DDD 讲完了。TDD 讲完了。SDD 双端 + 留白区也讲完了。
你可能觉得------三件套我都懂了,业务边界、审计红线、技术基线、留白区,脑子里都有一张图了。
可你最近有没有这种感觉:理论都听懂了,真要动手搭一个工程,脑子里还是空的?
DDD 的限界上下文怎么落到代码目录?TDD 的 JaCoCo 90% 怎么配到 pom.xml 里?SDD 的 Spec 端长期挂载,挂在哪个文件、用什么格式?这才是你缺的------不是方法论本身,是方法论怎么长成可跑可用的工程骨架。
光说不练假把式。前面三篇把三件套当乐器讲完了,这一篇我们到 ArchAIHarness/framework 这个公开仓库里去看一份完整的工程骨架长什么样。它是一座已经搭好的厨房------所有布局都按"工种分区 + 试菜员 + 墙上挂手册 + 留白区"的标准来。新人(新服务)直接搬走,不用重新搭工种分区、重新培养试菜员、重新写 Spec 手册。
这一篇就是 framework 整合实战------DDD / TDD / SDD 三件套在 framework 仓里的真实落地。
下面我们一段一段拆。
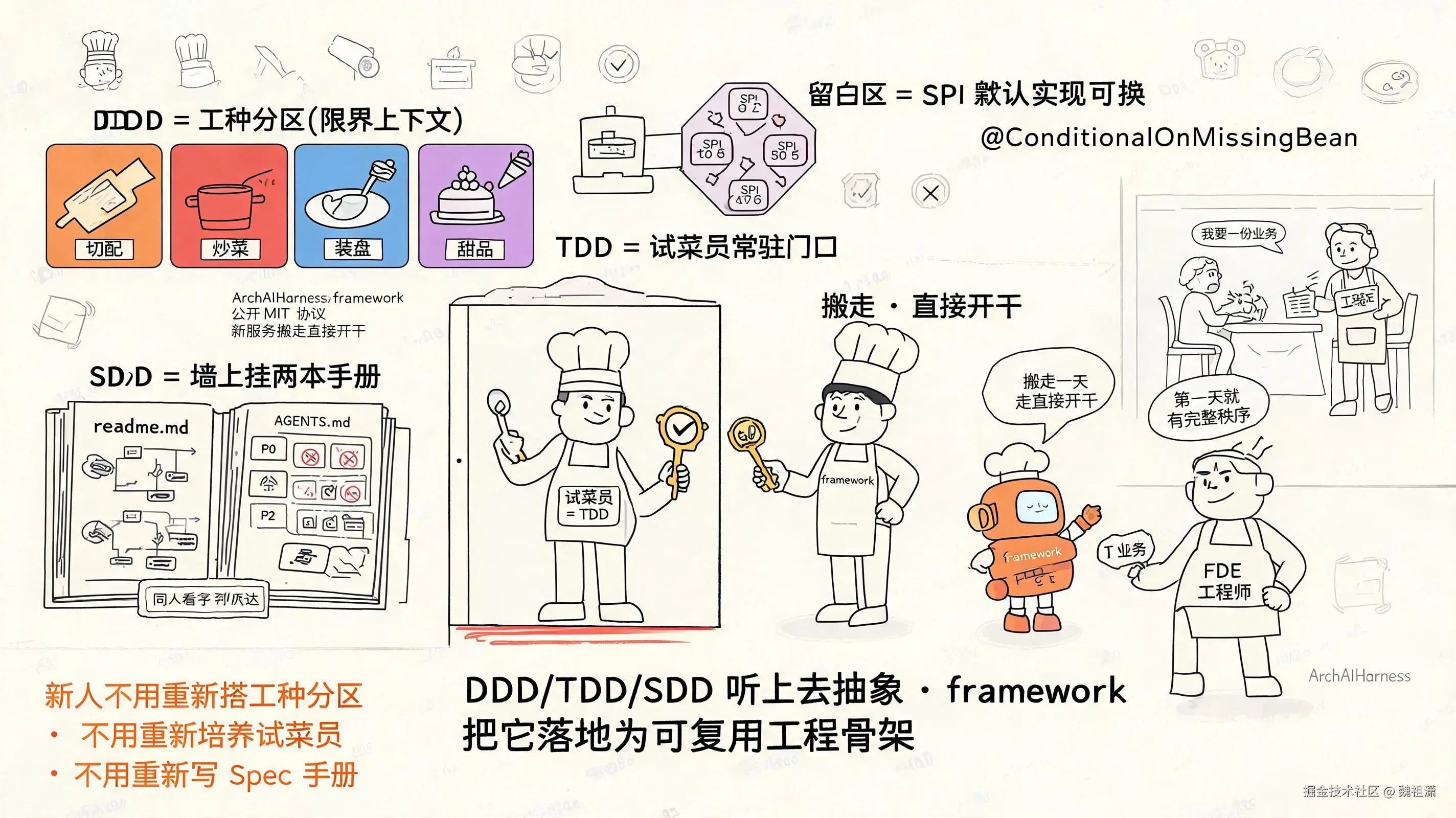
一、DDD/TDD/SDD 讲完了,真要落地还需要一座已经搭好的厨房
你可能觉得这标题有点夸张------前几篇把方法论讲得明明白白,落到代码不是手到擒来?
听起来很有道理。可真实现场不是这样。
我先把现场摆给你看。我过去一年在多个 AI 协作项目里看到的剧本,几乎都是这么演的。
第一个项目 ,你让 AI 给你搭一个新服务。AI 学得飞快------你说一句"加个用户聚合根",它给你整出 controller、service、domain、repository、dto、tests,整整齐齐一坨。你打开 PR 一看------domain 层竟然 import 了 org.springframework.stereotype.Service。你心里咯噔一下,提醒它:"domain 层不能 import Spring 框架。"它点点头:"好的,下次注意。"
第二个项目 ,你又拉了 AI,让它帮你写一个新的订单限流器。它又一次凭"印象"写------RestTemplate 调下游(项目里早就不用 RestTemplate 了,该用 WebClient)、@Transactional 加在了 domain 层的纯 Java 方法上(项目早就禁止 domain 层引 Spring)、日志直接 System.out.println(项目早就禁绝这种写法)。你又、又、又提醒一遍。
第三个项目 ,你新开了一个仓库,想让 AI 从零开始搭。它还是把"语料库平均值"那一套搬过来------JPA 注解写满 domain、异常每个 service 各自造一个子类、Header 用 X-User-Id 而不是项目定的 x-user-id。
第六个月 ,你打开 PR 列表,发现------同一个约束(domain 零 Spring),你跟 AI 讲了不下二十遍。每一遍它都点头、每一遍它下次又忘。约束没有沉淀下来,约束成了你每次会话必带的"开场白"。
为什么?
因为 DDD / TDD / SDD 三件套讲的是方法论 ------它告诉你"业务边界要画"、"测试要 90%"、"规范要长期挂载"。但方法论是抽象的,真要落地,你需要一座已经搭好的厨房------
- DDD 的"工种分区"落到代码目录上,就是六模块分层铁律(bootstrap / interfaces / application / domain / infrastructure / common);
- TDD 的"试菜员常驻门口"落到 CI/CD 里,就是JaCoCo 90% + P0 红线阻塞;
- SDD 的"墙上挂手册"落到代码仓里,就是readme.md + AGENTS.md 双文档体系;
- 留白区的"留出来的空间"落到扩展点上,就是6 个 SPI 接口 +
@ConditionalOnMissingBean默认实现可换。
这四件事凑在一起,就是 framework 仓库做的事------一座已经搭好的厨房,新服务 clone 下来第一天就有完整秩序,FDE 一线工程师不用从零搭。
不止 framework 仓。我之前做过一个国内多租户 SaaS 复杂业务项目 ,六模块分层(终端层 / 接入层 / 应用层 / 服务层 / 领域层 / 基础设施层)、多租户 PBAC 引擎、x-tenant-id Header 透传、三层身份体系(用户 / 租户 / 运营)、5 个核心领域(用户 / 租户 / 订单 / 商品 / 账单)、10 个扩展点(分布式事务 / 数据分片 / 插件机制 / 事件总线 / 存储抽象 / 缓存策略 / 协议适配)------这套完整的 DDD 落地范式,跟 framework 仓库的设计哲学高度同构。
framework 是公开的工程样板,国内那个项目是私有生产环境,但底层逻辑是同一套------DDD 业务边界 + TDD 审计红线 + SDD 规范挂载 + 留白区让 AI 飞。
所以这一篇我有两个目的:
- 拆 framework 仓库 ------以
ArchAIHarness/framework公开仓库为可验证样本,把六模块分层铁律、JaCoCo 90%、双文档体系、SPI 软秩序这一整套工程骨架讲透。 - 印证方法论可复用------framework 不只是"作者自己的工程样例",同一套方法论在国内复杂业务系统里也跑得通,印证"AI 时代的工程师不需要重新发明轮子,直接搬 framework 仓、按需改"。
DDD/TDD/SDD 听上去都是抽象方法论,真要落地需要一座已经搭好的厨房------framework 就是这座厨房。
这一句你得记牢。它是这一篇的底色。
为什么这件事过去没人提
你可能想问:DDD 是 Eric Evans 2003 年提出的,TDD 是 Kent Beck 2002 年的,SDD 是更老的"先写规范再写代码",加起来二十多年了。为什么今天才被 AI 时代捧成"三件套"?
因为过去不需要。
2003 年到 2023 年那段时间,这三件套是软件工程的"加分项"------你做银行、做交易所、做核心交易,DDD/TDD/SDD 能帮你把工程纪律磨平;你做个小博客、小 CRM、小工具,这套用不用差别不大,因为代码量小、人工复审能看完、规范口口相传也能到位。
AI 时代情况反过来了。
AI 进来之后,"人"和"人"的代码复审问题变成了"流水线"和"AI"的代码复审问题。你脑子里以为你跟 AI 对齐了,其实你只对齐了一次------你跟它说了"domain 零 Spring",它点点头;下次再写一个模块,它又回到"语料库平均值"那个工程师。每次新会话都得重新对齐。每次新分支都得重新对齐。
磨不平的。
怎么办?把方法论沉淀为可复用的工程骨架,让 AI 直接搬走用,而不是每次重新发明 。framework 仓库做的就是这件事------你不需要给 AI 重新讲一遍"D 的限界上下文应该怎么落到代码",framework 已经把这套骨架焊在 pom.xml 里了,clone 下来直接用。
这件事过去没人提,是因为过去没有 AI 需要"搬一座厨房"。今天有 AI 进场了,工程骨架才变成必需品。
那 framework 这座厨房具体长什么样?DDD 怎么落到代码目录?下一节我们正式讲 framework 怎么落 DDD。
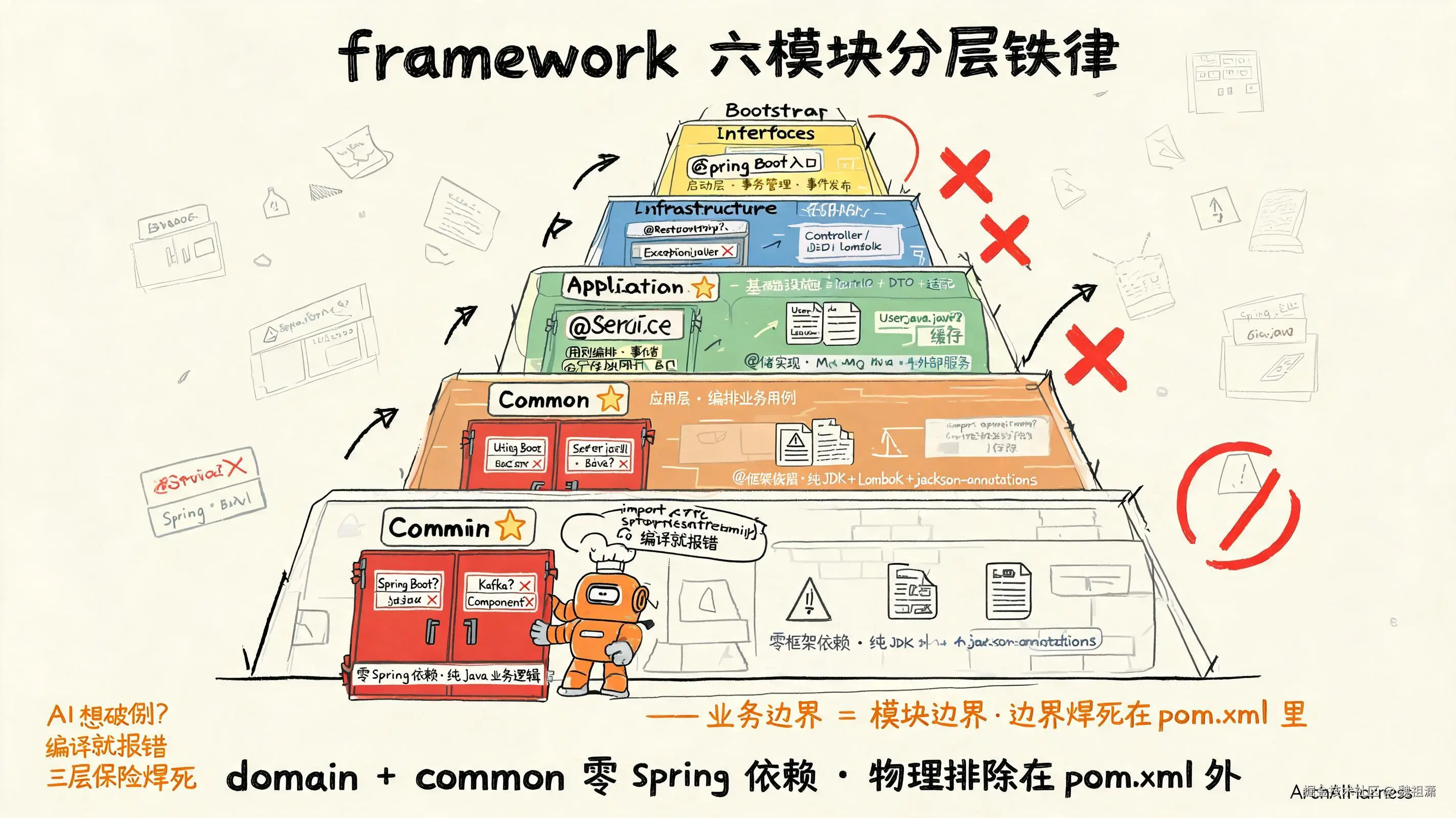
二、framework 怎么落 DDD------六模块分层铁律 + 零 Spring 依赖
我们把 framework 怎么落 DDD 摆到桌面上。
DDD 的精髓是业务边界 = 模块边界 。framework 仓库把这条精髓直接焊成了代码目录------任何新服务 clone 下来,目录结构就是 DDD 限界上下文的物理化身。
下面我们一段一段拆。
六模块分层铁律------业务边界 = 模块边界
framework 仓的代码分六个 Maven module,严格按层次依赖:
- bootstrap------启动层(最外层,Spring Boot 入口)
- interfaces------接口层(Controller / DTO / 适配)
- application------应用层(用例编排 / 事务管理 / 事件发布)
- domain------领域层(⭐ 零 Spring 依赖,所有业务规则在这里)
- infrastructure------基础设施层(仓储实现 / 外部服务 / MQ / 缓存)
- common------工具层(⭐ 零框架依赖,被其它五层引用)
依赖方向是严格单向的------
bootstrap → interfaces → application → domain → common
infrastructure → domain → common下层不能反向依赖上层。domain 不能 import bootstrap、interfaces、application、infrastructure 的任何类;common 不能 import 任何业务框架(Spring / Spring Boot / Kafka / Redis / Lombok 之外的)。
为什么这么严?
