OpenMP学习2------超算习堂
一、for指令的使用方法细嚼
1.1、parallel for指令的用法
在OpenMP并行程序设计中,for循环是一种独立的并行指令。它非常重要!它的指令格式是:
cpp
#include <omp.h>
#pragma omp parallel for
for(i = begin;i < end;++i)
{
// Content
}十分需要注意的是:
parallel for指令的后面必须要紧跟for语句块!!!!
并且for循环并行必须要处在parallel并行区块内!!!!否则会当作串行执行!
1.2、parallel for指令的执行机制
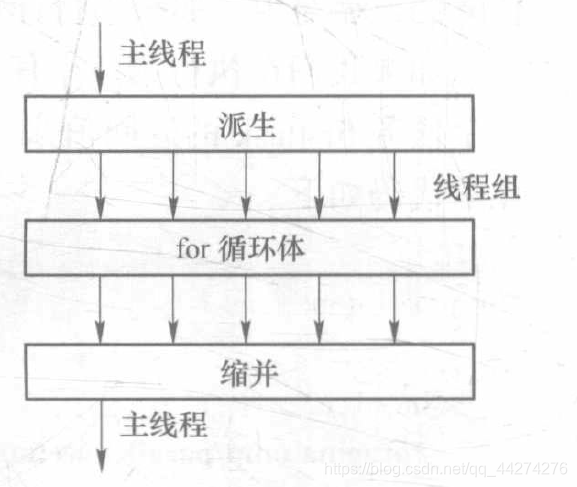
此前一篇博客已经说明了,OpenMP的并行计算模式是插入并行语句的方法,如上图。当我们的串行程序执行到并行语句块的时候,会从主线程中派生出线程组,然后线程组对计算任务进行均分,然后并行计算。并行计算结束后重新回到串行程序。
1.3、parallel for并行程序设计案例
案例1:计算两个向量的点乘
cpp
#include <omp.h>
#include <cstdio>
#include <cstdlib>
#include <cmath>
#include <ctime>
const int maxn = 5e7;
const int mod = 10000;
int vec1[maxn], vec2[maxn], vec[maxn], i;
int main()
{
srand((unsigned int)time(NULL));
for (i = 0; i < maxn; ++i)
{
vec1[i] = rand() % mod;
vec2[i] = rand() % mod;
}
printf("--------------before parallel compute---------------\n");
clock_t s, t;
s = clock();
for (i = 0; i < maxn; ++i)
{
vec[i] = vec1[i] * vec2[i];
}
t = clock();
printf("--------------used time = %d ms---------------\n", t - s);
s = clock();
printf("--------------enter parallel compute---------------\n");
#pragma omp parallel num_threads(20) shared(vec1, vec2, vec) private(i)
{
#pragma omp for
for (i = 0; i < maxn; ++i)
{
vec[i] = vec1[i] * vec2[i];
}
}
t = clock();
printf("--------------used time = %d ms---------------\n", t - s);
return 0;
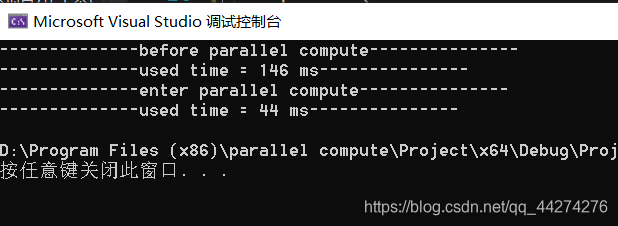
}计算效率对比:
案例2:parallel for并行计算矩阵乘法
cpp
#include <omp.h>
#include <cstdio>
#include <cstdlib>
#include <cmath>
#include <ctime>
const int maxn = 1000;
const int mod = 10000;
int vec1[maxn][maxn], vec2[maxn][maxn], vec[maxn][maxn], i, j, k;
int main()
{
srand((unsigned int)time(NULL));
for (i = 0; i < maxn; ++i)
{
for (j = 0; j < maxn; ++j)
{
vec1[i][j] = rand() % mod;
vec2[i][j] = rand() % mod;
}
}
printf("--------------before parallel compute---------------\n");
clock_t s1, t1, s2, t2;
s1 = clock();
for (i = 0; i < maxn; ++i)
{
for (j = 0; j < maxn; ++j)
{
for (k = 0; k < maxn; ++k)
{
vec[i][j] += (vec1[i][k] * vec2[k][j]);
}
}
}
t1 = clock();
printf("----------------used time = %d ms-----------------\n", t1 - s1);
printf("--------------enter parallel compute---------------\n");
s2 = clock();
