Kafka KRaft 完整深度架构设计(基于 KIP-500,Kafka 3.3+/4.x)
KRaft = Kafka + Raft ,核心目标:移除 ZooKeeper,内置 Raft 共识协议管理全集群元数据 ,把控制平面完全收归 Kafka 自身,分为角色分层、Raft 共识层、元数据存储层、元数据同步链路、故障转移、三种部署拓扑六大核心模块。
KRaft整体拓扑
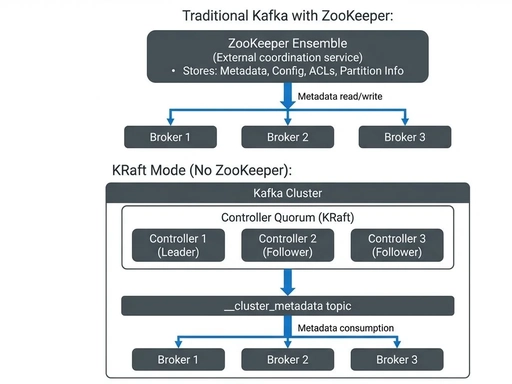
分离部署架构图
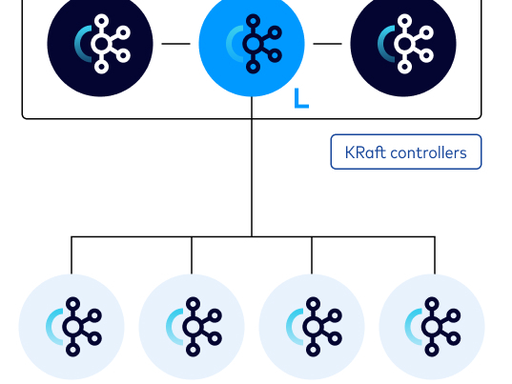
一、核心架构分层总览(三层设计)
plaintext
1. 应用层:Broker 业务节点(生产/消费/存储消息)
2. 控制平面层:Controller Quorum 仲裁集群(Raft Leader/Follower,元数据写入入口)
3. 底层存储层:__cluster_metadata 内部元数据日志 + 快照持久化1.节点角色定义(通过 process.roles 区分)
KRaft 把 Kafka 服务拆分为两种独立角色,可合并 / 分离部署:
- Controller(仲裁投票节点 Voter)
1.1 配置:process.roles=controller
1.2 职责:组成 Raft Quorum,执行元数据写入、选举、集群状态管理
1.3 数量规范:固定3/5 台(奇数),3 台容忍 1 节点故障,5 台容忍 2 节点故障
1.4 独有配置:controller.quorum.voters、独立 controller 监听端口 - Broker(业务数据节点)
2.1 配置:process.roles=broker
2.2 职责:处理生产者、消费者读写,同步元数据,存储业务 Topic 消息
2.3 不参与 Raft 投票,只拉取元数据,无元数据写入权限 - Combined 混合节点(测试 / 小集群)
3.1 配置:process.roles=broker,controller
3.2 单进程同时承担 Controller+Broker,开发环境用;生产大集群禁止(业务流量抢占 Controller CPU/IO,元数据延迟飙升)
二、Controller Quorum Raft 共识层(KRaft 核心)
2.1 Raft 三角色状态(Controller 节点循环切换)
- Leader(Active Controller 唯一主控制器)
1.1 集群唯一可接收元数据变更请求的节点
1.2 接收 Broker/AdminClient 的创建 Topic、分区重分配、Broker 上下线等写请求
1.3 通过AppendEntries同步元数据日志到所有 Follower Controller
定时发送心跳(500ms)阻止 Follower 发起新选举 - Follower(备用控制器)
2.1 被动同步 Leader 的__cluster_metadata日志,维护完整元数据副本
2.2 无写权限,仅作为热备,Leader 宕机后参与选举
2.3 心跳超时自动转为 Candidate - Candidate(选举候选人)
3.1 心跳超时后发起选举,向所有 Voter 发送RequestVote RPC
3.2 获得多数派投票自动升级为新 Leader,旧 Leader 收到新 term 心跳自动降级为 Follower
2.2 KRaft Raft 安全机制(规避脑裂、数据不一致)
- 任期 (term) 单调递增:每次选举 term+1,高 term 节点天然覆盖低 term 旧主
- 日志完整性校验:投票仅投给日志更新、term 更大的 Candidate,不会选出数据落后的 Leader
- 多数派提交:元数据日志必须同步到半数以上 Controller才算已提交,才会更新内存集群状态
- 空日志 No-Op 机制:新 Leader 上台先写入一条空日志,推进所有历史日志提交,保证读请求数据一致性
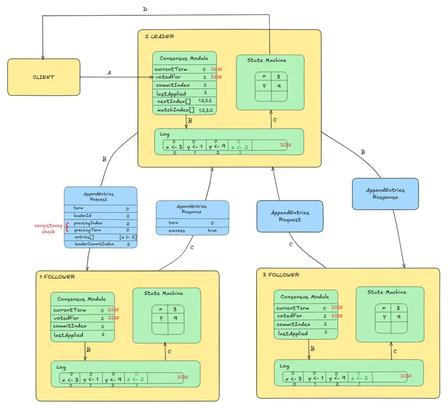
2.3 Controller 内部单线程事件模型(关键设计)
所有元数据请求、Raft 同步、状态更新串行单线程处理:
- Broker 发送元数据变更 RPC → 放入事件队列
- 单线程顺序消费事件,读取内存元数据状态机计算变更记录
变更记录封装写入 Raft 日志 - 等待多数派副本确认提交,再同步更新内存状态机、返回响应给 Broker
- 优势:无多线程并发锁竞争,大幅降低分布式状态一致性 BUG。
