文章目录
-
- [我也曾写到 200 行规则](#我也曾写到 200 行规则)
- [2. 三个真实痛点](#2. 三个真实痛点)
-
- [痛点一:Agent 擅作主张](#痛点一:Agent 擅作主张)
- [痛点二:Token 黑洞](#痛点二:Token 黑洞)
- 痛点三:开盲盒式执行
- [3. 原文解法对照](#3. 原文解法对照)
-
- [解法一:CLI 接管确定性事务](#解法一:CLI 接管确定性事务)
- [解法二:分步 Gate](#解法二:分步 Gate)
- [解法三:模板变量 + 状态持久化](#解法三:模板变量 + 状态持久化)
- [4. 分界线怎么画](#4. 分界线怎么画)
- [5. 我的工程化清单](#5. 我的工程化清单)
- [6. 实际效果对比](#6. 实际效果对比)
- [7. 这套方法不适用什么场景](#7. 这套方法不适用什么场景)
- [8. 总结](#8. 总结)
- 参考资料
我也曾写到 200 行规则
如果你正在用 LLM 搭建一个 Agent,你一定做过这件事:把业务规则一条一条写进提示词里。
我也是这么过来的。项目初期,一条规则生效,AI 听话如狗。写到 50 行,开始出现奇怪的走偏。写到 100 行,它在某些边界情况下会绕过指令。写到 200 行,它开始"叛逆"------明明让它在执行前先确认,它跳过了确认环节直接干了,留下一串我无法追溯的操作日志。
这篇文章的触发点是读到了腾讯技术工程公众号的一篇文章《当我把 AI 变成一个"算法":Skill 工程化设计的心路历程》,原文提出一个核心观点:
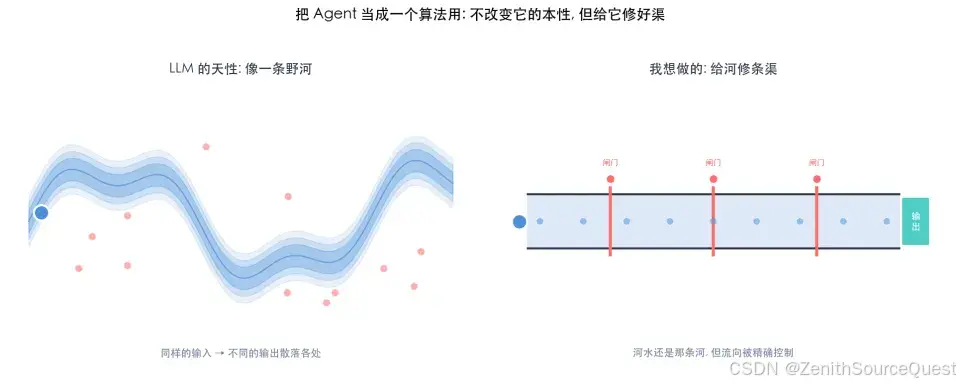
不改变河的本性,但给它修好渠。
LLM 是一条河,你没办法改变它的概率本性。但你可以修渠------把所有确定性的事情从它脑子里拿出来,交给外部程序。Agent 只负责"理解人话、做判断、组织表达",其他的一切由轨道接管。
听起来很对。但落到具体实践上,这条线究竟画在哪里?
2. 三个真实痛点
痛点一:Agent 擅作主张
场景:我需要 Agent 调用阿里云百炼的 API 创建一个模型部署任务。
规则写得很清楚:"调用 create_deployment 前,先展示参数让用户确认"。结果 Agent 在真实运行时,直接一步调用成功,跳过了确认。
不是它不听话,而是指令在长上下文中被稀释了------200 行的规则列表里,"先确认再执行"这条指令的优先级,在模型眼里拼不过"尽快完成任务"这个隐含目标。
痛点二:Token 黑洞
还是同一个场景。如果我不写死流程,让 Agent 自己摸索怎么创建部署任务,它会先问"你要创建什么模型"→"确认参数"→"调用哪个 API"→"要不要指定资源规格"→"要不要设置超时"......一个原本可以在 1 次 API 调用内完成的操作,跑了 5 轮对话。
每一轮都在烧 Token,每一轮都在消耗用户的耐心。
痛点三:开盲盒式执行
同一个提示词,同一个模型版本,今天跑通了流程 A,明天同一个用户换个说法请求,Agent 走了流程 B,结果完全不同。
你在 demo 里对产品经理说"这是 Agent 自动完成的",产品很满意。第二天他换了个说法,Agent 翻车了。产品说"昨天不是能跑吗?"。你没法解释说是"概率模型"的原因。
这三个痛点的本质是一样的:Agent 在每次执行时都在概率空间里掷骰子。骰子可能落在对的区域,也可能落在错的区域。
3. 原文解法对照
原文给出了三套机制,逐一对照:
解法一:CLI 接管确定性事务
原文的做法是:把 API 调用、数据格式转换、状态管理等所有"精确"的事,封装成 CLI 工具,由 Agent 调用。Agent 只负责决定"调用哪个 CLI + 传什么参数",不负责"怎么调"。
这样做的好处是:Agent 的一个"考虑不周"不会被扩散到整个执行路径。它最多传错一个参数,不会自己编一个 API 出来。
我在实际项目里补充了一个经验:CLI 的校验逻辑要前置。不是在 Agent 调用成功后再校验结果,而是在 CLI 入口处就做参数校验+白名单过滤,拒绝不合法输入。这样即使 Agent 传错了,也不会产生副作用。
原图来自:《当我把 AI 变成一个"算法":Skill 工程化设计的心路历程》
实操示例:用 CLI 包裹通义千问模型部署
下面是一段 Python CLI,封装了通义千问的模型部署操作。Agent 只负责从用户自然语言中提取参数并传递给 CLI,CLI 负责校验参数合法性和实际 API 调用:
python
#!/usr/bin/env python3