#pragma omp parallel for collapse(2) schedule(dynamic) private(i, j, k) shared(vec1, vec2, vec)
for (i = 0; i < maxn; ++i)
{
for (j = 0; j < maxn; ++j)
{
for (k = 0; k < maxn; ++k)
{
vec[i][j] += (vec1[i][k] * vec2[k][j]);
}
}
}
t2 = clock();
printf("----------------used time = %d ms-----------------\n", t2 - s2);
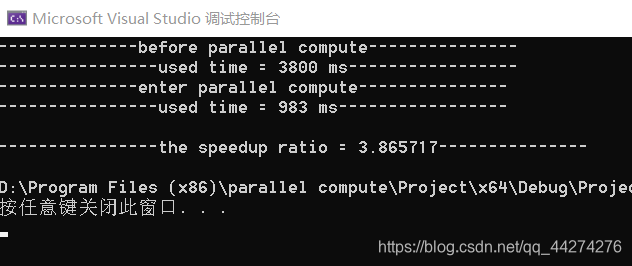
printf("\n----------------the speedup ratio = %lf---------------\n", 1.0 * (t1 - s1) / (t2 - s2));
return 0;
}运行结果如下:
1.4、运用omp parallel for的一些注意事项
第一:omp parallel for 和 omp for 不要混用
一旦在前面有使用过
cpp
#pragma omp parallel ...语句,并且当前还处在这个并行区,然后这个时候你想使用for循环并行,则千万不要再搞一次:
cpp
#pragma omp parallel for这样的操作了,因为这样会让线程组重组,然后相当于有两重并行,举个例子看看:
在有#pragma omp parallel 的并行区下运行
cpp
#include <omp.h>
#include <iostream>
using namespace std;
int main()
{
#pragma omp parallel num_threads(10)
{
#pragma omp for
for (int i = 0; i < 5; ++i)
{
#pragma omp critical
{
cout << "i = " << i << endl;
}
}
}
return 0;
}此时的运行结果是:
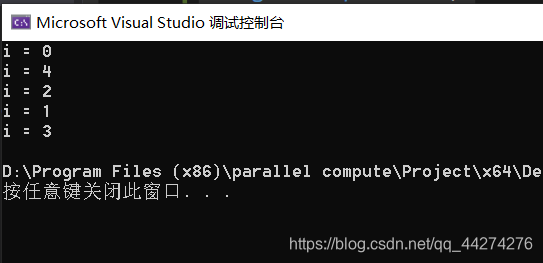
然后如果你多此一举多搞一遍parallel命令就会:
cpp
#include <omp.h>
#include <iostream>
using namespace std;
int main()
{
#pragma omp parallel num_threads(4)
{
#pragma omp parallel for // 注意看这里哦
for (int i = 0; i < 5; ++i)
{
#pragma omp critical
{
cout << "i = " << i << endl;
}
}
}
return 0;
}看看这样的"多此一举"的运行结果:
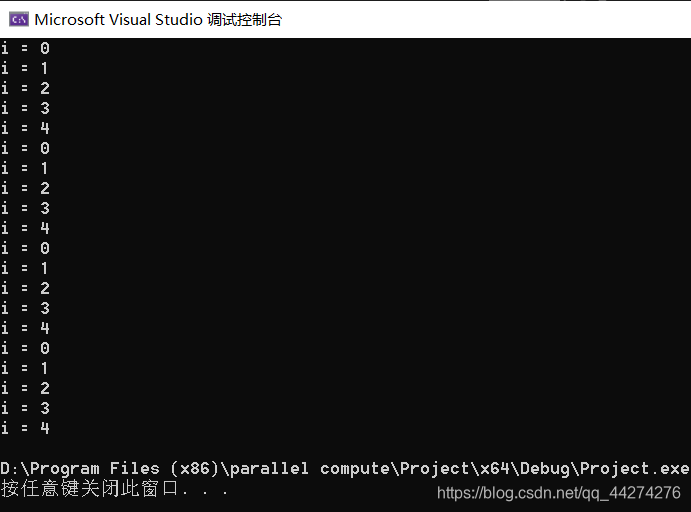
我们会发现,这个0 ~ 4 被重复执行啦!这样会影响并行程序结果,还会误以为运行的开销变大哦!!!!
造成这种结果的原因就是:parallel命令会告诉操作系统,此时我要重组线程组,要重新开始并行程序运行。然后这下好啦,每个线程到了那句指令的时候都重组线程组,白白多执行4次(取决于线程数)
二、多线程下数据访问同步
2.1、同步一词在并行计算的含义
其实同步啊,在并行计算里有两种含义:
第一:线程/进程的运行有的快有的慢,我想要在某处各个线程/进程达到同样的状态,这叫并行程序的运行同步
第二:对于共享内存的模型,我们需要控制数据的访问,达到线程同步。这样做的目的是为了防止多个进程/线程同时访问某个数据、内存,导致该数据同时改变,这样的作用下会让数据失真!举个例子:初始有变量a = 2,比如线程A要让a++,线程B要让a*=2。如果不控制访问,让变量a(或者某语句块)的执行的时候只能让一个线程进入执行,其他线程等待执行。则会让资源出现同步问题。这就叫数据同步。
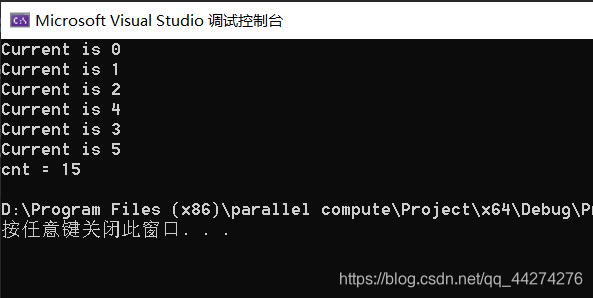
2.2用critical创建临界区的方式避免线程同步危害
cpp
#include <omp.h>
#include <iostream>
using namespace std;
int main()
{
int i, len, cnt = 0;
#pragma omp parallel num_threads(6)
{
len = omp_get_num_threads();
#pragma omp for private(i)
for (i = 0; i < len; ++i)
{
#pragma omp critical
{
cout << "Current is " << i << endl;
cnt += i;
}
}
}
cout << "cnt = " << cnt << endl;
return 0;
}利用critical指令完成线程同步的运行结果: