论文标题: A Systematic Survey of Self-Evolving Agents: From Model-Centric to Environment-Driven Co-Evolution
论文链接: TechRxiv PDF
论文作者: Zhishang Xiang、Chengyi Yang、Zerui Chen、Zhimin Wei、Yunbo Tang、Zongpei Teng、Zexi Peng、Zongxia Li、Chengsong Huang、Yicheng He、Chang Yang、Xinrun Wang、Xiao Huang、Qinggang Zhang、Jinsong Su
一句话总结: 论文把自进化智能体统一为"模型中心自演化---环境中心自演化---模型---环境协同进化"三层谱系,并明确把可验证、可扩展、能随智能体共同生长的环境视为突破能力上界的决定因素。
背景与动机
这篇 survey 要解决的不是"再列一遍 agent 方法",而是解释一个更核心的转向:为什么传统 agent 的进步越来越受限于人工监督,以及为什么单纯把模型做大、把 CoT 跑长,并不能自然得到开放世界里的持续进化。
论文把瓶颈讲得很直接。现有 agent 大多沿着"预训练 + 人工驱动的后训练"路线走:SFT 依赖高质量标注,RL 又常被人类设计的奖励函数约束。这样做有两个上限。第一,监督规模上不去 ,高质量 agent 数据比通用语料更贵。第二,能力天花板来自人类监督本身,模型最多学到人类已经写进数据和奖励里的东西。
作者据此提出 Self-Evolving Agents 范式:让 agent 不再只是消费静态数据,而是主动构造自己的改进闭环。闭环中的学习信号可以来自内部推理轨迹,也可以来自外部环境反馈。论文随后给出的核心判断是:真正让能力持续外溢的,不是模型内部再多一点自我反思,而是环境能否提供新的知识、真实的反馈、逐步抬升的任务难度,以及和 agent 一起演化的空间。
整体框架与分类体系总览
论文先给了一条时间线,再给统一 taxonomy。时间线说明这个方向并非突然出现,而是从 self-consistency、STaR、ReAct、Reflexion 一路演化到 DeepResearch、Reasoning Gym、AgentGym 这类更强环境参与的系统;taxonomy 则回答"这些方法到底在演化什么"。
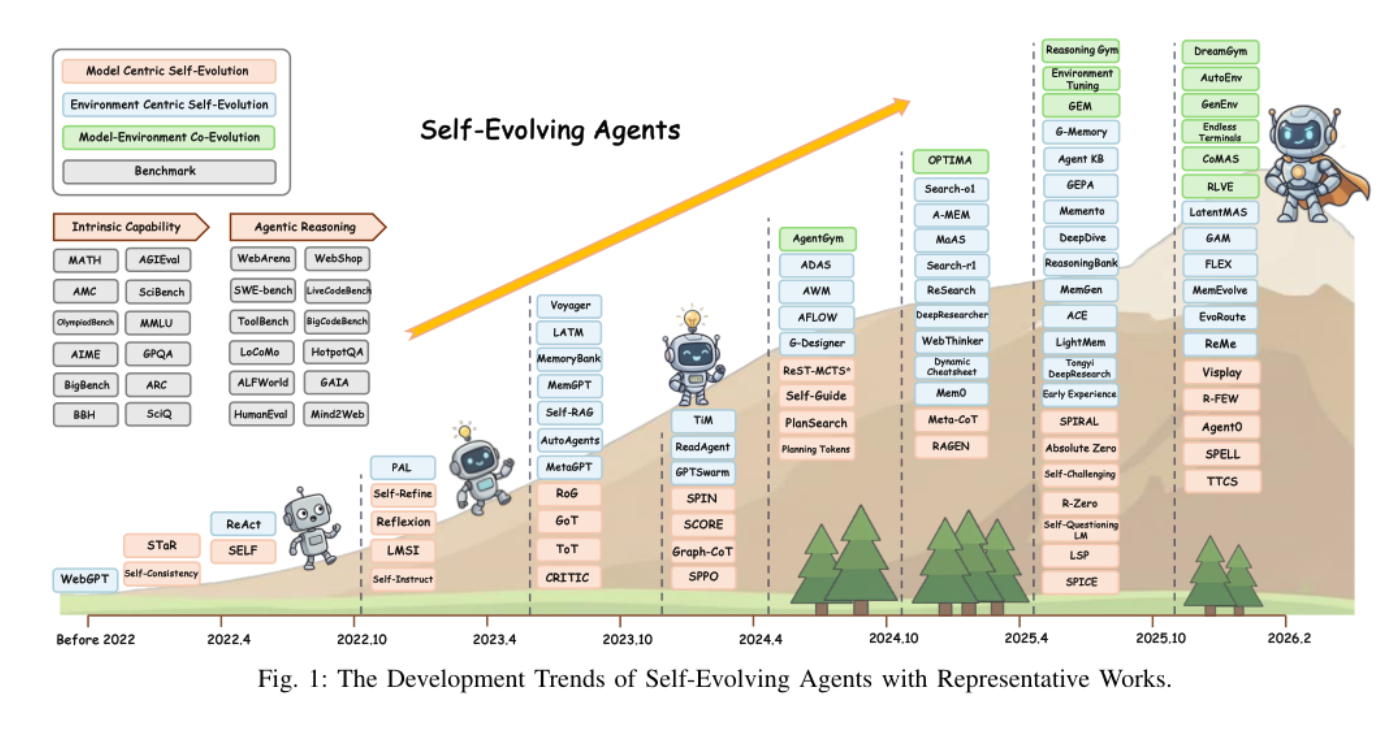
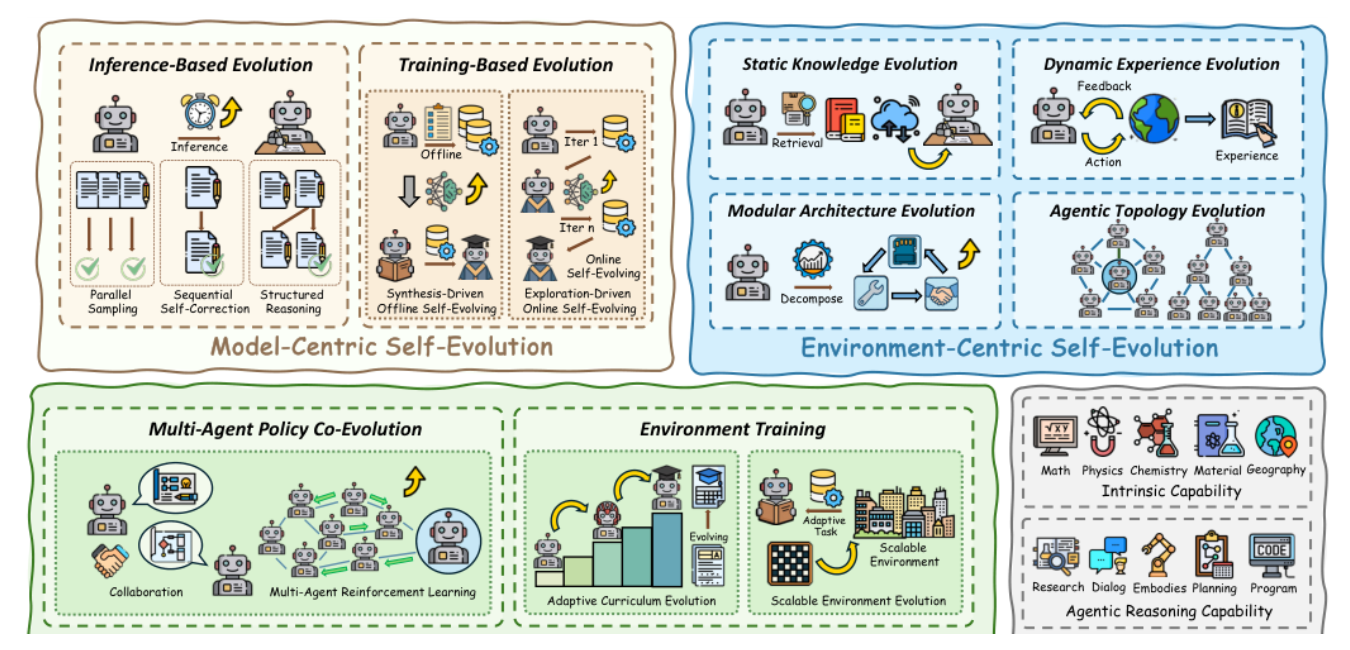
作者把自进化方法分成三大范式:
模型中心自演化
-
演化对象: 模型内部推理过程或参数
-
核心资源: test-time 计算、合成数据、自博弈轨迹
-
解决的问题: 把预训练权重里"已有但未充分释放"的能力挖出来
-
代表分支: 并行采样、顺序自纠错、结构化推理、离线/在线自训练
环境中心自演化
-
演化对象: 知识获取、经验沉淀、记忆结构、工具与多智能体拓扑
-
核心资源: 检索、执行结果、外部交互、经验库
-
解决的问题: 模型参数之外的知识与行为如何持续积累
-
代表分支: 静态知识演化、动态经验演化、模块架构演化、拓扑演化
模型---环境协同进化
-
演化对象: agent 策略与环境本身同时变化