因为 domain 层是所有业务规则的所在地 ------User.create() / User.changeUsername() / User.deactivate() 这些聚合根方法决定了业务怎么走。一旦 domain 层引入 Spring 注解,它就从"纯 Java 业务逻辑"变成了"必须在 Spring 容器里才能跑的代码"------AI 写出来的领域代码强耦合到 Spring 框架 ,失去可移植性、可测试性、可读性。一次破例,后续谁都可能"觉得加个 Spring 注解方便"再加一个,等发现时 domain 层已经千疮百孔。
所以 framework 把这条规矩焊死在 pom.xml 里------domain 模块的 <dependencies> 只有 common + Lombok + jackson-annotations,没有 spring-context 。common 模块的 <dependencies> 只有 JDK 标准库 + Lombok + jackson-annotations,没有 spring-context。
AI 想 import Spring?编译就报错。
这就是 DDD 的"边界焊死"在工程上的最硬呈现------不是靠文档写"domain 不要 import Spring",是靠 pom.xml 把 Spring 物理排除在依赖之外。AI 想破例?门都没有。
业务边界 = 模块边界
domain 模块里,DDD 的限界上下文、聚合根、值对象、领域事件全部落地------
- 聚合根基类 :
AggregateRoot<T>自带private final List<DomainEvent>+registerEvent()+clearDomainEvents()。业务方法User.changeUsername(new Username("lisi"))直接registerEvent(new UserRenamedEvent(userId, oldName, newName)),事务提交后由@TransactionalEventListener触发真正发布。 - 领域事件基类 :
DomainEvent构造函数自动注入eventId = UUID.randomUUID()、occurredAt = now、eventType = getClass().getSimpleName()。业务事件子类(UserRenamedEvent / UserDeactivatedEvent / TenantUserAddedEvent)无需手写 eventId,自动获得。 - 仓储接口 vs 实现跨模块分离 :
UserRepository接口定义在domain模块,UserRepositoryImpl实现在infrastructure模块。这条规矩保证 DDD 的"领域层不知道持久化细节"------AI 写仓储时必须实现接口、不能绕开。 - 值对象强制 ID 类型 :
UserId/TenantId/OrderId都是record值对象,提供of(String)与generate()工厂方法。禁止用String或Long------编译器这一关就拦住 AI 写错。 User双工厂模式 :create()走 Builder,生成 ID + 注册事件;reconstruct()私有构造函数,不生成 ID、不注册事件、不校验 ------专供infrastructure从数据库重建用。通过构造权限分离,杜绝"重建出来再发事件"的 bug。
这套落地范式不只在 framework 仓。
我之前做过那个国内多租户 SaaS 复杂业务项目 ,同样按 DDD 落地------六模块分层(终端层 / 接入层 / 应用层 / 服务层 / 领域层 / 基础设施层)、5 个核心领域(用户 / 租户 / 订单 / 商品 / 账单)、多租户 PBAC 策略引擎、x-tenant-id Header 网关透传 + ThreadLocal 上下文、三层身份体系(用户 / 租户 / 运营)。底层架构骨架与 framework 高度同构------DDD 限界上下文切得清、业务边界焊得死、AI 在边界内写代码守得住。
framework 是公开的工程样板,国内那个项目是私有生产环境,但方法论是同一套。
AI 写代码时怎么守这条边界
AI 接手一个新模块,framework 怎么保证它不破例?
三层保险:
pom.xml物理排除 ------domain模块的 Maven 依赖里根本没有 spring-context ,AI 想 import Spring?mvn compile直接报错。AGENTS.md文档约束 ------framework 的domain/AGENTS.md明确写"domain 层不依赖 Spring 框架、P0 红线、违规立即打回"。- CI/CD 流水线检查 ------framework 仓配了一个 P0 阻断脚本,自动扫描
domain模块的.java文件,如果发现import org.springframework.*,直接非零退出码,PR 打回。
三层保险加起来,AI 几乎不可能破例 。它想写"@Service 加在 domain 的 User 类上"------pom.xml 不让、文档不让、流水线不让。三道闸全焊死。
framework 的六模块分层铁律 + 零 Spring 依赖,是 AI 时代工程师给 AI 焊死的最硬的边界。
这一句你记下来。它是 framework 落 DDD 的核心命题,也是 AI 时代工程纪律的物理边界。
三、framework 怎么落 TDD------JaCoCo 90% + P0 红线 + Mock 边界
我们把 framework 怎么落 TDD 摆到桌面上。
DDD 把业务边界焊死了------AI 不会越界。但还有一类问题没解决:AI 写出来的代码,逻辑上对不对?
比如它把"折扣叠加规则"写错了,业务边界没越,但结果是错的。TDD 的工作就是在 CI/CD 里自动拦下这种 bug。
下面我们一段一段拆。
JaCoCo 90%------试菜员的统计仪表
framework 仓对覆盖率的硬规矩是这样的------
| 层级 | LINE 覆盖率 | BRANCH 覆盖率 | 性质 |
|---|---|---|---|
| 全集底门槛 | ≥ 70% | ≥ 30% | 准入底线 |
| common 层 | ≥ 90% | ≥ 90% | P0 准入 |
| domain 层 | ≥ 90% | ≥ 90% | P0 准入 |
整套项目整体上 LINE 必须 70% 以上、BRANCH 必须 30% 以上------这是底线,不达标 PR 不能合。但最关键的是 common 层和 domain 层 ------这两层的所有代码必须 90% 以上的行、90% 以上的分支都被测试覆盖到,不达标就是 P0 红线,PR 直接被流水线打回。
为什么 common 和 domain 要这么严?
