一、stream() 同步传输
python
from langchain_community.chat_models import ChatTongyi
#.stream() ⽅法返回⼀个迭代器,该迭代器在⽣成输出时同步产⽣输出 消息块 。可以使⽤ for 循环实时处理每个块
model = ChatTongyi(model="qwen-plus")
for chunk in model.stream("写一个1000字的作文"):
print(chunk.content, end= "", flush=True)二、astream() 异步传输
1.进程、线程、协程
进程:操作系统分配资源的基本单位,有独立内存空间,隔离性好,但创建和切换开销最大。适合需要强隔离,多核CPU密集计算的场景。
线程是操作系统调度的基本单位,属于某个进程,同一进程内线程共享内存,比进程轻量,但需要处理线程安全问题。适合I/O密集、并发量中等的场景。
协程是用户态的轻量级执行单元,由程序自己调度,不经过操作系统。切换成本极低,可创建大量协程,但采用协作式调度,只在主动让出(如await)时切换。适合高并发I/O场景,如网络请求,数据库查询。
关系:一个进程包含多个线程,一个线程可以运行多个协程。进程>线程>协程,粒度越来越细,开销越来越小。
python
import asyncio
import time
#定义协程
async def boil_water_async():
print("开始烧水...")
await asyncio.sleep(5) # await表示这个操作完成,但期间让事件循环去做别的事
print("水开了!")
async def send_message_saync():
print("开始发短信...")
await asyncio.sleep(2)
print("发送消息成功!")
#主程序也是一个协程
async def main():
current = time.time()
task1 = asyncio.create_task(send_message_saync())
task2 = asyncio.create_task(boil_water_async())
#等待两个任务都完成
await task1
await task2
end = time.time()
print(f"总耗时:{end-current}")
asyncio.run(main())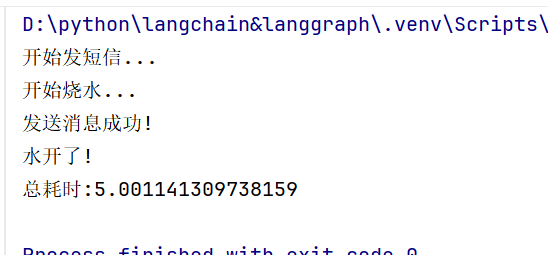
2.大模型的异步使用
python
import asyncio
from langchain_community.chat_models import ChatTongyi
model = ChatTongyi(model="qwen-plus", streaming=True)
async def async_stream():
print("====异步调用====")
async for chunk in model.astream("你是谁"):
print(chunk.content, end="|", flush=True)
asyncio.run(async_stream())
三、自定义流式输出解析器
当一个函数包含 yield 时,调用该函数不会立即执行代码,而是返回一个生成器对象。只有当你遍历这个生成器(如使用 for 循环或 next())时,函数才会开始执行。
-
执行到
yield行时,函数会返回 后面的值,并冻结当前状态(记住所有局部变量)。 -
下次调用
next()时,函数会从刚才冻结的下一行 继续执行,直到再次遇到yield或结束。
python
from typing import Iterable, List
from langchain_community.chat_models import ChatTongyi
from langchain_core.output_parsers import StrOutputParser
model = ChatTongyi(model="qwen-plus")
#定义输出解析器
parse = StrOutputParser()
def split_into_list(input: Iterable[str]) -> Iterable[List[str]]:
"""
流式句子切分器:将模型逐段输出的文本,按中文句号「。」拆成完整句子。
典型输入来自 LangChain 链式调用中的流式字符串(如 model | StrOutputParser)。
每凑齐一句(遇到句号)就立即 yield,无需等待全文生成完毕。
Args:
input: 字符串可迭代对象,每次迭代得到一小段文本(一个 chunk)
Yields:
List[str]: 单元素列表,包含一句已去掉首尾空白的完整句子(不含句号)
示例:
输入流: "春眠" -> "不觉晓。" -> "处处闻啼鸟。"
输出: ["春眠不觉晓"] -> ["处处闻啼鸟"]
"""
# 缓冲区:累积尚未形成完整句子的文本碎片
# 模型流式输出时每次只给几个字,需要暂存到 buffer 中拼接
buffer = ""
# 遍历上游传来的每一个文本片段(流式 chunk)
for chunk in input:
# 将新片段追加到缓冲区末尾
buffer += chunk
# 用 while 而非 if:一个 chunk 可能包含多个句号(如 "A。B。C。"),
# 需要循环切分,直到 buffer 中不再包含句号
while "。" in buffer:
# 找到第一个句号的位置,作为当前句子的结束边界
stop_index = buffer.index("。")
# 截取句号之前的内容作为一句,strip() 去掉首尾空白字符
# 包装成单元素列表,符合 LangChain 链式输出的列表格式
yield [buffer[:stop_index].strip()]
# 保留句号之后的剩余文本,供下一句拼接使用(句号本身丢弃)
buffer = buffer[stop_index + 1:]
# 输入流结束后,若 buffer 中仍有内容(最后一句没有句号,或只剩空白),
# 将剩余部分作为最后一条结果输出
yield [buffer.strip()]
chain = model | parse | split_into_list
for chunk in chain.stream("给我写一首七言绝律诗词, 每句以句号分割"):
print(chunk, end="|", flush=True)四、SSE协议
SSE(Server-Sent Events)是⼀种基于 HTTP 的轻量级实时通信协议,浏览器可以通过内置的
EventSource API 接收并处理这些实时事件。
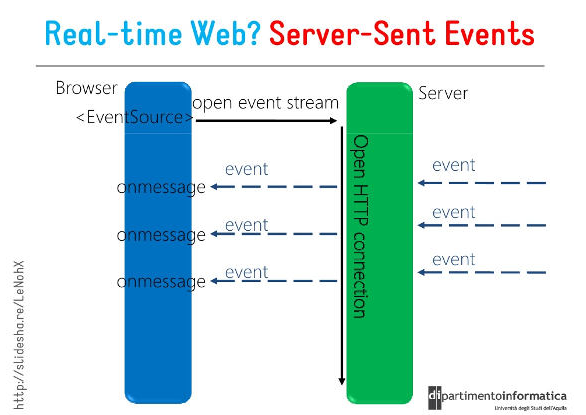
核⼼特点
基于 HTTP 协议
复⽤标准 HTTP/HTTPS 协议,⽆需额外端⼝或协议,兼容性好且易于部署。
单向通信机制
SSE 仅⽀持服务器向客⼾端的单向数据推送,客⼾端通过普通 HTTP 请求建⽴连接后,服务器可持续发送数据流,但客⼾端⽆法通过同⼀连接向服务器发送数据。
⾃动重连机制
⽀持断线重连,连接中断时,浏览器会⾃动尝试重新连接(⽀持 retry 字段指定重连间隔)。
⾃定义消息类型
客⼾端发起请求后,服务器保持连接开放,响应头设置 Content-Type: text/event
stream ,标识为事件流格式,持续推送事件流。