-
核心资源: 多智能体交互、课程难度调节、可扩展环境生成
-
解决的问题: 如何避免模型强了、环境却不再提供新增益
-
代表分支: 多智能体策略协同进化、环境训练
这三层不是并列目录,而是论文的主线递进:模型中心自演化 先把模型内部潜力压出来,环境中心自演化 把环境当成知识与经验来源,模型---环境协同进化则把环境从"被调用的外部资源"升级为"会一起长大的训练对象"。作者明确把第三层视为未来主航道。
形式化定义与统一问题表述
论文的公式不多,但这几条公式把全文的讨论框住了:agent 是什么、环境是什么、交互如何形成进化闭环。
Agent 五元组
论文将 LLM agent 写成一个五元组:
A = ⟨ Φ , M , P , T , I ⟩ A = \langle \Phi, M, P, T, I \rangle A=⟨Φ,M,P,T,I⟩
其中工具集合还单独写成:
T = { t 1 , t 2 , ... , t k } T = \{t_1, t_2, \dots, t_k\} T={t1,t2,...,tk}
| 符号 | 含义 | 类型 / shape | 论文中的角色 |
|---|---|---|---|
A |
完整 agent | 结构化对象;非张量,无固定 shape | 把 agent 看成由认知、记忆、工具和交互部件组成的系统,而不是单一 LLM 调用 |
\Phi |
Core LLM | 模型对象;参数记为 \theta,实现上是参数张量集合,论文未给固定维度 |
负责语义理解、推理、指令生成,是"脑" |
\theta |
LLM 参数 | 高维参数张量集合;可抽象记作 \theta \in \mathbb{R}^n,但论文未指定 n |
当方法做参数更新时,被优化的核心对象就是 \theta |
M |
Memory | 短期/长期记忆容器;非张量,无固定 shape | 存历史交互、知识库、过去经验,缓解上下文窗口和无状态问题 |
P |
式(1) 中出现的组件 | 论文未给显式 shape | 这里有一个记号层面的不一致:式(1) 写了 P,但紧接着的分项说明只明确展开了 \Phi、M、T、I 四类部件。为了避免超出正文推断,以下解读不把 P 当作独立技术分支展开。 |
T = \{t_i\}_{i=1}^k |
工具集合 | 有限集合,基数为 k;每个 t_i 是 API / 外部服务 / 执行器 |
把模型能力延伸到检索、计算、执行和物理控制 |
I |
Interaction Interface | 接口模块;非张量,无固定 shape | 承担感知、动作执行、反馈采集三件事,把 agent 接到真实环境里 |
这一定义的重点不在"用五个字母把 agent 记下来",而在于作者把记忆、工具、接口 都写成一等公民。后面的环境中心演化、协同进化,本质上都在增强这三类外部耦合部件,而不是只改 \Phi。
Environment 二元组
论文把环境定义为:
E = ⟨ S , V ⟩ E = \langle S, V \rangle E=⟨S,V⟩
| 符号 | 含义 | 类型 / shape | 论文中的角色 |
|---|---|---|---|
E |
环境整体 | 结构化对象;非张量,无固定 shape | 不是黑箱背景板,而是提供状态与验证机制的外部系统 |
