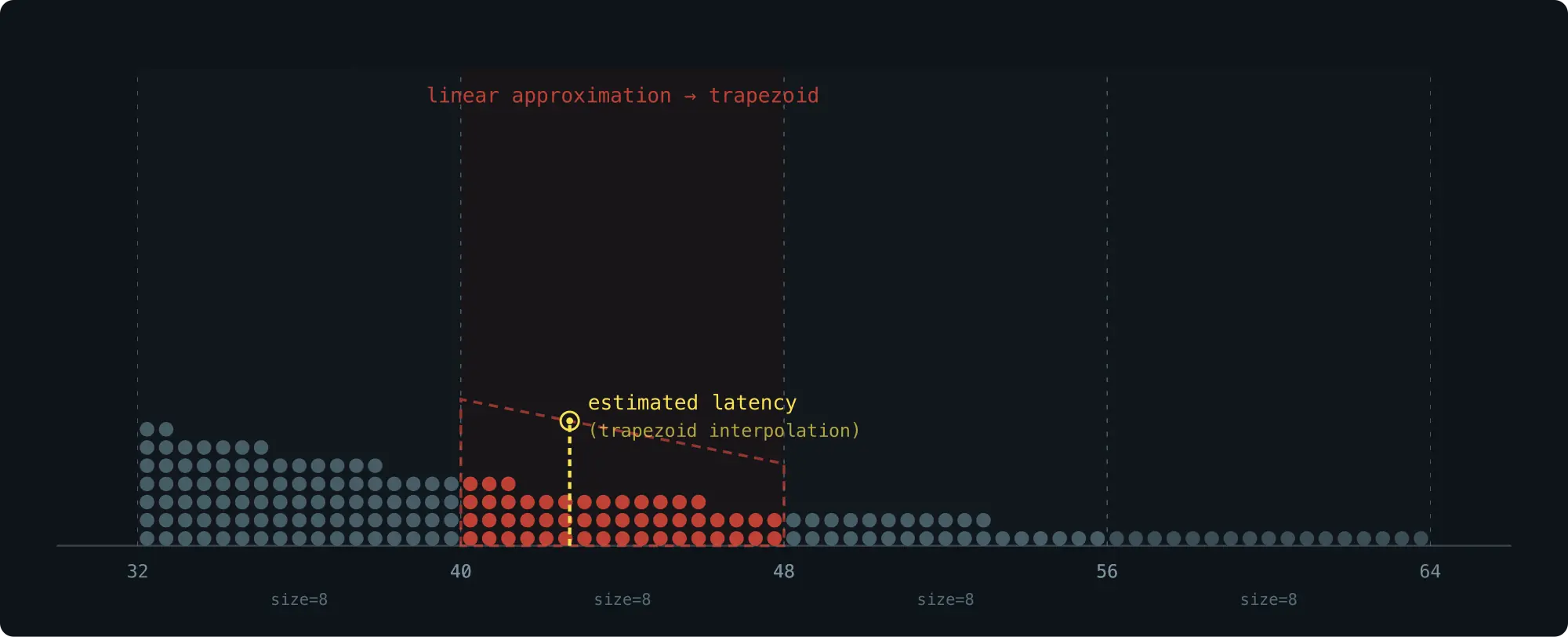
bucket 本身只存了一个 count 值,我们也不想增加额外存储。办法是利用左右两个相邻 bucket 的信息来推断 density 的倾斜方向。
相邻 bucket 的 sample density 能告诉我们当前 bucket 内分布的倾斜方向。
具体做法:取左 bucket 的平均 density d0 = c0/(x1-x0) 作为其 midpoint m0 处的 density,取右 bucket 的平均 density d2 = c2/(x3-x2) 作为其 midpoint m2 处的 density。假设 density 从 m0 到 m2 线性变化(范围不大,可以忽略二阶导数),由此得到 slope k。
目标 bucket 内的 sample 分布就构成一个梯形:斜边 slope 为 k,经过当前 bucket 的 midpoint (x1+x2)/2,该点处的 density 等于 bucket 自身的平均 density d1 = c1/(x2-x1)(线性变化的中点 density 等于平均 density)。
根据这个梯形的面积来定位目标 percentile 的位置。
同样的 log-normal 分布、同样的 bucket 结构,梯形插值的误差:
| midpoint | 梯形插值 | |
|---|---|---|
| P50 | 5.018% | 0.000% |
| P95 | 7.732% | 0.080% |
| P99 | 4.861% | 0.086% |
相同的 bucket 结构下,梯形插值把误差降低了两个数量级。
三个相邻 bucket 的布局:
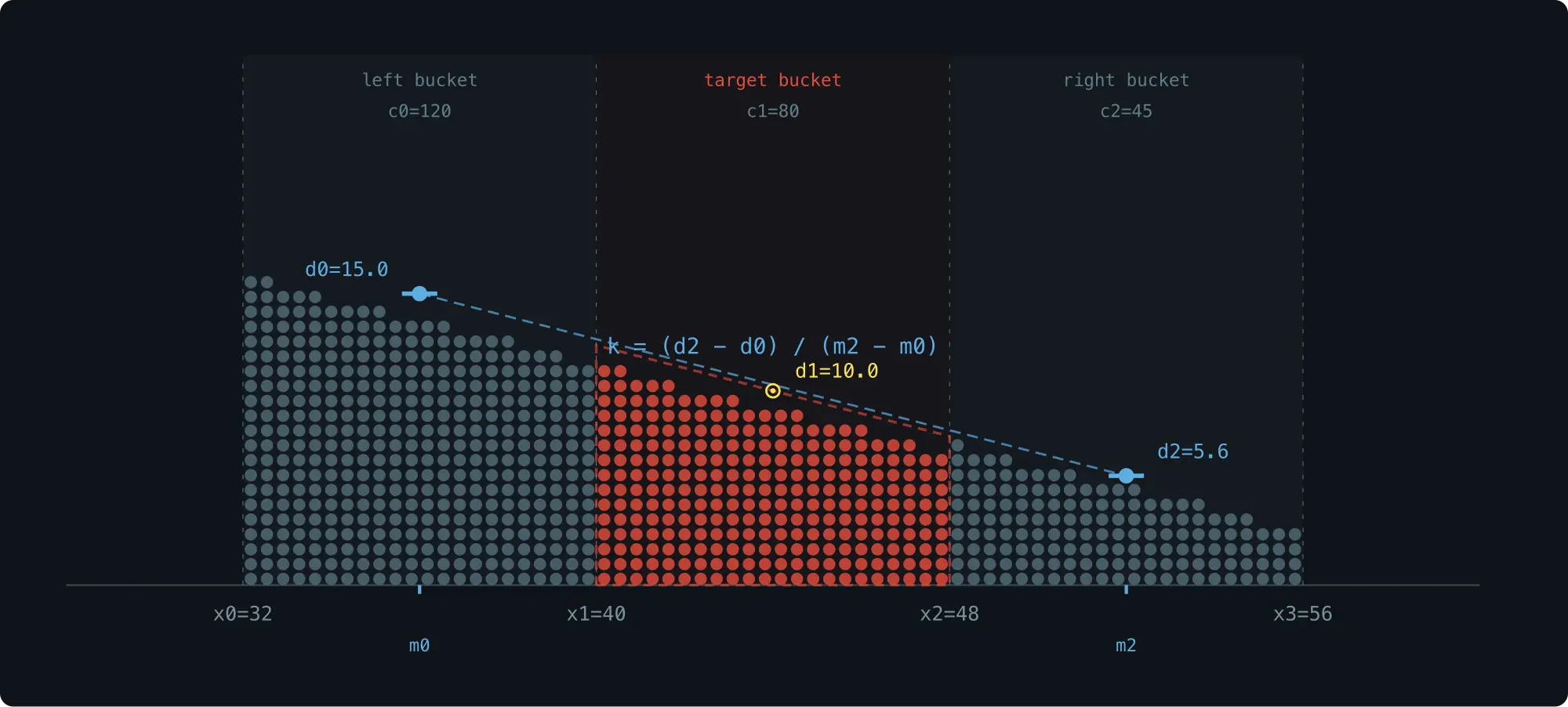
| 变量 | 含义 |
|---|---|
x0, x1, x2, x3 |
三个相邻 bucket 的边界 |
w0, w1, w2 |
三个 bucket 的宽度: w0 = x1-x0, w1 = x2-x1, w2 = x3-x2 |
c0, c1, c2 |
三个 bucket 的 sample count |
rank |
目标 percentile 在 target bucket 内是第几个 sample |
text
d0 = c0 / w0 -- 左 bucket density
d1 = c1 / w1 -- 目标 bucket density
d2 = c2 / w2 -- 右 bucket density取左 bucket midpoint m0 = (x0+x1)/2 和右 bucket midpoint m2 = (x2+x3)/2,density 变化 slope 为:
text
k = (d2 - d0) / (m2 - m0)最后,找到 x 轴上的位置,使得从 x1 到该位置的梯形面积等于 rank 即可。