common层是零框架依赖的工具层(domain、application、infrastructure三层都引用它)------一旦common层出 bug,所有引用它的代码全跟着错。LINE 90% / BRANCH 90% 双门槛,是为了让"出错的所有可能性都被测试走一遍"。domain层是领域代码的核心层(所有业务规则都在这里)------一旦domain层出 bug,业务逻辑出错,而且这种错不冒在编译期、在运行期、在特定的业务情境下才冒。LINE 90% / BRANCH 90% 双门槛,是为了让"所有业务分支都被测试走过"。
其它层没卡这么严------infrastructure 70% / interfaces 60% / application 80% / bootstrap 50%(具体数字以 framework 各层 AGENTS.md 为准)。这些层是"接外部世界"的层,异常路径太多、太杂,卡 90% 反而不现实。
framework 把这套规矩焊死在 pom.xml 的 JaCoCo 配置里------PR 一提,流水线自动跑 JaCoCo,任何一项不达标(全集 LINE < 70% / BRANCH < 30%,或 common 层任意一个 < 90% / domain 层任意一个 < 90%),流水线返回非零退出码,代码合并不进去。
P0/P1/P2 分级阻塞------试菜员的三个红绿灯
光有覆盖率还不够,framework 还配了 P0/P1/P2 三档分级阻塞------
P0 红线------菜里有毒,不能上桌,PR 必须立即修复、禁止合并。framework 仓里几个典型的 P0:
domain层引入了 Spring 框架(违反"零 Spring"分层铁律)auth-center在 SSO Cookie 写入时用了 Servlet API(Tomcat 9.0.58+ 的Rfc6265CookieProcessor会拒绝.example.com前导点,这条不修代码上生产直接 500)tenant-center在租户更新时用了x-accessible-tenantsHeader 判断权限(应该实时查t_user_tenant表,用 Header 会绕过多租户隔离)- Mock 用了实体或值对象(测试自己测自己,业务分支全漏)
P1 红线------菜卖相不好,下次必须改,PR 必须修复、禁止合并。比如:
- 单元测试里有没清理的 ThreadLocal(测试间状态污染)
- Feign 调用没配降级(下游故障时会雪崩)
- 领域事件子类没加
@NoArgsConstructor但字段加了final(Jackson 反序列化失败,影响事件链路) - Kafka 消费没加幂等(重复消费会产生副作用)
P2 红线------菜建议加葱花,提醒一下,可合并。比如:
- unused import(不影响功能)
- 注释不全(不影响运行)
- 类名命名稍欠规范(不影响功能,但读起来别扭)
这套三档分级,framework 用一个轻量的 verify 阶段实现------跑两个工具:JaCoCo 统计覆盖率(检查 P0 准入 90% 的硬规矩)、自定义 P0/P1/P2 阻断脚本(检查代码里有没有违反硬规矩)。任何一个不达标,流水线返回非零退出码,PR 卡住,代码无法合并。
Given-When-Then + Mock 边界
光有覆盖率门槛和 P0 红线还不够,framework 还在测试方法层面加了规范------
Given-When-Then 强制 :测试方法命名严格遵循 shouldXxxWhenYyy 格式(比如 shouldEmitRenamedEventWhenUsernameChanged)。AI 写测试时一眼就知道"这个测试在测什么行为、在什么条件下",不会出现 testUserCreate 这种含糊不清的命名。
Mock 边界规范 :common 与 domain 各层的单元测试,禁止 mock 实体、值对象、命令、查询------这些是测试对象本身,你 mock 掉它们等于"自己测自己";只允许 mock 仓储、领域服务中的外部接口部分、事件发布器、外部服务客户端。
为什么禁止 mock 实体?
因为 mock 实体 = 测试自己测自己。AI 写测试时,经常这么干------
java
// 反面例子:Mock 实体自己测自己
@MockBean private User mockUser;
when(mockUser.getUsername()).thenReturn(new Username("zhangsan"));
userService.doSomething(mockUser);
assertEquals(new Username("zhangsan"), mockUser.getUsername());这个测试能跑、能绿,但完全没有意义------它证明的是"mock 等于 mock",和真实业务逻辑一点关系都没有。试菜员吃了一口假食材,告诉你"味道对",你信了就把菜端上桌了。
framework 仓的规矩是------真造真测:
java
// 正确例子:真造真测
User user = User.create(
new CreateUserCommand(
new UserId(generateUUID()),
new Username("zhangsan"),
new Password("TestPwd@2026"),
new Email("zhangsan@example.com")
),
userDomainService // 真实的领域服务,不是 mock
);
user.changeUsername(new Username("lisi"));
assertEquals(new Username("lisi"), user.getUsername());这个测试跑出来的结果,才是业务逻辑真实跑过的结果。试菜员吃的是真食材,告诉你"味道对",你才信。
这套门槛挡了多少 bug
我看到的工程妥协现实------你看到这些数字可能会想:"90% 是不是太严了?"
我给你一组行业数据,你判断。
aiXcoder 在一家银行做 TDD 集成 CI/CD 改造时,把覆盖率门槛从 60% 提到 90%、加了 P0 阻断脚本、嵌进每条 PR 的流水线。结果是线上缺陷下降 34%、人工复审工作量下降 50%。
SpecStory Studio 在一家海外 Fintech 落地这套打法时,日均提交代码量是传统开发的 10 倍,但首次交付通过率达到 85.7%------意味着 10 倍的产出,85.7% 一次就过,剩下的 1.5 次打回改改就过。
这两个数字背后是什么?是当 AI 写代码的速度 10 倍于人工时,人工复审的覆盖率得跟上 ------AI 一小时能产出过去一天的代码量,你不能还靠人一行一行读 diff;你得让流水线替你挡 80% 的活,人只看机器挡不住的最后 20%。试菜员比人更稳定、不会累、不会跳着看、不会走神。
这也是为什么 framework 把 90% 双门槛 + P0/P1/P2 三档分级 + Mock 边界焊死在 pom.xml 和 AGENTS.md 里------这套规矩不是凭空定的,是踩了一年的 bug 才焊死的。

四、framework 怎么落 SDD------双文档体系 + Spec 端长期挂载
我们把 framework 怎么落 SDD 摆到桌面上。
DDD 把业务边界焊死了,TDD 把审计红线焊死了。但还有一类问题没解决:AI 开工前,怎么知道团队的整套规范?