S |
状态空间 | 状态集合;s_t \in S,单个状态通常是符号对象/文本上下文/任务配置,无统一张量维度 |
包含任务上下文、初始条件、外部知识库等 agent 可观察现实 |
V |
验证与反馈机制 | 验证器 / 反馈函数;输出可以是标量、文本、执行痕迹或状态码 | 这是环境最关键的部分,它决定 agent 是否能拿到客观、可归因的改进信号 |
对这篇 survey 来说,V 比 S 更关键。作者一再强调:自进化要能稳定发生,环境必须能验证 。代码解释器、单元测试、数学标准答案、定理证明器之所以反复出现,不是因为这些任务更"高级",而是因为它们更容易提供高质量、可复用的 V。
Agent---Environment 交互闭环
论文把交互过程抽象成 MDP,并给出轨迹定义:
τ = ( s 0 , a 0 , r 1 , s 1 , ... , s t , a t , r t + 1 , ... ) \tau = (s_0, a_0, r_1, s_1, \dots, s_t, a_t, r_{t+1}, \dots) τ=(s0,a0,r1,s1,...,st,at,rt+1,...)
策略生成动作:
a t ∼ π Φ ( a ∣ s t ) a_t \sim \pi_{\Phi}(a \mid s_t) at∼πΦ(a∣st)
环境转移与反馈在文中写成转移概率 T(s_{t+1}\mid s_t, a_t)。为避免和前面的工具集合 T 混淆,下面记作 \mathcal{T}:
s t + 1 ∼ T ( s t + 1 ∣ s t , a t ) s_{t+1} \sim \mathcal{T}(s_{t+1} \mid s_t, a_t) st+1∼T(st+1∣st,at)
| 符号 | 含义 | 类型 / shape | 解读重点 |
|---|---|---|---|
\tau |
交互轨迹 | 变长序列;长度随 rollout horizon 变化,无固定张量 shape | 后文很多方法本质上都在优化"如何采样、筛选、压缩、复用 \tau" |
s_t |
时刻 t 的状态 |
符号状态;若送入 LLM,通常会被序列化成 token 序列,但论文未给统一长度 T_t |
可对应问题描述、网页 DOM、代码仓库状态、实验场景等 |
a_t |
时刻 t 的动作 |
离散动作 / 文本动作 / 工具调用 / API 调用;非固定张量 | 不是只有自然语言输出,也可以是真实执行动作 |
r_{t+1} |
反馈信号 | 记号上像标量 reward;但论文明确指出实际可扩展为文本批评、执行结果、错误轨迹 | 这解释了为什么 survey 里"reward"不应狭义理解成一个数 |
\pi_{\Phi}(a \mid s_t) |
由 \Phi 参数化的策略 |
条件分布;定义在动作空间上 | 模型中心方法主要在改这条策略,协同进化方法同时改策略和环境 |
\mathcal{T}(s_{t+1} \mid s_t,a_t) |
状态转移机制 | 条件分布 / 环境动态 | 若 \mathcal{T} 也能被训练或扩展,就进入协同进化 |
这一组公式已经把全文串起来了:谁产生动作、谁给反馈、反馈是知识还是评价、环境会不会一起变化。 后面的全部分类,都只是对这四个问题的不同回答。
逐维度拆解
下面按论文主张的三大范式展开。这里的"模块"不再是 Transformer 层,而是 survey 自己定义的演化维度:每一维回答"哪一部分在变、靠什么信号变、变完会沉淀到哪里"。
模型中心自演化:先榨干内部潜力,再把有效轨迹写回参数
这一类方法默认:模型里已经有不少潜在能力,问题是如何在不依赖新人工标注的情况下把它们释放出来。作者把它再拆成两路:推理期增强,以及训练期内化。
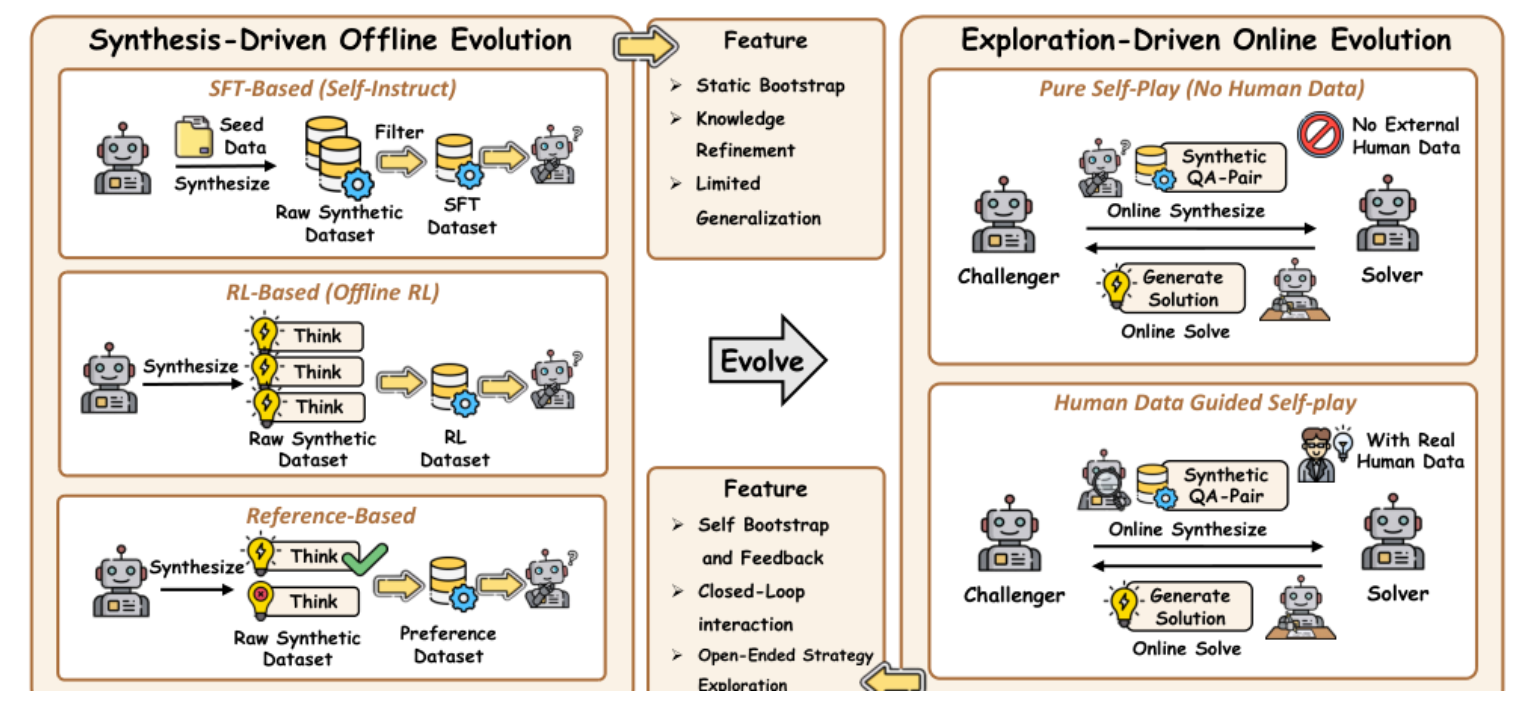
| 子类 | 模块作用 | 输入 → 输出(类型 / shape) | 反馈 / 更新对象 | 代表方法 |
|---|---|---|---|---|
| 并行采样 | 扩大单次求解时的候选覆盖面,降低单路径局部最优 | s_t 或问题描述 → \{y_i\}_{i=1}^N 候选解集;输出为变长文本集合,无固定 shape |
聚合器在候选之间投票、排序或一致性校验;通常不改参数 | Self-Consistency、LLM-BLENDER、Scaling Repeated Sampling |
| 顺序自纠错 | 把"生成---反馈---修正"串成闭环,逐步打磨单条解轨迹 | 初始答案 y^{(0)} + 反馈 f^{(k)} → 修正答案 y^{(k+1)};都是变长文本/执行轨迹 |
依赖 verbal feedback、外部工具验证或失败记忆;通常先改轨迹,再视情况改参数 | Reflexion、SELF-REFINE、CRITIC、PLANSEARCH |
| 结构化推理 | 把线性 CoT 扩成树/图/搜索过程,让推理本身可回溯、可裁剪 | 问题状态 s_t → 搜索结构 G / 树 \mathcal{T}_{search} / 最终解 a_t;对象型结构,无固定张量 shape |
通过搜索、验证、回溯优化推理路径;核心是计算分配,而不是参数更新 | ToT、GoT、RoG、Graph-CoT、LATS |
| 合成驱动离线自进化 | 先用模型自己造数据,再把有效模式蒸馏回参数 | 种子集合 D_{seed} → 合成数据 D_{syn} → 更新后参数 \theta';D_{syn} 是样本集合,大小随生成轮次变化 |
通过 SFT、偏好优化或离线 RL 更新 \theta |
SELF-INSTRUCT、STaR、LMSI、SPIN、ReST-MCTS* |
| 探索驱动在线自进化 | 让模型在环境里试错,自博弈或环境交互产生新策略 | 当前策略 \pi_{\Phi} + 环境 E → 在线轨迹 \tau + 反馈 r → 新策略 \pi_{\Phi'} |
反馈来自自博弈、代码执行、文档语料或外部环境;既可能改参数,也可能改策略缓存 | R-Zero、Absolute Zero、SPIRAL、WebRL、SPICE、TTCS |
这一段最重要的判断有两条。
第一,推理增强和参数增强不是一回事 。并行采样、自纠错、树搜索,本质上在增加 test-time compute;离线/在线自进化才真正把新能力写回 \theta。
第二,离线合成更像 bootstrap,在线探索才更接近持续进化。论文在 Figure 4 里把两者放在一起对照:前者擅长从已有知识里提纯训练样本,后者则通过真实试错获得闭环反馈。作者后面转向环境中心与协同进化,正是因为只靠前者仍会被"模型原有知识边界"卡住。
环境中心自演化:把环境当知识源、经验源、结构源
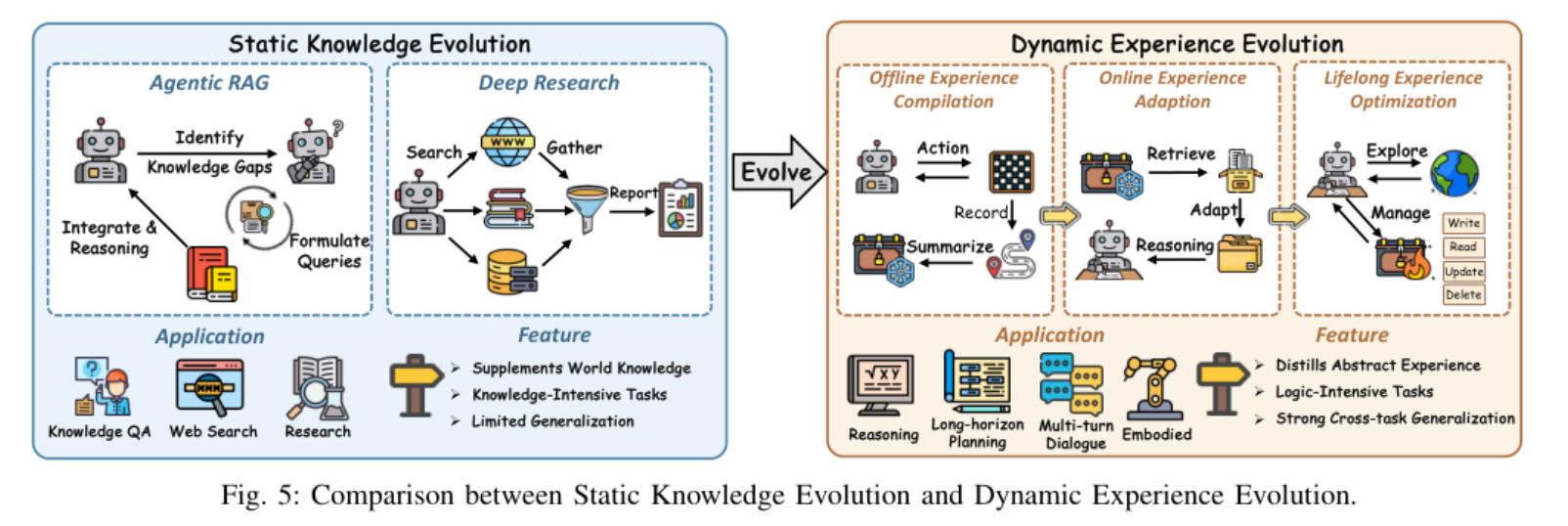
这一类方法的焦点从"怎么让模型自己想得更久"转到"怎么让外部世界持续给模型补东西"。论文把它拆成四条子线:静态知识、动态经验、模块架构、agent 拓扑。
| 方向 | 模块作用 | 输入 → 输出(类型 / shape) | 典型反馈 | 代表方法 |
|---|---|---|---|---|
| 静态知识演化 | 把外部信息源接入 agent,让模型主动识别知识缺口并发起检索 | s_t / 查询意图 → 检索证据集 R_t → 扩展上下文 c_t;都是文档/证据集合,无固定 shape |
检索相关性、证据一致性、报告质量 | SELF-RAG、Search-R1、Search-o1、ReSearch、DeepResearcher、WebThinker |
| 动态经验演化 | 把环境交互轨迹压成可复用经验,用于下一次决策 | 轨迹 \tau → case bank / workflow / skill library / latent memory;记忆条目数随时间增长 |
成功率、奖励、执行结果、自反思、未来状态 | Agent Workflow Memory、Agent KB、Memento、GEPA、ReasoningBank、MemGen |
| 模块架构演化 | 优化 Memory、Tool、Interaction Interface 三类中介模块 | 原始历史 H_t / 工具调用流 → 压缩记忆、路由策略、工具库 T' |
上下文效率、工具效果、长期任务完成度 | MemoryBank、MemGPT、ReadAgent、A-MEM、Mem0、VOYAGER、TOOLMAKER |
| Agent 拓扑演化 | 让多智能体的结构本身成为可学习对象 | 团队图 G_t / workflow code → 新结构 G_{t+1};图结构对象,无固定张量 shape |
协作收益、信息流、执行表现、成本---性能平衡 | AFLOW、MACNET、ADAS、GPTSwarm、AutoAgents、G-Designer、MaAS |
这里有一个很关键的对照:
-
静态知识演化解决的是"我不知道什么",偏向补知识。
-
动态经验演化解决的是"我下次该怎么做",偏向积累做事经验。
论文特别用 Figure 5 把这两条线放在一起:前者让 agent 从环境里拿"事实与证据",后者让 agent 从环境里拿"行为后果与可迁移策略"。这也是为什么作者把 Deep Research、经验库、工作流记忆放在同一个大范式里------它们都依赖环境,只是依赖的环境产物不同。
模型---环境协同进化:环境不再只是反馈器,而是一起训练的对象
这是全文最重要的一段。作者认为,如果环境始终静止,那么 agent 再强,也终会把环境"刷穿"。真正的开放式增长要求环境本身随 agent 一起变难、变广、变可验证。
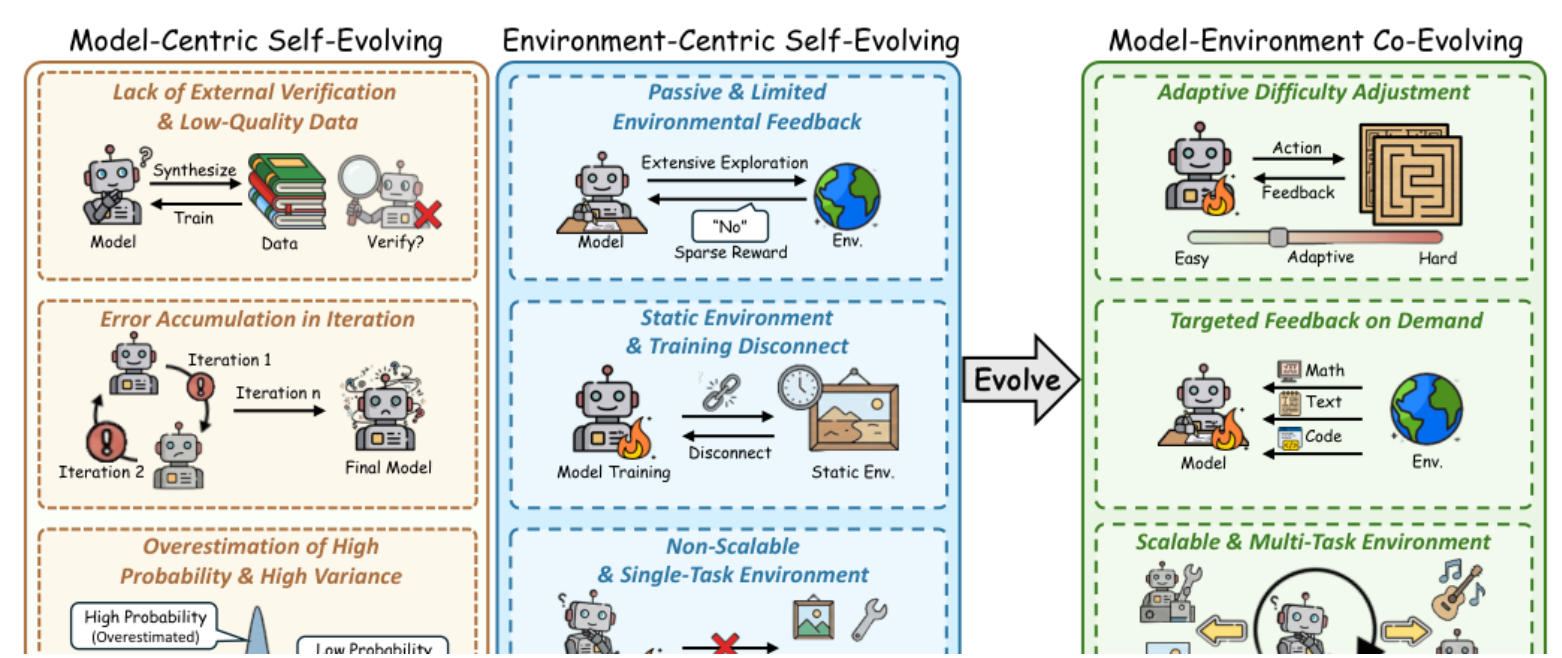
| 方向 | 模块作用 | 输入 → 输出(类型 / shape) | 反馈 / 更新对象 | 代表方法 |
|---|---|---|---|---|
| 多智能体策略协同进化 | 把"其他 agent"本身视为环境的一部分,通过交互共同提升策略 | 多智能体交互轨迹 \tau^{multi} → 更新后的多策略集合 \{\pi_i'\};对象集合,无固定 shape |
内部讨论奖励、协作质量、验证器反馈、对手/队友带来的新策略 | OPTIMA、MAPoRL、MARFT、CoMAS |
| 自适应课程演化 | 根据 agent 当前能力实时调整任务难度 | 能力评估 m_t → 新任务分布 p(task \mid m_t);分布对象,无固定 shape |
难度匹配、样本效率、稳定性 | GenEnv、Environment Tuning、RLVE |
| 可扩展环境演化 | 自动生成大规模、多样化、可验证环境,为持续训练提供新任务 | 环境生成器 g_\psi → 任务实例 / 奖励器 / 验证器集合 \mathcal{E}_{new} |
程序化验证、密集奖励、可扩展任务生成 | DreamGym、AutoEnv、Endless Terminals、Reasoning Gym、AgentGym |
Figure 6 传达的信息很集中:
-
模型中心自演化的问题在于缺少外部验证,容易在迭代中积累错误,还会高估高概率但高方差的轨迹。
-
环境中心自演化的问题在于环境经常是静态的、单任务的、不可扩展的,训练和环境逐渐脱节。
-
协同进化的解法就是把环境做成会跟着 agent 成长的对象:能调难度、能按需给反馈、能生成多任务场景。
这也是论文最明确的结论:自进化的下一阶段,不是继续向模型内部挤更多推理,而是把环境建成"可验证 + 可生长 + 可联合优化"的系统。
训练目标与优化形式化
这篇论文没有给一个统一的全局 loss。它给出的统一形式化是 MDP 式交互闭环,而不是单一训练目标。这一点很重要,因为不同子范式优化的对象根本不同:有的优化 test-time 采样策略,有的优化模型参数,有的优化经验库,有的优化团队拓扑,协同进化甚至连环境也要一起优化。
与其硬写一条论文没有给出的总损失,更忠实的表达方式是把优化信号拆开:
| 优化信号 | 典型来源 | 主要更新对象 | 对应范式 |
|---|---|---|---|
| 候选一致性 / 排名 | 多次采样、自一致性投票、pairwise ranking | 单次推理时的候选选择与聚合策略 | 并行采样、结构化推理 |
| 文本批评 / 自反思 | Reflexion、SELF-REFINE、critic game、self-reflection | 答案轨迹、系统提示、经验条目 | 顺序自纠错、在线经验适配、GEPA/ACE 一类方法 |
| 可执行验证信号 | 编译器、单元测试、代码执行、定理证明器、环境状态码 | 策略参数 \theta、技能库、工具调用策略 |
训练驱动自演化、软件工程 agent、环境训练 |
| 标量奖励 / 偏好信号 | RL、GRPO、对抗博弈、偏好优化 | 策略 \pi_{\Phi} 或参数 \theta |
在线自进化、多智能体协同进化 |
| 检索证据 / 研究材料 | 搜索引擎、知识库、网页、文档语料 | 上下文 c_t、研究报告、外部记忆库 |
静态知识演化、Deep Research |
| 任务难度与环境结构 | 课程调度器、环境生成器、可验证任务工厂 | 环境参数、任务分布、验证器 | 自适应课程演化、可扩展环境演化 |
如果一定要用一句话概括这一节:论文把"loss 设计"上升成了"反馈生态设计"。它关心的不只是奖励函数本身,而是奖励、验证、检索、经验沉淀、任务生成如何共同组成进化闭环。
评测体系、应用证据与风险边界
这篇 survey 不是一篇"统一跑分"的 leaderboard 论文。它对评测的贡献主要是重写 benchmark 版图:哪些 benchmark 在测模型内部能力,哪些 benchmark 真正在测 agent 与环境的交互能力。
Benchmark taxonomy
| 评测桶 | 代表 benchmark | 主要测什么 | 更适合评估的范式 |
|---|---|---|---|
| 通识推理 | MMLU-Pro、HotpotQA、LongBench、AGIEval、ARC | 多跳推理、长上下文、抽象规则、考试式认知 | 模型中心自演化 |
| 科学推理 | GPQA、SuperGPQA、SciBench、ChemBench、SciQA | 专家级科学问答、计算推理、可验证科学问题 | 模型中心 + 协同进化前的可验证训练 |
| 数学推理 | AIME、MATH、OlympiadBench、GSM8K、AMC | 长链条证明、数值求解、竞赛级难题 | 推理增强、在线探索、自博弈 |
| 代码生成 | LiveCodeBench、BigCodeBench、HumanEval、EvalPlus、CRUXEval | 功能正确性、真实库调用、执行级验证 | 训练驱动自演化、软件工程 agent、环境训练 |
| 网页与工具使用 | WebArena、WebVoyager、ToolLLM / ToolBench、Mind2Web、VisualWebArena | 长程网页交互、真实 API 调用、多模态观察---动作闭环 | 环境中心自演化、协同进化 |
| 通用 agent gym / OS / SWE | AgentGym、AgentBench、GAIA、ALFWorld、DeepResearch Bench、SWE-bench、Terminal-Bench、OSWorld | 跨环境任务、研究型搜索、终端与操作系统控制、仓库级修复 | 环境中心自演化、模型---环境协同进化 |
这张表背后的判断很直接:只看静态 QA、数学、代码 benchmark,只能说明模型内部推理够不够强;要判断 self-evolution 是否真的成立,必须看 agent 能不能在环境里持续互动、记忆、修正、扩展。
应用层证据
论文还把应用场景分成三类,并给出了几组非常具体的结果。这些结果的价值不在于"某个数字更高",而在于它们展示了环境反馈已经能把 agent 推到真实工作流里。
| 应用域 | 代表系统 | 环境定义与演化机制 | 论文列出的突破结果 |
|---|---|---|---|
| 自动化科学发现 | The AI Scientist、AlphaProof、ChemCrow、Coscientist、GNoME、A-Lab、CRESt、FARS | 同行评审系统、定理验证器、实验室工具、机器人平台、DFT 模拟空间等构成可验证环境 | GNoME 发现 220 万稳定晶体;A-Lab 在 17 天连续运行中达到 71% 合成成功率;CRESt 找到高性能 8 元催化剂并报告 9.3× cost-performance gain |