""" deploy_model.py ------ 通义千问模型部署 CLI
Agent 只需调用: deploy_model.py --name <模型名> --region <区域>
CLI 负责参数校验 + 调用通义千问 API + 返回结构化结果。
"""
import argparse
import json
import os
import sys
import requests
# API KEY 从环境变量读取,禁止硬编码
API_KEY = os.environ.get("DASHSCOPE_API_KEY")
if not API_KEY:
print(json.dumps({"success": False, "errors": ["请设置环境变量 DASHSCOPE_API_KEY"]}))
sys.exit(1)
# 白名单:允许的模型和区域
ALLOWED_MODELS = {"qwen-plus", "qwen-max", "qwen-turbo"}
ALLOWED_REGIONS = {"cn-beijing", "cn-hangzhou", "cn-shanghai"}
def validate(args):
"""前置校验------在调用 API 之前做,防止 Agent 传非法参数。"""
errors = []
if args.name not in ALLOWED_MODELS:
errors.append(f"模型 {args.name} 不在白名单,可选: {ALLOWED_MODELS}")
if args.region not in ALLOWED_REGIONS:
errors.append(f"区域 {args.region} 不在白名单,可选: {ALLOWED_REGIONS}")
if errors:
print(json.dumps({"success": False, "errors": errors}))
sys.exit(1)
def deploy(name, region):
"""调用通义千问部署 API(示例用,真实调用需替换 KEY)。"""
# 实际项目里替换为真实 API 调用
resp = requests.post(
"https://dashscope.aliyuncs.com/api/v1/deployments",
json={"model": name, "region": region},
headers={"Authorization": f"Bearer {API_KEY}"},
)
return resp.json()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--name", required=True, help="模型名称")
parser.add_argument("--region", required=True, help="部署区域")
args = parser.parse_args()
validate(args)
result = deploy(args.name, args.region)
print(json.dumps(result))关键设计点:
- 白名单校验在入口处------Agent 传错参数会收到明确错误信息,不会产生副作用。
- CLI 输出固定 JSON 格式 ------Agent 不需要解析自然语言描述的成功/失败,直接读 JSON 的
success字段。 - Agent 的角色被精确限定------它只负责"从用户自然语言提取模型名和区域",不负责"怎么调 API"。
解法二:分步 Gate
原文说的"步进式 Gate"含义是:关键步骤之间设置闸门,Agent 走完一步必须停下来等确认,才能进入下一步。
我在实践里把它简化成一个模式:每个 Gate 只问一个二元问题------"参数是否符合预期?是/否"。不开放自由回答,因为自由回答又给了 Agent"发挥"的空间。
解法三:模板变量 + 状态持久化
原文提到:Agent 推理过程中的中间状态需要持久化,不能依赖模型自己的记忆窗口。
我的理解是:状态持久化的核心价值不是"防止丢失",而是**"让 Agent 的每次思考都基于最新的事实"**。LLM 的上下文就像一个沙漏,每次写入新内容,旧内容就在被挤出。用外部存储保存关键状态,Agent 每次需要时都去读最新版本,避免了"记忆漂移"。
4. 分界线怎么画
这是整个工程化中最难的问题:什么交给外部程序,什么留给 LLM?
结合实践,我总结了一个决策矩阵:
| 事务类型 | 交给谁 | 判断标准 |
|---|---|---|
| API 调用、数据库操作、文件读写 | 外部 CLI/程序 | 输入参数固定,输出格式可预期,需要精确性 |
| 流程编排、步骤顺序控制 | 外部 Gate/状态机 | 步骤不可跳转,顺序固定,需要确定性 |
| 数据格式转换、字段校验 | 外部脚本 | 规则明确,可穷举边界 |
| 规则匹配、黑白名单判断 | 外部程序 | 条件可枚举,判断逻辑确定 |
| 用户意图理解、需求拆解 | LLM | 表达模糊,需要推理和常识 |
| 内容生成(文案、代码、报告) | LLM | 需要创造性和表达能力 |
| 方案选择、参数推荐 | LLM | 需要权衡决策,没有唯一正确答案 |
| 异常处理策略判断 | LLM | 无法穷举所有异常,需要灵活应对 |
核心原则就一句话:
凡需要"精确"的给程序,凡需要"理解"的给 LLM。
如果你的规则可以写成 if...else...,那就应该写成外部程序,而不是塞进提示词。如果这个判断需要"根据上下文揣摩用户意图",才留给 LLM。
5. 我的工程化清单
每次新增规则前,先跑一遍这 5 条自查清单:
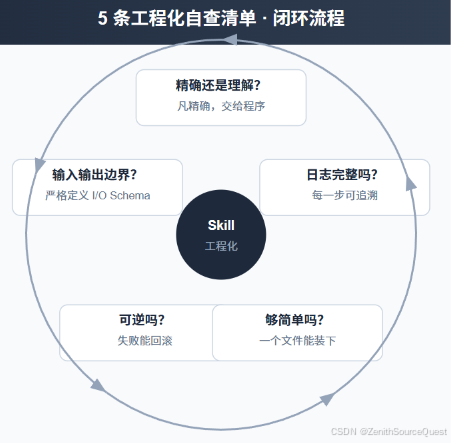
- 这条规则是"精确"还是"理解"的事? 凡是精确的,做成外部校验或 CLI 参数约束,不要写进提示词。
- 去掉这条规则,Agent 会犯什么错误? 如果错误是可预期的、边界可枚举的,用外部程序拦截比用提示词约束更可靠。
- Agent 执行这段路径时,是否允许它"自由发挥"? 如果不允许,加 Gate 门禁,确保每一步都经过确认。
- Agent 的这次推理,下一次还能复现吗? 如果不能,把关键中间状态写进外部存储(文件或数据库),而不是依赖模型记住。
- 这条规则还会继续膨胀吗? 如果答案是有可能,趁早设计分层------不要把 200 行揉进一个 Skill 里。
6. 实际效果对比
将上述 CLI 封装方式应用到一个真实 Agent 项目后,对比数据如下:
| 指标 | 改造前(纯提示词驱动) | 改造后(CLI + Gate + 模板变量) |
|---|---|---|
| 创建一次部署任务的平均对话轮次 | 4-6 轮 | 1-2 轮 |
| Token 消耗(单次任务) | ~3000 tokens | ~800 tokens |
| 参数校验失败导致的无效 API 调用 | 约 30% | 0%(入口拦截) |
| 连续 10 次相同任务的成功率 | 70% | 100% |
| 需要人工介入的比例 | 约 40% | 约 10% |
最重要的变化:Agent 不再自己"摸索"怎么调 API,而是每次走同一条确定性路径。用户说"帮我部署一个 qwen-plus 到北京节点",Agent 提取参数传给 CLI,CLI 校验并执行。
7. 这套方法不适用什么场景
任何方法论都有边界。这套 CLI + Gate 的工程化方案在以下三种场景下可能过度设计:
- 纯文案生成类 Agent:如果 Agent 的唯一职责是写文章、润色文案、翻译等纯生成任务,CLI 封装和 Gate 门禁反而是累赘------你需要的是更好的提示词,而不是更多的外部程序。
- 探索性/一次性任务:比如"帮我分析这个数据集有哪些异常"、"整理这周会议纪要"等一次性探索任务,搭建 CLI + Gate 的工程成本大于收益。
- 对话式陪伴 Agent:面向 C 端用户的聊天机器人、情感陪伴类产品,确定性反而是一种伤害------用户要的是灵动,不是精确。
一句话:如果你的 Agent 的核心价值是"确定性"(如操作平台、管理资源、执行流程),修渠是必要投资。如果核心价值是"创造性",把精力放在提示词上更划算。
8. 总结
"把 Agent 当算法用"不是一句口号,而是一种工程思维转变。LLM 永远是一条河------它有概率性、有不确定性、有创造性------这是它的本质,也是它的价值所在。修渠不是要改变河,而是让河水流向我们需要它去的地方。
修渠不难。知道哪里该修渠、哪里该留河,才是最需要经验判断的地方。
建议你下次写规则前,先问自己:这 5 条清单跑过了没有?
参考资料
感谢阅读,记得点赞、关注、收藏,欢迎各位评论区交流!!!