Raft内部状态机分层
三、元数据存储:__cluster_metadata 内部日志 + 快照机制
3.1 元数据日志(事件溯源设计,替代 ZK 树形 znode)
KRaft 使用单分区内部 Topic __cluster_metadata 存储全部集群元数据,每条日志是一条变更事件,完全替代 ZK 所有存储内容:
- Topic 创建 / 删除、分区分配、副本列表、ISR 集合
- Broker 上下线、Broker ID/UUID 注册
- ACL 权限、动态配置、分区重分配、消费者组元数据
- 控制器集群变更(新增 / 移除 Voter 节点)
核心特性:
- 仅单分区:全局唯一元数据顺序,保证集群变更有序执行
- 写入仅 Leader Controller,Follower Controller 复制完整日志
- 所有 Broker 定时拉取日志增量,同步本地内存元数据缓存
3.2 元数据快照(解决日志无限膨胀、节点快速启动)
日志持续增长会导致新 Controller/Broker 启动重放全量日志耗时过长,KRaft 引入快照 Snapshot:
- 触发时机:日志累计一定偏移量自动生成完整快照
- 快照内容:当前时间点完整全量集群状态(序列化静态视图)
- 存储位置:每个 Controller/Broker 本地元数据目录
- 恢复流程:
1.节点重启 / 新节点上线:先加载本地快照到内存
2.再从快照结束 offset 开始,增量拉取后续元数据日志
3.快照落地后,可截断快照前的旧日志,释放磁盘空间
四、元数据同步链路(Broker ↔ Controller 拉取模型,核心革新)
4.1 ZK 旧架构推送模式(缺陷)
Broker 注册 ZK Watcher,元数据变更主动推送全集群,产生 Watcher 羊群风暴,大量 Broker 同时拉取元数据阻塞 Controller。
4.2 KRaft 拉取同步模型(全新设计)
- 所有 Broker 维护一个元数据 offset 标记,记录自己已同步到哪一条元数据日志
- Broker 定时向 Leader Controller 发起FetchMetadata RPC(长轮询)
- Controller 对比 Broker 本地 offset,仅返回增量变更日志,无变更则阻塞等待新事件
- Broker 拿到增量日志,逐条重放更新本地内存元数据缓存
优势:
- 无广播风暴,每个 Broker 只拉取自身缺失增量,网络开销大幅降低
- Controller 无推送压力,支持百万级分区集群
- Broker 重启只需要拉取快照 + 少量增量,同步速度毫秒级
完整元数据变更时序(创建 Topic 举例)
- AdminClient/Broker 向Leader Controller发送 CreateTopic 请求
- Controller 单线程校验权限、计算分区副本分配方案
- 生成CreateTopicRecord元数据记录,追加到本地__cluster_metadata日志
- 同步日志到半数以上 Follower Controller(多数派提交)
- 提交成功后更新 Controller 内存集群状态,返回成功给客户端
- 后台所有 Broker 通过长轮询拉取这条增量记录,本地更新元数据缓存,感知新 Topic
五、三种官方部署拓扑(生产环境选型标准)
拓扑 1:分离部署模式(生产集群推荐,大型集群必用)
- Controller 集群:独立 3/5 台节点,process.roles=controller,仅跑元数据 Raft 共识,不处理业务消息读写
- Broker 集群:其余节点 process.roles=broker,只负责生产消费业务
- 优势:故障域隔离,业务流量 IO/CPU 波动不会干扰 Controller;Controller 可独立扩容、独立滚动升级;元数据延迟稳定
- 适用:生产线上、百万分区、高吞吐业务集群
拓扑 2:Combined 混合部署(开发 / 测试 / 小型边缘集群)
所有节点 process.roles=broker,controller,单进程同时承担投票 + 业务
- 优点:部署简单,最少 3 台即可组成完整集群,无额外机器
- 缺点:Controller 与业务抢占资源,高流量场景元数据延迟、选举卡顿,禁止核心生产业务使用
拓扑 3:混合异构部署(过渡迁移场景)
少量 3 台 Combined 节点充当 Quorum,其余纯 Broker 节点仅用于 ZK 迁移 KRaft 过渡阶段,不建议长期运行
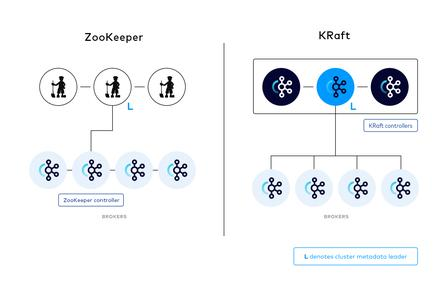
ZK架构 vs KRaft分离架构对比
六、Controller 故障转移完整流程(毫秒级切换,对比 ZK 秒级卡顿)
ZK 旧架构故障切换痛点
旧 Controller 宕机 → 所有 Broker 抢 ZK 临时节点选举新 Controller → 新 Controller全量拉取 ZK 所有元数据,分区越多加载越慢,数千分区切换耗时 5~30 秒,集群期间无法执行分区 Leader 选举、创建 Topic。
KRaft 故障切换流程(热备 Follower 秒级接管)
- Leader Controller 宕机,Follower 心跳超时,全部转为 Candidate 发起选举
- 最快拿到多数投票的 Follower 升级为新 Leader
- Follower 本地已完整同步全部元数据日志与快照,无需拉取任何全量数据,内存状态立即可用
- 立即对外提供元数据写入服务,Broker 长轮询自动连接新 Leader
- 切换耗时:几十~几百毫秒,集群业务几乎无感知
七、KRaft 关键内置 RPC 协议(内部通信)
- RequestVote RPC:选举阶段,Candidate 向其他 Voter 请求投票
- AppendEntries RPC:
1)Leader 同步元数据日志给 Follower Controller
2)无数据时作为心跳,维持 Leader 任期 - FetchMetadata RPC:Broker 向 Leader 拉取增量元数据(长轮询核心)
- AddVoter/RemoveVoter RPC:动态扩容 / 缩容 Controller 仲裁节点(在线调整 Quorum)
Kafka Zookeeper 架构完整深度设计
(0.8 ~ 3.4.x 传统架构,KIP-500 前标准)
整体架构分为三大块:ZooKeeper 存储层、Controller 控制层、Broker 数据节点层。
ZK 承担集群全部元数据持久化、分布式协调、锁、监听通知能力,Broker 只负责消息存储与读写。
一、整体架构分层
plaintext
1. 客户端层:Producer / Consumer / AdminClient
2. Broker 集群层:负责消息持久化、生产消费、副本读写
3. Controller 单点控制层:集群唯一主控制器(由ZK选举)
4. ZooKeeper 协调层:存储元数据、提供临时节点Watcher、分布式锁、选主通信链路:
Client ↔ Broker ↔ Zookeeper
Controller ↔ Zookeeper + Controller ↔ 所有Broker
二、ZooKeeper 中 Kafka 完整目录结构(核心元数据存储)
Kafka 在 ZK 根路径 /kafka(可通过 zookeeper.chroot 修改)下划分固定 znode:
plaintext
/kafka
├── brokers
│ ├── ids # 在线Broker ID持久节点
│ │ ├── 0 # Broker0元数据:host/port/rack
│ │ ├── 1
│ │ └── 2
│ ├── topics # 所有Topic元数据持久节点
│ │ ├── order_topic
│ │ │ ├── partitions # 分区列表
│ │ │ │ ├── 0
│ │ │ │ │ └── state # ISR、leader、副本分配
│ │ │ │ ├── 1
│ │ │ └── config # Topic配置(副本数、分区数、过期策略)
│ └── seqid_broker_ids # Broker自增ID生成器
├── controller # 临时节点:集群唯一Controller锁
├── controller_epoch # Controller任期,防止脑裂
├── admin
│ ├── delete_topics # 待删除Topic标记
│ └── reassign_partitions # 分区重分配任务
├── consumers # 旧版消费者组(0.9之前)
│ └── group_id
│ ├── offsets # 消费位移
│ └── owners
├── config # 全局动态配置
│ ├── brokers
│ ├── topics
│ └── clients
└── isr_change_notifier # ISR变更通知队列节点类型说明