| 自主软件工程 | SWE-agent、Claude Code、Manus、OpenClaw、Devin、Cursor | 代码库、终端、CI、浏览器、IDE、项目历史构成强反馈软件环境 | 论文没有给统一横向分数,但强调 bug-fix、长时程编码、技能沉淀和人机协作正在成为环境驱动的主战场 |
| 开放世界模拟 | Voyager、GITM、Cradle、Project Sid、Generative Agents、SIMA、Genie 3 | Minecraft、GUI、虚拟社会、生成式 3D 世界成为可探索、可塑形环境 | Voyager 实现 15.3× faster progression;GITM 在钻石任务上 +47.5% success;Project Sid 展示了社会规范与经济活动的涌现 |
风险与伦理边界
论文没有单列一个伦理章节,也没有给出规范性伦理框架。它对"安全/风险"的处理,主要体现在两类问题上:
-
反馈是否可验证。 代码执行器、单元测试、数学验证器之所以反复被强调,是因为它们能减少 reward hacking 和错误自强化。
-
环境是否足够真实。 论文指出,很多自进化方法仍停留在静态、简化、单任务模拟器里,这会让 agent 在理想化环境中看起来进步很快,但一落到真实世界就掉性能。
也就是说,这篇 survey 对安全的核心理解不是"加一套抽象伦理原则",而是先把验证机制、反馈质量、环境真实性做对。至于更广义的伦理治理,论文并没有展开。
优势与局限
这篇 survey 的价值
-
分类框架清楚。 它不是按任务、按模型、按工具零散罗列,而是按"谁在演化"统一拆成模型、环境、模型---环境三层。
-
形式化足够统一。 用
A = \langle \Phi, M, P, T, I \rangle、E = \langle S, V \rangle、轨迹\tau这三条主线,把后文所有方法装进同一套交互语义里。 -
对未来方向的判断明确。 论文不是中性地说三条路线都重要,而是明确押注协同进化,认为环境定义与环境训练会成为下一阶段关键瓶颈。
-
应用落点具体。 从科学发现、软件工程到开放世界模拟,作者给出的不是空泛"有前景",而是列出了已经跑到真实环境中的系统与结果。
论文自己指出的局限
-
静态且不可自适应的环境仍是主流。 环境不长大,agent 最终会把它学穿。
-
过度依赖可自动验证任务。 编译器、测试、证明器很好用,但也把研究重心锁在了更容易验证的任务上。
-
模拟环境真实度有限。 简化模拟器难以覆盖物理世界和开放社会里的噪声、随机性与复杂因果。
-
仍依赖人类初始化。 很多"自进化"方法的起点仍是人工 prompt、人工偏好或人工提供的初始范式。
-
自生成训练会带来 model collapse。 反复在自生成数据上训练,容易丢失长尾信息和策略多样性,削弱泛化能力。
作者最终给出的方向也很集中:环境要能随 agent 一起长大,要更真实、更开放、能连接多个模拟器与真实系统,还要把自进化从"有标准答案的任务"推向"没有明确 ground truth 但依然能自校验"的任务。