整个过程只使用了三个相邻 bucket 的 count 和边界 ------ 不需要额外存储。
Benchmark:不同 distribution × 不同 WIDTH
最后,我们在 7 种典型分布 上测试不同 WIDTH 的误差(1,000,000 sample,梯形插值)。
重点关注 LN-API 和 LN-DB 两行的 W=3 列 ------ 这是最典型的 latency 场景,也是默认配置(2 KB memory)下的实际表现:
text
| W=1 W=2 W=3 W=4 W=5 W=6
| ------------------------------------------------------------------
| Uniform P50 0.108% 0.028% 0.012% 0.018% 0.019% 0.002%
| P95 2.317% 1.988% 1.035% 0.475% 0.005% 0.005%
| P99 4.290% 4.129% 3.706% 1.486% 0.298% 0.162%
|
| LN-API P50 2.281% 0.182% 0.000% 0.000% 0.000% 0.000%
| P95 20.256% 3.963% 0.080% 0.040% 0.040% 0.000%
| P99 11.951% 3.594% 0.086% 0.000% 0.029% 0.000%
|
| Bimodal P50 1.381% 0.394% 0.394% 0.197% 0.197% 0.197%
| P95 3.918% 0.172% 0.012% 0.028% 0.038% 0.008%
| P99 1.521% 1.344% 0.543% 0.078% 0.016% 0.014%
|
| Expon P50 1.012% 0.000% 0.145% 0.145% 0.145% 0.000%
| P95 10.989% 0.200% 0.000% 0.000% 0.033% 0.033%
| P99 18.665% 4.574% 0.824% 0.022% 0.022% 0.022%
|
| LN-DB P50 2.018% 0.034% 0.000% 0.000% 0.000% 0.034%
| P95 2.027% 0.368% 0.039% 0.006% 0.019% 0.026%
| P99 3.764% 1.066% 0.187% 0.007% 0.003% 0.062%
|
| Sequent P50 0.095% 0.000% 0.000% 0.000% 0.000% 0.000%
| P95 2.271% 1.967% 1.011% 0.496% 0.000% 0.000%
| P99 4.272% 4.118% 3.696% 1.521% 0.305% 0.169%
|
| Pareto P50 10.127% 1.899% 0.633% 0.633% 0.633% 0.000%