- 持久节点 Persistent: brokers/ids、topics、config,集群重启数据不丢失;
- 临时节点 Ephemeral: /controller、Broker 上线临时标识、旧消费者组;Broker/Controller 宕机自动删除;
- 有序临时节点: 用于选举、分布式队列。
三、核心模块 1:Controller 控制器(ZK 架构单点核心)
3.1 Controller 选举机制(基于 ZK 临时节点抢锁)
- 所有 Broker 启动时,尝试创建临时节点 /kafka/controller;
- ZK 临时节点只能创建一个,创建成功的 Broker 成为Active Controller;
- 其余 Broker 创建失败,作为 Standby 持续 Watcher 监听该节点;
- 当 Active Controller 宕机,ZK 自动删除临时节点,所有 Standby 收到
- Watcher 事件,重新竞争创建,选出新 Controller。
3.2 controller_epoch 防脑裂设计
/kafka/controller_epoch持久节点存储数字任期:
- 每次新 Controller 当选,先将 epoch+1;
- 所有 Broker、元数据操作携带当前 epoch;
- 收到更小 epoch 的 Controller 指令直接拒绝,避免新旧 Controller 同时下发指令造成数据错乱(脑裂)。
3.3 Controller 完整职责(集群总调度中心)
- Broker 上下线感知处理
Broker 上线:ZK 新增brokers/ids触发 Watcher,Controller 分配分区副本、选举分区 Leader;
Broker 下线:临时节点消失,Controller 检测副本丢失,重新调整 ISR、切换 Leader、触发副本复制。
- Topic / 分区生命周期管理
创建 / 删除 Topic、增加分区、分区重分配、副本均衡。 - 分区 Leader & ISR 管理
监听每个分区state节点变化,处理副本同步、故障转移。 - 下发集群指令给所有 Broker
通过 RPC 下发 Leader 切换、副本迁移、停止副本等指令。
3.4 Controller 切换完整流程(痛点:全量加载元数据)
- 旧 Controller 宕机 → ZK 删除/controller临时节点;
- 所有 Broker 收到 Watcher 事件,并发竞争创建节点;
- 获胜 Broker 成为新 Controller;
- 关键耗时步骤:新 Controller 需要全量遍历 ZK 所有 Topic、所有分区、所有 Broker 元数据加载到内存;
- 分区数十万时,加载耗时可达数秒~数十秒,期间集群无法处理分区故障转移、无法新建 Topic。
四、核心模块 2:Broker 与 Zookeeper 交互设计
4.1 Broker 上线注册流程
- Broker 启动,生成唯一 broker.id;
- 在/brokers/ids/{id}写入本机 IP、端口、机架信息(持久节点);
- 注册大量 Watcher 监听关键 ZK 路径:
/controller:监听控制器切换;
/brokers/ids:监听 Broker 上下线;
/brokers/topics:监听 Topic 新增删除;
每个自身持有副本分区的partition/state:监听 ISR/Leader 变更。
- 上报本地所有块副本信息给 Controller。
4.2 Broker 心跳与副本同步逻辑
- Broker 不直接向 ZK 上报心跳,依靠临时节点存活特性:进程正常连接 ZK 则节点保留,断连 / 宕机自动清理;
- 每个分区副本定期向 Leader 同步数据;
- Leader 持续更新 ZK 对应分区state节点,维护 ISR(同步副本集合)。
4.3 Watcher 羊群风暴(ZK 架构重大缺陷)
每个 Broker 会注册数十上百个 Watcher;
任意一次集群变更(Broker 宕机、ISR 变动、新建 Topic),ZK 会一次性推送事件给全部 Broker,大量 Broker 同时拉取 ZK 元数据,瞬间产生大量网络与 ZK 读请求,集群卡顿。
五、核心模块 3:Topic & 分区副本元数据流程
5.1 创建 Topic 流程
- AdminClient 发送 CreateTopic 请求给任意 Broker;
- Broker 转发请求给 Active Controller;
- Controller 计算分区副本分配策略(机架感知、副本分散);