比如它不知道你们用 Java 17 还是 Java 21、不知道你们 Header 全小写、不知道你们 domain 层零 Spring、不知道你们 P0 红线包括 SSO Cookie 必须 JS 写。它每接一个新会话、每开一个新分支,都把这些事重听一遍------你觉得它学得越来越快,是的,快到把你每次口头告知的技术约束全都"重新发明"了一遍。
SDD 的工作就是让团队规范长期挂在 AI 工作台里,让工程师只聊业务、让 AI 自动按规范落地。
下面我们一段一段拆。
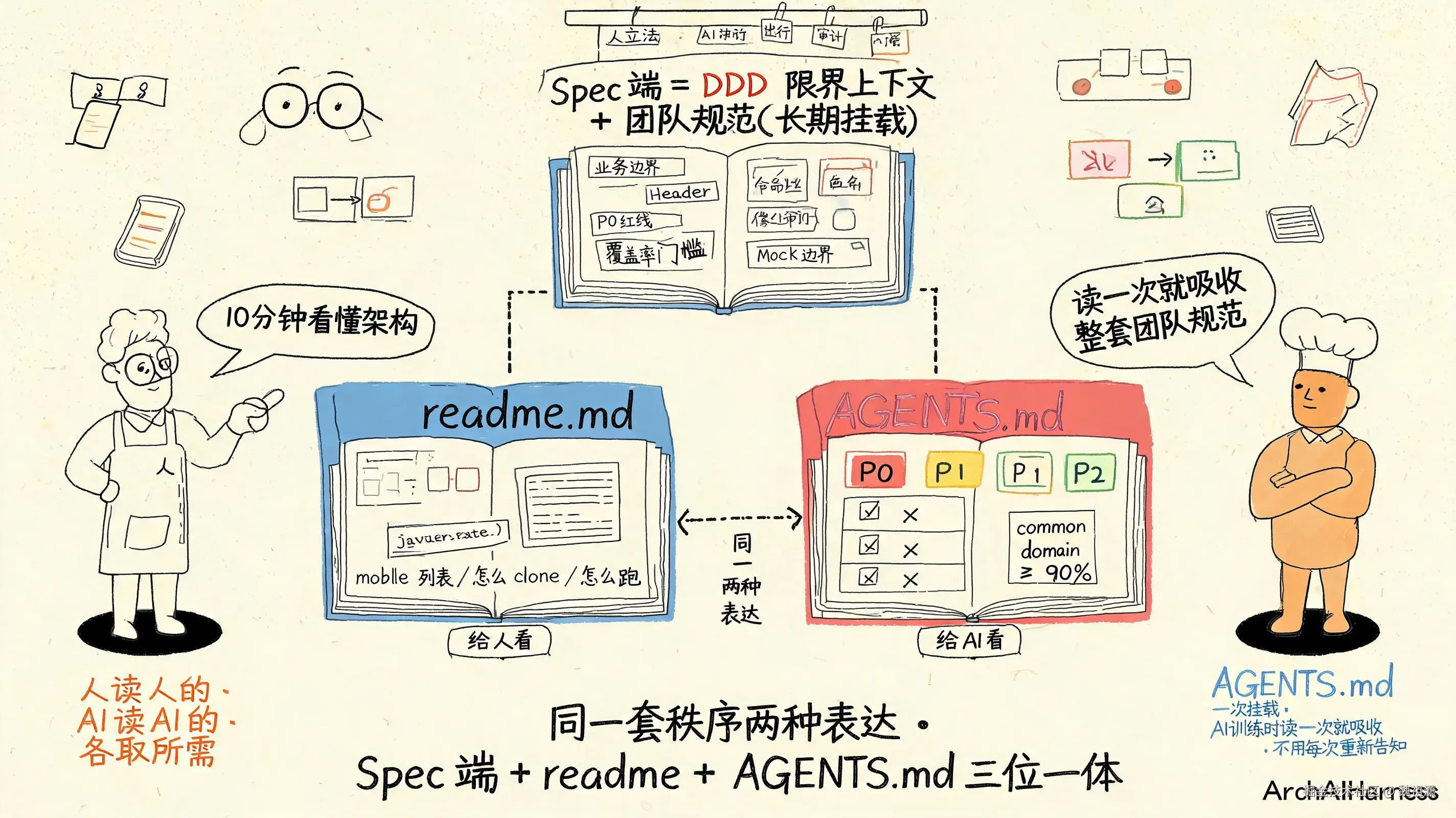
双文档体系------同一套秩序两种表达
framework 仓的 SDD 落地,核心是双文档体系------
readme.md------给人看的。讲架构、讲分层、讲模块、讲示例代码。人类开发者看这个文件,10 分钟就能搞懂 framework 是怎么组织的、为什么这样组织。AGENTS.md------给 AI 看的。讲 P0/P1/P2 清单、讲禁止事项、讲 Mock 边界、讲覆盖率门槛、讲 Java 编码规范。AI 训练时读这个文件,把整套团队规范吸收成自己的"团队习惯",后续写代码自动按规范来。
同一套秩序两种表达。readme.md 讲"为什么",AGENTS.md 讲"不能做什么"。
为什么必须分两份?
因为读者不同。人类开发者看 readme.md------他们要理解架构、要上手开发、要查 API 文档;AI 工程师看 AGENTS.md------它们要遵守红线、要知道哪些能写哪些不能写、要查 P0 红线清单。把两份职责塞进一份文件,人类觉得啰嗦、AI 抓不住重点。分两份,人读人的、AI 读 AI 的,各取所需。
framework 仓的 domain/AGENTS.md / application/AGENTS.md / infrastructure/AGENTS.md / common/AGENTS.md / bootstrap/AGENTS.md / interfaces/AGENTS.md 每一层都有一份 AGENTS.md,把该层的硬规范、P0 红线、禁止事项写到极致。AI 写该层代码前,先读该层 AGENTS.md------读完就吸收成自己的"团队习惯",后续按规矩写。
readme.md + AGENTS.md + DOCS.md 三位一体
framework 仓除了双文档,还配了第三份------DOCS.md。
三份文件分工明确:
readme.md------总入口,讲"这个仓库是什么、怎么 clone、怎么跑、目录长什么样"。AGENTS.md------AI 工程师必读,讲"这个仓库的硬规范、哪些能做哪些不能做"。DOCS.md------架构详细文档,讲"每个 module 的设计意图、关键决策、依赖关系、最佳实践"。
三份加起来,就是 framework 的 Spec 端长期挂载 ------AI 训练时读一次就吸收整套团队范式,后续写代码自动按规范来。不用每次新会话都重新告知一遍"domain 零 Spring、Header 全小写"。
这套做法不只在 framework。
我之前做那个国内多租户 SaaS 复杂业务项目 ,同样按 SDD 落地------总体架构设计文档 + 5 个领域设计文档 + ADR 关键决策记录 (架构决策的 Spec 端载体,记录"为什么这么选、有什么备选、被否掉的理由")。这三类文档长期挂在 Wiki / Confluence 上,架构师更新文档、AI 跟文档,人机分工彻底切分。
framework 是公开仓库用 AGENTS.md 的形式挂,我们那个项目是用 Wiki / Confluence 挂------形态不同,本质同构:团队规范长期挂载 + AI 自动按规范落地 + 工程师只聊业务。
Spec 端"长期挂载"省了多少成本
Spec 端长期挂载是不是真的能省成本?
SpecStory Studio 在一家海外 SaaS 团队落地 SDD 双端后------
- 澄清轮次仅 1.01 次(即 AI 平均只需要被澄清 1 次就能交付,远低于传统开发的 5-10 次)
- 日均提交代码量是传统开发的 10 倍
- 首次交付通过率达 85.7%
海外某 Fintech 公司 14 人团队用 SDD 双端落地后------
- 9 个月业务 roadmap 压缩到 11 周交付
- 上线故障从 17 个降至 3 个(下降 82%)
两组数据摆在一起看------一个靠"澄清轮次 + 日均提交 + 首次交付"衡量,一个靠"交付周期 + 故障数"衡量。两组数据都指向同一件事------规范长期挂载 = 工程师重复告知成本暴跌 + 代码质量跃升。
Spec 端不是"贴墙上的告示",是 AI 工作台的"开机启动项"。规范在那里,AI 就按规范写;规范不在那里,AI 就按印象写。
Story 端------framework 怎么让工程师只聊业务
framework 仓的 Story 端落地,核心是业务 Story 端接口------
工程师只跟 AI 聊三件事:
- 业务目标------这个 Story 要解决什么问题、为谁解决、解决到什么程度。
- 用户流程------用户怎么走到这一步、前置条件是什么、后置效果是什么。
- 验收场景------怎么算"做对了"。
这三件事讲清楚,业务对话就完了 。不需要工程师讲"用什么语言"、"用什么框架"、"Header 怎么写"、"P0 红线有哪些"。这些事 Spec 端(AGENTS.md)已经沉淀好,AI 自动按 Spec 落地。
framework 仓的 UserAppService 是一段完美示范------
java
public class UserAppService {
public UserResponse createUser(CreateUserCommand command) {
// 业务编排由 framework 已沉淀的规范自动完成:
// 1. 校验(由 Spec 端"编码规范"约束)
// 2. 调用聚合根工厂(由 Spec 端"类结构设计习惯"约束)
// 3. 持久化(由 Spec 端"仓储模式"约束)
// 4. 发领域事件(由 Spec 端"领域事件规范"约束)
// 5. 返回响应(由 Spec 端"响应包装"约束)
}
}工程师看到 createUser(CreateUserCommand),只关心"输入是什么、输出是什么"------业务的事 。技术实现由 framework 已沉淀的规范自动匹配,工程师不需要重复告知。
这就是 framework 落 SDD 的核心价值------真实现了"聊天即交付"。工程师只聊业务,AI 自动按 Spec 端团队规范落地。
五、边界焊死 + 选择放开------三个限界上下文硬秩序 vs 6 个 SPI 软秩序
我们把"边界焊死 + 选择放开"摆到桌面上。
这是 framework 这套工程骨架的核心创新------两层叠加,才完整。
下面我们一段一段拆。
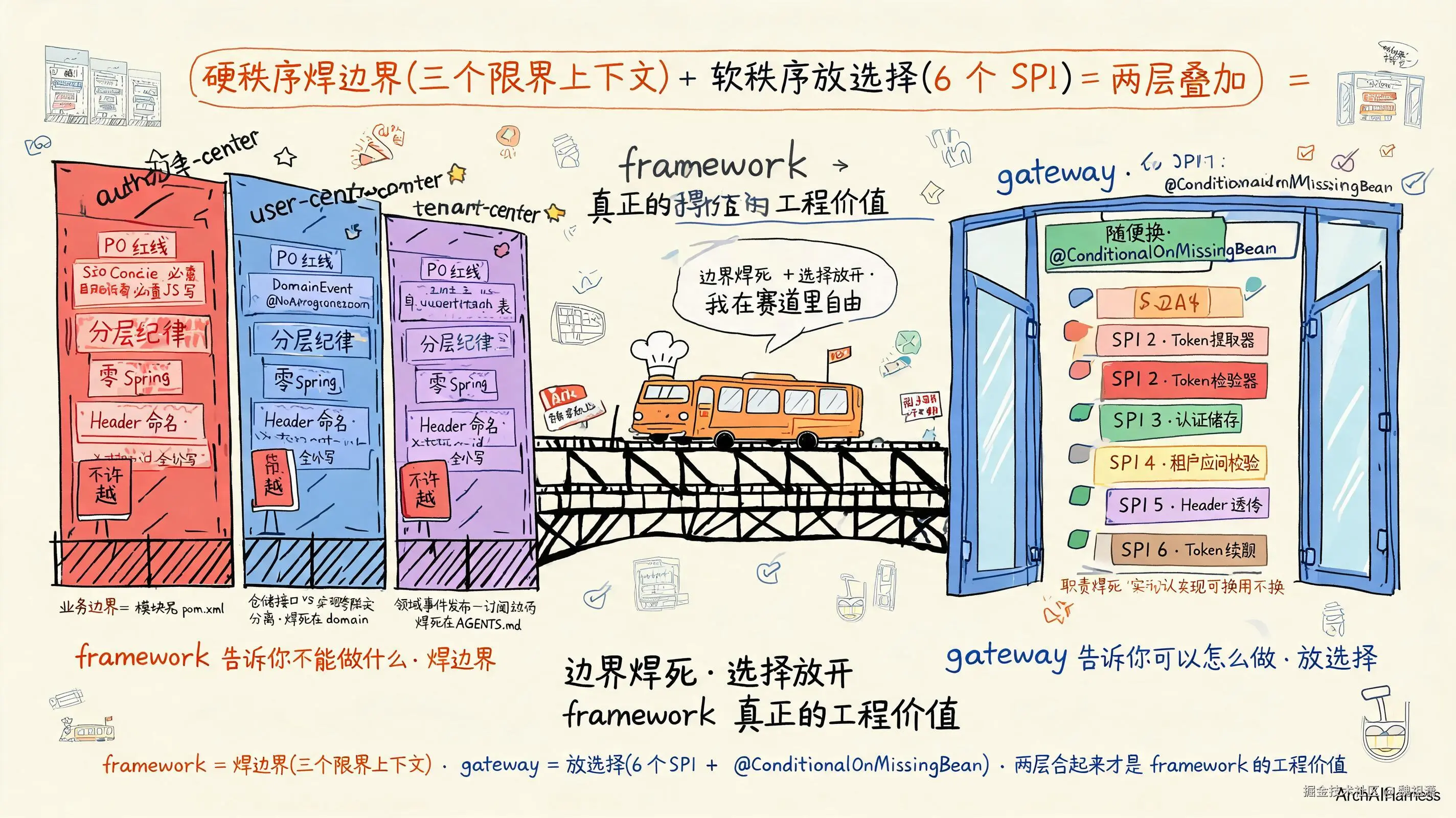
硬秩序焊边界------三个限界上下文
framework 仓配合三个限界上下文(auth-center / user-center / tenant-center)做演示------三个仓库演示硬秩序。
硬秩序就是焊死的边界------AI 不可越界的红线:
- DDD 边界 ------业务边界 = 模块边界。AI 在
auth-center里就只写认证的术语,在user-center里就只写用户的术语,在tenant-center里就只写租户的术语。跨上下文协作只能通过 Feign(客户-供应商)或 Kafka 事件(发布-订阅),不能直接跨表、不能直接调对方 service。 - Header 全小写 ------
x-user-id/x-tenant-id/x-tenant-ids/x-accessible-tenants四个 Header 是四仓横着穿的共享内核,谁都不能私自扩展。AI 想写X-User-Id?AGENTS.mdP0 红线,违规立即打回。 - P0 红线不能绕 ------
auth-center的 SSO Cookie 必须用 JS 写(不能用 Servlet API,Tomcat 9.0.58+ 的Rfc6265CookieProcessor拒绝.example.com前导点);tenant-center的租户更新/删除必须实时查t_user_tenant表,不能用x-accessible-tenantsHeader 判断权限;DomainEvent子类必须@NoArgsConstructor+ 字段禁止final(Jackson 反序列化要求)。三条 P0 焊死在AGENTS.md里,绕一次整个工程的纪律就崩了。 - 覆盖率 ≥ 90% 不能漏 ------
common和domain各层必须 90% 以上的行、90% 以上的分支都被测试覆盖到。不达标 PR 直接打回。
这四条每一单看都不复杂,但只要 AI 找到一次"绕过去没事"的口子,后续的硬秩序就会一条条失守------AI 学习能力太强了,你给它一个反例,下次它就学会绕过检测、绕过 review、绕过流水线。
所以硬秩序必须焊死------绕一次,整个工程的纪律就崩了。
软秩序放选择------6 个 SPI + @ConditionalOnMissingBean
framework 仓的 gateway 模块演示软秩序 ------6 个 SPI 接口 + @ConditionalOnMissingBean 零侵入扩展。
软秩序是留出来的空间------AI 在边界内自主决定"怎么实现":
gateway 的 6 个 SPI 接口职责焊死:
- Token 提取器------从请求里把 token 拎出来
- Token 校验器------验证 token 签名、过期、黑名单
- 认证缓存------校验过的 token 缓存起来(默认 Redis,可换本地 Caffeine)
- 租户访问校验------校验当前用户对当前租户的访问权限
- Header 透传 ------把用户上下文写到
x-user-id/x-tenant-id等 Header - Token 续期------token 即将过期时自动续签
6 个接口的职责 焊死------必须能提 token、必须能校验、必须能缓存、必须能验租户、必须能透传、必须能续期。但每个接口的具体实现 AI 自由决定------
- Token 校验器默认是 JWT 校验,你换成 Opaque Token 也行;
- 认证缓存默认是 Redis,你换成本地 Caffeine 也行;
- 租户访问校验默认是
t_user_tenant表查询,你换成 OPA 策略引擎也行; - Header 透传默认是
x-user-id这种命名,你换成X-User-Id也行(只要你内部所有下游都跟着改)。
具体怎么实现,AI 在边界内自主决定 ------@ConditionalOnMissingBean 注解让默认实现只在没有自定义 Bean 时才生效 ,你随时可以用一个 @Bean 把默认实现替换掉。
这就是软秩序的设计价值------职责焊死(必须能提 token、必须能校验),实现放开(用什么方式提、怎么校验 AI 自己决定)。
两层叠加才是 framework 真正的工程价值
我用一个对比把两层讲透------
| 维度 | 硬秩序(三个限界上下文) | 软秩序(gateway 6 个 SPI) |
|---|---|---|
| 焊什么 | 业务边界 / Header / P0 红线 / 覆盖率 | 接口职责(必须能做什么) |
| 放什么 | 不能放------绕一次崩一次 | 实现细节(怎么做 AI 自己决定) |
| 触发条件 | AGENTS.md P0 红线 / 流水线拦截 | @ConditionalOnMissingBean 默认实现可换 |
| 设计哲学 | "不能做什么" | "可以怎么做" |
两层合起来才是 framework 完整的工程秩序------
- 三个限界上下文告诉你不能做什么------业务边界焊死、Header 命名焊死、P0 红线焊死、覆盖率门槛焊死。
- 平台层 gateway 告诉你可以怎么做------6 个 SPI 接口职责焊死,但默认实现可换、可不换、AI 在边界内自主决定。
硬秩序焊边界(三个限界上下文)+ 软秩序放选择(6 个 SPI + @ConditionalOnMissingBean)------这两层加在一起,才是 framework 真正的工程价值。
这一句你记下来。它是 framework 的核心创新,也是 AI 时代工程秩序的物理边界。
国内生产项目印证------10 个扩展点 = 留白区
framework 的"硬秩序 + 软秩序"两层架构,在国内生产项目里也是同一种思路。
我之前做那个国内多租户 SaaS 复杂业务项目 ,架构里专门设计了10 个扩展点 ------分布式事务 / 数据分片 / 插件机制 / 事件总线 / 存储抽象 / 缓存策略 / 协议适配 等。每个扩展点的职责 焊死(分布式事务必须支持柔性事务、数据分片必须支持按租户分库),但具体实现 AI 自主决定------分布式事务用 Seata AT 模式还是 TCC 模式、事件总线用 Kafka 还是 RocketMQ、缓存用 Redis 还是 Caffeine,工程师不强制,AI 按场景选。
10 个扩展点 = 10 个留白区 = 10 处"软秩序"。
framework 仓的 6 个 SPI 是同一种思路,只是形态不同------framework 用接口 + @ConditionalOnMissingBean,国内那个项目用扩展点配置 + 工厂模式。形态不同,本质同构:硬秩序焊边界,软秩序放选择,留白区让 AI 飞。
六、framework 怎么落团队班规 + 留白区
我们把"团队班规 + 留白区"摆到桌面上。
framework 的 SDD 落地说到底是给团队立一套班规 ------AGENTS.md 是班规的实体化载体,Command/Query/Response 是班规的执行入口,留白区是班规里留给 AI 自由发挥的部分。
下面我们一段一段拆。
AGENTS.md = Spec 端的实体化
framework 仓的 AGENTS.md 不是一份普通文档,是Spec 端长期挂载的实体化载体。
每一层都有自己的 AGENTS.md:
framework/AGENTS.md------总纲,讲仓库组织、跨层规范、依赖方向framework/domain/AGENTS.md------讲domain层的 P0 红线(零 Spring、零框架、纯 Java)、聚合根规范、值对象规范、领域事件规范framework/application/AGENTS.md------讲application层的用例编排规范、事务规范、事件发布规范framework/infrastructure/AGENTS.md------讲仓储实现规范、外部服务接入规范、MQ 接入规范framework/common/AGENTS.md------讲工具类规范、异常规范、值对象工具规范framework/interfaces/AGENTS.md------讲 Controller 规范、DTO 规范、响应包装规范framework/bootstrap/AGENTS.md------讲启动配置规范、Spring Boot 装配规范
每一份 AGENTS.md 都有完整结构------仓库概述、目录组织、依赖约束、P0/P1/P2 清单、禁止事项、最佳实践、参考示例。AI 写该层代码前,先读该层 AGENTS.md------读完就吸收成自己的"团队习惯",后续按规矩写。
这套机制保证------AI 不会"凭印象写代码" 。它打开 domain 模块写 User.changeUsername(),第一件事是读 domain/AGENTS.md,知道:
- domain 层零 Spring(P0 红线)
- 聚合根必须用
AggregateRoot<T>基类 - 业务方法必须
registerEvent()注册领域事件 - 状态变更必须用值对象(禁止
String/Long) - 测试必须用 Given-When-Then
- Mock 边界:禁止 mock 实体 / 值对象 / 命令 / 查询
读完这些规矩,AI 写出来的代码自然就符合框架规范------不用工程师每次新会话都重新告知"domain 零 Spring、Header 全小写、P0 红线包括 SSO Cookie 必须 JS 写"。
这就是 framework 落 SDD 的核心机制------AGENTS.md 是班规的实体化,AI 读一次就吸收整套团队范式,后续按规矩写。
Command/Query/Response = Story 端的接口
framework 仓的 application 层用三套 DTO 严格切分------
- Command (写操作输入):
CreateUserCommand/ChangeUsernameCommand/DeactivateUserCommand------只描述"做什么",不涉及"怎么做"。 - Query (读操作输入):
GetUserQuery/ListUsersQuery------只描述"查什么",不涉及"怎么查"。 - Response (操作输出):
UserResponse/UserListResponse------只描述"返回什么",不涉及"怎么返回"。
工程师看到这三个 DTO,只关心业务输入输出------
- "输入是
CreateUserCommand,包含 userId / username / password / email" - "输出是
UserResponse,包含 userId / username / email / status"
至于"怎么校验"、"怎么调聚合根"、"怎么持久化"、"怎么发事件"、"怎么包响应"------这些技术实现由 framework 已沉淀的规范自动完成,工程师不需要重复告知。
这就是 framework 落 SDD 的 Story 端------Command/Query/Response 三套 DTO 是工程师唯一交互入口 。工程师只聊业务输入输出,AI 自动按 Spec 端(AGENTS.md)落地技术实现。
留白区------framework 在 SPI 设计里
留白区是 SDD 这套方法论的差异化亮点------前三道秩序(DDD / TDD / Spec 端)把规矩焊死了,规矩之间"留出来的空间"就是留白区。framework 的留白区在 SPI 设计里。
framework 的 6 个 SPI 接口职责焊死------必须能提 token、必须能校验、必须能缓存、必须能验租户、必须能透传、必须能续期。但默认实现可换、可不换------
java
// framework 默认实现:JWT + Redis 缓存 + t_user_tenant 查表
@Bean
@ConditionalOnMissingBean(TokenVerifier.class)
public TokenVerifier defaultTokenVerifier() {
return new JwtTokenVerifier(...);
}
// AI 想换成 Opaque Token?只需加一个 @Bean
@Bean
public TokenVerifier myCustomTokenVerifier() {
return new OpaqueTokenVerifier(...);
}@ConditionalOnMissingBean 注解让默认实现只在没有自定义 Bean 时才生效 ------AI 想换,加一个 @Bean 就行;不想换,默认实现照常工作。
这就是留白区------6 个接口职责焊死(必须能做什么),但默认实现可换(怎么做 AI 自己决定)。
不留空间------framework 写死 Token 校验逻辑,后续想换 OPA / OAuth2 / 自研 token 系统?改 framework 源码?不留空间就是逼用户改底层。 过度发挥------framework 不焊接口职责,AI 想怎么实现就怎么实现,6 个 SPI 各写各的,风格乱套、契约失效。 焊职责 + 放实现 ------framework 的 6 个 SPI + @ConditionalOnMissingBean 完美平衡:职责焊死保证契约稳定,实现放开保证灵活扩展。
framework 的留白区在 SPI 设计里------6 个接口职责焊死,但默认实现可换,AI 在边界内自主决定。
这一句你记下来。它是 framework 留白区设计的精髓,也是 AI 时代工程师给 AI 的"最后一层自由度"。
国内生产项目印证------ADR 关键决策记录
framework 的 AGENTS.md 作为团队班规载体,这套思路在国内生产项目里也是同一种形态。
我之前做那个国内多租户 SaaS 复杂业务项目 ,架构里专门维护一份ADR(架构决策记录)------记录架构层面"为什么这么选、有什么备选、被否掉的理由"。比如 ADR-001 多租户权限模型决策,记录"权限模型选 PBAC 而不是 RBAC、为什么不用 ACL、为什么放弃按角色硬编码------理由是 XXX、被否方案的理由是 YYY"。
ADR 是 Spec 端长期挂载 的另一种形态------AGENTS.md 写"班规是什么",ADR 写"班规为什么这么定"。两者合起来,就是完整的团队规范载体------既告诉 AI "要遵守什么",也告诉 AI "为什么这么定"(后续 AI 改规矩时知道背景)。
framework 用 AGENTS.md 体系挂载,我们用 ADR 体系挂载------形态不同,本质同构 :AGENTS.md 讲"硬规范",ADR 讲"硬规范背后的决策逻辑",两者加起来就是完整的团队班规。
七、写在最后------DDD/TDD/SDD 三件套在 framework 仓库里长成了工程骨架
回到开头那个反直觉的判断------DDD/TDD/SDD 三件套讲完了,真要落地还需要一座已经搭好的厨房。
你可能还在想:框架不是有的是吗?Spring Boot 不是一套框架?Spring Cloud 不是一套框架?阿里 COLA 不是一套框架?
这些框架都对。但它们是通用框架 ------给你一堆轮子让你自己拼。framework 仓不是通用框架,是已经拼好的厨房------所有布局都按"工种分区 + 试菜员 + 墙上挂手册 + 留白区"的标准来,新服务 clone 下来直接搬走用,不用从零搭工种分区、重新培养试菜员、重新写 Spec 手册。
四篇一组,29-32 全部讲完了。我们用一组厨房比喻串一串------
- DDD(29 篇)= 厨房工种分区。切配区、炒菜区、装盘区、甜品区、凉菜区------各管一段,各用各的台子/刀具/食材/用语。业务边界 = 模块边界,限界上下文切得清,AI 不越界。
- TDD(30 篇)= 试菜员常驻厨房门口。每道菜出锅前都试吃一口,合格放行,不合格退回重做。试菜员只关心"味道对不对、出锅形对不对",不关心"用什么锅、怎么炒"------这就是 TDD 的定位:只测"业务规则 + 流程结果",不测"具体怎么实现"。
- SDD(31 篇)= 厨房两本手册。Spec 端 = 墙上挂的团队操作手册 + 设备清单,AI 训练时读一次就吸收成"团队习惯";Story 端 = 服务员手里的顾客点菜单,工程师只聊业务输入输出,AI 自动按 Spec 端团队规范落地。留白区 = 菜单没写但厨师可自由发挥的部分,DDD 锁赛道 + TDD 卡审计 + Spec 固技术,三层之外完全交给 AI 自由发挥。
- framework 整合实战(32 篇)= 一座已经搭好的厨房。六模块分层铁律 / 零 Spring 依赖 / JaCoCo 90% / P0 红线 / 双文档体系 / SPI 软秩序------这套工程骨架把 DDD / TDD / SDD 三件套从方法论落到代码,新服务 clone 下来第一天就有完整秩序。
四篇合起来的金句收束------
DDD 锁业务赛道、TDD 卡审计红线、Spec 固技术基线、留白区让 AI 飞------这四层加在一起,就是 framework 仓库里那份跑得起来的厨房分工图。抽象的方法论一旦落地为可复用工程骨架,AI 时代的工程师才算真正从'重复告知规范'里解放出来,把精力放在业务本身。
这一句你记下来。它是这一篇的收束,也是 29-32 四篇一组的总结。
framework 仓的可验证落地数据
framework 这套工程骨架不是"画饼",是可验证的落地数据------
- 新服务搭建时间从天级压缩到小时级 ------不用从零搭六模块分层、重新配 JaCoCo、重新写
AGENTS.md、重新配 SPI,新服务 clone 下来第一天就有完整秩序。 - 整体交付周期缩短 30%~40%------AI 在秩序内自主开发,流水线自动审计,FDE 一线工程师只聊业务输入输出,交付效率跃升。
- 架构腐化率近 0 ------
AGENTS.md强制约束业务边界 / Header 命名 / P0 红线,AI 越界立即打回,架构不会随时间腐化。 - 领域层测试覆盖 ≥ 90%------JaCoCo 强制 + P0 准入,domain 层所有业务规则都被测试走过。
这套数据印证了 framework 的工程价值------抽象方法论一旦落地为可复用工程骨架,真的能让 AI 时代的工程师从重复告知规范里解放出来,把精力放在业务本身。
你接下来能做什么
读到这里,你可能想知道------我自己能搭一套 framework 吗?
答案分两层------
如果你想直接用 :去 GitHub 翻 ArchAIHarness/framework 公开仓库(开源 MIT 协议),clone 下来 clone 出新模块、改改包名、配配数据库连接,第一天就能跑起来。FDE 一线工程师拿到 framework,直接进入业务对话,不用重新搭工种分区、重新培养试菜员、重新写 Spec 手册。
如果你想搭自己的 framework :framework 不是唯一答案。同一套方法论在国内生产项目里也跑得通(就是我之前做那个项目),你可以按 DDD 业务边界、TDD 审计红线、Spec 端长期挂载、留白区软秩序四层架构,搭你自己团队的工程骨架。framework 仓的设计哲学是通用的,形态可以不一样,本质必须守住。
四篇一组,讲完了。29 讲 DDD、30 讲 TDD、31 讲 SDD、32 讲 framework 整合实战。后面我们接着按场景、按想法,一篇一个真实可落地的插件或 agent 开发案例,持续输出,不封口。
关于 ArchAIHarness
这篇文章是「看懂 AI 与智能体」专栏的一部分,由 ArchAIHarness 持续输出。
ArchAIHarness 是一套面向 AI 时代软件工程的人机协同架构哲学与公开工程资产,主张:
架构师定义秩序,AI 在秩序中生长。人立法,AI 执行,体系审计。
如果你也希望 AI 在明确的架构边界内协作,而不是在混沌中碰运气,欢迎到 GitHub 上看看我们在做什么:
- 组织主页 :github.com/ArchAIHarne... --- 了解完整理念与资产全景
- 本专栏 :
zhuanlan-ai-and-agents--- 所有文章的源码与发布记录 - 实践指南 :
docs--- 架构哲学、工程方法和落地指南 - 开源工具 :
agent-workflows--- 可复用的 AI 协作 Agents、Skills 与 Tools - 工程样例 :
framework--- DDD + AI 协作的工程底座,展示如何在开发中融合 AI
Engineered by Architects · Empowered by AI · Audited by Discipline