| P95 9.239% 0.272% 0.000% 0.136% 0.000% 0.000%
| P99 3.517% 0.879% 0.231% 0.093% 0.046% 0.046%
|
| ------------------------------------------------------------------
| Buckets 65 128 252 496 976 1920
| Mem/slot 520 B 1.0 KB 2.0 KB 3.9 KB 7.6 KB 15.0 KB
| Mem total 1.0 KB 2.0 KB 3.9 KB 7.8 KB 15.2 KB 30.0 KB各分布的典型应用场景:
- Uniform(均匀分布):合成 benchmark
- LN-API(log-normal σ=0.5):API / microservice latency
- Bimodal(双峰分布):cache hit / miss(90% fast path ~500μs, 10% slow path ~50ms)
- Expon(指数分布):network / IO wait
- LN-DB(log-normal σ=1.0):database query latency(tail 更宽)
- Sequent(sequential):worst case benchmark
- Pareto(Pareto 分布 α=1.5):heavy tail distribution(request size 等)
对于我们最关注的 latency 场景(LN-API 和 LN-DB),
WIDTH=3的 histogram 只用 2 KB memory ,误差就已经小于 0.2%。
总结
- 极致轻量 :2 KB memory(默认
WIDTH=3, u64 × 252 buckets),log-normal latency 场景下 P50 / P95 / P99 误差均 < 0.2% - 性能友好:O(1) 记录,O(buckets) 查询
- 梯形插值是关键:相同 bucket 结构下,比直接返回 bucket 边界精确一个数量级以上
- 灵活调参 :
WIDTH参数可调,从 520 B(极省 memory)到 15 KB(极高精度)按需选择
histogram 虽然是一个很小的基础组件,但它服务的是 Databend 更大的目标:让云数仓的性能更可观测、更可解释、更可优化 。欢迎访问 histogram 项目:base2histogram。
当系统可以用极低成本持续记录 P50、P95、P99 等分布信息,工程团队就能更快定位长尾延迟来自 storage、network、raft、execution pipeline 还是 query 本身。对用户来说,这最终会体现在更稳定的查询体验、更可预测的性能表现,以及更透明的成本优化空间上。