- 在 ZK /brokers/topics/xxx 写入分区分配元数据;
- Controller 下发 RPC 指令给对应 Broker 创建本地日志目录;
- 触发 Watcher,所有 Broker 同步感知新 Topic。
5.2 分区 Leader 与 ISR 故障转移
- Leader Broker 宕机 → ZK 临时节点失效;
- Controller 收到 Watcher 事件,读取该分区 ISR 列表;
- 从 ISR 中挑选新副本作为 Leader,更新 ZK 分区state;
- 通知所有 Broker 更新本地缓存的分区 Leader 信息;
- 生产者消费者重新连接新 Leader。
六、消费者组协调设计(ZK 存储位移,旧消费者)
6.1 ZK 存储结构(high-level consumer)
plaintext
/kafka/consumers/{group-id}
├── offsets/{topic}/{partition} # 存储该分区已消费offset
└── owners/{topic}/{partition} # 分区归属消费者线程- 消费者启动后注册组信息;
- 自动分配分区,将分区所有权写入 ZK 临时节点;
- 定时将消费位移持久化到 ZK;
- 消费者下线,临时节点删除,触发再平衡 rebalance。
注意:新版本引入 GroupCoordinator 后,消费者位移存入内部 Topic __consumer_offsets,不再大量写 ZK,但组元数据仍依赖 ZK 协调。
七、动态配置、权限、删除 Topic 机制
- 动态配置
/config 下分 broker/topic/client 三级配置节点,修改 ZK 数据,Broker 监听 Watcher 动态加载参数,无需重启。 - 删除 Topic
仅在/admin/delete_topics添加标记,Controller 后台异步清理分区数据,清理完成后删除 ZK 元数据。 - 分区重分配
重分配计划写入/admin/reassign_partitions,Controller 后台逐步迁移副本。
八、Zookeeper 在架构中的核心能力定位
- 分布式锁:利用临时节点实现 Controller 全局唯一;
- 元数据持久存储:树形 KV 保存 Topic、分区、Broker 全量集群信息;
- 事件通知 Watcher:数据变更主动推送所有 Broker 同步状态;
- 临时节点失效检测:进程宕机自动清理,实现 Broker / 消费者故障感知;
- 有序节点:实现任务队列、选举排序。
九、ZK 架构固有设计缺陷(也是 KRaft 替换的根本原因)
- Watcher 广播风暴
集群变更全量推送所有 Broker,大规模分区场景 ZK QPS 打满; - 元数据写入性能瓶颈
ZAB 协议适合低频配置写入,不支持百万分区高频元数据变更;集群分区上限约 20 万; - Controller 切换阻塞
新 Controller 需要全量遍历 ZK 加载元数据,切换耗时几秒到几十秒; - 双重运维组件
Kafka + ZK 两套分布式系统,两套监控、配置、升级、权限; - 两层网络依赖
Broker 强依赖 ZK,ZK 断连整个集群元数据不可用,生产消费受阻; - 两套安全体系
Kafka SASL/SSL + ZK 独立 SASL ACL,配置复杂易漏配; - 元数据存储模型不流式
ZK 是树形 KV,不像日志一样支持增量同步,每次变更全量拉取成本高。
十、ZK 架构 vs KRaft 关键设计对比简表
| 维度 | Zookeeper 架构 | KRaft 架构 |
|---|---|---|
| 元数据载体 | ZK 树形 znode | 内部 Raft 日志 __cluster_metadata |
| 控制器选举 | 所有 Broker 竞争 ZK 临时节点 | 固定 3/5 台 Voter Raft 选主 |
| 元数据同步 | ZK Watcher 主动广播推送 | Broker 主动长轮询拉取增量 |
| 故障切换耗时 | 全量加载元数据,秒~分钟级 | 本地已有完整日志,毫秒级 |
| 外部依赖 | 必须独立部署 ZK 集群 | 无外部依赖,内置共识 |
| 分区规模上限 | 20 万左右 | 百万级分区 |
| 通信依赖 | Broker 直连 ZK,多一层故障点 | 仅 Broker ↔ Controller 通信 |
| 运维 | 两套集群维护 | 单一套 Kafka 集群 |